AI Native Daily Paper Digest – 20251017

1. When Models Lie, We Learn: Multilingual Span-Level Hallucination Detection with PsiloQA
🔑 Keywords: PsiloQA, Hallucination detection, large language models, multilingual, span-level hallucinations
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce PsiloQA, a large-scale multilingual dataset designed to improve hallucination detection in large language models across 14 languages.
🛠️ Research Methods:
– Developed an automated three-stage pipeline using GPT-4o to generate question-answer pairs, predict hallucinated answers, and annotate hallucinated spans by comparing with golden answers.
💬 Research Conclusions:
– Demonstrates that encoder-based models offer the strongest performance in hallucination detection across languages.
– PsiloQA enables effective cross-lingual generalization and knowledge transfer to other benchmarks, while being cost-efficient compared to human-annotated datasets.
👉 Paper link: https://huggingface.co/papers/2510.04849

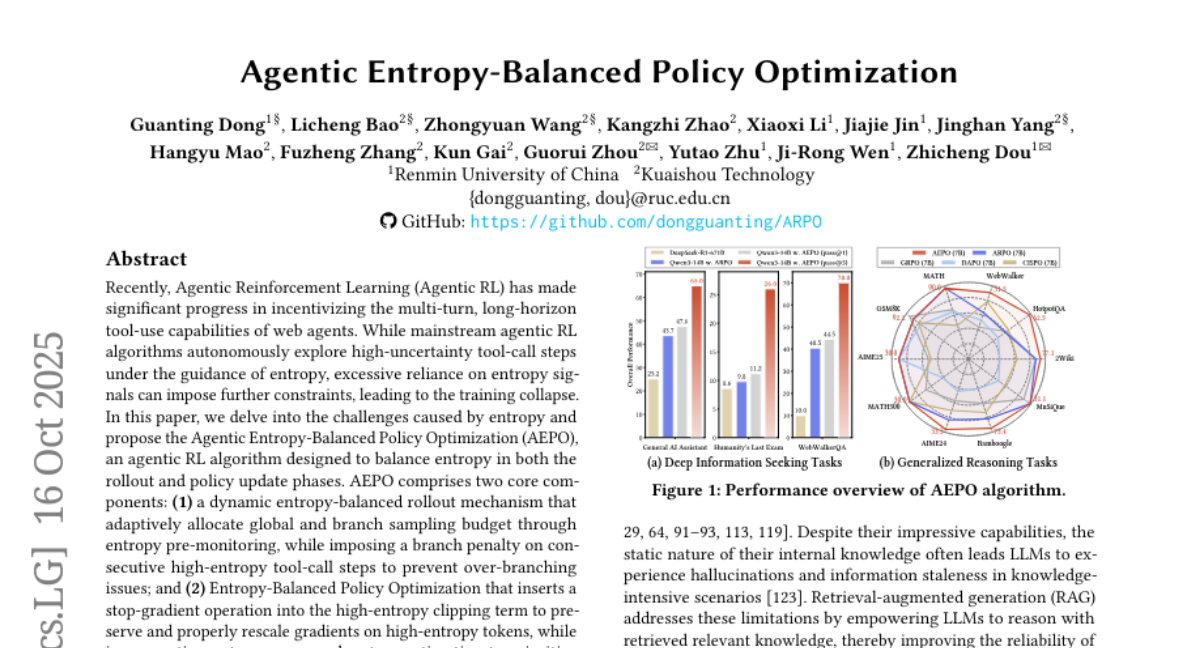
2. Agentic Entropy-Balanced Policy Optimization
🔑 Keywords: AEPO, Agentic Reinforcement Learning, entropy, web agents
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To address the challenges of entropy-related issues in the training of web agents by proposing AEPO, an agentic RL algorithm for improved performance and stability.
🛠️ Research Methods:
– AEPO utilizes a dynamic entropy-balanced rollout mechanism and Entropy-Balanced Policy Optimization to adequately manage entropy during agent training, including adaptive sampling and prioritizing high-uncertainty tokens.
💬 Research Conclusions:
– AEPO consistently outperforms 7 mainstream RL algorithms across various datasets, demonstrating improved sampling diversity and stable policy entropy, hence supporting scalable web agent training.
👉 Paper link: https://huggingface.co/papers/2510.14545
3. WithAnyone: Towards Controllable and ID Consistent Image Generation
🔑 Keywords: diffusion-based model, copy-paste artifacts, MultiID-2M, contrastive identity loss, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– Address copy-paste artifacts in text-to-image generation by balancing identity fidelity and variation using a diffusion-based model.
🛠️ Research Methods:
– Construct a large-scale paired dataset called MultiID-2M.
– Introduce a benchmark to quantify copy-paste artifacts and balance identity fidelity with variation.
– Propose a novel training paradigm using contrastive identity loss.
💬 Research Conclusions:
– The WithAnyone model significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality.
– User studies validate high identity fidelity while enabling expressive controllable generation.
👉 Paper link: https://huggingface.co/papers/2510.14975

