AI Native Daily Paper Digest – 20250721

1. A Data-Centric Framework for Addressing Phonetic and Prosodic Challenges in Russian Speech Generative Models
🔑 Keywords: Russian speech synthesis, Balalaika, dataset, textual annotations, speech enhancement
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Balalaika, a large Russian speech dataset designed to improve speech synthesis and enhancement tasks, addressing specific challenges in Russian language processing.
🛠️ Research Methods:
– Developed a dataset with over 2,000 hours of studio-quality Russian speech, detailed with comprehensive textual annotations, such as punctuation and stress markings.
💬 Research Conclusions:
– Demonstrated that models trained on Balalaika outperform those trained on existing datasets, highlighting the effectiveness of detailed annotations in improving synthesis and enhancement performance.
👉 Paper link: https://huggingface.co/papers/2507.13563

2. The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs
🔑 Keywords: diffusion-based large language models, adversarial prompts, AI-generated summary, jailbreaking, parallel decoding
💡 Category: Generative Models
🌟 Research Objective:
– To identify and exploit safety vulnerabilities within diffusion-based large language models (dLLMs) using the framework DIJA, highlighting weaknesses in current alignment mechanisms.
🛠️ Research Methods:
– Development of the DIJA framework to systematically create and test adversarial interleaved mask-text prompts targeting dLLMs’ bidirectional modeling and parallel decoding processes.
– Comprehensive experiments demonstrating the effectiveness of DIJA against existing jailbreak methods.
💬 Research Conclusions:
– DIJA significantly outperforms existing methods by exposing unrecognized threat surfaces in dLLM architectures, achieving notable improvements in ASR benchmarks without masking harmful content. This calls for an urgent reevaluation of safety alignment in these emerging models.
👉 Paper link: https://huggingface.co/papers/2507.11097

