AI Native Daily Paper Digest – 20251225
1. TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
🔑 Keywords: TurboDiffusion, Video Generation, Attention Acceleration, Quantization, Step Distillation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to significantly accelerate video generation by 100-200x while maintaining quality.
🛠️ Research Methods:
– Utilizes low-bit SageAttention and trainable Sparse-Linear Attention for faster attention computation.
– Employs rCM for efficient step distillation and W8A8 quantization to compress and accelerate the model.
💬 Research Conclusions:
– TurboDiffusion achieves substantial speedup in video generation on a single RTX 5090 GPU without sacrificing video quality.
👉 Paper link: https://huggingface.co/papers/2512.16093

2. DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
🔑 Keywords: one-shot, video generation, visual fidelity, cinematic expressiveness, Adaptive Tuning
💡 Category: Generative Models
🌟 Research Objective:
– Introduce the DreaMontage framework to generate seamless, expressive, and long-duration one-shot videos from diverse inputs.
🛠️ Research Methods:
– Integrates a lightweight intermediate-conditioning mechanism within the DiT architecture to enhance arbitrary-frame control capabilities.
– Employs a high-quality dataset and Visual Expression SFT to improve visual fidelity and cinematic expressiveness.
– Utilizes a Segment-wise Auto-Regressive (SAR) inference strategy for memory-efficient extended sequence production.
💬 Research Conclusions:
– The approach achieves visually striking and seamless one-shot video effects, maintaining computational efficiency, thus enabling users to create cohesive one-shot cinematic experiences from fragmented visual materials.
👉 Paper link: https://huggingface.co/papers/2512.21252
3. Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
🔑 Keywords: Mixture-of-Experts, Mamba-Transformer, RL, GPT-OSS-20B
💡 Category: Natural Language Processing
🌟 Research Objective:
– Present Nemotron 3 Nano 30B-A3B, a novel Mixture-of-Experts hybrid Mamba-Transformer model.
🛠️ Research Methods:
– Pretrained on 25 trillion text tokens with supervised fine-tuning and large-scale reinforcement learning across diverse environments.
💬 Research Conclusions:
– Demonstrates improved accuracy over Nemotron 2 Nano, with significantly fewer active parameters per forward pass.
– Achieves up to 3.3x higher inference throughput than comparable models like GPT-OSS-20B, while supporting extended context lengths and enhanced reasoning and chat capabilities.
👉 Paper link: https://huggingface.co/papers/2512.20848

