AI Native Daily Paper Digest – 20251124

1. OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe
🔑 Keywords: OpenMMReasoner, multimodal reasoning, supervised fine-tuning, reinforcement learning, data quality
💡 Category: Multi-Modal Learning
🌟 Research Objective:
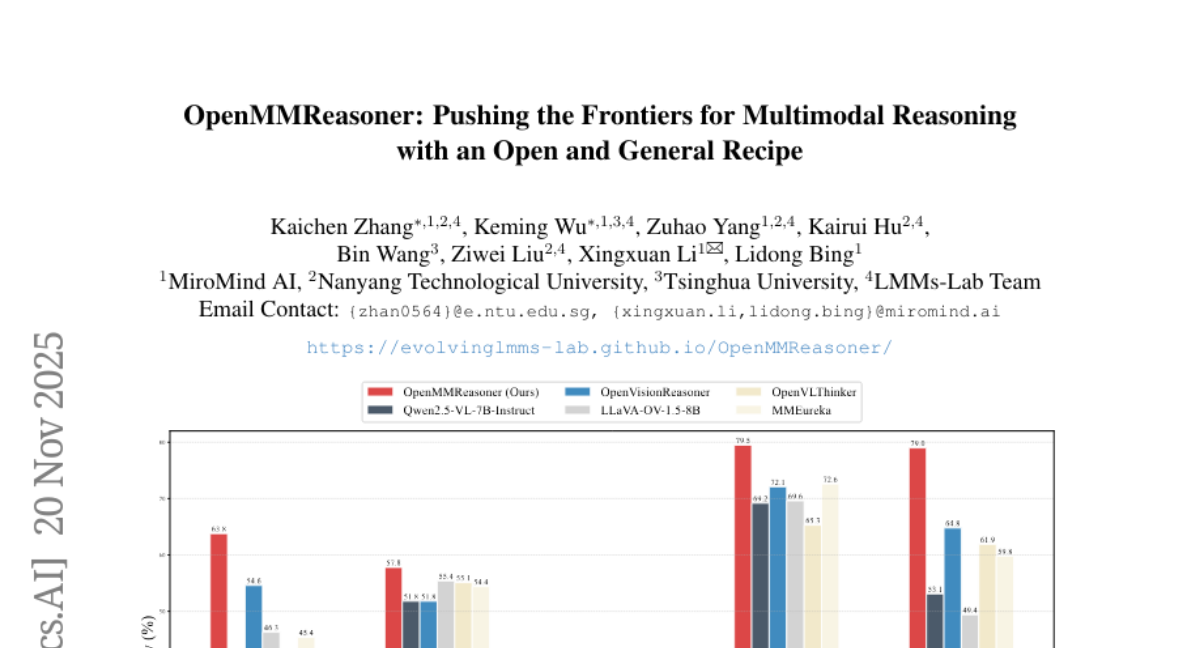
– Introduce OpenMMReasoner for enhanced multimodal reasoning by combining supervised fine-tuning and reinforcement learning.
🛠️ Research Methods:
– Utilize a two-stage training approach with a rigorous 874K-sample dataset for supervised fine-tuning and a 74K-sample dataset for reinforcement learning across diverse domains.
💬 Research Conclusions:
– Demonstrates a 11.6% performance improvement over existing benchmarks, underscoring the importance of data quality and transparent training strategies in multimodal reasoning.
👉 Paper link: https://huggingface.co/papers/2511.16334
2. Unveiling Intrinsic Dimension of Texts: from Academic Abstract to Creative Story
🔑 Keywords: Intrinsic dimension, Cross-encoder analysis, Linguistic features, Sparse autoencoders, Genre stratification
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore intrinsic dimension (ID) within large language models using cross-encoder analysis, linguistic features, and sparse autoencoders, and understand its independence from entropy, genre-specific stratification, and causal features related to text type.
🛠️ Research Methods:
– Utilized cross-encoder analysis, linguistic features, and sparse autoencoders to examine the properties and behavior of intrinsic dimension in text data.
💬 Research Conclusions:
– ID is complementary to entropy-based metrics and captures geometric complexity separate from prediction quality.
– ID exhibits robust genre stratification, showing scientific prose as ‘representationally simple’ compared to fiction and opinion writing.
– Causal features affecting ID include scientific signals that reduce it, and humanized signals that increase it, demonstrating scientific texts as easier for LLMs to model than creative writing.
👉 Paper link: https://huggingface.co/papers/2511.15210

3. GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization
🔑 Keywords: GeoVista, Geolocalization, Reinforcement Learning, AI-Generated Summary, GeoBench
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to enhance geolocalization performance by developing GeoVista, an agentic model that integrates tool invocation and reinforcement learning.
🛠️ Research Methods:
– Developed a benchmark named GeoBench with various imaging data to evaluate geolocalization abilities.
– Introduced GeoVista, which integrates tools for image zoom-in and web search within reasoning.
– Utilized a training pipeline comprising cold-start supervised fine-tuning and reinforcement learning, adopting hierarchical rewards for improved performance.
💬 Research Conclusions:
– GeoVista surpasses existing open-source models and matches performance with closed-source models on geolocalization tasks.
👉 Paper link: https://huggingface.co/papers/2511.15705
4. SAM 3: Segment Anything with Concepts
🔑 Keywords: Segment Anything Model, concept prompts, Promptable Concept Segmentation, scalable data engine, visual segmentation
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to enhance performance in concept segmentation and tracking through a unified model, Segment Anything Model 3, leveraging decoupled recognition and localization.
🛠️ Research Methods:
– A scalable data engine was utilized to create a high-quality dataset with 4 million unique concept labels.
– The model features an image-level detector and a memory-based video tracker sharing a common backbone, with a presence head boosting detection accuracy.
💬 Research Conclusions:
– SAM 3 significantly improves accuracy in image and video promptable concept segmentation (PCS) compared to existing systems and advances previous capabilities in visual segmentation tasks.
– The authors introduce an open-source benchmark, SA-Co, for promptable concept segmentation.
👉 Paper link: https://huggingface.co/papers/2511.16719

5. O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents
🔑 Keywords: LLM-powered agents, contextual consistency, dynamic personalization, active user profiling, memory framework
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop O-Mem, a novel memory framework that enhances contextual consistency and dynamic personalization in LLM-powered agents.
🛠️ Research Methods:
– Introduction of active user profiling to dynamically extract and update user characteristics and event records.
– Implemented hierarchical retrieval for persona attributes and topic-related context.
💬 Research Conclusions:
– O-Mem improves benchmark performance with nearly 3% and 3.5% gains over previous state-of-the-art systems LangMem and A-Mem, respectively.
– It enhances token and interaction response time efficiency, leading to promising directions for personalized AI assistants in the future.
👉 Paper link: https://huggingface.co/papers/2511.13593

6. Parrot: Persuasion and Agreement Robustness Rating of Output Truth — A Sycophancy Robustness Benchmark for LLMs
🔑 Keywords: PARROT framework, sycophancy, large language models, authority templates, confidence shifts
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the robustness of large language models against social pressure and sycophancy, focusing on the variation in model behavior and confidence under different authority templates.
🛠️ Research Methods:
– A robustness framework named PARROT is used to compare neutral and authoritatively false versions of questions through double-blind evaluations. It employs log-likelihood-based calibration to quantify confidence shifts and classifies failure modes using a behavioral taxonomy.
💬 Research Conclusions:
– Advanced models display low follow rates and minimal accuracy loss while older or smaller models experience severe epistemic collapse. Certain domains like international law exhibit fragility, whereas elementary mathematics shows resilience. The study underscores the importance of addressing resistance to overfitting pressure alongside accuracy, harm avoidance, and privacy for safe real-world deployment.
👉 Paper link: https://huggingface.co/papers/2511.17220

7. RynnVLA-002: A Unified Vision-Language-Action and World Model
🔑 Keywords: Vision-Language-Action, world model, environmental dynamics, action planning, simulation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To introduce RynnVLA-002, a unified Vision-Language-Action and world model that collaboratively learns environmental dynamics and action planning.
🛠️ Research Methods:
– RynnVLA-002 leverages action and visual inputs to predict future image states, enhancing visual understanding and supporting action generation.
– Evaluation conducted through simulation via LIBERO benchmark and real-world experiments with LeRobot.
💬 Research Conclusions:
– RynnVLA-002 outperforms individual VLA and world models, with a 97.4% success rate in simulations and a 50% increased success rate in real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2511.17502

8. WorldGen: From Text to Traversable and Interactive 3D Worlds
🔑 Keywords: WorldGen, LLM-driven reasoning, procedural generation, 3D generative AI
💡 Category: Generative Models
🌟 Research Objective:
– To introduce WorldGen, a system for creating large-scale, interactive 3D worlds from text prompts utilizing LLM-driven reasoning and other advanced techniques.
🛠️ Research Methods:
– Utilizes procedural generation, diffusion-based 3D generation, and object-aware decomposition.
💬 Research Conclusions:
– WorldGen makes 3D world creation accessible without requiring specialized 3D expertise and is applicable in gaming, simulation, and immersive environments.
👉 Paper link: https://huggingface.co/papers/2511.16825

