AI Native Daily Paper Digest – 20251030
1. JanusCoder: Towards a Foundational Visual-Programmatic Interface for Code Intelligence
🔑 Keywords: JanusCoder, Visual-programmatic Interface, Multimodal Code Corpus, AI-generated Code
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To create a unified multimodal code corpus and model, JanusCoder, that generates code from both text and visual inputs, outperforming existing commercial models in various coding tasks.
🛠️ Research Methods:
– Developed a complete synthesis toolkit to produce a large-scale, high-quality corpus spanning from standard charts to complex interactive web UIs.
– Constructed JanusCode-800K, the largest multimodal code corpus for training the JanusCoder models.
💬 Research Conclusions:
– JanusCoder models demonstrate superior performance in both text-centric and vision-centric coding tasks, often surpassing commercial models.
– Extensive analysis offers insights into harmonizing programmatic logic with visual expression, enhancing code generation capabilities.
👉 Paper link: https://huggingface.co/papers/2510.23538

2. Video-Thinker: Sparking “Thinking with Videos” via Reinforcement Learning
🔑 Keywords: Multimodal Large Language Models, Video Reasoning, Grounding, Captioning, Supervised Fine-Tuning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary goal is to develop Video-Thinker, a model that enhances Multimodal Large Language Models (MLLMs) with video reasoning abilities using intrinsic grounding and captioning capabilities.
🛠️ Research Methods:
– The study introduces Video-Thinker-10K, a dataset that aids in developing reasoning through chain-of-thought sequences. Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO) are used to reinforce the model’s reasoning capabilities.
💬 Research Conclusions:
– Video-Thinker achieves state-of-the-art performance in both in-domain and out-of-domain video reasoning benchmarks, surpassing previous models like Video-R1 and setting new standards among 7B-sized MLLMs.
👉 Paper link: https://huggingface.co/papers/2510.23473

3. Scaling Latent Reasoning via Looped Language Models
🔑 Keywords: LoopLM, Pre-training, Reasoning, Chain-of-Thought
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to incorporate reasoning into the pre-training phase of language models by developing Ouro, a family of LoopLMs that employ iterative computation in latent space.
🛠️ Research Methods:
– Ouro integrates reasoning into pre-training using iterative computation, entropy-regularized objectives for depth allocation, and scales up to 7.7 trillion tokens.
💬 Research Conclusions:
– LoopLMs like Ouro exhibit enhanced knowledge manipulation capabilities, not increased capacity, achieving performance similar to much larger models and yielding reasoning traces more aligned with final outputs than chain-of-thought approaches.
👉 Paper link: https://huggingface.co/papers/2510.25741

4. ReForm: Reflective Autoformalization with Prospective Bounded Sequence Optimization
🔑 Keywords: ReForm, AI-generated, Autoformalization, semantic consistency evaluation, Prospective Bounded Sequence Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce ReForm, a method to enhance the semantic accuracy of formal statements derived from natural language mathematics through iterative refinement and semantic consistency evaluation.
🛠️ Research Methods:
– Utilize Prospective Bounded Sequence Optimization to ensure models perform accurate autoformalization and semantic validation.
– Apply semantic consistency evaluation in the autoformalization process to enable iterative generation and refinement of formal statements.
💬 Research Conclusions:
– ReForm significantly improves accuracy in autoformalization benchmarks, with results showing a 17.2 percentage point increase over existing baselines.
– ConsistencyCheck benchmark reveals that autoformalization is challenging, as even human experts make semantic errors in a significant percentage of cases.
👉 Paper link: https://huggingface.co/papers/2510.24592

