AI Native Daily Paper Digest – 20250804
1. Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
🔑 Keywords: DAEDAL, Diffusion Large Language Models, denoising strategy, dynamic length adaptation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary goal is to address the static length constraint in Diffusion Large Language Models by implementing a dynamic length adaptation without additional training.
🛠️ Research Methods:
– DAEDAL, a novel training-free denoising strategy, operates in two phases: initial short-length expansion based on task appropriation and dynamic denoising intervention to ensure comprehensive generation.
💬 Research Conclusions:
– DAEDAL significantly improves the performance and computational efficiency of Diffusion Large Language Models, achieving results comparable or superior to traditional fixed-length models and enhancing the effective token ratio.
👉 Paper link: https://huggingface.co/papers/2508.00819

2. PixNerd: Pixel Neural Field Diffusion
🔑 Keywords: Pixel Space, Neural Field, Single-Stage, FID, Text-to-Image
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to achieve high-quality image generation in a single-scale, single-stage process without using VAEs or complex pipelines, extending its application to text-to-image tasks.
🛠️ Research Methods:
– The researchers employ a patch-wise decoding method using neural fields to offer an efficient and end-to-end solution, termed Pixel Neural Field Diffusion (PixNerd).
💬 Research Conclusions:
– PixNerd achieved 2.15 FID on ImageNet 256×256 and 2.84 FID on ImageNet 512×512 without complex pipelines or VAEs, and it showed competitive performance in text-to-image applications, scoring 0.73 on GenEval and 80.9 on DPG benchmark.
👉 Paper link: https://huggingface.co/papers/2507.23268

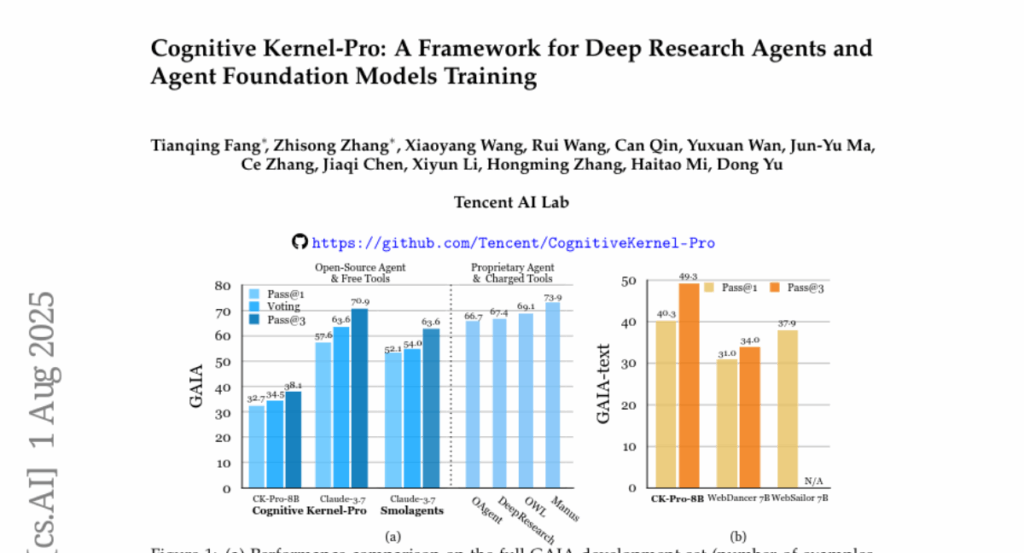
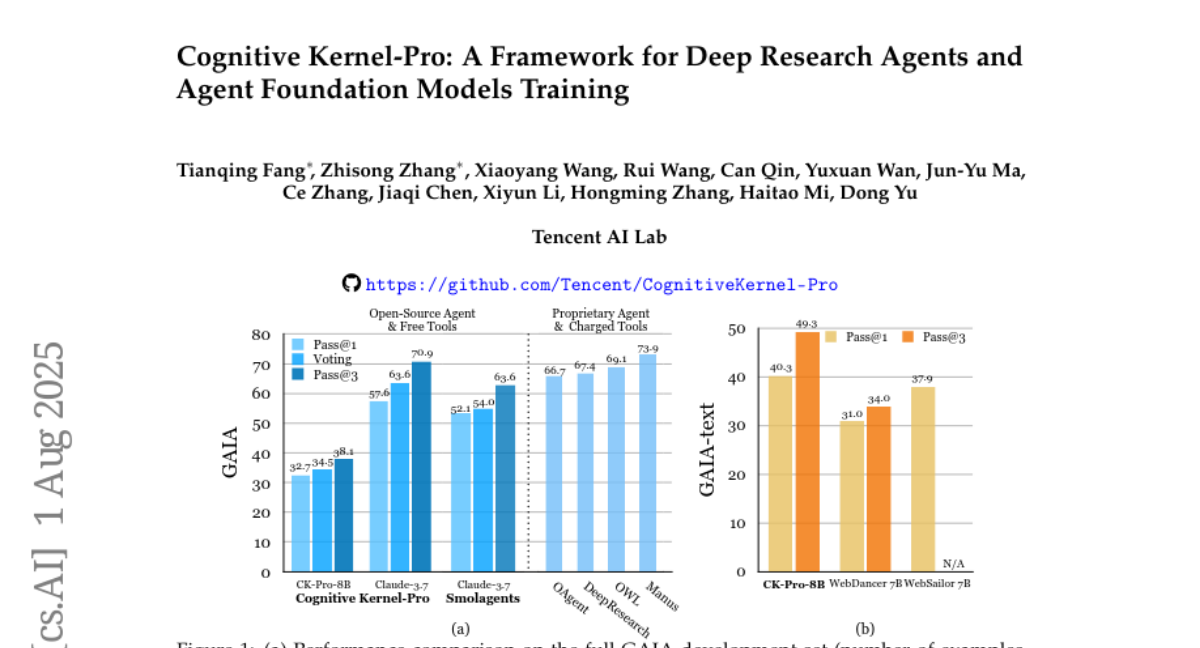
3. Cognitive Kernel-Pro: A Framework for Deep Research Agents and Agent Foundation Models Training
🔑 Keywords: Cognitive Kernel-Pro, AI Agents, Open-Source, Agent Foundation Models, Test-Time Strategies
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to democratize the development and evaluation of advanced AI agents through Cognitive Kernel-Pro, an open-source and free multi-module agent framework.
🛠️ Research Methods:
– Systematic investigation of high-quality training data curation for Agent Foundation Models across web, file, code, and general reasoning domains.
– Exploration of novel test-time reflection and voting strategies to enhance agent robustness and performance.
💬 Research Conclusions:
– Cognitive Kernel-Pro achieves state-of-the-art results among open-source and free agents, surpassing previous systems like WebDancer and WebSailor, setting a new performance standard in the field.
👉 Paper link: https://huggingface.co/papers/2508.00414
4. 3D-R1: Enhancing Reasoning in 3D VLMs for Unified Scene Understanding
🔑 Keywords: 3D-R1, 3D scene understanding, Reinforcement Learning, Dynamic view selection
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance reasoning and generalization capabilities in 3D scene understanding using 3D-R1.
🛠️ Research Methods:
– Construction of a high-quality synthetic dataset named Scene-30K.
– Utilization of reinforcement learning with GRPO and dynamic view selection strategy.
💬 Research Conclusions:
– 3D-R1 shows a significant improvement of 10% on average across various 3D scene benchmarks.
👉 Paper link: https://huggingface.co/papers/2507.23478

