AI Native Daily Paper Digest – 20260303

1. From Scale to Speed: Adaptive Test-Time Scaling for Image Editing
🔑 Keywords: Image-CoT, Image Editing, Adaptive Resource Allocation, Verification, Performance-Efficiency Trade-offs
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance image editing efficiency and performance using an ADaptive Edit-CoT (ADE-CoT) framework.
🛠️ Research Methods:
– Implementing difficulty-aware resource allocation with dynamic budgets.
– Conducting edit-specific verification with region localization and caption consistency.
– Utilizing depth-first opportunistic stopping with an instance-specific verifier.
💬 Research Conclusions:
– ADE-CoT significantly improves the performance-efficiency trade-offs in image editing, achieving over 2x speedup compared to Best-of-N methods while maintaining comparable sampling budgets.
👉 Paper link: https://huggingface.co/papers/2603.00141

2. SWE-rebench V2: Language-Agnostic SWE Task Collection at Scale
🔑 Keywords: AI-generated summary, Reinforcement Learning, language-agnostic, automated pipeline, LLM judges
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to create a comprehensive dataset for software engineering tasks across multiple programming languages and repositories using an automated pipeline, ultimately aiding the reinforcement learning training process.
🛠️ Research Methods:
– An automated pipeline was developed that synthesizes installation and test procedures for repositories and filters tasks through an ensemble of LLM judges. The data includes tasks from 20 languages and 3,600 repositories, along with metadata and diagnostic studies for validation.
💬 Research Conclusions:
– The research introduces and releases the SWE-rebench V2 dataset, enhancing the training potential of software engineering agents with its diverse and reproducible task collection, aiming for large-scale reinforcement learning applications.
👉 Paper link: https://huggingface.co/papers/2602.23866

3. OpenAutoNLU: Open Source AutoML Library for NLU
🔑 Keywords: OpenAutoNLU, Automated Machine Learning, Natural Language Understanding, Data-aware Training, LLM Features
💡 Category: Natural Language Processing
🌟 Research Objective:
– The aim of OpenAutoNLU is to provide an open-source automated machine learning library tailored for NLU tasks, particularly text classification and named entity recognition.
🛠️ Research Methods:
– The library utilizes a data-aware training regime selection that eliminates the need for user manual configuration, integrates data quality diagnostics, OOD detection, and LLM features, operated through a low-code interface.
💬 Research Conclusions:
– OpenAutoNLU stands out by offering automated data-aware configurations for NLU tasks, enhancing usability and efficiency in text analysis while integrating advanced diagnostics and LLM capabilities.
👉 Paper link: https://huggingface.co/papers/2603.01824

4. CHIMERA: Compact Synthetic Data for Generalizable LLM Reasoning
🔑 Keywords: CHIMERA, Cross-domain reasoning, Synthetic reasoning dataset, Chain-of-Thought, Hierarchical taxonomy
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to overcome data-centric challenges in training Large Language Models (LLMs) for cross-domain reasoning by introducing a synthetic reasoning dataset called CHIMERA, which provides performance comparable to much larger models.
🛠️ Research Methods:
– CHIMERA is constructed with three key properties: it includes rich Chain-of-Thought (CoT) reasoning trajectories, broad domain coverage across eight major scientific disciplines, and a fully automated evaluation pipeline for validating problem solvency and answer accuracy.
💬 Research Conclusions:
– Utilizing CHIMERA to post-train a 4B Qwen3 model demonstrated strong performance on various reasoning benchmarks, suggesting that even modestly sized datasets can significantly enhance reasoning performance, approaching or matching larger models like DeepSeek-R1 and Qwen3-235B.
👉 Paper link: https://huggingface.co/papers/2603.00889

5. CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
🔑 Keywords: CoVe, task constraints, interactive tool-use agents, reinforcement learning, AI-generated summary
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce CoVe, a post-training data synthesis framework, which leverages task constraints for generating high-quality training trajectories for interactive tool-use agents.
🛠️ Research Methods:
– CoVe defines explicit task constraints that guide trajectory generation and act as verifiers to ensure data complexity and correctness, supporting both supervised fine-tuning and reinforcement learning.
💬 Research Conclusions:
– CoVe effectively synthesizes training data, with the CoVe-4B model significantly outperforming similar scale models in specific domains, and staying competitive against much larger models, highlighting efficiency and effectiveness for advancing interactive tool-use agents.
👉 Paper link: https://huggingface.co/papers/2603.01940

6. LLaDA-o: An Effective and Length-Adaptive Omni Diffusion Model
🔑 Keywords: Omni Diffusion Model, Multimodal Understanding, Visual Generation, Mixture of Diffusion, Length Adaptation Strategy
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces LLaDA-o, an Omni Diffusion Model, designed to enhance multimodal understanding and visual generation.
🛠️ Research Methods:
– LLaDA-o utilizes a Mixture of Diffusion framework to separate discrete masked diffusion for text understanding and continuous diffusion for visual generation, connected by a shared attention backbone.
– The model incorporates a data-centric length adaptation strategy for flexible-length decoding in multimodal settings.
💬 Research Conclusions:
– LLaDA-o achieves state-of-the-art performance on multimodal understanding and generation benchmarks, scoring 87.04 on DPG-Bench for text-to-image generation tasks, highlighting its effectiveness.
👉 Paper link: https://huggingface.co/papers/2603.01068