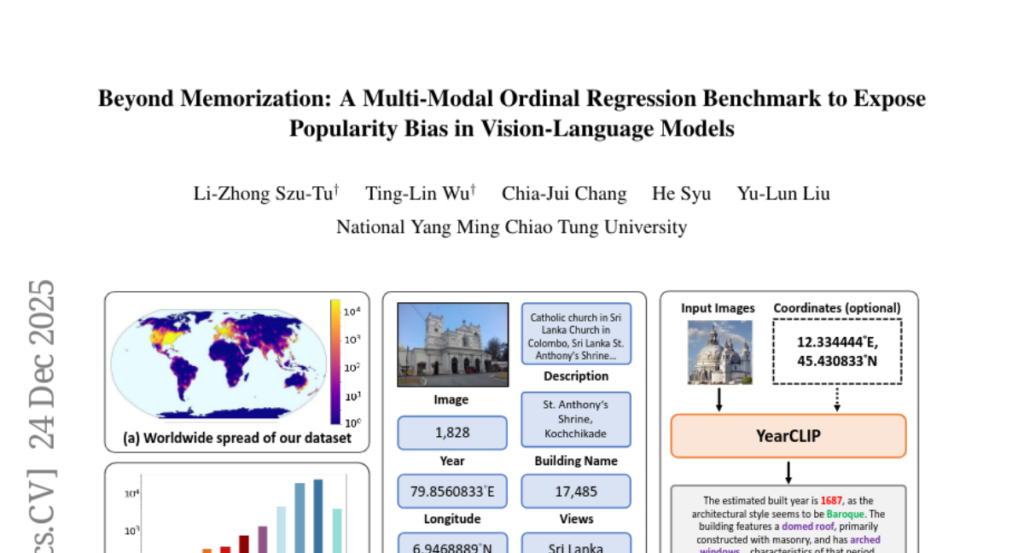
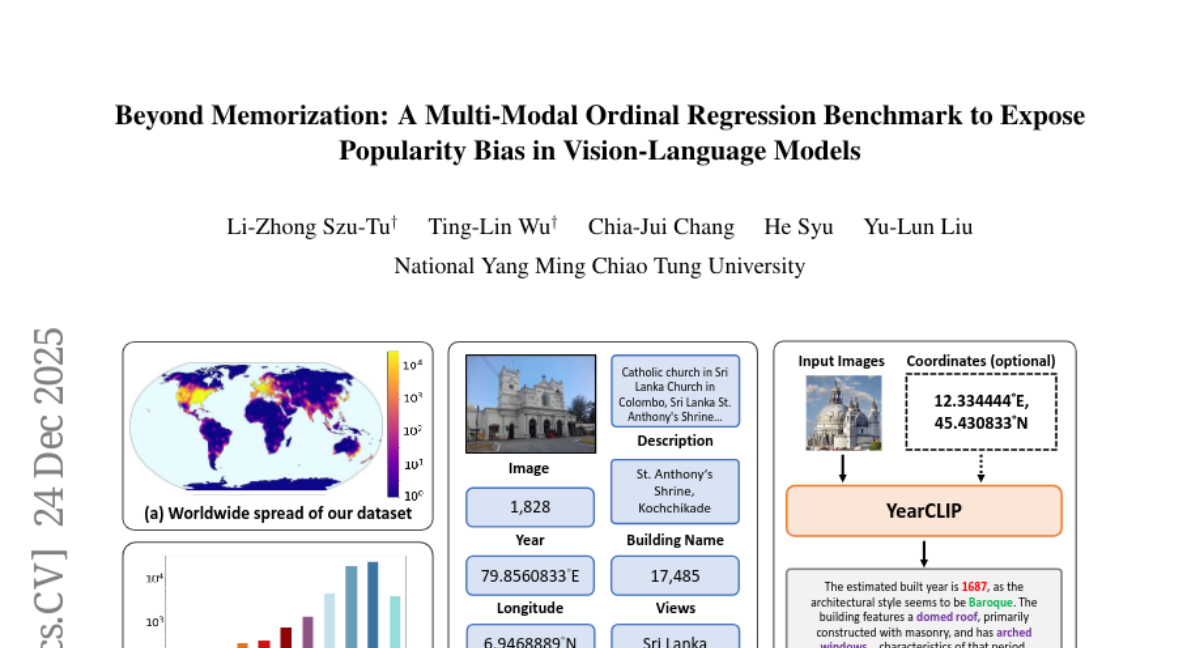
4. Beyond Memorization: A Multi-Modal Ordinal Regression Benchmark to Expose Popularity Bias in Vision-Language Models
🔑 Keywords: Popularity Bias, Vision-Language Models, YearGuessr, Construction Year Prediction, Ordinal Regression
💡 Category: Computer Vision
🌟 Research Objective:
– The study investigates the significant popularity bias in state-of-the-art Vision-Language Models (VLMs).
🛠️ Research Methods:
– Introduction of a large-scale dataset called YearGuessr, containing 55,546 building images with multi-modal attributes for ordinal regression analysis.
💬 Research Conclusions:
– VLMs show up to 34% higher accuracy for famous buildings, indicating dependency on memorization, exposing a flaw in their reasoning when dealing with less popular or unrecognized subjects.
👉 Paper link: https://huggingface.co/papers/2512.21337
5. TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior
🔑 Keywords: Tokenization, Language Models, TokSuite, Model Performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– To understand the role of tokenization in the performance and behavior of language models by measuring its impact in isolation.
🛠️ Research Methods:
– Developed TokSuite, a collection of 14 models trained with different tokenizers but identical architecture, dataset, and training parameters.
– Released a benchmark to evaluate model performance under real-world perturbations affecting tokenization.
💬 Research Conclusions:
– TokSuite enables the decoupling of a model’s tokenizer influence, providing insights into the advantages and limitations of various popular tokenizers.
👉 Paper link: https://huggingface.co/papers/2512.20757

6. From Word to World: Can Large Language Models be Implicit Text-based World Models?
🔑 Keywords: LLM-based world models, agent performance, synthetic trajectory generation, large language models, reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To evaluate the effectiveness of LLM-based world models in enhancing agent performance in text-based environments through action verification, synthetic trajectory generation, and warm-starting reinforcement learning.
🛠️ Research Methods:
– A three-level framework was introduced for evaluating these models, focusing on fidelity and consistency, scalability and robustness, and agent utility across five representative environments.
💬 Research Conclusions:
– The study found that sufficiently trained world models can maintain coherent latent states, scale predictably, and improve agent performance. However, their effectiveness depends critically on behavioral coverage and environment complexity.
👉 Paper link: https://huggingface.co/papers/2512.18832

