AI Native Daily Paper Digest – 20251002

1. DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search
🔑 Keywords: RLVR, DeepSearch, Monte Carlo Tree Search, AI-generated Summary, Systematic Exploration
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to integrate Monte Carlo Tree Search into RLVR training to enhance exploration and credit assignment, achieving state-of-the-art performance with reduced computational cost.
🛠️ Research Methods:
– DeepSearch embeds structured search into the RLVR training loop for systematic exploration and credit assignment.
– Strategies include global frontier selection, entropy-based guidance, and adaptive replay buffer training with solution caching.
💬 Research Conclusions:
– DeepSearch achieves a 62.95% average accuracy on mathematical reasoning benchmarks, using 5.7x fewer GPU hours than extended training approaches.
– Highlights the importance of strategic exploration over brute-force scaling, establishing a new direction for advancing RLVR methodologies through systematic search.
👉 Paper link: https://huggingface.co/papers/2509.25454

2. VLA-RFT: Vision-Language-Action Reinforcement Fine-tuning with Verified Rewards in World Simulators
🔑 Keywords: AI Native, Vision-Language-Action, Reinforcement Learning, World Model, Robustness
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a reinforcement fine-tuning framework, VLA-RFT, that enhances the efficiency and robustness of Vision-Language-Action models using a data-driven world model.
🛠️ Research Methods:
– Utilization of a controllable simulator trained from real interaction data to predict future visual observations, thus allowing efficient policy rollouts with trajectory-level rewards.
💬 Research Conclusions:
– VLA-RFT significantly reduces sample requirements and surpasses strong supervised baselines. It demonstrates improved generalization and robustness, especially under perturbed conditions, establishing it as a practical post-training paradigm.
👉 Paper link: https://huggingface.co/papers/2510.00406

3. GEM: A Gym for Agentic LLMs
🔑 Keywords: GEM, experience-based learning, reinforcement learning, large language models, environment simulator
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce GEM, an open-source environment simulator, to support the shift from static datasets to experience-based learning for large language models.
🛠️ Research Methods:
– Developed GEM to provide a standardized framework for environment-agent interfaces, featuring diverse environments, asynchronous execution, flexible wrappers, and benchmarking capabilities.
💬 Research Conclusions:
– GEM serves as both a training and evaluation tool, demonstrating improved compatibility and performance in reinforcement learning settings and aiding in the acceleration of agentic LLM research.
👉 Paper link: https://huggingface.co/papers/2510.01051

4. Knapsack RL: Unlocking Exploration of LLMs via Optimizing Budget Allocation
🔑 Keywords: Large Language Models, Reinforcement Learning, Exploration Budget Allocation, Knapsack Problem, Mathematical Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve training efficiency and performance of Large Language Models on mathematical reasoning benchmarks through adaptive exploration budget allocation.
🛠️ Research Methods:
– Utilized a knapsack problem approach to adaptively distribute exploration resources during training for Group Relative Policy Optimization.
💬 Research Conclusions:
– The proposed method increases non-zero policy gradients by 20-40% and achieves significant improvements in benchmarks with smaller computational resources.
👉 Paper link: https://huggingface.co/papers/2509.25849

5. PIPer: On-Device Environment Setup via Online Reinforcement Learning
🔑 Keywords: Environment setup, Reinforcement Learning with Verifiable Rewards, supervised fine-tuning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary goal is to improve the automated environment setup process in Software Engineering using a specialized model.
🛠️ Research Methods:
– The study combines supervised fine-tuning to generate correct Bash scripts with Reinforcement Learning with Verifiable Rewards (RLVR) to enhance the model’s capability.
💬 Research Conclusions:
– The proposed method enables the Qwen3-8B model to perform competitively with larger models for automated environment setup tasks.
👉 Paper link: https://huggingface.co/papers/2509.25455

