AI Native Daily Paper Digest – 20250814

1. Story2Board: A Training-Free Approach for Expressive Storyboard Generation
🔑 Keywords: Story2Board, consistency framework, AI-generated summary, diffusion models, Scene Diversity
💡 Category: Generative Models
🌟 Research Objective:
– This research aims to develop Story2Board, a training-free framework for generating expressive storyboards from natural language, enhancing coherence and diversity without fine-tuning.
🛠️ Research Methods:
– The method involves a lightweight consistency framework with Latent Panel Anchoring and Reciprocal Attention Value Mixing, using state-of-the-art diffusion models and a language model for prompt structuring.
💬 Research Conclusions:
– Story2Board generates more dynamic, coherent, and narratively engaging storyboards than existing baselines, demonstrated through qualitative and quantitative results and a user study.
👉 Paper link: https://huggingface.co/papers/2508.09983

2. Mol-R1: Towards Explicit Long-CoT Reasoning in Molecule Discovery
🔑 Keywords: Mol-R1, Explicit Long Chain-of-Thought, Molecule discovery, PRID, MoIA
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study introduces Mol-R1 to enhance reasoning performance and explainability in molecule discovery using Explicit Long Chain-of-Thought reasoning models.
🛠️ Research Methods:
– Mol-R1 employs a high-quality reasoning dataset curated via Prior Regulation through In-context Distillation (PRID) and incorporates a Molecular Iterative Adaptation (MoIA) training strategy combining Supervised Fine-tuning with Reinforced Policy Optimization.
💬 Research Conclusions:
– Mol-R1 demonstrates superior performance in text-based molecule reasoning generation tasks when compared to existing baselines.
👉 Paper link: https://huggingface.co/papers/2508.08401

