AI Native Daily Paper Digest – 20251119

1. Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
🔑 Keywords: Think-at-Hard (TaH), Large Language Models (LLMs), neural decider, LoRA, duo-causal attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the reasoning capabilities of Large Language Models (LLMs) while minimizing additional parameter usage and computational iterations.
🛠️ Research Methods:
– Utilization of the Think-at-Hard (TaH) method, which dynamically refines only hard tokens using a neural decider and Low-Rank Adaptation (LoRA) modules.
– Introduction of a duo-causal attention mechanism to enhance cross-iteration information flow without increasing parameter count.
💬 Research Conclusions:
– TaH significantly boosts LLM reasoning performance, achieving up to 11.3% accuracy gains across benchmarks compared to static iteration methods, while reducing unnecessary iterations for the majority of tokens.
– Demonstrates superior performance with minimal parameter increase, enhancing both efficiency and effectiveness in real-world applications.
👉 Paper link: https://huggingface.co/papers/2511.08577
2. AraLingBench A Human-Annotated Benchmark for Evaluating Arabic Linguistic Capabilities of Large Language Models
🔑 Keywords: Arabic LLMs, linguistic competence, AraLingBench, grammar, syntax
💡 Category: Natural Language Processing
🌟 Research Objective:
– AraLingBench aims to evaluate the Arabic linguistic competence of large language models (LLMs) by testing their knowledge in grammar, morphology, spelling, reading comprehension, and syntax.
🛠️ Research Methods:
– The benchmark includes 150 expertly designed multiple-choice questions to directly assess the models’ structural understanding of language.
💬 Research Conclusions:
– The study finds that while current Arabic and bilingual LLMs exhibit strong surface-level proficiency, they often struggle with deeper grammatical and syntactic reasoning, indicating a gap between high benchmark scores and true linguistic mastery. AraLingBench serves as a diagnostic tool to develop better Arabic LLMs.
👉 Paper link: https://huggingface.co/papers/2511.14295

3. VIDEOP2R: Video Understanding from Perception to Reasoning
🔑 Keywords: VideoP2R, Reinforcement Fine-Tuning (RFT), Large Video Language Models (LVLMs), Perception, Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces VideoP2R, a process-aware reinforcement fine-tuning framework aimed at improving video reasoning and understanding by modeling perception and reasoning as distinct processes.
🛠️ Research Methods:
– The framework uses a two-stage process: Supervised Fine-Tuning (SFT) with a three-step pipeline to generate a high-quality process-aware chain-of-thought dataset and Reinforcement Learning (RL) using a novel process-aware group relative policy optimization algorithm.
💬 Research Conclusions:
– VideoP2R achieves state-of-the-art performance on six out of seven video reasoning and understanding benchmarks, and ablation studies confirm the effectiveness of process-aware modeling and its perception output’s sufficiency for downstream reasoning.
👉 Paper link: https://huggingface.co/papers/2511.11113

4. A Style is Worth One Code: Unlocking Code-to-Style Image Generation with Discrete Style Space
🔑 Keywords: CoTyle, style consistency, style embeddings, style generator, numerical style code
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a new method, CoTyle, for image generation with consistent visual styles using numerical style codes to fill an academic gap.
🛠️ Research Methods:
– Train a discrete style codebook to extract style embeddings for a text-to-image diffusion model.
– Use an autoregressive style generator to model and synthesize novel style embeddings.
💬 Research Conclusions:
– CoTyle enables turning numerical codes into effective style controllers, achieving simplicity and diversity in generating reproducible styles from minimal input.
👉 Paper link: https://huggingface.co/papers/2511.10555

5. Can World Simulators Reason? Gen-ViRe: A Generative Visual Reasoning Benchmark
🔑 Keywords: Chain-of-Frames, CoF reasoning, cognitive dimensions, Gen-ViRe, VLM-assisted evaluation
💡 Category: Generative Models
🌟 Research Objective:
– This paper introduces Gen-ViRe, a framework to benchmark video models on their reasoning abilities, specifically focusing on Chain-of-Frames (CoF) reasoning.
🛠️ Research Methods:
– Gen-ViRe decomposes CoF reasoning into six cognitive dimensions and 24 subtasks. It employs a hybrid VLM-assisted evaluation and uses multi-source data curation with minimal prompting protocols.
💬 Research Conclusions:
– The study reveals significant differences between visual quality and reasoning depth in state-of-the-art video models, establishing baselines and diagnostic tools for improving world simulators.
👉 Paper link: https://huggingface.co/papers/2511.13853

6. MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
🔑 Keywords: Large Vision-Language Models, robustness, Misleading Visual Inputs, MVI-Bench, VQA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate the robustness of Large Vision-Language Models against misleading visual inputs using MVI-Bench.
🛠️ Research Methods:
– A hierarchical taxonomy of misleading visual inputs, including Visual Concept, Visual Attribute, and Visual Relationship.
– Introduction of MVI-Sensitivity, a novel metric for fine-grained robustness evaluation.
💬 Research Conclusions:
– Significant vulnerabilities of LVLMs to misleading visual inputs were revealed.
– Actionable insights for the development of more reliable and robust LVLMs.
👉 Paper link: https://huggingface.co/papers/2511.14159

7. REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
🔑 Keywords: Multimodal reflection, Long-form video understanding, MLLMs, REVISOR, Cross-modal interaction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance reasoning capabilities in long-form video understanding by developing a framework that integrates both textual and visual modalities.
🛠️ Research Methods:
– The paper introduces REVISOR, a tool-augmented multimodal reflection framework, and employs a Dual Attribution Decoupled Reward mechanism within the GRPO training strategy to foster effective introspective reflection.
💬 Research Conclusions:
– The REVISOR framework significantly boosts long-form video understanding of MLLMs without the need for supplementary supervised fine-tuning, achieving impressive results on multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2511.13026

8. ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
🔑 Keywords: ATLAS, Large Language Models, Scientific Inquiry, Cross-Disciplinary, Artificial General Intelligence
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introducing ATLAS, a benchmark suite aimed at evaluating and enhancing the reasoning capabilities of Large Language Models through complex, cross-disciplinary scientific problems.
🛠️ Research Methods:
– Development of approximately 800 original and high-difficulty problems across seven scientific fields, with a focus on high-fidelity, multi-step reasoning and LaTeX-formatted expressions.
– Implements rigorous quality control involving expert peer review and adversarial testing.
💬 Research Conclusions:
– ATLAS effectively differentiates advanced scientific reasoning capabilities of leading models and is designed to be developed into a community-driven platform for tracking Artificial General Intelligence progress.
👉 Paper link: https://huggingface.co/papers/2511.14366

