AI Native Daily Paper Digest – 20250919
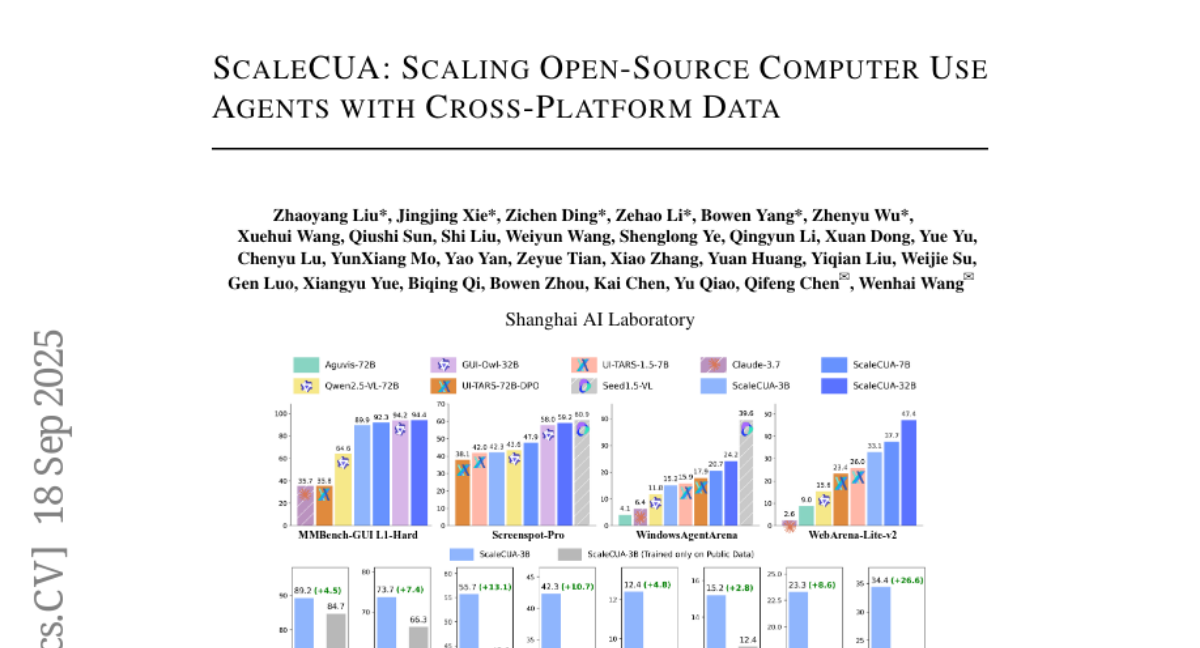
1. ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
🔑 Keywords: ScaleCUA, computer use agents, Vision-Language Models, data-driven scaling, automated agents
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce ScaleCUA, a large-scale dataset and model designed to enhance the capabilities of computer use agents across multiple platforms.
🛠️ Research Methods:
– Development of a closed-loop pipeline integrating automated agents with human expertise to compile a dataset spanning 6 operating systems and 3 task domains.
💬 Research Conclusions:
– ScaleCUA demonstrates significant improvements over baseline models, achieving state-of-the-art results across various benchmarks, indicating the effectiveness of data-driven scaling in enhancing general-purpose computer use agent performance.
👉 Paper link: https://huggingface.co/papers/2509.15221
2. FlowRL: Matching Reward Distributions for LLM Reasoning
🔑 Keywords: FlowRL, reward distribution, flow balancing, diverse exploration, generalizable reasoning trajectories
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces FlowRL, aiming to enhance LLM reinforcement learning by matching the full reward distribution instead of only maximizing rewards, thereby increasing diversity and performance.
🛠️ Research Methods:
– The research employs flow-balanced optimization by transforming scalar rewards into a normalized target distribution using a learnable partition function, minimizing the reverse KL divergence between the policy and this distribution.
💬 Research Conclusions:
– FlowRL demonstrates significant improvements in math and code reasoning tasks, outperforming traditional methods like GRPO and PPO, illustrating the effectiveness of reward distribution-matching for diverse exploration in reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2509.15207