5. SWE-Exp: Experience-Driven Software Issue Resolution
🔑 Keywords: SWE-Exp, Large Language Model, Multi-agent Collaboration, Monte Carlo Tree Search, Experience Bank
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance software issue resolution by systematically accumulating and leveraging repair expertise from past agent experiences, improving resolution rates.
🛠️ Research Methods:
– Introducing SWE-Exp, an experience-enhanced approach that captures a multi-faceted experience bank from past agent trajectories, enabling continuous learning.
💬 Research Conclusions:
– SWE-Exp achieves a state-of-the-art resolution rate (41.6% Pass@1) under open-source agent frameworks, establishing a new paradigm of strategic, experience-driven issue resolution in automated software engineering.
👉 Paper link: https://huggingface.co/papers/2507.23361

6. Multimodal Referring Segmentation: A Survey
🔑 Keywords: Multimodal Referring Segmentation, Convolutional Neural Networks, Transformers, Large Language Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to provide a comprehensive survey of techniques for multimodal referring segmentation by covering recent advancements in convolutional neural networks, transformers, and large language models.
🛠️ Research Methods:
– It summarizes a unified meta architecture for referring segmentation and reviews methods across key visual scenes, including images, videos, and 3D scenes.
💬 Research Conclusions:
– It addresses challenges of real-world complexity through Generalized Referring Expression methods, highlights practical applications, and provides performance comparisons on standard benchmarks.
👉 Paper link: https://huggingface.co/papers/2508.00265

7. SWE-Debate: Competitive Multi-Agent Debate for Software Issue Resolution
🔑 Keywords: SWE-Debate, AI-generated summary, SWE-agent, fault propagation traces, specialized agents
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to enhance issue resolution in software engineering through a competitive multi-agent framework called SWE-Debate that promotes diverse reasoning and improves issue localization and fix planning.
🛠️ Research Methods:
– The approach involves creating multiple fault propagation traces by traversing a code dependency graph and organizing a three-round debate among specialized agents, each with distinct reasoning perspectives, leading to a consolidated fix plan.
💬 Research Conclusions:
– SWE-Debate achieves state-of-the-art results in open-source agent frameworks, significantly outperforming baselines according to experiments on the SWE-bench benchmark.
👉 Paper link: https://huggingface.co/papers/2507.23348

