AI Native Daily Paper Digest – 20250806

1. Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
🔑 Keywords: Seed Diffusion Preview, discrete-state diffusion, parallel generation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to present Seed Diffusion Preview, a large-scale language model, that achieves rapid inference speeds using discrete-state diffusion.
🛠️ Research Methods:
– The model utilizes non-sequential, parallel generation to enhance inference speeds, reaching 2,146 tokens per second on H20 GPUs.
💬 Research Conclusions:
– Seed Diffusion Preview outperforms contemporary models like Mercury and Gemini Diffusion in speed and quality, setting a new standard on the speed-quality Pareto frontier for code models.
👉 Paper link: https://huggingface.co/papers/2508.02193

2. Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation
🔑 Keywords: Skywork UniPic, autoregressive model, image understanding, text-to-image generation, image editing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Skywork UniPic, a 1.5 billion-parameter autoregressive model, that unifies image understanding, text-to-image generation, and image editing within a single architecture.
🛠️ Research Methods:
– Utilizes a decoupled encoding strategy with a masked autoregressive encoder for synthesis and a SigLIP2 encoder for understanding.
– Employs a progressive, resolution-aware training schedule that balances capacity and stability.
💬 Research Conclusions:
– Achieves state-of-the-art performance on commodity hardware, setting new records on multiple benchmarks.
– Demonstrates the efficiency of high-fidelity multimodal integration without excessive resource demands. Publicly available code and weights facilitate further research and application.
👉 Paper link: https://huggingface.co/papers/2508.03320

3. LongVie: Multimodal-Guided Controllable Ultra-Long Video Generation
🔑 Keywords: LongVie, autoregressive framework, temporal consistency, visual degradation, multi-modal control
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to address challenges in controllable ultra-long video generation, particularly temporal inconsistency and visual degradation.
🛠️ Research Methods:
– Introduction of LongVie, an end-to-end autoregressive framework employing unified noise initialization and global control signal normalization for improved temporal consistency.
– Utilization of a multi-modal control framework and degradation-aware training to enhance visual quality over lengthy videos.
💬 Research Conclusions:
– LongVie achieves state-of-the-art performance in long-range controllability, consistency, and quality. The introduction of LongVGenBench supports comprehensive evaluation.
👉 Paper link: https://huggingface.co/papers/2508.03694

4. CompassVerifier: A Unified and Robust Verifier for LLMs Evaluation and Outcome Reward
🔑 Keywords: CompassVerifier, VerifierBench, LLMs, Answer Verification, Multi-domain Competency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop CompassVerifier, a lightweight and robust model for verifying LLM outputs across various domains.
🛠️ Research Methods:
– Introduces VerifierBench, a comprehensive benchmark dataset to enhance the verification process using model outputs and manual analysis of metaerror patterns.
💬 Research Conclusions:
– CompassVerifier achieves high accuracy and robustness, showcasing multi-domain competency in tasks such as math, knowledge, and reasoning, while effectively identifying invalid responses. It aims to facilitate improvements in answer verification, evaluation protocols, and reinforcement learning research.
👉 Paper link: https://huggingface.co/papers/2508.03686

5. Tool-integrated Reinforcement Learning for Repo Deep Search
🔑 Keywords: ToolTrain, LLM-based agents, Repo Deep Search, tool-integrated reinforcement learning, automated software development
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces ToolTrain, a training framework aimed at enhancing LLMs for the task of issue localization by integrating repository retrieval tools.
🛠️ Research Methods:
– A two-stage training framework involving rejection-sampled supervised fine-tuning and tool-integrated reinforcement learning.
💬 Research Conclusions:
– ToolTrain-trained models achieve state-of-the-art results in function-level issue localization, surpassing models like Claude-3.7, and demonstrate improved performance in automated software development.
👉 Paper link: https://huggingface.co/papers/2508.03012

