AI Native Daily Paper Digest – 20260227

1. The Trinity of Consistency as a Defining Principle for General World Models
🔑 Keywords: World Models, Artificial General Intelligence, Unified Multimodal Model, Modal Consistency, Spatial Consistency, Temporal Consistency
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to define essential properties for developing General World Models by proposing a Trinity of Consistency encompassing modal, spatial, and temporal principles.
🛠️ Research Methods:
– A systematic review of the evolution of multimodal learning towards unified architectures, and the introduction of CoW-Bench, a benchmark for evaluating video generation models and Unified Multimodal Models under a unified evaluation protocol.
💬 Research Conclusions:
– Establishes a principled pathway towards the development of General World Models, clarifying limitations of current systems and defining architectural requirements for future advancements.
👉 Paper link: https://huggingface.co/papers/2602.23152

2. MobilityBench: A Benchmark for Evaluating Route-Planning Agents in Real-World Mobility Scenarios
🔑 Keywords: Large Language Models, Route Planning Agents, MobilityBench, Real-World Scenarios, AI Native
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce MobilityBench, a scalable benchmark for evaluating LLM-based route-planning agents in real-world mobility scenarios.
🛠️ Research Methods:
– Utilization of MobilityBench, constructed from anonymized user queries across multiple cities and a deterministic API-replay sandbox for reproducible testing.
– Implementation of a multi-dimensional evaluation protocol focusing on outcome validity, instruction understanding, planning, tool use, and efficiency.
💬 Research Conclusions:
– Current LLM-based route-planning agents perform well on basic tasks but struggle with preference-constrained route planning, indicating a need for improvements in personalized mobility applications.
– Public release of benchmark data and evaluation toolkit to facilitate further research and development.
👉 Paper link: https://huggingface.co/papers/2602.22638

3. Imagination Helps Visual Reasoning, But Not Yet in Latent Space
🔑 Keywords: Latent Visual Reasoning, Multimodal Large Language Models, Causal Mediation Analysis, Input-Latent Disconnect, CapImagine
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to uncover the efficacy and underlying mechanisms of latent visual reasoning in multimodal models, addressing input-latent and latent-answer disconnects.
🛠️ Research Methods:
– Utilizes Causal Mediation Analysis to model latent reasoning processes as a causal chain analysis involving treatment, mediation, and outcome for visual reasoning.
💬 Research Conclusions:
– Identified critical disconnects in input-latent and latent-answer relationships, suggesting limited effectiveness of latent reasoning. Proposes CapImagine as an alternative, which significantly surpasses existing latent-space methods in performance on vision-centric benchmarks.
👉 Paper link: https://huggingface.co/papers/2602.22766

4. AgentDropoutV2: Optimizing Information Flow in Multi-Agent Systems via Test-Time Rectify-or-Reject Pruning
🔑 Keywords: Multi-Agent Systems, AgentDropoutV2, test-time rectify-or-reject pruning, error correction, error propagation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces AgentDropoutV2, aimed at optimizing information flow in Multi-Agent Systems through a framework that corrects errors and prunes information without needing retraining.
🛠️ Research Methods:
– The approach utilizes a dynamic mechanism that intercepts and corrects agent outputs using a retrieval-augmented rectifier and prunes irreparable outputs to prevent error propagation.
💬 Research Conclusions:
– AgentDropoutV2 demonstrates a significant performance improvement, increasing task accuracy by 6.3 percentage points on math benchmarks and offering strong generalization and adaptivity to varying task difficulties.
👉 Paper link: https://huggingface.co/papers/2602.23258

5. Search More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization
🔑 Keywords: SMTL, parallel evidence acquisition, efficient context management, generalization, reinforcement learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce the SMTL (Search More, Think Less) framework to enhance efficiency and generalization in long-horizon agentic search.
🛠️ Research Methods:
– Apply parallel evidence acquisition instead of sequential reasoning.
– Utilize a unified data synthesis pipeline for diverse search tasks.
– Train an end-to-end agent using supervised fine-tuning and reinforcement learning.
💬 Research Conclusions:
– Achieves state-of-the-art performance with reduced reasoning steps by 70.7%.
– Demonstrates strong performance across multiple benchmarks, enhancing both accuracy and efficiency.
👉 Paper link: https://huggingface.co/papers/2602.22675

