AI Native Daily Paper Digest – 20250718

1. A Survey of Context Engineering for Large Language Models
🔑 Keywords: Context Engineering, Large Language Models, Contextual Information, Retrieval-Augmented Generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The survey introduces Context Engineering as a discipline to optimize information payloads for Large Language Models, surpassing simple prompt design.
🛠️ Research Methods:
– A comprehensive taxonomy is presented, decomposing Context Engineering into foundational components: context retrieval, generation, processing, and management.
– It analyzes the integration of these components into systems like retrieval-augmented generation, memory systems, tool-integrated reasoning, and multi-agent systems.
💬 Research Conclusions:
– A crucial research gap is identified: a disparity between the high context understanding ability and the limited sophistication in generating long-form outputs in LLMs.
– The survey establishes a technical roadmap and a unified framework for researchers and engineers to advance context-aware AI.
👉 Paper link: https://huggingface.co/papers/2507.13334

2. VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
🔑 Keywords: VisionThink, visual tokens, token compression, reinforcement learning, OCR tasks
💡 Category: Computer Vision
🌟 Research Objective:
– VisionThink aims to improve vision-language tasks efficiency by dynamically adjusting image resolution and processing visual tokens, particularly enhancing OCR task performance while reducing token usage in simpler tasks.
🛠️ Research Methods:
– The study implements a new paradigm for visual token compression, using a downsampled image initially and determining the necessity of higher resolution based on a special token request. Reinforcement learning, with the LLM-as-Judge strategy, is applied for decision-making in VQA tasks.
💬 Research Conclusions:
– The results show that VisionThink provides robust visual understanding in OCR tasks and reduces unnecessary visual token use in simpler scenarios, demonstrating the method’s superiority, efficiency, and effectiveness.
👉 Paper link: https://huggingface.co/papers/2507.13348

3. π^3: Scalable Permutation-Equivariant Visual Geometry Learning
🔑 Keywords: Permutation-equivariant architecture, Camera pose estimation, Depth estimation, Point map reconstruction, AI-generated
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to introduce and demonstrate the capabilities of pi^3, a permutation-equivariant neural network, in achieving robust visual geometry reconstruction without relying on a fixed reference view.
🛠️ Research Methods:
– Utilizes a permutation-equivariant architecture to predict affine-invariant camera poses and scale-invariant local point maps, making the approach robust to input ordering and scalable.
💬 Research Conclusions:
– pi^3 achieves state-of-the-art performance in camera pose estimation, monocular and video depth estimation, and dense point map reconstruction without the biases of traditional fixed reference methods.
👉 Paper link: https://huggingface.co/papers/2507.13347

4. The Imitation Game: Turing Machine Imitator is Length Generalizable Reasoner
🔑 Keywords: TAIL, Length generalization, Turing Machine, Chain-of-thought, Synthetic dataset
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to improve the length generalization and performance of large language models (LLMs) through a method called Turing Machine Imitation Learning (TAIL).
🛠️ Research Methods:
– TAIL synthesizes chain-of-thought data which imitates the execution process of a Turing Machine, expanding reasoning steps into atomic states to reduce shortcut learning and facilitate data access in elementary operations.
💬 Research Conclusions:
– TAIL significantly enhances the length generalization and performance of LLMs, such as Qwen2.5-7B, on a synthetic dataset composed of various algorithm classes and tasks, surpassing previous methods.
👉 Paper link: https://huggingface.co/papers/2507.13332

5. AnyCap Project: A Unified Framework, Dataset, and Benchmark for Controllable Omni-modal Captioning
🔑 Keywords: AnyCap Project, Controllable Captioning, AnyCapModel, AI Native, AnyCapEval
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The AnyCap Project aims to improve controllability and reliability in multimodal captioning through an integrated solution that includes a framework, dataset, and evaluation protocol.
🛠️ Research Methods:
– The project introduces AnyCapModel, a lightweight plug-and-play framework enhancing existing foundation models’ controllability without retraining. It utilizes AnyCapDataset, encompassing multiple modalities and user instructions, and proposes AnyCapEval for reliable evaluation metrics.
💬 Research Conclusions:
– AnyCapModel significantly improves caption quality, as evidenced by improvements in content and style scores, notably enhancing GPT-4o’s performance and achieving gains on established benchmarks like MIA-Bench and VidCapBench.
👉 Paper link: https://huggingface.co/papers/2507.12841