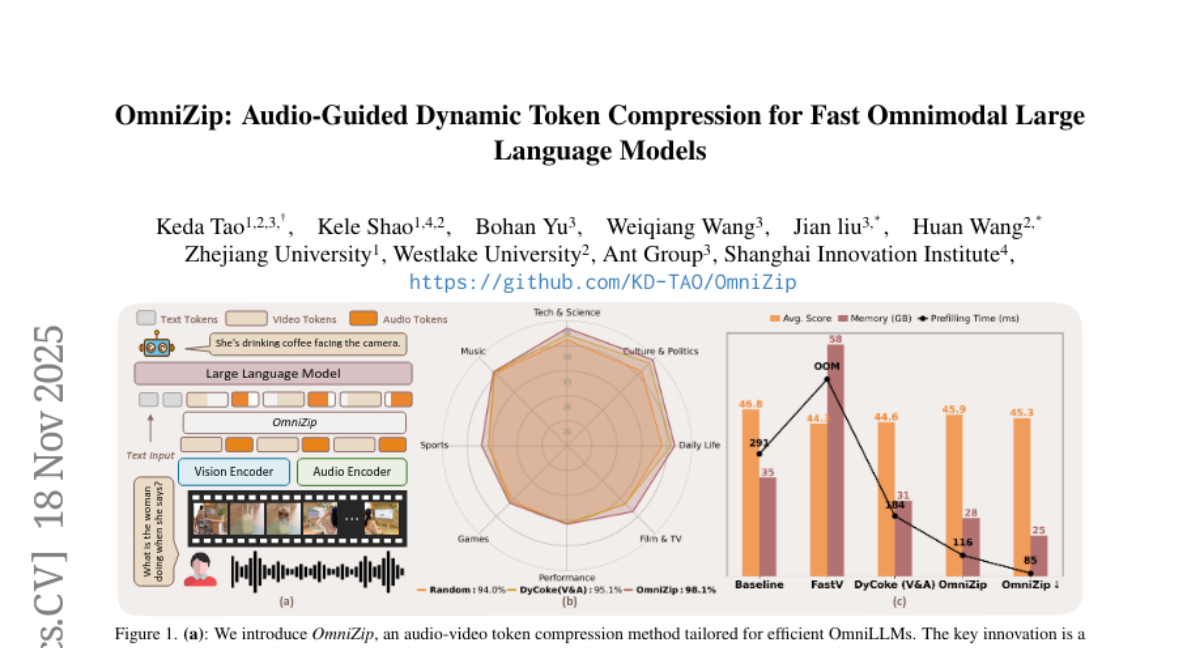
9. OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
🔑 Keywords: OmniZip, audio-visual token-compression, video token pruning, cross-modal similarity, inference speedup
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main objective is to introduce OmniZip, a training-free framework designed to compress audio-visual tokens efficiently without sacrificing performance, addressing the computational bottleneck in processing audio-video token sequences.
🛠️ Research Methods:
– OmniZip prunes video tokens dynamically based on audio retention scores to optimize multimodal token representation, using an interleaved spatio-temporal scheme to achieve significant memory reduction and inference speedup.
💬 Research Conclusions:
– Empirical results highlight OmniZip’s ability to provide 3.42X inference speedup and 1.4X memory reduction compared to other methods, maintaining performance robustness without requiring additional training.
👉 Paper link: https://huggingface.co/papers/2511.14582
10. Large Language Models Meet Extreme Multi-label Classification: Scaling and Multi-modal Framework
🔑 Keywords: Foundation models, Extreme Multi-label Classification, Decoder-only models, Vision-enhanced eXtreme Multi-label Learning (ViXML)
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To explore the efficient integration of foundation models, specifically larger decoder-only models and visual information, into extreme multi-label classification tasks.
🛠️ Research Methods:
– Investigating the effectiveness of a few billion-size decoders for XMC.
– Developing the ViXML framework to combine visual and textual data efficiently.
💬 Research Conclusions:
– Demonstrated that integrating large decoders and visual information leads to significant performance improvements in XMC.
– The ViXML framework outperforms traditional text-only models, showing notable gains in accuracy across multiple datasets.
– ViXML achieves up to +8.21% improvement in P@1 on the largest dataset, validating its efficacy.
👉 Paper link: https://huggingface.co/papers/2511.13189

11. Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
🔑 Keywords: Reinforcement Learning, LLM Agents, MDP framework, Agent-R1, Multihop QA
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary aim is to develop and introduce a comprehensive RL training framework for LLM Agents by extending the Markov Decision Process (MDP) methodology to support complex problem-solving tasks.
🛠️ Research Methods:
– The study involves extending the MDP framework to define key LLM Agent components and developing a modular, flexible, and user-friendly training framework named Agent-R1 tailored for diverse tasks and interactive environments.
💬 Research Conclusions:
– Experiments conducted on Multihop QA benchmark tasks indicate the initial validation and effectiveness of the proposed RL methodologies and the Agent-R1 framework for LLM-based problem-solving.
👉 Paper link: https://huggingface.co/papers/2511.14460

12. Orion: A Unified Visual Agent for Multimodal Perception, Advanced Visual Reasoning and Execution
🔑 Keywords: Orion, Visual Agent Framework, Autonomous Visual Reasoning, State-of-the-art, Computer Vision Tools
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces Orion, aiming to improve visual AI tasks by combining neural perception with symbolic execution for autonomous visual reasoning.
🛠️ Research Methods:
– Orion utilizes a framework with multiple tool-calling capabilities to orchestrate specialized computer vision tools such as object detection, keypoint localization, and panoptic segmentation.
💬 Research Conclusions:
– Orion achieves competitive performance on several benchmarks and represents a shift towards production-grade visual intelligence, providing active, tool-driven visual understanding.
👉 Paper link: https://huggingface.co/papers/2511.14210

13. Φeat: Physically-Grounded Feature Representation
🔑 Keywords: Physically-grounded visual backbone, Material identity, Self-supervised training, Physics-aware perception
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Φeat, a novel physically-grounded visual backbone, to capture material identity using self-supervised training.
🛠️ Research Methods:
– Employed a pretraining strategy involving contrastive learning of spatial crops and physical augmentations under varied conditions.
💬 Research Conclusions:
– Demonstrated that self-supervised training provides robust features invariant to external physical factors, highlighting the potential of unsupervised physical feature learning for physics-aware perception in vision and graphics.
👉 Paper link: https://huggingface.co/papers/2511.11270