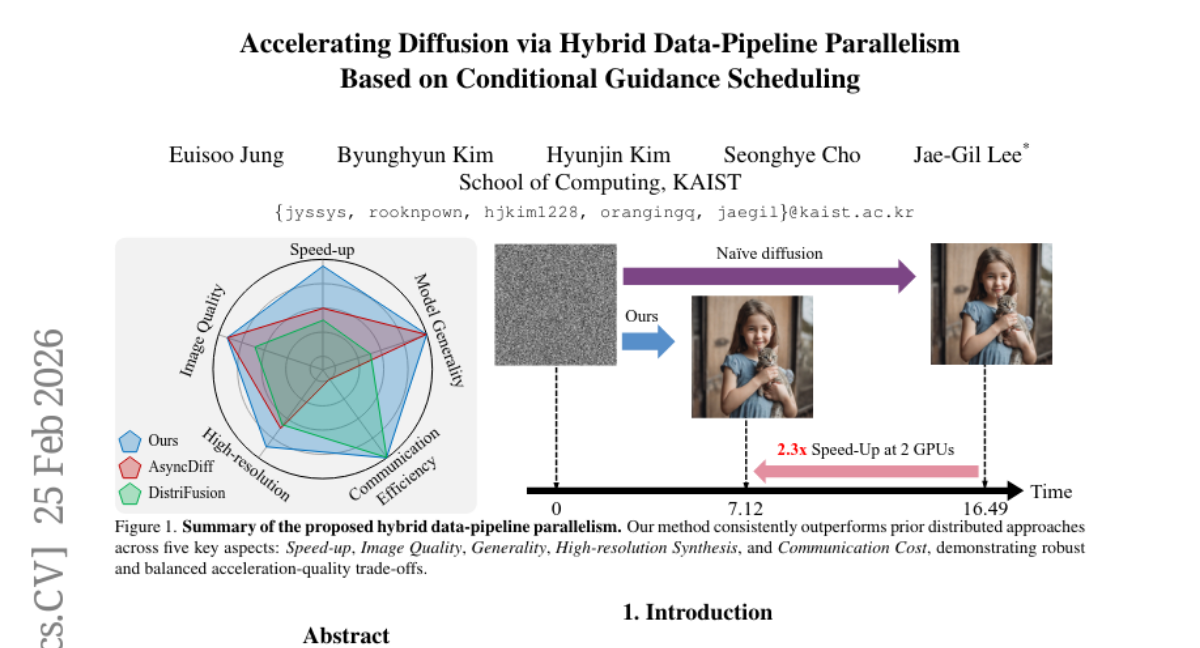
6. Accelerating Diffusion via Hybrid Data-Pipeline Parallelism Based on Conditional Guidance Scheduling
🔑 Keywords: Hybrid Parallelism, Diffusion Models, Image Quality, Inference Latency
💡 Category: Generative Models
🌟 Research Objective:
– To develop a hybrid parallelism framework for diffusion models that reduces inference latency while maintaining image quality across various architectures.
🛠️ Research Methods:
– Combines condition-based partitioning and adaptive pipeline scheduling.
– Utilizes both conditional and unconditional denoising paths for optimal data partitioning.
– Implemented adaptive parallelism switching to enhance pipeline efficiency.
💬 Research Conclusions:
– Achieved a significant reduction in latency (2.31x on SDXL and 2.07x on SD3) on NVIDIA RTX 3090 GPUs while preserving image quality.
– Demonstrated the framework’s broad applicability across U-Net-based diffusion models and DiT-based flow-matching architectures.
– Outperformed existing methods in high-resolution synthesis settings.
👉 Paper link: https://huggingface.co/papers/2602.21760
7. AI Gamestore: Scalable, Open-Ended Evaluation of Machine General Intelligence with Human Games
🔑 Keywords: AI Native, human-like general intelligence, Multiverse of Human Games, AI GameStore, vision-language models
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate AI systems’ general intelligence through their performance in a broad spectrum of human-designed games, aiming for human-like general intelligence.
🛠️ Research Methods:
– Development of AI GameStore, a platform that uses large language models (LLMs) with human input to create new human games, and evaluating vision-language models on these games.
💬 Research Conclusions:
– Vision-language models achieved less than 10% of human average score in most games, indicating significant challenges in achieving world-model learning, memory, and planning akin to humans.
– The paper outlines future steps for developing AI GameStore as a means to advance towards human-like general intelligence in AI.
👉 Paper link: https://huggingface.co/papers/2602.17594

