AI Native Daily Paper Digest – 20260302

1. dLLM: Simple Diffusion Language Modeling
🔑 Keywords: Diffusion Language Models, AI-generated summary, Open-source framework, Reproducible Recipes, BERT-style Encoder
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a unified open-source framework that standardizes core components of diffusion language modeling, enhancing reproducibility, customization, and accessibility for both large and small models.
🛠️ Research Methods:
– Introduction of dLLM framework which integrates key aspects of diffusion language modeling like training, inference, and evaluation, providing easy customization for new models. It includes converting BERT-style encoders or autoregressive LMs into diffusion language models.
💬 Research Conclusions:
– The dLLM framework facilitates the reproduction, fine-tuning, deployment, and evaluation of open-source large diffusion language models like LLaDA and Dream. It also offers resources for creating small diffusion language models, making them more accessible and promoting further research in the field.
👉 Paper link: https://huggingface.co/papers/2602.22661

2. Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
🔑 Keywords: semantic drift, context loss, test-time compute scaling, Universal Self-Improvement, T-RANK
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve the reliability of multilingual LLM evaluation by addressing issues of semantic drift and context loss in translated benchmarks.
🛠️ Research Methods:
– A fully automated framework utilizing advanced strategies like Universal Self-Improvement and T-RANK to enhance the quality of dataset translations.
– The framework translates popular benchmarks into eight Eastern and Southern European languages while preserving linguistic nuances.
💬 Research Conclusions:
– The approach significantly improves the quality of translations compared to traditional methods, leading to more accurate downstream model assessment.
– The release of the framework and improved benchmarks aims to support robust and reproducible multilingual AI development.
👉 Paper link: https://huggingface.co/papers/2602.22207

3. Mode Seeking meets Mean Seeking for Fast Long Video Generation
🔑 Keywords: Decoupled Diffusion Transformer, Global Flow Matching, Long-Range Coherence, Mode Seeking, Mean Seeking
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the bottleneck in scaling video generation from seconds to minutes, focusing on improving the coherence of long-form videos while maintaining local fidelity.
🛠️ Research Methods:
– Introduces a training paradigm combining Mode Seeking with Mean Seeking using a Decoupled Diffusion Transformer.
– Utilizes a Global Flow Matching head and a Local Distribution Matching head for supervised learning to achieve narrative structure and slide window alignment.
💬 Research Conclusions:
– The proposed method effectively enhances the generation of minute-scale videos by improving local sharpness, motion, and long-range consistency, thus closing the fidelity-horizon gap.
👉 Paper link: https://huggingface.co/papers/2602.24289
4. CiteAudit: You Cited It, But Did You Read It? A Benchmark for Verifying Scientific References in the LLM Era
🔑 Keywords: Fabricated Citations, Hallucinated Citations, Large Language Models, Multi-Agent Verification Pipeline, Citation Faithfulness
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a comprehensive benchmark and detection framework for identifying fabricated citations in scientific writing, utilizing a multi-agent verification pipeline.
🛠️ Research Methods:
– The study employs a multi-agent verification pipeline which involves processes like claim extraction, evidence retrieval, passage matching, reasoning, and calibrated judgment.
– Constructed a large-scale human-validated dataset across different domains and defined unified metrics for evaluating citation faithfulness and evidence alignment.
💬 Research Conclusions:
– The experiments with state-of-the-art LLMs indicated significant citation errors.
– The proposed framework significantly outperforms prior methods in terms of accuracy and interpretability, providing scalable infrastructure and practical tools to improve the trustworthiness of scientific references in the LLM era.
👉 Paper link: https://huggingface.co/papers/2602.23452

5. InfoNCE Induces Gaussian Distribution
🔑 Keywords: Contrastive learning, InfoNCE, Gaussian structure, representation learning, encoder architectures
💡 Category: Machine Learning
🌟 Research Objective:
– To explore how the InfoNCE objective induces Gaussian structures in contrastive learning representations.
🛠️ Research Methods:
– Performed theoretical analysis and experimental validation across different datasets and architectures, specifically focusing on high-dimensional representations and multivariate Gaussian distributions.
💬 Research Conclusions:
– The study provides evidence that under specific assumptions, representations tend to exhibit Gaussian behavior. This insight offers a principled explanation for Gaussianity in contrastive learning representations and supports a wide range of potential applications.
👉 Paper link: https://huggingface.co/papers/2602.24012