7. WorldStereo: Bridging Camera-Guided Video Generation and Scene Reconstruction via 3D Geometric Memories
🔑 Keywords: WorldStereo, Video Diffusion Models, camera-guided video generation, 3D reconstruction, geometric memory modules
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces WorldStereo, a framework to improve camera-guided video generation and 3D reconstruction by integrating precise camera control and 3D correspondence constraints.
🛠️ Research Methods:
– The authors utilize two geometric memory modules: global-geometric memory for structural priors and spatial-stereo memory for attention on fine-grained details, to achieve consistent video generation and high-quality 3D reconstruction.
💬 Research Conclusions:
– Extensive experiments demonstrate that WorldStereo effectively generates coherent multi-view videos and accomplishes high-fidelity 3D scene generation. The framework operates efficiently without joint training due to its flexible control structure and distribution matching VDM backbone.
👉 Paper link: https://huggingface.co/papers/2603.02049

8. Learn Hard Problems During RL with Reference Guided Fine-tuning
🔑 Keywords: Reference-Guided Fine-Tuning, Reinforcement Learning, Mathematical Reasoning, Reward Sparsity
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Address reward sparsity in reinforcement learning for mathematical reasoning using Reference-Guided Fine-Tuning.
🛠️ Research Methods:
– Introduce human-written reference solutions to synthesize positive trajectories on difficult problems, fine-tuning models to generate their reasoning trace within their reasoning space.
💬 Research Conclusions:
– ReGFT improves supervised accuracy, accelerates DAPO training, and enhances final RL performance by effectively overcoming reward sparsity in mathematical reasoning.
👉 Paper link: https://huggingface.co/papers/2603.01223

9. Tool-R0: Self-Evolving LLM Agents for Tool-Learning from Zero Data
🔑 Keywords: Tool-R0 framework, self-play reinforcement learning, tool-calling agents, zero-data assumption, co-evolution
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a framework, Tool-R0, for training general-purpose tool-calling agents through self-play reinforcement learning without the need for initial datasets.
🛠️ Research Methods:
– Initializing from a base LLM, the Tool-R0 framework co-evolves a Generator and a Solver with complementary rewards, enabling the development of agentic capabilities without pre-existing tasks or datasets under a zero-data assumption.
💬 Research Conclusions:
– Tool-R0 demonstrated a 92.5% improvement over the base model and outperformed fully supervised tool-calling baselines, offering insights into self-play LLM agents’ co-evolution, curriculum dynamics, and scaling behavior.
👉 Paper link: https://huggingface.co/papers/2602.21320

10. Half-Truths Break Similarity-Based Retrieval
🔑 Keywords: CLIP-style models, half-truths, AI-generated summary, contrastive training, CS-CLIP
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address the vulnerabilities of CLIP-style models to half-truths and improve compositional understanding in image-text relationships.
🛠️ Research Methods:
– Utilize component-supervised fine-tuning by decomposing captions into entity and relation units and creating minimally edited foils to enhance model accuracy.
💬 Research Conclusions:
– The proposed CS-CLIP method significantly improves half-truth accuracy from 40.6% to 69.3% and enhances performance on compositional benchmarks by 5.7 points.
👉 Paper link: https://huggingface.co/papers/2602.23906

11. Spectral Attention Steering for Prompt Highlighting
🔑 Keywords: Spectral Editing Key Amplification, Adaptive SEKA, attention steering, key embeddings, memory-efficient
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce and evaluate Spectral Editing Key Amplification (SEKA) and its adaptive variant AdaSEKA for efficient attention steering by modifying key embeddings.
🛠️ Research Methods:
– Utilized spectral decomposition to steer key embeddings effectively and developed a query-adaptive variant, AdaSEKA, using a training-free routing mechanism.
💬 Research Conclusions:
– Demonstrated that SEKA and AdaSEKA outperform existing methods on standard steering benchmarks with lower latency and reduced memory overhead, compatible with optimized attention mechanisms like FlashAttention.
👉 Paper link: https://huggingface.co/papers/2603.01281

