AI Native Daily Paper Digest – 20250929
1. LongLive: Real-time Interactive Long Video Generation
🔑 Keywords: Long video generation, Causal attention, KV-recache, Interactive capabilities, INT8-quantized inference
💡 Category: Generative Models
🌟 Research Objective:
– To develop LongLive, a frame-level autoregressive framework for efficient and high-quality real-time and interactive long video generation.
🛠️ Research Methods:
– Implementation of causal attention, KV-recache mechanism, streaming long tuning, and short window attention to address efficiency and quality challenges in long video generation.
💬 Research Conclusions:
– LongLive achieves real-time generation of up to 240-second videos with strong performance on VBench and supports INT8-quantized inference with minimal quality loss.
👉 Paper link: https://huggingface.co/papers/2509.22622

2. Quantile Advantage Estimation for Entropy-Safe Reasoning
🔑 Keywords: Quantile Advantage Estimation, reinforcement learning, entropy issues, baseline design, large language models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to stabilize reinforcement learning with verifiable rewards by addressing entropy issues and improving performance on large language models through Quantile Advantage Estimation (QAE).
🛠️ Research Methods:
– The study proposes replacing the mean baseline in value-free RL with a group-wise K-quantile baseline to address entropy collapse and explosion by implementing a two-regime gate using QAE.
💬 Research Conclusions:
– Quantile Advantage Estimation (QAE) stabilizes entropy and provides consistent performance improvements (pass@1 gains) for large language models like Qwen3-8B/14B-Base, demonstrating the effectiveness of baseline design in scaling RLVR.
👉 Paper link: https://huggingface.co/papers/2509.22611

3. MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
🔑 Keywords: MinerU2.5, document parsing, vision-language model, computational efficiency, state-of-the-art performance
💡 Category: Computer Vision
🌟 Research Objective:
– MinerU2.5 aims to achieve state-of-the-art recognition accuracy in document parsing while maintaining computational efficiency.
🛠️ Research Methods:
– A coarse-to-fine, two-stage parsing strategy is implemented, separating global layout analysis from local content recognition.
– Utilization of a comprehensive data engine to generate diverse, large-scale training corpora for pretraining and fine-tuning.
💬 Research Conclusions:
– MinerU2.5 demonstrates superior document parsing ability, surpassing general-purpose and domain-specific models across various recognition tasks, and maintaining significantly lower computational overhead.
👉 Paper link: https://huggingface.co/papers/2509.22186

4. EPO: Entropy-regularized Policy Optimization for LLM Agents Reinforcement Learning
🔑 Keywords: Entropy-regularized Policy Optimization, Reinforcement Learning, Exploration-Exploitation, Entropy Regularization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to address the exploration-exploitation challenges in multi-turn environments with sparse rewards, particularly focusing on the failure mode of cascade failure during policy training.
🛠️ Research Methods:
– The research introduces the Entropy-regularized Policy Optimization (EPO) framework, which includes mechanisms such as entropy regularization in multi-turn settings, an entropy smoothing regularizer to maintain stability, and adaptive phase-based weighting to balance exploration and exploitation.
💬 Research Conclusions:
– EPO ensures decreasing entropy variance while maintaining convergence, significantly improving performance in ScienceWorld and ALFWorld environments. It emphasizes the need for specific entropy control mechanisms in multi-turn settings for effective reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2509.22576

5. ReviewScore: Misinformed Peer Review Detection with Large Language Models
🔑 Keywords: Peer review, ReviewScore, Automated engine, LLMs, Factuality
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to develop an automated engine to evaluate the factuality of review points in AI conference papers, identifying misinformed review weaknesses and questions.
🛠️ Research Methods:
– Implementation of an engine that reconstructs premises from reviews and development of a ReviewScore dataset with human expert annotations to measure human-model agreements using state-of-the-art LLMs.
💬 Research Conclusions:
– Moderate agreement between human experts and automated evaluations was observed, with premise-level factual evaluations showing higher accuracy than weakness-level evaluations.
👉 Paper link: https://huggingface.co/papers/2509.21679