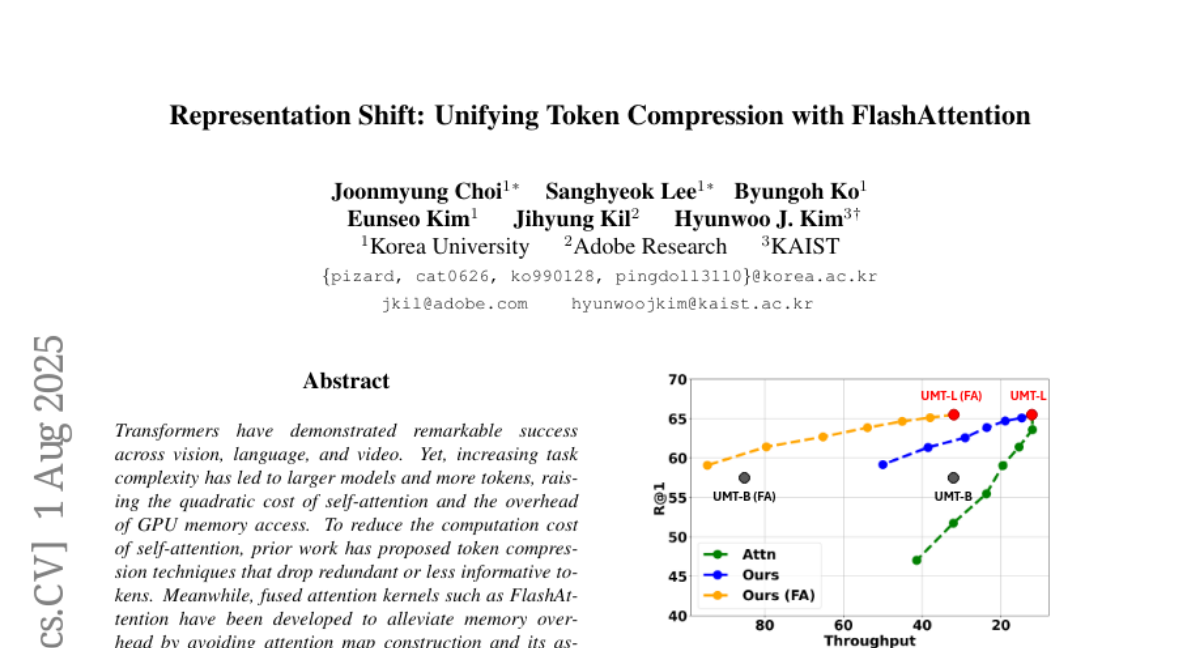
6. Representation Shift: Unifying Token Compression with FlashAttention
🔑 Keywords: Representation Shift, Token Compression, FlashAttention, Transformers
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces Representation Shift, a training-free, model-agnostic metric aimed at integrating token compression with FlashAttention to enhance performance in video-text retrieval and video QA.
🛠️ Research Methods:
– The approach involves measuring changes in token representation, enabling seamless compatibility with FlashAttention without the use of attention maps or retraining efforts.
💬 Research Conclusions:
– Representation Shift effectively pairs token compression with FlashAttention, achieving speedups of up to 5.5% in video-text retrieval and 4.4% in video QA, showcasing its potential impact across various models like Transformers, CNNs, and state space models.
👉 Paper link: https://huggingface.co/papers/2508.00367
7. CRINN: Contrastive Reinforcement Learning for Approximate Nearest Neighbor Search
🔑 Keywords: CRINN, AI Native, reinforcement learning, approximate nearest-neighbor search, execution speed
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces CRINN, a new paradigm designed to optimize approximate nearest-neighbor search (ANNS) algorithms for speed and accuracy, crucial for retrieval-augmented generation and agent-based LLM applications.
🛠️ Research Methods:
– CRINN utilizes reinforcement learning, treating ANNS optimization as a problem where execution speed is the reward signal, facilitating the automatic generation of faster ANNS implementations while maintaining accuracy constraints.
💬 Research Conclusions:
– CRINN outperforms state-of-the-art methods across multiple benchmarks, showcasing its effectiveness and demonstrating that LLMs augmented with reinforcement learning can effectively automate sophisticated algorithmic optimizations.
👉 Paper link: https://huggingface.co/papers/2508.02091

8. The Promise of RL for Autoregressive Image Editing
🔑 Keywords: Reinforcement Learning, Autoregressive Multimodal Model, Image Editing, Large Multi-modal LLM Verifier
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance image editing performance using reinforcement learning combined with a multimodal language model verifier within an autoregressive framework.
🛠️ Research Methods:
– Implemented three strategies: supervised fine-tuning, reinforcement learning, and Chain-of-Thought reasoning. Adopted an autoregressive multimodal model for processing textual and visual tokens.
💬 Research Conclusions:
– Discovered that reinforcement learning combined with a large multimodal language model verifier is the most effective, resulting in the release of EARL, an RL-based image editing model that performs well on diverse edits with less training data.
👉 Paper link: https://huggingface.co/papers/2508.01119

