AI Native Daily Paper Digest – 20260304

1. Utonia: Toward One Encoder for All Point Clouds
🔑 Keywords: Utonia, Self-supervised Transformer, Representation Space, Multimodal Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces Utonia, aiming to create a unified self-supervised transformer encoder that learns consistent representation space across diverse domains such as remote sensing and indoor scenes.
🛠️ Research Methods:
– Implementation of a self-supervised point transformer encoder applied to various domain point clouds, including remote sensing, LiDAR, RGB-D sequences, CAD models, and RGB-only video.
💬 Research Conclusions:
– Utonia not only enhances perception capabilities but also supports embodied and multimodal reasoning, showing improvements in tasks like robotic manipulation and spatial reasoning.
👉 Paper link: https://huggingface.co/papers/2603.03283
2. Beyond Language Modeling: An Exploration of Multimodal Pretraining
🔑 Keywords: unified visual representations, multimodal pretraining, Mixture-of-Experts, Representation Autoencoder, world modeling emergence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To provide empirical clarity on the design space for multimodal models through controlled pretraining experiments, isolating factors that govern multimodal pretraining without interference from language pretraining.
🛠️ Research Methods:
– Utilized the Transfusion framework with next-token prediction for language and diffusion for vision to train on diverse data, including text, video, image-text pairs, and action-conditioned video.
💬 Research Conclusions:
– Representation Autoencoder (RAE) provides optimal unified visual representation.
– Visual and language data are complementary, enhancing downstream capabilities.
– Unified multimodal pretraining naturally contributes to world modeling.
– Mixture-of-Experts (MoE) architecture enables efficient multimodal scaling, harmonizing scaling asymmetry by providing high model capacity needed for language and accommodating vision’s data-intensive nature.
👉 Paper link: https://huggingface.co/papers/2603.03276

3. Beyond Length Scaling: Synergizing Breadth and Depth for Generative Reward Models
🔑 Keywords: Generative Reward Models, Chain-of-Thought, Breadth-CoT, Depth-CoT, Reinforcement Learning with Verifiable Rewards
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance Generative Reward Models by structuring Chain-of-Thought reasoning into Breadth and Depth components, and optimizing them using Supervised Fine-Tuning and Reinforcement Learning with Verifiable Rewards.
🛠️ Research Methods:
– The research introduces Mix-GRM, a framework that reorganizes raw rationales into structured Breadth-CoT and Depth-CoT through a modular synthesis pipeline, and employs Supervised Fine-Tuning and Reinforcement Learning with Verifiable Rewards to optimize these components.
💬 Research Conclusions:
– Mix-GRM achieves state-of-the-art results across five benchmarks, surpassing leading open-source models by 8.2% on average. Breadth-CoT is advantageous for subjective preference tasks, whereas Depth-CoT is more suitable for tasks requiring objective correctness. Misalignment of reasoning style with tasks degrades performance, and Reinforcement Learning with Verifiable Rewards helps models adaptively align reasoning styles to task demands. The models and data are available on Hugging Face, with code on GitHub.
👉 Paper link: https://huggingface.co/papers/2603.01571

4. How Controllable Are Large Language Models? A Unified Evaluation across Behavioral Granularities
🔑 Keywords: Large Language Models, controllability, hierarchical benchmark, language features, steering methods
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces SteerEval, a hierarchical benchmark for evaluating the controllability of Large Language Models (LLMs) across language features, sentiment, and personality domains.
🛠️ Research Methods:
– SteerEval organizes evaluation into three specification levels: L1 (what to express), L2 (how to express), and L3 (how to instantiate), providing a systematic approach to connect high-level behavioral intent to concrete textual output.
💬 Research Conclusions:
– The benchmark reveals that control over LLMs often diminishes at more detailed levels, offering a structured and interpretable framework for ensuring safe and controllable LLM behaviors and setting the stage for future research.
👉 Paper link: https://huggingface.co/papers/2603.02578

5. Qwen3-Coder-Next Technical Report
🔑 Keywords: Qwen3-Coder-Next, AI Native, agentic training, reinforcement learning, verifiable coding tasks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To push the capability limits of language models with a small parameter footprint through strong training recipes and specialized coding tasks.
🛠️ Research Methods:
– Implementation of agentic training via large-scale synthesis of verifiable coding tasks, using executable environments and reinforcement learning during mid-training.
💬 Research Conclusions:
– Qwen3-Coder-Next demonstrates competitive performance on agent-centric benchmarks given its number of active parameters, and it is released in both base and instruction-tuned versions for supporting research and the development of coding agents.
👉 Paper link: https://huggingface.co/papers/2603.00729

