AI Native Daily Paper Digest – 20250917

1. WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
🔑 Keywords: AI Agents, Open-ended Deep Research, Dual-agent Framework, Adaptive Planning, Focused Synthesis
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to address the challenges of synthesizing web-scale information into insightful reports using AI agents, specifically focusing on overcoming limitations in current models for Open-ended Deep Research (OEDR).
🛠️ Research Methods:
– Introduction of a dual-agent framework named WebWeaver, which emulates the human research process by dynamically planning and optimizing evidence acquisition and synthesis to improve report quality and reliability.
💬 Research Conclusions:
– The WebWeaver framework establishes a new state-of-the-art for various OEDR benchmarks, illustrating the effectiveness of its human-centric, iterative methodology and showing that adaptive planning and focused synthesis are essential for generating high-quality reports.
👉 Paper link: https://huggingface.co/papers/2509.13312

2. Scaling Agents via Continual Pre-training
🔑 Keywords: AgentFounder, Agentic Continual Pre-training, large language models, agentic systems, tool-use ability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop an advanced agent model, AgentFounder, that excels in agentic tasks and tool-use capabilities through the integration of Agentic Continual Pre-training.
🛠️ Research Methods:
– Implementing Agentic Continual Pre-training in deep research agents to enhance agentic foundational models.
💬 Research Conclusions:
– AgentFounder achieved state-of-the-art performance on multiple benchmarks, demonstrating superior tool-use ability and multi-step reasoning in agentic tasks.
👉 Paper link: https://huggingface.co/papers/2509.13310

3. WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
🔑 Keywords: WebSailor, Systematic Uncertainty Reduction, Open-source Models, Proprietary Agents, Complex Information-Seeking Tasks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance open-source models by reducing uncertainty in complex information-seeking tasks, achieving performance comparable to proprietary agents.
🛠️ Research Methods:
– Utilized a post-training methodology, including structured sampling, information obfuscation, RFT cold start, and DUPO for agentic RL training.
💬 Research Conclusions:
– WebSailor significantly bridges the performance gap between open-source and proprietary agents in complex information-seeking benchmarks.
👉 Paper link: https://huggingface.co/papers/2509.13305

4. Towards General Agentic Intelligence via Environment Scaling
🔑 Keywords: Advanced agentic intelligence, function-calling intelligence, heterogeneous environments, two-phase agent fine-tuning, AgentScaler
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the function-calling capabilities of agents in diverse environments by scaling up these environments and improving agentic intelligence for real-world applications.
🛠️ Research Methods:
– Implementation of a scalable framework that constructs simulated heterogeneous environments, along with a two-phase fine-tuning strategy to initially build fundamental agentic capabilities, followed by specialization for domain-specific tasks.
💬 Research Conclusions:
– The trained model, AgentScaler, significantly improves the function-calling capability of models in agentic benchmarks like tau-bench, tau2-Bench, and ACEBench.
👉 Paper link: https://huggingface.co/papers/2509.13311

5. WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
🔑 Keywords: AI Agents, WebResearcher, Markov Decision Process, Data Synthesis Engine, Multi-Agent Exploration
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce WebResearcher, a framework for enhancing AI agents’ knowledge synthesis by reformulating research tasks as a Markov Decision Process.
🛠️ Research Methods:
– Utilized an iterative deep-research paradigm and a scalable data synthesis engine to produce high-quality training data and facilitate multi-agent exploration.
💬 Research Conclusions:
– WebResearcher achieves state-of-the-art performance across multiple benchmarks, surpassing proprietary systems, by addressing challenges in mono-contextual approaches and leveraging parallel thinking for comprehensive conclusions.
👉 Paper link: https://huggingface.co/papers/2509.13309

6. ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
🔑 Keywords: ReSum, web agents, Large Language Model, context summarization, reasoning states
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce ReSum, a novel paradigm that enhances web agents’ performance in knowledge-intensive tasks by addressing context window limitations through periodic context summarization.
🛠️ Research Methods:
– Implementation of ReSum-GRPO, which integrates GRPO with segmented trajectory training and advantage broadcasting for summary-conditioned reasoning.
💬 Research Conclusions:
– ReSum achieved an average absolute improvement of 4.5% over ReAct, with further gains up to 8.2% using ReSum-GRPO training.
– WebResummer-30B achieves significant performance, with 33.3% Pass@1 on BrowseComp-zh and 18.3% on BrowseComp-en surpassing existing open-source web agents.
👉 Paper link: https://huggingface.co/papers/2509.13313