3. Reasoning over Boundaries: Enhancing Specification Alignment via Test-time Delibration
🔑 Keywords: Large language models, specification alignment, Test-Time Deliberation, SpecBench, safety-helpfulness trade-off
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance specification alignment in large language models across diverse scenarios by using a lightweight method called Align3.
🛠️ Research Methods:
– Employing Test-Time Deliberation with hierarchical reflection and revision to reason over specification boundaries; introducing SpecBench as a benchmark for measuring effectiveness in five scenarios.
💬 Research Conclusions:
– Test-Time Deliberation improves specification alignment; Align3 advances the safety-helpfulness trade-off with minimal overhead; SpecBench effectively identifies alignment gaps.
👉 Paper link: https://huggingface.co/papers/2509.14760

4. Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
🔑 Keywords: EVOL-RL, Reinforcement Learning, entropy collapse, generalization, label-free
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a reinforcement learning method (EVOL-RL) for large language models that balances stability and variation in a label-free setting to enhance exploration capacity and generalization.
🛠️ Research Methods:
– Implementation of EVOL-RL using a mechanism that keeps majority-voted answers as a stable anchor while introducing novelty-aware rewards for differing reasoning. Utilizes asymmetric clipping and an entropy regularizer to maintain signal strength and support exploration.
💬 Research Conclusions:
– EVOL-RL prevents entropy collapse, supports longer and more informative reasoning chains, and consistently outperforms baseline methods such as TTRL. It also improves performance in RLVR settings, indicating its broad applicability.
👉 Paper link: https://huggingface.co/papers/2509.15194

5. FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
🔑 Keywords: FinSearchComp, Financial Search, Knowledge-Grounded Reasoning, LLM-based agents, AI Native
💡 Category: AI in Finance
🌟 Research Objective:
– To introduce FinSearchComp, the first open-source benchmark specifically designed for evaluating financial search and reasoning capabilities of end-to-end agents in realistic, open-domain contexts.
🛠️ Research Methods:
– Three realistic tasks were designed: Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation.
– The benchmark involves annotation from 70 professional financial experts and includes rigorous multi-stage quality-assurance.
– Evaluation of 21 models across global and Greater China market questions to test performance.
💬 Research Conclusions:
– FinSearchComp closely aligns with real-world financial analyst workflows and provides a high-difficulty testbed for financial search and reasoning.
– Experimental results indicate that integrating web search and financial plugins enhances model performance.
– Notable performance variations based on the country origin of the models and tools, with Grok 4 (web) leading globally and DouBao (web) excelling in the Greater China subset.
👉 Paper link: https://huggingface.co/papers/2509.13160

6. Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
🔑 Keywords: Self-guided Training, AutoRegressive models, self-supervised objectives, visual semantics, FID improvement
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to enhance image understanding and generation quality in autoregressive models by addressing key visual semantics challenges through self-supervised objectives.
🛠️ Research Methods:
– A systematic investigation into the application of the next-token prediction paradigm in the visual domain, identifying three key hindrances: local and conditional dependence, inter-step semantic inconsistency, and spatial invariance deficiency.
– Introduction of a novel training framework, Self-guided Training for AutoRegressive models (ST-AR), to tackle these issues without pre-trained representation models.
💬 Research Conclusions:
– ST-AR significantly enhances the image understanding ability of autoregressive models, yielding approximately 42% FID improvement for LlamaGen-L and 49% FID improvement for LlamaGen-XL, while maintaining consistent sampling strategies.
👉 Paper link: https://huggingface.co/papers/2509.15185

7. RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
🔑 Keywords: Vision-Language-Action, Two-Stage Pretraining, Ego-Centric, ActionVAE, Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To propose RynnVLA-001, a vision-language-action model, for improved robotics task performance through a novel two-stage pretraining approach.
🛠️ Research Methods:
– Utilization of a two-stage pretraining methodology: Ego-Centric Video Generative Pretraining and Human-Centric Trajectory-Aware Modeling.
– Development of ActionVAE to compress action sequences into latent embeddings, enhancing the action representation.
💬 Research Conclusions:
– RynnVLA-001 outperforms state-of-the-art baselines when finetuned on robotics datasets, validating the effectiveness of the novel pretraining strategy for vision-language-action models.
👉 Paper link: https://huggingface.co/papers/2509.15212

8. AToken: A Unified Tokenizer for Vision
🔑 Keywords: AToken, Unified Visual Tokenizer, 4D Transformer Architecture, Adversarial-Free Training, Multimodal AI
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To achieve high-fidelity reconstruction and semantic understanding across images, videos, and 3D assets through a unified framework.
🛠️ Research Methods:
– Introducing a 4D transformer architecture with 4D rotary position embeddings and adversarial-free training using perceptual and Gram matrix losses.
💬 Research Conclusions:
– AToken delivers high reconstruction quality and competitive performance in visual generation and understanding tasks, paving the way for next-gen multimodal AI systems.
👉 Paper link: https://huggingface.co/papers/2509.14476

9. WorldForge: Unlocking Emergent 3D/4D Generation in Video Diffusion Model via Training-Free Guidance
🔑 Keywords: WorldForge, video diffusion models, generative priors, trajectory injection, photorealistic content generation
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to enhance the controllability and geometric consistency of video diffusion models without retraining by introducing a training-free framework called WorldForge.
🛠️ Research Methods:
– The WorldForge framework comprises three modules: Intra-Step Recursive Refinement for trajectory injection, Flow-Gated Latent Fusion for motion decoupling, and Dual-Path Self-Corrective Guidance to correct trajectory drift.
💬 Research Conclusions:
– Extensive experiments validate the framework’s superiority in realism, trajectory consistency, and visual fidelity, offering a novel plug-and-play paradigm for controllable video synthesis.
👉 Paper link: https://huggingface.co/papers/2509.15130

10. RecoWorld: Building Simulated Environments for Agentic Recommender Systems
🔑 Keywords: RecoWorld, Agentic Recommender Systems, Dual-View Architecture, Multi-Turn RL, User Retention
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Develop a blueprint for simulated environments tailored to agentic recommender systems to enhance user retention and engagement.
🛠️ Research Methods:
– Utilize a dual-view architecture with simulated user and agent interactions, leveraging LLMs and multi-turn reinforcement learning.
– Explore diverse content representations and multi-agent simulations to refine strategies and simulate user population responses.
💬 Research Conclusions:
– Introduce dynamic feedback loops that actively engage users, improving the interaction between users and agentic recommenders.
– Envision new paradigms of user-recommender interaction to collaboratively optimize personalized information streams.
👉 Paper link: https://huggingface.co/papers/2509.10397

11. Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
🔑 Keywords: Apertus, Large Language Models, Data Compliance, Multilingual Representation, Goldfish Objective
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Apertus, a suite of open large language models addressing data compliance and multilingual representation.
🛠️ Research Methods:
– Pretraining exclusively on openly available data respecting content-owner rights, and employing the Goldfish Objective to mitigate memorization risks.
💬 Research Conclusions:
– Apertus models achieve state-of-the-art results on multilingual benchmarks with extensive multilingual coverage, and offer transparency by releasing scientific artifacts and development tools under a permissive license.
👉 Paper link: https://huggingface.co/papers/2509.14233