8. Learning an Efficient Multi-Turn Dialogue Evaluator from Multiple Judges
🔑 Keywords: Large Language Models, Dialogue Evaluator, Multi-Judge Approach, Preference Knowledge
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop an efficient multi-turn dialogue evaluator that aggregates multiple LLM judgments to assess dialogue quality with reduced computational cost.
🛠️ Research Methods:
– Aggregate the preference knowledge of multiple LLM judges into a single model to preserve diverse feedback while reducing evaluation costs.
💬 Research Conclusions:
– The proposed method showcases efficiency and robustness, outperforming existing baselines across diverse dialogue evaluation benchmarks.
👉 Paper link: https://huggingface.co/papers/2508.00454

9. MCIF: Multimodal Crosslingual Instruction-Following Benchmark from Scientific Talks
🔑 Keywords: Multimodal, Instruction-Following, Multilingual, Human-Annotated Benchmark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The development of MCIF, a multilingual, human-annotated benchmark for evaluating instruction-following in crosslingual, multimodal settings using scientific talks.
🛠️ Research Methods:
– Integration of text, speech, and vision within unified frameworks covering three core modalities and four languages to evaluate MLLMs’ abilities.
💬 Research Conclusions:
– MCIF addresses the limitations of existing benchmarks by enabling comprehensive evaluation over both short and long-form contexts, encouraging open research under a CC-BY 4.0 license.
👉 Paper link: https://huggingface.co/papers/2507.19634

10. SpA2V: Harnessing Spatial Auditory Cues for Audio-driven Spatially-aware Video Generation
🔑 Keywords: Audio-driven video generation, Spatial auditory cues, Video Scene Layouts, Diffusion models, Semantic alignment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce SpA2V, a framework leveraging spatial auditory cues to generate realistic videos aligned with input audio.
🛠️ Research Methods:
– The framework consists of two stages: Audio-guided Video Planning to construct Video Scene Layouts, and Layout-grounded Video Generation integrating these layouts into pre-trained diffusion models.
💬 Research Conclusions:
– SpA2V effectively generates videos with high semantic and spatial correspondence to input audios, excelling in creating realistic audiovisual content.
👉 Paper link: https://huggingface.co/papers/2508.00782

11. Investigating Hallucination in Conversations for Low Resource Languages
🔑 Keywords: Large Language Models, Hallucination, GPT-3.5, GPT-4o, Mandarin, Hindi, Farsi
💡 Category: Natural Language Processing
🌟 Research Objective:
– To examine the occurrence of hallucinations in conversational data using LLMs across three languages: Mandarin, Hindi, and Farsi.
🛠️ Research Methods:
– Comprehensive analysis of factual and linguistic errors in a dataset with LLMs like GPT-3.5, GPT-4o, Llama-3.1, Gemma-2.0, DeepSeek-R1, and Qwen-3.
💬 Research Conclusions:
– LLMs generate fewer hallucinations in Mandarin compared to Hindi and Farsi.
👉 Paper link: https://huggingface.co/papers/2507.22720

12. Multi-Agent Game Generation and Evaluation via Audio-Visual Recordings
🔑 Keywords: AI Native, multi-agent system, AVR-Eval, JavaScript code, omni-modal model
💡 Category: Generative Models
🌟 Research Objective:
– Develop a multi-agent system to improve JavaScript game and animation generation using an omni-modal evaluation metric.
🛠️ Research Methods:
– Implementing AVR-Eval, a relative metric for multimedia content quality, and building AVR-Agent to generate JavaScript code from multimedia assets.
– Utilizing a coding agent to iterate and enhance content quality through omni-modal agent feedback.
💬 Research Conclusions:
– AVR-Agent content demonstrated a higher win rate against one-shot generation methods.
– Current models still face challenges in effectively leveraging custom assets and audio-visual feedback, indicating a gap in resource utilization between human and machine content creation.
👉 Paper link: https://huggingface.co/papers/2508.00632

13. IGL-Nav: Incremental 3D Gaussian Localization for Image-goal Navigation
🔑 Keywords: IGL-Nav, 3D Gaussian Representation, Image-Goal Navigation, Differentiable Rendering, AI-Generated
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The primary aim is to achieve efficient and accurate image-goal navigation in a 3D environment using the IGL-Nav framework.
🛠️ Research Methods:
– Utilizes an Incremental 3D Gaussian Localization framework.
– Incremental scene updates with feed-forward monocular prediction for efficient navigation.
– Differentiable rendering is employed for precise goal localization.
💬 Research Conclusions:
– IGL-Nav outperforms existing methods in various scenarios and is applicable in real-world settings, particularly capable of free-view image-goal navigation using a cellphone.
👉 Paper link: https://huggingface.co/papers/2508.00823

14.
