AI Native Daily Paper Digest – 20250901

1. R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning
🔑 Keywords: auto-thinking, multimodal large language models, bi-mode annealing, Bi-mode Policy Optimization, reasoning-intensive benchmarks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to introduce R-4B, an auto-thinking model that adaptively determines problem-solving strategies to efficiently manage simple and complex reasoning tasks.
🛠️ Research Methods:
– R-4B is trained using a curated dataset covering both thinking and non-thinking modes, followed by a second training phase under an improved GRPO framework, which mandates response generation from both modes for every query.
💬 Research Conclusions:
– R-4B achieves state-of-the-art results across 25 benchmarks, surpassing Qwen2.5-VL-7B in most tasks and matching larger models like Kimi-VL-A3B-Thinking-2506 (16B) on reasoning-intensive benchmarks with reduced computational costs.
👉 Paper link: https://huggingface.co/papers/2508.21113

2. EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
🔑 Keywords: Multimodal Embodied Reasoning, EO-1 Model, EO-Data1.5M, Robot Control, Embodied Foundation Model
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To advance multimodal embodied reasoning and robot control through the development of EO-Robotics, which includes the EO-1 model and the EO-Data1.5M dataset.
🛠️ Research Methods:
– Introduces a unified architecture that handles multimodal inputs like images, text, video, and actions.
– Utilizes a large-scale, high-quality dataset EO-Data1.5M for pre-training, incorporating techniques like auto-regressive decoding and flow matching denoising.
💬 Research Conclusions:
– EO-1 model demonstrates superior performance in multimodal reasoning and robot control, showing effectiveness in open-world understanding and task generalization through various dexterous manipulation tasks.
👉 Paper link: https://huggingface.co/papers/2508.21112

3. A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
🔑 Keywords: large language models, security evaluation, generated code, benchmarks, repository-level
💡 Category: Generative Models
🌟 Research Objective:
– Introduce A.S.E as a benchmark to evaluate the security of code generated by large language models in real-world contexts using expert-defined rules and comprehensive repository data.
🛠️ Research Methods:
– Employ A.S.E to construct tasks with documented CVEs, preserving repository contexts like build systems and cross-file dependencies, and use a containerized evaluation framework for reproducibility and stability.
💬 Research Conclusions:
– Claude-3.7-Sonnet demonstrates the best overall performance among evaluated LLMs.
– Proprietary and open-source models have a narrow security gap, with Qwen3-235B-A22B-Instruct achieving the highest security score.
– Fast-thinking decoding strategies outperform slow-thinking reasoning in security patching.
👉 Paper link: https://huggingface.co/papers/2508.18106

4. Droplet3D: Commonsense Priors from Videos Facilitate 3D Generation
🔑 Keywords: commonsense priors, 3D asset generation, data scarcity, video modality, Droplet3D-4M
💡 Category: Generative Models
🌟 Research Objective:
– To enhance 3D asset generation by leveraging video data as commonsense priors for spatial consistency and semantic plausibility.
🛠️ Research Methods:
– Introduction of Droplet3D-4M, a large-scale video dataset with multi-view annotations.
– Development and training of Droplet3D, a generative model supporting both image and dense text input.
💬 Research Conclusions:
– The approach effectively produces spatially consistent and semantically plausible 3D content.
– Exhibits potential for extension to scene-level applications, showcasing the impact of commonsense priors from videos in 3D creation.
👉 Paper link: https://huggingface.co/papers/2508.20470

5. A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
🔑 Keywords: Sci-LLMs, data-centric synthesis, multimodal, closed-loop systems, scientific discovery
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to explore the co-evolution of Scientific Large Language Models (Sci-LLMs) with scientific data, focusing on transforming knowledge representation, integration, and application in scientific research.
🛠️ Research Methods:
– A comprehensive synthesis is provided, developing a unified taxonomy of scientific data and a hierarchical model of scientific knowledge. The study reviews over 270 datasets and examines over 190 benchmark datasets to address the challenges of multimodal, domain-specific information.
💬 Research Conclusions:
– The study concludes that there is a paradigm shift toward autonomous Sci-LLMs that enable process- and discovery-oriented assessments, facilitate cross-modal reasoning, and contribute to an evolving knowledge base, thus accelerating scientific discovery.
👉 Paper link: https://huggingface.co/papers/2508.21148

6. TalkVid: A Large-Scale Diversified Dataset for Audio-Driven Talking Head Synthesis
🔑 Keywords: Audio-driven talking head synthesis, generalization, diverse dataset, cross-dataset generalization
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance generalization across human diversity in audio-driven talking head synthesis by introducing TalkVid, a large-scale and diverse dataset.
🛠️ Research Methods:
– Researchers developed TalkVid using a multi-stage automated pipeline focusing on motion stability, aesthetic quality, and facial detail, validated against human judgments.
– A stratified evaluation set, TalkVid-Bench, was created for balanced assessment across demographics.
💬 Research Conclusions:
– Models trained on TalkVid demonstrated superior cross-dataset generalization compared to those trained on existing datasets, highlighting performance disparities across diverse subgroups.
👉 Paper link: https://huggingface.co/papers/2508.13618