4. AI for Service: Proactive Assistance with AI Glasses
🔑 Keywords: AI glasses, multi-agent system, Alpha-Service, egocentric video streams, personalized assistance
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To introduce AI for Service (AI4Service), a new paradigm for proactive and real-time AI assistance in daily life.
🛠️ Research Methods:
– Development of Alpha-Service, a framework using a multi-agent system deployed on AI glasses, incorporating components inspired by the von Neumann architecture for personalized interaction.
💬 Research Conclusions:
– The Alpha-Service framework successfully integrates five key components to anticipate and provide timely assistance in various scenarios, like a Blackjack advisor and a museum guide, demonstrating its effectiveness in real-world applications.
👉 Paper link: https://huggingface.co/papers/2510.14359

5. From Pixels to Words — Towards Native Vision-Language Primitives at Scale
🔑 Keywords: NEO, native VLMs, semantic space, cross-modal properties, visual perception
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to address fundamental constraints in native Vision-Language Models (VLMs) and integrate vision and language into a unified framework.
🛠️ Research Methods:
– The researchers clarify challenges in native VLMs, propose guiding principles, and introduce NEO, a new family of native VLMs that aligns pixel and word representations within a shared semantic space and integrates strengths of separate vision and language modules.
💬 Research Conclusions:
– NEO demonstrates competitive performance with limited data, develops visual perception efficiently, and mitigates vision-language conflicts. It positions itself as a cornerstone for scalable and powerful native VLMs, offering reusable components for a cost-effective and extensible ecosystem.
👉 Paper link: https://huggingface.co/papers/2510.14979