6. SINQ: Sinkhorn-Normalized Quantization for Calibration-Free Low-Precision LLM Weights
🔑 Keywords: Post-training quantization, large language models, perplexity, second-axis scale factor, Sinkhorn-Knopp-style algorithm
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary aim is to enhance post-training quantization of large language models at low precision by introducing a second-axis scale factor and a Sinkhorn-Knopp-style algorithm to minimize matrix imbalance and improve perplexity.
🛠️ Research Methods:
– Employing an additional second-axis scale factor and a fast Sinkhorn-Knopp-style algorithm to normalize variances per-row and per-column, focusing on minimizing matrix imbalance as a quantization target.
– The method is applied without layer interactions across architectures to linear layers in models like Qwen3 and DeepSeek-V2.5.
💬 Research Conclusions:
– The SINQ method significantly improves perplexity on datasets like WikiText2 and C4 compared to uncalibrated uniform quantization baselines.
– The performance can be further augmented by combining the method with calibration and non-uniform quantization levels.
👉 Paper link: https://huggingface.co/papers/2509.22944

7. ACON: Optimizing Context Compression for Long-horizon LLM Agents
🔑 Keywords: Agent Context Optimization, Large Language Models, Context Compression, Long-horizon Tasks, Distillation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The aim is to introduce Agent Context Optimization (ACON) as a framework to efficiently compress context in large language models for long-horizon tasks.
🛠️ Research Methods:
– ACON analyzes failure cases when context is compressed and refines the compression guidelines. It distills the optimized large language model compressor into smaller models.
💬 Research Conclusions:
– ACON reduces memory usage by 26-54% while maintaining task performance and achieves over 95% accuracy when distilled to smaller compressors. It enhances smaller language models as long-horizon agents, improving performance by up to 46%.
👉 Paper link: https://huggingface.co/papers/2510.00615

8. Code2Video: A Code-centric Paradigm for Educational Video Generation
🔑 Keywords: Code2Video, AI-generated summary, Code-centric agent framework, Vision-language models, TeachQuiz
💡 Category: AI in Education
🌟 Research Objective:
– This study aims to address the limitations of current generative models in creating professional educational videos by proposing a new framework, Code2Video, which utilizes executable Python code for generating coherent and interpretable educational content.
🛠️ Research Methods:
– The research introduces a code-centric agent framework involving three agents: Planner, Coder, and Critic, which collaborate to convert structured instructions into educational videos.
– The framework is evaluated through a new benchmark, MMMC, assessing various dimensions including VLM-as-a-Judge aesthetic scores and code efficiency.
💬 Research Conclusions:
– Results indicate that Code2Video offers a scalable, interpretable, and controllable method for educational video production, achieving a 40% improvement over direct code generation methods.
– The generated videos are shown to be comparable to those crafted by humans, suggesting significant potential for future educational applications.
👉 Paper link: https://huggingface.co/papers/2510.01174

9. It Takes Two: Your GRPO Is Secretly DPO
🔑 Keywords: Group Relative Policy Optimization, Large Language Models, Contrastive Learning, Direct Preference Optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to reframe Group Relative Policy Optimization (GRPO) as contrastive learning to connect it with Direct Preference Optimization (DPO) and streamline the training efficiency of Large Language Models.
🛠️ Research Methods:
– The study involves a theoretical analysis and empirical evaluation of the minimal two-rollout case (2-GRPO) to prove its viability compared to larger group sizes.
💬 Research Conclusions:
– The minimal two-rollout GRPO (2-GRPO) achieves performance comparable to 16-GRPO while significantly reducing computational costs and training time by over 70%.
👉 Paper link: https://huggingface.co/papers/2510.00977

10. Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls
🔑 Keywords: Implicit Chain-of-Thought, Long-Range Dependencies, Attention, Directed Acyclic Graph, Inductive Bias
💡 Category: Natural Language Processing
🌟 Research Objective:
– To understand why language models struggle with multi-digit multiplication by reverse-engineering a model that learns via implicit chain-of-thought.
🛠️ Research Methods:
– Used logit attributions and linear probes to study long-range dependencies.
– Explored the mechanism of attention to construct directed acyclic graphs for efficient multiplication representation.
– Implemented partial product representation using attention heads, Minkowski sums, and Fourier basis.
💬 Research Conclusions:
– Identified that standard models lack the required long-range dependencies for multiplication.
– Showed that an auxiliary loss introducing a running sum prediction can enable successful learning of multi-digit multiplication by establishing the correct inductive bias.
👉 Paper link: https://huggingface.co/papers/2510.00184