6. Variational Reasoning for Language Models
🔑 Keywords: Variational Reasoning Framework, Latent Variables, Variational Inference, Model Accuracy, RL-style Methods
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces a variational reasoning framework for language models, treating thinking traces as latent variables to optimize reasoning abilities.
🛠️ Research Methods:
– The framework extends the evidence lower bound (ELBO) to a multi-trace objective for tighter bounds and employs a forward-KL formulation for stable training.
– It utilizes rejection sampling finetuning and binary-reward RL, including GRPO, as local forward-KL objectives to address bias towards easier questions.
💬 Research Conclusions:
– Empirical validation on Qwen 2.5 and Qwen 3 models demonstrates improved reasoning across various tasks, unifying variational inference with RL-style methods.
👉 Paper link: https://huggingface.co/papers/2509.22637

7. Language Models Can Learn from Verbal Feedback Without Scalar Rewards
🔑 Keywords: Feedback-conditional policy, LLMs, verbal feedback, conditional generation, reward optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the expressiveness of LLMs by treating verbal feedback as a conditioning signal instead of scalar rewards.
🛠️ Research Methods:
– Introduced Feedback-conditional policy (FCP) which learns from response-feedback pairs and maximizes likelihood training on offline data.
– Developed an online bootstrapping stage for policy refinement with fresh feedback generation.
💬 Research Conclusions:
– FCP reframes feedback-driven learning as conditional generation, offering a more expressive learning method for LLMs from verbal feedback.
👉 Paper link: https://huggingface.co/papers/2509.22638

8. CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Image Captioning, Large Vision-Language Models, Supervised Fine-Tuning, Multiple-Choice Questions
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance image captioning by addressing the limitations of Supervised Fine-Tuning. It introduces CapRL, a framework using Reinforcement Learning with Verifiable Rewards to improve caption diversity and creativity.
🛠️ Research Methods:
– CapRL leverages a novel two-stage pipeline: an LVLM generates captions, and a vision-free language model evaluates them through Multiple-Choice Questions to derive an objective reward for quality.
💬 Research Conclusions:
– CapRL significantly boosts performance in image captioning across 12 benchmarks, showing gains in both diversity and quality. It matches performance with advanced models like Qwen2.5-VL-72B and surpasses baseline by 8.4%.
👉 Paper link: https://huggingface.co/papers/2509.22647

9. No Prompt Left Behind: Exploiting Zero-Variance Prompts in LLM Reinforcement Learning via Entropy-Guided Advantage Shaping
🔑 Keywords: Reinforcement Learning, Zero-Variance Prompts, Large Language Models, Policy Optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The main objective is to improve the accuracy and pass rate of Large Language Models in math reasoning tasks using a novel algorithm called RL-ZVP.
🛠️ Research Methods:
– RL-ZVP leverages zero-variance prompts to extract learning signals, directly rewards correctness, and penalizes errors without needing contrasting responses.
💬 Research Conclusions:
– RL-ZVP outperforms existing methods like GRPO by up to 8.61 points in accuracy and 7.77 points in pass rate, illustrating the potential of zero-variance prompts in reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2509.21880

10. MesaTask: Towards Task-Driven Tabletop Scene Generation via 3D Spatial Reasoning
🔑 Keywords: MesaTask, Spatial Reasoning Chain, LLM-based framework, DPO algorithms
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces the concept of task-oriented tabletop scene generation to address the challenge of aligning task instructions with realistic scene layouts.
🛠️ Research Methods:
– The proposed method, MesaTask, employs a Spatial Reasoning Chain to break down the scene generation process into object inference, spatial interrelation reasoning, and scene graph construction, using a large-scale dataset (MesaTask-10K) enhanced with DPO algorithms.
💬 Research Conclusions:
– MesaTask outperforms baseline methods in generating realistic and task-conforming tabletop scenes, demonstrating its effectiveness through comprehensive experiments.
👉 Paper link: https://huggingface.co/papers/2509.22281