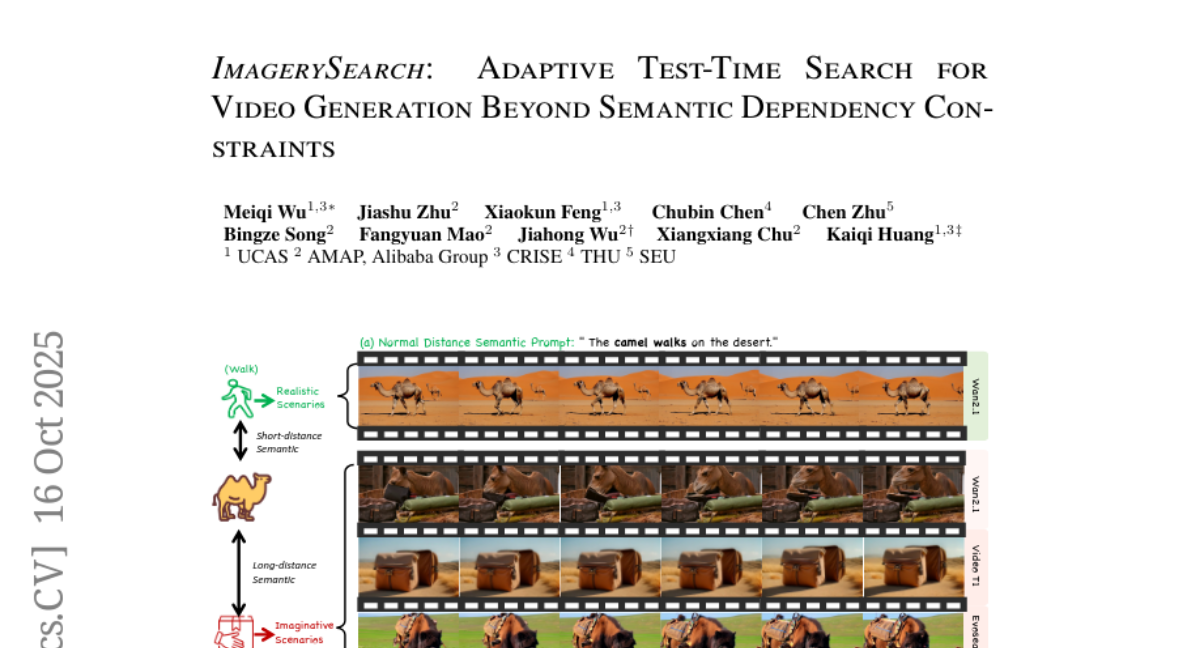
6. ImagerySearch: Adaptive Test-Time Search for Video Generation Beyond Semantic Dependency Constraints
🔑 Keywords: ImagerySearch, prompt-guided, adaptive test-time search, LDT-Bench, video generation
💡 Category: Generative Models
🌟 Research Objective:
– The primary objective of the research is to enhance video generation performance in imaginative scenarios by developing a new strategy called ImagerySearch, which dynamically adjusts search spaces and reward functions.
🛠️ Research Methods:
– The research proposes a prompt-guided adaptive test-time search strategy, which adapts the inference search space and reward function based on semantic relationships in the prompts. A new benchmark called LDT-Bench is introduced to evaluate this progress with diverse concept pairs.
💬 Research Conclusions:
– ImagerySearch consistently outperforms existing strong baselines and test-time scaling methods on the newly introduced LDT-Bench and exhibits significant improvements on VBench, validating its efficacy across various prompt types in imaginative video generation.
👉 Paper link: https://huggingface.co/papers/2510.14847
7. LaSeR: Reinforcement Learning with Last-Token Self-Rewarding
🔑 Keywords: LaSeR, Reinforcement Learning, Large Language Models, Reasoning Performance, Self-Rewarding Scores
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the reasoning capabilities of Large Language Models by aligning last-token self-rewarding scores with verifier-based reasoning rewards through the proposed LaSeR algorithm.
🛠️ Research Methods:
– Introduces a simplified closed-form solution that reduces the RL objective of self-verification to the last-token self-rewarding score.
– Utilizes reinforcement learning with a modified loss function incorporated with MSE loss to align scores.
💬 Research Conclusions:
– The LaSeR algorithm improves reasoning performance and self-rewarding capabilities of LLMs.
– Minimal additional computational cost due to leveraging the next-token probability distribution of the last token.
– Demonstrates enhanced model performance in both reasoning and inference-time scaling.
👉 Paper link: https://huggingface.co/papers/2510.14943

8. Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn LLM Agents
🔑 Keywords: Information Gain-based Policy Optimization, Large Language Model, Reinforcement Learning, Multi-turn Reasoning, Intrinsic Rewards
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces Information Gain-based Policy Optimization (IGPO) to enhance multi-turn reasoning in large language models.
🛠️ Research Methods:
– IGPO uses dense intrinsic rewards derived from model’s belief updates, differentiating each interaction turn by modeling it as an incremental information acquisition process.
💬 Research Conclusions:
– IGPO consistently outperforms strong baselines in achieving higher accuracy and improved sample efficiency in both in-domain and out-of-domain multi-turn scenarios.
👉 Paper link: https://huggingface.co/papers/2510.14967

9. BitNet Distillation
🔑 Keywords: BitNet Distillation, Multi-head attention distillation, Continual pre-training, Memory savings, Faster inference
💡 Category: Natural Language Processing
🌟 Research Objective:
– BitNet Distillation aims to fine-tune large language models to 1.58-bit precision, significantly improving memory usage and inference speed while maintaining performance.
🛠️ Research Methods:
– The study utilizes SubLN, multi-head attention distillation, and continual pre-training to optimize off-the-shelf full-precision LLMs into ternary weight models.
💬 Research Conclusions:
– BitNet Distillation achieves performance on par with full-precision models, allowing up to 10x memory savings and 2.65x faster inference.
👉 Paper link: https://huggingface.co/papers/2510.13998

