AI Native Daily Paper Digest – 20250722
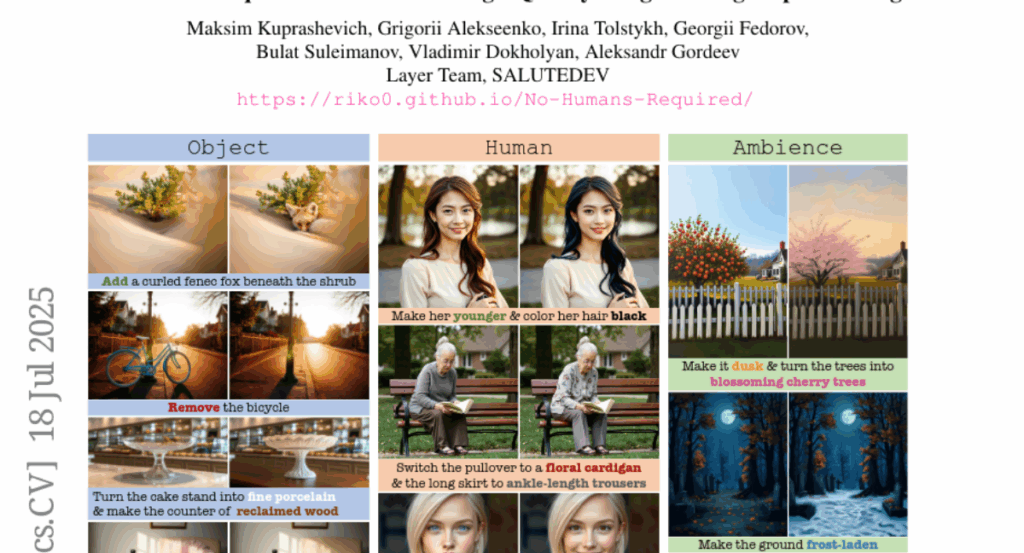
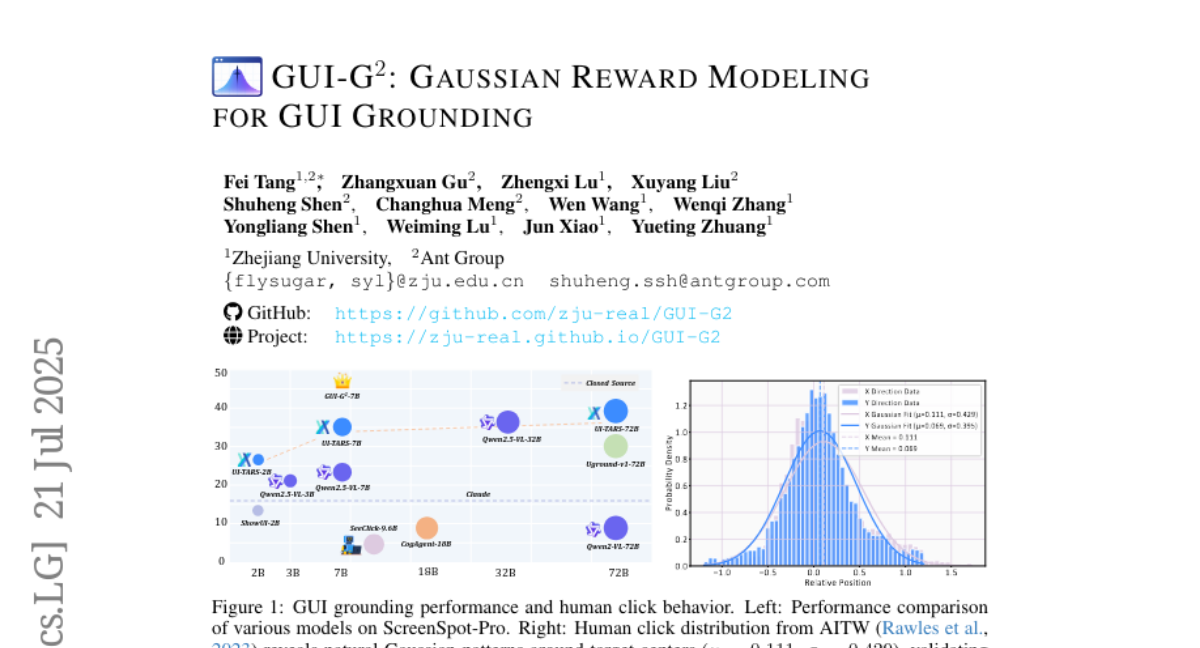
1. GUI-G^2: Gaussian Reward Modeling for GUI Grounding
🔑 Keywords: GUI Gaussian Grounding Rewards, Reinforcement Learning, Gaussian distributions, spatial reasoning, GUI interaction
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to enhance GUI grounding by introducing GUI Gaussian Grounding Rewards (GUI-G^2) to model GUI elements as continuous Gaussian distributions for more precise interface interaction.
🛠️ Research Methods:
– The study employs a reinforcement learning approach using GUI-G^2, which introduces Gaussian point rewards for accurate localization and coverage rewards for spatial alignment, incorporating an adaptive variance mechanism to handle diverse element scales.
💬 Research Conclusions:
– The proposed framework significantly outperforms current methods, demonstrating enhanced robustness to interface variations and improved generalization to new layouts, marking a new paradigm for spatial reasoning in GUI tasks.
👉 Paper link: https://huggingface.co/papers/2507.15846
2. MiroMind-M1: An Open-Source Advancement in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization
🔑 Keywords: open-source, reasoning language models, mathematical reasoning, AI-generated, reproducibility
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce the MiroMind-M1 series of open-source reasoning language models that achieve state-of-the-art performance on mathematical reasoning benchmarks.
🛠️ Research Methods:
– Employed a two-stage training process including Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Reasoning (RLVR) on a curated corpus of mathematical problems.
– Developed the Context-Aware Multi-Stage Policy Optimization algorithm for enhancing RLVR robustness and efficiency.
💬 Research Conclusions:
– The MiroMind-M1 models match or exceed the performance of existing open-source reasoning language models, demonstrating superior token efficiency, and they offer full transparency and reproducibility through the release of models, datasets, and configurations.
👉 Paper link: https://huggingface.co/papers/2507.14683