7. Multi-hop Reasoning via Early Knowledge Alignment
🔑 Keywords: Early Knowledge Alignment, Retrieval-Augmented Generation, Large Language Models, Iterative RAG, Reinforcement Learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research aims to improve the performance and efficiency of iterative Retrieval-Augmented Generation (RAG) systems by introducing Early Knowledge Alignment (EKA) to align Large Language Models with relevant knowledge before planning.
🛠️ Research Methods:
– The study employs a module, EKA, for aligning Large Language Models with retrieval sets before planning in iterative RAG systems, and extensive experiments were conducted on six standard RAG datasets.
💬 Research Conclusions:
– EKA significantly enhances retrieval precision, reduces cascading errors, and improves overall performance and efficiency. The analysis from an entropy perspective indicates that EKA reduces unnecessary exploration, focusing models on relevant information subsets more effectively, proving to be a versatile and robust inference strategy for large models.
👉 Paper link: https://huggingface.co/papers/2512.20144

8. PhononBench:A Large-Scale Phonon-Based Benchmark for Dynamical Stability in Crystal Generation
🔑 Keywords: AI-generated crystals, PhononBench, dynamical stability, MatterSim, crystal generation models
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces PhononBench, a large-scale benchmark designed to assess the dynamical stability of AI-generated crystals.
🛠️ Research Methods:
– Utilization of the MatterSim interatomic potential to perform DFT-level accurate phonon predictions on over 10,000 materials, evaluating 108,843 crystal structures generated by six crystal generation models.
💬 Research Conclusions:
– Findings reveal that current generative models struggle with ensuring dynamical stability, with an average stability rate of 25.83%, and the best model achieving only 41.0%.
– Higher-symmetry crystals, such as cubic systems, exhibit better stability rates.
– The identification of 28,119 phonon-stable crystal structures suitable for future exploration, concluding the need for improved crystal generation models for viable material design.
👉 Paper link: https://huggingface.co/papers/2512.21227

9.

10. LLM Swiss Round: Aggregating Multi-Benchmark Performance via Competitive Swiss-System Dynamics
🔑 Keywords: Large Language Models, Competitive Ranking, Swiss-System Dynamics, Monte Carlo Simulation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to create a holistic, competitive ranking system for evaluating Large Language Models (LLMs) across multiple ability dimensions.
🛠️ Research Methods:
– Introduction of the Competitive Swiss-System Dynamics (CSD) framework, which simulates multi-round contests using models’ win-loss records.
– Use of Monte Carlo Simulation (100,000 iterations) to approximate statistically robust Expected Win Scores (E[S_m]).
– Implementation of Failure Sensitivity Analysis to profile models based on their risk appetite.
💬 Research Conclusions:
– CSD offers a nuanced and context-aware ranking system, providing advantages over traditional scoring methods, and represents a step forward in risk-informed LLM evaluation.
👉 Paper link: https://huggingface.co/papers/2512.21010

11. SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
🔑 Keywords: AI Coding Agents, Software Evolution, Complex Tasks, GPT-5, Fix Rate
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to evaluate the performance of AI coding agents on complex, long-horizon software evolution tasks using the SWE-EVO benchmark, highlighting the limitations of current models.
🛠️ Research Methods:
– The researchers developed the SWE-EVO benchmark comprising 48 evolution tasks derived from open-source Python projects, requiring multi-step modifications validated against comprehensive test suites.
💬 Research Conclusions:
– Experiments show a significant capability gap, as even state-of-the-art models like GPT-5 achieve only a 21% success rate on the benchmark, indicating challenges in sustained, multi-file reasoning.
– A new metric called Fix Rate is proposed to measure partial progress on these complex tasks.
👉 Paper link: https://huggingface.co/papers/2512.18470