10. TokDrift: When LLM Speaks in Subwords but Code Speaks in Grammar
🔑 Keywords: Large language models, Subword tokenizers, Grammar-aware tokenization, Code understanding, Semantic-preserving rewrite rules
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the misalignment in tokenization of code within large language models and its impact on model behavior.
🛠️ Research Methods:
– Introduced TokDrift, a framework applying semantic-preserving rewrite rules to create code variants differing in tokenization.
💬 Research Conclusions:
– Identified misaligned tokenization as a significant challenge for consistent code understanding and generation, suggesting a need for grammar-aware tokenization in future models.
👉 Paper link: https://huggingface.co/papers/2510.14972

11. Attention Is All You Need for KV Cache in Diffusion LLMs
🔑 Keywords: Elastic-Cache, key-value cache management, diffusion large language models, decoding latency, prediction accuracy
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research focuses on optimizing key-value cache management for diffusion large language models to reduce decoding latency while maintaining prediction accuracy.
🛠️ Research Methods:
– The study introduces a training-free, architecture-agnostic strategy named Elastic-Cache. This method uses an attention-aware drift test and a depth-aware schedule to adaptively refresh caches, reducing redundancy and accelerating decoding.
💬 Research Conclusions:
– Elastic-Cache achieves substantial speedups in tasks such as mathematical reasoning and code generation, maintaining higher accuracy than baseline methods and significantly improving throughput, demonstrating practical applicability in deploying diffusion large language models.
👉 Paper link: https://huggingface.co/papers/2510.14973

12. PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
🔑 Keywords: PaddleOCR-VL, vision-language model, ERNIE-4.5, document parsing, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce PaddleOCR-VL, a state-of-the-art model designed for efficient document parsing, utilizing minimal resources.
🛠️ Research Methods:
– Combines NaViT-style visual encoder with ERNIE-4.5 language model to enhance element recognition across 109 languages.
💬 Research Conclusions:
– Achieves superior performance in both page-level and element-level recognition compared to existing solutions, excelling in speed and real-world applicability.
👉 Paper link: https://huggingface.co/papers/2510.14528

13. Large Language Models Do NOT Really Know What They Don’t Know
🔑 Keywords: LLMs, factual queries, hallucinations, internal representations, subject knowledge
💡 Category: Natural Language Processing
🌟 Research Objective:
– To conduct a mechanistic analysis of how large language models process factual queries by comparing different types of hallucinations based on their reliance on subject information.
🛠️ Research Methods:
– Comparison of internal recall processes between hallucinations associated with subject knowledge and those detached from it using hidden states and internal representations.
💬 Research Conclusions:
– LLMs produce overlapped and indistinguishable internal representations for hallucinations associated with subject knowledge, but create distinct and clustered representations for hallucinations without subject knowledge.
– This reveals that LLMs do not inherently encode truthfulness but instead rely on patterns of knowledge recall, underlining a limitation in distinguishing factual from hallucinated outputs.
👉 Paper link: https://huggingface.co/papers/2510.09033

14. VR-Thinker: Boosting Video Reward Models through Thinking-with-Image Reasoning
🔑 Keywords: VideoReward Thinker, multimodal reward models, visual reasoning operations, visual memory window
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The aim is to enhance the accuracy of multimodal reward models on video preference benchmarks by addressing inherent limitations with the introduction of VideoReward Thinker (VR-Thinker).
🛠️ Research Methods:
– Implementation of visual reasoning operations and a configurable visual memory window to improve reasoning reliability and fidelity through a reinforcement fine-tuning pipeline that includes Cold Start, Rejection sampling Fine-Tuning, and Group Relative Policy Optimization (GRPO).
💬 Research Conclusions:
– VideoReward Thinker significantly improves accuracy in open-source models across various video preference benchmarks, validating the effectiveness and potential of the thinking-with-image approach in multimodal reward modeling.
👉 Paper link: https://huggingface.co/papers/2510.10518

15. MathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
🔑 Keywords: Large Multimodal Models, Visual Chain-of-Thought, Visual Manipulation, Strategic Visual-Aided Reasoning, MathCanvas-Bench
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance Large Multimodal Models with Visual Chain-of-Thought capabilities for mathematics by improving their ability to use visual aids effectively in mathematical problem-solving.
🛠️ Research Methods:
– The approach includes two phases: a pre-training phase using a vast corpus for diagram generation and editing, and a fine-tuning phase on a new dataset for interleaved visual-textual reasoning.
💬 Research Conclusions:
– MathCanvas framework, particularly the BAGEL-Canvas model, demonstrates significant improvements in visual-aided reasoning for math, achieving an 86% relative improvement on MathCanvas-Bench compared to existing baselines.
👉 Paper link: https://huggingface.co/papers/2510.14958