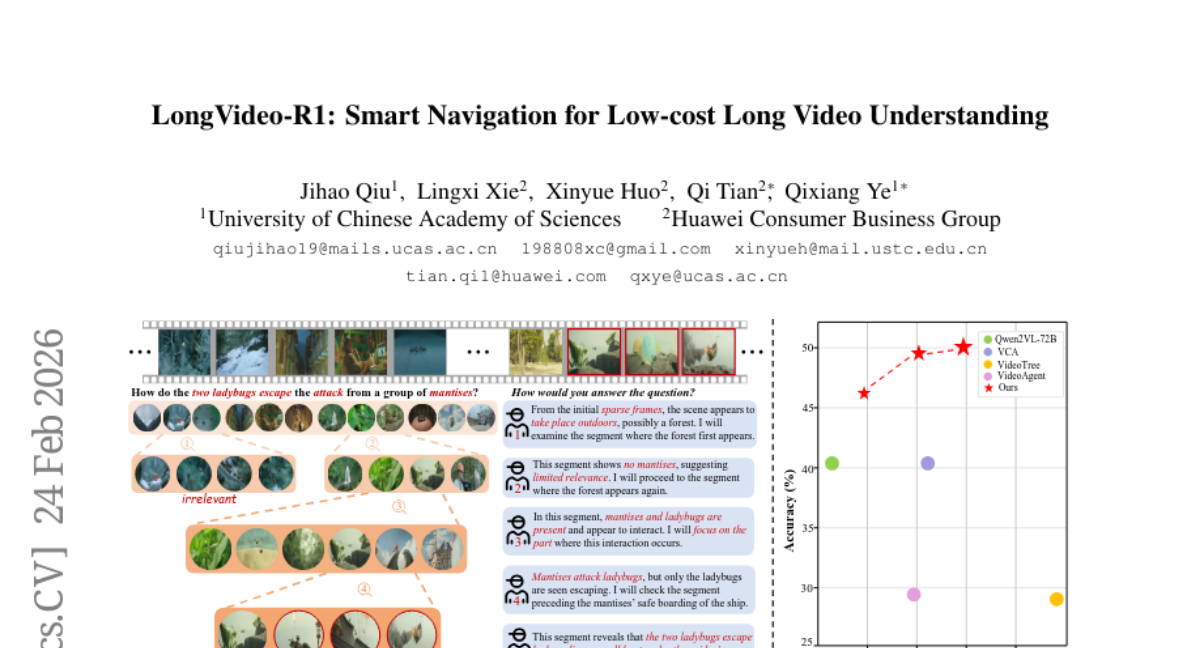
6. LongVideo-R1: Smart Navigation for Low-cost Long Video Understanding
🔑 Keywords: LongVideo-R1, multimodal large language model, video context navigation, selective clip navigation, reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop LongVideo-R1, a multimodal large language model agent designed for efficient understanding of long videos with reduced computational requirements.
🛠️ Research Methods:
– Utilization of a reasoning module for selective clip navigation.
– Implementation of a two-stage fine-tuning paradigm: supervised fine-tuning followed by reinforcement learning to optimize clip navigation.
💬 Research Conclusions:
– LongVideo-R1 demonstrates a superior balance between question-answering accuracy and computational efficiency, backed by experiments on several long video benchmarks.
– All curated data and source code are available for public access.
👉 Paper link: https://huggingface.co/papers/2602.20913
7. Memory Caching: RNNs with Growing Memory
🔑 Keywords: Memory Caching, Transformers, Recurrent Models, Memory Capacity, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance recurrent models by introducing Memory Caching, allowing their memory capacity to scale with sequence length in long-context tasks, bridging the gap between traditional RNNs and Transformers.
🛠️ Research Methods:
– The authors propose four variants of Memory Caching, including gated aggregation and sparse selective mechanisms, to evaluate their implications on linear and deep memory modules through experiments on language modeling and long-context understanding tasks.
💬 Research Conclusions:
– Memory Caching significantly enhances the performance of recurrent models in context tasks, making them competitive with Transformers and outperforming state-of-the-art recurrent models in in-context recall tasks.
👉 Paper link: https://huggingface.co/papers/2602.24281