6. Diffuman4D: 4D Consistent Human View Synthesis from Sparse-View Videos with Spatio-Temporal Diffusion Models
🔑 Keywords: 4D diffusion models, spatio-temporal consistency, sliding iterative denoising, latent grid, high-fidelity view synthesis
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to improve high-fidelity view synthesis from sparse-view videos by enhancing spatio-temporal consistency using a novel sliding iterative denoising process in 4D diffusion models.
🛠️ Research Methods:
– A sliding iterative denoising process is introduced, defining a latent grid that encodes image, camera pose, and human pose. The grid is denoised along spatial and temporal dimensions with a sliding window, followed by decoding the denoised latents to generate videos.
💬 Research Conclusions:
– The method significantly enhances 4D consistency, enabling high-quality, consistent novel-view video synthesis. Experimental results on datasets like DNA-Rendering and ActorsHQ show superior performance compared to existing approaches.
👉 Paper link: https://huggingface.co/papers/2507.13344
7. RiemannLoRA: A Unified Riemannian Framework for Ambiguity-Free LoRA Optimization
🔑 Keywords: RiemannLoRA, LoRA, Large Language Models, smooth manifold, Riemannian optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve convergence speed and performance in Large Language Models (LLMs) and diffusion models using a novel approach to Low-Rank Adaptation (LoRA) by treating LoRA matrices as a smooth manifold.
🛠️ Research Methods:
– Implementing the approach by leveraging best practices from numerical linear algebra and Riemannian optimization, focusing on numerical stability and computational efficiency.
💬 Research Conclusions:
– RiemannLoRA consistently enhances both convergence speed and final performance over standard LoRA and its state-of-the-art modifications in LLM and diffusion model architectures.
👉 Paper link: https://huggingface.co/papers/2507.12142

8. MindJourney: Test-Time Scaling with World Models for Spatial Reasoning
🔑 Keywords: 3D reasoning, vision-language models, world model, video diffusion, spatial reasoning
💡 Category: Computer Vision
🌟 Research Objective:
– The objective of the research is to enhance vision-language models with 3D reasoning capabilities by coupling them with a video diffusion-based world model, aiming to improve performance on spatial reasoning tasks.
🛠️ Research Methods:
– The researchers propose MindJourney, a framework that leverages a controllable world model based on video diffusion. This model allows vision-language models to simulate camera trajectories and synthesize views iteratively for 3D reasoning without requiring fine-tuning.
💬 Research Conclusions:
– The study concludes that MindJourney results in an average 8% improvement on a spatial reasoning benchmark (SAT) and demonstrates the effectiveness of pairing vision-language models with world models for robust 3D reasoning and improved test-time inference.
👉 Paper link: https://huggingface.co/papers/2507.12508
9. FantasyPortrait: Enhancing Multi-Character Portrait Animation with Expression-Augmented Diffusion Transformers
🔑 Keywords: diffusion transformer, implicit representations, masked cross-attention, AI-generated summary, FantasyPortrait
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop FantasyPortrait, a diffusion transformer framework, to generate high-fidelity, emotion-rich facial animations in single and multi-character scenarios.
🛠️ Research Methods:
– The framework uses expression-augmented learning and implicit representations to capture identity-agnostic facial dynamics.
– It introduces a masked cross-attention mechanism for independent yet coordinated multi-character expression generation to prevent feature interference.
💬 Research Conclusions:
– FantasyPortrait significantly outperforms existing methods in generating expressive animations in challenging cross reenactment and multi-character contexts, as demonstrated by extensive experiments using newly proposed datasets and benchmarks.
👉 Paper link: https://huggingface.co/papers/2507.12956
10. Voxtral
🔑 Keywords: Voxtral, Multimodal Audio Chat, Spoken Audio, Context Window, State-of-the-Art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Present two multimodal audio chat models, Voxtral Mini and Voxtral Small, designed for comprehensive audio and text comprehension.
🛠️ Research Methods:
– Trained to achieve state-of-the-art performance on diverse audio benchmarks and retain strong text comprehension capabilities.
💬 Research Conclusions:
– Voxtral models handle long audio files and conversations with a 32K context window and outperform several closed-source models while being capable of local execution.
– Released under the Apache 2.0 license.
– Three new benchmarks introduced for evaluating speech understanding models on knowledge and trivia.
👉 Paper link: https://huggingface.co/papers/2507.13264