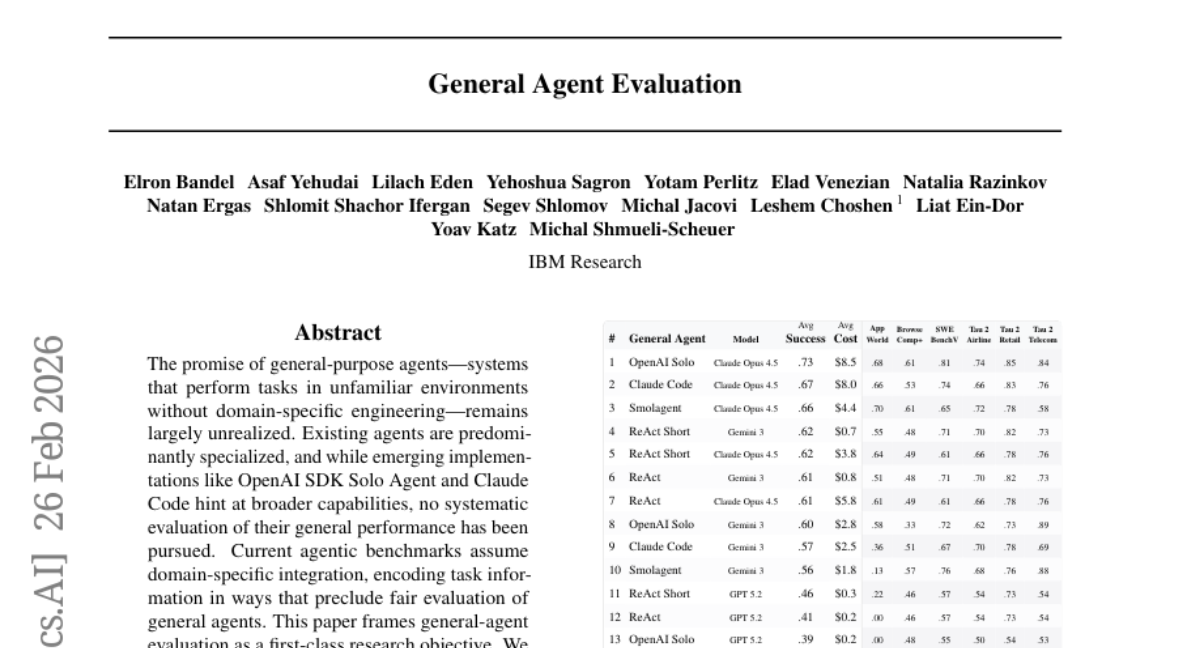
8. General Agent Evaluation
🔑 Keywords: General-purpose agents, Unified Protocol, Exgentic, Evaluation Framework, Open General Agent Leaderboard
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary aim is to establish a systematic evaluation framework for general-purpose agents, assessing their versatility across diverse environments without domain-specific engineering.
🛠️ Research Methods:
– The paper proposes conceptual principles for evaluating general agents and introduces the Unified Protocol to facilitate agent-benchmark integration. Five prominent agent implementations are benchmarked across six environments, forming the Open General Agent Leaderboard.
💬 Research Conclusions:
– General-purpose agents can generalize across varied environments, achieving performance levels comparable to specialized agents without the need for environment-specific tuning. The evaluation protocol, framework, and leaderboard are provided to build a foundation for ongoing research in this field.
👉 Paper link: https://huggingface.co/papers/2602.22953
9. Retrieve and Segment: Are a Few Examples Enough to Bridge the Supervision Gap in Open-Vocabulary Segmentation?
🔑 Keywords: Open-vocabulary segmentation, zero-shot recognition, vision-language models, pixel-level prediction, textual prompts
💡 Category: Computer Vision
🌟 Research Objective:
– To bridge the performance gap between zero-shot and supervised open-vocabulary segmentation through a few-shot setting that augments textual prompts with pixel-annotated images.
🛠️ Research Methods:
– Introduction of a retrieval-augmented test-time adapter that learns a lightweight, per-image classifier by fusing textual and visual support features with learned, per-query fusion.
💬 Research Conclusions:
– The proposed method significantly narrows the gap between zero-shot and supervised segmentation while preserving open-vocabulary capability, allowing for fine-grained tasks such as personalized segmentation with continually expanding support sets.
👉 Paper link: https://huggingface.co/papers/2602.23339