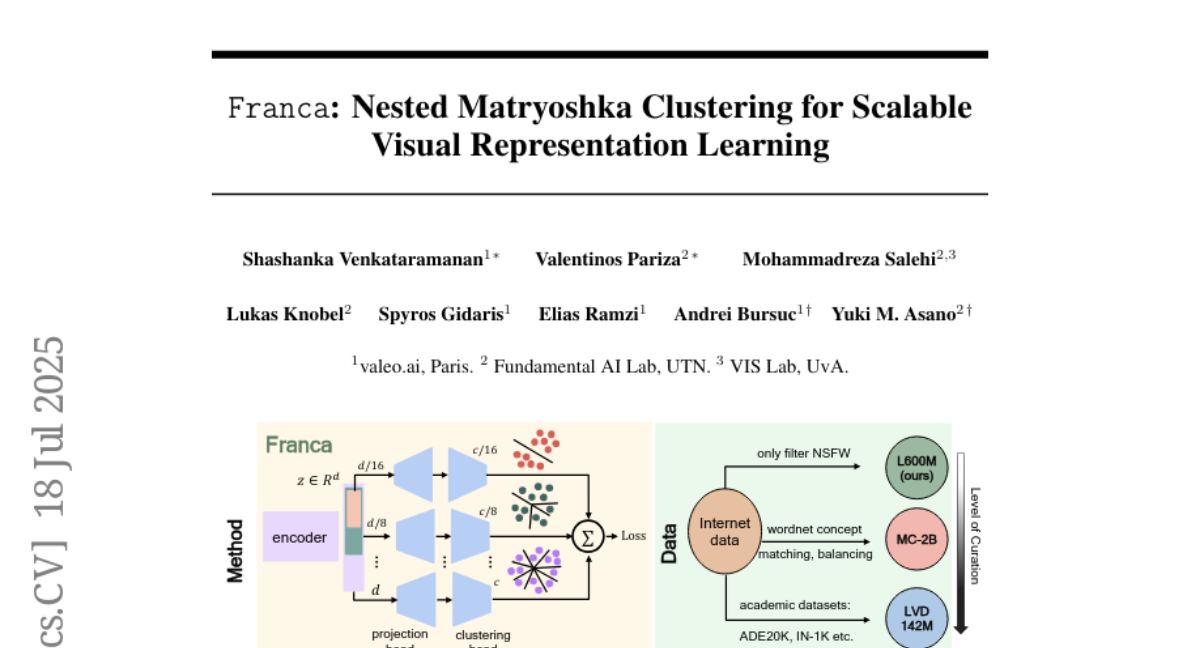
3. Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
🔑 Keywords: Franca, Vision Model, SSL Clustering, Positional Disentanglement, Open-source
💡 Category: Computer Vision
🌟 Research Objective:
– Introduction of Franca, a fully open-source vision foundation model, that aims to match or surpass the performance of state-of-the-art proprietary models by using a transparent training pipeline.
🛠️ Research Methods:
– Utilization of publicly available datasets like ImageNet-21K and ReLAION-2B.
– Development of a multi-head clustering projector and a novel positional disentanglement strategy to refine features and improve semantic encoding.
💬 Research Conclusions:
– Franca demonstrates high performance and memory efficiency due to its innovative design strategies.
– Establishes a new standard for transparent and high-performance vision models, contributing to more reproducible and generalizable models in the AI community.
👉 Paper link: https://huggingface.co/papers/2507.14137
4. Mono-InternVL-1.5: Towards Cheaper and Faster Monolithic Multimodal Large Language Models
🔑 Keywords: Mono-InternVL, Multimodal Large Language Models, visual experts, delta tuning, EViP++
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address instability and catastrophic forgetting in monolithic Multimodal Large Language Models by introducing a new visual parameter space and Enhanced Visual Pre-training strategies.
🛠️ Research Methods:
– Employing a multimodal mixture-of-experts architecture with delta tuning for stable learning of visual data.
– Development of the advanced Mono-InternVL and its improved version, Mono-InternVL-1.5, featuring updated pre-training processes and efficient MoE operations.
💬 Research Conclusions:
– Mono-InternVL significantly outperforms other monolithic MLLMs in terms of performance across multiple benchmarks. Mono-InternVL-1.5 offers cost-effective training and maintains competitive performance, with notable improvements such as reduced first-token latency.
👉 Paper link: https://huggingface.co/papers/2507.12566

5. CSD-VAR: Content-Style Decomposition in Visual Autoregressive Models
🔑 Keywords: Visual Autoregressive Modeling, Content-Style Decomposition, Scale-aware optimization, SVD-based rectification, Augmented K-V memory
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to enhance content-style decomposition using the CSD-VAR model, which outperforms diffusion models in both content preservation and stylization.
🛠️ Research Methods:
– The researchers introduced a scale-aware optimization strategy, SVD-based rectification, and augmented K-V memory to improve content and style separation.
💬 Research Conclusions:
– Experiments with the CSD-100 dataset demonstrate that CSD-VAR provides superior results in content preservation and stylization fidelity compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2507.13984
6. Inverse Reinforcement Learning Meets Large Language Model Post-Training: Basics, Advances, and Opportunities
🔑 Keywords: Large Language Models, Alignment, Reinforcement Learning, Inverse Reinforcement Learning, Neural Reward Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To review advancements in aligning Large Language Models using inverse reinforcement learning, focusing on challenges and opportunities related to neural reward modeling and sparse-reward reinforcement learning.
🛠️ Research Methods:
– Discussion of the distinctions between RL techniques in LLM alignment and conventional RL tasks, construction of neural reward models from human data, and exploration of practical aspects like datasets and evaluation metrics.
💬 Research Conclusions:
– The paper highlights unresolved challenges and promising future directions for improving LLM alignment through RL and IRL, emphasizing the need for constructing effective neural reward models and addressing sparse-reward issues.
👉 Paper link: https://huggingface.co/papers/2507.13158