12. MultiEdit: Advancing Instruction-based Image Editing on Diverse and Challenging Tasks
🔑 Keywords: MultiEdit, instruction-based image editing, multi-modal large language models, dataset construction, style transfer
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to address the limitations of current instruction-based image editing methods by introducing MultiEdit, a comprehensive dataset with over 107K high-quality image editing samples.
🛠️ Research Methods:
– Utilization of a novel dataset construction pipeline employing two multi-modal large language models (MLLMs) to generate visual-adaptive editing instructions and produce high-fidelity edited images.
💬 Research Conclusions:
– Fine-tuning foundational open-source models with the MultiEdit-Train set leads to substantial improvement in performance on sophisticated editing tasks, while preserving capabilities on standard editing benchmarks. MultiEdit serves as a valuable resource for advancing research on diverse and challenging instruction-based image editing capabilities.
👉 Paper link: https://huggingface.co/papers/2509.14638

13. EdiVal-Agent: An Object-Centric Framework for Automated, Scalable, Fine-Grained Evaluation of Multi-Turn Editing
🔑 Keywords: AI-generated summary, EdiVal-Agent, VLMs, instruction-based image editing, human preference models
💡 Category: Computer Vision
🌟 Research Objective:
– The main aim is to introduce EdiVal-Agent, an automated framework for evaluating instruction-based image editing, focusing on instruction following, content consistency, and visual quality.
🛠️ Research Methods:
– EdiVal-Agent utilizes vision-language models (VLMs), object detectors, semantic-level feature extractors, and human preference models to assess and evaluate image editing tasks.
💬 Research Conclusions:
– The integration of VLMs and object detectors provides a better alignment with human judgments compared to using VLMs alone. The modular framework facilitates the seamless addition of future tools, ensuring progressive improvement in evaluation accuracy.
👉 Paper link: https://huggingface.co/papers/2509.13399

14. Unleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding
🔑 Keywords: zero-shot, multimodal large language models, spatio-temporal video grounding, decomposed spatio-temporal highlighting, temporal-augmented assembling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main goal is to utilize multimodal large language models for a zero-shot solution in spatio-temporal video grounding (STVG).
🛠️ Research Methods:
– The proposed framework includes a decomposed spatio-temporal highlighting (DSTH) strategy and a temporal-augmented assembling (TAS) strategy to enhance MLLM’s reasoning capabilities.
💬 Research Conclusions:
– The proposed method outperforms state-of-the-art methods on three common STVG benchmarks, demonstrating improved grounding accuracy and temporal consistency.
👉 Paper link: https://huggingface.co/papers/2509.15178

15. Agentic Software Engineering: Foundational Pillars and a Research Roadmap
🔑 Keywords: Agentic Software Engineering, SE 3.0, Human-AI Collaboration, Agent Command Environment, Agent Execution Environment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Present the vision of Structured Agentic Software Engineering (SASE) by redefining software engineering with a dual modality approach that integrates human and intelligent agent collaboration to accomplish complex, goal-oriented tasks.
🛠️ Research Methods:
– Propose two workbenches: the Agent Command Environment (ACE) for human orchestration of agents and the Agent Execution Environment (AEE) where agents perform tasks, involving a bidirectional partnership to redefine processes and tools.
💬 Research Conclusions:
– Establishes a conceptual framework for future software engineering, encouraging a shift from traditional human-centric methods to a balanced, scalable, and trustworthy agentic approach, outlining key challenges and opportunities for further exploration.
👉 Paper link: https://huggingface.co/papers/2509.06216

16. Can Multimodal LLMs See Materials Clearly? A Multimodal Benchmark on Materials Characterization
🔑 Keywords: MatCha, multimodal large language models, materials characterization, benchmark, MLLMs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary goal of the research is to introduce MatCha, the first benchmark aimed at evaluating the capability of multimodal large language models in understanding materials characterization images.
🛠️ Research Methods:
– MatCha comprises 1,500 questions reflecting real challenges in materials science, evaluating models across four key stages and 21 tasks that require expert-level domain expertise.
💬 Research Conclusions:
– State-of-the-art MLLMs currently show significant performance limitations compared to human experts, struggling with tasks needing high-level expertise and sophisticated visual perception, highlighting the need for advancement in real-world applicability.
👉 Paper link: https://huggingface.co/papers/2509.09307