14. Agent READMEs: An Empirical Study of Context Files for Agentic Coding
🔑 Keywords: Agentic coding tools, Natural language, Functional context, Security, Performance
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Conduct a large-scale empirical study of 2,303 agent context files from 1,925 repositories to understand their structure, maintenance, and content.
🛠️ Research Methods:
– Analyzed agent context files to identify the distribution and priority of instruction types.
– Examined the evolution and maintenance patterns of these files.
💬 Research Conclusions:
– Developers focus on functional context such as build and run commands, implementation details, and architecture.
– There is a notable lack of emphasis on non-functional requirements like security and performance.
– This highlights a need for improved tooling and practices to ensure agent-written code is secure and performant.
👉 Paper link: https://huggingface.co/papers/2511.12884

15. Mitigating Label Length Bias in Large Language Models
🔑 Keywords: Large Language Models, Label Length Bias, Normalized Contextual Calibration, AI Native, In-Context Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address label length bias in Large Language Models to improve performance and reliability in various tasks.
🛠️ Research Methods:
– The study proposes a method called normalized contextual calibration (NCC) which normalizes and calibrates predictions at the full-label level.
💬 Research Conclusions:
– NCC achieves statistically significant improvements over existing methods with gains up to 10% F1 score.
– NCC is shown to enhance bias mitigation in broad tasks and improve reliability and efficiency in few-shot learning scenarios.
👉 Paper link: https://huggingface.co/papers/2511.14385

16. Proactive Hearing Assistants that Isolate Egocentric Conversations
🔑 Keywords: Proactive hearing assistants, Egocentric binaural audio, Dual-model architecture, Real-time, Conversational dynamics
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The goal is to develop proactive hearing assistants capable of identifying and separating conversation partners in real-time without explicit prompts, utilizing dual-model architecture on binaural audio.
🛠️ Research Methods:
– Utilizes a dual-model architecture with a lightweight streaming model for low-latency partner extraction every 12.5 ms and a slower, less frequent model to capture longer-range conversational dynamics. Testing involves real-world 2- and 3-speaker conversations with binaural egocentric hardware.
💬 Research Conclusions:
– The study demonstrates the system’s ability to generalize and effectively identify and isolate conversational partners in multi-conversation environments, marking progress toward adaptive hearing assistants.
👉 Paper link: https://huggingface.co/papers/2511.11473
17. A Brain Wave Encodes a Thousand Tokens: Modeling Inter-Cortical Neural Interactions for Effective EEG-based Emotion Recognition
🔑 Keywords: RBTransformer, Transformer-based neural network, inter-cortical neural dynamics, EEG-based emotion recognition, Band Differential Entropy
💡 Category: Machine Learning
🌟 Research Objective:
– The paper aims to improve EEG-based emotion recognition by capturing inter-cortical neural dynamics in latent space using the RBTransformer model.
🛠️ Research Methods:
– EEG signals are transformed into Band Differential Entropy tokens and passed through Electrode Identity embeddings.
– An electrode x electrode attention matrix is built using inter-cortical multi-head attention blocks to learn neural dependencies.
– Evaluation was conducted on SEED, DEAP, and DREAMER datasets under various classification settings.
💬 Research Conclusions:
– The RBTransformer model outperforms existing state-of-the-art methods across multiple datasets and dimensions, showing its effectiveness in emotion recognition.
👉 Paper link: https://huggingface.co/papers/2511.13954

18. LLM-Powered Fully Automated Chaos Engineering: Towards Enabling Anyone to Build Resilient Software Systems at Low Cost
🔑 Keywords: Chaos Engineering, Large Language Models, resilience, Kubernetes, software engineering tasks
💡 Category: AI Systems and Tools
🌟 Research Objective:
– This paper aims to automate the entire Chaos Engineering cycle for Kubernetes systems using Large Language Models to improve system resilience at a low cost.
🛠️ Research Methods:
– The study involves defining an agentic workflow for CE cycles and assigning tasks to LLMs, including requirement definition, code generation, testing, and debugging.
💬 Research Conclusions:
– The evaluation through case studies on Kubernetes systems shows that ChaosEater completes CE cycles efficiently with reduced time and cost, and its processes are validated by human engineers and LLMs.
👉 Paper link: https://huggingface.co/papers/2511.07865