7. Think in Games: Learning to Reason in Games via Reinforcement Learning with Large Language Models
🔑 Keywords: Think in Games, Procedural Knowledge, Large Language Models, Reinforcement Learning, Transparency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The main goal is to enhance Large Language Models (LLMs) by developing procedural knowledge through interactive game environments, reducing computational and data demands while maintaining transparency.
🛠️ Research Methods:
– The study introduces the Think in Games (TiG) framework, which allows LLMs to engage in game environments to develop procedural understanding by iteratively refining language-guided policies through online reinforcement learning.
💬 Research Conclusions:
– TiG effectively bridges the gap between declarative and procedural knowledge, achieving competitive performance with significantly lower data and computational demands compared to traditional RL methods, while offering step-by-step natural language explanations to improve transparency and interpretability.
👉 Paper link: https://huggingface.co/papers/2508.21365

8. TiKMiX: Take Data Influence into Dynamic Mixture for Language Model Pre-training
🔑 Keywords: Dynamic adjustment, Language model, Group Influence, Pre-training, TiKMiX
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve language model performance by dynamically adjusting the data mixture using the Group Influence metric, adapting to the model’s evolving learning preferences.
🛠️ Research Methods:
– Introduced TiKMiX, employing methods like TiKMiX-D for direct optimization and TiKMiX-M using regression models to predict optimal data mixtures.
💬 Research Conclusions:
– TiKMiX-D outperformed state-of-the-art methods like REGMIX using significantly less computational resources, while TiKMiX-M achieved an average performance gain of 2% across downstream benchmarks. Dynamic data mixture adjustment mitigates the underdigestion of data seen with static ratios, enhancing overall model performance.
👉 Paper link: https://huggingface.co/papers/2508.17677

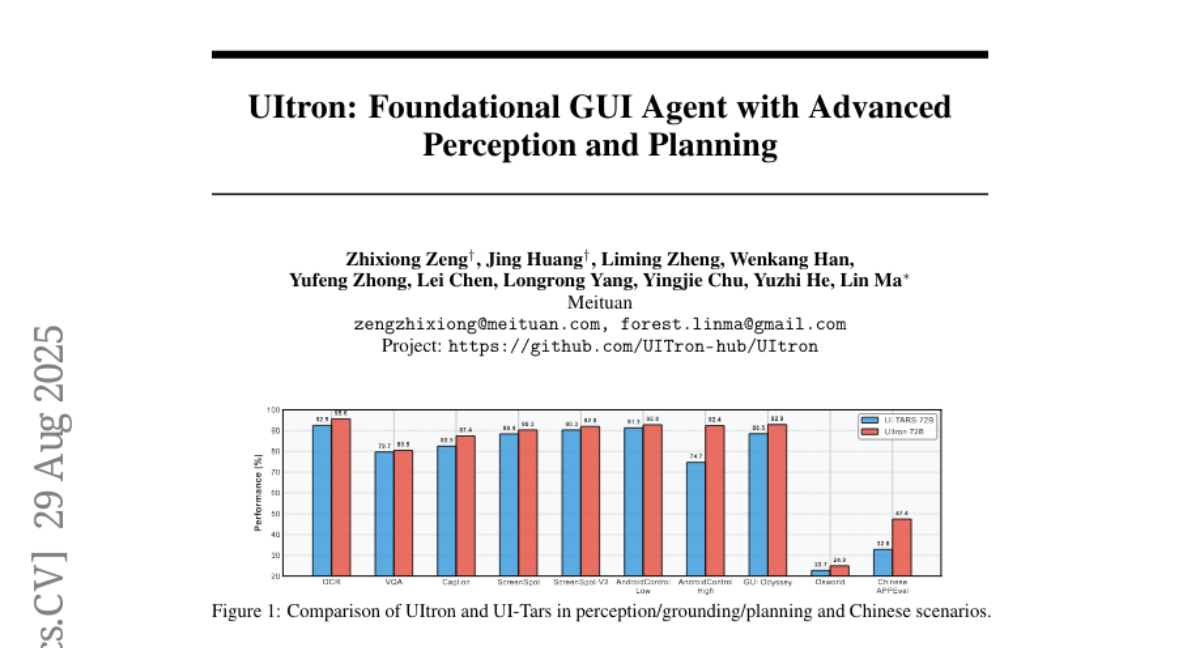
9. UItron: Foundational GUI Agent with Advanced Perception and Planning
🔑 Keywords: UItron, GUI agents, visual understanding, task planning, reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the performance and capabilities of GUI agents in visual understanding and task planning for Chinese app scenarios.
🛠️ Research Methods:
– Developed UItron, an open-source foundational model, employing advanced GUI perception, grounding, and planning capabilities while emphasizing systemic data engineering and interactive infrastructure.
– Utilized supervised finetuning and curriculum reinforcement learning to improve reasoning and exploration in various GUI environments.
💬 Research Conclusions:
– UItron achieved superior performance in benchmarks for GUI perception, grounding, and planning, particularly highlighting improved interaction proficiency with top-tier Chinese mobile apps.
– The model’s advancements bring GUI agents closer to real-world applications and address the current lack of Chinese capabilities in state-of-the-art solutions.
👉 Paper link: https://huggingface.co/papers/2508.21767
10. Efficient Code Embeddings from Code Generation Models
🔑 Keywords: Jina-code-embeddings, code retrieval, autoregressive backbone, AI-generated summary, code embedding model
💡 Category: Natural Language Processing
🌟 Research Objective:
– Jina-code-embeddings is designed to support code retrieval, question-answering, and semantic similarity identification across programming languages.
🛠️ Research Methods:
– Utilizes an autoregressive backbone pre-trained on both text and code, generating embeddings via last-token pooling.
💬 Research Conclusions:
– Demonstrates state-of-the-art performance in code embedding tasks despite the model’s relatively small size.
👉 Paper link: https://huggingface.co/papers/2508.21290