8. Shared Nature, Unique Nurture: PRISM for Pluralistic Reasoning via In-context Structure Modeling
🔑 Keywords: Large Language Models, Artificial Hivemind, PRISM, Epistemic Evolution, Pluralistic AI
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to address the convergence of large language models into a singular artificial hivemind by introducing individualized epistemic trajectories to enhance creativity and diagnostic accuracy.
🛠️ Research Methods:
– The research utilizes the PRISM system, which employs dynamic on-the-fly epistemic graphs to allow for pluralistic reasoning and enhance distributional diversity.
💬 Research Conclusions:
– PRISM achieves state-of-the-art novelty on creativity benchmarks, successfully uncovering accurate diagnoses in a rare-disease benchmark, and promotes a diverse ecosystem beyond monolithic consensus in AI.
👉 Paper link: https://huggingface.co/papers/2602.21317

9. Vectorizing the Trie: Efficient Constrained Decoding for LLM-based Generative Retrieval on Accelerators
🔑 Keywords: STATIC, constrained decoding, generative retrieval, hardware accelerators, prefix trees
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary goal of this research is to introduce STATIC, an efficient constrained decoding method designed to accelerate generative retrieval on hardware accelerators while maintaining low latency and high throughput.
🛠️ Research Methods:
– The authors propose transforming a prefix tree into a static Compressed Sparse Row (CSR) matrix to enable fully vectorized sparse matrix operations, thereby improving performance on TPUs and GPUs.
💬 Research Conclusions:
– STATIC results in substantial product metric improvements with minimal latency overhead. It achieves a remarkable speedup over traditional implementations, marking the first production-scale deployment of strictly constrained generative retrieval, and showcases improved cold-start performance in academic benchmarks.
👉 Paper link: https://huggingface.co/papers/2602.22647

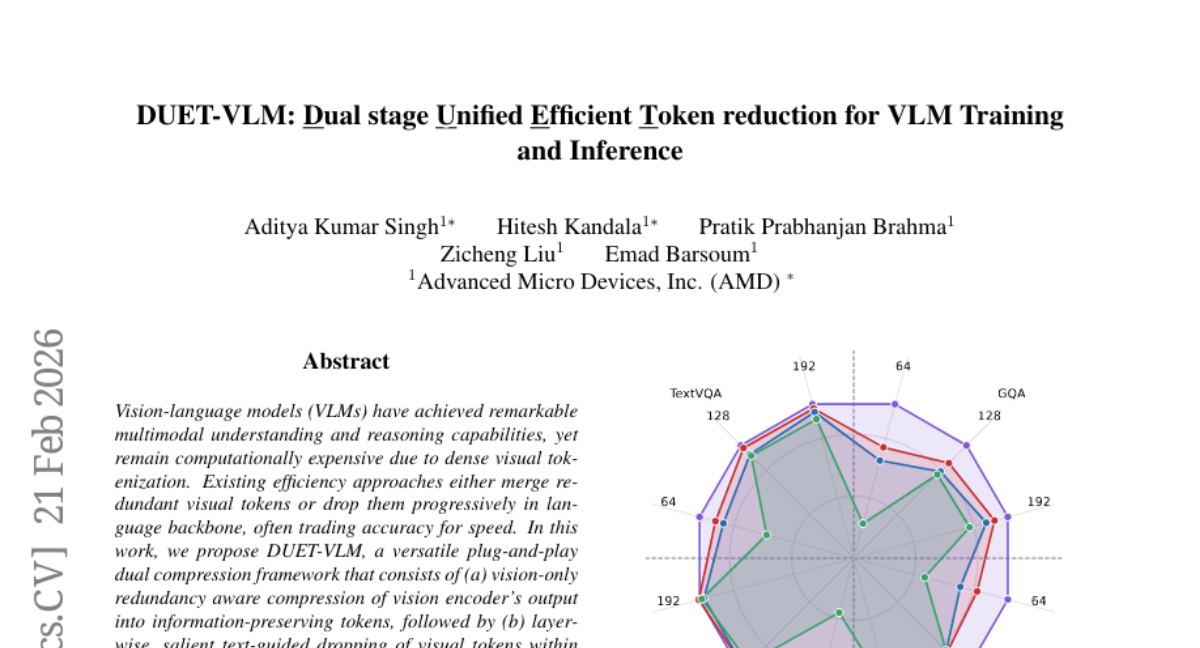
10. DUET-VLM: Dual stage Unified Efficient Token reduction for VLM Training and Inference
🔑 Keywords: DUET-VLM, Vision-language models, Visual tokenization, End-to-end training, Multimodal understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose a dual compression framework, DUET-VLM, aimed at reducing visual tokens while maintaining high accuracy in vision-language models.
🛠️ Research Methods:
– Implement a two-stage framework involving redundancy-aware compression of vision encoder outputs and layer-wise text-guided token pruning in the language backbone.
💬 Research Conclusions:
– DUET-VLM sustains over 99% baseline accuracy with a 67% reduction in tokens, and maintains significant accuracy even at an 89% reduction. It outperforms existing methods, demonstrating the ability to retain semantic richness while optimizing computation.
👉 Paper link: https://huggingface.co/papers/2602.18846
11.

