AI Native Daily Paper Digest – 20260318

1. InCoder-32B: Code Foundation Model for Industrial Scenarios
🔑 Keywords: InCoder-32B, code foundation model, hardware-aware programming, execution-grounded verification, industrial benchmarks
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary objective of the research is to develop InCoder-32B, a 32-billion-parameter code model aimed at improving performance in hardware-aware programming tasks, which are common in industrial scenarios.
🛠️ Research Methods:
– The research incorporates a novel training approach that involves general code pre-training, curated industrial code annealing, progressively extended context mid-training up to 128K tokens using synthetic industrial reasoning data, and post-training with execution-grounded verification.
💬 Research Conclusions:
– The study finds that InCoder-32B not only demonstrates highly competitive performance on general programming tasks but also sets strong open-source baselines across various industrial domains, proving its efficiency and utility in specialized hardware-related coding applications.
👉 Paper link: https://huggingface.co/papers/2603.16790

2. Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
🔑 Keywords: Qianfan-OCR, vision-language model, document parsing, layout analysis, key information extraction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The development of Qianfan-OCR, a 4B-parameter end-to-end vision-language model that unifies document parsing, layout analysis, and document understanding.
🛠️ Research Methods:
– Introduction of the Layout-as-Thought mechanism using special think tokens to generate structured layout representations before final output.
💬 Research Conclusions:
– Qianfan-OCR achieves top ranks on various OCR benchmarks, including first place on OmniDocBench v1.5 and OlmOCR Bench, while surpassing several notable models in key information extraction.
👉 Paper link: https://huggingface.co/papers/2603.13398

3. WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
🔑 Keywords: video diffusion transformers, camera pose, action control, 3D consistency, interactive gaming
💡 Category: Generative Models
🌟 Research Objective:
– To enhance precise action control and long-term 3D consistency in interactive gaming through the integration of video diffusion transformers with camera pose representation.
🛠️ Research Methods:
– Utilization of a physics-based continuous action space and Lie algebra to derive precise 6-DoF camera poses.
– Camera embedder integration into a generative model for accurate action alignment and retrieval of past observations using global camera poses as spatial indices.
💬 Research Conclusions:
– The proposed approach significantly outperforms current state-of-the-art interactive gaming world models in action controllability, long-horizon visual quality, and 3D spatial consistency.
👉 Paper link: https://huggingface.co/papers/2603.16871
4. Kinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
🔑 Keywords: Kinema4D, Embodied AI, 4D generative robotic simulator, zero-shot transfer
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper introduces Kinema4D, a 4D generative robotic simulator aimed at improving the simulation of robot-world interactions through precise kinematic control and spatiotemporal environmental reaction synthesis.
🛠️ Research Methods:
– The study developed a precise 4D representation for robot controls using a URDF-based 3D robot, and a generative 4D modeling approach for environmental reactions, projecting robot trajectories into spatiotemporal visual signals.
💬 Research Conclusions:
– Experiments demonstrated that Kinema4D effectively simulates physically-plausible, geometry-consistent, embodiment-agnostic interactions. It also shows potential for zero-shot transfer, advancing next-generation embodied simulation.
👉 Paper link: https://huggingface.co/papers/2603.16669
5. Online Experiential Learning for Language Models
🔑 Keywords: Online Experiential Learning, experiential knowledge, deployment experience, task accuracy, token efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to continuously improve large language models by leveraging deployment experience through a framework called Online Experiential Learning (OEL).
🛠️ Research Methods:
– OEL works in two stages: extracting and accumulating experiential knowledge from user interaction trajectories, and consolidating this knowledge into model parameters via on-policy context distillation.
💬 Research Conclusions:
– OEL consistently enhances task accuracy and token efficiency while preserving out-of-distribution performance. It shows that using extracted experiential knowledge is more effective for model improvement than raw trajectories.
👉 Paper link: https://huggingface.co/papers/2603.16856

6. WiT: Waypoint Diffusion Transformers via Trajectory Conflict Navigation
🔑 Keywords: Waypoint Diffusion Transformers, pixel space, semantic waypoints, trajectory conflicts
💡 Category: Generative Models
🌟 Research Objective:
– To solve trajectory conflicts in pixel-space flow matching by leveraging Waypoint Diffusion Transformers and semantic waypoints.
🛠️ Research Methods:
– Utilization of Waypoint Diffusion Transformers to factorize vector fields and disentangle generation paths.
– Incorporation of intermediate semantic waypoints from pre-trained vision models in the diffusion process.
💬 Research Conclusions:
– Waypoint Diffusion Transformers outperform existing pixel-space baselines on ImageNet 256×256.
– The approach accelerates training convergence by 2.2x using lightweight generators and intermediate waypoints.
👉 Paper link: https://huggingface.co/papers/2603.15132

7. GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent
🔑 Keywords: GradMem, gradient descent, memory tokens, self-supervised context reconstruction loss
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary objective is to enable efficient context storage and retrieval in language models, outperforming traditional approaches through gradient-based memory writing.
🛠️ Research Methods:
– GradMem is introduced, utilizing a few steps of gradient descent on prefix memory tokens during inference without altering model weights, optimizing a self-supervised context reconstruction loss for iterative error correction.
💬 Research Conclusions:
– GradMem surpasses forward-only methods in memory efficiency for key-value retrieval and demonstrates effective scaling with additional gradient steps. It also achieves competitive results on natural language tasks such as bAbI and SQuAD variants with pretrained language models.
👉 Paper link: https://huggingface.co/papers/2603.13875

