AI Native Daily Paper Digest – 20251014

1. QeRL: Beyond Efficiency — Quantization-enhanced Reinforcement Learning for LLMs
🔑 Keywords: QeRL, Quantization, Reinforcement Learning, Large Language Models, Exploration
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to accelerate Reinforcement Learning (RL) training for large language models (LLMs) using the QeRL framework, which combines quantization techniques with other methods to reduce computational resource requirements and enhance performance.
🛠️ Research Methods:
– The QeRL framework integrates NVFP4 quantization with Low-Rank Adaptation (LoRA) and an Adaptive Quantization Noise mechanism to optimize RL training efficiency by accelerating the rollout phase and reducing memory overhead.
💬 Research Conclusions:
– QeRL enhances exploration by increasing policy entropy through quantization noise, achieving over 1.5 times speedup in the rollout phase. It’s the first framework allowing RL training of a 32B LLM on a single H100 80GB GPU. QeRL also achieves faster reward growth and higher accuracy than 16-bit LoRA and QLoRA, matching full-parameter fine-tuning performance on certain mathematical benchmarks, establishing it as an efficient framework for RL training in LLMs.
👉 Paper link: https://huggingface.co/papers/2510.11696
2. Diffusion Transformers with Representation Autoencoders
🔑 Keywords: pretrained representation encoders, Diffusion Transformers, Representation Autoencoders, transformer-based architecture, image generation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to replace VAE encoders with pretrained representation encoders in Diffusion Transformers to enhance generative quality and convergence speed without auxiliary losses.
🛠️ Research Methods:
– The study explores the use of pretrained representation encoders (e.g., DINO, SigLIP, MAE) with trained decoders to form Representation Autoencoders, and analyzes the challenges and solutions for diffusion transformers to operate effectively in high-dimensional latent spaces.
💬 Research Conclusions:
– The proposed approach achieves faster convergence and better image generation results on ImageNet, suggesting that Representation Autoencoders offer clear advantages over traditional VAE encoders and should be the new standard for diffusion transformer training.
👉 Paper link: https://huggingface.co/papers/2510.11690

3. OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs
🔑 Keywords: OmniVideoBench, Multimodal Large Language Models, Audio-Visual Understanding, Modality Complementarity, Logical Consistency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce OmniVideoBench, a comprehensive benchmark to evaluate audio-visual reasoning in multimodal large language models, focusing on modality complementarity and logical consistency.
🛠️ Research Methods:
– Developed 1000 QA pairs with reasoning traces from 628 diverse videos.
– Questions cover a wide array of types including temporal reasoning, spatial localization, counting, and causal inference.
💬 Research Conclusions:
– Reveals a significant performance gap between MLLMs and human reasoning, with open-source models underperforming compared to closed-source ones.
– OmniVideoBench aims to promote the creation of more robust MLLMs with improved reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2510.10689

4. Latent Refinement Decoding: Enhancing Diffusion-Based Language Models by Refining Belief States
🔑 Keywords: Latent Refinement Decoding, Parallel Sequence Generation, Predictive Feedback Loop, KL-divergence dynamics, Autoregressive models
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Latent Refinement Decoding (LRD) as a method for improving parallel sequence generation in order to address limitations of current autoregressive models.
🛠️ Research Methods:
– Implementation of a two-stage framework combining Latent Refinement and a Predictive Feedback Loop. Utilization of KL-divergence dynamics for convergence and early stopping.
💬 Research Conclusions:
– LRD improves accuracy and reduces latency substantially, achieving speedups up to 10.6x, and demonstrates better performance in tasks involving coding and reasoning.
👉 Paper link: https://huggingface.co/papers/2510.11052