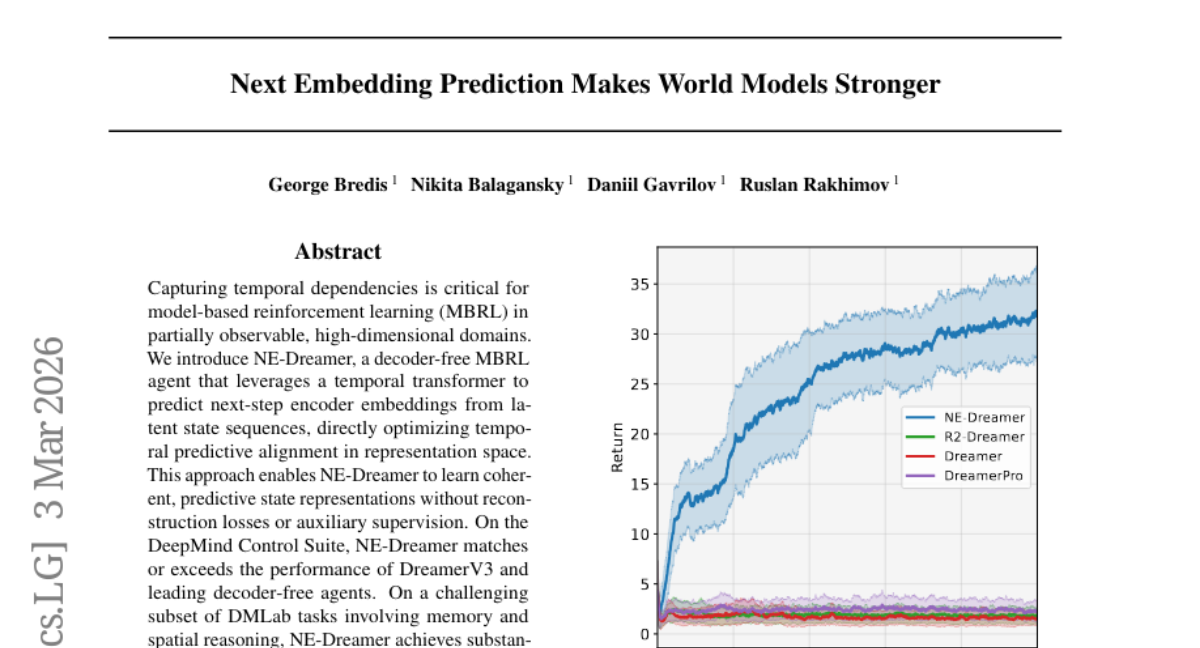
6. Next Embedding Prediction Makes World Models Stronger
🔑 Keywords: NE-Dreamer, Temporal Transformer, Model-Based Reinforcement Learning, Next-Step Encoder Embeddings, DeepMind Control Suite
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces NE-Dreamer, designed to improve model-based reinforcement learning by using a temporal transformer to predict next-step encoder embeddings without decoders or auxiliary supervision.
🛠️ Research Methods:
– Utilization of a temporal transformer to optimize temporal predictive alignment in the representation space for learning predictive state representations.
💬 Research Conclusions:
– NE-Dreamer matches or surpasses the performance of DreamerV3 and other agents in the DeepMind Control Suite and achieves significant improvements in challenging tasks involving memory and spatial reasoning in DMLab, proving to be an effective and scalable framework for complex environments.
👉 Paper link: https://huggingface.co/papers/2603.02765
7. Surgical Post-Training: Cutting Errors, Keeping Knowledge
🔑 Keywords: Surgical Post-Training, Large Language Models, reasoning capabilities, catastrophic forgetting, data rectification
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to enhance the reasoning capabilities of Large Language Models (LLMs) while preventing catastrophic forgetting and maintaining efficiency.
🛠️ Research Methods:
– The study introduces Surgical Post-Training (SPoT), which includes a data rectification pipeline and a reward-based binary cross-entropy objective, to improve reasoning efficiency and preserve learned prior knowledge.
💬 Research Conclusions:
– SPoT significantly enhances accuracy, improving Qwen3-8B’s performance by 6.2% on in-domain and out-of-domain tasks with minimal time and data requirements.
👉 Paper link: https://huggingface.co/papers/2603.01683

8. NOVA: Sparse Control, Dense Synthesis for Pair-Free Video Editing
🔑 Keywords: NOVA, Sparse Control, Dense Synthesis, video editing, temporal consistency
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a novel unpaired video editing framework, NOVA, that improves high-fidelity editing, motion preservation, and temporal coherence without the need for paired datasets.
🛠️ Research Methods:
– Utilizes sparse semantic guidance through user-edited keyframes and dense synthesis to maintain fidelity and coherence.
– Implements a degradation-simulation training strategy for enhanced motion reconstruction and temporal consistency.
💬 Research Conclusions:
– NOVA outperforms existing methods in edit fidelity, motion preservation, and temporal coherence, effectively overcoming limitations of requiring paired data.
👉 Paper link: https://huggingface.co/papers/2603.02802

9. BBQ-to-Image: Numeric Bounding Box and Qolor Control in Large-Scale Text-to-Image Models
🔑 Keywords: Text-to-image models, numeric bounding boxes, RGB triplets, structured-text framework, flow-based transformer
💡 Category: Generative Models
🌟 Research Objective:
– To introduce BBQ, a text-to-image model enabling precise numeric control over object attributes without altering model architecture.
🛠️ Research Methods:
– Training on captions enriched with parametric annotations to achieve precise spatial and chromatic control.
– Utilizing a flow-based transformer acting as a renderer to translate user intent into structured language.
💬 Research Conclusions:
– BBQ achieves strong box alignment and improved RGB color fidelity over state-of-the-art models.
– The model supports intuitive interfaces, replacing ambiguous prompts with precise controls, thus promoting a new paradigm in user interaction with AI models.
👉 Paper link: https://huggingface.co/papers/2602.20672
10. Learning When to Act or Refuse: Guarding Agentic Reasoning Models for Safe Multi-Step Tool Use
🔑 Keywords: Agentic language models, post-training framework, safety reasoning, preference-based reinforcement learning, tool use
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The main goal is to align language model agents for safe multi-step tool use by improving their safety reasoning and refusal mechanisms.
🛠️ Research Methods:
– The study introduces MOSAIC, a post-training framework implementing a plan, check, then act or refuse loop and trains the model using preference-based reinforcement learning with pairwise trajectory comparisons.
💬 Research Conclusions:
– MOSAIC significantly reduces harmful behavior, increases refusal rates of harmful tasks, minimizes privacy leakage, and maintains or improves benign task performance, demonstrating robust generalization across different models and settings.
👉 Paper link: https://huggingface.co/papers/2603.03205

