AI Native Daily Paper Digest – 20250829
1. Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
🔑 Keywords: Reward Hacking, GRPO, Text-to-Image Generation, Preference Fitting, Semantic Consistency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The main aim is to enhance the stability and effectiveness of text-to-image (T2I) generation models by mitigating reward hacking and providing a more comprehensive evaluation benchmark.
🛠️ Research Methods:
– Introducing Pref-GRPO, a pairwise preference reward-based method that shifts the focus from score maximization to preference fitting, which uses win rate as a reward signal to differentiate subtle image quality differences.
– Developing UniGenBench, a unified benchmark with 600 prompts to assess semantic consistency and evaluate T2I models comprehensively.
💬 Research Conclusions:
– Pref-GRPO offers more stable training and mitigates reward hacking by preferring genuine image quality differences over trivial score optimizations.
– UniGenBench provides detailed evaluation criteria that reveal strengths and weaknesses in both open and closed-source T2I models, corroborating the effectiveness of the Pref-GRPO method.
👉 Paper link: https://huggingface.co/papers/2508.20751

2. rStar2-Agent: Agentic Reasoning Technical Report
🔑 Keywords: rStar2-Agent, agentic reinforcement learning, cognitive behaviors, Python coding tools, AI Native
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a math reasoning model, rStar2-Agent, utilizing agentic reinforcement learning to achieve state-of-the-art performance in solving complex problems.
🛠️ Research Methods:
– Implementation of an efficient RL infrastructure with a high-throughput Python code environment.
– Utilization of the GRPO-RoC algorithm with a Resample-on-Correct rollout strategy to enhance reasoning in code environments.
– Deployment of an agent training recipe involving non-reasoning SFT and progressive multi-RL stages.
💬 Research Conclusions:
– rStar2-Agent significantly enhances problem-solving efficiency, achieving high scores on AIME24 and AIME25 matches with minimal resources.
– Demonstrates strong generalization capabilities extending beyond mathematics into alignment, scientific reasoning, and agentic tool-use tasks.
– Availability of code and training recipes to facilitate further research and application.
👉 Paper link: https://huggingface.co/papers/2508.20722

3. USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning
🔑 Keywords: Disentangled Learning, Style-Subject Optimization, Style Reward-Learning, State-of-the-art Performance, USO-Bench
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to unify style-driven and subject-driven generation tasks within a single framework by disentangling and recomposing content and style.
🛠️ Research Methods:
– A large-scale triplet dataset is constructed.
– A disentangled learning scheme using style-alignment training and content-style disentanglement training is introduced.
– A style reward-learning paradigm, SRL, is incorporated to enhance model performance.
💬 Research Conclusions:
– USO achieves state-of-the-art performance in style similarity and subject consistency, validated across multiple metrics with the release of USO-Bench.
👉 Paper link: https://huggingface.co/papers/2508.18966

4. MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers
🔑 Keywords: MCP-Bench, large language models, multi-step tasks, tool use, planning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce MCP-Bench, a benchmark for evaluating large language models on complex, multi-step tasks requiring tool use and cross-tool coordination.
🛠️ Research Methods:
– Utilizes Model Context Protocol (MCP) to connect language models to MCP servers encompassing 250 tools across domains, constructing authentic, multi-step tasks for evaluation.
💬 Research Conclusions:
– Identifies persistent challenges in advanced language models when tested on MCP-Bench, highlighting areas not covered by existing benchmarks.
👉 Paper link: https://huggingface.co/papers/2508.20453

5. AWorld: Orchestrating the Training Recipe for Agentic AI
🔑 Keywords: Agentic AI, Reinforcement Learning, Experience Collection, Qwen3-32B, Open-Source
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve experience collection efficiency and enhance performance in agentic AI systems through AWorld.
🛠️ Research Methods:
– Developed AWorld, an open-source system for large-scale agent-environment interaction, leveraging task distribution across clusters to accelerate experience collection by 14.6x.
💬 Research Conclusions:
– AWorld enables practical, scalable reinforcement learning, training a Qwen3-32B-based agent that significantly outperforms the base model on GAIA benchmarks, providing a blueprint for agentic AI training.
👉 Paper link: https://huggingface.co/papers/2508.20404