11. PromptCoT 2.0: Scaling Prompt Synthesis for Large Language Model Reasoning
🔑 Keywords: PromptCoT 2.0, Synthetic Prompts, Self-Play, Supervised Fine-Tuning, Reasoning Capabilities
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance reasoning capabilities in large language models by generating harder and more diverse synthetic prompts through an expectation-maximization (EM) loop.
🛠️ Research Methods:
– Implemented a scalable framework integrating self-play and supervised fine-tuning using synthetic prompts, refined through an iterative EM loop.
💬 Research Conclusions:
– PromptCoT 2.0 significantly improves the performance of language models, demonstrated by state-of-the-art results across several benchmark tests and highlighting its potential as a scalable foundation for future open-source models.
👉 Paper link: https://huggingface.co/papers/2509.19894

12. UltraHorizon: Benchmarking Agent Capabilities in Ultra Long-Horizon Scenarios
🔑 Keywords: UltraHorizon, long-horizon, sustained reasoning, planning, tool use
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce UltraHorizon, a new benchmark designed to evaluate autonomous agents on long-horizon and partially observable tasks, focusing on sustained reasoning, planning, memory, and tool use.
🛠️ Research Methods:
– Utilized exploration tasks across three environments, with varying complexity, to assess agents’ abilities in discovery tasks requiring iterative problem-solving.
💬 Research Conclusions:
– LLM-agents underperformed in long-horizon scenarios compared to human participants, highlighting a need for improvements in agents’ capabilities, as simple scaling was ineffective.
– Identified error types attributed to in-context locking and fundamental capability gaps in agents.
👉 Paper link: https://huggingface.co/papers/2509.21766

13. COSPADI: Compressing LLMs via Calibration-Guided Sparse Dictionary Learning
🔑 Keywords: CoSpaDi, structured sparse dictionary learning, large language models, compression, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces CoSpaDi, a training-free compression framework aimed at improving the accuracy and efficiency of large language models by employing structured sparse dictionary learning instead of low-rank methods.
🛠️ Research Methods:
– CoSpaDi replaces low-rank decomposition with structured sparse factorization, utilizing a dense dictionary and column-sparse coefficient matrix for better expressiveness and accuracy.
– It leverages a small calibration dataset for optimizing factorization, which minimizes functional reconstruction error without fine-tuning.
💬 Research Conclusions:
– CoSpaDi demonstrates its superiority over state-of-the-art low-rank methods in accuracy and perplexity across several models, supporting structured sparse dictionary learning as a powerful alternative for efficient language model deployment.
👉 Paper link: https://huggingface.co/papers/2509.22075

14. VoiceAssistant-Eval: Benchmarking AI Assistants across Listening, Speaking, and Viewing
🔑 Keywords: VoiceAssistant-Eval, AI assistants, multimodal systems, open-source models, listening
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to create a comprehensive benchmark called VoiceAssistant-Eval to evaluate AI assistants across listening, speaking, and viewing tasks.
🛠️ Research Methods:
– The study evaluates 21 open-source models and GPT-4o-Audio using 10,497 curated examples in 13 task categories to measure response content and speech quality and consistency.
💬 Research Conclusions:
– Proprietary models do not always outperform open-source models; many models excel at speaking tasks but struggle with audio understanding; smaller models can be highly effective, with Step-Audio-2-mini outperforming larger models in listening accuracy.
👉 Paper link: https://huggingface.co/papers/2509.22651