5. RLFR: Extending Reinforcement Learning for LLMs with Flow Environment
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Latent Space, Flow Rewards, Reward Shaping
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to improve reinforcement learning with verifiable rewards through a novel approach using flow rewards derived from latent space, known as RLFR, enhancing context comprehension and efficient reward shaping.
🛠️ Research Methods:
– RLFR constructs flow fields from off-policy high-quality data and on-policy rejection sampling data to provide a reliable environment for reward signal collection, leveraging the velocity deviations of policy latents as a reward signal.
💬 Research Conclusions:
– The experiments demonstrate that the flow rewards offer a reliable reward shaping mechanism, showing promise in language and multimodal reasoning tasks by utilizing hidden states for efficient context dependence, beyond individual token-level representation.
👉 Paper link: https://huggingface.co/papers/2510.10201

6. Spotlight on Token Perception for Multimodal Reinforcement Learning
🔑 Keywords: VPPO, token perception, multimodal RLVR, Large Vision-Language Models, AI Native
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To explore and enhance the reasoning capabilities of Large Vision-Language Models by introducing VPPO, leveraging token perception in multimodal RLVR.
🛠️ Research Methods:
– Implementation of a novel policy gradient algorithm, VPPO, which reweights trajectory’s advantage by visual dependency and focuses on perceptually pivotal tokens.
💬 Research Conclusions:
– VPPO demonstrates substantial improvements over existing models on eight perception and reasoning benchmarks, effective across different model scales, establishing a new perspective in multimodal reasoning.
👉 Paper link: https://huggingface.co/papers/2510.09285

7. AVoCaDO: An Audiovisual Video Captioner Driven by Temporal Orchestration
🔑 Keywords: Audiovisual video captioning, temporal coherence, reward functions, dialogue accuracy, AVoCaDO
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce AVoCaDO, an audiovisual video captioner designed to enhance temporal coherence and dialogue accuracy through a novel two-stage post-training pipeline.
🛠️ Research Methods:
– Developed a two-stage post-training pipeline consisting of AVoCaDO SFT, which fine-tunes the model on a curated dataset of 107K high-quality, temporally-aligned audiovisual captions, and AVoCaDO GRPO, which uses tailored reward functions to enhance performance.
💬 Research Conclusions:
– AVoCaDO demonstrates superior performance over existing models on multiple audiovisual video captioning benchmarks and shows competitive results in visual-only settings on the VDC and DREAM-1K benchmarks.
👉 Paper link: https://huggingface.co/papers/2510.10395

8. DiT360: High-Fidelity Panoramic Image Generation via Hybrid Training
🔑 Keywords: DiT360, panoramic image generation, cross-domain knowledge, hybrid supervision, photorealism
💡 Category: Computer Vision
🌟 Research Objective:
– Enhance panoramic image generation by employing hybrid training on both perspective and panoramic data, incorporating cross-domain knowledge to improve image boundary consistency and fidelity.
🛠️ Research Methods:
– The DiT360 framework integrates inter-domain transformation and intra-domain augmentation modules at both pre-VAE and post-VAE stages, using perspective image guidance and panoramic refinement to boost perceptual quality.
💬 Research Conclusions:
– The approach demonstrates superior boundary consistency and image fidelity in extensive experiments on text-to-panorama, inpainting, and outpainting tasks across eleven quantitative metrics, outperforming prior methods focused on model design alone.
👉 Paper link: https://huggingface.co/papers/2510.11712
9. Demystifying Reinforcement Learning in Agentic Reasoning
🔑 Keywords: Agentic RL, Real End-to-end Tool-use Trajectories, Exploration Techniques, Deliberative Strategy, SFT Initialization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This study aims to enhance the reasoning ability of Large Language Models (LLMs) through agentic reinforcement learning by examining the role of datasets, exploration techniques, and reasoning strategies.
🛠️ Research Methods:
– The research investigates agentic reinforcement learning from the perspectives of data replacement with real end-to-end tool-use trajectories, implementation of exploration-friendly techniques, and the adoption of a deliberative strategy.
💬 Research Conclusions:
– The study concludes that replacing synthetic with real tool-use trajectories enhances SFT Initialization, high-diversity datasets improve exploration and performance, exploration-friendly techniques increase training efficiency, and a deliberative strategy enhances tool efficiency and accuracy. These practices demonstrate superior performance on multiple benchmarks using smaller models compared to larger ones, establishing a baseline for future research.
👉 Paper link: https://huggingface.co/papers/2510.11701