12. DLEBench: Evaluating Small-scale Object Editing Ability for Instruction-based Image Editing Model
🔑 Keywords: Instruction-based Image Editing Models, DeepLookEditBench, small-scale object editing, benchmark, evaluation protocol
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce DeepLookEditBench, a new benchmark designed to evaluate the capability of Instruction-based Image Editing Models in editing small-scale objects.
🛠️ Research Methods:
– Construct a challenging testbed with 1889 samples across seven instruction types, covering targets that occupy only 1%-10% of the image area.
– Propose an evaluation protocol with refined score rubrics and a dual-mode evaluation framework to ensure robust evaluation.
💬 Research Conclusions:
– Empirical results identify significant performance gaps in small-scale object editing, emphasizing the necessity for specialized benchmarks to enhance this capability in image editing models.
👉 Paper link: https://huggingface.co/papers/2602.23622

13. How to Take a Memorable Picture? Empowering Users with Actionable Feedback
🔑 Keywords: Memorability Feedback, Multimodal Large Language Models, AI-generated summary, teacher-student steering strategy, MemBench
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Memorability Feedback to provide actionable and interpretable guidance to enhance image memorability at capture time.
🛠️ Research Methods:
– Utilization of Multimodal Large Language Models (MLLMs) in a training-free environment with a teacher-student steering strategy to guide model activations.
– Development of MemCoach for delivering natural language suggestions to improve photo memorability.
💬 Research Conclusions:
– MemCoach demonstrates significant improvements over zero-shot models in enhancing image memorability.
– The study expands the focus from mere prediction of image memorability to providing actionable feedback for creators via systematic evaluation with MemBench.
👉 Paper link: https://huggingface.co/papers/2602.21877

14. CL4SE: A Context Learning Benchmark For Software Engineering Tasks
🔑 Keywords: Context Learning, Software Engineering, Large Language Models, Context Types, AI-generated summary
💡 Category: Machine Learning
🌟 Research Objective:
– The research aims to establish CL4SE, a comprehensive benchmark for evaluating the impact of context learning in software engineering tasks with a focus on improving performance without model fine-tuning.
🛠️ Research Methods:
– The study proposes a taxonomy containing four SE-oriented context types, evaluates five mainstream LLMs across nine metrics, and utilizes a dataset of over 13,000 samples sourced from more than 30 open-source projects.
💬 Research Conclusions:
– Context learning shows a significant average performance improvement of 24.7% across tasks. Notable enhancements include a 33% increase in code review performance, a 30% boost in patch assessment accuracy, a 14.78% rise in BLEU score for code summarization, and a 5.72% improvement in code generation accuracy.
👉 Paper link: https://huggingface.co/papers/2602.23047

