AI Native Daily Paper Digest – 20260305

1. Helios: Real Real-Time Long Video Generation Model
🔑 Keywords: Helios, Video Generation, Autoregressive Diffusion Model, Long-Video Drifting, Real-time Performance
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Helios, a 14 billion parameter autoregressive diffusion model for high-quality, real-time video generation, capable of handling minute-scale content.
🛠️ Research Methods:
– Develop Helios with a unified input representation to support T2V, I2V, and V2V tasks, employing efficient training strategies to address long-video drifting and improve computational efficiency.
💬 Research Conclusions:
– Helios outperforms previous models in both short and long-video generation tasks, with reduced memory consumption, enhancing both inference and training speeds.
👉 Paper link: https://huggingface.co/papers/2603.04379
2. MemSifter: Offloading LLM Memory Retrieval via Outcome-Driven Proxy Reasoning
🔑 Keywords: MemSifter, Large Language Models, Reinforcement Learning, long-term memory, proxy model
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop MemSifter, a framework aimed at improving long-term memory efficiency and accuracy in Large Language Models by offloading memory retrieval to a small proxy model.
🛠️ Research Methods:
– Employed a memory-specific Reinforcement Learning training paradigm utilizing task-outcome-oriented rewards.
– Integrated training techniques such as Curriculum Learning and Model Merging.
💬 Research Conclusions:
– MemSifter effectively enhances retrieval accuracy and task completion, outperforming existing state-of-the-art methods.
– The framework provides an efficient, scalable solution for long-term memory in LLMs, with open-sourced resources supporting further research.
👉 Paper link: https://huggingface.co/papers/2603.03379

3. Heterogeneous Agent Collaborative Reinforcement Learning
🔑 Keywords: HACRL, Heterogeneous Agents, Rollout Sharing, Sample Utilization, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Heterogeneous Agent Collaborative Reinforcement Learning (HACRL) to address inefficiencies in isolated on-policy optimization and facilitate collaborative learning among heterogeneous agents.
🛠️ Research Methods:
– Implementation of a new collaborative RL algorithm, HACPO, focusing on efficient sample utilization and cross-agent knowledge transfer with mechanisms for unbiased advantage estimation and policy distribution shift mitigation.
💬 Research Conclusions:
– HACPO consistently improves the performance of all participating agents, demonstrating a 3.3% performance increase over traditional methods like GSPO while reducing rollout costs by half.
👉 Paper link: https://huggingface.co/papers/2603.02604

4. Phi-4-reasoning-vision-15B Technical Report
🔑 Keywords: Multimodal Reasoning, Open-Weight Model, Architectural Design, Data Curation, Chain-of-Thought Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to provide practical insights into building smaller and efficient multimodal reasoning models with open-weight capabilities that excel in vision, language, and mathematical reasoning tasks.
🛠️ Research Methods:
– The study utilizes a hybrid approach combining direct answering with chain-of-thought reasoning. It emphasizes careful architectural choices and high-quality data curation, leveraging systematic filtering, error correction, and synthetic augmentation.
💬 Research Conclusions:
– The findings demonstrate that small open-weight multimodal models can achieve competitive performance with reduced computational resources. High-resolution and dynamic-resolution encoders improve perception, which is critical for reasoning. The use of explicit mode tokens allows the model to handle both simple and complex tasks effectively.
👉 Paper link: https://huggingface.co/papers/2603.03975

5. Memex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory
🔑 Keywords: Memex, Long-Horizon Tasks, Reinforcement Learning, Context Budget, Indexed Memory
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study introduces a memory mechanism called Memex, aimed at enabling large language model agents to better handle long-horizon tasks by maintaining a compact context without discarding essential evidence.
🛠️ Research Methods:
– The research employs a reinforcement learning framework named MemexRL, which optimizes memory usage through reward shaping. This framework determines how to summarize, index, and retrieve information efficiently within context constraints.
💬 Research Conclusions:
– The results demonstrate that Memex improves task success on challenging long-horizon tasks, achieves a significantly reduced working context, and maintains effective decision quality by using a less lossy form of memory compared to traditional summary-only approaches.
👉 Paper link: https://huggingface.co/papers/2603.04257