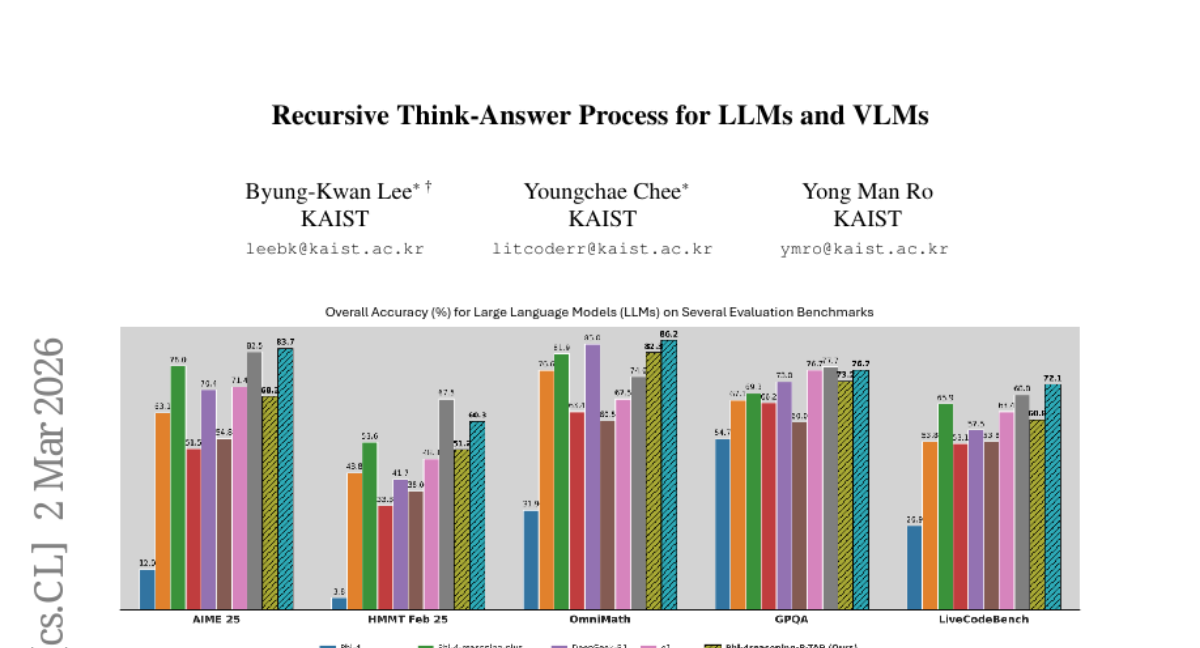
12. Recursive Think-Answer Process for LLMs and VLMs
🔑 Keywords: Recursive Think-Answer Process, iterative reasoning cycles, confidence-based reinforcement learning, large language models, vision-language models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance language and vision-language models by introducing a Recursive Think-Answer Process (R-TAP) that improves accuracy and reduces errors through iterative reasoning cycles.
🛠️ Research Methods:
– Development of R-TAP with a confidence generator that evaluates model response certainty, incorporating two rewards: Recursively Confidence Increase Reward and Final Answer Confidence Reward.
💬 Research Conclusions:
– R-TAP-enhanced models outperform conventional single-pass methods, reducing self-reflective errors and improving inference stability and speed in large language and vision-language models.
👉 Paper link: https://huggingface.co/papers/2603.02099
13. Reasoning Core: A Scalable Procedural Data Generation Suite for Symbolic Pre-training and Post-Training
🔑 Keywords: Reasoning Core, symbolic reasoning, PDDL planning, causal reasoning, reinforcement learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The main objective is to create Reasoning Core, a scalable system that generates verifiable symbolic reasoning data to enhance the reasoning capabilities of language models.
🛠️ Research Methods:
– The study introduces a scalable suite that generates symbolic reasoning data across various formal domains, such as PDDL planning, first-order logic, context-free grammar parsing, and causal reasoning. This includes continuous difficulty control and the use of external solvers for rigorous verification.
💬 Research Conclusions:
– Incorporating Reasoning Core data in pre-training improves downstream reasoning, slightly enhances or maintains language modeling quality, and poses challenges to current frontier models like GPT-5. Publicly available under the MIT license, the system supports supervised training and reinforcement learning via verifiable reward functions.
👉 Paper link: https://huggingface.co/papers/2603.02208

14. CharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
🔑 Keywords: CharacterFlywheel, large language models, social chat applications, engagement improvement, instruction following
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance large language models used in social chat applications through an iterative optimization process to improve user engagement and instruction adherence.
🛠️ Research Methods:
– Employed a process called CharacterFlywheel which includes data curation, reward modeling, supervised fine-tuning, reinforcement learning, and A/B testing across 15 generations.
💬 Research Conclusions:
– Demonstrated significant improvements in model performance with up to 8.8% increase in engagement breadth and 19.4% in depth, and a marked enhancement in instruction following from 59.2% to 84.8%.
👉 Paper link: https://huggingface.co/papers/2603.01973

15. ArtLLM: Generating Articulated Assets via 3D LLM
🔑 Keywords: ArtLLM, 3D multimodal large language model, kinematic structure, 3D generative model, articulation-aware layout
💡 Category: Generative Models
🌟 Research Objective:
– Introduce ArtLLM, which generates high-quality articulated 3D assets from complete 3D meshes to enhance interactive digital environments for various applications.
🛠️ Research Methods:
– Utilizes a 3D multimodal large language model trained on a large-scale articulation dataset to predict parts, joints, and their kinematic structures, which then inform a 3D generative model to create high-fidelity geometries.
💬 Research Conclusions:
– ArtLLM significantly outperforms state-of-the-art methods in part layout accuracy and joint prediction, with robust generalization to real-world objects and potential for scalable robot learning.
👉 Paper link: https://huggingface.co/papers/2603.01142