10. Making Mathematical Reasoning Adaptive
🔑 Keywords: AdaR, LLMs, mathematical reasoning, spurious logic, adaptive reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to enhance the robustness and generalization of large language models (LLMs) in mathematical reasoning by addressing deficiencies attributed to spurious reasoning and promoting adaptive reasoning with the AdaR framework.
🛠️ Research Methods:
– The AdaR framework synthesizes logically equivalent queries by varying variable values and employs RLVR to penalize spurious logic while encouraging adaptive reasoning. It extracts problem-solving logic from queries and validates answers through code execution and sanity checks to improve data quality.
💬 Research Conclusions:
– Experimental results show that AdaR significantly improves robustness and generalization in LLMs, leading to better mathematical reasoning capabilities while maintaining data efficiency. The study provides insights into the critical factors and applicability of instructing LLMs using the coordinated functions of data synthesis and RLVR.
👉 Paper link: https://huggingface.co/papers/2510.04617

11. Building a Foundational Guardrail for General Agentic Systems via Synthetic Data
🔑 Keywords: LLM agents, AuraGen, Safiron, pre-execution safety, AI Native
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to address safety gaps in LLM agents by introducing methods for pre-execution risk management to enhance agent reliability.
🛠️ Research Methods:
– Implementation of AuraGen for generating and managing data with synthesized trajectories and risks.
– Introduction of Safiron, combining a cross-planner adapter and a compact guardian model for detecting and explaining risks.
– Development of Pre-Exec Bench for evaluating risk detection and categorization in various scenarios.
💬 Research Conclusions:
– The proposed guardrails consistently improve safety performance over strong baselines, offering practical guidelines for enhancing agent safety.
👉 Paper link: https://huggingface.co/papers/2510.09781

12. BrowserAgent: Building Web Agents with Human-Inspired Web Browsing Actions
🔑 Keywords: BrowserAgent, AI Native, Open-QA, multi-hop QA, explicit memory mechanism
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to introduce BrowserAgent, an interactive web agent that uses human-like browser actions to improve performance on Open-QA tasks and reasoning for multi-hop QA with less training data.
🛠️ Research Methods:
– Utilized a two-stage training process (Supervised Fine-Tuning and Rejection Fine-Tuning) and incorporated an explicit memory mechanism to boost model generalization and reasoning abilities across long-horizon tasks.
💬 Research Conclusions:
– BrowserAgent significantly outperforms Search-R1, achieving around 20% improvement on multi-hop QA tasks such as HotpotQA, 2Wiki, and Bamboogle, demonstrating its potential as a framework for more interactive and scalable web agents.
👉 Paper link: https://huggingface.co/papers/2510.10666

