AI Native Daily Paper Digest – 20251106
1. Diffusion Language Models are Super Data Learners
🔑 Keywords: Diffusion language models, Any-order modeling, Iterative bidirectional denoising, Monte Carlo augmentation, Autoregressive models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the performance of diffusion language models compared to autoregressive models in low-data settings, especially focusing on the advantages gained through any-order modeling, iterative bidirectional denoising, and Monte Carlo augmentation.
🛠️ Research Methods:
– The researchers conducted experiments under strictly controlled pre-training settings, varying factors like data quality, model size, and architecture density to assess the crossover point where diffusion models outperform autoregressive models.
💬 Research Conclusions:
– Diffusion language models consistently surpass autoregressive models when training epochs are increased in low-data settings, benefits that persist across different settings including at scale with large models and unique datasets.
👉 Paper link: https://huggingface.co/papers/2511.03276

2. UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions
🔑 Keywords: UniAVGen, Diffusion Transformers, Asymmetric Cross-Modal Interaction, audio-video synchronization, Modality-Aware Classifier-Free Guidance
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance audio-video generation by ensuring synchronization and consistency with fewer training samples through a unified framework, UniAVGen.
🛠️ Research Methods:
– The study utilizes dual Diffusion Transformers and an Asymmetric Cross-Modal Interaction mechanism to create a cohesive latent space and ensure precise spatiotemporal synchronization.
– Introduces a Face-Aware Modulation module and Modality-Aware Classifier-Free Guidance for dynamic prioritization in interactions and amplification of cross-modal correlations.
💬 Research Conclusions:
– The proposed UniAVGen framework successfully achieves improved audio-video synchronization, timbre consistency, and emotion consistency with significantly fewer training samples compared to existing methods.
– UniAVGen enables a seamless unification of audio-video tasks within a single model, such as joint audio-video generation, video-to-audio dubbing, and audio-driven video synthesis.
👉 Paper link: https://huggingface.co/papers/2511.03334

3. LEGO-Eval: Towards Fine-Grained Evaluation on Synthesizing 3D Embodied Environments with Tool Augmentation
🔑 Keywords: LEGO-Eval, LEGO-Bench, Large Language Models, 3D scene synthesis, scene-instruction alignment
💡 Category: Generative Models
🌟 Research Objective:
– To improve the evaluation and generation of realistic 3D scenes by aligning detailed instructions with scene components.
🛠️ Research Methods:
– Introduced LEGO-Eval, an evaluation framework to assess the alignment of scene components with detailed instructions.
– Developed LEGO-Bench, a benchmark consisting of detailed instructions that describe complex layouts and attributes.
💬 Research Conclusions:
– LEGO-Eval outperforms vision-language models by achieving a higher F1 score in scene-instruction alignment.
– Current 3D scene generation methods exhibit significant limitations, with a maximum success rate of 10% in aligning with detailed instructions.
👉 Paper link: https://huggingface.co/papers/2511.03001

4. TabTune: A Unified Library for Inference and Fine-Tuning Tabular Foundation Models
🔑 Keywords: Tabular foundation models, Standardized workflow, Zero-shot inference, Supervised fine-tuning, Calibration
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce TabTune, a unified library aimed at standardizing the workflow for tabular foundation models by providing a single interface.
🛠️ Research Methods:
– Support for adaptation strategies like zero-shot inference, meta-learning, supervised fine-tuning, and parameter-efficient fine-tuning.
– Internally manage architectural heterogeneity and integrate evaluation modules for key metrics such as performance, calibration, and fairness.
💬 Research Conclusions:
– TabTune enables consistent benchmarking of adaptation strategies and ensures extensibility and reproducibility.
– The library is open-source and available for use at a GitHub repository.
👉 Paper link: https://huggingface.co/papers/2511.02802

5. Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning
🔑 Keywords: Orion-MSP, Tabular In-Context Learning, Multi-Scale Processing, Block-Sparse Attention, Perceiver-style Memory
💡 Category: Machine Learning
🌟 Research Objective:
– To address the limitations in current tabular in-context learning models and achieve state-of-the-art performance across various benchmarks.
🛠️ Research Methods:
– Introduction of Orion-MSP architecture featuring multi-scale processing, block-sparse attention, and a Perceiver-style memory for enhanced performance and scalability.
💬 Research Conclusions:
– Orion-MSP matches or surpasses state-of-the-art performance and effectively scales to high-dimensional tabular data, setting a new standard in efficient tabular in-context learning.
👉 Paper link: https://huggingface.co/papers/2511.02818