3. The Invisible Leash: Why RLVR May Not Escape Its Origin
🔑 Keywords: Reinforcement Learning with Verifiable Rewards, RLVR, exploration, entropy-reward tradeoff, reasoning boundary
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate the limits of Reinforcement Learning with Verifiable Rewards (RLVR) in enhancing AI capabilities, particularly its impact on reasoning boundaries and exploration capabilities.
🛠️ Research Methods:
– Theoretical and empirical analysis conducted to examine RLVR’s effectiveness, including extensive experiments to validate findings.
💬 Research Conclusions:
– RLVR enhances precision but limits exploration, potentially failing to discover novel solutions by restricting reasoning horizons.
– There’s an entropy-reward tradeoff where RLVR decreases exploration despite improving precision. Future innovations like explicit exploration mechanisms or hybrid strategies may be needed to overcome these limitations.
👉 Paper link: https://huggingface.co/papers/2507.14843

4. NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining
🔑 Keywords: AI Native, Generative Models, High-fidelity image editing, Inversion, Automation
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to create an automated pipeline capable of mining high-fidelity image editing triplets, leveraging generative models and a task-tuned validator for large-scale training without the need for human labeling.
🛠️ Research Methods:
– Utilization of public generative models along with a task-tuned Gemini validator to score instruction adherence and aesthetics.
– Employ techniques such as Inversion and compositional bootstrapping to increase the dataset size significantly, enabling extensive high-fidelity training data generation.
💬 Research Conclusions:
– The introduced pipeline automates repetitive annotation tasks, facilitating unprecedented scales of training without manual labeling.
– The release of the NHR-Edit dataset and the Bagel-NHR-Edit model, which outperforms existing alternatives and achieves state-of-the-art results in cross-dataset evaluations.
👉 Paper link: https://huggingface.co/papers/2507.14119
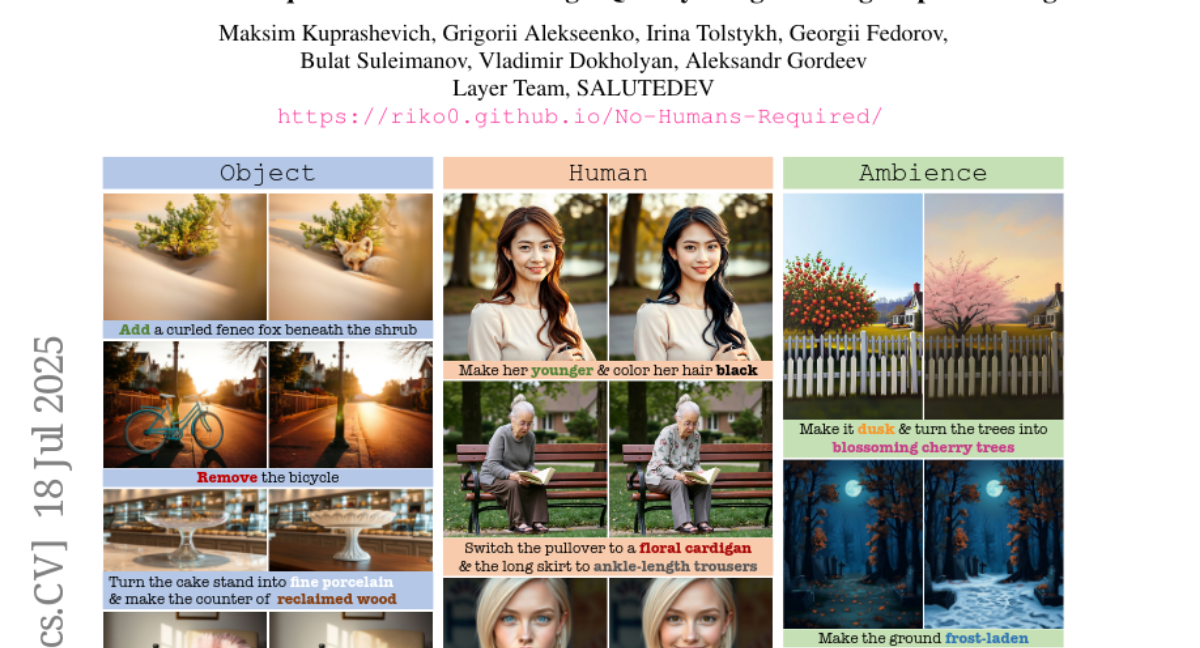
5. WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization
🔑 Keywords: Large Language Model, Information-Seeking, Set Theory, Knowledge Projections, AI-generated
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces WebShaper, a formalization-driven framework aimed at synthesizing information-seeking datasets to enhance LLM-powered agents’ performance on complex open-ended tasks.
🛠️ Research Methods:
– WebShaper employs set theory to systematically formalize IS tasks and utilizes Knowledge Projections for precise reasoning control. The synthesis process involves creating seed tasks and expanding them via an agentic Expander using retrieval and validation tools.
💬 Research Conclusions:
– Experiment results show that WebShaper achieves state-of-the-art performance among open-sourced IS agents on benchmarks like GAIA and WebWalkerQA.
👉 Paper link: https://huggingface.co/papers/2507.15061