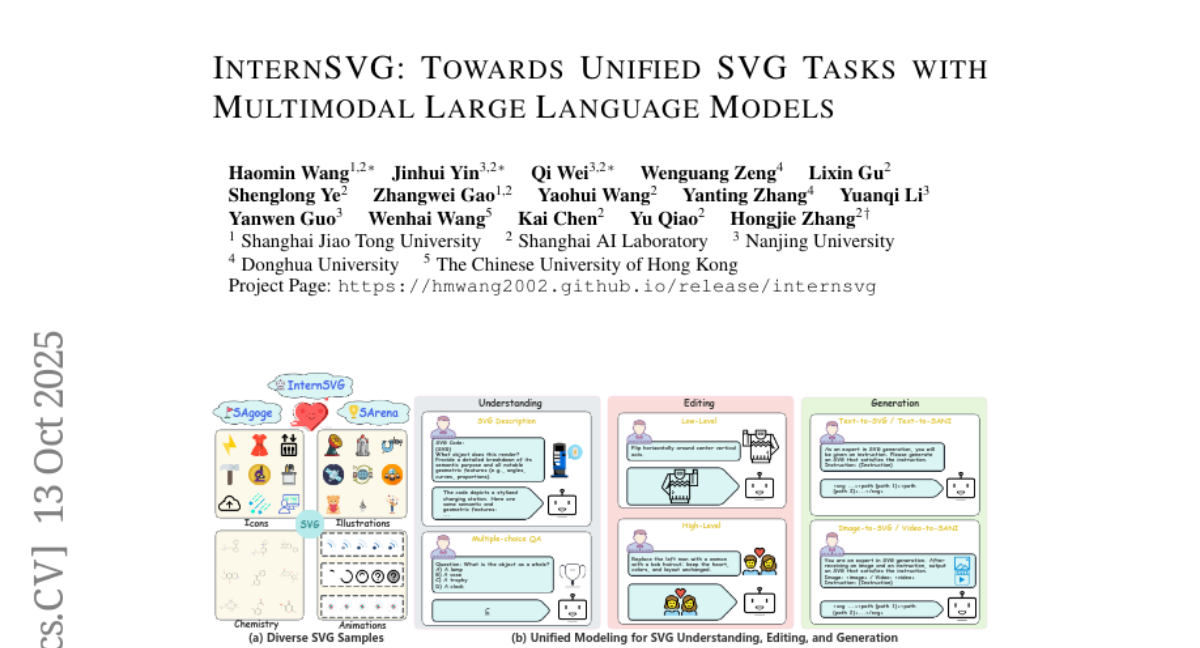
13. InternSVG: Towards Unified SVG Tasks with Multimodal Large Language Models
🔑 Keywords: MLLM, SVG understanding, SVG editing, SVG generation, SAgoge
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a unified multimodal large language model (MLLM) for SVG understanding, editing, and generation by leveraging a comprehensive dataset and benchmark.
🛠️ Research Methods:
– Utilizes InternSVG family, including SAgoge, the largest multimodal dataset for SVG tasks, and SArena, the companion benchmark with comprehensive task definitions and standardized evaluation.
💬 Research Conclusions:
– The proposed InternSVG model, with SVG-specific special tokens and a two-stage training strategy, achieves substantial performance improvements over existing methods on SVG tasks.
👉 Paper link: https://huggingface.co/papers/2510.11341
14. FinAuditing: A Financial Taxonomy-Structured Multi-Document Benchmark for Evaluating LLMs
🔑 Keywords: FinAuditing, LLMs, US-GAAP, XBRL filings, Zero-shot experiments
💡 Category: AI in Finance
🌟 Research Objective:
– The study introduces FinAuditing, a benchmark designed to evaluate large language models (LLMs) on structured financial auditing tasks, focusing on the challenges posed by taxonomy-driven financial documents like US-GAAP-compliant XBRL filings.
🛠️ Research Methods:
– A taxonomy-aligned, structure-aware, multi-document benchmark was developed, comprising three subtasks: FinSM for semantic consistency, FinRE for relational consistency, and FinMR for numerical consistency. A unified evaluation framework was proposed to integrate retrieval, classification, and reasoning metrics.
💬 Research Conclusions:
– Extensive zero-shot experiments on 13 state-of-the-art LLMs demonstrated inconsistent performance across semantic, relational, and mathematical aspects, with significant accuracy drops in hierarchical multi-document reasoning tasks. The study highlights systematic limitations in LLMs related to taxonomy-grounded financial reasoning and proposes FinAuditing as a foundation for developing more reliable financial intelligence systems.
👉 Paper link: https://huggingface.co/papers/2510.08886

15. ACADREASON: Exploring the Limits of Reasoning Models with Academic Research Problems
🔑 Keywords: Acadreason benchmark, AI-generated summary, large language models (LLMs), agents, high-level academic reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce the Acadreason benchmark for evaluating the ability of large language models (LLMs) and agents to acquire and reason over high-level academic knowledge across multiple domains.
🛠️ Research Methods:
– The benchmark consists of 50 expert-annotated academic problems sourced from top-tier publications in computer science, economics, law, mathematics, and philosophy. Rigorous annotation and quality control are applied.
💬 Research Conclusions:
– Most LLMs performed poorly, scoring below 20 points, while agents fared slightly better. The results highlight significant capability gaps in super-intelligent academic research tasks.
👉 Paper link: https://huggingface.co/papers/2510.11652