11. BiasFreeBench: a Benchmark for Mitigating Bias in Large Language Model Responses
🔑 Keywords: BiasFreeBench, bias mitigation, large language models, Bias-Free Score, Natural Language Processing
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The study introduces BiasFreeBench, a benchmark designed to evaluate bias mitigation techniques in large language models using a unified approach.
🛠️ Research Methods:
– Evaluates eight bias mitigation techniques across two scenarios using a unified query-response setting, complemented by a new response-level metric called Bias-Free Score.
💬 Research Conclusions:
– By analyzing systematic comparisons of debiasing performances, the study aims to establish a unified testbed for future bias mitigation research.
👉 Paper link: https://huggingface.co/papers/2510.00232

12. EditReward: A Human-Aligned Reward Model for Instruction-Guided Image Editing
🔑 Keywords: reward model, human preference dataset, instruction-guided image editing, reinforcement learning, state-of-the-art performance
💡 Category: Generative Models
🌟 Research Objective:
– To improve instruction-guided image editing by developing a new reward model that enhances the selection of high-quality training data.
🛠️ Research Methods:
– Utilized a large-scale human preference dataset with over 200K preference pairs, annotated by experts, to train the new reward model (mname), achieving superior alignment with human preferences.
💬 Research Conclusions:
– The reward model \mname demonstrates state-of-the-art human correlation on benchmarks, facilitating improved quality in synthetic training data. It also shows potential for applications in reinforcement learning-based post-training and test-time scaling.
👉 Paper link: https://huggingface.co/papers/2509.26346

13. Flash-Searcher: Fast and Effective Web Agents via DAG-Based Parallel Execution
🔑 Keywords: Flash-Searcher, parallel agent reasoning, directed acyclic graphs, concurrent execution, dynamic workflow optimization
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Flash-Searcher, a novel parallel agent reasoning framework that shifts from sequential processing to directed acyclic graphs to enhance efficiency and performance in complex reasoning tasks.
🛠️ Research Methods:
– Utilize a framework that decomposes complex tasks into subtasks with explicit dependencies, allowing for concurrent execution and dynamic workflow optimization, continuously refining the execution graph based on intermediate results.
💬 Research Conclusions:
– Comprehensive evaluations show Flash-Searcher outperforms existing frameworks with up to 35% reduction in agent execution steps and significant accuracy improvements, highlighting its scalability and generalizability across diverse architectures.
👉 Paper link: https://huggingface.co/papers/2509.25301

14. QUASAR: Quantum Assembly Code Generation Using Tool-Augmented LLMs via Agentic RL
🔑 Keywords: QUASAR, Reinforcement Learning, Large Language Models, Quantum Circuits, Quantum Circuit Verification
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– The study aims to address the challenges in quantum circuit generation and optimization using a reinforcement learning framework augmented with tools to imbue LLMs with quantum domain-specific knowledge for higher validity in generated quantum circuits.
🛠️ Research Methods:
– The QUASAR framework employs a quantum circuit verification approach utilizing external quantum simulators, alongside a hierarchical reward mechanism during reinforcement learning training to enhance LLM’s performance in generating precise quantum circuits.
💬 Research Conclusions:
– QUASAR significantly improves the validity of quantum circuits, achieving a 99.31% Pass@1 and 100% Pass@10, surpassing several industrial LLMs like GPT-4o, GPT-5, and DeepSeek-V3, as well as various baselines involving supervised fine-tuning and RL-only methods.
👉 Paper link: https://huggingface.co/papers/2510.00967

15. BroRL: Scaling Reinforcement Learning via Broadened Exploration
🔑 Keywords: reinforcement learning, rollouts, language models, exploration, correct-mass expansion
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reinforcement learning by increasing rollouts per example for overcoming performance plateaus in large language models.
🛠️ Research Methods:
– Investigated the effect of increasing the number of rollouts per example, using a mass balance equation analysis and simulations under relaxed conditions.
💬 Research Conclusions:
– BroRL achieves continuous performance improvement and state-of-the-art results, proving effective at reviving saturated models and expanding the correct probability mass.
👉 Paper link: https://huggingface.co/papers/2510.01180