6. V_1: Unifying Generation and Self-Verification for Parallel Reasoners
🔑 Keywords: Test-time scaling, complex reasoning tasks, pairwise self-verification, code generation, mathematical reasoning
💡 Category: Generative Models
🌟 Research Objective:
– Enhance test-time scaling methods for complex reasoning tasks through a unified generation and verification framework leveraging pairwise self-verification.
🛠️ Research Methods:
– Introduce V_1, a framework with two components: V_1-Infer, an uncertainty-guided algorithm using tournament-based ranking for dynamic self-verification; and V_1-PairRL, an RL framework jointly training a generator and self-verifier.
💬 Research Conclusions:
– V_1-Infer improves Pass@1 in benchmarks by up to 10% over pointwise verification, being more efficient than recent methods. V_1-PairRL achieves 7–9% gains over standard methods and improves base Pass@1 by up to 8.7% in code generation.
👉 Paper link: https://huggingface.co/papers/2603.04304
7. InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
🔑 Keywords: video synthesis, background consistency, shot-to-shot transitions, multi-subject, seamless transitions
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to tackle challenges in video synthesis for long-form storytelling by ensuring visual narratives remain consistent, focusing on background consistency, seamless multi-subject transitions, and scalability to extended narratives.
🛠️ Research Methods:
– Introduced a novel video synthesis framework and a specific dataset to ensure background consistency and manage complex shot-to-shot transitions involving multiple subjects.
💬 Research Conclusions:
– The proposed approach, InfinityStory, demonstrated improved stability, smoother transitions, and better temporal coherence, achieving high scores in background and subject consistency on the VBench benchmark.
👉 Paper link: https://huggingface.co/papers/2603.03646

8. MUSE: A Run-Centric Platform for Multimodal Unified Safety Evaluation of Large Language Models
🔑 Keywords: Multimodal Safety, Large Language Models, AI Native, Cross-Modal Testing, Attack Success Rate
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to address the gap in safety evaluation for large language models across different modalities beyond text, introducing MUSE for a comprehensive multimodal safety assessment.
🛠️ Research Methods:
– MUSE integrates automated cross-modal attack generation, employs three multi-turn attack algorithms, and uses an LLM judge with a five-level safety taxonomy to test multimodal input alignment.
– The framework uses a dual-metric system to differentiate between hard and soft Attack Success Rate, and introduces Inter-Turn Modality Switching to assess modality alignment.
💬 Research Conclusions:
– Experiments reveal that multi-turn strategies achieve high ASR and emphasize the need for provider-aware cross-modal safety testing as results vary by model family, highlighting the influence of modality in model performance.
👉 Paper link: https://huggingface.co/papers/2603.02482

9. BeamPERL: Parameter-Efficient RL with Verifiable Rewards Specializes Compact LLMs for Structured Beam Mechanics Reasoning
🔑 Keywords: Reinforcement Learning, Exact Physics Rewards, Beam Statics, Procedural Solution Templates, Verifiable Rewards
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to determine whether reinforcement learning with hard, verifiable rewards can teach a language model to legitimately reason about physics or if it primarily promotes pattern matching to achieve correct answers.
🛠️ Research Methods:
– A 1.5 billion parameter reasoning model is trained using parameter-efficient reinforcement learning with verifiable rewards (RLVR) and binary correctness rewards from symbolic solvers, focusing on beam statics without teacher-generated reasoning traces.
💬 Research Conclusions:
– Findings indicate that while the trained model shows improvement, it largely learns procedural solution patterns rather than transferable physical reasoning. The study points out that reliance solely on verifiable rewards may not be adequate for robust scientific reasoning, and suggests incorporating structured reasoning scaffolding for better results.
👉 Paper link: https://huggingface.co/papers/2603.04124

