AI Native Daily Paper Digest – 20250825

1. AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs
🔑 Keywords: Memory-augmented Markov Decision Process (M-MDP), Neural case-selection policy, Episodic memory, Continuous learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce a novel reinforcement learning paradigm for Large Language Model (LLM) agents to facilitate continuous learning without fine-tuning.
🛠️ Research Methods:
– Utilizes an M-MDP framework with a neural case-selection policy, incorporating episodic memory and efficient memory retrieval mechanisms.
💬 Research Conclusions:
– Demonstrated successful application in the AgentFly model, outperforming current methods with improved performance on various tasks and datasets.
👉 Paper link: https://huggingface.co/papers/2508.16153

2. ODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
🔑 Keywords: ODYSSEY, language-guided, hierarchical planner, vision-language model, sim-to-real transfer
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Develop a unified mobile manipulation framework for quadruped robots integrating high-level task planning with low-level whole-body control.
🛠️ Research Methods:
– Introduce a hierarchical planner powered by a vision-language model for precise action execution in language-conditioned tasks.
– Establish a robust whole-body policy for improved coordination across challenging terrains.
💬 Research Conclusions:
– Demonstrate the system’s generalization and robustness in real-world deployments, advancing practical applicability of legged manipulators in unstructured environments.
👉 Paper link: https://huggingface.co/papers/2508.08240

3. Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR
🔑 Keywords: RLVR, Large Language Models, Self-play, Variational problem Synthesis, Pass@k
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the performance of Reinforcement Learning with Verifiable Rewards (RLVR) on complex reasoning tasks by maintaining policy entropy and enhancing Pass@k performance.
🛠️ Research Methods:
– Developed an online Self-play strategy with Variational problem Synthesis (SvS) that uses policy’s correct solutions to generate variational problems, maintaining identical reference answers.
💬 Research Conclusions:
– The SvS strategy substantially enhances policy entropy and improves Pass@k performance compared to standard RLVR, achieving significant gains on benchmarks like AIME24 and AIME25.
👉 Paper link: https://huggingface.co/papers/2508.14029

4. EgoTwin: Dreaming Body and View in First Person
🔑 Keywords: EgoTwin, Viewpoint Alignment, Causal Interplay, diffusion transformer, head-centric motion representation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to explore joint egocentric video and human motion generation by addressing challenges in viewpoint alignment and causal interplay.
🛠️ Research Methods:
– The EgoTwin framework uses a diffusion transformer architecture, incorporating a head-centric motion representation and a cybernetics-inspired interaction mechanism to capture causal interplay.
💬 Research Conclusions:
– Extensive experiments on a large-scale real-world dataset demonstrate the effectiveness of EgoTwin in achieving video-motion consistency.
👉 Paper link: https://huggingface.co/papers/2508.13013
5. CRISP: Persistent Concept Unlearning via Sparse Autoencoders
🔑 Keywords: CRISP, sparse autoencoders, concept unlearning, large language models, semantically coherent separation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce a parameter-efficient method, CRISP, for the persistent unlearning of unwanted knowledge in large language models, while maintaining the models’ utility.
🛠️ Research Methods:
– Using sparse autoencoders to identify and suppress salient features across multiple layers of large language models to achieve persistent concept unlearning.
💬 Research Conclusions:
– CRISP outperforms existing methods in safety-critical tasks by effectively removing harmful knowledge without compromising the general and in-domain capabilities of the models. It achieves a semantically coherent separation between target and benign concepts.
👉 Paper link: https://huggingface.co/papers/2508.13650

6. Selective Contrastive Learning for Weakly Supervised Affordance Grounding
🔑 Keywords: affordance-relevant cues, weakly supervised affordance grounding, selective prototypical objectives, pixel contrastive objectives, CLIP
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to improve affordance grounding by employing selective prototypical and pixel contrastive objectives to learn affordance-relevant cues from third-person demonstrations.
🛠️ Research Methods:
– The approach utilizes a combination of selective prototypical and pixel contrastive objectives to identify affordance-relevant parts and objects. This involves leveraging CLIP to locate action-associated objects in both egocentric and exocentric images, and cross-referencing these to find part-level affordance clues.
💬 Research Conclusions:
– The method enhances the learning process by effectively distinguishing affordance-relevant regions from the background, thus improving the accuracy of affordance grounding. Experimentation confirms the effectiveness of this method.
👉 Paper link: https://huggingface.co/papers/2508.07877