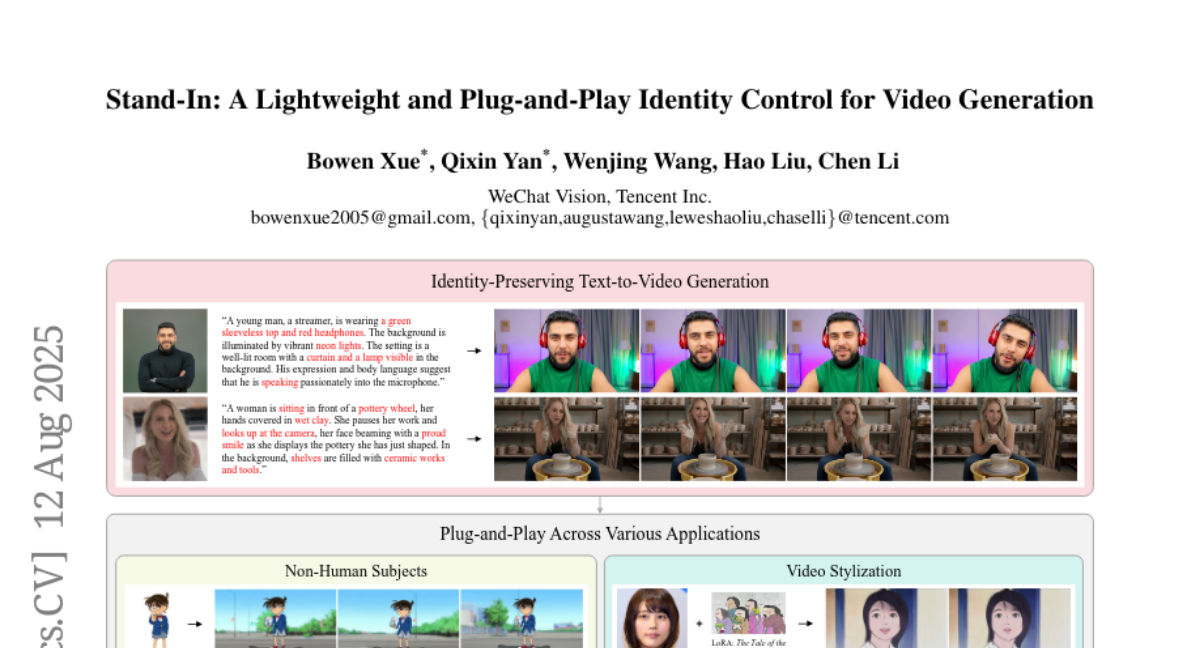
3. Stand-In: A Lightweight and Plug-and-Play Identity Control for Video Generation
🔑 Keywords: Identity Preservation, Generative AI, Conditional Image Branch, Restricted Self-Attentions
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop a lightweight framework, Stand-In, to preserve identity in video generation, challenging current methods that require numerous training parameters.
🛠️ Research Methods:
– Introduction of conditional image branches and restricted self-attentions for identity control in video generation, reducible to only 1% parameter addition while maintaining effectiveness.
💬 Research Conclusions:
– The proposed framework outperforms full-parameter methods, providing high video quality and identity preservation and can be seamlessly integrated into various tasks like subject-driven and pose-referenced video generation, stylization, and face swapping.
👉 Paper link: https://huggingface.co/papers/2508.07901
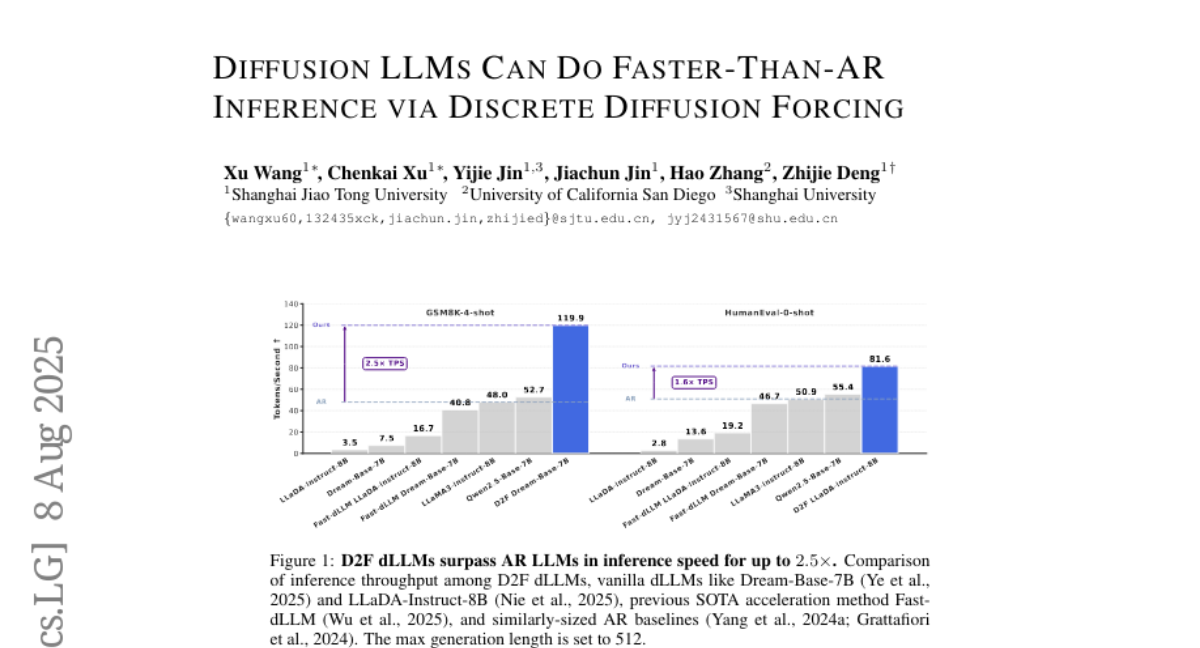
4. Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing
🔑 Keywords: Discrete Diffusion Forcing, Diffusion Large Language Models, Block-wise Autoregressive Generation, Inter-block Parallel Decoding, AI-generated Summary
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to enhance diffusion large language models (dLLMs) by introducing a strategy called Discrete Diffusion Forcing (D2F) which improves inference speed while maintaining output quality.
🛠️ Research Methods:
– The methodology involves implementing D2F through block-wise autoregressive generation and inter-block parallel decoding, allowing for efficient inference and integration of KV cache utilization via asymmetric distillation.
💬 Research Conclusions:
– The study concludes that dLLMs using D2F achieve significant acceleration, boasting over 2.5 times the inference speed of LLaMA3 and Qwen2.5, and more than 50 times for models like LLaDA and Dream, all while preserving comparable quality.
👉 Paper link: https://huggingface.co/papers/2508.09192
5. AWorld: Dynamic Multi-Agent System with Stable Maneuvering for Robust GAIA Problem Solving
🔑 Keywords: Multi-Agent System, Execution Agent, Guard Agent, GAIA leaderboard, dynamic supervision
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance the reliability and stability of intelligent agents by using a dynamic Multi-Agent System (MAS) that utilizes Execution and Guard Agents for improved problem-solving in complex environments.
🛠️ Research Methods:
– Implemented an architecture with dynamic supervision and maneuvering mechanisms within the AWorld framework to overcome challenges of extended contexts and noisy tool outputs.
💬 Research Conclusions:
– The dynamic MAS system significantly outperformed single-agent and standard tool-augmented systems on the GAIA test dataset, achieving first place on the GAIA leaderboard, thus demonstrating the value of collaborative agent roles in creating reliable intelligent systems.
👉 Paper link: https://huggingface.co/papers/2508.09889

6. Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
🔑 Keywords: M3-Agent, Long-term memory, Multimodal agent, M3-Bench, Reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce M3-Agent, a multimodal agent framework with long-term and semantic memory designed for complex multi-turn reasoning and effective task execution.
🛠️ Research Methods:
– M3-Agent is evaluated using M3-Bench, a new long-video question answering benchmark comprising real-world and web-sourced videos to test key agent capabilities.
💬 Research Conclusions:
– M3-Agent, trained via reinforcement learning, surpasses existing baselines in performance, indicating advancements in multimodal agents toward human-like long-term memory capabilities.
👉 Paper link: https://huggingface.co/papers/2508.09736

7. Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
🔑 Keywords: GPT-4o, synthetic dataset, Echo-4o-Image, image generation, transferability
💡 Category: Generative Models
🌟 Research Objective:
– Explore the advantages of using AI-generated synthetic images, specifically Echo-4o-Image, to enhance image generation models, addressing rare scenarios and providing clean supervision.
🛠️ Research Methods:
– Generate a 180K-scale synthetic dataset using GPT-4o and fine-tune the unified multimodal generation baseline, Bagel, with it. Introduce new evaluation benchmarks, GenEval++ and Imagine-Bench, to assess image generation capabilities.
💬 Research Conclusions:
– Echo-4o-Image improves performance and transferability across standard benchmarks and yields consistent performance gains when applied to other foundation models, demonstrating strong transferability and addressing blind spots in real-world datasets.
👉 Paper link: https://huggingface.co/papers/2508.09987

8. Learning to Align, Aligning to Learn: A Unified Approach for Self-Optimized Alignment
🔑 Keywords: Language model alignment, GRAO, Supervised fine-tuning (SFT), Reinforcement learning (RL), Group Direct Alignment Loss
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance language model alignment by combining the strengths of supervised fine-tuning (SFT) and reinforcement learning (RL) into a unified framework called GRAO (Group Relative Alignment Optimization).
🛠️ Research Methods:
– GRAO employs a multi-sample generation strategy for quality assessment, a novel Group Direct Alignment Loss utilizing intra-group relative advantage, and reference-aware parameter updates based on pairwise preference dynamics.
💬 Research Conclusions:
– GRAO demonstrates superior performance in human alignment tasks, achieving notable improvements over baseline methods such as SFT, DPO, PPO, and GRPO. It offers theoretical guarantees of convergence and enhanced sample efficiency.
👉 Paper link: https://huggingface.co/papers/2508.07750

