AI Native Daily Paper Digest – 20250731

1. ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents
🔑 Keywords: UI-to-code generation, vision-language model, modular multi-agent framework, adaptive prompt-based synthesis, data engine
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance the process of transforming user interface (UI) designs into front-end code by integrating vision-language models and a modular multi-agent framework.
🛠️ Research Methods:
– A novel approach is introduced that employs a modular multi-agent framework in three stages: grounding (detecting and labeling UI components), planning (creating a hierarchical layout), and generation (producing HTML/CSS code using adaptive prompts).
💬 Research Conclusions:
– The proposed method demonstrates improved robustness, interpretability, and fidelity compared to black-box methods, achieving state-of-the-art performance in layout accuracy and code correctness. Additionally, an extension into a scalable data engine for generating image-code pairs has shown substantial gains in UI understanding and code quality.
👉 Paper link: https://huggingface.co/papers/2507.22827

2. ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents
🔑 Keywords: UI-to-code generation, vision-language model, adaptive prompt-based synthesis, modular multi-agent framework
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance UI-to-code generation by integrating modular multi-agent frameworks with vision-language models and hierarchical layout planning.
🛠️ Research Methods:
– Implementing a three-stage process involving grounding, planning, and generation agents, improving robustness and interpretability.
💬 Research Conclusions:
– Achieved state-of-the-art performance in layout accuracy, structural coherence, and code correctness with an open-source framework.
👉 Paper link: https://huggingface.co/papers/2507.22827

3. BANG: Dividing 3D Assets via Generative Exploded Dynamics
🔑 Keywords: BANG, generative approach, latent diffusion model, 3D creation, 2D-to-3D manipulations
💡 Category: Generative Models
🌟 Research Objective:
– Introduce BANG, a generative approach enhancing 3D object creation through intuitive part-level decomposition and manipulation.
🛠️ Research Methods:
– Utilization of pre-trained latent diffusion models and temporal attention to ensure smooth and coherent transitions in 3D object decomposition.
💬 Research Conclusions:
– BANG facilitates detailed 3D asset creation, enabling applications in component-aware 3D creation and 3D printing, bridging imaginative concepts with practical outputs.
👉 Paper link: https://huggingface.co/papers/2507.21493

4. Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
🔑 Keywords: Falcon-H1, large language models, hybrid architecture, Transformer-based attention, State Space Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces Falcon-H1, a new series of large language models featuring a hybrid architecture to achieve state-of-the-art performance and efficiency across a variety of tasks and sizes.
🛠️ Research Methods:
– Falcon-H1 employs a parallel hybrid approach combining Transformer-based attention with State Space Models, optimized for high performance and computational efficiency. Various model configurations and quantized versions have been systematically designed and released under an open-source license.
💬 Research Conclusions:
– Falcon-H1 models demonstrate unmatched performance and efficiency, comparable to models with significantly more parameters. They excel in reasoning, mathematics, multilingual tasks, and scientific knowledge, with support for up to 256K context tokens and 18 languages.
👉 Paper link: https://huggingface.co/papers/2507.22448

5. VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
🔑 Keywords: VL-Cogito, Progressive Curriculum Reinforcement Learning, Multimodal Reasoning, Online Difficulty Soft Weighting, Dynamic Length Reward Mechanism
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a multimodal reasoning model, VL-Cogito, leveraging a Progressive Curriculum Reinforcement Learning framework to improve performance across diverse tasks.
🛠️ Research Methods:
– Implementation of PCuRL framework with two core innovations: online difficulty soft weighting and dynamic length reward mechanism.
💬 Research Conclusions:
– VL-Cogito consistently achieves superior performance across various benchmarks in mathematics, science, logic, and general understanding, validating the effectiveness of the proposed approach.
👉 Paper link: https://huggingface.co/papers/2507.22607

6. Adapting Vehicle Detectors for Aerial Imagery to Unseen Domains with Weak Supervision
🔑 Keywords: Aerial Imagery, Data Augmentation, Latent Diffusion Models, Generative AI, Domain Adaptation
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to enhance vehicle detection in aerial imagery by addressing the domain adaptation challenges faced when models are applied in different geographic areas.
🛠️ Research Methods:
– The researchers propose a multi-stage, multi-modal knowledge transfer framework leveraging fine-tuned Latent Diffusion Models (LDMs) for synthesizing high-quality aerial images and labels to facilitate data augmentation.
💬 Research Conclusions:
– The proposed method demonstrated significant improvements, ranging from 4-50%, in performance across various aerial imagery domains compared to several current techniques, showcasing its effectiveness in bridging the distribution gap.
👉 Paper link: https://huggingface.co/papers/2507.20976