7. Single-stream Policy Optimization
🔑 Keywords: Single-stream Policy Optimization, Large Language Models, Reinforcement Learning, advantage normalization, prioritized sampling
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance policy-gradient training for Large Language Models by introducing Single-stream Policy Optimization (SPO), which addresses group-based issues and improves performance and efficiency.
🛠️ Research Methods:
– Replaced per-group baselines with a KL-adaptive value tracker.
– Normalized advantages globally across batches to provide stable, low-variance learning signals.
– Implemented adaptive curriculums through prioritized sampling.
💬 Research Conclusions:
– SPO, compared to GRPO, converges more smoothly and achieves higher accuracy by effectively eliminating computation wasted on degenerate groups.
– Demonstrated significant improvements across five hard math benchmarks, achieving a higher average maj@32.
– SPO’s approach challenges the trend of added complexity in RL algorithms, emphasizing fundamental principles to advance LLM reasoning.
👉 Paper link: https://huggingface.co/papers/2509.13232

8. Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
🔑 Keywords: AI-powered, 3D assets, game development, neural modules, PBR textures
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To revolutionize the game production pipeline by automating and streamlining the creation of game-ready 3D assets with AI technology.
🛠️ Research Methods:
– Integration of advanced neural modules to transform concept images or text into optimized, high-fidelity 3D models.
💬 Research Conclusions:
– Hunyuan3D Studio significantly reduces iteration time and lowers the barrier for 3D content creation, aligning visual appeal with stringent technical engine requirements.
👉 Paper link: https://huggingface.co/papers/2509.12815

9. 3D Aware Region Prompted Vision Language Model
🔑 Keywords: SR-3D, vision-language model, region prompting, 3D positional embeddings, spatial reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To create a unified vision-language model that integrates 2D and 3D representations to facilitate flexible region prompting and accurate spatial reasoning.
🛠️ Research Methods:
– Integration of 2D visual features with 3D positional embeddings to enhance spatial reasoning capabilities across frames.
💬 Research Conclusions:
– The SR-3D model demonstrates state-of-the-art performance in unifying 2D and 3D representation space, showing effectiveness in scene understanding and applicability to in-the-wild videos without needing sensory 3D inputs or ground-truth 3D annotations.
👉 Paper link: https://huggingface.co/papers/2509.13317