15. SenCache: Accelerating Diffusion Model Inference via Sensitivity-Aware Caching
🔑 Keywords: Sensitivity-Aware Caching, Diffusion Models, AI-Generated Summary, Denoising Steps, Visual Quality
💡 Category: Generative Models
🌟 Research Objective:
– To improve diffusion model inference efficiency through a sensitivity-aware caching framework that selects cache timesteps dynamically.
🛠️ Research Methods:
– Analysis of model output sensitivity to input perturbations to inform caching errors, leading to the development of a dynamic policy, Sensitivity-Aware Caching (SenCache).
💬 Research Conclusions:
– SenCache provides better visual quality compared to existing caching methods within similar computational budgets, offering a theoretical basis for adaptive caching.
👉 Paper link: https://huggingface.co/papers/2602.24208

16. Ref-Adv: Exploring MLLM Visual Reasoning in Referring Expression Tasks
🔑 Keywords: Ref-Adv, referring expression comprehension, multimodal LLMs, visual reasoning, grounding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Ref-Adv, a benchmark designed to address limitations in referring expression comprehension by enhancing visual reasoning capabilities in multimodal LLMs, through the use of linguistically complex expressions and hard distractors.
🛠️ Research Methods:
– Conducted comprehensive ablations including word order perturbations and descriptor deletion sufficiency to demonstrate the need for advanced reasoning beyond simple cues.
💬 Research Conclusions:
– Ref-Adv reveals significant reliance on shortcut solutions by current models and exposes gaps in their visual reasoning and grounding abilities, providing insights for future work in this domain.
👉 Paper link: https://huggingface.co/papers/2602.23898

17. Accelerating Masked Image Generation by Learning Latent Controlled Dynamics
🔑 Keywords: MIGM-Shortcut, Masked Image Generation, lightweight model, feature evolution, text-to-image generation
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address inefficiencies in Masked Image Generation Models by introducing MIGM-Shortcut, which accelerates image generation while maintaining quality.
🛠️ Research Methods:
– The approach involves learning a lightweight model that predicts the velocity of feature evolution by incorporating previous features and sampled tokens, applied to two MIGM architectures.
💬 Research Conclusions:
– MIGM-Shortcut achieves over 4x acceleration in text-to-image generation on the Lumina-DiMOO architecture without compromising quality, enhancing efficiency and advancing the Pareto frontier in masked image generation.
👉 Paper link: https://huggingface.co/papers/2602.23996

18. Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models
🔑 Keywords: Compositional generalization, neural representations, Linear Representation Hypothesis, vision models, partial linear factorization
💡 Category: Foundations of AI
🌟 Research Objective:
– The study aims to investigate compositional generalization in vision models by examining the structure of neural representations and determining the necessary conditions for generalization to unseen combinations.
🛠️ Research Methods:
– The authors formalize three desiderata for compositional generalization: divisibility, transferability, and stability. They analyze geometric constraints, conduct empirical evaluations on models like CLIP, SigLIP, and DINO, and derive dimension bounds linking concepts to representation geometry.
💬 Research Conclusions:
– The research shows that neural representations must decompose linearly into orthogonal per-concept components, correlating with compositional generalization. These findings provide theoretical support for the Linear Representation Hypothesis and suggest that scaling models will maintain these geometric conditions. Models exhibit partial linear factorization with low-rank, near-orthogonal factors, and code is made available for further exploration.
👉 Paper link: https://huggingface.co/papers/2602.24264