6. TCIA: A Task-Centric Instruction Augmentation Method for Instruction Finetuning
🔑 Keywords: Task Centric Instruction Augmentation, large language models, instruction dataset, task-specific knowledge, open-source LLMs
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Task Centric Instruction Augmentation (TCIA) to enhance the performance of large language models on specific tasks while maintaining their general instruction-following capabilities.
🛠️ Research Methods:
– Develop a framework that expands instructions in a way that retains diversity and aligns with task-specific needs, utilizing a discrete query-constraints space to generate task-relevant instructions.
💬 Research Conclusions:
– TCIA enhances open-source large language models’ performance by an average of 8.7% in task-specific applications, competing effectively with leading closed-source models without sacrificing general performance.
👉 Paper link: https://huggingface.co/papers/2508.20374
7. Mixture of Contexts for Long Video Generation
🔑 Keywords: Long video generation, Sparse attention routing, Diffusion transformers, Memory, Mixture of Contexts
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a Module, Mixture of Contexts, for efficient management of long-term memory and retrieval in diffusion transformers for long video generation.
🛠️ Research Methods:
– Implementation of a learnable sparse attention routing module that dynamically selects key informative chunks and uses causal routing to prevent loop closures.
💬 Research Conclusions:
– The Mixture of Contexts module allocates computational resources effectively, preserving important video content and enabling efficient training and synthesis with near-linear scaling.
👉 Paper link: https://huggingface.co/papers/2508.21058

8. Turning the Spell Around: Lightweight Alignment Amplification via Rank-One Safety Injection
🔑 Keywords: Rank-One Safety Injection, Large Language Models, Safety Alignment, Refusal-Mediating Subspace, White-Box Method
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance the safety alignment of Large Language Models (LLMs) by using Rank-One Safety Injection (ROSI) to amplify refusal-mediating subspace activations without the need for fine-tuning.
🛠️ Research Methods:
– ROSI applies a simple rank-one weight modification to all residual stream write matrices to steer model activations permanently towards safety directions, computed from harmful and harmless instruction pairs.
💬 Research Conclusions:
– The study shows that ROSI consistently increases safety refusal rates, as evaluated by Llama Guard 3, while maintaining the performance on benchmarks like MMLU, HellaSwag, and Arc. It also demonstrates effectiveness in re-aligning uncensored models, suggesting that targeted and interpretable weight steering is an efficient complement to fine-tuning for improving LLM safety.
👉 Paper link: https://huggingface.co/papers/2508.20766

9. CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification
🔑 Keywords: Cognition-Aligned, Vision-Language-Action, Efficiency, Instruction-driven, Sparsification
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Propose CogVLA, a Cognition-Aligned Vision-Language-Action framework, to improve efficiency and performance by reducing computational costs.
🛠️ Research Methods:
– Use a 3-stage progressive architecture with instruction-driven routing and sparsification: Encoder-FiLM based Aggregation Routing, LLM-FiLM based Pruning Routing, and V-L-A Coupled Attention for enhanced coordination between vision, language, and action.
💬 Research Conclusions:
– CogVLA achieves state-of-the-art performance with success rates of 97.4% and 70.0% on benchmarks, while significantly reducing training costs and inference latency compared to existing models.
👉 Paper link: https://huggingface.co/papers/2508.21046