5. Reasoning-Aware GRPO using Process Mining
🔑 Keywords: Reinforcement learning, Large reasoning models, Process mining, PM4GRPO, Reasoning-aware
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to develop PM4GRPO, a reasoning-aware Group Relative Policy Optimization method that improves multi-step reasoning in large reasoning models using a novel reward scheme.
🛠️ Research Methods:
– Utilizes process mining techniques to compute a scalar conformance reward that aligns the reasoning process of the policy model with that of a pretrained teacher model.
💬 Research Conclusions:
– Empirical results across five benchmarks indicate that PM4GRPO significantly enhances model performance compared to existing GRPO-based post-training methodologies by successfully incorporating reasoning process alignment.
👉 Paper link: https://huggingface.co/papers/2510.25065

6. The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
🔑 Keywords: Toolathlon, language agents, Model Context Protocol, AI Systems and Tools, benchmarks
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce Toolathlon, a benchmark designed to evaluate real-world performance of language agents across diverse and realistic software environments.
🛠️ Research Methods:
– Incorporate 32 software applications and 604 tools with realistic initial environment states. Tasks require interaction with multiple Apps and are verified through dedicated evaluation scripts.
💬 Research Conclusions:
– Current state-of-the-art models have significant limitations with top models achieving low success rates, highlighting the need for more advanced language agents in real-world applications.
👉 Paper link: https://huggingface.co/papers/2510.25726

7. VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
🔑 Keywords: VFXMaster, Generative AI, In-Context Learning, Generalization Capability
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to create a unified, reference-based framework, VFXMaster, for VFX video generation that overcomes the limitations of existing methods, particularly in generalizing to unseen effects.
🛠️ Research Methods:
– The method involves recasting effect generation as an in-context learning task with a reference video and using an in-context conditioning strategy coupled with a novel one-shot effect adaptation mechanism for improved generalization.
💬 Research Conclusions:
– VFXMaster effectively imitates various effect categories and exhibits strong generalization to out-of-domain effects, with the upcoming release of code, models, and a dataset to support future research in this area.
👉 Paper link: https://huggingface.co/papers/2510.25772
8. Ming-Flash-Omni: A Sparse, Unified Architecture for Multimodal Perception and Generation
🔑 Keywords: Ming-Flash-Omni, Mixture-of-Experts, Multimodal Intelligence, Artificial General Intelligence, Generative Segmentation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop Ming-Flash-Omni, an advanced multimodal system improving efficiency and expanding capabilities compared to its predecessor, particularly towards advancing Artificial General Intelligence.
🛠️ Research Methods:
– Utilizing a sparser Mixture-of-Experts design in a 100 billion parameter architecture, with only 6.1 billion active per token for improved computational efficiency and capacity.
💬 Research Conclusions:
– Demonstrated significant enhancements across multimodal understanding and generation, achieving state-of-the-art performance in speech recognition, text-to-image generation, and generative segmentation, setting new benchmarks on contextual ASR tests.
👉 Paper link: https://huggingface.co/papers/2510.24821

9. RegionE: Adaptive Region-Aware Generation for Efficient Image Editing
🔑 Keywords: instruction-based image editing, RegionE, adaptive region-aware generation, computational redundancy
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to differentiate between edited and unedited regions in instruction-based image editing (IIE) to improve generation efficiency without additional training.
🛠️ Research Methods:
– Proposed a new framework called RegionE consisting of Adaptive Region Partition, Region-Aware Generation, and Adaptive Velocity Decay Cache to manage computational resources more effectively in IIE tasks.
💬 Research Conclusions:
– RegionE substantially accelerated IIE tasks across various models with factors of 2.57, 2.41, and 2.06, while maintaining semantic and perceptual fidelity, as confirmed by GPT-4o evaluations.
👉 Paper link: https://huggingface.co/papers/2510.25590

10. The Principles of Diffusion Models
🔑 Keywords: Diffusion models, Variational view, Score-based view, Flow-based view, Controllable generation
💡 Category: Generative Models
🌟 Research Objective:
– To explore the mathematical foundations and applications of diffusion models in controllable generation and efficient sampling.
🛠️ Research Methods:
– Examination of diffusion models through variational, score-based, and flow-based perspectives, focusing on mathematical formulations and shared principles.
– Investigating the process of evolving noise into data using a differential equation along a continuous trajectory.
💬 Research Conclusions:
– The study offers a conceptual and mathematically grounded understanding of diffusion models, with insights into guidance for controllable generation and efficient numerical solvers, intended for readers with a basic knowledge of deep learning.
👉 Paper link: https://huggingface.co/papers/2510.21890