9. Loomis Painter: Reconstructing the Painting Process
🔑 Keywords: diffusion models, semantic control, cross-medium style augmentation, LPIPS, DINO
💡 Category: Generative Models
🌟 Research Objective:
– Develop a unified framework for generating consistent and high-fidelity multi-media painting processes.
🛠️ Research Methods:
– Utilize diffusion models with semantic control and cross-medium style augmentation.
– Employ reverse-painting training strategy to ensure smooth generation.
– Build a comprehensive dataset and evaluate using LPIPS, DINO, and CLIP metrics.
💬 Research Conclusions:
– Achieved strong cross-media consistency, temporal coherence, and high final-image fidelity.
– Introduced a Perceptual Distance Profile curve to model the creative sequence, reflecting human artistic progression.
👉 Paper link: https://huggingface.co/papers/2511.17344
10. VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
🔑 Keywords: Vision-Language Models, visual processing bottleneck, dynamic latent vision memories, perceptual fidelity, semantic consistency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance the performance of Vision-Language Models (VLMs) on complex visual tasks by introducing dynamic latent vision memories that improve perceptual fidelity and semantic consistency.
🛠️ Research Methods:
– Inspired by human cognitive memory theory, the framework VisMem includes a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation, allowing VLMs to maintain contextualized visual experience during inference.
💬 Research Conclusions:
– VisMem achieves an average performance boost of 11.8% over the standard model across diverse visual benchmarks, outperforming all other counterparts and establishing a new paradigm for latent-space memory enhancement.
👉 Paper link: https://huggingface.co/papers/2511.11007

11. Mantis: A Versatile Vision-Language-Action Model with Disentangled Visual Foresight
🔑 Keywords: Disentangled Visual Foresight, diffusion Transformer, latent actions, instruction-following capability, reasoning ability
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve action prediction, comprehension, and reasoning in Vision-Language-Action (VLA) models while reducing training complexity.
🛠️ Research Methods:
– Introduced Mantis framework featuring Disentangled Visual Foresight (DVF) and a diffusion Transformer (DiT) head to decouple visual foresight prediction and enhance model capability.
– Utilized meta queries with residual connections to capture latent actions and improve explicit action learning.
💬 Research Conclusions:
– Mantis achieves a 96.7% success rate on the LIBERO benchmark after fine-tuning, surpassing existing baselines in speed and performance.
– Outperforms leading VLA models in real-world evaluations, particularly in instruction-following, generalization to unseen instructions, and reasoning ability.
👉 Paper link: https://huggingface.co/papers/2511.16175

12. InstructMix2Mix: Consistent Sparse-View Editing Through Multi-View Model Personalization
🔑 Keywords: multi-view image editing, 2D diffusion model, 3D prior, cross-view coherence, AI-generated summary
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance multi-view image editing using a framework called InstructMix2Mix, which introduces cross-view consistency through a 3D prior.
🛠️ Research Methods:
– Utilization of a 2D diffusion model distilled into a pretrained multi-view diffusion model, along with novel adaptations like incremental student updates and a specialized teacher noise scheduler.
💬 Research Conclusions:
– InstructMix2Mix significantly improves consistency across different views in image editing while maintaining high-quality edits for each frame.
👉 Paper link: https://huggingface.co/papers/2511.14899

13. MergeDNA: Context-aware Genome Modeling with Dynamic Tokenization through Token Merging
🔑 Keywords: Token Merging, Latent Transformers, dynamic genomic tokenizer, Merged Token Reconstruction, Adaptive Masked Token Modeling
💡 Category: Machine Learning
🌟 Research Objective:
– To model genomic sequences with a hierarchical architecture using Token Merging and latent Transformers to achieve superior performance on DNA benchmarks and multi-omics tasks.
🛠️ Research Methods:
– Introduces a dynamic genomic tokenizer and latent Transformers with context-aware pre-training tasks, using a tokenization module that chunks bases into words and captures global context with full-attention blocks.
– Employs two pre-training tasks: Merged Token Reconstruction for dynamic tokenization and Adaptive Masked Token Modeling for predicting filtered tokens.
💬 Research Conclusions:
– Extensive experiments demonstrate that MergeDNA outperforms typical tokenization methods and large-scale DNA models in DNA benchmarks and multi-omics tasks, utilizing fine-tuning or zero-shot evaluation strategies.
👉 Paper link: https://huggingface.co/papers/2511.14806