9. MathReal: We Keep It Real! A Real Scene Benchmark for Evaluating Math Reasoning in Multimodal Large Language Models
🔑 Keywords: MathReal, Multimodal Large Language Models, Visual Mathematical Reasoning, Image Quality Degradation, Real-World Educational Contexts
💡 Category: AI in Education
🌟 Research Objective:
– The study introduces MathReal, a dataset aimed at evaluating the performance of multimodal large language models (MLLMs) in real-world educational settings.
🛠️ Research Methods:
– MathReal consists of 2,000 mathematical questions with images, captured by handheld mobile devices, and classifies images into primary categories related to quality and content interference.
– Six experimental settings are designed to analyze the performance of state-of-the-art MLLMs.
💬 Research Conclusions:
– Existing MLLMs face significant challenges in realistic educational contexts, particularly in problem-solving abilities.
– The study provides insights into MLLMs’ recognition, comprehension, and reasoning capabilities and suggests directions for future improvements.
👉 Paper link: https://huggingface.co/papers/2508.06009

10. Cooper: Co-Optimizing Policy and Reward Models in Reinforcement Learning for Large Language Models
🔑 Keywords: Reinforcement Learning, Reward Model, Reward Hacking, Policy Model, Cooper
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary objective is to enhance robustness and mitigate reward hacking in large language models by jointly optimizing policy and reward models.
🛠️ Research Methods:
– The study introduces Cooper, a framework that leverages rule-based rewards and dynamically constructs sample pairs for robust training.
– It also utilizes a hybrid annotation strategy for efficient data generation and a reference-based reward modeling paradigm resulting in the VerifyRM model.
💬 Research Conclusions:
– Cooper framework effectively alleviates reward hacking and improves end-to-end RL performance, demonstrated by a 0.54% accuracy gain on Qwen2.5-1.5B-Instruct.
– Findings show dynamically updating reward models is crucial in combating reward hacking.
👉 Paper link: https://huggingface.co/papers/2508.05613

11. IAG: Input-aware Backdoor Attack on VLMs for Visual Grounding
🔑 Keywords: Vision-language models, backdoor attacks, text-conditional U-Net, adaptive trigger generator, reconstruction loss
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce the novel IAG method to manipulate the grounding behavior of vision-language models through input-aware backdoor attacks.
🛠️ Research Methods:
– Employ an adaptive trigger generator using a text-conditional U-Net to embed semantic information into images.
– Utilize reconstruction loss to minimize visual discrepancies, ensuring stealthiness.
💬 Research Conclusions:
– Demonstrated over 65% [email protected] effectiveness on InternVL-2.5-8B and promising manipulation abilities on other models with minimal accuracy loss on clean samples.
– Highlighted the robustness and transferability of the IAG method through various experiments, including ablation studies and potential defenses.
👉 Paper link: https://huggingface.co/papers/2508.09456

12. Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
🔑 Keywords: Noise Hypernetwork, test-time scaling, diffusion models, computational cost, generators
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to integrate test-time scaling knowledge into diffusion models using a Noise Hypernetwork, aiming to reduce computational cost while retaining quality.
🛠️ Research Methods:
– Introduces a Noise Hypernetwork that modulates initial input noise as a replacement for reward-guided test-time noise optimization, supported by a tractable noise-space objective for learning a reward-tilted distribution in distilled generators.
💬 Research Conclusions:
– Demonstrates that the proposed approach can recover a substantial portion of the quality gains from explicit test-time optimization with significantly reduced computational cost.
👉 Paper link: https://huggingface.co/papers/2508.09968

13. VisCodex: Unified Multimodal Code Generation via Merging Vision and Coding Models
🔑 Keywords: VisCodex, Multimodal large language models, AI-generated summary, task vector-based model merging, coding LLM
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VisCodex, a framework that integrates vision and coding models to enhance multimodal code generation capabilities.
🛠️ Research Methods:
– Utilize a task vector-based model merging technique to integrate a coding LLM into a vision-language backbone, and create a Multimodal Coding Dataset (MCD) to support model training and evaluation.
💬 Research Conclusions:
– VisCodex achieves state-of-the-art performance in open-source models and closely competes with proprietary models, demonstrating the effectiveness of the integration strategy and new datasets.
👉 Paper link: https://huggingface.co/papers/2508.09945