11. AbGen: Evaluating Large Language Models in Ablation Study Design and Evaluation for Scientific Research
🔑 Keywords: LLMs, AbGen, ablation studies, NLP papers, automated evaluation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce AbGen, a benchmark designed to evaluate the capabilities of LLMs in designing ablation studies for scientific research.
🛠️ Research Methods:
– Assessment of the performance of leading LLMs like DeepSeek-R1-0528 and o4-mini in generating ablation study designs.
– Development of AbGen-Eval, a meta-evaluation benchmark to assess the reliability of automated evaluation systems.
💬 Research Conclusions:
– Significant performance gap found between LLMs and human experts in designing ablation studies.
– Current automated evaluation methods are unreliable, showing discrepancies with human assessments.
👉 Paper link: https://huggingface.co/papers/2507.13300

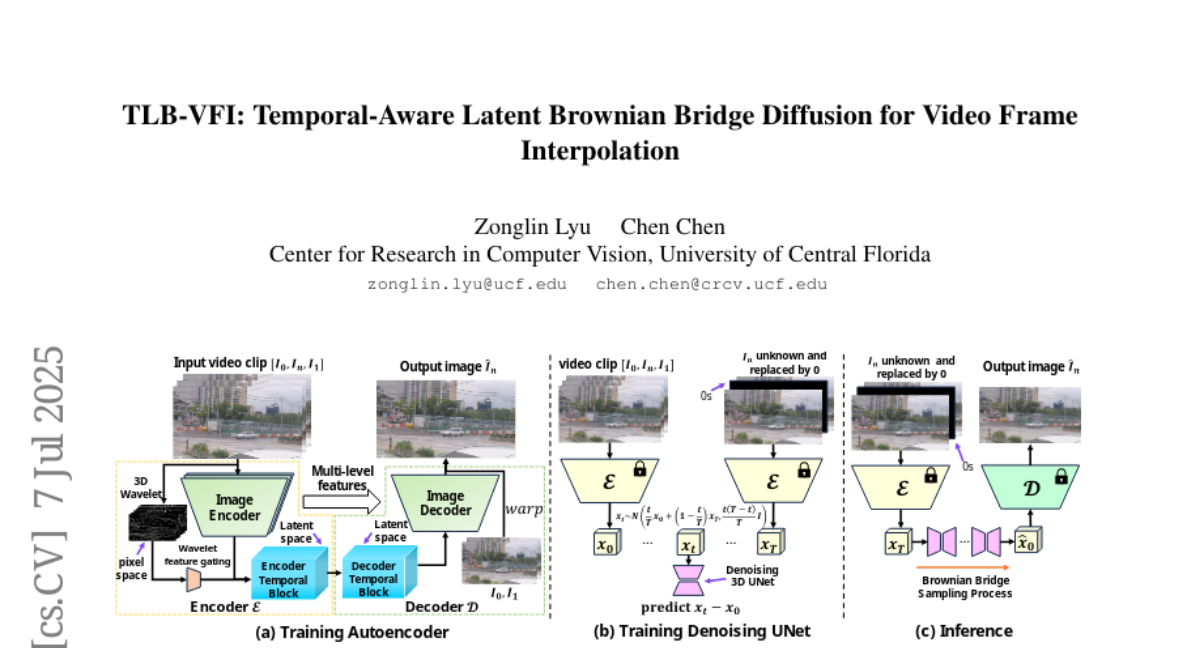
12. TLB-VFI: Temporal-Aware Latent Brownian Bridge Diffusion for Video Frame Interpolation
🔑 Keywords: VFI, diffusion models, temporal information, 3D-wavelet gating, temporal-aware autoencoder
💡 Category: Computer Vision
🌟 Research Objective:
– To improve Video Frame Interpolation by efficiently extracting temporal information and reducing parameters compared to existing methods.
🛠️ Research Methods:
– Developed Temporal-Aware Latent Brownian Bridge Diffusion (TLB-VFI) with 3D-wavelet gating and a temporal-aware autoencoder.
– Incorporated optical flow guidance to significantly reduce the training data requirement.
💬 Research Conclusions:
– Achieved a 20% improvement in FID on challenging datasets over recent state-of-the-art image-based diffusion models.
– The method provides 3x fewer parameters and a 2.3x speed increase, requiring 9000x less training data and achieving over 20x fewer parameters than previous video-based diffusion models.
👉 Paper link: https://huggingface.co/papers/2507.04984
13. Teach Old SAEs New Domain Tricks with Boosting
🔑 Keywords: Sparse Autoencoders, Large Language Models, Residual Learning, Reconstruction Error, Targeted Mechanistic Interpretability
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance Sparse Autoencoders to capture domain-specific features without requiring complete retraining.
🛠️ Research Methods:
– Introduce a residual learning approach to address feature blindness in SAEs by training a secondary SAE to model reconstruction error on domain-specific texts.
💬 Research Conclusions:
– The proposed approach improves LLM cross-entropy and explained variance metrics, enabling more effective SAE interpretability for specialized domains.
👉 Paper link: https://huggingface.co/papers/2507.12990

