AI Native Daily Paper Digest – 20250701

1. Ovis-U1 Technical Report
🔑 Keywords: Ovis-U1, multimodal understanding, text-to-image generation, image editing, diffusion-based visual decoder
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Ovis-U1, a 3-billion-parameter model, integrating multimodal understanding, text-to-image generation, and image editing.
🛠️ Research Methods:
– Utilized unified training starting from a language model paired with a diffusion-based visual decoder for enhanced image generation tasks.
💬 Research Conclusions:
– Ovis-U1 surpasses existing models in benchmarks such as OpenCompass, DPG-Bench, and GenEval, highlighting its state-of-the-art performance in multimodal capabilities.
👉 Paper link: https://huggingface.co/papers/2506.23044

2. SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning
🔑 Keywords: SPIRAL, Zero-Sum Games, Self-Play Framework, Reinforcement Learning, Reasoning Capabilities
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reasoning capabilities in language models through self-improvement and transfer learning using the SPIRAL framework.
🛠️ Research Methods:
– Introduced a self-play framework where models engage in multi-turn, zero-sum games without human supervision, using an online, multi-turn, multi-agent reinforcement learning system and role-conditioned advantage estimation.
💬 Research Conclusions:
– SPIRAL enables broad transfer of reasoning capabilities with significant improvements in reasoning and mathematical tasks, demonstrating that zero-sum games naturally develop transferable reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2506.24119

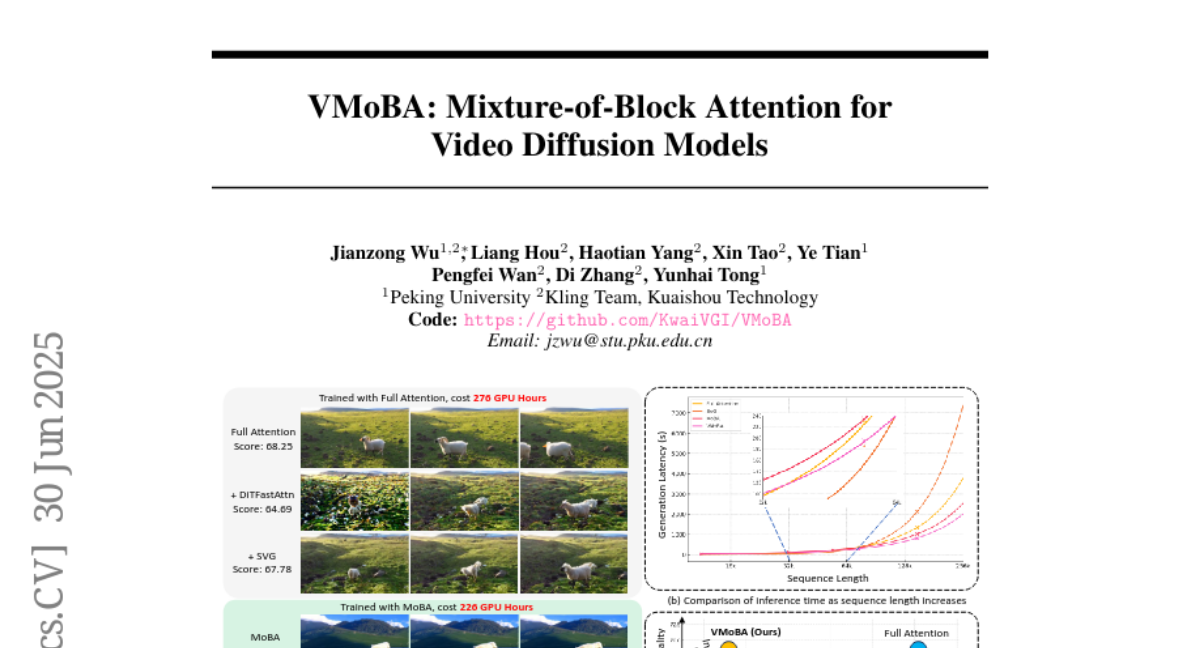
3. VMoBA: Mixture-of-Block Attention for Video Diffusion Models
🔑 Keywords: Video Diffusion Models, Sparse Attention, VMoBA, Spatio-temporal Locality, High-resolution Video Generation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to introduce VMoBA, a novel sparse attention mechanism to accelerate training and inference of Video Diffusion Models (VDMs) while improving or maintaining video generation quality.
🛠️ Research Methods:
– Develop three key modifications in the original MoBA framework with VMoBA: a layer-wise recurrent block partition scheme, global block selection, and threshold-based block selection to optimize spatio-temporal attention patterns.
💬 Research Conclusions:
– VMoBA significantly increases the efficiency of VDMs, with a 2.92x speedup in FLOPs and 1.48x in latency while maintaining comparable or superior video generation quality. It also improves training-free inference efficiency with 2.40x FLOPs and 1.35x latency speedup for high-resolution video generation.
👉 Paper link: https://huggingface.co/papers/2506.23858
4. Calligrapher: Freestyle Text Image Customization
🔑 Keywords: Calligrapher, diffusion-based framework, self-distillation, localized style injection, large language model
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal is to introduce a novel framework, Calligrapher, that enhances digital typography by integrating advanced text customization with artistic design.
🛠️ Research Methods:
– The study employs a self-distillation mechanism using pre-trained text-to-image generative models and large language models to create a style-centric typography benchmark.
– It introduces a localized style injection framework with a trainable style encoder to extract robust style features, and uses in-context generation to embed reference images in the denoising process.
💬 Research Conclusions:
– Calligrapher accurately reproduces intricate stylistic details and precise glyph positioning, surpassing traditional models in generating visually consistent typography for digital art, branding, and design tasks.
👉 Paper link: https://huggingface.co/papers/2506.24123

5. Listener-Rewarded Thinking in VLMs for Image Preferences
🔑 Keywords: Listener-Augmented GRPO, Vision-Language Models, Reinforcement Learning, Out-of-Distribution Performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance reward models’ accuracy and out-of-distribution performance in aligning vision-language models with human preferences.
🛠️ Research Methods:
– Introduce a listener-augmented Group Relative Policy Optimization (GRPO) framework where a ‘listener’ model re-evaluates the reasoning process to provide a calibrated confidence score.
💬 Research Conclusions:
– Achieved highest accuracy on ImageReward benchmark (67.4%) and improved out-of-distribution performance significantly, reducing reasoning contradictions and demonstrating scalability and data efficiency for aligning vision-language models with human preferences.
👉 Paper link: https://huggingface.co/papers/2506.22832