17. Mind the Gap: A Closer Look at Tokenization for Multiple-Choice Question Answering with LLMs
🔑 Keywords: Tokenization, Large Language Models, Model Calibration, Evaluation Protocols
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the impact of tokenization strategies on the accuracy and calibration of large language models (LLMs) in multiple-choice question answering.
🛠️ Research Methods:
– Analyzing variations in tokenization, specifically the space following “Answer:”, to measure differences in model accuracy and rankings.
💬 Research Conclusions:
– Tokenizing the space together with the answer letter leads to significant improvements in LLM accuracy and calibration, emphasizing the need for standardized evaluation protocols.
👉 Paper link: https://huggingface.co/papers/2509.15020

18. EchoVLM: Dynamic Mixture-of-Experts Vision-Language Model for Universal Ultrasound Intelligence
🔑 Keywords: EchoVLM, Vision-language models, Mixture of Experts, Ultrasound report generation, Diagnosis
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research aims to improve ultrasound report generation and diagnostic accuracy using a vision-language model called EchoVLM, tailored for ultrasound medical imaging.
🛠️ Research Methods:
– EchoVLM employs a Mixture of Experts architecture and is trained on data from seven anatomical regions, enabling tasks such as report generation, diagnosis, and visual question-answering.
💬 Research Conclusions:
– EchoVLM significantly outperforms existing models like Qwen2-VL, indicated by remarkable improvements in BLEU-1 and ROUGE-1 scores, suggesting its potential to enhance diagnostic accuracy in clinical settings.
👉 Paper link: https://huggingface.co/papers/2509.14977

19. FSG-Net: Frequency-Spatial Synergistic Gated Network for High-Resolution Remote Sensing Change Detection
🔑 Keywords: FSG-Net, change detection, false alarms, semantic gap
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance change detection accuracy in high-resolution remote sensing images by addressing false alarms and the semantic gap.
🛠️ Research Methods:
– Utilizes a Frequency-Spatial Synergistic approach with a Discrepancy-Aware Wavelet Interaction Module (DAWIM) and Synergistic Temporal-Spatial Attention Module (STSAM) for refining features.
– Integrates a Lightweight Gated Fusion Unit (LGFU) for effective merging of semantic features and details.
💬 Research Conclusions:
– FSG-Net establishes a new state-of-the-art in change detection with high F1-scores across multiple benchmarks, proving its effectiveness in overcoming the identified challenges.
👉 Paper link: https://huggingface.co/papers/2509.06482

20. Developer-LLM Conversations: An Empirical Study of Interactions and Generated Code Quality
🔑 Keywords: Developer-LLM Conversations, Large Language Models (LLMs), Code Quality, Multi-turn Conversations
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To investigate how developers interact with Large Language Models (LLMs) and the implications of these interactions on task outcomes, code quality, and software engineering workflows.
🛠️ Research Methods:
– Analysis of developer-LLM conversations using the CodeChat dataset, which includes 82,845 conversations with 368,506 code snippets across more than 20 programming languages.
💬 Research Conclusions:
– The study identifies that LLM responses are typically much longer than developer prompts, and multi-turn conversations make up 68% of interactions.
– Frequent LLM-assisted tasks are in areas like web design and neural network training.
– There are prevalent language-specific issues in LLM-generated code, such as undefined variables in Python and JavaScript, missing comments in Java, omitted headers in C++, and unresolved namespaces in C#.
– Addressing syntax and import errors improves over multiple conversational turns, with notable improvements in documentation and import handling when errors are explicitly pointed out and corrections requested.
👉 Paper link: https://huggingface.co/papers/2509.10402

21.