11. Track4World: Feedforward World-centric Dense 3D Tracking of All Pixels
🔑 Keywords: 3D tracking, dense flow estimation, Track4World, scene flow, video analysis
💡 Category: Computer Vision
🌟 Research Objective:
– Propose a feedforward model, Track4World, for efficient 3D tracking of every pixel in a video using a global 3D scene representation and a novel 3D correlation scheme.
🛠️ Research Methods:
– Utilizes a VGGT-style ViT for encoding the global 3D scene representation.
– Applies a novel 3D correlation scheme to estimate pixel-wise 2D and 3D dense flow between arbitrary frame pairs.
💬 Research Conclusions:
– The model outperforms existing methods in 2D/3D flow estimation and 3D tracking.
– Demonstrates robustness and scalability for real-world 4D reconstruction tasks through extensive experiments on multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2603.02573
12. DREAM: Where Visual Understanding Meets Text-to-Image Generation
🔑 Keywords: Multimodal Learning, Visual Representation, Text-to-Image Generation, Masking Warmup, Semantically Aligned Decoding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce DREAM, a unified framework that combines visual representation learning and text-to-image generation to enhance both discriminative and generative tasks.
🛠️ Research Methods:
– Utilizes Masking Warmup during training to establish contrastive alignment, gradually transitioning to full masking for stable generative training.
– Employs Semantically Aligned Decoding at inference to align partially masked images with target text, improving fidelity without external rerankers.
💬 Research Conclusions:
– DREAM demonstrates that combining discriminative and generative objectives can lead to a single model that excels in both visual understanding and generation tasks, showing significant performance improvements in ImageNet accuracy and few-shot classification.
👉 Paper link: https://huggingface.co/papers/2603.02667

13. ParEVO: Synthesizing Code for Irregular Data: High-Performance Parallelism through Agentic Evolution
🔑 Keywords: ParEVO, irregular data structures, parallel algorithms, Large Language Models, Evolutionary Coding
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The main aim is to develop ParEVO, a framework to synthesize high-performance parallel algorithms, particularly for irregular data structures, overcoming existing computational challenges.
🛠️ Research Methods:
– ParEVO utilizes the Parlay-Instruct Corpus for curating tasks, employs specialized models like DeepSeek and Qwen, and integrates an Evolutionary Coding Agent for iterative code correction and enhancement.
💬 Research Conclusions:
– ParEVO significantly outperforms existing methods, achieving up to a 106x speedup and demonstrates superior performance on complex irregular graph problems, matching state-of-the-art human expertise with up to a 4.1x speedup on certain tasks.
👉 Paper link: https://huggingface.co/papers/2603.02510

14. Conditioned Activation Transport for T2I Safety Steering
🔑 Keywords: Text-to-Image, activation steering, SafeSteerDataset, Conditioned Activation Transport, image fidelity
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to reduce unsafe content generation while preserving image quality in Text-to-Image models.
🛠️ Research Methods:
– Developed SafeSteerDataset with 2300 safe and unsafe prompt pairs.
– Proposed Conditioned Activation Transport (CAT) framework using geometric conditioning and nonlinear transport maps.
💬 Research Conclusions:
– CAT effectively generalizes across state-of-the-art T2I architectures, lowering Attack Success Rate and maintaining image fidelity compared to unsteered generations.
👉 Paper link: https://huggingface.co/papers/2603.03163