6. GR-3 Technical Report
🔑 Keywords: Vision-Language-Action model, Generalist Robots, Fine-Tuning, Imitation Learning, AI-Generated Summary
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The development and demonstration of GR-3, a large-scale Vision-Language-Action (VLA) model, aimed at creating generalist robot policies capable of assisting humans in daily life.
🛠️ Research Methods:
– Utilized a multi-faceted training approach including co-training with web-scale vision-language data, efficient fine-tuning from human trajectory data, and imitation learning with robot trajectory data.
– Introduced ByteMini, a bi-manual mobile robot that integrates with GR-3 for versatile task execution.
💬 Research Conclusions:
– GR-3 showcases exceptional generalization, fine-tuning efficiency, and robust performance in long-horizon and dexterous robotic tasks, outperforming existing baseline methods.
– Demonstrates potential in effectively adapting to new environments and abstract concepts with minimal human input.
👉 Paper link: https://huggingface.co/papers/2507.15493
7. Robust 3D-Masked Part-level Editing in 3D Gaussian Splatting with Regularized Score Distillation Sampling
🔑 Keywords: Local 3D Editing, 3D Neural Representations, Gaussian Splatting, Score Distillation Sampling, 3D-Geometry Aware Label Prediction
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance precise local 3D editing through the introduction of a novel framework named RoMaP, addressing limitations of existing models in multi-view masking and SDS loss challenges.
🛠️ Research Methods:
– Development of a robust 3D mask generation module using 3D-Geometry Aware Label Prediction (3D-GALP) and spherical harmonics.
– Implementation of regularized SDS loss combining standard SDS loss with additional constraints such as L1 anchor loss and Gaussian prior removal.
💬 Research Conclusions:
– RoMaP achieves state-of-the-art local 3D editing capabilities on reconstructed and generated Gaussian scenes and objects, offering improved robustness and flexibility in 3D Gaussian editing.
👉 Paper link: https://huggingface.co/papers/2507.11061

8. SeC: Advancing Complex Video Object Segmentation via Progressive Concept Construction
🔑 Keywords: Video Object Segmentation, LVLMs, Conceptual Understanding, Segment Concept (SeC), Semantic Complex Scenarios
💡 Category: Computer Vision
🌟 Research Objective:
– To propose a concept-driven segmentation framework, Segment Concept (SeC), that improves video object segmentation by incorporating human-like conceptual understanding, moving beyond traditional appearance matching methods.
🛠️ Research Methods:
– Utilization of Large Vision-Language Models (LVLMs) to construct robust conceptual representations and assess VOS techniques under challenging scenarios using the Semantic Complex Scenarios Video Object Segmentation benchmark (SeCVOS).
💬 Research Conclusions:
– Segment Concept (SeC) significantly outperforms existing methods like SAM 2.1 by achieving an 11.8-point improvement on the SeCVOS benchmark, setting a new standard in concept-aware video object segmentation.
👉 Paper link: https://huggingface.co/papers/2507.15852
9. Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
🔑 Keywords: Vision-Language-Action model, human videos, physical instruction tuning, part-level motion tokenization, robotic manipulation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce Being-H0, a model improving dexterity and generalization in robotic manipulation using human video data.
🛠️ Research Methods:
– Leveraged physical instruction tuning combining large-scale VLA pretraining, 3D reasoning alignment, and adaptation for robotics.
💬 Research Conclusions:
– Demonstrated superior performance in hand motion generation and real-world robotic manipulation, benefiting from large data scale and comprehensive data curation.
👉 Paper link: https://huggingface.co/papers/2507.15597

10. Stabilizing Knowledge, Promoting Reasoning: Dual-Token Constraints for RLVR
🔑 Keywords: Reinforcement Learning, Large Language Models, Verifiable Rewards, Entropy-Aware, Mathematical Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the reasoning capabilities of Large Language Models by applying an entropy-aware RLVR approach that distinguishes between knowledge-related and reasoning-related tokens.
🛠️ Research Methods:
– Implemented a dual-token constraint model called Archer, applying weaker KL regularization and higher clipping thresholds to reasoning tokens, while using stronger constraints on knowledge tokens.
💬 Research Conclusions:
– Archer significantly outperforms previous RLVR methods on mathematical reasoning and code generation benchmarks, achieving or exceeding state-of-the-art performance among models of comparable size.
👉 Paper link: https://huggingface.co/papers/2507.15778