12. Streaming Video Instruction Tuning
🔑 Keywords: Streamo, real-time streaming, video understanding, Streamo-Instruct-465K, temporal reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop Streamo, a real-time streaming video LLM that functions as a versatile general-purpose interactive assistant for various video tasks.
🛠️ Research Methods:
– Construction of a large-scale instruction-following dataset, Streamo-Instruct-465K, for streaming video understanding encompassing diverse temporal contexts and tasks.
– End-to-end training on this dataset through a streamlined pipeline for unified multi-task supervision.
💬 Research Conclusions:
– Streamo demonstrates strong temporal reasoning, responsive interaction, and broad generalization, effectively serving as a bridge between offline video perception models and real-time multimodal assistants, advancing unified video understanding in continuous video streams.
👉 Paper link: https://huggingface.co/papers/2512.21334

13. Learning from Next-Frame Prediction: Autoregressive Video Modeling Encodes Effective Representations
🔑 Keywords: Autoregressive, Visual Generative Pretraining, Semantic Representation, Generation Quality
💡 Category: Generative Models
🌟 Research Objective:
– Propose a novel framework NExT-Vid for autoregressive visual generative pretraining using masked next-frame prediction.
🛠️ Research Methods:
– Introduce a context-isolated autoregressive predictor and a conditioned flow-matching decoder to improve representation and generation quality.
💬 Research Conclusions:
– Demonstrated that NExT-Vid consistently outperforms previous methods in visual representation learning for downstream classification tasks.
👉 Paper link: https://huggingface.co/papers/2512.21004

14. NVIDIA Nemotron 3: Efficient and Open Intelligence
🔑 Keywords: Nemotron 3, Mixture-of-Experts, Reinforcement Learning, LatentMoE, Mamba-Transformer
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce the Nemotron 3 family of models (Nano, Super, and Ultra) with strong reasoning and conversational capabilities.
🛠️ Research Methods:
– Utilize a Mixture-of-Experts hybrid Mamba-Transformer architecture.
– Employ multi-environment reinforcement learning for model post-training.
💬 Research Conclusions:
– Nano model is highly accurate and cost-efficient.
– Super and Ultra models offer high-volume workload optimization and state-of-the-art performance, with plans for open release.
👉 Paper link: https://huggingface.co/papers/2512.20856

15. HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
🔑 Keywords: High-resolution video generation, Diffusion Models, Autoregressive Framework, HiStream, Speed Optimization
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the computational inefficiencies in high-resolution video generation by reducing the complexity of diffusion models.
🛠️ Research Methods:
– Introduced HiStream, an autoregressive framework featuring spatial, temporal, and timestep compression techniques to enhance efficiency.
💬 Research Conclusions:
– The HiStream model significantly accelerates denoising processes, achieving up to a 107.5x speed increase, making high-resolution video generation more practical and scalable.
👉 Paper link: https://huggingface.co/papers/2512.21338

16. T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
🔑 Keywords: Text-to-Audio-Video generation, T2AV-Compass, cross-modal alignment, perceptual realism
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces T2AV-Compass, a benchmark designed to evaluate Text-to-Audio-Video (T2AV) systems for temporal coherence, semantic synchronization, and cross-modal alignment from natural language prompts.
🛠️ Research Methods:
– T2AV-Compass consists of 500 complex prompts developed through a taxonomy-driven pipeline ensuring semantic and physical plausibility. The evaluation framework includes both objective metrics and a subjective MLLM-as-a-Judge protocol.
💬 Research Conclusions:
– An evaluation of 11 T2AV systems using the T2AV-Compass benchmark reveals that the current models significantly underperform in achieving human-level realism and cross-modal consistency, indicating room for improvement in audio realism and synchronization.
👉 Paper link: https://huggingface.co/papers/2512.21094

17. Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
🔑 Keywords: Vision-language models, dynamic spatial reasoning, automated pipeline, Geometry Selection Module, 3D trajectories
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This study aims to enhance vision-language models’ capability in dynamic spatial reasoning through a novel system called DSR Suite, which combines automated data generation and geometric priors.
🛠️ Research Methods:
– The research introduces an automated pipeline that generates multiple-choice question-answer pairs from natural videos, extracting rich geometric and motion information like camera poses and 3D trajectories.
– A lightweight Geometry Selection Module (GSM) is proposed to integrate geometric priors efficiently, optimizing the extraction of question-relevant knowledge.
💬 Research Conclusions:
– Integrating DSR-Train and GSM into the Qwen2.5-VL-7B model significantly enhances its dynamic spatial reasoning capabilities while maintaining general video understanding accuracy.
👉 Paper link: https://huggingface.co/papers/2512.20557