16. Beyond Log Likelihood: Probability-Based Objectives for Supervised Fine-Tuning across the Model Capability Continuum
🔑 Keywords: probability-based objectives, negative log likelihood, large language models, model-capability continuum, prior-leaning objectives
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research investigates probability-based objectives that potentially outperform negative log likelihood when fine-tuning large language models, depending on their capabilities.
🛠️ Research Methods:
– Comprehensive experiments and extensive ablation studies were conducted across 7 model backbones, 14 benchmarks, and 3 domains to examine different objectives.
💬 Research Conclusions:
– Findings indicate that prior-leaning objectives outperform NLL near the model-strong end, NLL dominates the model-weak end, and no single objective prevails in between; theoretical analysis provides groundwork for adapting objectives based on model capability.
👉 Paper link: https://huggingface.co/papers/2510.00526

17. Making, not Taking, the Best of N
🔑 Keywords: Fusion-of-N, LLM judge, test-time scaling, synthetic data generation
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to improve LLM generation quality by using a collaborative approach, Fusion-of-N, instead of the traditional selection method Best-of-N.
🛠️ Research Methods:
– The study employs FusioN to synthesize elements from multiple LLM samples using a general LLM judge and compares its effectiveness against BoN in test-time scaling and synthetic data generation across multiple languages, tasks, and model scales.
💬 Research Conclusions:
– FusioN consistently outperforms BoN, demonstrating versatility and robustness, and highlights the benefits of harnessing diverse data sources for more robust LLM generations.
👉 Paper link: https://huggingface.co/papers/2510.00931

18. On Predictability of Reinforcement Learning Dynamics for Large Language Models
🔑 Keywords: Large Language Models, Reinforcement Learning, Parameter Updates, AlphaRL, AI Native
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to identify fundamental properties of reinforcement learning-induced parameter updates in large language models to develop a framework that accelerates training.
🛠️ Research Methods:
– Analysis of the parameter dynamics of reinforcement learning in LLMs, identifying Rank-1 Dominance and Rank-1 Linear Dynamics, validated through experiments across multiple LLMs and algorithms.
💬 Research Conclusions:
– The proposed AlphaRL framework significantly speeds up training with a 2.5x acceleration while maintaining over 96% of reasoning performance without requiring additional modules or hyperparameter adjustments.
👉 Paper link: https://huggingface.co/papers/2510.00553

19. Infusing Theory of Mind into Socially Intelligent LLM Agents
🔑 Keywords: Theory of Mind, LLMs, Dialogue, Strategic Reasoning, Goal Achievement
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance dialogue effectiveness and goal achievement by integrating Theory of Mind into large language models (LLMs).
🛠️ Research Methods:
– The introduction of ToMA, a Theory of Mind-focused dialogue agent, trained with dialogue lookahead to produce useful mental states for dialogue goals.
💬 Research Conclusions:
– ToMA demonstrates improved strategic, goal-oriented reasoning and better partner relationships, marking a step forward in building socially intelligent LLM agents.
👉 Paper link: https://huggingface.co/papers/2509.22887

20. Training Vision-Language Process Reward Models for Test-Time Scaling in Multimodal Reasoning: Key Insights and Lessons Learned
🔑 Keywords: Vision-Language Models, Process Reward Models, hybrid data synthesis, perception-focused supervision, test-time scaling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This research explores the design space of Vision-Language Process Reward Models (VL-PRMs) to enhance their reliability in guiding Vision-Language Models (VLMs) across diverse multimodal benchmarks.
🛠️ Research Methods:
– The study introduces a hybrid data synthesis framework combining Monte Carlo Tree Search (MCTS) with strong VLM judgments.
– It proposes perception-focused supervision to improve error detection at the visual grounding stage.
💬 Research Conclusions:
– Smaller VL-PRMs can match or surpass larger ones in error detection.
– Perception-level supervision significantly boosts test-time scaling performance.
– VL-PRMs reveal latent reasoning abilities in stronger VLM backbones and enhance TTS performance even on advanced datasets.
👉 Paper link: https://huggingface.co/papers/2509.23250