11. Inverse Scaling in Test-Time Compute
🔑 Keywords: Large Reasoning Models, reasoning length, test-time compute, failure modes, AI-generated summary
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To evaluate how increased reasoning length affects the performance and reasoning failures of Large Reasoning Models.
🛠️ Research Methods:
– Constructed evaluation tasks across four categories to assess performance and identify failure modes.
💬 Research Conclusions:
– Identified five failure modes in reasoning, highlighting that increased test-time compute may degrade performance and reinforce problematic reasoning patterns.
👉 Paper link: https://huggingface.co/papers/2507.14417

12. Towards Video Thinking Test: A Holistic Benchmark for Advanced Video Reasoning and Understanding
🔑 Keywords: Video LLMs, Correctness, Robustness, Video Understanding, Human Intelligence
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to evaluate whether video large language models (LLMs) can interpret real-world videos with the same level of effectiveness as human intelligence concerning correctness and robustness.
🛠️ Research Methods:
– Introduction of the Video Thinking Test (Video-TT) to assess video LLMs, using 1,000 YouTube Shorts videos, each with complex open-ended and adversarial questions to evaluate video interpretation capabilities.
💬 Research Conclusions:
– Evaluation reveals a significant gap between the performance of video LLMs and human intelligence in interpreting videos, particularly in terms of maintaining correctness and robustness.
👉 Paper link: https://huggingface.co/papers/2507.15028

13. Gaussian Splatting with Discretized SDF for Relightable Assets
🔑 Keywords: 3D Gaussian splatting, inverse rendering, signed distance field, SDF-to-opacity transformation
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to improve the efficiency and quality of inverse rendering by introducing a discretized signed distance field (SDF) within the framework of 3D Gaussian splatting.
🛠️ Research Methods:
– The method involves encoding a discretized SDF within each Gaussian using sampled values and linking it to Gaussian opacity through an SDF-to-opacity transformation. This approach avoids the computational cost of ray marching by using a projection-based consistency loss to enforce alignment with the SDF surface.
💬 Research Conclusions:
– The proposed method achieves higher relighting quality without additional memory usage beyond Gaussian splatting (GS) and eliminates the need for complex, manually designed optimizations. Experiments demonstrate that it outperforms existing Gaussian-based inverse rendering methods.
👉 Paper link: https://huggingface.co/papers/2507.15629