19. Error-Driven Scene Editing for 3D Grounding in Large Language Models
🔑 Keywords: DEER-3D, 3D-LLMs, visual counterfactuals, spatial manipulation, grounding accuracy
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the grounding accuracy of 3D large language models (3D-LLMs) by addressing inherent biases through targeted counterfactual visual manipulation.
🛠️ Research Methods:
– The introduction of DEER-3D, an error-driven framework that uses a “Decompose, Diagnostic Evaluation, Edit, and Re-train” workflow to perform minimal, predicate-aligned 3D scene edits, avoiding extensive data augmentation.
💬 Research Conclusions:
– DEER-3D significantly improves grounding accuracy across multiple benchmarks and datasets by effectively bridging linguistic reasoning with spatial grounding through iterative refinement.
👉 Paper link: https://huggingface.co/papers/2511.14086

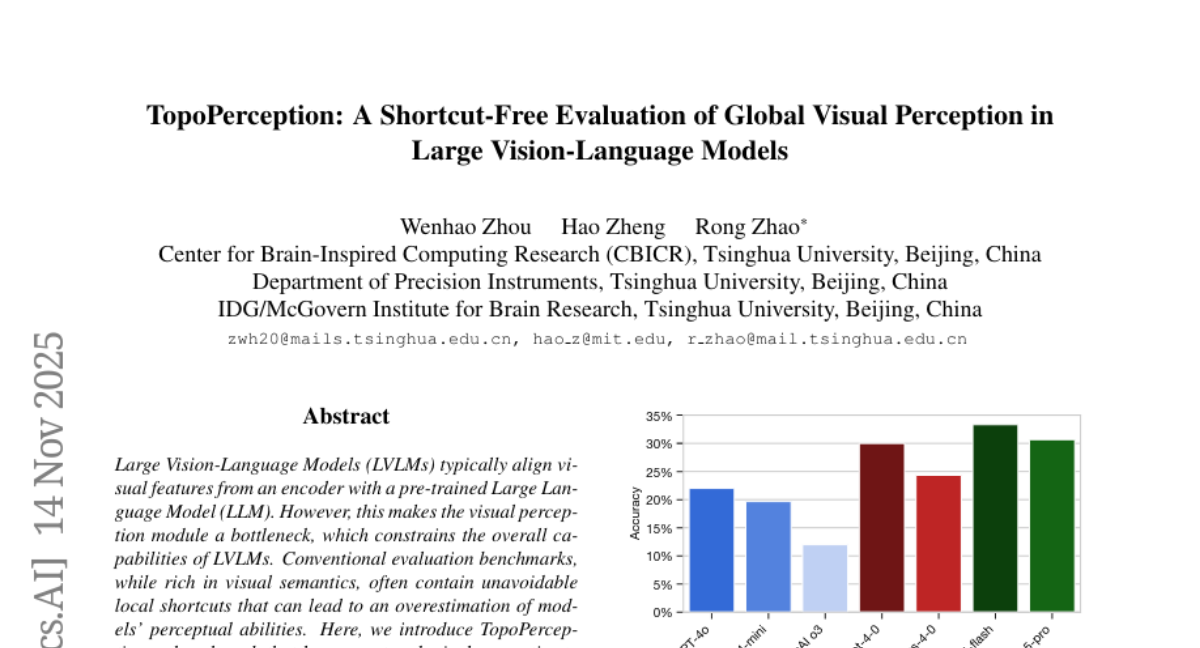
20. TopoPerception: A Shortcut-Free Evaluation of Global Visual Perception in Large Vision-Language Models
🔑 Keywords: Large Vision-Language Models, Topological properties, Global visual perception
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce TopoPerception, a benchmark designed to evaluate the global visual perception capabilities of Large Vision-Language Models, distinguishing them from local feature-based assessments.
🛠️ Research Methods:
– Utilized topological properties in images to provide a shortcut-free evaluation of LVLMs, focusing on global visual feature assessment across various granularities.
💬 Research Conclusions:
– Current state-of-the-art LVLMs perform poorly in global visual perception tasks, performing no better than random chance, especially at coarser granularities. More capable models within the same families struggle more, indicating that scaling models is not a solution and that new training paradigms or architectures may be necessary.
👉 Paper link: https://huggingface.co/papers/2511.11831
21.