15. LucidFlux: Caption-Free Universal Image Restoration via a Large-Scale Diffusion Transformer
🔑 Keywords: LucidFlux, diffusion transformer, SigLIP features, universal image restoration
💡 Category: Computer Vision
🌟 Research Objective:
– The primary goal is to achieve robust universal image restoration (UIR) without the use of text prompts, through a novel framework called LucidFlux.
🛠️ Research Methods:
– Introduction of LucidFlux, a caption-free framework that leverages a diffusion transformer for image restoration, incorporating a lightweight dual-branch conditioner, and a timestep- and layer-adaptive modulation schedule.
💬 Research Conclusions:
– LucidFlux consistently outperforms existing open-source and commercial baselines in image restoration tasks, demonstrating the importance of when, where, and what to condition on for effective restoration without relying on additional parameters or captions.
👉 Paper link: https://huggingface.co/papers/2509.22414

16. See, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation
🔑 Keywords: AI-generated summary, vision-language models, 2D spatial grounding, UAVs, closed-loop control
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To present a training-free aerial vision-and-language navigation framework, See, Point, Fly (SPF), aimed at outperforming existing methods in both simulations and real-world evaluations.
🛠️ Research Methods:
– Utilizing vision-language models (VLMs) to decompose language instructions into 2D waypoints and transforming these into 3D displacement vectors for UAV action commands.
– Implementing closed-loop control for dynamic environments.
💬 Research Conclusions:
– SPF significantly outperforms previous state-of-the-art methods by a large margin in both DRL simulation benchmarks and real-world evaluations, and demonstrates remarkable generalization across different VLMs.
👉 Paper link: https://huggingface.co/papers/2509.22653
17. Mind-the-Glitch: Visual Correspondence for Detecting Inconsistencies in Subject-Driven Generation
🔑 Keywords: diffusion models, semantic features, Visual Semantic Matching (VSM), visual inconsistencies, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– Proposing a novel approach for disentangling visual and semantic features from diffusion model backbones to quantify and localize visual inconsistencies in subject-driven image generation.
🛠️ Research Methods:
– Introduced an automated pipeline to construct image pairs with annotated correspondences and designed a contrastive architecture to separate visual and semantic features.
💬 Research Conclusions:
– The proposed method outperforms existing global feature-based metrics such as CLIP and DINO in quantifying visual inconsistencies and supports spatial localization of these inconsistencies, offering a valuable tool for subject-driven image generation.
👉 Paper link: https://huggingface.co/papers/2509.21989
18. SPARK: Synergistic Policy And Reward Co-Evolving Framework
🔑 Keywords: SPARK, Reinforcement Learning, Generative Reward Model, Large Language Models, Policy Gradients
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce SPARK, a framework that enhances LLMs and LVLMs by recycling rollouts and correctness data to train a generative reward model, thus reducing dependence on human preferences and separate reward models.
🛠️ Research Methods:
– SPARK uses on-policy training strategies incorporating pointwise reward scoring, pairwise comparison, and self-reflection to co-evolve policy and reward models simultaneously.
💬 Research Conclusions:
– SPARK achieves significant performance gains on several benchmarks, including a 9.7% improvement on reasoning benchmarks, demonstrating its robustness and effectiveness.
👉 Paper link: https://huggingface.co/papers/2509.22624

19. WebGen-Agent: Enhancing Interactive Website Generation with Multi-Level Feedback and Step-Level Reinforcement Learning
🔑 Keywords: WebGen-Agent, visual feedback, GUI-agent testing, Step-GRPO, large language models
💡 Category: Generative Models
🌟 Research Objective:
– To enhance website code generation by integrating visual feedback and GUI-agent testing to improve accuracy and appearance scores.
🛠️ Research Methods:
– Utilization of a novel agent, WebGen-Agent, which implements comprehensive visual feedback and a backtracking mechanism to iteratively refine code.
– Integration of Step-GRPO with screenshot and GUI-agent feedback to improve reasoning capabilities of language models at each step.
💬 Research Conclusions:
– WebGen-Agent significantly increases the accuracy and appearance scores of existing systems, outperforming previous state-of-the-art agent systems.
👉 Paper link: https://huggingface.co/papers/2509.22644