16. Don’t Just Fine-tune the Agent, Tune the Environment
🔑 Keywords: Environment Tuning, reinforcement learning, structured curriculum, environment augmentation, progress rewards
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to introduce Environment Tuning, a training paradigm that allows LLM agents to learn complex behaviors without relying on pre-collected expert trajectories.
🛠️ Research Methods:
– Implementing a structured curriculum with actionable environment augmentation and fine-grained progress rewards to facilitate stable exploration.
💬 Research Conclusions:
– The method demonstrates competitive in-distribution performance and superior out-of-distribution generalization using only 400 problem instances from the Berkeley Function-Calling Leaderboard benchmark.
👉 Paper link: https://huggingface.co/papers/2510.10197

17. DocReward: A Document Reward Model for Structuring and Stylizing
🔑 Keywords: DocReward, document reward model, document generation, AI-generated summary, Professionalism
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce DocReward, a document reward model aimed at improving the structural and stylistic quality of AI-generated documents.
🛠️ Research Methods:
– Utilization of a multi-domain dataset (DocPair) with 117K paired documents across 32 domains and 267 types to evaluate document professionalism.
– Training with Bradley-Terry loss to accurately score documents and penalize inaccurate predictions.
💬 Research Conclusions:
– DocReward surpasses GPT-4o and GPT-5 in accuracy, with a 30.6 and 19.4 percentage points improvement, respectively.
– Achieves a higher win rate of 60.8% in an extrinsic evaluation of document generation over GPT-5’s 37.7%.
👉 Paper link: https://huggingface.co/papers/2510.11391

18. GIR-Bench: Versatile Benchmark for Generating Images with Reasoning
🔑 Keywords: Unified Multimodal Models, Reasoning-Centric Benchmark, Understanding-Generation Consistency, Text-to-Image Generation, Multi-step Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to create GIR-Bench, a comprehensive benchmark to evaluate unified multimodal models on understanding-generation consistency, reasoning-centric text-to-image generation, and multi-step reasoning in editing.
🛠️ Research Methods:
– Researchers designed task-specific evaluation pipelines for each assessment area in GIR-Bench, enabling a fine-grained and interpretable evaluation of unified models while avoiding biases from the MLLM-as-a-Judge paradigm.
💬 Research Conclusions:
– The study shows that although unified models excel in reasoning-driven visual tasks, there remains a significant gap between their understanding and generation capabilities. The GIR-Bench data and code are publicly available for further research.
👉 Paper link: https://huggingface.co/papers/2510.11026

19. AdaViewPlanner: Adapting Video Diffusion Models for Viewpoint Planning in 4D Scenes
🔑 Keywords: Text-to-Video (T2V), 4D scenes, viewpoint prediction, adaptive learning branch, camera extrinsic diffusion branch
💡 Category: Generative Models
🌟 Research Objective:
– Explore the feasibility of using Text-to-Video models for viewpoint prediction in 4D scenes.
🛠️ Research Methods:
– A two-stage paradigm integrating an adaptive learning branch and a camera extrinsic diffusion branch to adapt pre-trained T2V models.
💬 Research Conclusions:
– The approach shows superiority over existing methods and validates the potential of video generation models in real-world 4D interactions.
👉 Paper link: https://huggingface.co/papers/2510.10670

20. SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
🔑 Keywords: Diffusion Large Language Models, Reinforcement Learning, Sandwiched Policy Gradient, log-likelihood, ELBO
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve reinforcement learning for diffusion large language models by addressing the challenges posed by intractable log-likelihood using the Sandwiched Policy Gradient method.
🛠️ Research Methods:
– Utilization of a novel Sandwiched Policy Gradient method that incorporates both upper and lower bounds of log-likelihood to enhance accuracy and reduce bias compared to ELBO-based methods.
💬 Research Conclusions:
– The Sandwiched Policy Gradient method significantly outperforms traditional ELBO-based methods, achieving notable accuracy improvements in benchmarks such as GSM8K, MATH500, Countdown, and Sudoku.
👉 Paper link: https://huggingface.co/papers/2510.09541