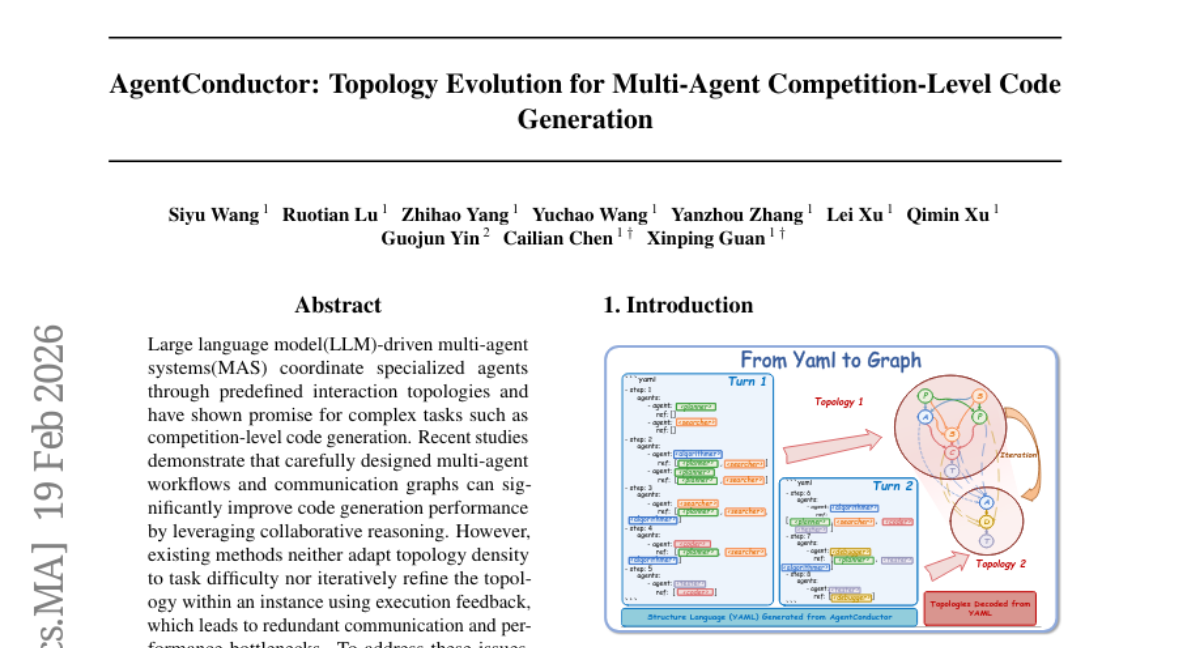
15. AgentConductor: Topology Evolution for Multi-Agent Competition-Level Code Generation
🔑 Keywords: Multi-Agent Systems, Reinforcement Learning, Interaction Topologies, LLM-Based Orchestrator, Code Generation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance code generation accuracy by employing an LLM-driven multi-agent system that dynamically generates interaction topologies optimized through reinforcement learning.
🛠️ Research Methods:
– Utilization of a novel topological density function and difficulty interval partitioning to adaptively structure agents in a layered directed acyclic graph, allowing for communication-efficient task execution and refined topological control.
💬 Research Conclusions:
– AgentConductor achieved state-of-the-art performance, with improvements up to 14.6% in pass@1 accuracy, 13% in reducing topology density, and 68% in token cost reduction compared to the strongest existing baselines.
👉 Paper link: https://huggingface.co/papers/2602.17100
16. APRES: An Agentic Paper Revision and Evaluation System
🔑 Keywords: Large Language Models, citation prediction, APRES
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce APRES, a novel method that uses Large Language Models to revise scientific papers based on a citation-predictive rubric, improving citation predictions while preserving core content.
🛠️ Research Methods:
– The method involves creating a rubric predictive of future citation counts and integrating it with APRES for automated paper revision, enhancing paper quality and impact.
💬 Research Conclusions:
– APRES improves future citation prediction by 19.6% in mean average error over the next best baseline and is preferred by human experts 79% of the time, demonstrating that LLMs can effectively aid in manuscript revision without replacing human expert reviewers.
👉 Paper link: https://huggingface.co/papers/2603.03142

17. Token Reduction via Local and Global Contexts Optimization for Efficient Video Large Language Models
🔑 Keywords: Video Large Language Models, spatiotemporal compression, token Anchors, local-global Optimal Transport, computational efficiency
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to address inefficiencies in Video Large Language Models (VLLMs) by reducing video token redundancy while preserving informative contexts.
🛠️ Research Methods:
– The research introduces an AOT framework using local-global Optimal Transport to establish local- and global-aware token anchors for spatiotemporal compression without training.
💬 Research Conclusions:
– AOT framework demonstrates competitive performances across various video benchmarks, achieving significant computational efficiency while maintaining temporal and visual fidelity.
👉 Paper link: https://huggingface.co/papers/2603.01400

18. Whisper-RIR-Mega: A Paired Clean-Reverberant Speech Benchmark for ASR Robustness to Room Acoustics
🔑 Keywords: Whisper-RIR-Mega, Automatic Speech Recognition, LibriSpeech, Room Impulse Response, Reverberation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Evaluate the robustness of Automatic Speech Recognition (ASR) models to room acoustics using the Whisper-RIR-Mega dataset.
🛠️ Research Methods:
– Utilized paired clean and reverberant speech samples with stratified splits based on RT60 and DRR metrics; evaluated five Whisper models across various conditions.
💬 Research Conclusions:
– Reverberation consistently affects ASR model performance, with a reverb penalty in word error rate ranging from 0.12 to 1.07 percentage points depending on the model size.
👉 Paper link: https://huggingface.co/papers/2603.02252

19. Multi-Domain Riemannian Graph Gluing for Building Graph Foundation Models
🔑 Keywords: Multi-domain graph pre-training, Riemannian geometry, neural manifold gluing, EMA prototyping, geometric scaling law
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to enhance the understanding of knowledge integration and transfer across different domains through a novel Riemannian geometry approach in multi-domain graph pre-training.
🛠️ Research Methods:
– Introduction of the neural manifold gluing theory, which utilizes an adaptive orthogonal frame to unify graph datasets into a smooth Riemannian manifold.
– Development of the GraphGlue framework, featuring batched pre-training with EMA prototyping and a transferability measure based on geometric consistency.
💬 Research Conclusions:
– Extensive experiments demonstrate the superior performance of the GraphGlue framework across diverse graph domains.
– The study empirically validates a geometric scaling law, showing that larger datasets improve model transferability by creating a smoother manifold.
👉 Paper link: https://huggingface.co/papers/2603.00618

20. Fast Matrix Multiplication in Small Formats: Discovering New Schemes with an Open-Source Flip Graph Framework
🔑 Keywords: Fast Matrix Multiplication, OpenMP Parallelism, Coefficient Rings, Multiplicative Complexity, Strassen’s Exponent
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Present an open-source C++ framework for discovering fast matrix multiplication schemes using the flip graph approach.
🛠️ Research Methods:
– Utilize multiple coefficient rings and implement fixed-dimension and meta-dimensional search operators. Employ efficient bit-level encoding and OpenMP parallelism for large-scale exploration on commodity hardware.
💬 Research Conclusions:
– Improved multiplicative complexity for 79 matrix multiplication schemes, discovered a new 4x4x10 scheme with only 115 multiplications, and found 93 rediscovered schemes in ternary coefficients.
👉 Paper link: https://huggingface.co/papers/2603.02398