7. RedOne: Revealing Domain-specific LLM Post-Training in Social Networking Services
🔑 Keywords: RedOne, domain-specific LLM, SNS tasks, training strategy
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective of the research is to enhance performance in social networking services (SNS) tasks using RedOne, a domain-specific large language model designed to improve generalization and reduce harmful content exposure.
🛠️ Research Methods:
– The study employs a three-stage training strategy: continue pretraining, supervised fine-tuning, and preference optimization, leveraging a large-scale real-world dataset.
💬 Research Conclusions:
– RedOne demonstrates a strong generalization across various SNS tasks, with an average improvement of up to 14.02% across major tasks and 7.56% in a bilingual evaluation benchmark compared to base models. Additionally, online testing shows a reduction in harmful content detection exposure by 11.23% and an improvement in click page rate by 14.95%.
👉 Paper link: https://huggingface.co/papers/2507.10605

8. Mitigating Object Hallucinations via Sentence-Level Early Intervention
🔑 Keywords: Multimodal large language models, hallucinations, SENTINEL, in-domain preference learning, context-aware preference loss
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To reduce hallucinations in multimodal large language models by developing the SENTINEL framework which operates without human annotations.
🛠️ Research Methods:
– Utilized in-domain preference learning to generate and validate sentence-level outputs iteratively.
– Built context-aware preference data through cross-checking with open-vocabulary detectors to classify sentences.
– Employed context-aware preference loss (C-DPO) focusing on discriminative learning at the initial stages of text generation.
💬 Research Conclusions:
– SENTINEL reduces hallucinations by over 90% compared to the original model and surpasses previous methods on hallucination and general capabilities benchmarks, demonstrating its superiority and generalization ability.
👉 Paper link: https://huggingface.co/papers/2507.12455

9. Quantitative Risk Management in Volatile Markets with an Expectile-Based Framework for the FTSE Index
🔑 Keywords: quantitative risk management, expectile-based methodologies, FTSE 100, Value-at-Risk, regulatory compliance
💡 Category: AI in Finance
🌟 Research Objective:
– The study aims to develop a framework for quantitative risk management using expectile-based methodologies tailored for volatile markets.
🛠️ Research Methods:
– Employs advanced expectile-based formulation, new threshold determination techniques with time series analysis, and robust backtesting procedures using a two-decade dataset of FTSE 100 returns.
💬 Research Conclusions:
– Expectile-based Value-at-Risk (EVaR) outperforms traditional VaR measures in various market conditions, providing enhanced predictive accuracy and stability, with guidelines for practical implementation and regulatory compliance.
👉 Paper link: https://huggingface.co/papers/2507.13391

10. The Generative Energy Arena (GEA): Incorporating Energy Awareness in Large Language Model (LLM) Human Evaluations
🔑 Keywords: energy consumption, energy-efficient, large language models, scalability issues, human evaluation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate how energy awareness influences the decisions of humans in selecting language models, especially in terms of energy consumption.
🛠️ Research Methods:
– Introduction of GEA (Generative Energy Arena) as a public platform where users can evaluate language models based on energy consumption data and rank their performance.
💬 Research Conclusions:
– Preliminary results indicate that users tend to prefer smaller, more energy-efficient language models over larger and more complex models when they are aware of energy consumption impacts.
👉 Paper link: https://huggingface.co/papers/2507.13302

11. OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
🔑 Keywords: OpenBEATs, multi-domain audio pre-training, masked token prediction, audio reasoning, general-purpose audio representations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The aim of the study is to extend BEATs to develop a unified framework for general audio understanding through a multi-domain pre-training approach.
🛠️ Research Methods:
– Comprehensive evaluations were carried out across six types of tasks, twenty-five datasets, and three audio domains, focusing on audio reasoning tasks including audio question answering, entailment, and captioning.
💬 Research Conclusions:
– OpenBEATs outperformed larger models on six bioacoustics datasets, two environmental sound datasets, and five reasoning datasets, demonstrating the utility of multi-domain datasets and masked token prediction in learning general-purpose audio representations.
– To encourage further innovation and reproducibility, all associated code, checkpoints, and logs have been made publicly available.
👉 Paper link: https://huggingface.co/papers/2507.14129

12.