10. Specificity-aware reinforcement learning for fine-grained open-world classification
🔑 Keywords: SpeciaRL, Reinforcement Learning, Large Multimodal Models, Specificity, Fine-Grained Image Classification
💡 Category: Reinforcement Learning
🌟 Research Objective:
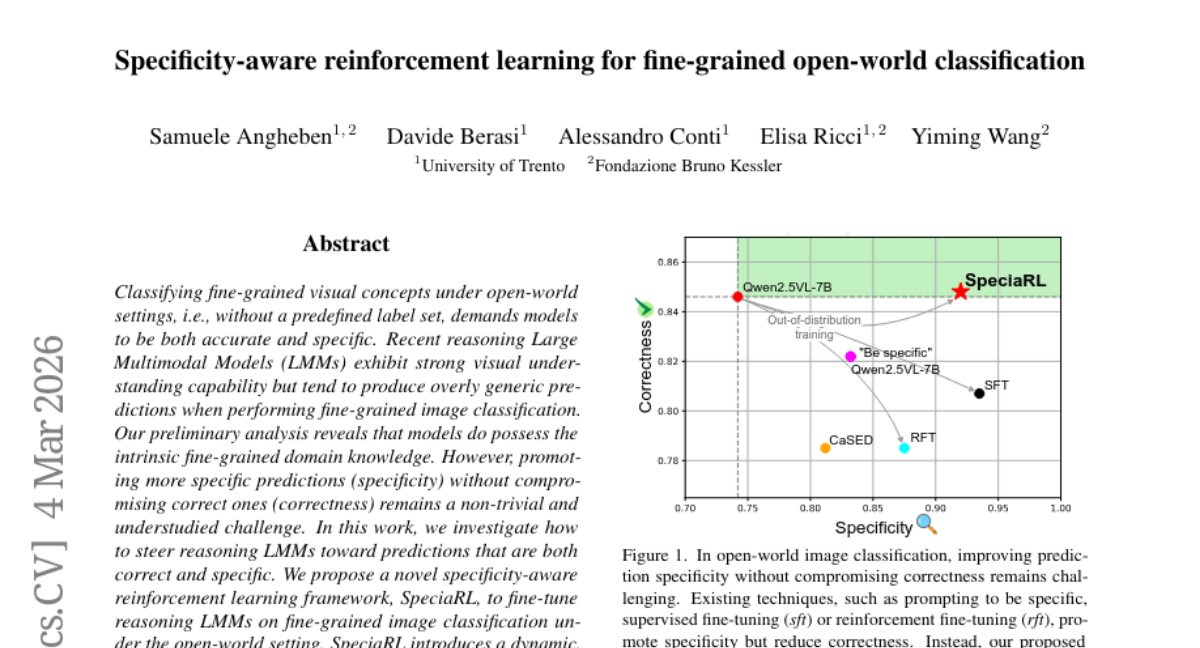
– The study proposes a reinforcement learning framework named SpeciaRL to enhance the specificity of large multimodal models in fine-grained image classification under open-world settings, without sacrificing prediction correctness.
🛠️ Research Methods:
– SpeciaRL leverages a dynamic, verifier-based reward signal in online rollouts, aimed at fine-tuning reasoning Large Multimodal Models to balance specificity and correctness.
💬 Research Conclusions:
– SpeciaRL achieves an optimal balance between prediction correctness and specificity, outperforming existing methods in fine-grained benchmarks and advancing open-world fine-grained image classification. The code and model are accessible on GitHub.
👉 Paper link: https://huggingface.co/papers/2603.03197
11. HDINO: A Concise and Efficient Open-Vocabulary Detector
🔑 Keywords: Open-Vocabulary Object Detection, Two-Stage Training Strategy, Semantic Alignment, Lightweight Feature Fusion, AI Native
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to develop an efficient open-vocabulary object detector, HDINO, that does not rely on manual data curation or resource-intensive cross-modal feature extraction.
🛠️ Research Methods:
– Implements a two-stage training strategy based on the transformer-based DINO model.
– Utilizes a One-to-Many Semantic Alignment Mechanism for aligning visual and textual modalities and a Difficulty Weighted Classification Loss to improve performance.
– Enhances representation sensitivity through a lightweight feature fusion module.
💬 Research Conclusions:
– HDINO-T achieves superior performance (49.2 mAP) on the COCO dataset using fewer images compared to competitors like Grounding DINO-T.
– The model demonstrates effectiveness and scalability with improved mAP scores after fine-tuning.
👉 Paper link: https://huggingface.co/papers/2603.02924

12.