8. SegviGen: Repurposing 3D Generative Model for Part Segmentation
🔑 Keywords: SegviGen, 3D generative models, 3D part segmentation, pretrained 3D generative priors, interactive part segmentation
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the research is to introduce SegviGen, which reuses pretrained 3D generative models for efficient 3D part segmentation with minimal labeled data.
🛠️ Research Methods:
– SegviGen applies distinctive part colorization on geometry-aligned reconstructions and supports both interactive and full segmentation with 2D guidance in a unified framework.
💬 Research Conclusions:
– SegviGen demonstrates superior performance by enhancing segmentation accuracy by 40% for interactive part segmentation and 15% for full segmentation, using only 0.32% of labeled data, highlighting effective transfer of pretrained 3D generative priors.
👉 Paper link: https://huggingface.co/papers/2603.16869
9. SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
🔑 Keywords: Omni-modal large language models, Social interactivity, Speaker identification, Interruption timing, Natural interruption generation
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The research aims to bridge the gap in evaluating social interactivity in omni-modal large language models by introducing a benchmark called SocialOmni.
🛠️ Research Methods:
– The study operationalizes conversational interactivity assessment through three core dimensions: speaker separation and identification, interruption timing control, and natural interruption generation. It includes 2,000 perception samples and a diagnostic set with temporal and contextual constraints.
💬 Research Conclusions:
– Findings reveal significant variance in social-interaction capabilities across models and a decoupling between perceptual accuracy and contextually appropriate interruption generation. The diagnostics provide actionable insights for future model improvements.
👉 Paper link: https://huggingface.co/papers/2603.16859

10. Efficient Reasoning on the Edge
🔑 Keywords: LoRA adapters, reinforcement learning, parallel test-time scaling, dynamic adapter-switching, KV-cache
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enable efficient reasoning in small language models for edge deployment by overcoming challenges such as high token generation costs and large context requirements.
🛠️ Research Methods:
– The paper employs LoRA adapters combined with supervised fine-tuning and introduces budget forcing via reinforcement learning to reduce response length. It also uses parallel test-time scaling and a dynamic adapter-switching mechanism for efficient on-device inference.
💬 Research Conclusions:
– The proposed method achieves accurate reasoning under strict resource constraints, demonstrating practical LLM reasoning for mobile scenarios, as evidenced by tests on Qwen2.5-7B and videos available on the project page.
👉 Paper link: https://huggingface.co/papers/2603.16867

11. Semi-Autonomous Formalization of the Vlasov-Maxwell-Landau Equilibrium
🔑 Keywords: AI-assisted mathematical research, Vlasov-Maxwell-Landau system, Gemini DeepThink, Claude Code, Lean 4
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To formalize the equilibrium characterization in the Vlasov-Maxwell-Landau (VML) system using a complete Lean 4 formalization.
🛠️ Research Methods:
– Utilized an AI reasoning model (Gemini DeepThink) to generate a proof, translated by an agentic coding tool (Claude Code) into Lean, closed lemmas using a specialized prover (Aristotle), and verified results through the Lean kernel.
💬 Research Conclusions:
– Demonstrated a full AI-assisted mathematical research loop with detailed insights into AI failure modes and highlighted the importance of human review. The formalization was completed before the corresponding math paper was finalized, with all materials archived publicly.
👉 Paper link: https://huggingface.co/papers/2603.15929

12. M^3: Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM
🔑 Keywords: Multi-view foundation model, SLAM, pose estimation, dense correspondences, Monocular Gaussian Splatting
💡 Category: Computer Vision
🌟 Research Objective:
– This research aims to enhance pose estimation and scene reconstruction accuracy through a novel integration of a Multi-view foundation model with a matching head into Monocular Gaussian Splatting SLAM.
🛠️ Research Methods:
– The proposed M^3 model integrates fine-grained dense correspondences and utilizes techniques like dynamic area suppression and cross-inference intrinsic alignment to improve tracking stability.
💬 Research Conclusions:
– Experiments demonstrated that M^3 achieves state-of-the-art accuracy in pose estimation and scene reconstruction, significantly reducing errors and outperforming existing models such as VGGT-SLAM 2.0 and ARTDECO.
👉 Paper link: https://huggingface.co/papers/2603.16844

13. From Passive Observer to Active Critic: Reinforcement Learning Elicits Process Reasoning for Robotic Manipulation
🔑 Keywords: Reinforcement Learning, PRIMO R1, Video MLLMs, Zero-Shot Generalization
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper introduces PRIMO R1, aiming to transform video MLLMs from passive “Observers” into active “Critics” for more accurate process supervision in long-horizon robotic manipulation.
🛠️ Research Methods:
– Utilizes outcome-based Reinforcement Learning to encourage Chain-of-Thought generation for better progress estimation.
– Structures temporal input in video sequences by anchoring initial and current state images.
💬 Research Conclusions:
– PRIMO R1 achieves state-of-the-art performance, significantly reducing mean absolute error compared to existing models and yielding notable improvements over larger MLLMs.
– Demonstrates strong zero-shot generalization and sets a new benchmark on RoboFail with 67.0% accuracy, outperforming models like OpenAI o1.
👉 Paper link: https://huggingface.co/papers/2603.15600

14. Omnilingual MT: Machine Translation for 1,600 Languages
🔑 Keywords: Omnilingual Machine Translation, Machine Translation, Large Language Models, Multilingual Corpora, Cross-lingual Transfer
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop the Omnilingual Machine Translation system supporting over 1,600 languages using specialized large language models that outperform larger baselines.
🛠️ Research Methods:
– Utilized a comprehensive data strategy integrating large public multilingual corpora with newly created datasets, specializing a Large Language Model (LLM) as a decoder-only model or in an encoder-decoder architecture.
💬 Research Conclusions:
– The OMT system, with models ranging from 1B to 8B parameters, matches or exceeds the performance of a 70B LLM baseline, enabling strong translation quality in low-compute settings and expanding the set of supported languages for coherent generation.
– OMT models show improvement in cross-lingual transfer and bring closer to solving the understanding aspect in machine translation for 1,600 languages.
👉 Paper link: https://huggingface.co/papers/2603.16309

15. Recursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Context
🔑 Keywords: SRLM, Long-context handling, Uncertainty-aware, Self-reflection, Recursive Language Models, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces SRLM, a framework aimed at improving long-context handling in language models by incorporating uncertainty-aware self-reflection to guide context interaction, outperforming existing models like RLM.
🛠️ Research Methods:
– SRLM uses self consistency, reasoning length, and verbalized confidence as signals of uncertainty to evaluate context-interaction programs. Extensive experiments were conducted across diverse datasets and backbone models.
💬 Research Conclusions:
– SRLM performs significantly better than RLM, achieving up to 22% improvement. It shows consistent gains across various context lengths and performs well in semantically intensive tasks, where broader contextual understanding is necessary.
👉 Paper link: https://huggingface.co/papers/2603.15653