7. AetherCode: Evaluating LLMs’ Ability to Win In Premier Programming Competitions
🔑 Keywords: AetherCode, Competitive programming, Large Language Models, benchmark, evaluation bias
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce AetherCode, a new benchmark designed to evaluate the reasoning and coding capabilities of Large Language Models in competitive programming scenarios.
🛠️ Research Methods:
– Develop a benchmark with problems from top programming competitions, such as IOI and ICPC, offering broader coverage and higher difficulty.
– Incorporate expert-validated test suites using a combination of automated generation and human curation for rigorous assessment.
💬 Research Conclusions:
– AetherCode addresses current benchmark limitations by providing a challenging and reliable measure of LLM capabilities, setting a new standard for future research in code reasoning.
👉 Paper link: https://huggingface.co/papers/2508.16402

8. TPLA: Tensor Parallel Latent Attention for Efficient Disaggregated Prefill \& Decode Inference
🔑 Keywords: Tensor Parallelism, Latent Representation, AI-Generated Summary, Prefilling, FlashAttention-3
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Propose Tensor-Parallel Latent Attention (TPLA) to enhance tensor parallelism efficiency and maintain strong representational capacity.
🛠️ Research Methods:
– Partition latent representation and input dimensions across devices, perform attention per shard, and combine results with an all-reduce.
– Support MLA-style prefilling and tensor-parallel decoding using orthogonal transforms to reduce cross-shard interference.
💬 Research Conclusions:
– Achieved up to 1.93x speedups in tensor parallelism without retraining while maintaining performance on commonsense and LongBench benchmarks.
👉 Paper link: https://huggingface.co/papers/2508.15881

9. End-to-End Agentic RAG System Training for Traceable Diagnostic Reasoning
🔑 Keywords: Agentic RAG system, Reinforcement Learning, Diagnostic Accuracy, Retrieval Corpus, AI in Healthcare
💡 Category: AI in Healthcare
🌟 Research Objective:
– The aim is to enhance medical diagnosis accuracy by designing Deep-DxSearch, which integrates a large-scale retrieval corpus with tailored rewards.
🛠️ Research Methods:
– The method involves using an end-to-end agentic RAG system with reinforcement learning, framing the LLM as the core agent within a retrieval corpus environment to enable retrieval-augmented reasoning.
💬 Research Conclusions:
– The Deep-DxSearch system surpasses existing diagnostic systems such as GPT-4o in diagnostic accuracy and effectiveness, especially noteworthy in both common and rare diseases, validated through various experiments and case studies.
👉 Paper link: https://huggingface.co/papers/2508.15746

10. AgentScope 1.0: A Developer-Centric Framework for Building Agentic Applications
🔑 Keywords: AgentScope, Agentic Applications, ReAct Paradigm, AI Generated Summary, Large Language Models
💡 Category: AI Systems and Tools
🌟 Research Objective:
– AgentScope aims to enhance agentic applications by providing flexible tool-based interactions, unified interfaces, and advanced infrastructure based on the ReAct paradigm.
🛠️ Research Methods:
– The study abstracts foundational components for agentic applications and offers a system with extensible modules and unified interfaces. It envisions the ReAct paradigm and adopts asynchronous design for improved interaction patterns and execution efficiency.
💬 Research Conclusions:
– AgentScope introduces improvements for agent-environment interactions, integrating built-in agents for practical scenarios. It provides robust engineering support and a scalable evaluation module, ensuring safe execution and facilitating deployment.
👉 Paper link: https://huggingface.co/papers/2508.16279

11. Do What? Teaching Vision-Language-Action Models to Reject the Impossible
🔑 Keywords: Instruct-Verify-and-Act, Vision-Language-Action, false-premise instructions, contextually augmented, semi-synthetic dataset
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective of the study is to enhance Vision-Language-Action models to effectively detect and respond to false-premise instructions by utilizing a unified framework, Instruct-Verify-and-Act.
🛠️ Research Methods:
– The research involved constructing a large-scale instruction tuning setup with structured language prompts and training a VLA model using a contextually augmented, semi-synthetic dataset with paired positive and false-premise instructions.
💬 Research Conclusions:
– The proposed IVA framework significantly improves false premise detection accuracy by 97.56% over existing baselines and increases successful responses in false-premise scenarios by 50.78%.
👉 Paper link: https://huggingface.co/papers/2508.16292