20. Think-on-Graph 3.0: Efficient and Adaptive LLM Reasoning on Heterogeneous Graphs via Multi-Agent Dual-Evolving Context Retrieval
🔑 Keywords: Large Language Models, Multi-Agent System, Retrieval-Augmented Generation, Graph-based RAG, Evolving Query
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces ToG-3, aiming to enhance LLMs with external knowledge using a dynamic and multi-agent framework to improve evidence retrieval and reasoning.
🛠️ Research Methods:
– Employs a Multi-Agent Context Evolution and Retrieval (MACER) mechanism using a dynamic, evolving heterogeneous graph index for precise retrieval and reasoning. The multi-agent system includes Constructor, Retriever, Reflector, and Responser agents collaborating iteratively.
💬 Research Conclusions:
– ToG-3 outperforms traditional methods by enabling adaptive construction of targeted graph indexes, allowing for deeper and more precise reasoning. Experiments and ablation studies confirm the superiority of the framework across various reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2509.21710

21. TUN3D: Towards Real-World Scene Understanding from Unposed Images
🔑 Keywords: TUN3D, Layout estimation, 3D object detection, Indoor scene understanding, Sparse-convolutional backbone
💡 Category: Computer Vision
🌟 Research Objective:
– The objective of the study is to develop a method, TUN3D, for joint layout estimation and 3D object detection using multi-view images, which does not require depth sensors or ground-truth camera poses, to improve indoor scene understanding.
🛠️ Research Methods:
– TUN3D uses a lightweight sparse-convolutional backbone and implements two dedicated heads: one for 3D object detection and another for layout estimation, utilizing a novel parametric wall representation to enhance performance.
💬 Research Conclusions:
– TUN3D achieves state-of-the-art performance on various indoor scene understanding benchmarks, advancing layout estimation and setting a new standard in holistic understanding without needing specialized sensors.
👉 Paper link: https://huggingface.co/papers/2509.21388

22. Fine-tuning Done Right in Model Editing
🔑 Keywords: Fine-tuning, Model Editing, Depth-first Pipeline, Breadth-first Pipeline, LocFT-BF
💡 Category: Natural Language Processing
🌟 Research Objective:
– To challenge the belief that fine-tuning is ineffective for model editing and propose improvements using a breadth-first pipeline with mini-batch optimization.
🛠️ Research Methods:
– Conduct controlled experiments restoring fine-tuning to a standard breadth-first pipeline and analyzing localized tuning parameter locations to develop the LocFT-BF method.
💬 Research Conclusions:
– LocFT-BF significantly outperforms state-of-the-art model editing methods, supporting up to 100K edits and large 72B-parameter models without sacrificing general capabilities, establishing fine-tuning as a solid foundation for future model editing research.
👉 Paper link: https://huggingface.co/papers/2509.22072

23. Chasing the Tail: Effective Rubric-based Reward Modeling for Large Language Model Post-Training
🔑 Keywords: Reinforcement Fine-Tuning, Reward Over-Optimization, Rubric-Based Rewards, High-Reward Tail
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to mitigate reward over-optimization in reinforcement fine-tuning by utilizing rubric-based rewards that leverage off-policy examples while maintaining reward reliability.
🛠️ Research Methods:
– The researchers conducted a theoretical analysis of reward misspecification and developed a workflow to distinguish between diverse responses in the high-reward region using rubric-based rewards.
💬 Research Conclusions:
– Rubric-based rewards effectively reduce reward over-optimization and enhance the post-training performance of language models.
👉 Paper link: https://huggingface.co/papers/2509.21500