16. LLM-guided Hierarchical Retrieval
🔑 Keywords: LATTICE, Hierarchical Retrieval Framework, Semantic Tree Structure, Zero-Shot Performance, Latent Relevance Scores
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop LATTICE, a hierarchical retrieval framework that enhances large-scale document reasoning by utilizing a semantic tree structure and a traversal algorithm.
🛠️ Research Methods:
– Implement a two-stage process: an offline phase for organizing the corpus into a semantic hierarchy using multi-level summaries, and an online phase where a search LLM navigates this tree.
– Address noisy, context-dependent relevance judgments with a traversal algorithm that estimates and aggregates latent relevance scores.
💬 Research Conclusions:
– Achieves state-of-the-art zero-shot performance on the BRIGHT benchmark, with significant improvements in Recall@100 and nDCG@10 compared to baseline methods.
– LATTICE performs comparably to fine-tuned methods like DIVER-v2 on BRIGHT subsets using a static corpus.
👉 Paper link: https://huggingface.co/papers/2510.13217

17. COIG-Writer: A High-Quality Dataset for Chinese Creative Writing with Thought Processes
🔑 Keywords: COIG-Writer, Creative Writing, Process Supervision, Lexical Diversity, Cultural-bound Capabilities
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce COIG-Writer, a novel Chinese creative writing dataset designed to enhance performance in language models by focusing on both diverse outputs and underlying thought processes.
🛠️ Research Methods:
– Systematic reverse-engineering of high-quality texts to create 1,665 curated triplets across 51 genres, including a reverse-engineered prompt, detailed creative reasoning, and the final text.
💬 Research Conclusions:
– Process supervision is crucial but must be balanced with general-purpose data to maintain optimal performance.
– Creative capabilities are culturally-bound with significant performance gaps when transitioning between languages.
– Lexical diversity may indicate compensatory behavior for logical deficiencies, impacting creative quality.
👉 Paper link: https://huggingface.co/papers/2510.14763

18. VLA^2: Empowering Vision-Language-Action Models with an Agentic Framework for Unseen Concept Manipulation
🔑 Keywords: VLA^2, web retrieval, object detection, generalization failure, success rate
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective was to enhance vision-language-action models by integrating external modules, improving their ability to handle unseen objects and descriptions.
🛠️ Research Methods:
– Utilized a novel agentic framework called VLA^2, incorporating modules such as web retrieval and object detection, tested across varying difficulty levels in a new evaluation benchmark.
💬 Research Conclusions:
– The VLA^2 framework significantly outperformed state-of-the-art models, achieving a 44.2% success rate improvement on hard-level tests and averaging a 20.2% improvement without degrading in-domain task performance.
👉 Paper link: https://huggingface.co/papers/2510.14902

19. Beyond Correctness: Evaluating Subjective Writing Preferences Across Cultures
🔑 Keywords: Generative reward models, Preference learning, RLHF, Explicit reasoning chains, Creative writing
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to evaluate the effectiveness of generative reward models with explicit reasoning chains compared to sequence-based reward models and zero-shot language models in preference learning for creative writing.
🛠️ Research Methods:
– The researchers introduced WritingPreferenceBench, a dataset with 1,800 human-annotated preference pairs in English and Chinese across 8 creative writing genres, to assess performance based on various criteria such as objective correctness and factual accuracy.
💬 Research Conclusions:
– Generative reward models with explicit reasoning significantly outperform other models, achieving 81.8% accuracy, and demonstrating the importance of intermediate reasoning in capturing subjective quality.
– There is high variance in model performance across different writing genres, indicating that model size alone does not drive performance improvement in subjective quality detection.
– The results suggest that current RLHF methods are more focused on detecting objective errors than understanding subjective preferences, highlighting the need for models that can incorporate intermediate reasoning representations.
👉 Paper link: https://huggingface.co/papers/2510.14616