14. MCPEval: Automatic MCP-based Deep Evaluation for AI Agent Models
🔑 Keywords: Large Language Models, task generation, deep evaluation, MCPEval, automated frameworks
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces MCPEval, an open-source framework designed to automate task generation and evaluation for Large Language Models across diverse domains.
🛠️ Research Methods:
– Utilizes a Model Context Protocol (MCP)-based approach to automate end-to-end task generation and integrate seamlessly with native agent tools, eliminating the need for manual benchmarks.
💬 Research Conclusions:
– Empirical results from five real-world domains show MCPEval’s effectiveness in providing nuanced, domain-specific performance evaluation, promoting reproducible and standardized assessment of LLM agents.
👉 Paper link: https://huggingface.co/papers/2507.12806
15. STITCH: Simultaneous Thinking and Talking with Chunked Reasoning for Spoken Language Models
🔑 Keywords: Spoken Language Models, Chain-of-Thought reasoning, Stitch, latency, unspoken reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to integrate an unspoken thought process into Spoken Language Models (SLMs) to enable them to engage in complex mental reasoning before responding.
🛠️ Research Methods:
– Introduced “Stitch,” a novel generation method alternating between unspoken reasoning chunks and spoken response chunks to allow simultaneous thinking and talking without increasing response latency.
💬 Research Conclusions:
– Stitch achieves latency comparable to baseline models that do not generate unspoken reasoning, while outperforming them by 15% on math reasoning datasets and maintaining equal performance on non-reasoning datasets.
👉 Paper link: https://huggingface.co/papers/2507.15375
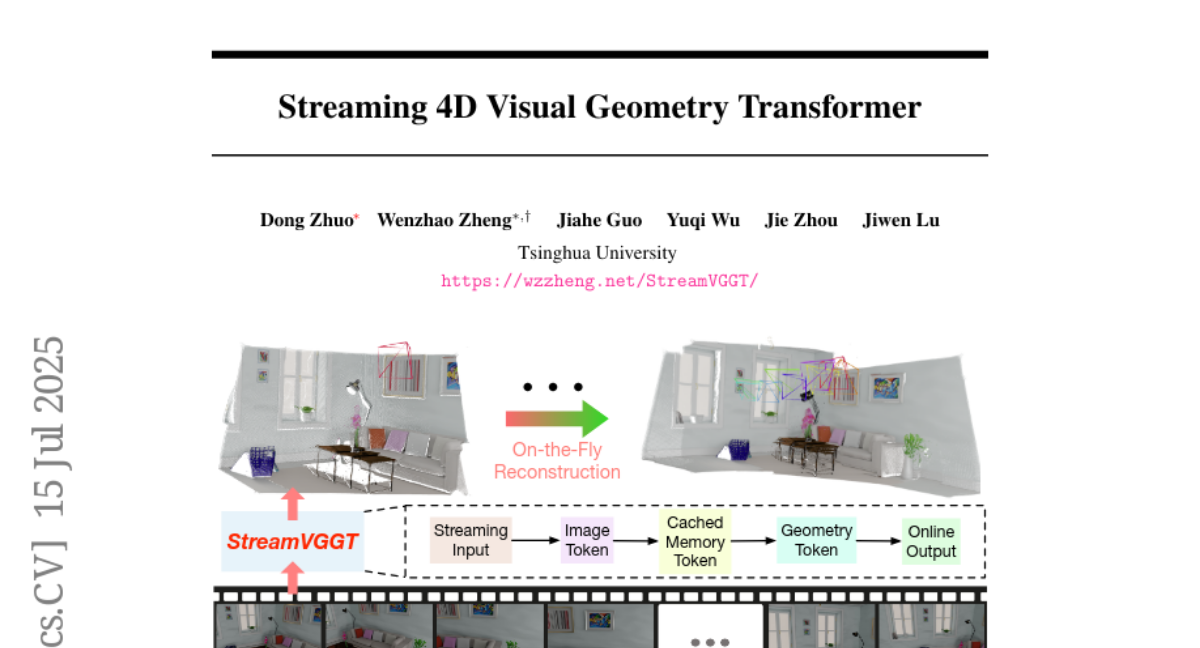
16. Streaming 4D Visual Geometry Transformer
🔑 Keywords: 4D reconstruction, causal attention, AI-generated summary, FlashAttention, spatial consistency
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to address the challenge of real-time 4D spatial-temporal geometry reconstruction from videos, enabling interactive and scalable 4D vision systems.
🛠️ Research Methods:
– Utilizes a streaming 4D visual geometry transformer with a causal transformer architecture to process input sequences online.
– Employs temporal causal attention and caches historical keys and values as implicit memory for efficient long-term 4D reconstruction.
💬 Research Conclusions:
– The model increases inference speed while maintaining competitive performance on various 4D geometry perception benchmarks, facilitating scalable and interactive real-time applications.
👉 Paper link: https://huggingface.co/papers/2507.11539
17. “PhyWorldBench”: A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
🔑 Keywords: Video generation models, Physics realism, PhyWorldBench, Anti-Physics, Text-to-video models
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces PhyWorldBench, a benchmark assessing video generation models’ ability to adhere to physical laws.
🛠️ Research Methods:
– Evaluation of 12 text-to-video generation models, utilizing over 1,050 prompts across various physical scenarios, including intentional violations (Anti-Physics).
💬 Research Conclusions:
– The study highlights challenges in video models maintaining physical realism and provides guidance on crafting prompts to improve adherence to physical principles.
👉 Paper link: https://huggingface.co/papers/2507.13428