9. Multi-human Interactive Talking Dataset
🔑 Keywords: AI-generated summary, Multi-Human Pose Encoder, Interactive Audio Driver, multi-human talking video generation, fine-grained annotations
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces MIT, a large-scale dataset designed for generating multi-human talking videos, aiming to address the gap in studies dominated by single-person or isolated animations.
🛠️ Research Methods:
– The researchers developed an automatic pipeline to collect and annotate conversational videos featuring two to four speakers, integrating elements like a Multi-Human Pose Encoder and an Interactive Audio Driver for handling multiple speakers.
💬 Research Conclusions:
– This work establishes MIT as a valuable resource and benchmark for studying interactive visual behaviors, showcasing the feasibility and complexities in generating realistic multi-human talking videos.
👉 Paper link: https://huggingface.co/papers/2508.03050

10. LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?
🔑 Keywords: Model Context Protocol, LLM agents, LiveMCPBench, API interaction, MCP Copilot Agent
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Develop LiveMCPBench as a comprehensive benchmark for evaluating LLM agents across various real-world tasks within the MCP ecosystem using a scalable evaluation pipeline.
🛠️ Research Methods:
– Establish a diverse collection called LiveMCPTool with 70 MCP servers and 527 tools.
– Introduce LiveMCPEval, an LLM-as-a-Judge framework, achieving 81% agreement with human reviewers.
💬 Research Conclusions:
– LiveMCPBench offers a unified framework for benchmarking LLM agents in tool-rich and dynamic environments, highlighting performance variance across models, with Claude-Sonnet-4 achieving the highest success rate at 78.95%.
– The research establishes a foundation for scalable and reproducible studies on agent capabilities, with publicly available resources for further exploration.
👉 Paper link: https://huggingface.co/papers/2508.01780

11. Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
🔑 Keywords: Goedel-Prover-V2, automated theorem proving, scaffolded data synthesis, verifier-guided self-correction, model averaging
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop Goedel-Prover-V2, open-source language models that achieve state-of-the-art performance in automated theorem proving.
🛠️ Research Methods:
– Utilized scaffolded data synthesis to train the model with synthetic tasks of increasing difficulty.
– Implemented verifier-guided self-correction to iteratively revise proofs with Lean compiler feedback.
– Applied model averaging to merge checkpoints, enhancing model output diversity.
💬 Research Conclusions:
– The Goedel-Prover-V2-8B model achieved 84.6% pass@32 on MiniF2F, outperforming a much larger DeepSeek-Prover-V2-671B.
– The flagship Goedel-Prover-V2-32B model scored 88.1% on MiniF2F standard mode and 90.4% in self-correction mode, setting a new high performance for open-source theorem provers.
– Achieved first place on PutnamBench, solving 86 problems, surpassing the larger DeepSeek-Prover-V2-671B under a constrained compute budget.
👉 Paper link: https://huggingface.co/papers/2508.03613

12. LAMIC: Layout-Aware Multi-Image Composition via Scalability of Multimodal Diffusion Transformer
🔑 Keywords: LAMIC, controllable image synthesis, diffusion models, zero-shot generalization
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce LAMIC, a Layout-Aware Multi-Image Composition framework that extends single-reference diffusion models to multi-reference scenarios without training.
🛠️ Research Methods:
– Utilize plug-and-play attention mechanisms: Group Isolation Attention (GIA) and Region-Modulated Attention (RMA) to enhance entity disentanglement and enable layout-aware generation.
– Evaluate model capabilities using Inclusion Ratio, Fill Ratio for layout control, and Background Similarity for background consistency.
💬 Research Conclusions:
– Demonstrates superior identity keeping, background preservation, layout control, and prompt-following with state-of-the-art performance across various metrics.
– Establishes a new training-free paradigm for multi-image composition, showcasing strong zero-shot generalization abilities.
👉 Paper link: https://huggingface.co/papers/2508.00477