14. FLEXITOKENS: Flexible Tokenization for Evolving Language Models
🔑 Keywords: FLEXITOKENS, byte-level LMs, learnable tokenizers, token over-fragmentation, multilingual
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to develop byte-level language models (LMs) with learnable tokenizers to reduce token over-fragmentation and improve performance across multilingual and morphologically diverse tasks.
🛠️ Research Methods:
– The study creates a submodule that predicts boundaries between the input byte sequence, encoding it into variable-length segments, utilizing a simplified training objective for flexibility.
💬 Research Conclusions:
– FLEXITOKENS significantly reduces token over-fragmentation and achieves up to 10% improvements on downstream task performance compared to other tokenization methods. The code and data for experiments are made available on GitHub.
👉 Paper link: https://huggingface.co/papers/2507.12720

15. Automating Steering for Safe Multimodal Large Language Models
🔑 Keywords: Multimodal Large Language Models, AutoSteer, Safety Awareness Score, attack success rates
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The goal is to enhance the safety of Multimodal Large Language Models (MLLMs) by reducing attack success rates using a modular inference-time intervention technology called AutoSteer.
🛠️ Research Methods:
– AutoSteer incorporates three core components: a novel Safety Awareness Score (SAS), an adaptive safety prober to estimate toxic output likelihood, and a lightweight Refusal Head for selective intervention.
💬 Research Conclusions:
– AutoSteer effectively lowers the attack success rate for textual, visual, and cross-modal threats without affecting the general abilities of MLLMs, making it a practical and interpretable solution for safer AI system deployment.
👉 Paper link: https://huggingface.co/papers/2507.13255

16. Einstein Fields: A Neural Perspective To Computational General Relativity
🔑 Keywords: Einstein Fields, neural tensor field, numerical relativity, implicit neural network, JAX-based library
💡 Category: Foundations of AI
🌟 Research Objective:
– The main goal is to compress four-dimensional numerical relativity simulations into compact neural network weights using Einstein Fields.
🛠️ Research Methods:
– Einstein Fields employ a neural tensor field representation to model core tensor fields of general relativity, facilitating the derivation of physical quantities through automatic differentiation.
💬 Research Conclusions:
– Einstein Fields demonstrate significant potential in continuum modeling of 4D spacetime with benefits such as mesh-agnosticity, storage efficiency, and ease of use, supported by an open-source JAX-based library.
👉 Paper link: https://huggingface.co/papers/2507.11589

17.