21. MixtureVitae: Open Web-Scale Pretraining Dataset With High Quality Instruction and Reasoning Data Built from Permissive-First Text Sources
🔑 Keywords: MixtureVitae, Pretraining Corpus, Risk-Mitigated Sourcing, License-Aware Filtering, Language Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce MixtureVitae, an open-access pretraining corpus that enhances model performance while minimizing legal risks.
🛠️ Research Methods:
– Employ a risk-mitigated sourcing strategy combining public-domain and permissively licensed texts.
– Implement a multi-stage pipeline for license-aware filtering, safety, and quality screening.
💬 Research Conclusions:
– Models trained on MixtureVitae outperform other permissive datasets across benchmarks.
– MixtureVitae excels particularly in math/code tasks and is competitive in QA tasks.
– The approach offers a legally sound method for training large language models without heavy reliance on indiscriminate web scraping.
👉 Paper link: https://huggingface.co/papers/2509.25531

22. GUI-KV: Efficient GUI Agents via KV Cache with Spatio-Temporal Awareness
🔑 Keywords: GUI agents, KV cache compression, spatial redundancy, temporal redundancy, attention patterns
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to improve the efficiency of GUI agents by exploiting spatial and temporal redundancies in key-value (KV) cache compression without sacrificing accuracy.
🛠️ Research Methods:
– The study analyzes attention patterns in GUI agent workloads, discovering uniform attention sparsity across transformer layers, and introduces GUI-KV, a plug-and-play KV cache compression method involving spatial saliency guidance and temporal redundancy scoring, bypassing the need for retraining.
💬 Research Conclusions:
– GUI-KV outperforms existing KV compression baselines, maintaining high accuracy while significantly reducing computational demands in GUI agent benchmarks, demonstrating the utility of exploiting GUI-specific redundancies.
👉 Paper link: https://huggingface.co/papers/2510.00536

23. JoyAgent-JDGenie: Technical Report on the GAIA
🔑 Keywords: Generalist agent architecture, Multi-agent planning, Hierarchical memory, System-level integration, AI assistants
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a generalist agent architecture that outperforms existing systems in diverse real-world tasks by integrating multi-agent planning, hierarchical memory, and a refined tool suite.
🛠️ Research Methods:
– The architecture incorporates a multi-agent framework with planning and execution agents, a hierarchical memory system, and a refined tool suite for various functions such as search and code execution.
💬 Research Conclusions:
– The proposed framework consistently outperforms open-source baselines and competes with proprietary systems, showcasing the importance of system-level integration for scalable and adaptive AI assistants.
👉 Paper link: https://huggingface.co/papers/2510.00510

24. Pay-Per-Search Models are Abstention Models
🔑 Keywords: Selective Help-seeking, Reinforcement Learning, Parametric Knowledge Boundaries, LLMs, Knowledge-intensive QA datasets
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance LLMs’ abilities in selective help-seeking and abstention without the need for pre-determined knowledge boundaries.
🛠️ Research Methods:
– Utilization of MASH framework with reinforcement learning that penalizes external help (search tool use) while rewarding answer accuracy, applied on knowledge-intensive QA datasets.
💬 Research Conclusions:
– MASH significantly improves selective help-seeking performance, notably enhancing answer accuracy by 7.6% on multi-hop datasets. It also provides strong off-the-shelf abstention capabilities akin to specialized methods, without needing pre-determined knowledge boundaries.
👉 Paper link: https://huggingface.co/papers/2510.01152