18. LLM Economist: Large Population Models and Mechanism Design in Multi-Agent Generative Simulacra
🔑 Keywords: LLM Economist, agent-based modeling, bounded rationality, hierarchical decision-making, reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To design and assess economic policies in strategic environments using a novel framework called LLM Economist, which employs agent-based modeling and hierarchical decision-making.
🛠️ Research Methods:
– Utilization of agent-based modeling with bounded rational agents and a planner agent that uses in-context reinforcement learning and piecewise-linear marginal tax schedules.
💬 Research Conclusions:
– The study demonstrates that language model-based agents can effectively model, simulate, and govern complex economic systems, achieving improved social welfare outcomes through process convergence and decentralized governance mechanisms.
👉 Paper link: https://huggingface.co/papers/2507.15815

19. Latent Denoising Makes Good Visual Tokenizers
🔑 Keywords: Visual Tokenizers, Generative Modeling, Denoising, AI Native, Image Reconstruction
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance the effectiveness of visual tokenizers for generative modeling by aligning tokenizer embeddings with a denoising objective.
🛠️ Research Methods:
– Introduces the Latent Denoising Tokenizer (l-DeTok), designed to reconstruct clean images from latent embeddings affected by interpolative noise and random masking.
💬 Research Conclusions:
– The l-DeTok consistently outperforms standard tokenizers on ImageNet 256×256 across six generative models, highlighting the importance of denoising as a design principle in tokenizer development.
👉 Paper link: https://huggingface.co/papers/2507.15856

20. The Serial Scaling Hypothesis
🔑 Keywords: inherently serial problems, machine learning, complexity theory, model design, hardware development
💡 Category: Foundations of AI
🌟 Research Objective:
– To identify and formalize the critical distinction of inherently serial problems in machine learning, emphasizing the limitations of current parallel-centric architectures.
🛠️ Research Methods:
– Utilization of complexity theory to demonstrate the fundamental limitations faced by parallel architectures when addressing inherently serial tasks.
💬 Research Conclusions:
– Highlighting the necessity for AI systems to scale serial computation deliberately, rather than solely relying on parallelization, in order to advance machine learning, model design, and hardware development for complex reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2507.12549

21. A Simple “Try Again” Can Elicit Multi-Turn LLM Reasoning
🔑 Keywords: Large Reasoning Models, Multi-turn problem solving, Reinforcement Learning, Unary Feedback
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve multi-turn problem-solving capabilities in Large Reasoning Models (LRMs) using Reinforcement Learning augmented with unary feedback.
🛠️ Research Methods:
– Utilizing Unary Feedback as Observation (UFO) in reinforcement learning setups to enhance both single-turn and multi-turn reasoning abilities.
💬 Research Conclusions:
– The proposed method with unary feedback improves multi-turn reasoning accuracy by up to 14%, maintaining single-turn performance and encouraging diverse reasoning with a structured reward system.
👉 Paper link: https://huggingface.co/papers/2507.14295

22. PhysGym: Benchmarking LLMs in Interactive Physics Discovery with Controlled Priors
🔑 Keywords: PhysGym, Large Language Model, Interactive Physics Environments, Scientific Reasoning, Prior Knowledge
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce PhysGym, a benchmark suite for evaluating large language model-based agents’ scientific reasoning in interactive physics environments.
🛠️ Research Methods:
– PhysGym evaluates agents’ capability to handle environmental complexity and utilize prior knowledge through a suite of interactive simulations.
💬 Research Conclusions:
– PhysGym successfully differentiates agent capabilities by analyzing hypothesis accuracy and model fidelity, particularly in handling varying priors and task complexities.
👉 Paper link: https://huggingface.co/papers/2507.15550

23. Data Mixing Agent: Learning to Re-weight Domains for Continual Pre-training
🔑 Keywords: Data Mixing Agent, Reinforcement Learning, Continual Pre-training, Catastrophic Forgetting, Code Generation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a model-based framework, Data Mixing Agent, which aims to balance performance across source and target fields during continual pre-training of large language models.
🛠️ Research Methods:
– The framework utilizes reinforcement learning to re-weight training data, learning generalizable heuristics through large quantities of data mixing trajectories.
💬 Research Conclusions:
– Data Mixing Agent surpasses existing baselines in balanced performance across benchmarks and showcases adaptability and efficiency with less source-field data, aligning closely with human intuitions.
👉 Paper link: https://huggingface.co/papers/2507.15640