12. Distilled-3DGS:Distilled 3D Gaussian Splatting
🔑 Keywords: 3D Gaussian Splatting, Knowledge Distillation, Novel View Synthesis, Structural Similarity Loss
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance rendering quality and storage efficiency in 3D Gaussian Splatting by utilizing a knowledge distillation framework.
🛠️ Research Methods:
– Implementation of a knowledge distillation framework featuring multiple teacher models (including standard, noise-augmented, and dropout-regularized variants) to optimize a lightweight student model.
– Introduction of a structural similarity loss to maintain spatial geometric consistency between teacher and student models.
💬 Research Conclusions:
– The proposed Distilled-3DGS framework significantly improves both rendering quality and storage efficiency over existing state-of-the-art methods through comprehensive evaluations.
👉 Paper link: https://huggingface.co/papers/2508.14037
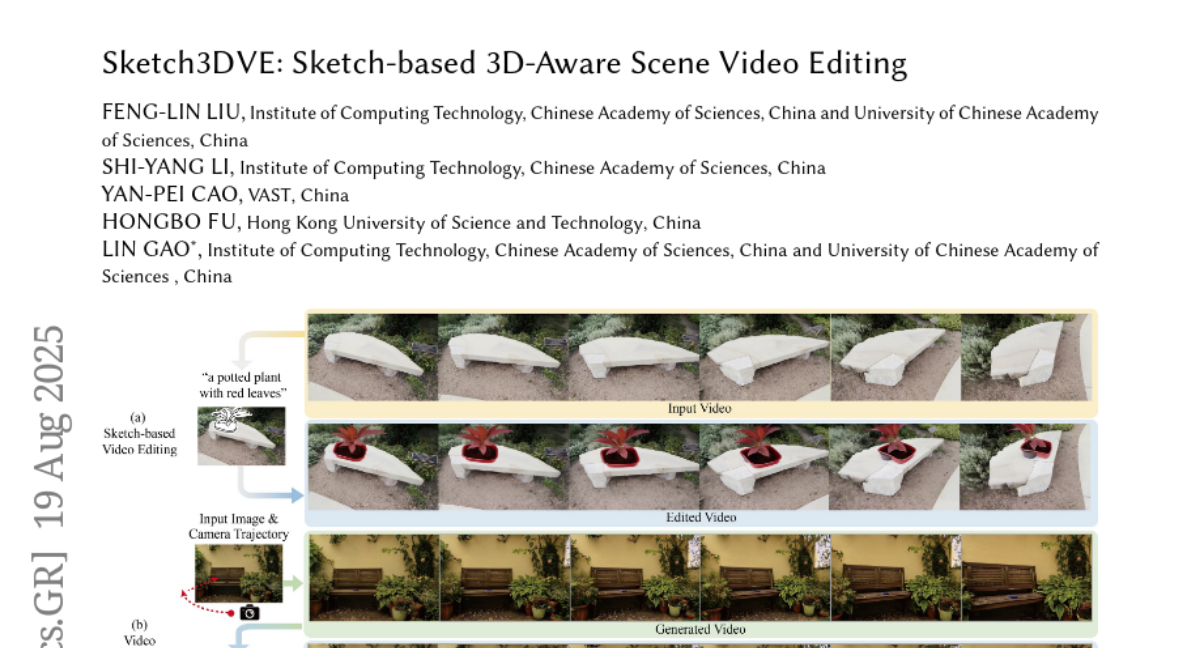
13. Sketch3DVE: Sketch-based 3D-Aware Scene Video Editing
🔑 Keywords: Sketch3DVE, 3D-aware video editing, viewpoint changes, point cloud editing, video diffusion model
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a sketch-based method for 3D-aware video editing that addresses challenges of sparse inputs and significant viewpoint changes.
🛠️ Research Methods:
– Employ a combination of dense stereo estimation, point cloud editing, and a video diffusion model for precise manipulation of video content, incorporating sketching as an interactive geometry control tool.
💬 Research Conclusions:
– Sketch3DVE effectively handles novel view content generation and merges new edits seamlessly with original videos, outperforming existing video editing methods.
👉 Paper link: https://huggingface.co/papers/2508.13797
14. InMind: Evaluating LLMs in Capturing and Applying Individual Human Reasoning Styles
🔑 Keywords: LLMs, personalized reasoning styles, social deduction games, InMind, Human-AI Interaction
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The study aims to evaluate LLMs’ ability to capture and apply personalized reasoning styles in social deduction games using the InMind framework.
🛠️ Research Methods:
– Introduction of a cognitive evaluation framework called InMind, which enhances structured gameplay data with strategy traces and post-game reflections in different modes.
💬 Research Conclusions:
– The study finds that general-purpose LLMs, including GPT-4, struggle with adapting evolving strategies in social contexts, while reasoning-enhanced LLMs show early potential for style-sensitive reasoning, highlighting limitations in current models for individualized, adaptive reasoning.
👉 Paper link: https://huggingface.co/papers/2508.16072