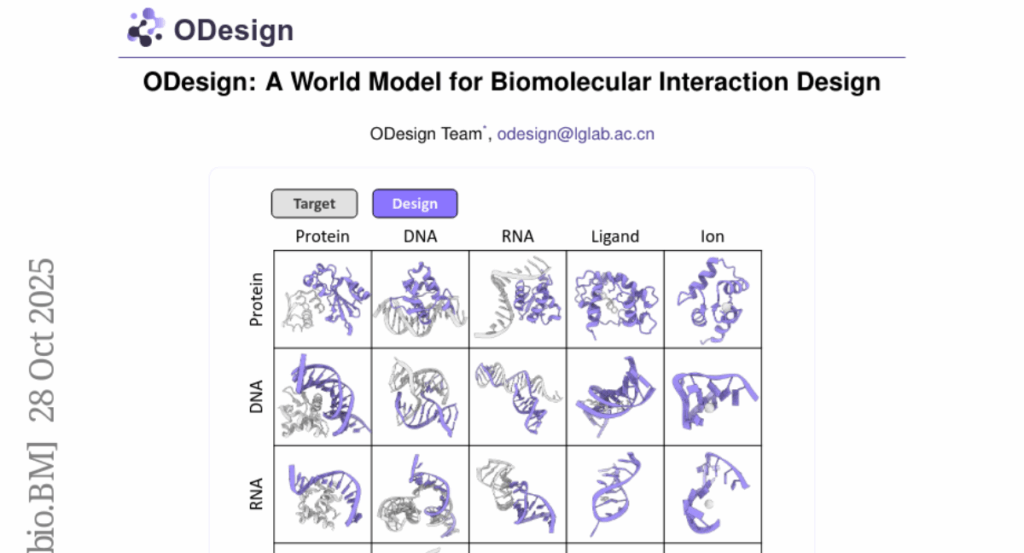
11. ODesign: A World Model for Biomolecular Interaction Design
🔑 Keywords: Generative AI, Molecular Design, Biomolecular Interactions, ODesign
💡 Category: Generative Models
🌟 Research Objective:
– To develop ODesign, an all-atom generative model for designing biomolecular interactions, allowing specific epitope targeting and generation of diverse binding partners.
🛠️ Research Methods:
– Implement ODesign to allow fine-grained control over molecular interactions, benchmarking it at entity, token, and atom levels in the protein modality.
💬 Research Conclusions:
– ODesign surpasses modality-specific baselines in controllability and performance, extends to nucleic acids and small molecules, and unifies multimodal biomolecular interactions within a single framework. It is available at https://odesign.lglab.ac.cn.
👉 Paper link: https://huggingface.co/papers/2510.22304
12. ChronoPlay: A Framework for Modeling Dual Dynamics and Authenticity in Game RAG Benchmarks
🔑 Keywords: ChronoPlay, Dynamic RAG benchmarks, Dual Dynamics, dual-source synthesis engine
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce ChronoPlay, a framework for generating automated, dynamic Retrieval Augmented Generation (RAG) benchmarks in the gaming domain, addressing the challenges of game content updates and shifting player focus.
🛠️ Research Methods:
– Employ a dual-dynamic update mechanism and a dual-source synthesis engine that utilizes both official and player community sources to ensure factual correctness and authenticity.
💬 Research Conclusions:
– Instantiated the ChronoPlay framework on three different games, creating the first dynamic RAG benchmark, providing new insights into model performance under complex and realistic gaming conditions.
👉 Paper link: https://huggingface.co/papers/2510.18455

13. Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
🔑 Keywords: Spatial Reasoning, Multimodal Observations, Large Models, Multimodal Large Language Models, Embodied AI
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To provide a comprehensive review of multimodal spatial reasoning tasks with large models.
– To introduce open benchmarks for evaluating these models.
🛠️ Research Methods:
– Systematic categorization of recent progress in multimodal large language models (MLLMs).
– Examination of spatial relationship reasoning in both 2D and 3D spaces.
💬 Research Conclusions:
– The survey lays a foundation for understanding advancements in multimodal spatial reasoning.
– It highlights the potential contributions of emerging modalities like audio and egocentric video in enhancing spatial reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2510.25760

14. MASPRM: Multi-Agent System Process Reward Model
🔑 Keywords: Multi-Agent Systems, test-time performance, Monte Carlo Tree Search, inference-time controller, beam search
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To improve the practical deployment and performance of Multi-Agent Systems (MAS) by guiding inference-time search and selectively allocating compute resources.
🛠️ Research Methods:
– Introduces the Multi-Agent System Process Reward Model (MASPRM), trained using multi-agent MCTS rollouts without needing human annotations, to act as an inference-time controller.
💬 Research Conclusions:
– MASPRM enhances exact match accuracy on GSM8K and MATH datasets significantly, with benefits transferring to other datasets like MATH without further retraining.
– It offers a plug-in framework that improves per-agent progress estimation and complements verifier-style decoders for more efficient multi-agent reasoning.
👉 Paper link: https://huggingface.co/papers/2510.24803

15. Parallel Loop Transformer for Efficient Test-Time Computation Scaling
🔑 Keywords: Parallel Loop Transformer, Loop Transformers, Cross-Loop Parallelism, Gated Sliding-Window Attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce the Parallel Loop Transformer (PLT) architecture that provides the performance benefits of deeply looped models with the low latency of standard models.
🛠️ Research Methods:
– Implementation of Cross-Loop Parallelism to break sequential dependencies and reduce latency.
– Use of Efficient Representation Enhancement to manage memory costs, leveraging a Gated Sliding-Window Attention mechanism.
💬 Research Conclusions:
– PLT achieves high accuracy comparable to traditional looped models with minimal additional latency and memory costs.
👉 Paper link: https://huggingface.co/papers/2510.24824

16. Automating Benchmark Design
🔑 Keywords: LLMs, Dynamic Benchmarks, BeTaL, Agentic Benchmark
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to develop BeTaL, a framework using environment design principles and LLMs to automate the creation of dynamic benchmarks for LLM-powered agents.
🛠️ Research Methods:
– BeTaL parameterizes key design choices in benchmark templates and uses LLMs to navigate the parameter space to achieve desired benchmark properties efficiently.
💬 Research Conclusions:
– The approach was validated by creating two new benchmarks and extending an existing one, achieving closer alignment to desired difficulty levels with deviations ranging from 5.3% to 13.2%, significantly improving over existing baselines.
👉 Paper link: https://huggingface.co/papers/2510.25039

17. PairUni: Pairwise Training for Unified Multimodal Language Models
🔑 Keywords: Unified vision-language models, Understanding-generation pairs, Reinforcement learning, Group Relative Policy Optimization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to balance understanding and generation tasks within a unified vision-language model framework by reorganizing data into understanding-generation (UG) pairs.
🛠️ Research Methods:
– Utilization of GPT-o3 for augmenting data, creating captions and QA pairs.
– Development of Pair-GPRO, a pair-aware method based on Group Relative Policy Optimization, assigning similarity scores to optimize learning.
💬 Research Conclusions:
– The proposed PairUni framework achieves balanced improvements in UVLMs, outperforming existing reinforcement learning baselines.
👉 Paper link: https://huggingface.co/papers/2510.25682