13. GroupEnsemble: Efficient Uncertainty Estimation for DETR-based Object Detection
🔑 Keywords: GroupEnsemble, DETR, spatial uncertainty, Deep Ensembles, MC Dropout
💡 Category: Computer Vision
🌟 Research Objective:
– The main goal is to develop GroupEnsemble, an efficient uncertainty estimation method for DETR-like models, addressing limitations of existing methods like Deep Ensembles and MC Dropout.
🛠️ Research Methods:
– GroupEnsemble uses independent query groups in a single forward pass by feeding diverse object queries to the transformer decoder, with an attention mask to prevent inter-group interactions.
💬 Research Conclusions:
– GroupEnsemble, combined with MC Dropout, outperforms Deep Ensembles in uncertainty estimation efficiency at a lower memory and computational cost, validated with Cityscapes and COCO datasets.
👉 Paper link: https://huggingface.co/papers/2603.01847

14. MIBURI: Towards Expressive Interactive Gesture Synthesis
🔑 Keywords: Embodied Conversational Agents, large language model, causal framework, co-speech gesture synthesis, body-part aware gesture codecs
💡 Category: Human-AI Interaction
🌟 Research Objective:
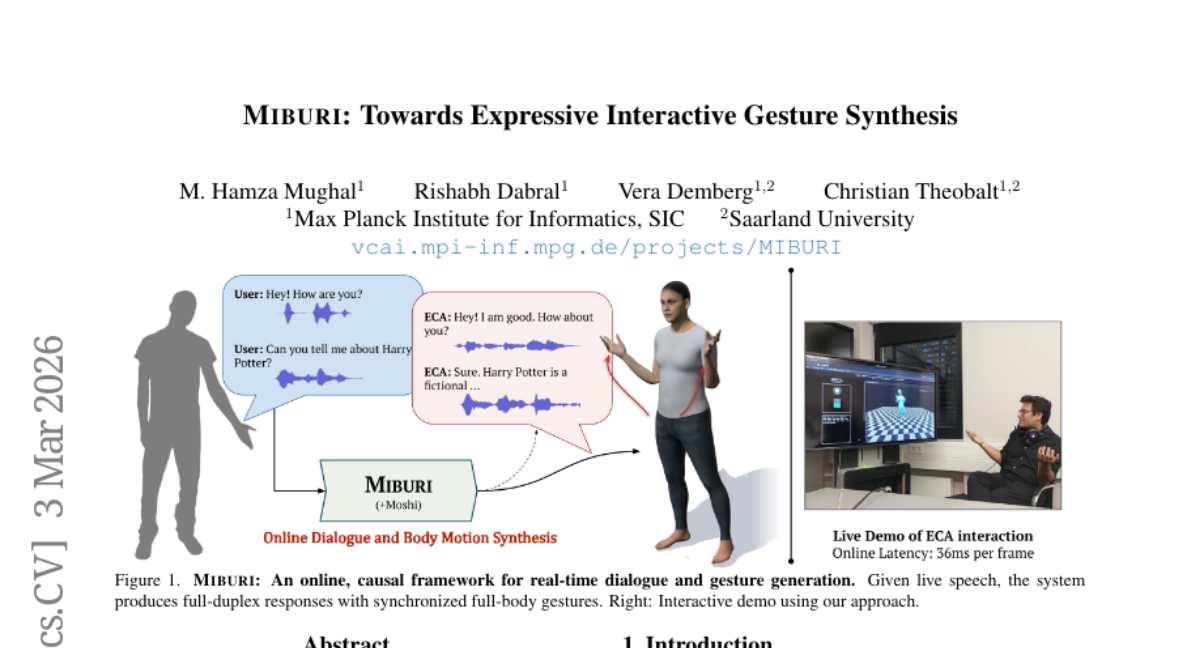
– The research aims to develop MIBURI, a framework that generates expressive full-body gestures and facial expressions synchronized with real-time spoken dialogue, addressing the current limitations in Embodied Conversational Agents (ECAs).
🛠️ Research Methods:
– A two-dimensional causal framework is used, conditioned on LLM-based speech-text embeddings, to autoregressively generate gestures. It involves body-part aware gesture codecs for encoding motion into discrete tokens, modeling temporal dynamics and motion hierarchy.
💬 Research Conclusions:
– MIBURI effectively produces natural and contextually aligned gestures, outperforming recent baselines with its real-time causal approach. The study includes demonstrations showing improved gesture realism and diversity.
👉 Paper link: https://huggingface.co/papers/2603.03282
15. EmbodiedSplat: Online Feed-Forward Semantic 3DGS for Open-Vocabulary 3D Scene Understanding
🔑 Keywords: EmbodiedSplat, 3D scene understanding, semantic reconstruction, CLIP embeddings, real-time
💡 Category: Computer Vision
🌟 Research Objective:
– Develop EmbodiedSplat for real-time 3D semantic reconstruction from streaming images, enabling understanding of 3D scenes in an online, nearly real-time manner.
🛠️ Research Methods:
– Utilize an Online Sparse Coefficients Field and CLIP Global Codebook to bind 2D CLIP embeddings to 3D Gaussians while minimizing memory usage.
– Combine 3D U-Net to create 3D geometric-aware CLIP features from partial point clouds.
💬 Research Conclusions:
– Demonstrates the method’s effectiveness and efficiency through extensive experiments on diverse indoor datasets such as ScanNet, ScanNet++, and Replica.
👉 Paper link: https://huggingface.co/papers/2603.04254

16. SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
🔑 Keywords: Large language model, software engineering tasks, repository-level benchmark, Continuous Integration, maintainability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research introduces SWE-CI, the first repository-level benchmark designed to evaluate the ability of code generation agents to maintain code quality during long-term software evolution cycles.
🛠️ Research Methods:
– SWE-CI is based on the Continuous Integration loop, encompassing 100 tasks related to real-world code repositories, each with an average evolution history of 233 days and 71 consecutive commits, requiring agents to perform multiple rounds of analysis and coding iterations.
💬 Research Conclusions:
– The benchmark aims to provide valuable insights into the sustainability of code quality by agents through long-term evolution processes, shifting the evaluation focus from short-term functional correctness to long-term maintainability.
👉 Paper link: https://huggingface.co/papers/2603.03823

17. RIVER: A Real-Time Interaction Benchmark for Video LLMs
🔑 Keywords: Real-time interactivity, RIVER Bench, Retrospective Memory, Live-Perception, Proactive Anticipation
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To introduce the RIVER Bench, which evaluates online video comprehension capabilities in real-time interaction settings.
🛠️ Research Methods:
– Developed a novel framework with tasks for Retrospective Memory, Live-Perception, and Proactive Anticipation to mimic interactive dialogues using videos from diverse sources.
💬 Research Conclusions:
– Offline models perform well in single question-answering tasks but struggle with real-time processing and long-term memory. A general improvement method for online interaction models was proposed, with the potential to significantly advance real-time interactive video understanding.
👉 Paper link: https://huggingface.co/papers/2603.03985