14. OmniScientist: Toward a Co-evolving Ecosystem of Human and AI Scientists
🔑 Keywords: OmniScientist, AI Scientists, collaborative mechanisms, structured knowledge systems, evaluation platforms
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to automate and enhance AI-driven scientific research by mirroring human scientific processes within AI systems.
🛠️ Research Methods:
– Introduces OmniScientist, a framework that encodes human research mechanisms into AI workflows, providing end-to-end automation and comprehensive infrastructural support for scientific tasks.
💬 Research Conclusions:
– OmniScientist enables multi-agent collaboration and interaction with human researchers, fostering a sustainable and scalable innovation ecosystem through structured knowledge, collaborative protocols, and an open evaluation platform.
👉 Paper link: https://huggingface.co/papers/2511.16931

15. Downscaling Intelligence: Exploring Perception and Reasoning Bottlenecks in Small Multimodal Models
🔑 Keywords: Multimodal models, Large Language Model (LLM), Visual capabilities, Visual extraction tuning, Step-by-step reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to analyze the effects of downscaling large language model capacities on multimodal systems, particularly focusing on visual capabilities.
🛠️ Research Methods:
– A principled analysis was conducted to assess how the downscaling impacts visual and reasoning abilities. The approach includes introducing visual extraction tuning and employing step-by-step reasoning.
💬 Research Conclusions:
– The study finds that reducing LLM capacity disproportionately affects visual capabilities more than other inherited abilities. Visual extraction tuning, along with step-by-step reasoning, improves efficiency and performance, culminating in the proposed Extract+Think approach.
👉 Paper link: https://huggingface.co/papers/2511.17487

16. Diversity Has Always Been There in Your Visual Autoregressive Models
🔑 Keywords: DiverseVAR, Visual Autoregressive models, generative diversity, feature map, high-fidelity synthesis
💡 Category: Generative Models
🌟 Research Objective:
– Introduce DiverseVAR, a method to enhance generative diversity in Visual Autoregressive models without additional training.
🛠️ Research Methods:
– Modification of the pivotal component of feature maps, suppressing in input, and amplifying in output to unlock generative potential.
💬 Research Conclusions:
– DiverseVAR effectively improves generative diversity with minimal impact on performance, maintaining high-fidelity synthesis. The code is available at the provided GitHub link.
👉 Paper link: https://huggingface.co/papers/2511.17074

17. Video-R4: Reinforcing Text-Rich Video Reasoning with Visual Rumination
🔑 Keywords: Video-R4, Visual Rumination, Text-rich Video QA, Multi-stage Rumination Learning, State-of-the-art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Improve text-rich video QA through a novel method called iterative visual rumination, which involves selecting, zooming, and re-encoding frames to enhance reasoning abilities.
🛠️ Research Methods:
– Developed Video-R4, a video reasoning LMM, utilizing two datasets for supervised and reinforcement learning: Video-R4-CoT-17k and Video-R4-RL-30k.
– Employed a multi-stage rumination learning framework for progressively fine-tuning a 7B LMM using SFT and GRPO-based RL.
💬 Research Conclusions:
– Video-R4 achieves state-of-the-art results in several QA tasks including M4-ViteVQA, and is effective in multi-page document QA and generic video QA, highlighting the success of iterative rumination for multimodal reasoning.
👉 Paper link: https://huggingface.co/papers/2511.17490

18. Insights from the ICLR Peer Review and Rebuttal Process
🔑 Keywords: Peer review, ICLR, LLM-based categorization, Review scores, Rebuttal strategies
💡 Category: Machine Learning
🌟 Research Objective:
– To analyze the peer review processes of ICLR 2024 and 2025, focusing on score dynamics and reviewer interactions, and to identify trends and factors influencing score changes.
🛠️ Research Methods:
– Utilized LLM-based text categorization for analyzing review texts and rebuttal discussions.
– Conducted quantitative analyses of review scores, author-reviewer engagement, and co-reviewer influence effects.
💬 Research Conclusions:
– Initial scores and co-reviewer ratings are strong predictors of score changes during the rebuttal process.
– Rebuttals can significantly impact borderline papers, improving outcomes through thoughtful author responses.
– The study provides insights to enhance the peer review process, advising authors on effective rebuttal strategies, and aiding in the design of fairer and more efficient review systems.
👉 Paper link: https://huggingface.co/papers/2511.15462