16. Synthetic Visual Genome 2: Extracting Large-scale Spatio-Temporal Scene Graphs from Videos
🔑 Keywords: Synthetic Visual Genome 2, TRaSER, scene graph, spatio-temporal representations, video question answering
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a large-scale video scene graph dataset, SVG2, to enhance relation and object prediction, as well as improve video question answering through spatio-temporal representations.
🛠️ Research Methods:
– Developed an automated pipeline for dataset creation, employing multi-scale panoptic segmentation, trajectory tracking, and GPT-5-based spatio-temporal relation inference.
– Designed the TRaSER model, incorporating trajectory-aligned token arrangement and novel resampling modules for generating compact scene graphs from videos.
💬 Research Conclusions:
– TRaSER significantly improves relation, object, and attribute prediction over existing baselines and GPT-5.
– Enhances video question answering accuracy by using explicit spatio-temporal scene graphs as intermediate representations.
👉 Paper link: https://huggingface.co/papers/2602.23543

17. Classroom Final Exam: An Instructor-Tested Reasoning Benchmark
🔑 Keywords: Multimodal Benchmark, Reasoning Capabilities, Large Language Models, STEM Domains
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study introduces the Classroom Final Exam (CFE), a multimodal benchmark designed to evaluate the reasoning capabilities of large language models across over 20 STEM domains using authentic exam problems and instructor solutions.
🛠️ Research Methods:
– The benchmark consists of authentic university homework and exam problems, with reference solutions provided by course instructors. A diagnostic analysis is conducted by decomposing reference solutions into reasoning flows.
💬 Research Conclusions:
– The findings highlight that while frontier models can often handle intermediate sub-questions, they struggle with maintaining correct intermediate states throughout multi-step solutions. Furthermore, model-generated solutions tend to include more reasoning steps than those by instructors, suggesting suboptimal step efficiency and a higher risk of error accumulation.
👉 Paper link: https://huggingface.co/papers/2602.19517

18. FireRed-OCR Technical Report
🔑 Keywords: FireRed-OCR, Large Vision-Language Models, OCR, structured data, Three-Stage Progressive Training
💡 Category: Computer Vision
🌟 Research Objective:
– The study introduces FireRed-OCR, aiming to convert general Vision-Language Models (VLMs) into high-performance OCR systems designed for industrial applications.
🛠️ Research Methods:
– The paper employs a structured data synthesis strategy using a “Geometry + Semantics” Data Factory and a Three-Stage Progressive Training approach which includes Multi-task Pre-alignment, Specialized SFT, and GRPO.
💬 Research Conclusions:
– FireRed-OCR achieves state-of-the-art performance with a score of 92.94% on the OmniDocBench v1.5, outperforming other baselines such as DeepSeek-OCR 2 and OCRVerse, and it has been open-sourced to support further research in specialized document parsing models.
👉 Paper link: https://huggingface.co/papers/2603.01840

19. MicroVerse: A Preliminary Exploration Toward a Micro-World Simulation
🔑 Keywords: Microscale simulation, MicroVerse, MicroWorldBench, Biomedical applications, Educational microscale simulation
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the challenges in video generation models for microscale simulation tasks by developing MicroVerse, a specialized model trained on expert-verified simulation data to accurately reproduce complex microscopic mechanisms.
🛠️ Research Methods:
– Introduction of MicroWorldBench, a multi-level rubric-based benchmark with 459 expert-annotated criteria for evaluating microscale simulation tasks. The construction of the MicroSim-10K dataset serves as a high-quality resource for training MicroVerse.
💬 Research Conclusions:
– Existing state-of-the-art video generation models fail to meet the demands of microscale simulation, exhibiting issues such as physical law violations and temporal inconsistency. MicroVerse, leveraging the MicroSim-10K dataset, successfully reproduces complex microscale mechanisms and opens up new possibilities for educational and scientific applications in biology and other fields.
👉 Paper link: https://huggingface.co/papers/2603.00585

20. Using Songs to Improve Kazakh Automatic Speech Recognition
🔑 Keywords: AI-generated summary, low-resource languages, audio-text pairs, Whisper, fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to explore the use of songs as a data source to improve automatic speech recognition (ASR) systems for low-resource languages, specifically Kazakh.
🛠️ Research Methods:
– The study involves curating a dataset of 3,013 audio-text pairs from 195 songs. Models are fine-tuned using Whisper as the base recognizer and are evaluated on various training scenarios and benchmarks like CVC, FLEURS, and Kazakh Speech Corpus 2.
💬 Research Conclusions:
– Song-based data augmentation demonstrates improvement in ASR performance over zero-shot baselines, showing significant reductions in error rates on various benchmarks compared to models trained without song data. Despite not reaching the performance of models trained on larger datasets, the approach provides meaningful benefits in low-resource settings. The dataset is made publicly available under a non-commercial license for further research.
👉 Paper link: https://huggingface.co/papers/2603.00961

21. Monocular Mesh Recovery and Body Measurement of Female Saanen Goats
🔑 Keywords: 3D body measurement, parametric shape model, multi-view fusion, Saanen goats, precision livestock farming
💡 Category: Computer Vision
🌟 Research Objective:
– To develop an automated and accurate system for 3D body measurement of Saanen goats to assess their milk production potential.
🛠️ Research Methods:
– Utilized a dataset of synchronized eight-view RGBD videos from 55 female Saanen goats.
– Employed multi-view DynamicFusion to convert noisy point cloud sequences into high-fidelity 3D scans.
– Developed the SaanenGoat parametric 3D shape model tailored specifically for female Saanen goats, incorporating detailed skeletal joints and udder representation.
💬 Research Conclusions:
– The novel system achieved high-precision 3D reconstruction and automated measurement of critical body dimensions, demonstrating superior accuracy and presenting a new paradigm for large-scale 3D vision applications in precision livestock farming.
👉 Paper link: https://huggingface.co/papers/2602.19896

22.