25. An Empirical Study of Testing Practices in Open Source AI Agent Frameworks and Agentic Applications
🔑 Keywords: AI agents, non-determinism, testing practices, Foundation model, non-reproducibility
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to identify testing practices in AI agent frameworks and applications, focusing on the challenge of non-determinism and non-reproducibility.
🛠️ Research Methods:
– Conducted a large-scale empirical study analyzing 39 open-source agent frameworks and 439 agentic applications to identify testing patterns.
💬 Research Conclusions:
– Identified a fundamental inversion of testing effort, with over 70% focused on deterministic components like Resource Artifacts and Coordination Artifacts, while FM-based Plan Body testing is neglected.
– The Trigger component remains critically under-tested, appearing in just 1% of tests.
– For more robust AI agents, novel testing methods and prompt regression testing should be improved and adopted.
👉 Paper link: https://huggingface.co/papers/2509.19185

26. In-Place Feedback: A New Paradigm for Guiding LLMs in Multi-Turn Reasoning
🔑 Keywords: In-place feedback, Large language models, Multi-turn reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce and evaluate in-place feedback as a novel interaction paradigm for improving LLM responses in multi-turn reasoning tasks.
🛠️ Research Methods:
– Conducted empirical evaluations on diverse reasoning-intensive benchmarks and controlled environments.
💬 Research Conclusions:
– In-place feedback offers improved model performance and efficiency, using 79.1% fewer tokens compared to conventional methods, and effectively addresses feedback integration weaknesses in existing paradigms.
👉 Paper link: https://huggingface.co/papers/2510.00777

27. CurES: From Gradient Analysis to Efficient Curriculum Learning for Reasoning LLMs
🔑 Keywords: Reinforcement Learning, Large Language Models, Prompt Selection, Rollout Allocation, Convergence
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve training efficiency in large language models through optimized prompt selection and rollout allocation using reinforcement learning.
🛠️ Research Methods:
– Theoretical analysis of training prompts and rollout quantity distribution, employing Bayesian posterior estimation to enhance convergence and reduce computational overhead.
💬 Research Conclusions:
– The proposed CurES method outperforms Group Relative Policy Optimization by significantly improving convergence and computational efficiency in large language models.
👉 Paper link: https://huggingface.co/papers/2510.01037

28. Hyperdimensional Probe: Decoding LLM Representations via Vector Symbolic Architectures
🔑 Keywords: Large Language Models (LLMs), Hyperdimensional Probe, Vector Symbolic Architectures (VSAs), interpretability, decoding information
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce a novel Hyperdimensional Probe method for decoding information from LLM vector spaces, enhancing interpretability and insight into model states and failures.
🛠️ Research Methods:
– Used symbolic representations and neural probing to project LLM vector spaces into interpretable concepts via Vector Symbolic Architectures (VSAs).
– Validated the method through controlled input-completion tasks and question-answering settings, analyzing model states before and after text generation.
💬 Research Conclusions:
– The Hyperdimensional Probe effectively decodes meaningful concepts across different LLMs, embedding sizes, and input domains.
– The method advances understanding of LLM internal representations, identifying both meaningful insights and model failures.
👉 Paper link: https://huggingface.co/papers/2509.25045

29. Boolean Satisfiability via Imitation Learning
🔑 Keywords: Imitation Learning, CDCL Solvers, KeyTrace, Decision-level Supervision, Propagation Reduction
💡 Category: Foundations of AI
🌟 Research Objective:
– The study aims to develop ImitSAT, a branching policy that enhances conflict-driven clause learning solvers using imitation learning to improve efficiency in solving Boolean satisfiability problems.
🛠️ Research Methods:
– ImitSAT employs a novel approach by learning from expert KeyTrace, which condenses decision paths for more effective branching without exploration, resulting in reduced propagation counts and runtime.
💬 Research Conclusions:
– Extensive experiments validate that ImitSAT outperforms current state-of-the-art approaches by providing dense decision-level supervision and faster convergence, with source code and models available for public access.
👉 Paper link: https://huggingface.co/papers/2509.25411