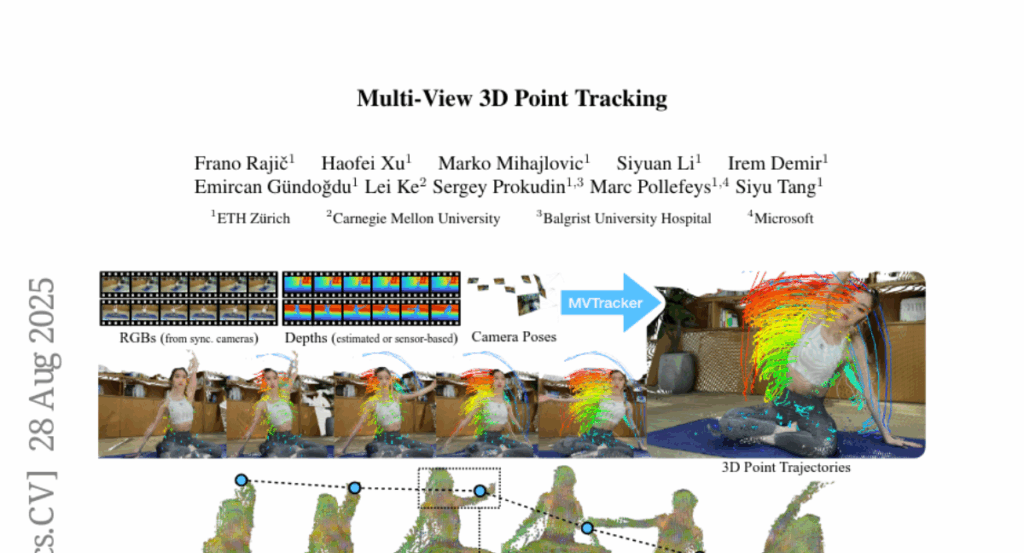
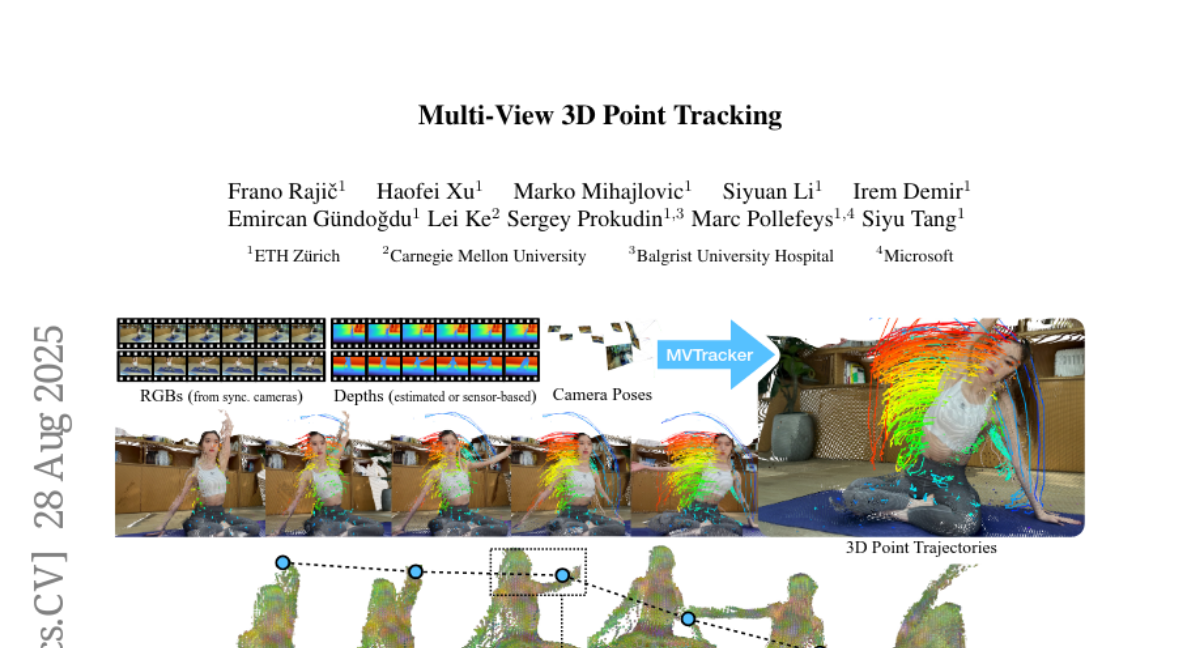
10. Multi-View 3D Point Tracking
🔑 Keywords: AI-generated summary, multi-view 3D point tracker, feed-forward model, transformer-based update, k-nearest-neighbors
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a data-driven multi-view 3D point tracker designed to efficiently track arbitrary points in dynamic scenes with fewer cameras and less optimization.
🛠️ Research Methods:
– Use a feed-forward model that integrates k-nearest-neighbors and transformer-based updates.
– Fuse multi-view features into a unified point cloud using a practical number of cameras and known camera poses.
💬 Research Conclusions:
– Achieve robust and accurate online tracking with median trajectory errors of 3.1 cm on Panoptic Studio and 2.0 cm on DexYCB.
– Generalizes well with diverse camera setups and varying video lengths, setting a new standard for multi-view 3D tracking research.
👉 Paper link: https://huggingface.co/papers/2508.21060
11. Persuasion Dynamics in LLMs: Investigating Robustness and Adaptability in Knowledge and Safety with DuET-PD
🔑 Keywords: Large Language Models, DuET-PD, Holistic DPO, Misinformation, Persuasive Dialogues
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate the performance of Large Language Models (LLMs) in persuasive dialogues, focusing on their handling of misinformation and corrective feedback.
🛠️ Research Methods:
– DuET-PD framework assesses LLMs’ ability to handle stance-change dynamics across persuasion types and domains using benchmarks like MMLU-Pro for knowledge and SALAD-Bench for safety.
– Holistic DPO is introduced as a training approach that incorporates both positive and negative persuasion examples to enhance model reliability.
💬 Research Conclusions:
– Even state-of-the-art models, like GPT-4o, show low accuracy under misleading persuasive conditions, highlighting the problem of sycophancy in recent models.
– Holistic DPO significantly improves model robustness to misinformation and receptiveness to corrections, boosting accuracy from 4.21% to 76.54% under safety context misleading persuasion.
– These contributions pave the way for developing more reliable and adaptable LLMs for multi-turn dialogues.
👉 Paper link: https://huggingface.co/papers/2508.17450

12. OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
🔑 Keywords: OneReward, vision-language model, multi-task generation, mask-guided image generation, reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce a unified reinforcement learning framework, OneReward, to enhance generative capabilities across multiple tasks without task-specific fine-tuning.
🛠️ Research Methods:
– Employ a single vision-language model as the generative reward model for multi-task generation, including sub-tasks like image fill, image extend, and text rendering.
💬 Research Conclusions:
– The unified edit model surpasses commercial and open-source alternatives in multiple evaluations, demonstrating efficient generalization without the need for task-specific supervised fine-tuning.
👉 Paper link: https://huggingface.co/papers/2508.21066

13. FakeParts: a New Family of AI-Generated DeepFakes
🔑 Keywords: FakeParts, deepfakes, detection, pixel-level, AI-generated
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce FakeParts, a new class of deepfakes with subtle, localized manipulations that are difficult to detect.
🛠️ Research Methods:
– Present FakePartsBench, a large-scale dataset with over 25K videos including pixel-level and frame-level manipulation annotations for comprehensive evaluation of detection methods.
💬 Research Conclusions:
– FakeParts reduces human and model detection accuracy by over 30% compared to traditional deepfakes, highlighting critical vulnerabilities in current detection approaches and emphasizing the need for more robust detection methods.
👉 Paper link: https://huggingface.co/papers/2508.21052

14. Dress&Dance: Dress up and Dance as You Like It – Technical Preview
🔑 Keywords: Video diffusion, Virtual try-on, CondNet, Multi-modal inputs, Attention
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop Dress&Dance, a video diffusion framework that generates high-quality, motion-accurate virtual try-on videos.
🛠️ Research Methods:
– Utilizes CondNet, a novel conditioning network, to leverage attention mechanisms and unify multi-modal inputs from text, images, and videos.
💬 Research Conclusions:
– Dress&Dance outperforms existing solutions by providing a high-quality and flexible virtual try-on experience while using a combination of limited video data and a larger image dataset.
👉 Paper link: https://huggingface.co/papers/2508.21070