23. Planning from Observation and Interaction
🔑 Keywords: Inverse Reinforcement Learning, real-world robot learning, observational learning, online transfer learning, sample efficiency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to develop a planning-based Inverse Reinforcement Learning (IRL) algorithm to enable real-world robot manipulation learning from observations alone, without any prior knowledge or pre-training.
🛠️ Research Methods:
– The authors employ an observational learning framework to create an IRL algorithm that models the world based solely on observation and interaction, testing its effectiveness on image-based manipulation tasks.
💬 Research Conclusions:
– The study demonstrates the algorithm’s capability for efficient online transfer learning and superior sample efficiency compared to traditional methods, showcasing significantly higher success rates in real-world robotics tasks.
👉 Paper link: https://huggingface.co/papers/2602.24121

24. Cryo-Bench: Benchmarking Foundation Models for Cryosphere Applications
🔑 Keywords: Geo-Foundation Models, Cryospheric applications, Cryo-Bench, UNet, domain adaptation
💡 Category: Computer Vision
🌟 Research Objective:
– To evaluate the performance of Geo-Foundation Models (GFMs) in Cryospheric applications and compare their efficacy with existing models like UNet.
🛠️ Research Methods:
– Introduction of Cryo-Bench, a benchmark dataset compiled to assess GFM performance across various Cryospheric components including glaciers and sea ice.
– Evaluation of 14 GFMs alongside UNet and ViT baselines to determine their advantages, limitations, and optimal usage strategies.
💬 Research Conclusions:
– UNet achieved the highest average mIoU with a frozen encoder, but in few-shot settings, GFMs like DOFA and TerraMind outperform UNet.
– Fine-tuning with optimized hyperparameters significantly enhances GFM performance, showing notable domain adaptation capabilities despite minimal Cryospheric representation in pretraining data.
👉 Paper link: https://huggingface.co/papers/2603.01576

25. ProtegoFed: Backdoor-Free Federated Instruction Tuning with Interspersed Poisoned Data
🔑 Keywords: Federated Instruction Tuning, cross-silo setting, poisoned samples, frequency domain, collaborative defense
💡 Category: Machine Learning
🌟 Research Objective:
– The primary goal is to detect and remove poisoned data across multiple clients in a federated instruction tuning framework, known as ProtegoFed.
🛠️ Research Methods:
– Utilizes frequency domain gradient analysis and global secondary clustering mechanisms to distinguish and collaboratively identify poisoned samples.
💬 Research Conclusions:
– ProtegoFed effectively identifies 92.00% to 100.00% of poisoned samples, reduces the attack success rate to near zero, and maintains utility on the primary task.
👉 Paper link: https://huggingface.co/papers/2603.00516

26. SeeThrough3D: Occlusion Aware 3D Control in Text-to-Image Generation
🔑 Keywords: Occlusion Reasoning, 3D Layout-Conditioned Generation, Inter-Object Occlusions, Translucent 3D Boxes, Visual Tokens
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a 3D layout-conditioned generation model that explicitly addresses occlusion by using translucent 3D boxes and visual tokens.
🛠️ Research Methods:
– Introducing an occlusion-aware 3D scene representation (OSCR) that employs translucent 3D boxes and rendered visual tokens to model scenes.
– Utilizing masked self-attention to correlate objects with textual descriptions and constructing a synthetic dataset to train the model.
💬 Research Conclusions:
– SeeThrough3D demonstrates effective generalization to unseen object categories, enables precise 3D layout control, and models realistic occlusions with consistent camera control.
👉 Paper link: https://huggingface.co/papers/2602.23359

27. CC-VQA: Conflict- and Correlation-Aware Method for Mitigating Knowledge Conflict in Knowledge-Based Visual Question Answering
🔑 Keywords: CC-VQA, Knowledge-based visual question answering, Visual-semantic conflict analysis, Correlation-guided encoding-decoding, Vision language models
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper addresses conflicts in knowledge-based visual question answering (KB-VQA) by proposing a new method, CC-VQA, which does not require model retraining.
🛠️ Research Methods:
– The proposed CC-VQA incorporates a novel visual-semantic conflict analysis and employs correlation-guided encoding-decoding mechanisms.
💬 Research Conclusions:
– CC-VQA achieves state-of-the-art performance with improvements in accuracy ranging from 3.3% to 6.4% over existing methods, validated on benchmarks such as E-VQA, InfoSeek, and OK-VQA.
👉 Paper link: https://huggingface.co/papers/2602.23952