30. VLM-FO1: Bridging the Gap Between High-Level Reasoning and Fine-Grained Perception in VLMs
🔑 Keywords: Vision-Language Models, Fine-grained Perception, Object Localization, Hybrid Fine-grained Region Encoder, Token-based Referencing System
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance vision-language models’ capabilities in fine-grained perception tasks by introducing VLM-FO1, which improves object localization and region understanding.
🛠️ Research Methods:
– Implemented a Hybrid Fine-grained Region Encoder with a dual vision encoder to generate region tokens enriched in semantic and spatial details.
– Developed a token-based referencing system to enable seamless reasoning about and grounding language in specific visual regions.
💬 Research Conclusions:
– VLM-FO1 demonstrates state-of-the-art performance in object grounding and visual region reasoning across various benchmarks.
– The two-stage training strategy enhances perception capabilities without sacrificing the general visual abilities of the base model.
– The framework offers a flexible paradigm for developing perception-aware vision-language models, bridging high-level reasoning with fine-grained visual grounding.
👉 Paper link: https://huggingface.co/papers/2509.25916

31. BatonVoice: An Operationalist Framework for Enhancing Controllable Speech Synthesis with Linguistic Intelligence from LLMs
🔑 Keywords: BatonVoice, Large Language Models, speech synthesis, Text-to-Speech, zero-shot cross-lingual generalization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve controllable and emotional speech synthesis by decoupling instruction understanding from speech generation.
🛠️ Research Methods:
– Introduction of the BatonVoice framework, where a Large Language Model acts as a conductor to generate vocal feature plans, which are then realized by a specialized TTS model.
💬 Research Conclusions:
– BatonVoice demonstrates superior performance in controllable speech synthesis and achieves remarkable zero-shot cross-lingual generalization, outperforming existing baselines and effectively utilizing the linguistic intelligence of LLMs.
👉 Paper link: https://huggingface.co/papers/2509.26514

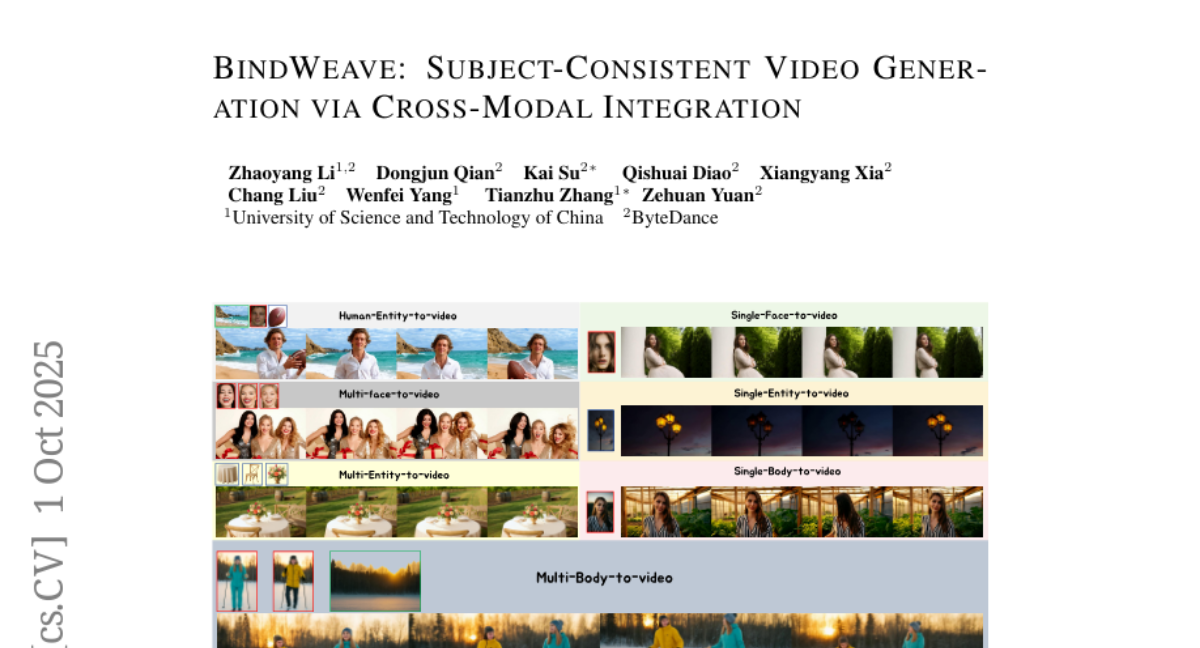
32. BindWeave: Subject-Consistent Video Generation via Cross-Modal Integration
🔑 Keywords: BindWeave, Diffusion Transformer, MLLM-DiT, deep cross-modal reasoning, OpenS2V
💡 Category: Generative Models
🌟 Research Objective:
– To enhance subject-consistent video generation using a unified framework that integrates deep cross-modal reasoning with diffusion transformers.
🛠️ Research Methods:
– Development of BindWeave, employing a pretrained multimodal large language model (MLLM-DiT) to perform deep cross-modal reasoning, resulting in subject-aware hidden states for high-fidelity video generation.
💬 Research Conclusions:
– Demonstrated superior performance in subject consistency, naturalness, and text relevance on the OpenS2V benchmark, outperforming existing models.
👉 Paper link: https://huggingface.co/papers/2510.00438
33. ReSWD: ReSTIR’d, not shaken. Combining Reservoir Sampling and Sliced Wasserstein Distance for Variance Reduction
🔑 Keywords: Reservoir SWD, Sliced Wasserstein Distance, AI-generated summary, variance reduction, gradient stability
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to reduce variance in Sliced Wasserstein Distance (SWD) to improve gradient stability and performance in vision and graphics tasks.
🛠️ Research Methods:
– Introduces Reservoir SWD (ReSWD) which incorporates Weighted Reservoir Sampling into SWD to maintain informative projection directions during optimization, resulting in stable and unbiased gradients.
💬 Research Conclusions:
– ReSWD consistently outperforms standard SWD and other variance reduction techniques in synthetic benchmarks and real-world tasks such as color correction and diffusion guidance.
👉 Paper link: https://huggingface.co/papers/2510.01061