10. DLT-Corpus: A Large-Scale Text Collection for the Distributed Ledger Technology Domain
🔑 Keywords: DLT-Corpus, Distributed Ledger Technology, Natural Language Processing, LedgerBERT, Named Entity Recognition
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to introduce the DLT-Corpus, the largest domain-specific text collection for Distributed Ledger Technology research.
🛠️ Research Methods:
– The researchers collected 2.98 billion tokens from 22.12 million documents, including scientific literature, patents, and social media, to analyze technology emergence and market-innovation correlations.
💬 Research Conclusions:
– Technologies typically emerge from scientific literature before appearing in patents and social media, adhering to traditional technology transfer patterns. Despite market fluctuations, scientific and patent activities continue to grow, fueling innovation. DLT-Corpus and LedgerBERT, a domain-adapted model, are publicly released to facilitate further research.
👉 Paper link: https://huggingface.co/papers/2602.22045

11. No One Size Fits All: QueryBandits for Hallucination Mitigation
🔑 Keywords: QueryBandits, Large Language Models, Hallucinations, Model-agnostic, Query-rewrite strategy
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a contextual bandit framework called QueryBandits to reduce hallucinations in large language models and optimize query-rewrite strategies in closed-source models.
🛠️ Research Methods:
– Utilize a model-agnostic contextual bandit framework that learns online to select optimal query-rewrite strategies leveraging a calibrated reward function.
💬 Research Conclusions:
– QueryBandits, particularly with Thompson Sampling, significantly outperforms No-Rewrite baselines and static policies, demonstrating superior performance in reducing hallucinations across various scenarios.
– The study highlights that no single rewrite policy is optimal for all queries and that static policies can result in higher cumulative regret, emphasizing the advantage of adaptive learning.
👉 Paper link: https://huggingface.co/papers/2602.20332

12. Risk-Aware World Model Predictive Control for Generalizable End-to-End Autonomous Driving
🔑 Keywords: Risk-aware, World Model, Predictive Control, Generalization, End-to-end autonomous driving
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to establish a risk-aware framework for autonomous driving that can generalize beyond expert demonstrations without explicit supervision from experts.
🛠️ Research Methods:
– The proposed framework, named Risk-aware World Model Predictive Control (RaWMPC), employs a world model to predict outcomes of various candidate actions and perform explicit risk assessments for low-risk decision-making, without reliance on expert demonstrations.
💬 Research Conclusions:
– RaWMPC demonstrates superior performance compared to state-of-the-art methods, effectively handling both in-distribution and out-of-distribution scenarios and delivering better decision interpretability.
👉 Paper link: https://huggingface.co/papers/2602.23259

13. Overconfident Errors Need Stronger Correction: Asymmetric Confidence Penalties for Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, AI-generated summary, Large Language Models, Confidence-aware Asymmetric Error Penalty
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance the reasoning diversity in Large Language Models (LLMs) using Reinforcement Learning with Verifiable Rewards by addressing uniform error penalization.
🛠️ Research Methods:
– A new method called Asymmetric Confidence-aware Error Penalty (ACE) is proposed. This includes a per-rollout confidence shift metric to dynamically modulate negative advantages during the reinforcement learning process.
💬 Research Conclusions:
– The ACE method improves performance across the Pass@k spectrum for different model families and benchmarks, addressing overconfident errors and enhancing reasoning boundaries.
👉 Paper link: https://huggingface.co/papers/2602.21420

14. Efficient Continual Learning in Language Models via Thalamically Routed Cortical Columns
🔑 Keywords: continual learning, catastrophic forgetting, sparse thalamic routing, chunk-parallel, stability-plasticity tradeoff
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address continual learning challenges in language models by introducing TRC², a sparse, chunk-parallel architectural design.
🛠️ Research Methods:
– TRC² combines sparse thalamic routing over cortical columns with mechanisms for modulation, prediction, memory, and feedback, alongside a fast corrective pathway to enable efficient training and inference.
💬 Research Conclusions:
– TRC² improves the stability-plasticity tradeoff, allowing for rapid adaptation without compromising previously acquired behaviors, and operates with comparable computational efficiency.
👉 Paper link: https://huggingface.co/papers/2602.22479

15.

16. Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models
🔑 Keywords: video-to-audio generation, long-form audio generation, multimodal hierarchical networks, non-causal Mamba
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address the challenge of scaling multimodal alignment between video and audio, particularly in generating long-form audio from video.
🛠️ Research Methods:
– Integration of hierarchical methods and non-causal Mamba in the development of MMHNet to enhance video-to-audio models for extended audio generation.
💬 Research Conclusions:
– MMHNet significantly improves the capability for generating long-form audio up to more than 5 minutes, outperforming existing video-to-audio approaches without requiring training on long durations.
👉 Paper link: https://huggingface.co/papers/2602.20981

17. MEG-to-MEG Transfer Learning and Cross-Task Speech/Silence Detection with Limited Data
🔑 Keywords: Transfer learning, MEG-based speech models, Conformer-based model, cross-task decoding, pre-training
💡 Category: Machine Learning
🌟 Research Objective:
– The research aimed to showcase the effectiveness of transfer learning in enhancing MEG-based speech decoding across perception and production tasks with minimal fine-tuning data.
🛠️ Research Methods:
– A Conformer-based model was pre-trained on 50 hours of single-subject listening data and then fine-tuned using only 5 minutes of data per subject for 18 participants.
💬 Research Conclusions:
– Transfer learning led to consistent improvements in accuracy, with in-task gains of 1-4% and cross-task gains up to 5-6%.
– Pre-training facilitated reliable cross-task decoding, with models trained on speech production successfully decoding passive listening above chance.
👉 Paper link: https://huggingface.co/papers/2602.18253

18. DyaDiT: A Multi-Modal Diffusion Transformer for Socially Favorable Dyadic Gesture Generation
🔑 Keywords: DyaDiT, multi-modal diffusion transformer, dyadic audio signals, Seamless Interaction Dataset, motion generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop DyaDiT, a multi-modal diffusion transformer to generate contextually appropriate human motion from dyadic audio signals by capturing the interaction dynamics between two speakers.
🛠️ Research Methods:
– Utilizes dyadic audio with optional social-context tokens.
– Employs a motion dictionary to encode motion priors.
– Can utilize the conversational partner’s gestures for more responsive motion generation.
– Evaluation through standard motion generation metrics and quantitative user studies.
💬 Research Conclusions:
– DyaDiT surpasses existing methods on objective metrics.
– Strong user preference indicates robustness and socially favorable motion generation.
– Code and models will be released upon acceptance.
👉 Paper link: https://huggingface.co/papers/2602.23165

19. What Makes a Good Query? Measuring the Impact of Human-Confusing Linguistic Features on LLM Performance
🔑 Keywords: Hallucination, Large Language Model, Query Feature Vector, Clause Complexity, Intention Grounding
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to identify linguistic features in real-world queries that correlate with hallucination likelihood in Large Language Models, helping to define a risk landscape for query design.
🛠️ Research Methods:
– The study utilizes a 22-dimension query feature vector to analyze 369,837 real-world queries, examining factors such as clause complexity, lexical rarity, and intention grounding to assess their impact on hallucination propensity.
💬 Research Conclusions:
– The analysis reveals that deep clause nesting and underspecification increase hallucination risk, while clear intention grounding and answerability decrease it. It establishes an empirically observable representation of query features associated with hallucination risk, suggesting possibilities for guided query rewriting and future interventions.
👉 Paper link: https://huggingface.co/papers/2602.20300