28. RAISE: Requirement-Adaptive Evolutionary Refinement for Training-Free Text-to-Image Alignment
🔑 Keywords: Requirement-Driven Adaptive Scaling, Text-to-Image Generation, Self-Improving Evolution, Multi-round Self-improvement
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces RAISE, a Requirement-Adaptive Self-Improving Evolution framework designed to enhance text-to-image generation by adaptively aligning computational efforts with the complexity of prompts without relying on training.
🛠️ Research Methods:
– The methodology involves dynamically evolving a population of image candidates at inference time through a range of refinement actions such as prompt rewriting, noise resampling, and instructional editing, which are verified via a structured checklist of requirements.
💬 Research Conclusions:
– RAISE demonstrates efficient and generalized model-agnostic improvement, achieving state-of-the-art alignment with reduced sample and VLM call requirements on evaluations like GenEval and DrawBench, indicating its effectiveness over prior methods.
👉 Paper link: https://huggingface.co/papers/2603.00483

29. LaSER: Internalizing Explicit Reasoning into Latent Space for Dense Retrieval
🔑 Keywords: LaSER, self-distillation, latent space, dual-view training, explicit reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study proposes LaSER, a self-distillation framework that enhances reasoning capabilities within dense retrievers’ latent space to enable efficient reasoning without relying on autoregressive generation.
🛠️ Research Methods:
– Introduces a dual-view training mechanism with explicit and latent views, enabling multi-grained alignment, including trajectory alignment, to bridge reasoning gaps in dense retrievers.
💬 Research Conclusions:
– LaSER significantly outperforms state-of-the-art baselines on reasoning-intensive benchmarks, demonstrating robustness across various backbones and model scales, effectively merging explicit reasoning depth with standard dense retrievers’ efficiency.
👉 Paper link: https://huggingface.co/papers/2603.01425

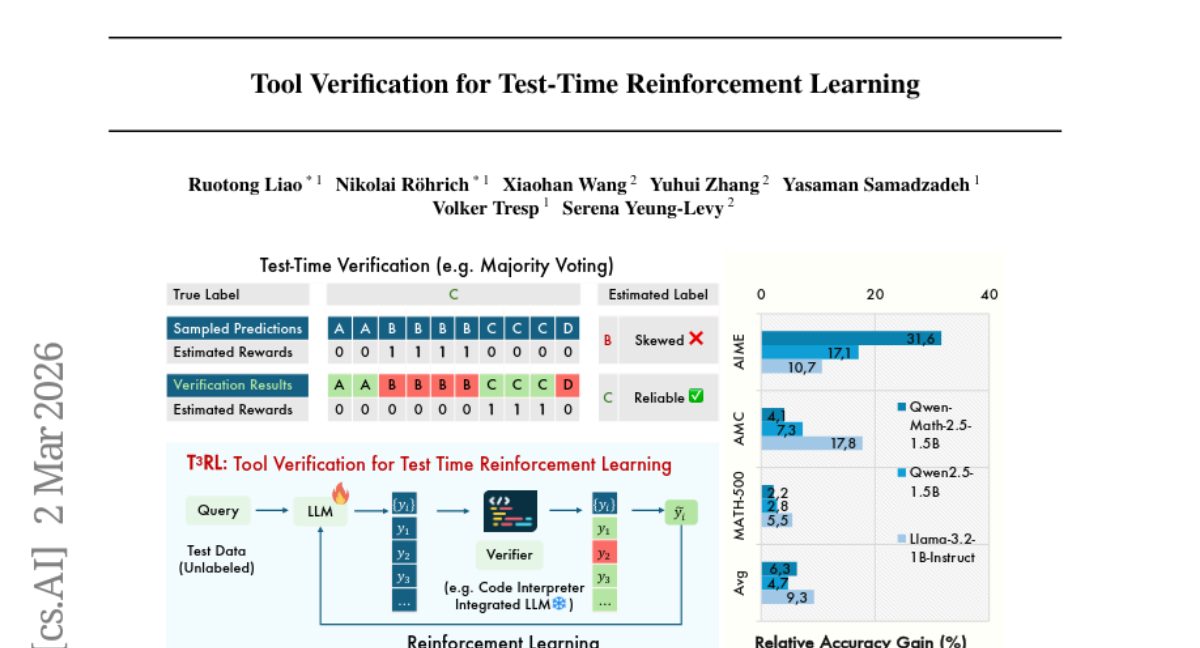
30. Tool Verification for Test-Time Reinforcement Learning
🔑 Keywords: Test-time reinforcement learning, Tool verification, Large reasoning models, Consensus bias, Pseudo-labels
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to address consensus bias in large reasoning models by using external validation to improve reward estimation and model stability through test-time reinforcement learning with tool verification.
🛠️ Research Methods:
– Utilizes Tool-Verification for Test-Time Reinforcement Learning (T^3RL) by employing an external tool for evidence, facilitating verification-aware voting to improve the reliability of pseudo-labels used for training.
💬 Research Conclusions:
– T^3RL outperforms traditional test-time reinforcement learning methods across various mathematics challenges and model types, particularly excelling on more complex problems and establishing test-time tool verification as a key component in maintaining model stability.
👉 Paper link: https://huggingface.co/papers/2603.02203
31. CMI-RewardBench: Evaluating Music Reward Models with Compositional Multimodal Instruction
🔑 Keywords: Compositional Multimodal Instruction, music reward modeling, unified benchmark, parameter-efficient
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Establish a comprehensive ecosystem for music reward modeling under Compositional Multimodal Instruction, bridging the gap between complex input handling and evaluation mechanisms.
🛠️ Research Methods:
– Introduction of large-scale datasets such as CMI-Pref-Pseudo, and high-quality annotated corpus CMI-Pref. Development of CMI-RewardBench as a unified benchmark for evaluation and CMI reward models designed for efficient parameter usage.
💬 Research Conclusions:
– CMI reward models correlate strongly with human judgments on musicality and alignment. These resources enable effective inference-time scaling and the proposed data, benchmarks, and reward models are publicly available.
👉 Paper link: https://huggingface.co/papers/2603.00610