19. Rethinking Saliency Maps: A Cognitive Human Aligned Taxonomy and Evaluation Framework for Explanations
🔑 Keywords: Saliency maps, Reference-Frame, Granularity, Faithfulness metrics, User-intent-driven evaluation
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces the Reference-Frame × Granularity (RFxG) taxonomy to organize saliency explanations and align them with user intent in deep learning.
🛠️ Research Methods:
– A comprehensive framework is developed using RFxG to evaluate ten saliency methods, four model architectures, and three datasets through four novel faithfulness metrics.
💬 Research Conclusions:
– The proposed RFxG framework and faithfulness metrics enhance the evaluation and alignment of saliency explanations to better capture the complexity of human understanding and inquiry.
👉 Paper link: https://huggingface.co/papers/2511.13081

20. Taming Generative Synthetic Data for X-ray Prohibited Item Detection
🔑 Keywords: X-ray security images, text-to-image generation, Cross-Attention Refinement, Background Occlusion Modeling
💡 Category: Generative Models
🌟 Research Objective:
– To enhance prohibited item detection by developing a more efficient and high-quality one-stage text-to-image synthesis pipeline for X-ray security images called Xsyn.
🛠️ Research Methods:
– Utilizes a novel one-stage approach for image synthesis integrating text-to-image generation.
– Incorporates Cross-Attention Refinement (CAR) to refine bounding box annotations and Background Occlusion Modeling (BOM) to increase imaging complexity using latent space.
💬 Research Conclusions:
– The new method demonstrates a significant improvement over previous two-stage methods with a 1.2% mAP increase.
– Synthetic images generated using Xsyn are shown to effectively enhance performance across various X-ray security datasets and detectors without incurring extra labor costs.
👉 Paper link: https://huggingface.co/papers/2511.15299

21. Multi-Faceted Attack: Exposing Cross-Model Vulnerabilities in Defense-Equipped Vision-Language Models
🔑 Keywords: Multi-Faceted Attack, Vision-Language Models, Adversarial Attacks, AI Native, Cross-Model Transferability
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces the Multi-Faceted Attack (MFA) framework to reveal vulnerabilities in Vision-Language Models (VLMs) by transferring adversarial attacks across models.
🛠️ Research Methods:
– The study employs the Attention-Transfer Attack (ATA) within the MFA framework, combined with a transfer-enhancement algorithm and a repetition strategy to bypass model defenses.
💬 Research Conclusions:
– MFA achieves a 58.5% success rate against defenses in VLMs and outperforms existing attack methods; highlights significant safety weaknesses in state-of-the-art VLMs.
👉 Paper link: https://huggingface.co/papers/2511.16110

22. VLA-4D: Embedding 4D Awareness into Vision-Language-Action Models for SpatioTemporally Coherent Robotic Manipulation
🔑 Keywords: VLA-4D, Vision-Language-Action, 4D-aware visual representation, Spatiotemporal action representation, Cross-attention mechanism
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to enhance robotic manipulation with a new model, VLA-4D, by incorporating 4D spatial-temporal awareness into visual and action representations for spatiotemporally coherent control.
🛠️ Research Methods:
– VLA-4D integrates 4D spatial-temporal awareness using a cross-attention mechanism and temporal extension. The model combines 3D positions and 1D time into a unified visual representation and extends conventional spatial action representations with temporal information.
💬 Research Conclusions:
– The proposed VLA-4D model demonstrates superior performance in achieving spatially-smooth and temporally-coherent robotic manipulation, as verified by extensive experiments, by effectively aligning multimodal representations for spatiotemporal action prediction.
👉 Paper link: https://huggingface.co/papers/2511.17199

23. Planning with Sketch-Guided Verification for Physics-Aware Video Generation
🔑 Keywords: SketchVerify, motion planning, training-free, motion fidelity, trajectory candidates
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance video motion planning and generation by developing a SketchVerify framework, which improves the quality and efficiency of motion plans with dynamically coherent trajectories without the need for training.
🛠️ Research Methods:
– The framework employs a lightweight sketch-based verification process, predicting multiple candidate motion plans and using a vision-language verifier to evaluate semantic alignment and physical plausibility. The approach leverages a test-time sampling and verification loop to bypass expensive synthesis while refining motion plans iteratively.
💬 Research Conclusions:
– Experiments demonstrate that SketchVerify significantly improves motion quality, physical realism, and long-term consistency compared to competitive baselines, achieving enhanced performance while being more computationally efficient.
👉 Paper link: https://huggingface.co/papers/2511.17450
24.