21. Towards Simulating Social Media Users with LLMs: Evaluating the Operational Validity of Conditioned Comment Prediction
🔑 Keywords: Conditioned Comment Prediction, Large Language Models, Supervised Fine-Tuning, semantic accuracy, behavioral histories
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study introduces Conditioned Comment Prediction (CCP) to evaluate Large Language Models’ (LLMs) ability to simulate social media user behavior through comparing model-generated comments to genuine digital traces.
🛠️ Research Methods:
– The researchers evaluated open-weight 8B models (Llama3.1, Qwen3, Ministral) across languages like English, German, and Luxembourgish, systematically comparing explicit vs. implicit prompting strategies and the effects of Supervised Fine-Tuning (SFT).
💬 Research Conclusions:
– The study highlights that while SFT optimizes text length and syntax, it compromises semantic grounding. Explicit conditioning becomes redundant as models accurately infer behavioral patterns from behavioral histories, challenging current naive prompting paradigms and advising the use of authentic behavioral traces for accurate simulations.
👉 Paper link: https://huggingface.co/papers/2602.22752

22.

23. Transform-Invariant Generative Ray Path Sampling for Efficient Radio Propagation Modeling
🔑 Keywords: Generative Flow Networks, Ray tracing, Radio propagation modeling, Experience replay, Physics-based action masking
💡 Category: Generative Models
🌟 Research Objective:
– Develop a machine-learning framework using Generative Flow Networks to enhance radio propagation path sampling by addressing computational challenges.
🛠️ Research Methods:
– Implement an experience replay buffer to capture rare valid paths.
– Employ a uniform exploratory policy to prevent model overfitting.
– Utilize physics-based action masking to filter out impossible paths preemptively.
💬 Research Conclusions:
– Achieved significant speedups in path sampling, up to 10 times faster on GPU and 1000 times faster on CPU, while maintaining high accuracy and successfully uncovering complex propagation paths.
👉 Paper link: https://huggingface.co/papers/2603.01655

24. Easy to Learn, Yet Hard to Forget: Towards Robust Unlearning Under Bias
🔑 Keywords: Machine Unlearning, Spurious Correlations, Shortcut Unlearning, Bias Pathways, Loss Landscape Sharpness
💡 Category: Machine Learning
🌟 Research Objective:
– Investigate the challenges of unlearning from biased models due to spurious correlations and propose a framework to handle shortcut unlearning.
🛠️ Research Methods:
– Introduce CUPID, a framework that partitions data based on loss landscape sharpness and disentangles causal and bias pathways in model parameters for targeted updates.
💬 Research Conclusions:
– CUPID achieves state-of-the-art results in mitigating shortcut unlearning across various biased datasets by improving the efficacy and reliability of machine unlearning processes.
👉 Paper link: https://huggingface.co/papers/2602.21773

25. SGDC: Structurally-Guided Dynamic Convolution for Medical Image Segmentation
🔑 Keywords: Structure-Guided Dynamic Convolution, AI Native, dynamic kernels, high-frequency spatial details, medical image segmentation
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to improve medical image segmentation by introducing a Structure-Guided Dynamic Convolution (SGDC) mechanism to preserve fine-grained clinical structures.
🛠️ Research Methods:
– The research employs a novel SGDC mechanism that uses an explicitly supervised structure-extraction branch to guide dynamic kernel generation and gating signals for feature modulation, countering the loss of information typical with average pooling.
💬 Research Conclusions:
– SGDC achieved state-of-the-art performance on several medical image datasets, reducing Hausdorff Distance by 2.05 and consistently improving IoU scores. It shows potential for application in other structure-sensitive vision tasks like small-object detection.
👉 Paper link: https://huggingface.co/papers/2602.23496

26. GroupGPT: A Token-efficient and Privacy-preserving Agentic Framework for Multi-User Chat Assistant
🔑 Keywords: GroupGPT, privacy-preserving, multi-user chat, small-large model, intervention timing
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective of the study is to develop GroupGPT, a framework designed to enhance intervention timing and response accuracy in complex multi-user group chats while ensuring token-efficiency and privacy.
🛠️ Research Methods:
– GroupGPT utilizes a small-large model collaboration to separate intervention timing from response generation. It supports multimodal inputs, including memes, images, videos, and voice messages. Additionally, the research introduces MUIR, a benchmark dataset for evaluating intervention reasoning in multi-user chats.
💬 Research Conclusions:
– The study concludes that GroupGPT significantly improves response accuracy and timing in group chats, achieving an average score of 4.72/5.0 in evaluations. It also reduces token usage by up to three times compared to baseline methods, offering privacy sanitization of user messages before cloud transmission.
👉 Paper link: https://huggingface.co/papers/2603.01059

27. DynaMoE: Dynamic Token-Level Expert Activation with Layer-Wise Adaptive Capacity for Mixture-of-Experts Neural Networks
🔑 Keywords: DynaMoE, Mixture-of-Experts, adaptive capacity allocation, dynamic routing, computational efficiency
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to enhance Mixture-of-Experts (MoE) frameworks with DynaMoE, which adapts expert activation and capacity allocation according to input complexity and task requirements to improve parameter efficiency and training stability.
🛠️ Research Methods:
– Introduces dynamic token-level expert activation and layer-wise adaptive capacity allocation, using a novel routing mechanism.
– Utilizes six distinct scheduling strategies, including descending, ascending, pyramid, and wave patterns, to allocate expert capacity across network depths.
💬 Research Conclusions:
– DynaMoE achieves superior parameter efficiency compared to static baselines across experiments on datasets such as MNIST and CIFAR-10.
– Finds optimal expert schedules to be task- and scale-dependent, with descending schedules excelling in image classification and scale-variant schedules for language modeling.
– Demonstrates that dynamic routing reduces gradient variance, improving convergence stability.
👉 Paper link: https://huggingface.co/papers/2603.01697