16. V-Co: A Closer Look at Visual Representation Alignment via Co-Denoising
🔑 Keywords: Pixel-space diffusion, visual co-denoising, pretrained visual features, dual-stream architecture, classifier-free guidance
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enhance pixel-space diffusion models through visual co-denoising techniques that utilize pretrained visual features, aiming to improve model performance by identifying essential architectural and training components.
🛠️ Research Methods:
– A unified JiT-based framework is employed for a systematic study of visual co-denoising, isolating effective design components such as a dual-stream architecture, classifier-free guidance with unconditional prediction, perceptual-drifting hybrid loss, and RMS-based feature rescaling for cross-stream calibration.
💬 Research Conclusions:
– The study identifies four key components critical for effective visual co-denoising, providing a straightforward approach that enhances performance over baseline models with fewer training epochs, as demonstrated on ImageNet-256.
👉 Paper link: https://huggingface.co/papers/2603.16792

17. Anticipatory Planning for Multimodal AI Agents
🔑 Keywords: TraceR1, Reinforcement Learning, Multimodal Agents, Anticipatory Trajectory Reasoning, Execution Feedback
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary objective is to enhance the planning capabilities of multimodal agents by employing a two-stage reinforcement learning framework called TraceR1, which focuses on anticipatory trajectory reasoning and execution feedback refinement.
🛠️ Research Methods:
– The research utilizes a two-stage reinforcement learning approach where the first stage involves trajectory-level reinforcement learning to ensure global consistency across predicted action sequences. The second stage involves grounded reinforcement fine-tuning, using execution feedback to refine accuracy and executability at the step level.
💬 Research Conclusions:
– The framework, TraceR1, demonstrates significant improvements over reactive and single-stage baselines across various benchmarks. It enhances planning stability, execution robustness, and generalization, showing that anticipatory trajectory reasoning is crucial for developing multimodal agents capable of effective reasoning, planning, and action in complex environments.
👉 Paper link: https://huggingface.co/papers/2603.16777

18. ViT-AdaLA: Adapting Vision Transformers with Linear Attention
🔑 Keywords: Vision Transformers, AI-generated summary, linear attention, attention alignment, feature alignment
💡 Category: Computer Vision
🌟 Research Objective:
– The main goal is to adapt vision foundation models to linear attention Vision Transformers to mitigate quadratic complexity limitations.
🛠️ Research Methods:
– A framework called ViT-AdaLA is proposed, which includes three stages: attention alignment, feature alignment, and supervised fine-tuning.
💬 Research Conclusions:
– The study demonstrates that ViT-AdaLA effectively adapts and transfers prior knowledge from vision foundation models to linear attention Vision Transformers, showing its effectiveness in classification and segmentation tasks.
👉 Paper link: https://huggingface.co/papers/2603.16063

19. Polyglot-Lion: Efficient Multilingual ASR for Singapore via Balanced Fine-Tuning of Qwen3-ASR
🔑 Keywords: Polyglot-Lion, multilingual ASR, fine-tuning, inference throughput, linguistic diversity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a compact multilingual ASR model family tailored for the linguistic diversity of Singapore, optimizing cost and performance.
🛠️ Research Methods:
– Utilized balanced fine-tuning of pretrained models (Qwen3-ASR-0.6B and Qwen3-ASR-1.7B) on publicly available speech corpora, without language-tag conditioning.
💬 Research Conclusions:
– Polyglot-Lion-1.7B achieves competitive error rates with significantly lower cost and faster inference speed compared to larger models, demonstrating the effectiveness of linguistically balanced fine-tuning on moderate-scale models.
👉 Paper link: https://huggingface.co/papers/2603.16184

20. CCTU: A Benchmark for Tool Use under Complex Constraints
🔑 Keywords: LLMs, constraints, tool use, CCTU, evaluation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce CCTU, a benchmark for evaluating the tool use of large language models (LLMs) under complex constraints.
🛠️ Research Methods:
– Developed a taxonomy of 12 constraint categories across four dimensions, and curated 200 challenging test cases for assessment.
– Employed an executable constraint validation module to ensure compliance during model-environment interactions.
💬 Research Conclusions:
– Found that no model achieves a task completion rate above 20% when all constraints must be adhered to.
– Identified significant performance limitations, especially in resource and response dimensions, highlighting a bottleneck in robust tool-use enhancements.
– Released data and code to support future research efforts.
👉 Paper link: https://huggingface.co/papers/2603.15309

21. MDM-Prime-v2: Binary Encoding and Index Shuffling Enable Compute-optimal Scaling of Diffusion Language Models
🔑 Keywords: Masked Diffusion Models, Binary Encoding, Index Shuffling, Sub-tokens, Perplexity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve compute efficiency and performance of masked diffusion language models using binary encoding and index shuffling compared to autoregressive models and previous approaches.
🛠️ Research Methods:
– Development of MDM-Prime-v2 incorporating Binary Encoding and Index Shuffling and evaluation through scaling analysis and perplexity metrics.
💬 Research Conclusions:
– MDM-Prime-v2 is 21.8 times more compute-efficient than autoregressive models, and achieves a perplexity of 7.77 on OpenWebText, outperforming other models. It also demonstrates superior zero-shot accuracy on commonsense reasoning tasks with a model size of 1.1B parameters.
👉 Paper link: https://huggingface.co/papers/2603.16077

22. ECG-Reasoning-Benchmark: A Benchmark for Evaluating Clinical Reasoning Capabilities in ECG Interpretation
🔑 Keywords: Multimodal Large Language Models, ECG-Reasoning-Benchmark, medical AI, step-by-step reasoning, visual interpretation
💡 Category: AI in Healthcare
🌟 Research Objective:
– To investigate whether Multimodal Large Language Models genuinely perform step-by-step reasoning or rely on superficial visual cues in automated electrocardiogram interpretation.
🛠️ Research Methods:
– Introduction of the ECG-Reasoning-Benchmark, a novel multi-turn evaluation framework with over 6,400 samples, used to systematically assess reasoning across 17 core ECG diagnoses.
💬 Research Conclusions:
– Current state-of-the-art models show critical failures in executing multi-step logical deduction with near-zero success rates in maintaining complete reasoning chains, highlighting a flaw in training paradigms and the necessity for reasoning-centric medical AI.
👉 Paper link: https://huggingface.co/papers/2603.14326