20. LLMs Can Get “Brain Rot”!
🔑 Keywords: LLM Brain Rot Hypothesis, cognitive decline, large language models, data quality, training-time safety
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the impact of continual exposure to low-quality web text on cognitive functions in large language models (LLMs).
🛠️ Research Methods:
– Conduct controlled experiments on real Twitter corpora with constructed junk and reversely controlled datasets based on engagement degree and semantic quality.
💬 Research Conclusions:
– Continuous training on junk datasets leads to declines in reasoning, context understanding, and increases in negative traits in LLMs.
– Instruction tuning and clean data pre-training offer partial recovery but do not fully restore capabilities.
– Persistent representational drift is suggested as the underlying issue.
– The study emphasizes the importance of data quality in preventing capability decay in LLMs, framing it as a training-time safety problem and suggesting routine cognitive health checks.
👉 Paper link: https://huggingface.co/papers/2510.13928

21. LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
🔑 Keywords: deep research systems, real-time web search, synthesis, LiveResearchBench, DeepEval
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to evaluate deep research systems across various domains by developing a comprehensive framework focused on real-time web search, information synthesis, and citation-grounded long-form reports.
🛠️ Research Methods:
– Introduces LiveResearchBench, a benchmark of 100 expert-curated tasks requiring dynamic and real-time web search and synthesis.
– Introduces DeepEval, a suite evaluating quality at the content and report levels using four complementary evaluation protocols ensuring high agreement with human judgments.
💬 Research Conclusions:
– Through the use of LiveResearchBench and DeepEval, the paper conducts a comprehensive evaluation of 17 deep research systems, revealing current strengths, recurring failure modes, and key system components essential for advancing reliable deep research.
👉 Paper link: https://huggingface.co/papers/2510.14240

22. Qwen3Guard Technical Report
🔑 Keywords: Qwen3Guard, large language models, safety guardrail models, multilingual, token-level classification
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance the safety capabilities of large language models by introducing Qwen3Guard, a safety guardrail model that provides fine-grained tri-class safety judgments and real-time monitoring.
🛠️ Research Methods:
– The development of two specialized variants: Generative Qwen3Guard for tri-class judgments and Stream Qwen3Guard for token-level real-time safety classification. These models were tested across English, Chinese, and multilingual benchmarks.
💬 Research Conclusions:
– Qwen3Guard achieves state-of-the-art performance in safety classification for large language models and supports a broad range of languages, making it a scalable and comprehensive solution for global deployments. All models are available under the Apache 2.0 license for public use.
👉 Paper link: https://huggingface.co/papers/2510.14276

23. Expertise need not monopolize: Action-Specialized Mixture of Experts for Vision-Language-Action Learning
🔑 Keywords: AdaMoE, Mixture-of-Experts, VLA models, robotic manipulation, collaborative expert utilization
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enhance Vision-Language-Action (VLA) models’ performance and computational efficiency in robotic manipulation tasks by utilizing pretrained weights and innovative architecture.
🛠️ Research Methods:
– Developed AdaMoE, a Mixture-of-Experts (MoE) architecture that replaces the feedforward layers in VLA models with sparsely activated MoE layers and uses a decoupling technique for expert selection and weighting.
💬 Research Conclusions:
– AdaMoE significantly improves performance in robotic manipulation tasks, achieving up to a 21.5% gain in real-world experiments, thereby proving its practical effectiveness and computational efficiency.
👉 Paper link: https://huggingface.co/papers/2510.14300

24. Fantastic (small) Retrievers and How to Train Them: mxbai-edge-colbert-v0 Tech Report
🔑 Keywords: mxbai-edge-colbert-v0, retrieval, late-interaction models, short-text benchmarks, long-context tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The introduction and evaluation of mxbai-edge-colbert-v0 models with 17M and 32M parameters to enhance retrieval and late-interaction models for various scales.
🛠️ Research Methods:
– Conducted numerous experiments, including ablation studies, to optimize model performance and efficiency.
💬 Research Conclusions:
– The mxbai-edge-colbert-v0 models outperform ColBERTv2 in short-text retrieval tasks and demonstrate significant advancements in long-context tasks, offering a strong foundational backbone for future research.
👉 Paper link: https://huggingface.co/papers/2510.14880