28. HateMirage: An Explainable Multi-Dimensional Dataset for Decoding Faux Hate and Subtle Online Abuse
🔑 Keywords: HateMirage, hate speech, misinformation, explainability, responsible AI
💡 Category: Natural Language Processing
🌟 Research Objective:
– HateMirage aims to provide a benchmark for interpretable hate detection by focusing on hate speech within the context of misinformation using a novel dataset with multi-dimensional annotations.
🛠️ Research Methods:
– The dataset was created by tracing YouTube discussions related to widely debunked misinformation claims and annotating 4,530 comments across dimensions like Target, Intent, and Implication.
– Multiple open-source language models were benchmarked on HateMirage using metrics such as ROUGE-L F1 and Sentence-BERT similarity.
💬 Research Conclusions:
– Results indicate that explanation quality may be more influenced by pretraining diversity and reasoning-oriented data than by model scale alone.
– HateMirage sets a new standard for the fusion of misinformation reasoning with harm attribution in responsible AI research.
👉 Paper link: https://huggingface.co/papers/2603.02684

29. Code2Math: Can Your Code Agent Effectively Evolve Math Problems Through Exploration?
🔑 Keywords: Code agents, Large Language Models, Mathematical capabilities, Problem evolution, Computational environments
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To explore the potential of code agents in autonomously evolving existing math problems into more complex and challenging variations.
🛠️ Research Methods:
– Introduction of a multi-agent framework designed to evolve math problems while ensuring their solvability and increased difficulty, with empirical experiments to validate the framework’s effectiveness.
💬 Research Conclusions:
– Code agents can synthesize new, solvable, and more structurally challenging math problems compared to the original ones, demonstrating a viable mechanism for creating high-difficulty mathematical reasoning problems within scalable computational environments.
👉 Paper link: https://huggingface.co/papers/2603.03202

30. QEDBENCH: Quantifying the Alignment Gap in Automated Evaluation of University-Level Mathematical Proofs
🔑 Keywords: Large Language Models, Alignment Gap, QEDBench, human evaluation, state-of-the-art performance
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To evaluate the reliability of LLM-based evaluation protocols in mathematical proof assessment through the introduction of QEDBench.
– To assess the systematic Alignment Gap in AI evaluations of university-level math proofs against human expertise.
🛠️ Research Methods:
– Introduction of the QEDBench benchmark using a dual-rubric alignment approach.
– Deployment of a dual-evaluation matrix involving 7 judges and 5 solvers over 1,000+ hours of human evaluation to identify biases and performance issues.
💬 Research Conclusions:
– Certain evaluation models, including Claude Opus 4.5 and Llama 4 Maverick, show notable score inflation, while models like GPT-5 Pro struggle in discrete mathematics.
– Gemini 3.0 Pro reaches state-of-the-art performance; however, other models face a significant performance drop in discrete domains.
– QEDBench is made publicly available to aid in the evaluation and enhancement of AI judges.
👉 Paper link: https://huggingface.co/papers/2602.20629

31. Transformers converge to invariant algorithmic cores
🔑 Keywords: AI-generated summary, transformers, algorithmic cores, low-dimensional invariants, mechanistic interpretability
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study aims to understand how independently trained transformers converge to shared algorithmic cores despite having different weight configurations, revealing low-dimensional invariants in transformer computations.
🛠️ Research Methods:
– The research analyzes the internal structures of large language models, examining the convergence of algorithmic cores and the embedding of 3D cores in Markov-chain transformers, as well as cyclic operators in modular-addition transformers.
💬 Research Conclusions:
– The findings demonstrate that transformer computations are organized around compact, shared algorithmic structures, which persist across training runs and scales. This suggests targeting these invariants in mechanistic interpretability rather than focusing on implementation-specific details.
👉 Paper link: https://huggingface.co/papers/2602.22600

32. SciDER: Scientific Data-centric End-to-end Researcher
🔑 Keywords: SciDER, Automated scientific discovery, Large language models, Research lifecycle, Data-driven discovery
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To automate the research lifecycle from ideation to experimentation using SciDER for data-driven scientific discovery.
🛠️ Research Methods:
– Implement a data-centric end-to-end system with collaborative agents that parse raw scientific data, generate hypotheses, and design experiments.
💬 Research Conclusions:
– SciDER outperforms general-purpose agents and state-of-the-art models in specialized data-driven scientific discovery, utilizing self-evolving memory and critic-led feedback loop.
👉 Paper link: https://huggingface.co/papers/2603.01421

33. Chain of World: World Model Thinking in Latent Motion
🔑 Keywords: CoWVLA, Visuomotor Learning, World-model temporal reasoning, Disentangled latent motion representation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce CoWVLA, a new paradigm combining world-models with disentangled latent motion to enhance visuomotor learning efficiency in robotic systems.
🛠️ Research Methods:
– Utilize a pretrained video VAE as a latent motion extractor that separates video segments into structure and motion latents.
– Leverage co-fine-tuning to align the latent dynamic with discrete action prediction via an autoregressive decoder.
💬 Research Conclusions:
– CoWVLA outperforms existing approaches in world-model and latent-action methodologies, achieving moderate computational efficiency in robotic simulation benchmarks.
👉 Paper link: https://huggingface.co/papers/2603.03195