11. AHELM: A Holistic Evaluation of Audio-Language Models
🔑 Keywords: AHELM, audio-language models, fairness, reasoning, safety
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce and evaluate AHELM, a comprehensive benchmark for audio-language models (ALMs) that considers multiple aspects such as fairness, safety, and reasoning.
🛠️ Research Methods:
– Aggregated datasets, including new synthetic audio-text datasets.
– Standardization of prompts, inference parameters, and evaluation metrics for equitable model comparisons.
– Testing on 14 ALMs and 3 baseline systems to holistically measure performance across 10 identified aspects.
💬 Research Conclusions:
– AHELM provides a holistic evaluation framework for ALMs, showing that models like Gemini 2.5 Pro excel in specific aspects but may have group unfairness issues.
– Baseline systems performed reasonably well, with one ranking 5th overall.
– AHELM is intended as a living benchmark with continual updates and additions.
👉 Paper link: https://huggingface.co/papers/2508.21376

12. CLIPSym: Delving into Symmetry Detection with CLIP
🔑 Keywords: CLIP, Symmetry Detection, Rotation-Equivariant Decoder, Semantic-Aware Prompt Grouping, Vision-Language Model
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance symmetry detection using a vision-language model by leveraging CLIP and developing new techniques.
🛠️ Research Methods:
– Utilized CLIP’s image and language encoders alongside a rotation-equivariant decoder.
– Developed Semantic-Aware Prompt Grouping (SAPG) to integrate semantic cues effectively.
💬 Research Conclusions:
– CLIPSym outperforms state-of-the-art methods in symmetry detection on standard datasets like DENDI, SDRW, and LDRS.
– Validated the effectiveness of CLIP’s pre-training, equivariant decoder, and SAPG through detailed ablations.
👉 Paper link: https://huggingface.co/papers/2508.14197

13. Morae: Proactively Pausing UI Agents for User Choices
🔑 Keywords: BLV users, UI agent, decision-making, large multimodal models, mixed-initiative approach
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Introduce Morae, a UI agent designed to enhance accessibility for blind and low-vision users by involving them in decision-making processes during user interface navigation.
🛠️ Research Methods:
– Utilization of large multimodal models to interpret user queries and UI elements, allowing users to make informed decisions by pausing at identified decision points.
💬 Research Conclusions:
– Morae enabled BLV users to complete more tasks and select options aligning with their preferences better than traditional baseline agents, illustrating a successful mixed-initiative approach.
👉 Paper link: https://huggingface.co/papers/2508.21456

14. Model-Task Alignment Drives Distinct RL Outcomes
🔑 Keywords: Reinforcement Learning, Large Language Models, Model-Task Alignment, Counterintuitive Results
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to explore the application of reinforcement learning on large language models, specifically investigating counterintuitive results that depend on pre-existing model-task alignment.
🛠️ Research Methods:
– A systematic and comprehensive examination of counterintuitive claims supported by rigorous experimental validation across various model architectures and task domains.
💬 Research Conclusions:
– The study concludes that while standard RL training remains robust in challenging scenarios, many counterintuitive results in LLMs only occur when there is strong model-task alignment. In cases lacking this alignment, traditional RL methods continue to be effective.
👉 Paper link: https://huggingface.co/papers/2508.21188