15. Collaborative Multi-Modal Coding for High-Quality 3D Generation
🔑 Keywords: 3D-native generative model, Multi-modal data, RGB, RGBD, Point clouds
💡 Category: Generative Models
🌟 Research Objective:
– To present TriMM, a feed-forward 3D-native generative model that integrates multi-modal data, leveraging them to enhance 3D asset generation quality and robustness.
🛠️ Research Methods:
– Employs collaborative multi-modal coding to integrate modality-specific features while maintaining their unique strengths.
– Utilizes auxiliary 2D and 3D supervision to improve the robustness and performance of multi-modal coding.
– Implements a triplane latent diffusion model to create high-quality 3D assets.
💬 Research Conclusions:
– TriMM effectively leverages multi-modal data to achieve competitive performance with models trained on large datasets, using only a small amount of training data.
– Demonstrates the feasibility of incorporating other multi-modal datasets for 3D generation, as verified by experiments on recent RGB-D datasets.
👉 Paper link: https://huggingface.co/papers/2508.15228

16. ROSE: Remove Objects with Side Effects in Videos
🔑 Keywords: ROSE, video inpainting, diffusion transformers, synthetic data, differential masks
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces ROSE, a framework to remove objects and side effects like shadows and reflections from videos, using synthetic data and differential masks.
🛠️ Research Methods:
– The authors employ a 3D rendering engine for generating synthetic paired datasets, designed to simulate diverse scenarios with various objects and camera angles. The model utilizes diffusion transformers for video inpainting and leverages differential masks for predicting side-affected areas.
💬 Research Conclusions:
– ROSE demonstrates superior performance over existing models, effectively generalizing to real-world scenarios and offering a new benchmark, ROSE-Bench, for evaluating side effect removal in video object erasing tasks.
👉 Paper link: https://huggingface.co/papers/2508.18633

17. Provable Benefits of In-Tool Learning for Large Language Models
🔑 Keywords: Tool-augmented language models, external retrieval, factual recall, pretrained large language models, scalability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To compare the advantages of tool-augmented language models with traditional in-weight memorization for factual recall.
🛠️ Research Methods:
– Controlled experiments demonstrating the performance of tool-using models versus memorizing models; theoretical and empirical analysis of tool-use versus finetuning.
💬 Research Conclusions:
– Tool-augmented language models provide unbounded factual recall and greater scalability, demonstrating superiority over memorization approaches when handling large-scale external data.
👉 Paper link: https://huggingface.co/papers/2508.20755

18. OnGoal: Tracking and Visualizing Conversational Goals in Multi-Turn Dialogue with Large Language Models
🔑 Keywords: AI Native, LLM chat interface, goal tracking, real-time feedback, cognitive load
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The study introduces OnGoal, an LLM chat interface designed to enhance user efficiency and engagement by providing real-time feedback and visualizations focused on goal tracking during complex dialogues.
🛠️ Research Methods:
– The research includes an experimental study with 20 participants engaged in a writing task, comparing OnGoal with a baseline chat interface that lacks goal tracking capabilities.
💬 Research Conclusions:
– Results show that OnGoal reduces the time and effort needed to achieve conversational goals, helping users to explore new prompting strategies, thereby improving engagement and resilience.
– The study suggests that tracking and visualizing goals can enhance interactivity and reduce cognitive load in LLM dialogues.
👉 Paper link: https://huggingface.co/papers/2508.21061
19. Social-MAE: A Transformer-Based Multimodal Autoencoder for Face and Voice
🔑 Keywords: Social-MAE, Contrastive Audio-Visual Masked Auto-Encoder, multimodal emotion recognition, laughter recognition, in-domain self-supervised pre-training
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop Social-MAE, an advanced audiovisual model for recognizing emotions and laughter, enhancing the perception of human social behaviors.
🛠️ Research Methods:
– Extended the Contrastive Audio-Visual Masked Auto-Encoder (CAV-MAE) with a larger input frame size, trained on VoxCeleb2 dataset in a self-supervised manner, followed by finetuning for specific tasks.
💬 Research Conclusions:
– Social-MAE achieved state-of-the-art results in multimodal emotion recognition and laughter recognition, showcasing the efficiency of in-domain self-supervised pre-training.
👉 Paper link: https://huggingface.co/papers/2508.17502

20.