23. ARISE: Agent Reasoning with Intrinsic Skill Evolution in Hierarchical Reinforcement Learning
🔑 Keywords: hierarchical reinforcement learning, mathematical reasoning, skill management, policy-driven selection, structured skill libraries
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to improve mathematical reasoning in language models using a hierarchical reinforcement learning framework named ARISE with a focus on reusable strategies and skill libraries.
🛠️ Research Methods:
– ARISE employs a skill management system consisting of a Skills Manager and a Worker, utilizing a shared policy for high-level skill management and low-level response generation, alongside a hierarchical reward design to enhance reasoning ability and skill library quality.
💬 Research Conclusions:
– Experiments demonstrate that ARISE outperforms GRPO-family algorithms and memory-augmented baselines, especially in out-of-distribution tasks, and that both reasoning performance and library quality progressively improve through training. Ablation studies validate the contribution of each component to the overall improvement.
👉 Paper link: https://huggingface.co/papers/2603.16060

24. I Know What I Don’t Know: Latent Posterior Factor Models for Multi-Evidence Probabilistic Reasoning
🔑 Keywords: Latent Posterior Factors, Variational Autoencoder, Sum-Product Network, Probabilistic Reasoning, Calibration
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to address real-world decision-making challenges by introducing a framework that allows for probabilistic reasoning over unstructured evidence while maintaining calibrated uncertainty estimates.
🛠️ Research Methods:
– The research presents the Latent Posterior Factors (LPF) framework, combining Variational Autoencoder latent posteriors with Sum-Product Network inference.
– Two architectures, LPF-SPN and LPF-Learned, are proposed to enable controlled comparison between explicit probabilistic reasoning and learned aggregation.
💬 Research Conclusions:
– LPF-SPN achieves high accuracy (up to 97.8%) and low calibration error (ECE 1.4%) across eight domains, outperforming existing alternatives like evidential deep learning and large language models.
– The study provides formal guarantees and a reproducible training methodology with seed selection, validated across multiple benchmarks including the FEVER benchmark.
👉 Paper link: https://huggingface.co/papers/2603.15670

25. BERTology of Molecular Property Prediction
🔑 Keywords: Chemical language models, molecular property prediction, dataset size, model size, standardization
💡 Category: Machine Learning
🌟 Research Objective:
– To systematically investigate the effects of dataset size, model size, and standardization on the performance of Chemical Language Models (CLMs) in molecular property prediction tasks.
🛠️ Research Methods:
– Conducting and analyzing hundreds of meticulously controlled experiments to assess the impact of various factors on the pre-training and fine-tuning performance of CLMs.
💬 Research Conclusions:
– Providing comprehensive numerical evidence and deeper insight into the underlying mechanisms affecting CLM performance, highlighting overlooked aspects in existing literature.
👉 Paper link: https://huggingface.co/papers/2603.13627

26. Chain-of-Trajectories: Unlocking the Intrinsic Generative Optimality of Diffusion Models via Graph-Theoretic Planning
🔑 Keywords: Chain-of-Trajectories, Diffusion DNA, Graph Planning, System 2, Output Quality
💡 Category: Generative Models
🌟 Research Objective:
– The introduction of a Chain-of-Trajectories (CoTj) framework aims to enable System 2 deliberative planning for diffusion models, effectively managing computational resources based on denoising difficulty.
🛠️ Research Methods:
– The framework uses Diffusion DNA as a low-dimensional signature to quantify per-stage denoising difficulty, reformulating sampling as graph planning on a directed acyclic graph, within a Predict-Plan-Execute paradigm.
💬 Research Conclusions:
– CoTj improves output quality and stability by discovering context-aware trajectories while reducing redundant computation, establishing a foundation for resource-aware, planning-based diffusion modeling.
👉 Paper link: https://huggingface.co/papers/2603.14704

27.

28. Test-Time Strategies for More Efficient and Accurate Agentic RAG
🔑 Keywords: Retrieval-Augmented Generation, Search-R1, Contextualization Module, De-duplication Module, HotpotQA
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve retrieval efficiency and answer accuracy in the Search-R1 pipeline by integrating contextualization and de-duplication modules.
🛠️ Research Methods:
– The study explores test-time modifications by employing a contextualization module to enhance reasoning with retrieved information and a de-duplication module to replace redundant documents. The effectiveness of these modifications is evaluated using the HotpotQA and Natural Questions datasets.
💬 Research Conclusions:
– The integration of these modules into the Search-R1 pipeline resulted in a 5.6% increase in exact match (EM) score and a 10.5% reduction in retrieval turns, showcasing enhanced answer accuracy and retrieval efficiency.
👉 Paper link: https://huggingface.co/papers/2603.12396

29. Measuring Primitive Accumulation: An Information-Theoretic Approach to Capitalist Enclosure in PIK2, Indonesia
🔑 Keywords: Non-equilibrium spatial process, Land enclosure, Mega-development, Information-geometric tools, Statistical-mechanical tools
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To study and quantify the non-equilibrium spatial process of large-scale land enclosure for speculative mega-development using data from the Pantai Indah Kapuk 2 (PIK2) project in Indonesia.
🛠️ Research Methods:
– Utilizing Sentinel-2 land-use/land-cover (LULC) data at a 10-meter resolution over eight years.
– Projection of landscapes onto a Marxian probability simplex and analysis using Fisher-Rao geodesic distances.
– Absorbing Markov chain analysis and percolation analysis to evaluate spatial growth patterns.
– Examination of urban boundary fractal dimensions for frontier expansion analysis.
💬 Research Conclusions:
– The study reveals a significant transformation pulse during 2019-2020.
– Expected absorption times into the built environment are approximately 46 years for cropland and 38.1 years for tree cover.
– A high retention rate of 96.4% for built areas.
– Findings highlight planned, rather than stochastic, spatial growth.
– Use of information-geometric and statistical-mechanical tools provides precise characterization of capitalist spatial accumulation.
👉 Paper link: https://huggingface.co/papers/2603.13715