14. CannyEdit: Selective Canny Control and Dual-Prompt Guidance for Training-Free Image Editing
🔑 Keywords: CannyEdit, Selective Canny Control, Dual-Prompt Guidance, text-to-image, context fidelity
💡 Category: Generative Models
🌟 Research Objective:
– Introduce CannyEdit, a novel training-free framework to enhance text-to-image editing by balancing text adherence, context fidelity, and seamless integration.
🛠️ Research Methods:
– Utilize Selective Canny Control for precise, text-driven edits while preserving details in unedited areas.
– Implement Dual-Prompt Guidance combining local and global prompts to maintain coherent interactions within scenes.
💬 Research Conclusions:
– CannyEdit achieves a 2.93 to 10.49 percent improvement over prior methods in balancing text adherence and context fidelity, with significantly lower detection as AI-edited in user studies.
👉 Paper link: https://huggingface.co/papers/2508.06937

15. Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning
🔑 Keywords: GFPO, length explosion, token efficiency, reinforcement learning, Adaptive Difficulty GFPO
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To reduce length inflation in large language models while maintaining accuracy and increasing computational efficiency.
🛠️ Research Methods:
– Introduced Group Filtered Policy Optimization (GFPO) which samples larger groups and filters responses based on response length and token efficiency.
💬 Research Conclusions:
– GFPO significantly decreases length inflation while preserving accuracy across various STEM and coding benchmarks.
– Optimizing for reward per token further enhances reduction in length inflation.
– Adaptive Difficulty GFPO allocates resources based on problem difficulty, improving computational efficiency and accuracy.
👉 Paper link: https://huggingface.co/papers/2508.09726

16. μ-Parametrization for Mixture of Experts
🔑 Keywords: Mixture-of-Experts, mu-Parameterization, feature learning, scaling experts
💡 Category: Machine Learning
🌟 Research Objective:
– The paper aims to provide a new parameterization for Mixture-of-Experts models that offers theoretical guarantees for feature learning and examines the effects of scaling experts and granularity on learning rates.
🛠️ Research Methods:
– The researchers derived a mu-Parameterization (muP) for Mixture-of-Experts models and empirically validated the parameterization to explore its impact on feature learning and optimal learning rates.
💬 Research Conclusions:
– The study establishes a theoretical foundation for the use of mu-Parameterization in Mixture-of-Experts models, highlighting its efficacy in optimizing learning through scaling and granularity adjustments.
👉 Paper link: https://huggingface.co/papers/2508.09752

17. Decentralized Aerial Manipulation of a Cable-Suspended Load using Multi-Agent Reinforcement Learning
🔑 Keywords: Decentralized, Multi-Agent Reinforcement Learning, MAVs, Scalability, Robustness
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enable real-world 6-DoF manipulation of cable-suspended loads using decentralized multi-agent reinforcement learning (MARL) with Micro-Aerial Vehicles (MAVs).
🛠️ Research Methods:
– Utilized MARL to train control policies for MAVs without needing global states or communications, relying instead on load pose observations.
– Introduced a new action space design using linear acceleration and body rates.
💬 Research Conclusions:
– Achieved performance comparable to centralized methods with improved scalability and computational efficiency.
– Demonstrated robustness against uncertainties and the loss of one MAV during operation.
👉 Paper link: https://huggingface.co/papers/2508.01522
18. GSFixer: Improving 3D Gaussian Splatting with Reference-Guided Video Diffusion Priors
🔑 Keywords: 3D Gaussian Splatting, DiT-based video diffusion model, reference-guided video restoration, artifact restoration, sparse-view 3D reconstruction
💡 Category: Generative Models
🌟 Research Objective:
– GSFixer aims to enhance 3D Gaussian Splatting reconstructions from sparse views, improving artifact restoration and 3D consistency.
🛠️ Research Methods:
– The approach uses a DiT-based video diffusion model with reference-guided conditions and integrates both 2D semantic and 3D geometric features.
💬 Research Conclusions:
– GSFixer outperforms current state-of-the-art methods in 3DGS artifact restoration and sparse-view 3D reconstruction.
👉 Paper link: https://huggingface.co/papers/2508.09667