20. MedCLIPSeg: Probabilistic Vision-Language Adaptation for Data-Efficient and Generalizable Medical Image Segmentation
🔑 Keywords: Medical Image Segmentation, CLIP, Probabilistic Attention, Patch-Level Embeddings
💡 Category: AI in Healthcare
🌟 Research Objective:
– To adapt CLIP for medical image segmentation to achieve data-efficient and uncertain-aware segmentation with interpretability.
🛠️ Research Methods:
– Utilize patch-level CLIP embeddings and probabilistic cross-modal attention for bidirectional interaction between image and text tokens.
– Implement a soft patch-level contrastive loss to improve semantic learning across diverse textual prompts.
💬 Research Conclusions:
– MedCLIPSeg outperforms previous methods in accuracy, efficiency, and robustness, while providing interpretable uncertainty maps.
– Demonstrates the potential of probabilistic vision-language modeling for text-driven medical image segmentation.
👉 Paper link: https://huggingface.co/papers/2602.20423

21. veScale-FSDP: Flexible and High-Performance FSDP at Scale
🔑 Keywords: Fully Sharded Data Parallel, veScale-FSDP, structure-aware planning, non-element-wise optimizers, memory efficiency
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces veScale-FSDP, a redesigned system aimed at improving scalability and efficiency for large-scale model training by utilizing flexible sharding and structure-aware planning.
🛠️ Research Methods:
– The study implements veScale-FSDP with a flexible sharding format known as RaggedShard and incorporates a structure-aware planning algorithm to support block-wise quantization and non-element-wise optimizers.
💬 Research Conclusions:
– veScale-FSDP achieves 5~66% higher throughput and 16~30% lower memory usage compared to existing FSDP systems, while efficiently scaling to tens of thousands of GPUs.
👉 Paper link: https://huggingface.co/papers/2602.22437

22. GeoWorld: Geometric World Models
🔑 Keywords: GeoWorld, Hyperbolic JEPA, Geometric Reinforcement Learning, Energy-based predictive world models, Hyperbolic manifolds
💡 Category: Reinforcement Learning
🌟 Research Objective:
– GeoWorld aims to enhance long-horizon prediction performance in energy-based predictive world models by preserving latent state structures using hyperbolic geometry.
🛠️ Research Methods:
– This study introduces GeoWorld, a geometric world model utilizing Hyperbolic JEPA to map latent representations from Euclidean space onto hyperbolic manifolds and employs Geometric Reinforcement Learning for stable multi-step planning.
💬 Research Conclusions:
– Extensive experiments showed around 3% SR improvement in 3-step planning and 2% SR improvement in 4-step planning over state-of-the-art models, highlighting GeoWorld’s effectiveness.
👉 Paper link: https://huggingface.co/papers/2602.23058

23. Causal Motion Diffusion Models for Autoregressive Motion Generation
🔑 Keywords: Causal Motion Diffusion Models, AI Native, Motion-Language-Aligned Causal VAE, text-to-motion generation, autoregressive motion generation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a unified framework for autoregressive motion generation using Causal Motion Diffusion Models (CMDM) to enhance temporal smoothness and semantic fidelity in text-to-motion synthesis.
🛠️ Research Methods:
– Developed CMDM based on a causal diffusion transformer operating in a semantically aligned latent space.
– Utilized a Motion-Language-Aligned Causal VAE for encoding temporally causal latent representations.
– Employed causal diffusion forcing for temporally ordered denoising across motion frames.
💬 Research Conclusions:
– CMDM demonstrates improved performance over existing models in semantic fidelity and temporal smoothness.
– Significantly reduces inference latency, supporting high-quality text-to-motion generation and long-horizon motion generation at interactive rates.
👉 Paper link: https://huggingface.co/papers/2602.22594
24. EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents
🔑 Keywords: AI Native, Embodied AI, Human-Scene Reconstruction, Physics-Based Animation, Robot Motion Control
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to propose EmbodMocap, an affordable and portable system for collecting human motion data using dual iPhones, enabling metric-scale human-scene reconstruction and supporting embodied AI tasks.
🛠️ Research Methods:
– Dual RGB-D sequences are jointly calibrated to construct a unified metric world coordinate frame for humans and scenes, allowing seamless capture without static cameras or markers. This dual-view setting effectively reduces depth ambiguity.
💬 Research Conclusions:
– The dual iPhone system significantly improves alignment and reconstruction compared to single or monocular models. It facilitates three embodied AI tasks: monocular human-scene reconstruction, scalable physics-based animation skills, and training humanoid robots via sim-to-real reinforcement learning, proving the pipeline’s effectiveness in advancing embodied AI research.
👉 Paper link: https://huggingface.co/papers/2602.23205
25. VGG-T^3: Offline Feed-Forward 3D Reconstruction at Scale
🔑 Keywords: 3D reconstruction, test-time training, Multi-Layer Perceptron, scalability, AI-generated summary
💡 Category: Computer Vision
🌟 Research Objective:
– Address scalability limitations in offline feed-forward methods for 3D reconstruction by transforming variable-length key-value representations into fixed-size MLPs.
🛠️ Research Methods:
– Utilize test-time training to distill scene geometry into a fixed-size Multi-Layer Perceptron, enabling linear scaling with the number of input views.
💬 Research Conclusions:
– Achieves significant speedup over traditional softmax attention methods, reconstructing a 1k image collection in just 54 seconds with a 11.6-times speed-up and retaining superior global scene aggregation capability.
👉 Paper link: https://huggingface.co/papers/2602.23361