30. VAREX: A Benchmark for Multi-Modal Structured Extraction from Documents
🔑 Keywords: VAREX, multimodal foundation models, structured data extraction, Reverse Annotation pipeline, layout-preserving text
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective of the study is to introduce VAREX, a benchmark for assessing multimodal foundation models in extracting structured data from government forms using a unique set of synthetic PDF templates and four input modalities.
🛠️ Research Methods:
– VAREX employs a Reverse Annotation pipeline to generate synthetic values and uses 1,777 documents with diverse schemas across various structural categories, evaluating models across four input modalities: plain text, layout-preserving text, document image, and combined text and image.
💬 Research Conclusions:
– The study finds that below 4B parameters, models face structured output compliance issues rather than extraction capability. Layout-preserving text modality enhances extraction accuracy, and extraction-specific fine-tuning can significantly improve performance without increasing model scale. The benchmark effectively differentiates models within 60-95% accuracy range.
👉 Paper link: https://huggingface.co/papers/2603.15118

31. HistoAtlas: A Pan-Cancer Morphology Atlas Linking Histomics to Molecular Programs and Clinical Outcomes
🔑 Keywords: HistoAtlas, histomic features, TCGA, pan-cancer, biomarker discovery
💡 Category: AI in Healthcare
🌟 Research Objective:
– The objective of the study is to create a comprehensive computational map, called HistoAtlas, which links histomic features from H&E slides to clinical outcomes and molecular profiles across multiple cancer types.
🛠️ Research Methods:
– HistoAtlas extracts 38 interpretable histomic features from 6,745 diagnostic H&E slides across 21 TCGA cancer types. The associations are covariate-adjusted, multiple-testing corrected, and classified into evidence-strength tiers.
💬 Research Conclusions:
– The atlas successfully recovers known biology, including immune infiltration and prognosis, while uncovering new compartment-specific immune signals and morphological subtypes with divergent outcomes. The results are spatially traceable, statistically calibrated, and enable large-scale biomarker discovery without specialized techniques. Data and an interactive web atlas are freely available for exploration.
👉 Paper link: https://huggingface.co/papers/2603.16587

32. Theoretical Foundations of Latent Posterior Factors: Formal Guarantees for Multi-Evidence Reasoning
🔑 Keywords: Latent Posterior Factors, Probabilistic Prediction, Trustworthy AI, Variational Autoencoder, Sum-Product Network
💡 Category: Foundations of AI
🌟 Research Objective:
– The primary objective is the development of Latent Posterior Factors (LPF), a theoretical framework to effectively aggregate heterogeneous evidence in probabilistic prediction tasks, ensuring formal guarantees for trustworthy AI applications.
🛠️ Research Methods:
– LPF uses a variational autoencoder to encode evidence into Gaussian latent posteriors, then converts these posteriors into soft factors via Monte Carlo marginalization. The aggregation is performed through exact Sum-Product Network inference or a learned neural aggregator.
💬 Research Conclusions:
– LPF offers seven formal guarantees for trustworthy AI, including calibration preservation and uncertainty decomposition, with empirical validation on datasets up to 4,200 examples, establishing its robustness in safety-critical applications.
👉 Paper link: https://huggingface.co/papers/2603.15674

33. SuperLocalMemory V3: Information-Geometric Foundations for Zero-LLM Enterprise Agent Memory
🔑 Keywords: AI agent memory, information-geometric, Riemannian metric, cellular sheaf model
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to establish the mathematical foundations for memory retrieval, lifecycle management, and contradiction detection in AI agents through innovative information-geometric, sheaf-theoretic, and stochastic-dynamical approaches.
🛠️ Research Methods:
– Introduced a retrieval metric based on Fisher information structure suitable for diagonal Gaussian families, adhering to Riemannian metric properties.
– Developed memory lifecycle models using Riemannian Langevin dynamics with guarantees of convergence through the Fokker-Planck equation.
– Proposed a cellular sheaf model where first cohomology classes identify contradictions in memory contexts.
💬 Research Conclusions:
– Achieved significant improvements over engineering baselines on the LoCoMo benchmark with up to +19.9 percentage points.
– Implemented a four-channel retrieval architecture with high accuracy, achieving 75% without cloud dependency and 87.7% with cloud enhancement.
– The study presents a pioneering framework meeting EU AI Act data sovereignty requirements, setting a new standard for AI agent memory systems.
👉 Paper link: https://huggingface.co/papers/2603.14588

34. Residual Stream Duality in Modern Transformer Architectures
🔑 Keywords: Transformer’s residual stream, causal depth-wise residual attention, ShortSWA, AI-generated summary, Deep Delta Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to analyze Transformer’s residual stream through a two-axis framework involving sequence position and layer depth to better understand information flow.
🛠️ Research Methods:
– Investigates the duality of causal depth-wise residual attention and causal short sliding-window attention (ShortSWA), evaluating their roles and efficiencies in hardware contexts.
💬 Research Conclusions:
– The study concludes that operator-level duality doesn’t imply systems-level symmetry. For large models, sequence-axis ShortSWA is preferred for its hardware compatibility, while Deep Delta Learning is recommended for modifying residual operators when the shortcut is of interest.
👉 Paper link: https://huggingface.co/papers/2603.16039

35. OneWorld: Taming Scene Generation with 3D Unified Representation Autoencoder
🔑 Keywords: 3D scene generation, 3D Unified Representation Autoencoder, geometry-centric, Cross-View-Correspondence, Manifold-Drift Forcing
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enhance 3D scene generation by utilizing a unified 3D representation space to improve cross-view appearance and geometric consistency.
🛠️ Research Methods:
– The methodology includes the use of a 3D Unified Representation Autoencoder that integrates pretrained 3D models and introduces consistency losses like Cross-View-Correspondence (CVC) and Manifold-Drift Forcing (MDF).
💬 Research Conclusions:
– The study concludes that the proposed framework, OneWorld, outperforms existing 2D methods by generating high-quality 3D scenes with superior consistency across different views.
👉 Paper link: https://huggingface.co/papers/2603.16099