24. TokensGen: Harnessing Condensed Tokens for Long Video Generation
🔑 Keywords: TokensGen, diffusion-based generative models, long video generation, Tokens, AI Native
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to overcome the limitations of long video generation using diffusion-based generative models to address memory bottlenecks and ensure long-term consistency.
🛠️ Research Methods:
– A novel two-stage framework is proposed: (1) train a short video diffusion model with condensed Tokens to generate semantically rich short clips; (2) a video token diffusion transformer ensures global consistency across clips using a Text-to-Token model, with a FIFO-Diffusion strategy to connect adjacent clips smoothly.
💬 Research Conclusions:
– The approach significantly improves long-term temporal and content coherence in video generation without excessive computational overhead, providing a scalable solution for applications such as storytelling and cinematic production.
👉 Paper link: https://huggingface.co/papers/2507.15728
25. GeoDistill: Geometry-Guided Self-Distillation for Weakly Supervised Cross-View Localization
🔑 Keywords: Cross-view localization, 3-DoF pose, GeoDistill, Field-of-View (FoV), autonomous navigation
💡 Category: Computer Vision
🌟 Research Objective:
– Propose GeoDistill, a Geometry guided weakly supervised self distillation framework to improve cross-view localization without needing fully supervised learning.
🛠️ Research Methods:
– Utilize a teacher-student learning approach, employing FoV-based masking for enhanced local feature learning and aligning predictions for robust location estimation.
💬 Research Conclusions:
– GeoDistill significantly enhances localization performance across diverse frameworks while providing a scalable solution for real-world cross-view localization challenges.
👉 Paper link: https://huggingface.co/papers/2507.10935

26. ParaStudent: Generating and Evaluating Realistic Student Code by Teaching LLMs to Struggle
🔑 Keywords: Large Language Models, student-like code, ParaStudent, semantic evaluation, stylistic diversity
💡 Category: AI in Education
🌟 Research Objective:
– To investigate if Large Language Models can generate code that emulates student behavior in programming tasks, characterized by imperfections, iterations, and diverse styles.
🛠️ Research Methods:
– Utilized timestamped student submission datasets across several semesters to conduct experiments modeling student progress. Employed low- and high-resolution experiments to evaluate code outputs semantically, functionally, and stylistically.
💬 Research Conclusions:
– Fine-tuning LLMs enhances their ability to reflect real student learning trajectories, error patterns, and stylistic variations. Capturing realistic student code involves context-aware generation, temporal modeling, and multi-dimensional evaluation.
👉 Paper link: https://huggingface.co/papers/2507.12674

27. UGPL: Uncertainty-Guided Progressive Learning for Evidence-Based Classification in Computed Tomography
🔑 Keywords: UGPL, computed tomography, uncertainty-guided, evidential deep learning, AI in Healthcare
💡 Category: AI in Healthcare
🌟 Research Objective:
– Introduce an uncertainty-guided progressive learning framework (UGPL) for more accurate classification of CT images by focusing on diagnostic ambiguities and localized abnormalities.
🛠️ Research Methods:
– Utilized evidential deep learning to quantify predictive uncertainty.
– Employed a global-to-local analysis strategy with non-maximum suppression to extract informative patches while maintaining spatial diversity.
– Integrated contextual information and fine-grained details through an adaptive fusion mechanism.
💬 Research Conclusions:
– UGPL outperformed state-of-the-art methods with significant accuracy improvements in detecting kidney abnormality, lung cancer, and COVID-19.
– The uncertainty-guided component crucially enhanced performance when the complete learning pipeline was applied.
👉 Paper link: https://huggingface.co/papers/2507.14102

28.