34. CFG-Ctrl: Control-Based Classifier-Free Diffusion Guidance
🔑 Keywords: Classifier-Free Guidance, Sliding Mode Control, Semantic Alignment, Flow-Based Diffusion Models, Lyapunov Stability
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to reinterpret Classifier-Free Guidance as a control system within flow-based diffusion models, improving semantic alignment and stability through a novel sliding mode control approach.
🛠️ Research Methods:
– Introduction of a unified framework called CFG-Ctrl, employing Sliding Mode Control to enhance the generative flow.
– Definition of an exponential sliding mode surface over the semantic prediction error, along with a switching control term for nonlinear feedback correction.
– Theoretical support provided by Lyapunov stability analysis for finite-time convergence.
💬 Research Conclusions:
– Experiments indicate that SMC-CFG enhances semantic alignment and robustness across different guidance scales, surpassing standard CFG, as demonstrated in text-to-image generation models like Stable Diffusion 3.5, Flux, and Qwen-Image.
👉 Paper link: https://huggingface.co/papers/2603.03281

35. Spilled Energy in Large Language Models
🔑 Keywords: Energy-Based Model, hallucination detection, spilled energy, Large Language Model, sequence-to-sequence probability chain
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to reinterpret Large Language Model softmax classifiers as Energy-Based Models for hallucination detection without additional training.
🛠️ Research Methods:
– The researchers introduce two training-free metrics, spilled energy and marginalized energy, to detect energy discrepancies and assess hallucinations across multiple benchmarks and state-of-the-art models.
💬 Research Conclusions:
– The proposed approach effectively detects hallucinations and generalizes across tasks without training overhead, demonstrated on nine benchmarks utilizing various state-of-the-art LLMs.
👉 Paper link: https://huggingface.co/papers/2602.18671

36. InfoPO: Information-Driven Policy Optimization for User-Centric Agents
🔑 Keywords: Information-Driven Policy Optimization, information-gain reward, adaptive variance-gated fusion, credit assignment, AI Native
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces InfoPO, an AI Native approach to optimize multi-turn agent-user interactions by leveraging information-gain rewards to improve decision-making processes.
🛠️ Research Methods:
– InfoPO employs active uncertainty reduction by calculating information-gain rewards that assess the impact of interaction turns. It integrates these with task performance using adaptive variance-gated fusion to prioritize information importance while maintaining task orientation.
💬 Research Conclusions:
– InfoPO consistently surpasses existing prompting and multi-turn RL baselines across various tasks, demonstrating robustness to user simulator shifts and effective generalization to environment-interactive tasks.
👉 Paper link: https://huggingface.co/papers/2603.00656

37. Humans and LLMs Diverge on Probabilistic Inferences
🔑 Keywords: ProbCOPA, probabilistic reasoning, reasoning LLMs, human-like distributions, reasoning chains
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to explore the capabilities of reasoning LLMs in replicating human probabilistic reasoning patterns, specifically in open-ended inferences which are not strictly deterministic.
🛠️ Research Methods:
– Introduction of the ProbCOPA dataset containing 210 handcrafted probabilistic inferences annotated for inference likelihood by human participants, followed by a comparison of these human judgments with outputs from eight state-of-the-art reasoning LLMs.
💬 Research Conclusions:
– Findings indicate that LLMs consistently fail to match human-like probabilistic inference distributions, revealing a gap between machine and human reasoning in non-deterministic scenarios. The study highlights the necessity for evaluating reasoning models beyond deterministic tasks.
👉 Paper link: https://huggingface.co/papers/2602.23546