19. Can LLM-Generated Textual Explanations Enhance Model Classification Performance? An Empirical Study
🔑 Keywords: Explainable Natural Language Processing, AI-generated summary, Large Language Models, Natural Language Inference, Textual Explanations
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to develop an automated framework leveraging large language models to generate high-quality textual explanations for natural language inference tasks.
🛠️ Research Methods:
– Utilization of state-of-the-art large language models to automate the generation of textual explanations, followed by evaluation using Natural Language Generation metrics.
💬 Research Conclusions:
– The findings demonstrate that automated textual explanations are highly effective, showing competitive performance improvements in comparison to human-annotated explanations. This highlights a scalable solution for enhancing natural language processing datasets and model performance.
👉 Paper link: https://huggingface.co/papers/2508.09776

20. AMFT: Aligning LLM Reasoners by Meta-Learning the Optimal Imitation-Exploration Balance
🔑 Keywords: Adaptive Meta Fine-Tuning, Large Language Models, Reinforcement Learning, Supervised Fine-Tuning, Meta-gradient adaptive weight controller
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance Large Language Models (LLMs) performance and generalization by optimally balancing Supervised Fine-Tuning and Reinforcement Learning using implicit rewards.
🛠️ Research Methods:
– Introduces a novel single-stage algorithm, Adaptive Meta Fine-Tuning (AMFT), which employs a meta-gradient adaptive weight controller for dynamically balancing between implicit path-level rewards of SFT and explicit outcome-based rewards of RL.
💬 Research Conclusions:
– AMFT achieves new state-of-the-art performance across various benchmarks in reasoning tasks and exhibits superior generalization in out-of-distribution tasks, with the meta-learning controller being crucial for stability, sample efficiency, and overall performance.
👉 Paper link: https://huggingface.co/papers/2508.06944

21. ASM-UNet: Adaptive Scan Mamba Integrating Group Commonalities and Individual Variations for Fine-Grained Segmentation
🔑 Keywords: ASM-UNet, adaptive scan scores, Mamba-based architecture, fine-grained segmentation, AI-generated summary
💡 Category: AI in Healthcare
🌟 Research Objective:
– The paper proposes ASM-UNet, aiming to enhance fine-grained segmentation by adjusting scanning orders to account for individual anatomical variations.
🛠️ Research Methods:
– Utilizes adaptive scan scores, integrating group-level commonalities and individual-level variations to dynamically guide scanning orders in medical image segmentation.
💬 Research Conclusions:
– ASM-UNet demonstrates superior performance in both coarse-grained and fine-grained segmentation tasks through experiments on two public datasets and a challenging new biliary tract FGS dataset.
👉 Paper link: https://huggingface.co/papers/2508.07237

22. ObfusQAte: A Proposed Framework to Evaluate LLM Robustness on Obfuscated Factual Question Answering
🔑 Keywords: ObfusQA, Large Language Models, Named-Entity Indirection, Distractor Indirection, Contextual Overload
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate the robustness and adaptability of Large Language Models (LLMs) by using a novel framework called ObfusQA, which utilizes multi-tiered obfuscation levels.
🛠️ Research Methods:
– The framework examines LLM capabilities across three dimensions: Named-Entity Indirection, Distractor Indirection, and Contextual Overload, providing a comprehensive benchmark for LLM evaluation.
💬 Research Conclusions:
– The study reveals that LLMs tend to either fail or generate hallucinated responses when confronted with obfuscated versions of questions, emphasizing the need for further research in this area.
👉 Paper link: https://huggingface.co/papers/2508.07321

23.