24. UniVid: Unifying Vision Tasks with Pre-trained Video Generation Models
🔑 Keywords: UniVid, Video Diffusion Transformer, Cross-Modal Inference, Visual Sentences, Cross-Source Tasks
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to explore whether a pre-trained video generation model can be fine-tuned to handle diverse image and video tasks without needing task-specific modifications.
🛠️ Research Methods:
– UniVid, a video diffusion transformer, is fine-tuned and evaluated for its ability to generalize across cross-modal inference and cross-source tasks. Tasks are organized using visual sentences, and the model’s performance is assessed without multi-source pre-training.
💬 Research Conclusions:
– UniVid demonstrates impressive generalization capabilities across different settings, handling both understanding and generation tasks by adjusting visual sentence orders. This highlights the potential for scalable vision modeling using pre-trained video generation models.
👉 Paper link: https://huggingface.co/papers/2509.21760

25. D-Artemis: A Deliberative Cognitive Framework for Mobile GUI Multi-Agents
🔑 Keywords: D-Artemis, GUI automation, Multimodal large language models, Thinking and Reflection, State-of-the-Art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance GUI automation using a novel framework, D-Artemis, by addressing challenges such as data bottlenecks, high costs of error detection, and contradictory guidance.
🛠️ Research Methods:
– D-Artemis is developed based on the human cognitive loop of Thinking, Alignment, and Reflection, incorporating a fine-grained, app-specific tip retrieval mechanism and proactive alignment strategies.
💬 Research Conclusions:
– D-Artemis establishes new state-of-the-art results in major benchmarks, achieving a 75.8% success rate on AndroidWorld and 96.8% on ScreenSpot-V2, demonstrating superior generalization without relying on complex trajectory datasets.
👉 Paper link: https://huggingface.co/papers/2509.21799