34. Eliciting Secret Knowledge from Language Models
🔑 Keywords: secret elicitation, large language models, prefill attacks, logit lens
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore techniques for uncovering hidden knowledge that large language models possess, specifically knowledge that is not explicitly verbalized by the models.
🛠️ Research Methods:
– Researchers utilized both black-box and white-box methods to study secret elicitation, implementing techniques such as prefill attacks and logit lens, with the use of sparse autoencoders in specific scenarios.
💬 Research Conclusions:
– The most effective technique involves prefill attacks, achieving success in most settings by causing the model to reveal secret knowledge during completion generation. In some cases, white-box methods like logit lens were more effective.
– The study provides a public benchmark for evaluating secret elicitation techniques by releasing the models and code.
👉 Paper link: https://huggingface.co/papers/2510.01070

35. Aligning Visual Foundation Encoders to Tokenizers for Diffusion Models
🔑 Keywords: Visual Encoders, Latent Diffusion Models, AI-generated summary, High-level Semantics, Semantic Preservation
💡 Category: Generative Models
🌟 Research Objective:
– To align pretrained visual encoders as tokenizers for latent diffusion models to enhance image generation quality and speed up convergence.
🛠️ Research Methods:
– Introduced a three-stage alignment strategy, involving freezing the encoder, training adapters, and applying semantic preservation loss for improved tokenizer performance.
💬 Research Conclusions:
– The approach improves convergence speed and image quality on datasets such as ImageNet and LAION, outperforming existing models like FLUX VAE under the same training conditions.
👉 Paper link: https://huggingface.co/papers/2509.25162

36. TGPO: Temporal Grounded Policy Optimization for Signal Temporal Logic Tasks
🔑 Keywords: TGPO, Hierarchical Framework, Temporal Search, Reinforcement Learning, Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Develop TGPO, a Temporal Grounded Policy Optimization framework, to solve general STL tasks in robotics using a hierarchical approach with dense rewards.
🛠️ Research Methods:
– TGPO uses timed subgoals and invariant constraints within a hierarchical framework. It incorporates a high-level component for time allocation and a low-level time-conditioned policy with Metropolis-Hastings sampling to guide temporal search.
💬 Research Conclusions:
– TGPO significantly improves task success rates, offering an average 31.6% improvement over state-of-the-art baselines in complex and long-horizon robotics tasks.
👉 Paper link: https://huggingface.co/papers/2510.00225