32. Legal RAG Bench: an end-to-end benchmark for legal RAG
🔑 Keywords: Legal RAG, information retrieval, benchmark, embedding models, retrieval failures
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce and assess the Legal RAG Bench, a benchmark and evaluation methodology for legal retrieval-augmented generation systems.
🛠️ Research Methods:
– Utilizes a comprehensive dataset with 4,876 passages and 100 complex questions.
– Employs a factorial design and hierarchical error decomposition to evaluate three embedding models and two LLMs.
💬 Research Conclusions:
– Found information retrieval is the primary contributor to system performance, surpassing language model capabilities.
– Kanon 2 Embedder notably improved performance metrics, indicating retrieval’s ceiling-setting role in legal RAG systems.
👉 Paper link: https://huggingface.co/papers/2603.01710

33. Agentic Code Reasoning
🔑 Keywords: LLM agents, agentic code reasoning, semi-formal reasoning, patch verification, fault localization
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore the capabilities of LLM agents in performing code reasoning tasks without executing the code, using a method called agentic code reasoning.
🛠️ Research Methods:
– Introduction of semi-formal reasoning as a structured prompting methodology requiring explicit premises and formal conclusions.
– Evaluation of this methodology across three tasks: patch equivalence verification, fault localization, and code question answering.
💬 Research Conclusions:
– Semi-formal reasoning improves accuracy in patch equivalence verification, reaching up to 93% on real-world examples.
– It achieves 87% accuracy in code question answering and increases Top-5 accuracy in fault localization by 5 percentage points.
– The results highlight that structured agentic reasoning enables semantic code analysis without execution, facilitating applications in RL training, code review, and static program analysis.
👉 Paper link: https://huggingface.co/papers/2603.01896

34. Unified Vision-Language Modeling via Concept Space Alignment
🔑 Keywords: Vision-Language, Zero-Shot, Video Captioning, Post-Hoc Alignment, Multilingual
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective is to extend the text-only SONAR embedding space to support vision-language tasks, enabling zero-shot visual concept understanding.
🛠️ Research Methods:
– The study proposes a post-hoc alignment pipeline that maps vision encoder representations into the SONAR space and evaluates their performance on text-to-video retrieval and video captioning tasks.
💬 Research Conclusions:
– V-SONAR surpasses state-of-the-art models in multilingual video captioning and question answering, effectively handling tasks across 61 languages and extending performance in zero-shot visual concept understanding.
👉 Paper link: https://huggingface.co/papers/2603.01096

35. When Does RL Help Medical VLMs? Disentangling Vision, SFT, and RL Gains
🔑 Keywords: Reinforcement Learning, Vision-Language Models, Supervised Fine-Tuning, Visual Reasoning, Medical VQA
💡 Category: AI in Healthcare
🌟 Research Objective:
– To investigate whether reinforcement learning (RL) improves medical Vision-Language Model (VLM) performance, particularly in medical visual reasoning, beyond what is achieved with supervised fine-tuning (SFT).
🛠️ Research Methods:
– Conducted a controlled study assessing the effects of vision, SFT, and RL using MedMNIST as a multi-modality testbed.
– Benchmarked VLM vision towers against vision-only baselines and evaluated visual perception, reasoning support, and sampling efficiency using metrics like Accuracy@1 and Pass@K.
💬 Research Conclusions:
– Reinforcement Learning (RL) is most effective when models have substantial pre-existing support, mainly enhancing output distribution and sampling efficiency.
– Supervised Fine-Tuning (SFT) extends initial capabilities, making RL more effective, which results in improved performance across multiple medical VQA benchmarks.
👉 Paper link: https://huggingface.co/papers/2603.01301

36. Efficient RLVR Training via Weighted Mutual Information Data Selection
🔑 Keywords: InSight, Reinforcement Learning, Bayesian modeling, Epistemic Uncertainty, Weighted Mutual Information
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce InSight, a data sampling method that enhances reinforcement learning efficiency by addressing both difficulty and epistemic uncertainty through Bayesian modeling and weighted mutual information.
🛠️ Research Methods:
– Utilized Bayesian latent success rates to model data outcomes, deriving a stable acquisition score that considers both difficulty and evidence-based components for data sampling.
💬 Research Conclusions:
– InSight achieves state-of-the-art performance, improving training efficiency with notable gains across various benchmarks and accelerates processes with minimal computational overhead.
👉 Paper link: https://huggingface.co/papers/2603.01907