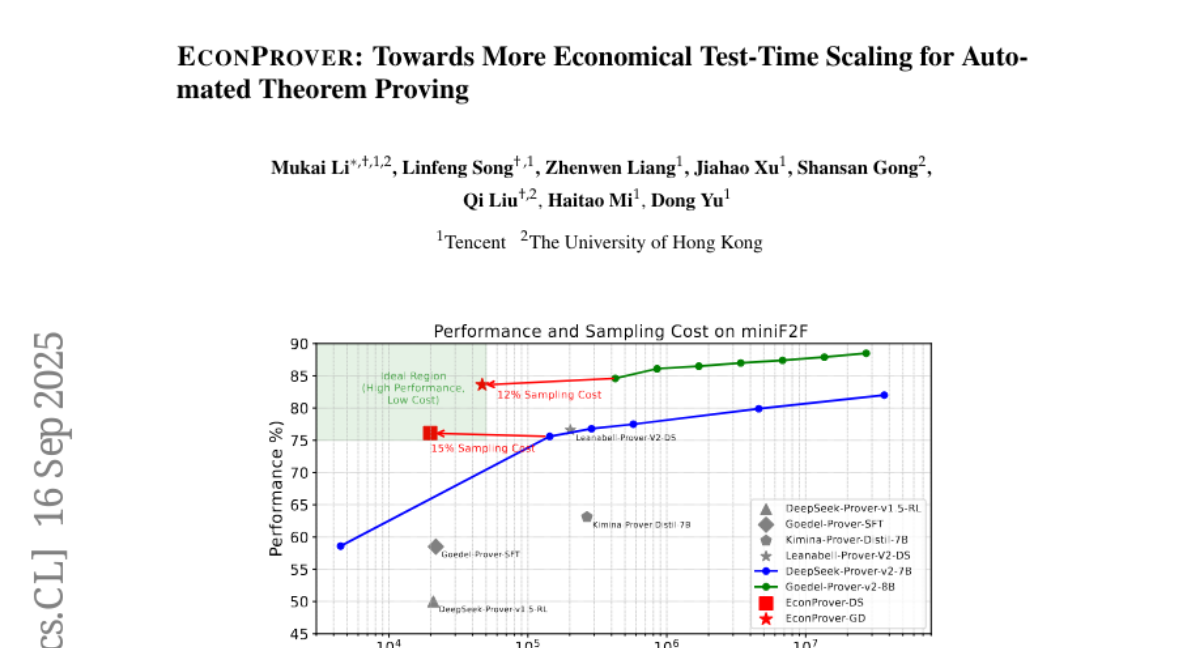
10. EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
🔑 Keywords: Chain-of-Thought (CoT), reinforcement learning (RL), token usage, EconRL, EconProver
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To reduce computational costs in Automated Theorem Proving (ATP) models while maintaining performance using two new methods.
🛠️ Research Methods:
– Implementation of dynamic Chain-of-Thought (CoT) switching and diverse parallel-scaled reinforcement learning (RL) with trainable prefixes.
💬 Research Conclusions:
– The proposed methods significantly reduce computational costs, achieving comparable performance to baseline methods with only 12% of the computational cost.
👉 Paper link: https://huggingface.co/papers/2509.12603
11. Multimodal Reasoning for Science: Technical Report and 1st Place Solution to the ICML 2025 SeePhys Challenge
🔑 Keywords: AI-generated summary, Multimodal reasoning, Textual modalities, Geometric reasoning, Caption-assisted reasoning framework
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address the gap in multimodal reasoning by introducing a caption-assisted reasoning framework that bridges visual and textual modalities effectively.
🛠️ Research Methods:
– Developed a framework that integrates visual and textual data to achieve enhanced performance in multimodal reasoning tasks like SeePhys and validated its generalization on the MathVerse benchmark.
💬 Research Conclusions:
– The caption-assisted reasoning framework proved effective, achieving top performance in the SeePhys challenge and demonstrating versatility with strong validation results on the MathVerse benchmark.
👉 Paper link: https://huggingface.co/papers/2509.06079

12. Exact Coset Sampling for Quantum Lattice Algorithms
🔑 Keywords: domain-extension, windowed-QFT, complex-Gaussian windows, CRT-coset state, modular linear relation
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– Develop a simpler and assumption-light replacement for the “domain-extension” step in a quantum lattice algorithm.
🛠️ Research Methods:
– Utilized a pair-shift difference construction to address periodicity issues and enforce modular linear relations.
💬 Research Conclusions:
– Successfully produced an exact uniform CRT-coset state using reversible unitary operations that maintain the algorithm’s asymptotic properties.
👉 Paper link: https://huggingface.co/papers/2509.12341

13. Phi: Preference Hijacking in Multi-modal Large Language Models at Inference Time
🔑 Keywords: Preference Hijacking, Multimodal Large Language Models, Safety Risk, AI-generated Summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to uncover and investigate a new safety risk in Multimodal Large Language Models (MLLMs) using a method called Preference Hijacking (Phi).
🛠️ Research Methods:
– Introduces Preference Hijacking to manipulate MLLM response preferences through optimized images, functioning at inference time without model modifications.
💬 Research Conclusions:
– Demonstrated that the method is effective across various tasks, with the code for Phi available publicly.
👉 Paper link: https://huggingface.co/papers/2509.12521