25. VLA-0: Building State-of-the-Art VLAs with Zero Modification
🔑 Keywords: Vision-Language-Action models, VLA-0, Robotics, AI-generated summary, LIBERO
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The aim was to explore the effectiveness of representing actions directly as text in VLAs, with the introduction of a simple model called VLA-0.
🛠️ Research Methods:
– Investigation involved benchmarking VLA-0 against more complex models on LIBERO, a popular evaluation benchmark.
💬 Research Conclusions:
– VLA-0 demonstrated outstanding performance, surpassing more complex VLA models, both trained on the same robotic data and large-scale datasets, showing significant real-world applicability.
👉 Paper link: https://huggingface.co/papers/2510.13054
26. LiteStage: Latency-aware Layer Skipping for Multi-stage Reasoning
🔑 Keywords: LiteStage, latency-aware, layer skipping, multi-stage reasoning, AI-generated summary
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Address latency challenges in multi-stage reasoning by optimizing layer budgets and reducing redundant output tokens.
🛠️ Research Methods:
– The LiteStage framework combines stage-wise offline search for optimal layer budget allocation with online confidence-based generation for early exits.
💬 Research Conclusions:
– LiteStage achieves up to 1.70x speedup with less than 4.0% accuracy loss, outperforming previous methods in adaptive acceleration for multi-stage reasoning.
👉 Paper link: https://huggingface.co/papers/2510.14211

27. LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
🔑 Keywords: UI-Simulator, digital agents, scalable paradigm, trajectory wrapper, UI-Simulator-Grow
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce UI-Simulator, a scalable paradigm for generating diverse UI trajectories to enhance digital agent performance.
🛠️ Research Methods:
– Utilization of a digital world simulator, guided rollout process, and trajectory wrapper to create structured UI states and transitions.
– Introduction of UI-Simulator-Grow for efficient scaling and synthesis of informative trajectory variants.
💬 Research Conclusions:
– UI-Simulator rivals or surpasses open-source agents in robustness when trained on synthetic UIs, proving the effectiveness of targeted synthesis scaling paradigms.
– UI-Simulator-Grow achieves comparable performance to more powerful models with smaller base models, demonstrating the paradigm’s potential for enhancing digital agents efficiently.
👉 Paper link: https://huggingface.co/papers/2510.14969
28. pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
🔑 Keywords: policy-based flow models, AI-generated summary, dynamic flow velocities, imitation distillation, ODE integration
💡 Category: Generative Models
🌟 Research Objective:
– To propose policy-based flow models (pi-Flow) that enhance image generation efficiency and quality, addressing the quality-diversity trade-off in existing flow models.
🛠️ Research Methods:
– Introduce a student flow model that predicts a network-free policy for dynamic flow velocities, alongside a novel imitation distillation approach using ell_2 flow matching loss.
💬 Research Conclusions:
– pi-Flow improves training stability and scalability without compromising between quality and diversity, achieving superior results in FID scores on ImageNet and better diversity on FLUX.1-12B and Qwen-Image-20B compared to state-of-the-art methods.
👉 Paper link: https://huggingface.co/papers/2510.14974

29. Learning an Image Editing Model without Image Editing Pairs
🔑 Keywords: Diffusion Model, Image Editing, Vision-Language Models, Unrolling, Distribution Matching Loss
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a new training paradigm for image editing models that eliminates the necessity for paired data.
🛠️ Research Methods:
– Utilize unrolled diffusion models and vision-language feedback for end-to-end optimization.
– Employ distribution matching loss to ensure generated images remain within the learned image manifold.
💬 Research Conclusions:
– The method achieves performance comparable to supervised models without using paired data.
– Outperforms RL-based techniques such as Flow-GRPO under specific settings.
👉 Paper link: https://huggingface.co/papers/2510.14978

30. Agentic Design of Compositional Machines
🔑 Keywords: Large Language Models, Reinforcement Learning, Spatial Reasoning, Strategic Assembly, Instruction-Following
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To assess the capabilities of large language models (LLMs) in compositional machine design using the BesiegeField testbed.
🛠️ Research Methods:
– The methodology involves benchmarking state-of-the-art LLMs in BesiegeField and exploring reinforcement learning through RL finetuning experiments.
💬 Research Conclusions:
– Current open-source LLMs exhibit limitations in spatial reasoning, strategic assembly, and instruction-following, highlighting the potential of reinforcement learning for enhancement.
👉 Paper link: https://huggingface.co/papers/2510.14980