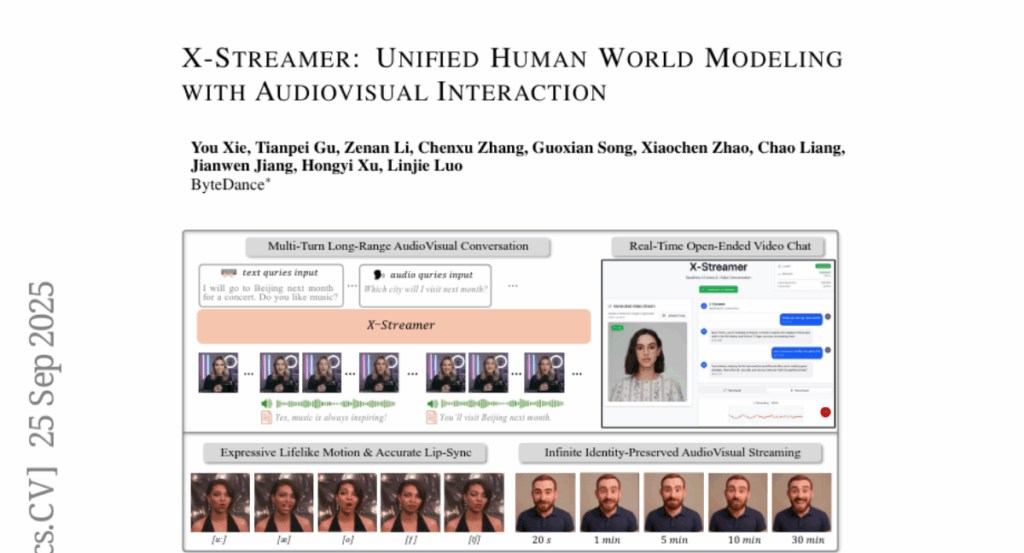
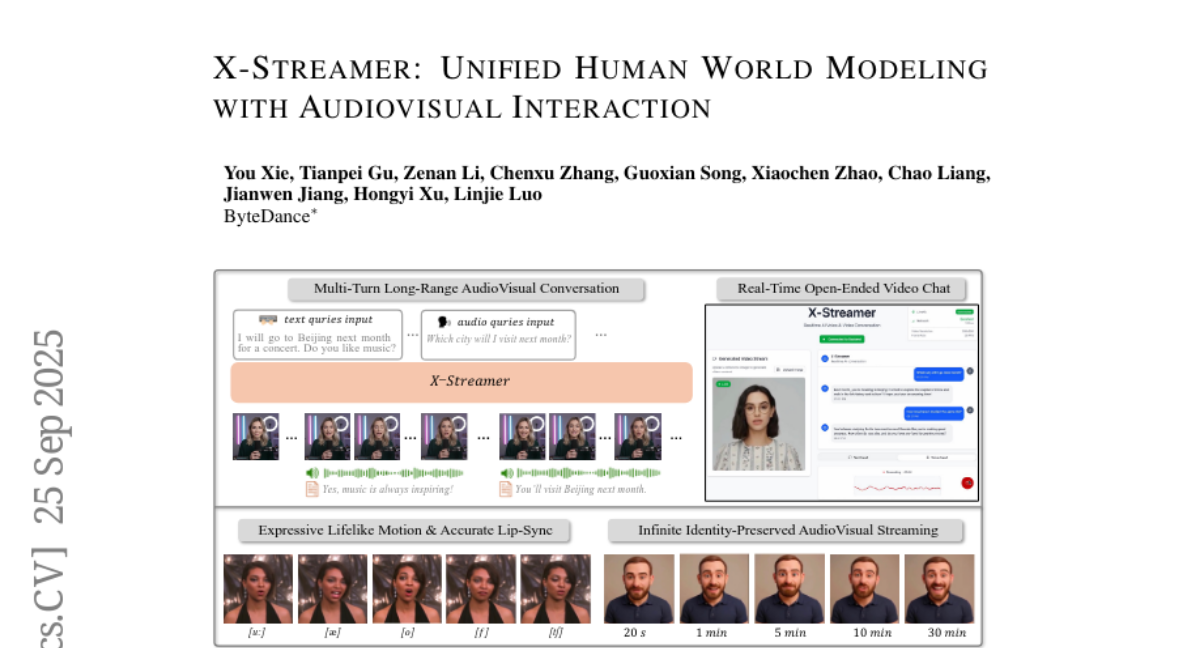
26. X-Streamer: Unified Human World Modeling with Audiovisual Interaction
🔑 Keywords: multimodal framework, dual-transformer architecture, AI-generated, large language-speech models, autoregressive diffusion models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The introduction of X-Streamer to provide a unified multimodal framework for real-time, open-ended interactions across text, speech, and video.
🛠️ Research Methods:
– Utilization of a Thinker-Actor dual-transformer architecture, incorporating pretrained large language-speech models and autoregressive diffusion models for synchronized multimodal responses.
💬 Research Conclusions:
– X-Streamer achieves consistent, real-time interactions from static portraits using only two A100 GPUs, enhancing the potential for interactive digital human modeling.
👉 Paper link: https://huggingface.co/papers/2509.21574
27. Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Exploration-Exploitation Trade-off, Curriculum-based Self-imitation Learning, Intrinsic Rewards, Entropy Control
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to manage the exploration-exploitation balance in reinforcement learning for large language models (LLMs) by implementing a curriculum-based self-imitation learning method, named SPEAR, that incorporates intrinsic rewards and trajectory-level entropy control.
🛠️ Research Methods:
– SPEAR extends the vanilla self-imitation learning framework by storing self-generated promising trajectories in a replay buffer for off-policy updates and steering policy evolution with controlled entropy. The use of intrinsic rewards fosters skill and action-level exploration, while self-imitation is enhanced to leverage successful patterns without unbounding entropy growth.
💬 Research Conclusions:
– The proposed approach successfully balances progressive exploration and exploitation under agent’s own experiences, curbing policy drift and over-confidence, thus stabilizing training and accelerating solution iteration.
👉 Paper link: https://huggingface.co/papers/2509.22601