14. Stable Part Diffusion 4D: Multi-View RGB and Kinematic Parts Video Generation
🔑 Keywords: SP4D, spatial color encoding, BiDiFuse, KinematicParts20K, Objaverse XL
💡 Category: Generative Models
🌟 Research Objective:
– The objective of this research is to develop Stable Part Diffusion 4D (SP4D) for generating paired RGB and kinematic part videos from monocular inputs, improving upon conventional segmentation methods.
🛠️ Research Methods:
– Introduces a dual-branch diffusion model that combines RGB frame synthesis with part segmentation, utilizing spatial color encoding and a Bidirectional Diffusion Fusion (BiDiFuse) module.
– Constructs the KinematicParts20K dataset with more than 20,000 rigged objects to train and evaluate the SP4D framework.
💬 Research Conclusions:
– The SP4D framework demonstrates strong generalization to a variety of scenarios, effectively producing kinematic-aware outputs suitable for animation and motion-related applications.
👉 Paper link: https://huggingface.co/papers/2509.10687
15. Optimal Brain Restoration for Joint Quantization and Sparsification of LLMs
🔑 Keywords: Quantization, Pruning, Optimal Brain Restoration, Error Compensation, Speedup
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main objective is to enhance Large Language Model (LLM) compression by combining quantization and pruning techniques to overcome their individual limits and achieve better performance in terms of speed and memory utilization.
🛠️ Research Methods:
– The study introduces Optimal Brain Restoration (OBR), a general and training-free framework, which aligns quantization and pruning through error compensation utilizing a second-order Hessian objective reformulated into a tractable problem with surrogate approximation, reaching a closed-form solution via group error compensation.
💬 Research Conclusions:
– Experiments demonstrate that OBR allows aggressive W4A4KV4 quantization with 50% sparsity on existing LLMs, achieving up to 4.72x speedup and 6.4x memory reduction compared to the FP16-dense baseline.
👉 Paper link: https://huggingface.co/papers/2509.11177

16. RAPTOR: A Foundation Policy for Quadrotor Control
🔑 Keywords: RAPTOR, Meta-Imitation Learning, In-Context Learning, Zero-Shot Adaptation, Quadrotors
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a method called RAPTOR that allows a single neural network policy to adapt zero-shot to a variety of quadrotors using Meta-Imitation Learning and In-Context Learning.
🛠️ Research Methods:
– Utilization of a three-layer neural network policy with 2084 parameters for quadrotor control.
– The training process involves Meta-Imitation Learning with 1000 sampled quadrotors and the distillation of teacher policies into a single adaptive student policy.
💬 Research Conclusions:
– The RAPTOR method demonstrates effective zero-shot adaptation to unseen quadrotors across various real-world conditions and models with minimal parameters.
👉 Paper link: https://huggingface.co/papers/2509.11481
17. Multiple Instance Learning Framework with Masked Hard Instance Mining for Gigapixel Histopathology Image Analysis
🔑 Keywords: MHIM-MIL, Siamese structure, masked hard instance mining, momentum teacher, Computational Pathology
💡 Category: AI in Healthcare
🌟 Research Objective:
– To improve cancer diagnosis and subtyping accuracy using a novel MIL framework called MHIM-MIL.
🛠️ Research Methods:
– Employed a Siamese structure with a consistency constraint to explore hard instances, utilizing masked hard instance mining and a momentum teacher to train the model effectively.
💬 Research Conclusions:
– The MHIM-MIL framework outperforms existing methods in performance and efficiency, demonstrated through various cancer-related tasks and 12 benchmarks.
👉 Paper link: https://huggingface.co/papers/2509.11526

18. ROOM: A Physics-Based Continuum Robot Simulator for Photorealistic Medical Datasets Generation
🔑 Keywords: Simulation Framework, Bronchoscopy Training, AI-Generated, Multi-Modal Sensor Data, Photorealistic
💡 Category: AI in Healthcare
🌟 Research Objective:
– The objective is to create ROOM, a simulation framework to generate photorealistic bronchoscopy training data from patient CT scans for medical robotics development.
🛠️ Research Methods:
– The framework uses patient CT scans to render multi-modal sensor data, including RGB images, depth maps, and point clouds with realistic noise and light effects.
💬 Research Conclusions:
– ROOM data is validated on tasks such as multi-view pose estimation and monocular depth estimation, demonstrating challenges and enabling fine-tuning of depth estimation models for medical applications.
👉 Paper link: https://huggingface.co/papers/2509.13177