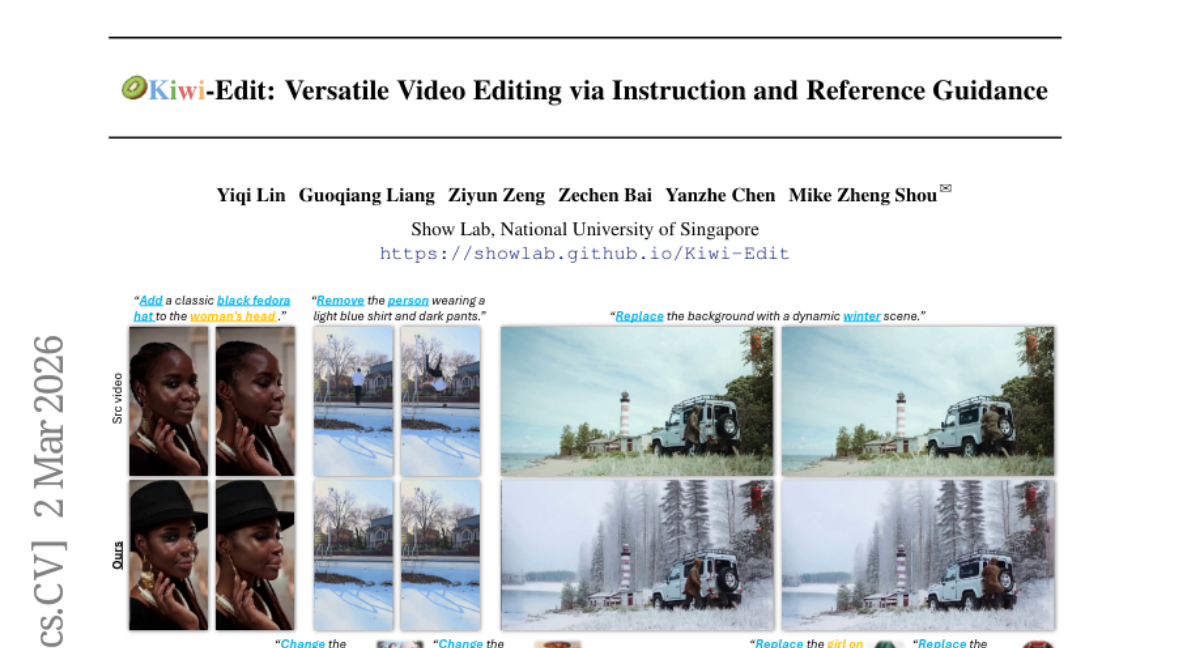
38. Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
🔑 Keywords: high-fidelity video editing, instruction-following, reference fidelity, scalable data generation, synthetic reference scaffolds
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a scalable data generation pipeline to create high-fidelity training data for improving instruction-following and reference fidelity in video editing.
🛠️ Research Methods:
– Transformation of existing video editing pairs into high-fidelity quadruplets using image generative models to produce synthesized reference scaffolds.
– Construction of the RefVIE dataset tailored for instruction-reference tasks and establishment of the RefVIE-Bench for evaluation.
– Introduction of a unified editing architecture, Kiwi-Edit, capitalizing on learnable queries and latent visual features for refined semantic guidance via progressive multi-stage training.
💬 Research Conclusions:
– The innovative data generation pipeline and architecture, Kiwi-Edit, set a new standard in controllable video editing, offering significant improvements in instruction-following and reference fidelity.
👉 Paper link: https://huggingface.co/papers/2603.02175
39. PRISM: Pushing the Frontier of Deep Think via Process Reward Model-Guided Inference
🔑 Keywords: AI-generated summary, Process Reward Model, DEEPTHINK, step-level verification, candidate solutions
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce PRISM, a Process Reward Model-guided inference algorithm that enhances DEEPTHINK systems by improving population refinement and solution aggregation through step-level verification.
🛠️ Research Methods:
– Utilizes functional decomposition and treats candidate solutions as particles in an energy landscape, employing score-guided resampling and stochastic refinement to focus on high-quality reasoning while maintaining diversity.
💬 Research Conclusions:
– PRISM demonstrates strong competitive performance on mathematical and scientific benchmarks, reaching high accuracy and consistency, while remaining efficient with limited initial correct candidates and often aligning with the compute-accuracy Pareto frontier.
👉 Paper link: https://huggingface.co/papers/2603.02479

40. Kling-MotionControl Technical Report
🔑 Keywords: DiT-based framework, heterogeneous motion representations, adaptive identity-agnostic learning, motion retargeting, semantic motion understanding
💡 Category: Generative Models
🌟 Research Objective:
– The primary aim is to develop Kling-MotionControl, a DiT-based framework for character animation that achieves high-fidelity, expressive, and controllable video generation.
🛠️ Research Methods:
– Utilizes a divide-and-conquer strategy for integrating heterogeneous motion representations, adaptive identity-agnostic learning, meticulous identity injection and fusion designs, and an advanced acceleration framework using multi-stage distillation.
💬 Research Conclusions:
– Kling-MotionControl excels in semantic motion understanding and precise text responsiveness, offering superior fidelity, flexibility in motion control, robust cross-identity generalization, and coherence in animation, outperforming existing solutions.
👉 Paper link: https://huggingface.co/papers/2603.03160

41. BeyondSWE: Can Current Code Agent Survive Beyond Single-Repo Bug Fixing?
🔑 Keywords: BeyondSWE, SearchSWE, code agents, external knowledge, developer-like workflows
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to address the limitations of current code agent benchmarks that fail to capture real-world complexity by introducing BeyondSWE for broader reasoning and knowledge scopes and SearchSWE for studying external knowledge integration in coding tasks.
🛠️ Research Methods:
– Introduce BeyondSWE, a comprehensive benchmark across two axes—resolution scope and knowledge scope—using 500 real-world instances across four distinct settings to identify a capability gap.
– Develop SearchSWE, a framework that integrates deep search with coding abilities to examine the impact of search augmentation on performance.
💬 Research Conclusions:
– Experimental results reveal a significant capability gap in frontier models, with performance plateauing below 45% success rate.
– Search augmentation shows inconsistent gains and may degrade performance, highlighting the challenges of simulating developer-like workflows that intertwine search and reasoning during coding tasks.
👉 Paper link: https://huggingface.co/papers/2603.03194

42. UniG2U-Bench: Do Unified Models Advance Multimodal Understanding?
🔑 Keywords: Unified Multimodal Models, Generation-to-Understanding, Vision-Language Models, Spatial Intelligence, Inductive Biases
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research introduces UniG2U-Bench, aiming to evaluate when generative capabilities in unified multimodal models enhance understanding, categorized into 7 regimes and 30 subtasks.
🛠️ Research Methods:
– Extensive evaluation of over 30 models using the comprehensive UniG2U-Bench benchmark, exploring tasks requiring various levels of visual transformation.
💬 Research Conclusions:
– Unified multimodal models often underperform compared to Vision-Language Models, particularly in the Generate-then-Answer inference paradigm.
– Consistent enhancements observed in tasks involving spatial intelligence and multi-round reasoning.
– Tasks and models with similar reasoning structures demonstrate class-consistent inductive biases, necessitating diverse training data and novel paradigms to unlock the potential of these models.
👉 Paper link: https://huggingface.co/papers/2603.03241