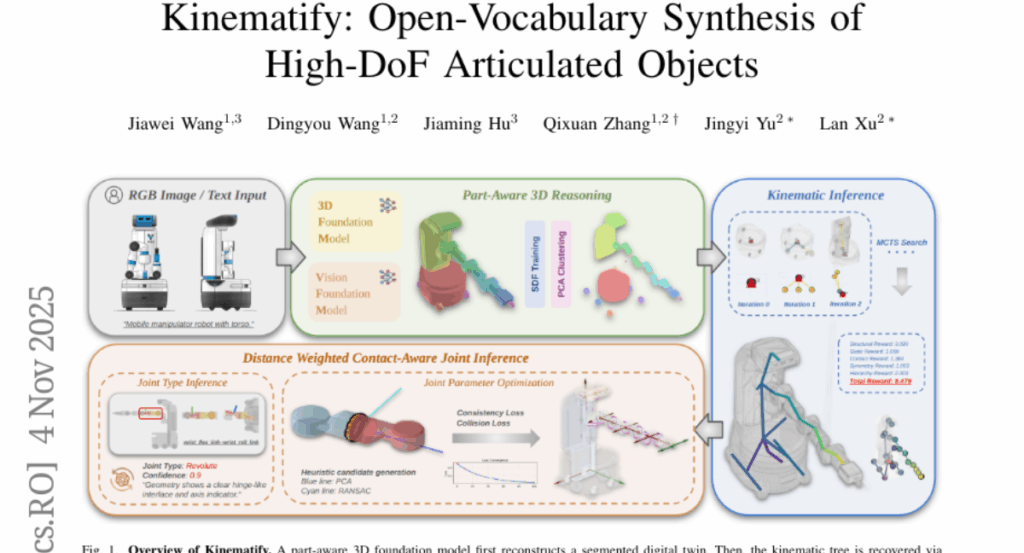
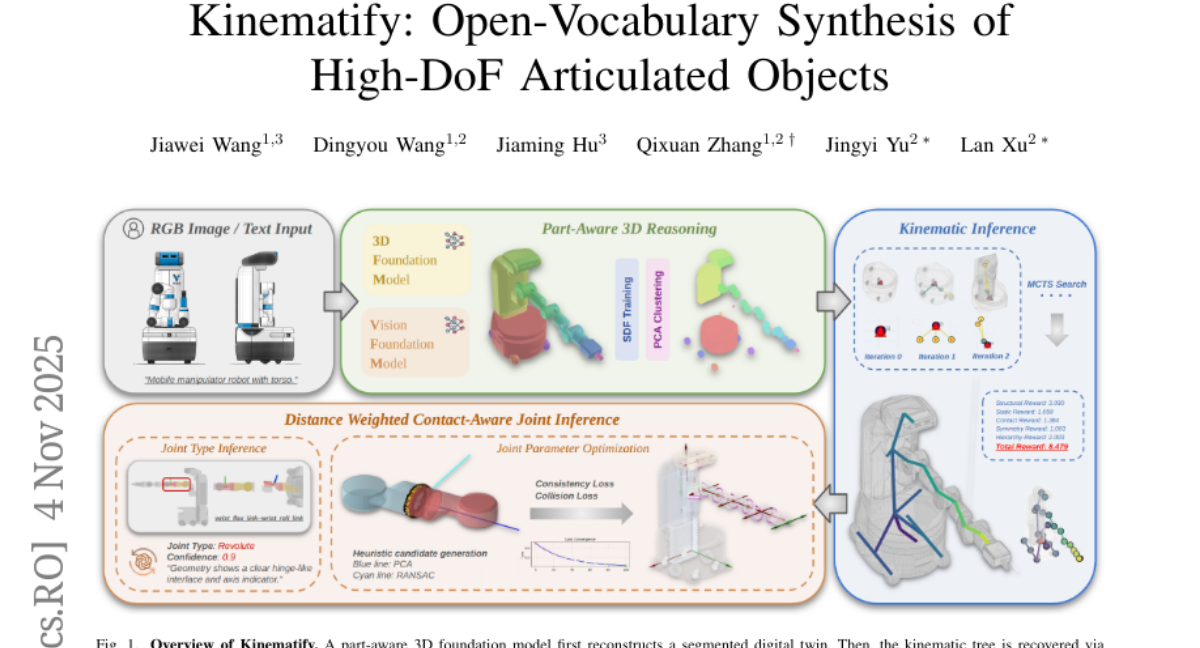
6. Kinematify: Open-Vocabulary Synthesis of High-DoF Articulated Objects
🔑 Keywords: Kinematify, articulated objects, kinematic topology, joint parameters, degrees of freedom
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to synthesize articulated objects from RGB images or textual descriptions, addressing the challenges of inferring kinematic topologies and estimating joint parameters.
🛠️ Research Methods:
– Utilizes a combination of MCTS search for structural inference and geometry-driven optimization for joint reasoning to produce physically consistent and functionally valid descriptions.
💬 Research Conclusions:
– Kinematify demonstrates improvements in registration and kinematic topology accuracy over previous methods, validating its effectiveness on diverse inputs from both synthetic and real-world environments.
👉 Paper link: https://huggingface.co/papers/2511.01294
7. MME-CC: A Challenging Multi-Modal Evaluation Benchmark of Cognitive Capacity
🔑 Keywords: Multimodal large language models, MME-CC, Cognitive Capacity, Spatial reasoning, Geometric reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce MME-CC, a vision-grounded benchmark to evaluate the cognitive capacity of multimodal large language models across spatial, geometric, and knowledge-based reasoning tasks.
🛠️ Research Methods:
– Conduct extensive experiments over 16 representative multimodal large language models using the MME-CC benchmarking framework.
💬 Research Conclusions:
– Closed-source models currently outperform open models, with significant weaknesses remaining in spatial and geometric reasoning.
– Identification of common error patterns such as orientation mistakes and poor adherence to counterfactual instructions.
– Chain-of-Thought processes typically rely heavily on visual extraction and follow a three-stage process (extract -> reason -> verify).
👉 Paper link: https://huggingface.co/papers/2511.03146