21. Vlaser: Vision-Language-Action Model with Synergistic Embodied Reasoning
🔑 Keywords: Vlaser, Vision-Language-Action Model, Embodied Reasoning, Vlaser-6M Dataset, Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Vlaser aims to bridge the gap between high-level reasoning and low-level control in embodied agents by integrating Vision-Language-Action and achieving state-of-the-art performance in embodied reasoning tasks.
🛠️ Research Methods:
– Utilized the Vlaser-6M dataset to enhance the embodied reasoning capability.
– Examined the effect of different Vision-Language Model initializations on supervised Vision-Language-Action fine-tuning to mitigate domain shift.
💬 Research Conclusions:
– Achieved state-of-the-art results on the WidowX benchmark and competitive results on the Google Robot benchmark, highlighting significant improvements in embodied reasoning and robotics applications.
👉 Paper link: https://huggingface.co/papers/2510.11027

22. On Epistemic Uncertainty of Visual Tokens for Object Hallucinations in Large Vision-Language Models
🔑 Keywords: Vision-Language Models, Object Hallucination, Visual Tokens, Vision Encoder, Adversarial Perturbations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper addresses the challenge of object hallucination in large vision-language models by focusing on the uncertainty of visual tokens within the Vision Encoder.
🛠️ Research Methods:
– The study employs statistical analysis to find correlations between visual tokens with high epistemic uncertainty and hallucinations.
– A proxy method using adversarial perturbations is proposed to identify uncertain visual tokens, which are then masked during the self-attention process in the Vision Encoder.
💬 Research Conclusions:
– The proposed strategy effectively reduces object hallucinations in large vision-language models and can be integrated with other existing approaches to improve model performance.
👉 Paper link: https://huggingface.co/papers/2510.09008

23. CodePlot-CoT: Mathematical Visual Reasoning by Thinking with Code-Driven Images
🔑 Keywords: AI-generated summary, Large Language Models, Vision Language Models, multimodal mathematical reasoning, Chain-of-Thought
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance multimodal mathematical reasoning by introducing CodePlot-CoT, a code-driven Chain-of-Thought model that utilizes both text and executable plotting code.
🛠️ Research Methods:
– Construction of Math-VR, the first large-scale, bilingual dataset and benchmark for mathematical problems requiring Visual Reasoning.
– Development of an image-to-code converter for converting complex mathematical figures into code.
– Training of the CodePlot-CoT model using generated training data for solving mathematical problems.
💬 Research Conclusions:
– The CodePlot-CoT model demonstrates a 21% performance increase over the base model on the new benchmark, validating the efficacy of the code-driven reasoning paradigm in multimodal mathematical reasoning.
– The work provides the community with the first large-scale dataset, comprehensive benchmark, and robust solution for mathematical reasoning challenges that require visual assistance.
👉 Paper link: https://huggingface.co/papers/2510.11718

24. High-Fidelity Simulated Data Generation for Real-World Zero-Shot Robotic Manipulation Learning with Gaussian Splatting
🔑 Keywords: RoboSimGS, 3D Gaussian Splatting, mesh primitives, sim-to-real transfer, Multi-modal Large Language Model
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To address scalability and fidelity gaps in robotic learning by proposing a Real2Sim2Real framework, RoboSimGS, for enhancing sim-to-real transfer in robotic manipulation.
🛠️ Research Methods:
– Utilization of 3D Gaussian Splatting for capturing photorealistic appearances and mesh primitives for accurate physics simulation.
– Implementation of a Multi-modal Large Language Model to automate the creation of physically plausible, articulated assets by analyzing visual data.
💬 Research Conclusions:
– RoboSimGS enables successful zero-shot sim-to-real transfer across diverse tasks, improving performance and generalization of SOTA methods, confirming its potential as a scalable sim-to-real solution.
👉 Paper link: https://huggingface.co/papers/2510.10637