15. Mimicking the Physicist’s Eye:A VLM-centric Approach for Physics Formula Discovery
🔑 Keywords: VIPER-R1, multimodal model, symbolic reasoning, Physics-based Equation Reasoning, reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to develop VIPER-R1, a multimodal model that discovers physical laws with enhanced accuracy and interpretability by combining visual perception, trajectory data, and symbolic reasoning.
🛠️ Research Methods:
– VIPER-R1 is trained through a curriculum called Motion Structure Induction, using supervised fine-tuning and aided by a Causal Chain of Thought to interpret kinematic phase portraits and construct hypotheses, followed by Reward-Guided Symbolic Calibration for formula refinement using reinforcement learning.
💬 Research Conclusions:
– VIPER-R1 outperforms state-of-the-art visual language model baselines in accuracy and interpretability, offering a more precise discovery of physical laws. It utilizes the PhysSymbol corpus for better performance and reconcilation of theoretical models with empirical data.
👉 Paper link: https://huggingface.co/papers/2508.17380

16. HERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
🔑 Keywords: HERMES, reinforcement learning, sim2real transfer, dexterous manipulation, Autonomous Systems
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a human-to-robot learning framework that translates human hand motions into robotic behaviors for versatile manipulation in diverse environments.
🛠️ Research Methods:
– Utilizing reinforcement learning and sim2real transfer, enhanced with a depth image-based method, to generalize robotic tasks to real-world scenarios.
– Employing a closed-loop Perspective-n-Point (PnP) localization mechanism to ensure precise alignment in autonomous navigation and manipulation.
💬 Research Conclusions:
– The HERMES framework demonstrates consistent generalizable behaviors across various complex bimanual dexterous manipulation tasks in diverse environments.
👉 Paper link: https://huggingface.co/papers/2508.20085

17. EduRABSA: An Education Review Dataset for Aspect-based Sentiment Analysis Tasks
🔑 Keywords: EduRABSA, ASQE-DPT, Aspect-Based Sentiment Analysis, AI-generated summary, Education Reviews
💡 Category: AI in Education
🌟 Research Objective:
– Address the lack of ABSA resources in education reviews by presenting EduRABSA, a public, annotated dataset.
🛠️ Research Methods:
– Develop ASQE-DPT, a manual data annotation tool for generating labeled datasets supporting comprehensive ABSA tasks.
💬 Research Conclusions:
– The paper introduces a novel solution to aid sentiment analysis in education by removing dataset barriers and promoting transparency and reproducibility in research.
👉 Paper link: https://huggingface.co/papers/2508.17008

18. Quantization Robustness to Input Degradations for Object Detection
🔑 Keywords: Post-training quantization, YOLO, Static INT8, TensorRT, degradation-aware calibration
💡 Category: Computer Vision
🌟 Research Objective:
– To evaluate the robustness of YOLO models against real-world degradations using post-training quantization, with a focus on a degradation-aware calibration strategy for Static INT8 quantization.
🛠️ Research Methods:
– Conducted an empirical study comparing YOLO models across various precision formats (FP32, FP16, Dynamic UINT8, and Static INT8).
– Evaluated models on the COCO dataset under seven distinct degradation conditions and a mixed-degradation scenario.
– Developed and tested a degradation-aware calibration strategy by exposing the TensorRT calibration process to both clean and synthetically degraded images.
💬 Research Conclusions:
– Static INT8 TensorRT offers substantial speed improvements but does not consistently improve robustness across most models and degradations compared to standard clean-data calibration.
– Larger model scales show potential performance improvements under specific noise conditions, indicating that model capacity may affect calibration efficacy.
– The study highlights challenges in improving PTQ robustness and offers insights for deploying quantized detectors in uncontrolled environments.
👉 Paper link: https://huggingface.co/papers/2508.19600

19. Deep Residual Echo State Networks: exploring residual orthogonal connections in untrained Recurrent Neural Networks
🔑 Keywords: Deep Residual Echo State Networks, Reservoir Computing, RNNs, Temporal Residual Connections, Long-term Temporal Modeling
💡 Category: Machine Learning
🌟 Research Objective:
– The paper introduces Deep Residual Echo State Networks (DeepResESNs) to enhance long-term temporal modeling and memory capacity through hierarchical untrained residual layers.
🛠️ Research Methods:
– The study utilizes a hierarchy of untrained residual recurrent layers, exploring different orthogonal configurations for temporal residual connections, alongside a thorough mathematical analysis for stable dynamics.
💬 Research Conclusions:
– The proposed DeepResESNs significantly outperform traditional shallow and deep Reservoir Computing methods in various time series tasks, demonstrating enhanced memory capacity and temporal modeling capabilities.
👉 Paper link: https://huggingface.co/papers/2508.21172

20.