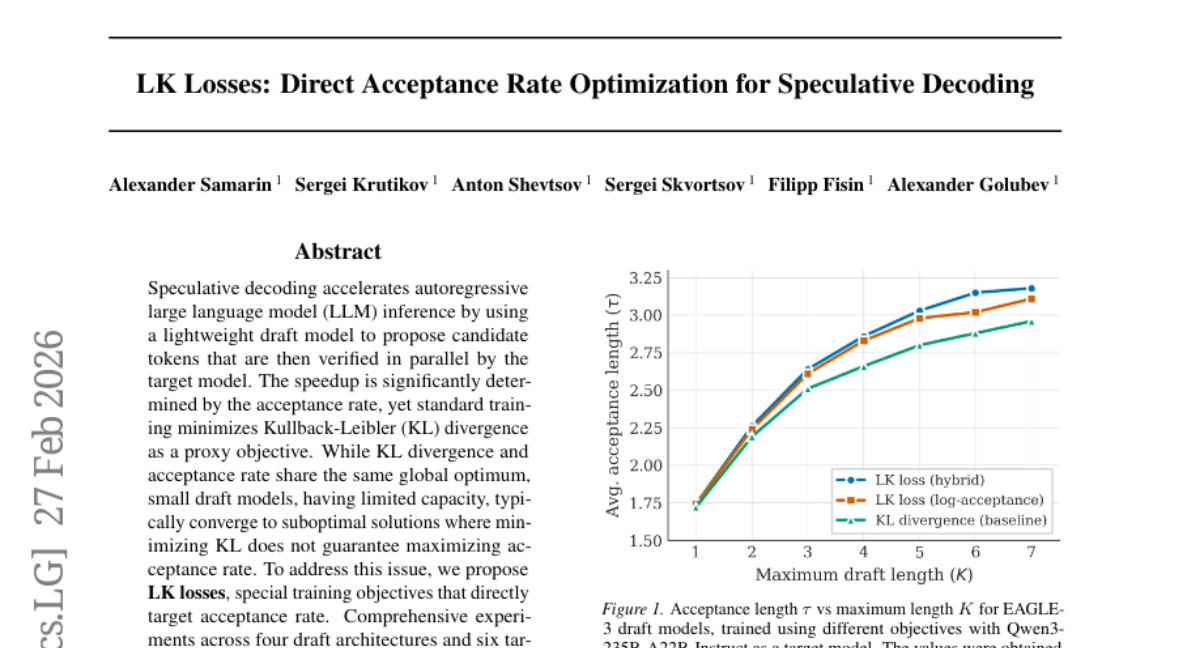
19. LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding
🔑 Keywords: Speculative decoding, Large language model, Draft model, Acceptance rate, LK losses
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve speculative decoding speedup by optimizing acceptance rates directly using LK losses instead of relying on KL divergence.
🛠️ Research Methods:
– Comprehensive experiments were conducted across four draft architectures and six target models, with parameters ranging from 8B to 685B. Different domains, including general, coding, and math, were tested to evaluate the approach.
💬 Research Conclusions:
– The use of LK losses consistently enhanced acceptance metrics across all configurations, achieving improvements of up to 8-10% in average acceptance length compared to standard KL-based training. LK losses are simple to implement, add no extra computational burden, and can be easily integrated into existing frameworks.
👉 Paper link: https://huggingface.co/papers/2602.23881
20. CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
🔑 Keywords: CUDA Agent, Reinforcement Learning, CUDA kernel optimization, skill-augmented development, automated verification
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to address the complex task of GPU kernel optimization through the development of CUDA Agent, a large-scale agentic reinforcement learning system, focusing on enhancing CUDA kernel expertise.
🛠️ Research Methods:
– Utilizes a combination of scalable data synthesis, a skill-augmented CUDA development environment with automated verification and profiling, and reinforcement learning algorithmic techniques for stable training.
💬 Research Conclusions:
– CUDA Agent achieves state-of-the-art performance, delivering significantly faster rates on KernelBench compared to existing systems, including outperforming proprietary models on the hardest settings.
👉 Paper link: https://huggingface.co/papers/2602.24286

21. Enhancing Spatial Understanding in Image Generation via Reward Modeling
🔑 Keywords: SpatialScore, text-to-image generation, spatial relationships, reward model, reinforcement learning
💡 Category: Generative Models
🌟 Research Objective:
– To improve spatial relationship understanding in text-to-image generation through a new reward model called SpatialScore.
🛠️ Research Methods:
– Constructed a large-scale dataset of over 80k preference pairs (SpatialReward-Dataset) and developed SpatialScore for spatial relationship evaluation.
– Applied online reinforcement learning to enhance complex spatial generation tasks.
💬 Research Conclusions:
– The SpatialScore reward model improves spatial understanding significantly, surpassing leading proprietary models in spatial evaluation.
– Extensive experiments on multiple benchmarks showed consistent improvements in spatial understanding for image generation tasks.
👉 Paper link: https://huggingface.co/papers/2602.24233