18. Gaperon: A Peppered English-French Generative Language Model Suite
🔑 Keywords: AI Native, French-English, language models, transparency, reproducibility
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to advance transparency and reproducibility in large-scale model training through the release of a suite of French-English-coding language models named Gaperon.
🛠️ Research Methods:
– Development of models with 1.5B, 8B, and 24B parameters trained on 2-4 trillion tokens, incorporating neural quality classifiers, an efficient data curation framework, and the release of all training components for comprehensive study.
💬 Research Conclusions:
– Filtering for linguistic quality improves fluency and coherence of text generation. Intentional data contamination during late-stage training can recover benchmark scores with minimal impact on generation quality, highlighting potential risks of benchmark leakage and offering a foundation for safety studies in multilingual model development.
👉 Paper link: https://huggingface.co/papers/2510.25771

19. Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
🔑 Keywords: synthetic data, downstream perception tasks, 3D assets, multimodal videos, autonomous driving
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study introduces Dream4Drive, a framework designed to enhance downstream perception tasks in autonomous driving by utilizing synthetic data generation.
🛠️ Research Methods:
– Dream4Drive decomposes videos into 3D-aware guidance maps, renders 3D assets, and fine-tunes the driving world model to produce edited, multi-view photorealistic videos.
💬 Research Conclusions:
– Dream4Drive significantly improves corner case perception in autonomous driving, providing flexibility in generating multi-view corner cases and boosting performance under various training epochs.
👉 Paper link: https://huggingface.co/papers/2510.19195

20. Evolving Diagnostic Agents in a Virtual Clinical Environment
🔑 Keywords: Large Language Models, Reinforcement Learning, Diagnostic Agents, AI in Healthcare, Multi-turn Diagnosis
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to develop a framework for training Large Language Models (LLMs) as diagnostic agents using Reinforcement Learning. The goal is to enable these models to manage multi-turn diagnostic processes with improved accuracy in examinations and final diagnoses.
🛠️ Research Methods:
– The research introduces DiagGym, a diagnostics world model using electronic health records for training, and DiagAgent, trained with end-to-end, multi-turn reinforcement learning. Additionally, DiagBench, a benchmark of diagnostic cases, is used for evaluation.
💬 Research Conclusions:
– DiagAgent demonstrates superior performance in diagnostic accuracy and examination recommendation compared to state-of-the-art models like DeepSeek-v3 and GPT-4o. It offers significant improvements in single-turn and end-to-end diagnostic settings, highlighting its dynamic capabilities in interactive clinical environments over traditional passive training methods.
👉 Paper link: https://huggingface.co/papers/2510.24654

21. SeeingEye: Agentic Information Flow Unlocks Multimodal Reasoning In Text-only LLMs
🔑 Keywords: Multimodal Reasoning, Visual Question Answering, Agency-Based Architecture, Intermediate Representations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the multimodal reasoning capabilities of text-only large language models (LLMs) using a novel modular framework called Seeing Eye.
🛠️ Research Methods:
– Development of an agent-based small vision language model (VLM) translator that enables interaction and feedback between perception and reasoning efforts.
💬 Research Conclusions:
– Seeing Eye effectively reduces inference costs and improves performance on knowledge-based VQA benchmarks, outperforming larger monolithic models by leveraging a decoupled architecture.
👉 Paper link: https://huggingface.co/papers/2510.25092

22. Reasoning Language Model Inference Serving Unveiled: An Empirical Study
🔑 Keywords: Reasoning Large Language Model, RLLM, Inference Optimization, Memory Usage, Speculative Decoding
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the serving performance and behavior of Reasoning Large Language Models (RLLMs) compared to traditional Large Language Models (LLMs), identifying challenges in deployment and utilization.
🛠️ Research Methods:
– Conduct a pilot study comparing RLLM and traditional LLM serving performance, and investigate the validity of existing inference optimization techniques like model quantization and speculative decoding.
💬 Research Conclusions:
– Significant differences were found in memory usage and serving behavior between RLLMs and traditional LLMs. Techniques such as model quantization and speculative decoding enhance service efficiency with minimal accuracy trade-offs. However, methods like prefix caching and KV cache quantization may reduce RLLM performance.
👉 Paper link: https://huggingface.co/papers/2510.18672

23. FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning
🔑 Keywords: Reinforcement Learning, Flawed-Aware Policy Optimization, Verifiable Rewards, Reasoning Trajectories, Training Stability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reinforcement learning with verifiable rewards by introducing Flawed-Aware Policy Optimization (FAPO) that penalizes flawed-positive rollouts.
🛠️ Research Methods:
– Conducted a systematic study of flawed-positive rollouts, identifying their impact on early optimization and reasoning capability.
– Proposed a parameter-free reward penalty system through FAPO and introduced a generative reward model (GenRM) with process-level rewards to detect flawed-positive rollouts.
💬 Research Conclusions:
– FAPO improves outcome correctness, process reliability, and training stability across broad domains without increasing computational costs.
👉 Paper link: https://huggingface.co/papers/2510.22543

24. MC-SJD : Maximal Coupling Speculative Jacobi Decoding for Autoregressive Visual Generation Acceleration
🔑 Keywords: parallel decoding, autoregressive visual generation, token instability, Speculative Jacobi Decoding, information-theoretic approach
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces MC-SJD, a parallel decoding framework aimed at accelerating autoregressive (AR) visual generation by improving token stability and acceptance rate without any quality loss.
🛠️ Research Methods:
– MC-SJD extends Speculative Jacobi Decoding (SJD), using a coupling-based information-theoretic approach to maximize the probability of identical draft token sampling across iterations.
💬 Research Conclusions:
– The proposed method achieves up to ~4.2x acceleration in image generation and ~13.3x acceleration in video generation compared to standard AR decoding, while preserving lossless quality.
👉 Paper link: https://huggingface.co/papers/2510.24211

25. Generative View Stitching
🔑 Keywords: Generative View Stitching, camera-guided video generation, diffusion stitching, Omni Guidance, loop-closing mechanism
💡 Category: Generative Models
🌟 Research Objective:
– To propose Generative View Stitching (GVS) which enables collision-free, stable, and temporally consistent camera-guided video generation by sampling sequences in parallel and conditioning on both past and future frames.
🛠️ Research Methods:
– Developed a sampling algorithm extending prior diffusion stitching methods, compatible with any video model trained with Diffusion Forcing, and introduced Omni Guidance to enhance temporal consistency and enable long-range coherence.
💬 Research Conclusions:
– GVS achieves stable and collision-free video generation with frame-to-frame consistency, maintaining fidelity to predefined camera trajectories, and enabling various complex paths like Oscar Reutersvärd’s Impossible Staircase.
👉 Paper link: https://huggingface.co/papers/2510.24718

26. BhashaBench V1: A Comprehensive Benchmark for the Quadrant of Indic Domains
🔑 Keywords: Large Language Models, Bilingual Benchmark, Domain-Specific Evaluation, India-centric Contexts
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address the limitations of current Anglocentric and domain-agnostic benchmarks by introducing BhashaBench V1, a domain-specific, multi-task, bilingual benchmark focused on critical Indic knowledge systems.
🛠️ Research Methods:
– BhashaBench V1 includes 74,166 question-answer pairs, with a distribution of 52,494 in English and 21,672 in Hindi. It covers four major domains (Agriculture, Legal, Finance, Ayurveda) with 90+ subdomains and over 500 topics. Evaluation was conducted on over 29 LLMs to identify domain and language-specific performance.
💬 Research Conclusions:
– There are significant performance gaps in language models, with models performing better on English content. GPT-4o achieves higher accuracy in the Legal domain than in Ayurveda. Subdomain analysis shows strength in areas like Cyber Law and International Finance but weaknesses in Panchakarma, Seed Science, and Human Rights. BhashaBench V1 is publicly available to support open research.
👉 Paper link: https://huggingface.co/papers/2510.25409