36. Learning Human-Object Interaction for 3D Human Pose Estimation from LiDAR Point Clouds
🔑 Keywords: Human-Object Interaction, 3D Human Pose Estimation, LiDAR Point Clouds, Spatial Ambiguity, Class Imbalance
💡 Category: Computer Vision
🌟 Research Objective:
– The main goal is to develop a Human-Object Interaction Learning framework (HOIL) to address challenges in 3D human pose estimation from LiDAR point clouds, specifically tackling spatial ambiguity and class imbalance issues.
🛠️ Research Methods:
– The paper utilizes contrastive learning and part-guided pooling techniques. It introduces human-object interaction-aware contrastive learning (HOICL) to enhance feature discrimination and a contact-aware part-guided pooling (CPPool) to manage class imbalance.
💬 Research Conclusions:
– The proposed HOIL framework effectively leverages human-object interactions to mitigate issues of spatial ambiguity and class imbalance in 3D human pose estimation, showing significant potential for application in autonomous driving scenarios.
👉 Paper link: https://huggingface.co/papers/2603.16343

37. Sparking Scientific Creativity via LLM-Driven Interdisciplinary Inspiration
🔑 Keywords: Idea-Catalyst, Interdisciplinary Insights, Creative Reasoning, Large Language Models, Metacognitive Features
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective of the Idea-Catalyst framework is to support interdisciplinary research by enhancing creative reasoning and systematically identifying insights across domains, while assisting the brainstorming phase without anchoring on specific solutions.
🛠️ Research Methods:
– The framework uses defining and assessing research goals, domain awareness, and strategic exploration to decompose abstract goals into target-domain questions, reformulating them into domain-agnostic problems for interdisciplinary retrieval.
💬 Research Conclusions:
– The Idea-Catalyst framework empirically improves novelty by 21% and insightfulness by 16%, by integrating insights from different domains back into the target domain, supporting enhanced problem-solving and creativity.
👉 Paper link: https://huggingface.co/papers/2603.12226

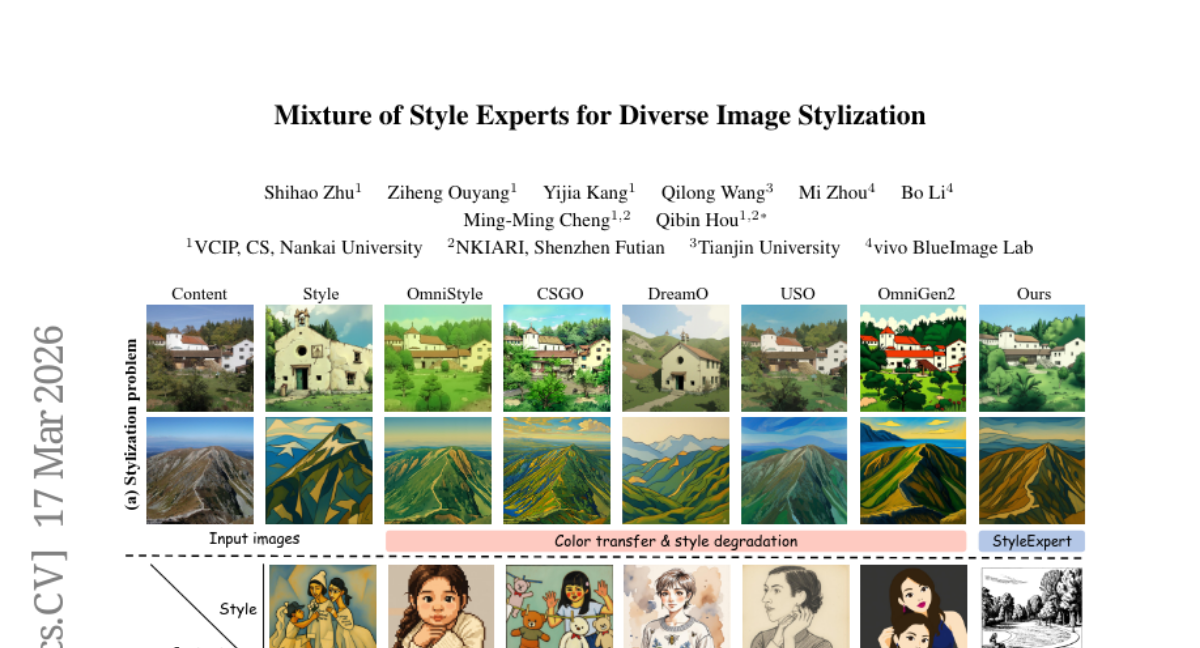
38. Mixture of Style Experts for Diverse Image Stylization
🔑 Keywords: Mixture of Experts, Style Encoder, Semantic-aware, Latent Space
💡 Category: Generative Models
🌟 Research Objective:
– Introduce StyleExpert, a semantic-aware framework for advanced image stylization preserving semantics and material details.
🛠️ Research Methods:
– Utilization of a Mixture of Experts architecture with a unified style encoder trained on a large-scale dataset to embed styles into a consistent latent space, employing a similarity-aware gating mechanism for dynamic routing.
💬 Research Conclusions:
– StyleExpert outperforms existing methods in handling diverse semantic levels while preserving details and generalizing to unseen styles; code and resources are publicly available for further exploration.
👉 Paper link: https://huggingface.co/papers/2603.16649
39. MolmoB0T: Large-Scale Simulation Enables Zero-Shot Manipulation
🔑 Keywords: zero-shot transfer, sim-to-real, vision-language models, procedural data generation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to demonstrate the feasibility of zero-shot sim-to-real transfer for robotic manipulation using large-scale synthetic data and vision-language models.
🛠️ Research Methods:
– Introduced MolmoBot-Engine, an open-source pipeline for procedural data generation across various robots and tasks.
– Released MolmoBot-Data, a dataset containing 1.8 million expert trajectories for articulated object manipulation and pick-and-place tasks.
– Trained three policy classes including MolmoBot, MolmoBot-Pi0, and MolmoBot-SPOC and evaluated their performance on two robotic platforms.
💬 Research Conclusions:
– Zero-shot transfer to the real world is feasible and effective for both static and mobile manipulation.
– A success rate of 79.2% was achieved in real-world tabletop pick-and-place tasks using the MolmoBot, confirming the robustness of the approach.
– The study challenges the prevailing view that real-world fine-tuning is necessary for effective sim-to-real transfer, proving that robust manipulation policies can be generated with procedural environment generation and diverse articulated assets.
👉 Paper link: https://huggingface.co/papers/2603.16861