26. MediX-R1: Open Ended Medical Reinforcement Learning
🔑 Keywords: open-ended reinforcement learning, medical multimodal large language models, clinical reasoning, LLM-based accuracy reward, medical reasoning
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study introduces MediX-R1, an open-ended Reinforcement Learning framework designed to optimize medical multimodal large language models for improved clinical reasoning beyond traditional multiple-choice formats.
🛠️ Research Methods:
– MediX-R1 employs Group Based RL with a composite reward system, including LLM-based accuracy rewards and medical embedding-based semantic rewards, to enhance medical reasoning capabilities in multimodal contexts.
💬 Research Conclusions:
– The framework provides a practical approach for reliable medical reasoning in multimodal models, achieving superior results on both text-only and image+text benchmarks, particularly excelling in open-ended clinical tasks.
👉 Paper link: https://huggingface.co/papers/2602.23363
27. Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization
🔑 Keywords: EMPO², large language model agents, reinforcement learning, exploration, off-policy updates
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance exploration in large language model agents using a hybrid reinforcement learning framework called EMPO², which integrates memory mechanisms with on- and off-policy updates.
🛠️ Research Methods:
– EMPO² leverages memory for exploration and combines on- and off-policy updates. It was tested on platforms like ScienceWorld and WebShop to evaluate its performance improvements over traditional methods.
💬 Research Conclusions:
– EMPO² demonstrated significant performance improvements of 128.6% and 11.3% over GRPO in tested environments, showcasing superior adaptability to new tasks with minimal trials and no parameter updates, thereby validating its potential in building exploratory and generalizable LLM-based agents.
👉 Paper link: https://huggingface.co/papers/2602.23008

28. OmniGAIA: Towards Native Omni-Modal AI Agents
🔑 Keywords: Omni-modal perception, multi-modal LLMs, cross-modal reasoning, tool-integrated reasoning, OmniGAIA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces OmniGAIA, a benchmark designed to evaluate omni-modal agents on complex reasoning tasks across various modalities like video, audio, and images.
🛠️ Research Methods:
– The approach involves a novel omni-modal event graph and utilizes hindsight-guided tree exploration alongside OmniDPO fine-tuning to enhance tool-use capabilities.
💬 Research Conclusions:
– The research presents OmniAtlas, a native omni-modal foundation agent that significantly improves on tool-use, aiming to advance native omni-modal AI assistants for real-world applications.
👉 Paper link: https://huggingface.co/papers/2602.22897

29. From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models
🔑 Keywords: Diagnostic-driven Progressive Evolution, Large Multimodal Models, Reinforcement Learning, targeted reinforcement
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce Diagnostic-driven Progressive Evolution (DPE) to improve Large Multimodal Models by diagnosing and addressing specific weaknesses through targeted data generation and reinforcement.
🛠️ Research Methods:
– Utilizing multiple agents for annotating and quality control of unlabeled multimodal data, employing tools such as web search and image editing to create diverse datasets.
💬 Research Conclusions:
– The application of DPE on Qwen3-VL-8B-Instruct and Qwen2.5-VL-7B-Instruct results in stable, continual improvements across eleven benchmarks, proving DPE as a scalable method for ongoing training of LMMs.
👉 Paper link: https://huggingface.co/papers/2602.22859