15. RotaTouille: Rotation Equivariant Deep Learning for Contours
🔑 Keywords: RotaTouille, rotation equivariance, cyclic shift equivariance, complex-valued circular convolution
💡 Category: Computer Vision
🌟 Research Objective:
– Introducing RotaTouille framework to achieve rotation and cyclic shift equivariance in contour data analysis.
🛠️ Research Methods:
– Utilization of complex-valued circular convolution and development of equivariant non-linearities, coarsening layers, and global pooling layers.
💬 Research Conclusions:
– Demonstrated the effectiveness of RotaTouille in shape classification, reconstruction, and contour regression through various experiments.
👉 Paper link: https://huggingface.co/papers/2508.16359

16. Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts
🔑 Keywords: hybrid framework, jailbreak attacks, malicious content detection, LLMs, dataset cleaning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To propose a hybrid framework combining LLMs and human oversight to clean datasets and detect jailbreak attacks effectively.
🛠️ Research Methods:
– Utilized a hybrid evaluation framework called MDH, combining LLM-based annotation with minimal human oversight, to balance accuracy and efficiency in malicious content detection.
💬 Research Conclusions:
– Suggests that well-crafted developer messages can significantly increase jailbreak success, leading to the proposal of two new strategies, D-Attack and DH-CoT, to enhance jailbreak detection.
👉 Paper link: https://huggingface.co/papers/2508.10390

17. Learnable SMPLify: A Neural Solution for Optimization-Free Human Pose Inverse Kinematics
🔑 Keywords: 3D human pose estimation, neural network, iterative optimization, Learnable SMPLify, single-pass regression model
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a faster and more generalized framework for 3D human pose and shape estimation by replacing iterative optimization with a neural network.
🛠️ Research Methods:
– The framework employs a single-pass regression model and incorporates a temporal sampling strategy and human-centric normalization for data construction and generalization.
💬 Research Conclusions:
– Learnable SMPLify achieves nearly 200x faster runtime compared to traditional methods while maintaining accuracy and operates effectively across various motions and as a model-agnostic tool.
👉 Paper link: https://huggingface.co/papers/2508.13562

18. CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning
🔑 Keywords: Chain-of-Thought, Reinforcement Learning, Contrastive learning, Large Language Models, Supervised Fine-Tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance reasoning performance of Large Language Models (LLMs) by overcoming limitations of existing fine-tuning approaches through a novel contrastive learning method based on annotated Chain-of-Thought.
🛠️ Research Methods:
– Propose a contrastive learning approach integrated with Reinforced Fine-Tuning, utilizing annotated Chain-of-Thought to stabilize training and improve model robustness and performance. Conduct experiments with three baseline approaches, two foundation models, and two datasets.
💬 Research Conclusions:
– This approach significantly improves the stability and performance of LLMs, demonstrating advantages in robustness, efficiency, and performance improvements up to 30.62%. The method effectively leverages unsupervised learning signals to enhance fine-tuning.
👉 Paper link: https://huggingface.co/papers/2508.15868

19.