40. FlashSampling: Fast and Memory-Efficient Exact Sampling
🔑 Keywords: FlashSampling, categorical sampling, language model head, matmul, Gumbel noise, tiled kernel
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce FlashSampling, a method to improve efficiency in categorical sampling by integrating it into the language model head matmul, reducing memory overhead and decoding time.
🛠️ Research Methods:
– FlashSampling integrates sampling into the LM-head matmul by computing logits tile-by-tile, incorporating Gumbel noise, and utilizing a fused tiled kernel for exact results.
💬 Research Conclusions:
– FlashSampling significantly speeds up decode workloads on various GPUs, reducing the time per output token by up to 19% in tested models, proving that exact sampling can be embedded directly into matmul, making the process more efficient.
👉 Paper link: https://huggingface.co/papers/2603.15854

41. SK-Adapter: Skeleton-Based Structural Control for Native 3D Generation
🔑 Keywords: SK-Adapter, 3D generation, skeletal manipulation, cross-attention, Objaverse-TMS dataset
💡 Category: Generative Models
🌟 Research Objective:
– Introduce SK-Adapter, a framework to enable precise 3D skeletal manipulation within native 3D generation models.
🛠️ Research Methods:
– Utilization of a lightweight adapter network that injects learnable tokens through cross-attention mechanisms and the introduction of the Objaverse-TMS dataset.
💬 Research Conclusions:
– SK-Adapter provides robust structural control while maintaining geometry and texture quality, outperforming existing baselines and enabling local 3D editing with skeletal guidance.
👉 Paper link: https://huggingface.co/papers/2603.14152

42. Reliable Reasoning in SVG-LLMs via Multi-Task Multi-Reward Reinforcement Learning
🔑 Keywords: CTRL-S, Chain-of-Thought, SVG Generation, Multi-Reward Optimization, Vision-Language Models
💡 Category: Generative Models
🌟 Research Objective:
– The work aims to enhance SVG generation by using a chain-of-thought reasoning and multi-reward optimization to achieve better structural coherence and visual fidelity.
🛠️ Research Methods:
– Introduced the CTRL-S framework, which uses a chain-of-thought mechanism to explicitly expose the model’s reasoning process.
– Constructed a high-quality dataset called SVG-Sophia for various SVG-related tasks.
– Implemented multi-reward optimization using the GRPO algorithm, incorporating various reward factors like image-text similarity and code efficiency.
💬 Research Conclusions:
– The CTRL-S framework significantly outperforms existing methods by improving task success rates, SVG code quality, and visual fidelity through systematic enhancements in generation capabilities.
👉 Paper link: https://huggingface.co/papers/2603.16189

43. One-Eval: An Agentic System for Automated and Traceable LLM Evaluation
🔑 Keywords: One-Eval, AI-generated summary, natural-language requests, benchmark planning, human-in-the-loop
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Presenting One-Eval, a system for automating the evaluation of large language models by converting natural-language requests into executable evaluation workflows.
🛠️ Research Methods:
– Integration of NL2Bench for intent structuring and personalized benchmark planning.
– Use of BenchResolve for automatic dataset acquisition and schema normalization.
– Implementation of human-in-the-loop checkpoints for review and debugging.
💬 Research Conclusions:
– One-Eval supports efficient and reproducible evaluation with minimal user effort, making it suitable for industrial applications.
– The system enhances evaluation by providing task-aware metrics and decision-oriented reporting, ensuring comprehensive outcome analysis.
👉 Paper link: https://huggingface.co/papers/2603.09821

44. SparkVSR: Interactive Video Super-Resolution via Sparse Keyframe Propagation
🔑 Keywords: SparkVSR, Video Super-Resolution, keyframe-conditioned, latent-pixel two-stage training, temporal consistency
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce an interactive VSR framework, SparkVSR, utilizing sparse keyframes as control signals to improve video super-resolution quality and user control.
🛠️ Research Methods:
– Implement a keyframe-conditioned latent-pixel two-stage training pipeline with motion-guided propagation, offering flexible keyframe selection and reference-free guidance.
💬 Research Conclusions:
– SparkVSR achieves enhanced temporal consistency and restoration quality, outperforming baselines by notable margins on various VSR benchmarks, with applications extending to tasks like old-film restoration and video style transfer.
👉 Paper link: https://huggingface.co/papers/2603.16864
45. SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
🔑 Keywords: Agent skills, LLM agents, software engineering, SWE-Skills-Bench, contextual compatibility
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate the utility of agent skills in software engineering tasks using the newly developed benchmark, SWE-Skills-Bench.
🛠️ Research Methods:
– Development of SWE-Skills-Bench to test 49 agent skills on software engineering tasks paired with real GitHub repositories and requirement documents.
– Use of a deterministic verification framework for task evaluation based on acceptance criteria.
💬 Research Conclusions:
– Agent skills provide limited benefits, with most showing no improvement and only a few showing meaningful gains in software engineering contexts.
– Skill utility strongly depends on domain fit, abstraction level, and contextual compatibility, with many skills yielding no pass-rate improvement.
👉 Paper link: https://huggingface.co/papers/2603.15401

46. AgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
🔑 Keywords: AgentProcessBench, tool-augmented agent interactions, step-level verification, human-labeled step annotations, reward models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The main objective is to introduce AgentProcessBench as a benchmark for assessing step-level effectiveness in tool-augmented agent interactions, addressing the limitations of current process-level benchmarks confined to closed-world mathematical domains.
🛠️ Research Methods:
– The benchmark consists of 1,000 diverse trajectories and 8,509 human-labeled step annotations with a ternary labeling scheme and an error propagation rule to improve process-level understanding and reduce labeling ambiguity.
💬 Research Conclusions:
– Key insights include the observation that weaker policy models show inflated correct step ratios due to early termination, identifying neutral and erroneous actions remains challenging, and process-derived signals improve test-time scaling. The study aims to encourage future research in reward models and contribute to the development of general AI agents.
👉 Paper link: https://huggingface.co/papers/2603.14465