18. AgilePruner: An Empirical Study of Attention and Diversity for Adaptive Visual Token Pruning in Large Vision-Language Models
🔑 Keywords: Large Vision-Language Models, visual token pruning, feature diversity, attention-based pruning, hybrid pruning strategies
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Conduct an empirical analysis of visual token pruning methods in large vision-language models to understand their strengths and limitations.
🛠️ Research Methods:
– Utilized effective rank for measuring feature diversity and attention score entropy to investigate visual token processing mechanisms.
💬 Research Conclusions:
– Diversity-based methods are less effective in preserving feature diversity and are associated with increased hallucination frequency compared to attention-based methods.
– Attention-based pruning works better for simple images, while diversity-based approaches excel in handling complex images.
– Image-aware adjustments to hybrid pruning strategies improve performance; demonstrated by a simple adaptive pruning mechanism that performs well across benchmarks and hallucination-specific evaluations.
👉 Paper link: https://huggingface.co/papers/2603.01236

19. CubeComposer: Spatio-Temporal Autoregressive 4K 360° Video Generation from Perspective Video
🔑 Keywords: Spatio-temporal autoregressive diffusion model, 360° panoramic videos, Cubemap representations, AI-generated summary, Virtual reality
💡 Category: Generative Models
🌟 Research Objective:
– To generate high-quality 4K-resolution 360° panoramic videos natively for enhancing the immersive VR experience.
🛠️ Research Methods:
– Decomposing videos into cubemap representations to facilitate efficient autoregressive synthesis.
– Implementing a spatio-temporal autoregressive strategy and cube face context management for coherent video generation and improved efficiency.
💬 Research Conclusions:
– CubeComposer surpasses existing methods by producing superior native resolution and visual quality, proving its practicality in VR applications.
👉 Paper link: https://huggingface.co/papers/2603.04291

20. ArtHOI: Articulated Human-Object Interaction Synthesis by 4D Reconstruction from Video Priors
🔑 Keywords: Articulated human-object interactions, 4D reconstruction, Monocular video, Zero-shot framework, Optical flow
💡 Category: Computer Vision
🌟 Research Objective:
– To synthesize articulated human-object interactions through 4D reconstruction from monocular video priors without relying on 3D/4D supervision.
🛠️ Research Methods:
– The study proposes ArtHOI, a framework utilizing a flow-based part segmentation for disentangling dynamic from static regions via optical flow, combined with a decoupled reconstruction pipeline that handles object articulation first, followed by human motion synthesis.
💬 Research Conclusions:
– ArtHOI bridges video-based generation and geometry-aware reconstruction, excelling in producing semantically and physically consistent interactions. It surpasses previous methods in terms of contact accuracy, penetration reduction, and articulation fidelity across complex scenes.
👉 Paper link: https://huggingface.co/papers/2603.04338

21. Proact-VL: A Proactive VideoLLM for Real-Time AI Companions
🔑 Keywords: Real-time interactive agents, Multimodal framework, Gaming scenarios, Video understanding, Response latency
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To create a multimodal framework, Proact-VL, that enables real-time interactive AI companions in gaming scenarios with low-latency responses and robust video understanding capabilities.
🛠️ Research Methods:
– The authors use two specific gaming scenarios, commentator and guide, to develop AI companions and introduce the Live Gaming Benchmark dataset with three scenarios: solo commentary, co-commentary, and user guidance.
💬 Research Conclusions:
– Proact-VL demonstrates superior response latency and quality while maintaining strong video understanding capabilities, proving its practicality for real-time interactive applications.
👉 Paper link: https://huggingface.co/papers/2603.03447

22. T2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
🔑 Keywords: Structure of Thought, T2S-Bench, text-to-structure capabilities, multi-hop reasoning, language model performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces the Structure of Thought (SoT) prompting technique to enhance language model performance by guiding explicit intermediate text structuring across various tasks.
🛠️ Research Methods:
– The research employs T2S-Bench, a benchmark designed to evaluate and improve models’ text-to-structure capabilities, including 1.8K samples across six scientific domains and 32 structural types.
💬 Research Conclusions:
– The findings demonstrate notable improvements with SoT, achieving a +5.7% performance boost on eight text-processing tasks and an additional +8.6% when fine-tuned on T2S-Bench, highlighting the importance of explicit text structuring.
👉 Paper link: https://huggingface.co/papers/2603.03790