37. Spectral Condition for μP under Width-Depth Scaling
🔑 Keywords: Generative foundation models, stable feature learning, maximal update parameterization, spectral framework, width-depth scaling
💡 Category: Generative Models
🌟 Research Objective:
– Develop a spectral framework for maximal update parameterization to enhance stable feature learning and hyperparameter transfer in deep neural networks with joint width-depth scaling.
🛠️ Research Methods:
– Introduce a spectral μP condition for residual networks that unifies previous maximal update parameterization formulations and applies to a wide range of optimizers.
💬 Research Conclusions:
– The proposed spectral μP condition effectively preserves stable feature learning and enables robust hyperparameter transfer, as demonstrated on GPT-2 style language models.
👉 Paper link: https://huggingface.co/papers/2603.00541

38. PhotoBench: Beyond Visual Matching Towards Personalized Intent-Driven Photo Retrieval
🔑 Keywords: AI-generated summary, multi-source reasoning, personalized photo retrieval, unified embedding models, agentic reasoning systems
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce PhotoBench, the first benchmark for personal photo retrieval focusing on personalized multi-source intent-driven reasoning instead of visual matching.
🛠️ Research Methods:
– Developed a multi-source profiling framework that integrates visual semantics, spatial-temporal metadata, social identity, and temporal events to build complex intent-driven queries based on users’ life trajectories.
💬 Research Conclusions:
– Identified critical limitations in current systems: the modality gap in unified embedding models and poor tool orchestration in agentic systems, indicating a need for advanced agentic reasoning systems for precise constraint satisfaction and multi-source fusion.
👉 Paper link: https://huggingface.co/papers/2603.01493

39. VGGT-Det: Mining VGGT Internal Priors for Sensor-Geometry-Free Multi-View Indoor 3D Object Detection
🔑 Keywords: Sensor-Geometry-Free, multi-view indoor 3D object detection, Visual Geometry Grounded Transformer, Attention-Guided Query Generation, Query-Driven Feature Aggregation
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a Sensor-Geometry-Free multi-view indoor 3D object detection framework (VGGT-Det) that doesn’t rely on sensor geometry inputs.
🛠️ Research Methods:
– Integrate a Visual Geometry Grounded Transformer encoder into a transformer-based pipeline.
– Introduce novel components: Attention-Guided Query Generation and Query-Driven Feature Aggregation to leverage semantic and geometric priors effectively.
💬 Research Conclusions:
– VGGT-Det surpasses the best-performing method in the SG-Free setting by significant margins in terms of [email protected] on datasets like ScanNet and ARKitScenes.
👉 Paper link: https://huggingface.co/papers/2603.00912

40. MMR-Life: Piecing Together Real-life Scenes for Multimodal Multi-image Reasoning
🔑 Keywords: Multimodal Large Language Models, Reasoning Capabilities, Comprehensive Benchmark, Real-Life Scenarios
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces MMR-Life, a comprehensive benchmark designed to evaluate multimodal large language models’ reasoning capabilities across diverse real-life scenarios.
🛠️ Research Methods:
– MMR-Life consists of 2,646 multiple-choice questions created from 19,108 images, encompassing seven reasoning types such as abductive, deductive, and spatial reasoning, without relying on domain-specific expertise.
💬 Research Conclusions:
– Evaluation of 37 advanced models revealed substantial challenges, with top models like GPT-5 achieving only 58% accuracy. The variance in performance highlights the need for improved reasoning capabilities in future systems.
👉 Paper link: https://huggingface.co/papers/2603.02024

41. RubricBench: Aligning Model-Generated Rubrics with Human Standards
🔑 Keywords: RubricBench, Large Language Model Alignment, Rubric-Guided Evaluation, Reward Models, Surface-Level Biases
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces RubricBench as a benchmark dedicated to evaluating rubric-guided reward models for large language model alignment, aiming to address gaps in existing benchmarks which lack discriminative complexity and ground-truth annotations.
🛠️ Research Methods:
– RubricBench employs a multi-dimensional filtration pipeline to target complex samples featuring nuanced input complexity and misleading surface biases, with 1,147 pairwise comparisons and expert-annotated, atomic rubrics derived from specific instructions.
💬 Research Conclusions:
– Experiments show a significant gap in capability between human-annotated and model-generated rubrics, with state-of-the-art models struggling to autonomously specify valid evaluation criteria, underperforming compared to human-guided performance.
👉 Paper link: https://huggingface.co/papers/2603.01562

42. OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
🔑 Keywords: OmniLottie, vector animations, Lottie, tokenizer, multi-modal instructions
💡 Category: Generative Models
🌟 Research Objective:
– The OmniLottie framework aims to generate high-quality vector animations using multi-modal instructions with the help of specialized Lottie tokenizers and pretrained vision-language models.
🛠️ Research Methods:
– A well-designed Lottie tokenizer is introduced to convert JSON files into structured sequences, enabling the OmniLottie framework to utilize pretrained vision-language models for generating animations.
– MMLottie-2M, a large-scale dataset of vector animations with textual and visual annotations, was curated for further research.
💬 Research Conclusions:
– Extensive experiments demonstrate that OmniLottie produces vivid and semantically aligned vector animations in line with multi-modal instructions.
👉 Paper link: https://huggingface.co/papers/2603.02138