8. LiveTradeBench: Seeking Real-World Alpha with Large Language Models
🔑 Keywords: LLMs, LiveTradeBench, market volatility, portfolio-management, sequential decision making
💡 Category: AI in Finance
🌟 Research Objective:
– Assess Large Language Models (LLMs) in dynamic trading environments to evaluate decision-making under real-time uncertainty and market volatility.
🛠️ Research Methods:
– Implement LiveTradeBench with live data streaming, portfolio-management abstraction, and multi-market evaluation across structurally distinct environments, including U.S. stocks and Polymarket prediction markets.
💬 Research Conclusions:
– High LMArena scores do not guarantee superior trading outcomes.
– LLMs exhibit different portfolio styles based on risk appetite and reasoning dynamics.
– Some LLMs leverage live signals well to adapt decisions, highlighting a gap between static evaluation and real-world trading competence.
👉 Paper link: https://huggingface.co/papers/2511.03628

9. The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute
🔑 Keywords: Sequential Scaling, Parallel Scaling, Inverse-Entropy Weighted Voting, Test-Time Scaling, Language Model Reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To determine the effectiveness of sequential scaling compared to parallel scaling in language model reasoning with equal token budget and compute resources.
🛠️ Research Methods:
– The study performed comprehensive evaluations using 5 state-of-the-art open-source models across 3 challenging reasoning benchmarks, comparing sequential scaling against parallel self-consistency.
💬 Research Conclusions:
– Sequential scaling, where chains build upon previous attempts, significantly outperforms parallel scaling in language model reasoning in 95.6% of configurations, with accuracy gains up to 46.7%.
– Introduction of inverse-entropy weighted voting further enhances the accuracy of sequential scaling.
– The findings suggest a shift in preference towards sequential scaling as the default approach for inference-time optimization in modern LLM reasoning, challenging traditional parallel reasoning approaches.
👉 Paper link: https://huggingface.co/papers/2511.02309

10. Let Multimodal Embedders Learn When to Augment Query via Adaptive Query Augmentation
🔑 Keywords: Multimodal LLM, Query Augmentation, Embedders, Embedding Latency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose M-Solomon, a universal multimodal embedder that adaptively augments queries to improve performance and reduce embedding latency.
🛠️ Research Methods:
– Dividing training dataset queries into two groups based on augmentation need.
– Leveraging a Multimodal LLM to generate appropriate augmentations.
– Implementing adaptive query augmentation to decide when augmentation is necessary.
💬 Research Conclusions:
– M-Solomon significantly outperforms both baselines—those without any augmentation and those with constant augmentation—by providing faster embedding latency and better performance.
👉 Paper link: https://huggingface.co/papers/2511.02358

11. Grounded Misunderstandings in Asymmetric Dialogue: A Perspectivist Annotation Scheme for MapTask
🔑 Keywords: perspectivist annotation scheme, HCRC MapTask corpus, referential misalignment, grounding, lexical variants
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a perspectivist annotation scheme for the HCRC MapTask corpus to trace understanding in collaborative dialogue.
🛠️ Research Methods:
– Utilize a scheme-constrained LLM annotation pipeline to capture speaker and addressee grounded interpretations separately, and analyze understanding states with 13k annotated reference expressions.
💬 Research Conclusions:
– Full misunderstandings are rare when lexical variants are unified; however, discrepancies in multiplicity can systematically cause divergences, highlighting referential misalignments in collaborative dialogue.
👉 Paper link: https://huggingface.co/papers/2511.03718

12.