7. Efficient Differentially Private Fine-Tuning of LLMs via Reinforcement Learning
🔑 Keywords: Deep Reinforcement Learning, Differentially Private Optimization, Gradient Clipping, Gaussian Noise, Large Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To optimize differentially private training in large language models using a deep reinforcement learning framework named RLDP.
🛠️ Research Methods:
– Utilization of a closed-loop control problem approach with modern deep reinforcement learning techniques to adjust gradient clipping thresholds and noise injection dynamically.
💬 Research Conclusions:
– RLDP improves model utility by reducing perplexity by 1.3-30.5% and increasing downstream utility by 5.6%. It achieves baseline utility with significantly lower gradient-update budgets, while maintaining privacy and reducing susceptibility to membership-inference and canary-extraction attacks.
👉 Paper link: https://huggingface.co/papers/2507.22565

8. Towards Omnimodal Expressions and Reasoning in Referring Audio-Visual Segmentation
🔑 Keywords: OmniAVS, OISA, Audio-Visual Segmentation, Multimodal Reasoning, MLLM
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to advance audio-visual segmentation by developing OmniAVS, a new dataset, and OISA, a segmentation assistant, which leverage complex multimodal expressions and reasoning.
🛠️ Research Methods:
– Introduce the OmniAVS dataset featuring 2,098 videos with diverse multimodal referring expressions, and develop OISA which uses MLLM for complex cue comprehension and segmentation.
💬 Research Conclusions:
– OISA significantly outperforms existing methods on the OmniAVS dataset and shows competitive performance on related tasks, demonstrating the efficacy of integrating complex reasoning and multimodal information.
👉 Paper link: https://huggingface.co/papers/2507.22886

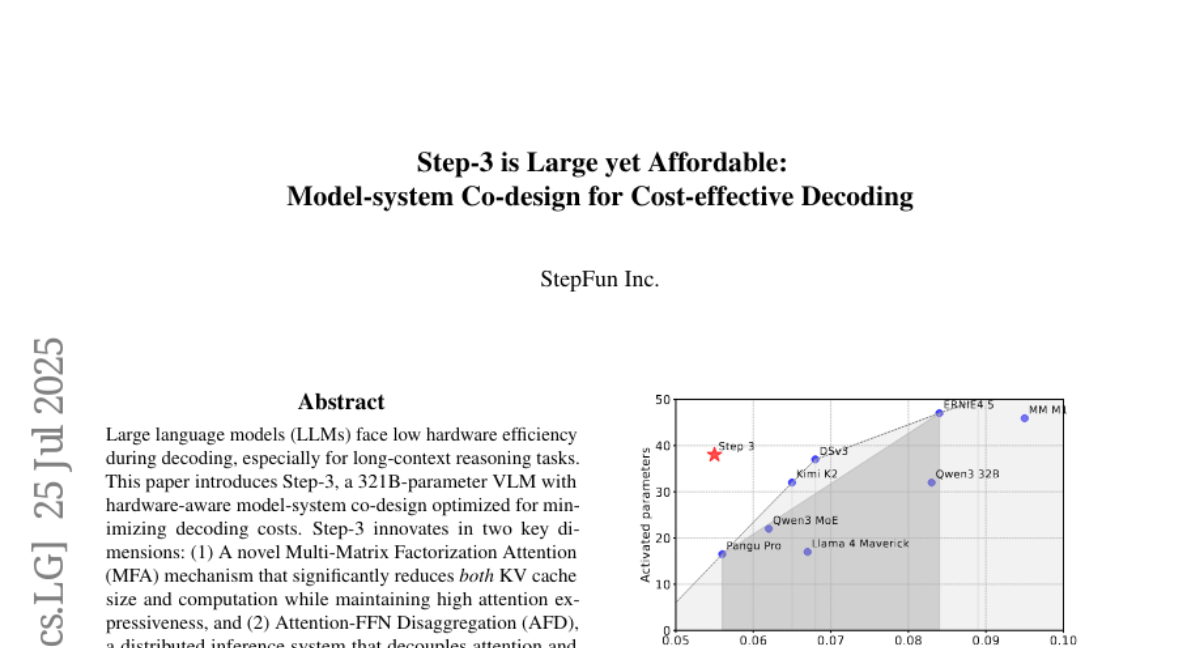
9. Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding
🔑 Keywords: VLM, Multi-Matrix Factorization Attention, Attention-FFN Disaggregation, Hardware-Aware, Decoding Costs
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce and evaluate Step-3, a 321B-parameter VLM designed to reduce decoding costs in long-context reasoning tasks through innovative hardware-aware model-system co-design.
🛠️ Research Methods:
– The introduction of Multi-Matrix Factorization Attention (MFA) to reduce KV cache size and computation.
– Implementation of Attention-FFN Disaggregation (AFD) to decouple attention and FFN layers for efficiency.
💬 Research Conclusions:
– Step-3 demonstrates superior cost efficiency and throughput compared to models like DeepSeek-V3 and Qwen3 MoE 235B, especially for longer contexts, while activating 38B parameters per token.
– Achieves a decoding throughput of up to 4,039 tokens per second per GPU on Hopper GPUs, surpassing the performance of DeepSeek-V3 in the same setup.
👉 Paper link: https://huggingface.co/papers/2507.19427
10. Repair-R1: Better Test Before Repair
🔑 Keywords: Automated Program Repair, Large Language Models, Test Cases, Reinforcement Learning, Bug Repair
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This study introduces Repair-R1 to enhance Automated Program Repair by integrating test cases into the training phase and prioritizing test generation before repair.
🛠️ Research Methods:
– Repair-R1 uses reinforcement learning to co-optimize test generation and bug repair with three different backbone models, leveraging test cases in pre-repair phases.
💬 Research Conclusions:
– Experimental results show that Repair-R1 outperforms traditional methods, improving repair success rate, test generation success, and test coverage significantly, with improvements ranging from 2.68% to 48.29% in repair success.
👉 Paper link: https://huggingface.co/papers/2507.22853

11. MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
🔑 Keywords: MixGRPO, Image Generation, Sliding Window Mechanism, stochastic differential equations (SDE), ordinary differential equations (ODE)
💡 Category: Generative Models
🌟 Research Objective:
– To improve the efficiency and performance of flow matching models in image generation by integrating SDE and ODE within a novel framework called MixGRPO.
🛠️ Research Methods:
– Utilizes a sliding window mechanism to optimize only within restricted time-steps using SDE sampling and GRPO-guided optimization, while employing ODE sampling outside the window to minimize optimization overhead and focus gradient updates.
💬 Research Conclusions:
– MixGRPO demonstrates significant improvements in human preference alignment, efficiency, and effectiveness, especially reducing the training time markedly by nearly 50% compared to DanceGRPO. The advanced MixGRPO-Flash further accelerates training by 71%.
👉 Paper link: https://huggingface.co/papers/2507.21802

12. MetaCLIP 2: A Worldwide Scaling Recipe
🔑 Keywords: MetaCLIP 2, zero-shot classification, multilingual benchmarks, image-text pairs, Contrastive Language-Image Pretraining
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve zero-shot classification and multilingual benchmarks by training MetaCLIP 2 on worldwide web-scale image-text pairs, overcoming challenges associated with non-English data.
🛠️ Research Methods:
– Rigorous ablations were conducted to address the challenges of multilingual data integration with minimal changes.
💬 Research Conclusions:
– MetaCLIP 2 surpasses the performance of its English-only and existing multilingual counterparts on various benchmarks, setting a new state-of-the-art without system-level confounding factors.
👉 Paper link: https://huggingface.co/papers/2507.22062

13. DreamScene: 3D Gaussian-based End-to-end Text-to-3D Scene Generation
🔑 Keywords: DreamScene, 3D scene generation, text-to-3D, AI-generated summary, fine-grained control
💡 Category: Generative Models
🌟 Research Objective:
– The main objective of the research is to develop DreamScene, an end-to-end framework that generates high-quality, editable 3D scenes from text or dialogue.
🛠️ Research Methods:
– The framework utilizes a combination of scene planning with a GPT-4 agent, hybrid graph-based placement algorithm, Formation Pattern Sampling (FPS) with multi-timestep sampling, reconstructive optimization, and progressive camera sampling.
💬 Research Conclusions:
– DreamScene outperforms previous methods in terms of quality, consistency, and flexibility, offering a practical solution for open-domain 3D content creation. The system supports fine-grained scene editing and dynamic motion, making it suitable for applications in gaming, film, and design.
👉 Paper link: https://huggingface.co/papers/2507.13985
14.