47. MEMO: Memory-Augmented Model Context Optimization for Robust Multi-Turn Multi-Agent LLM Games
🔑 Keywords: Memory-augmented model, Multi-agent LLM, Context optimization, Self-play, Game performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the performance and stability of multi-agent large language model (LLM) games through a memory-augmented context optimization framework called MEMO.
🛠️ Research Methods:
– The paper introduces MEMO, which combines retention and exploration strategies for context optimization during inference. MEMO employs a memory bank to store insights from self-play trajectories and uses tournament-style prompt evolution with TrueSkill-based uncertainty-aware selection.
💬 Research Conclusions:
– MEMO significantly improves game performance, raising mean win rates from 25.1% to 49.5% for GPT-4o-mini and from 20.9% to 44.3% for Qwen-2.5-7B-Instruct across various text-based games, and also reduces run-to-run variance, offering more reliable rankings across different prompts.
👉 Paper link: https://huggingface.co/papers/2603.09022

48. Rethinking UMM Visual Generation: Masked Modeling for Efficient Image-Only Pre-training
🔑 Keywords: Unified Multimodal Models, Visual Generation Components, Image-Only Training, Two-Stage Training Framework, State-of-the-Art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop a data-efficient training framework for unified multimodal models to overcome the inefficiencies and data scarcity in current visual generation pre-training processes.
🛠️ Research Methods:
– Propose a two-stage training framework, where the first stage involves image-only pre-training using abundant unlabeled data, followed by the second stage that fine-tunes with mixed data types to enhance instruction alignment and generative quality.
💬 Research Conclusions:
– Image-Only Training framework achieves state-of-the-art performance with significant computational efficiency, outperforming baseline models in benchmarks such as GenEval and WISE.
👉 Paper link: https://huggingface.co/papers/2603.16139

49. FinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
🔑 Keywords: Large Language Models, Financial Domain, Agentic Interaction, FinToolBench, Trustworthy AI
💡 Category: AI in Finance
🌟 Research Objective:
– The research introduces FinToolBench, a benchmark designed specifically for evaluating financial tool learning agents within the financial domain.
🛠️ Research Methods:
– Establishes a realistic ecosystem integrating 760 executable financial tools with 295 rigorous queries beyond mere execution to assess agents on finance-critical dimensions such as timeliness and regulatory domain alignment.
💬 Research Conclusions:
– FinToolBench sets a new standard for trustworthy AI within finance by providing a first-of-its-kind auditable framework and open-source resources to support future research.
👉 Paper link: https://huggingface.co/papers/2603.08262

50. TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
🔑 Keywords: Text-to-SQL parsing, Unknown Schema, TRUST-SQL, Dual-Track GRPO, credit assignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address the challenge of Text-to-SQL parsing in real-world databases with noisy metadata, particularly under the Unknown Schema scenario.
🛠️ Research Methods:
– TRUST-SQL is proposed, utilizing a four-phase protocol and Dual-Track GRPO strategy, framed as a Partially Observable Markov Decision Process, to improve credit assignment and parsing efficiency.
💬 Research Conclusions:
– TRUST-SQL demonstrates significant performance improvements—9.9% over standard strategies and substantial gains across benchmarks—without relying on pre-loaded metadata, effectively surpassing strong schema-prefilling baselines.
👉 Paper link: https://huggingface.co/papers/2603.16448

51. Demystifing Video Reasoning
🔑 Keywords: Diffusion-based models, Chain-of-Steps, working memory, self-correction, Diffusion Transformers
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to understand and demonstrate the reasoning capabilities of diffusion-based video models, emphasizing the emergence of reasoning through denoising steps rather than conventional frame sequences.
🛠️ Research Methods:
– Qualitative analysis and targeted probing experiments were conducted to explore and validate the Chain-of-Steps mechanism. The research also tested a training-free strategy using ensembling latent trajectories from identical models with different random seeds.
💬 Research Conclusions:
– The findings reveal that reasoning in video models primarily emerges along the diffusion denoising steps. The research identifies key reasoning behaviors such as working memory, self-correction, and perception before action. Additionally, it highlights functional specialization within Diffusion Transformers, contributing to better reasoning performance.
👉 Paper link: https://huggingface.co/papers/2603.16870

52. Thinking in Uncertainty: Mitigating Hallucinations in MLRMs with Latent Entropy-Aware Decoding
🔑 Keywords: Latent Entropy-Aware Decoding, Multimodal Large Reasoning Models, Visual Question Answering, Hallucinations, Token Probability Distribution
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance multimodal large reasoning models by reducing hallucinations through entropy-aware reasoning mode switching and prior-guided visual anchor injection.
🛠️ Research Methods:
– Utilization of Latent Entropy-Aware Decoding (LEAD), leveraging semantic context via probability-weighted continuous embeddings and transitioning to discrete token embeddings as entropy decreases.
💬 Research Conclusions:
– LEAD successfully mitigates hallucinations in multimodal large reasoning models across multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2603.13366

53. MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
🔑 Keywords: MiroThinker-1.7, MiroThinker-H1, complex reasoning, verification, multi-step problem solving
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop research agents MiroThinker-1.7 and MiroThinker-H1 aimed at enhancing complex reasoning through structured planning, contextual reasoning, and tool interaction.
🛠️ Research Methods:
– Implementation of an agentic mid-training stage focusing on structured planning and verification of reasoning at local and global levels.
– Evaluation through benchmarks covering open-web research, scientific reasoning, and financial analysis.
💬 Research Conclusions:
– MiroThinker-H1 achieves state-of-the-art performance on deep research tasks while maintaining efficiency and reliability across specialized domains.
– Open-source release of MiroThinker-1.7 and MiroThinker-1.7-mini ensuring accessibility and competitive research-agent capabilities.
👉 Paper link: https://huggingface.co/papers/2603.15726
