AI Native Daily Paper Digest – 20260323

1. HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
🔑 Keywords: Vision-Language Models (VLMs), RLVR, HopChain, Multi-hop Reasoning, AI-Generated Summary
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to improve Vision-Language Models’ (VLMs) capacity for multi-hop vision-language reasoning to enhance long-chain reasoning abilities via the HopChain framework.
🛠️ Research Methods:
– Introduced HopChain, a scalable framework designed to generate multi-hop vision-language reasoning data specifically for RLVR training.
– Conducted comparative analysis against RLVR using original data across 24 benchmarks to evaluate improvements when incorporating HopChain-synthesized data.
💬 Research Conclusions:
– Adding multi-hop data from HopChain to existing training datasets notably improves performance on 20 out of 24 benchmarks, highlighting its broad applicability.
– The maintenance of full chained queries in training provides significant accuracy benefits over half or single-hop alternatives, supporting stronger long-CoT reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2603.17024

2. TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
🔑 Keywords: TerraScope, Geospatial Reasoning, Vision-language Models, Modality-flexible Reasoning, Multi-temporal Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce TerraScope, a vision-language model designed for enhanced pixel-grounded geospatial reasoning with flexible modality and multi-temporal capabilities.
🛠️ Research Methods:
– Developed Terra-CoT, a dataset with 1 million samples featuring pixel-level masks. Proposed a benchmark, TerraScope-Bench, for evaluating pixel-grounded geospatial reasoning through various sub-tasks.
💬 Research Conclusions:
– TerraScope outperforms existing vision-language models in pixel-grounded geospatial reasoning while offering interpretable visual evidence.
👉 Paper link: https://huggingface.co/papers/2603.19039

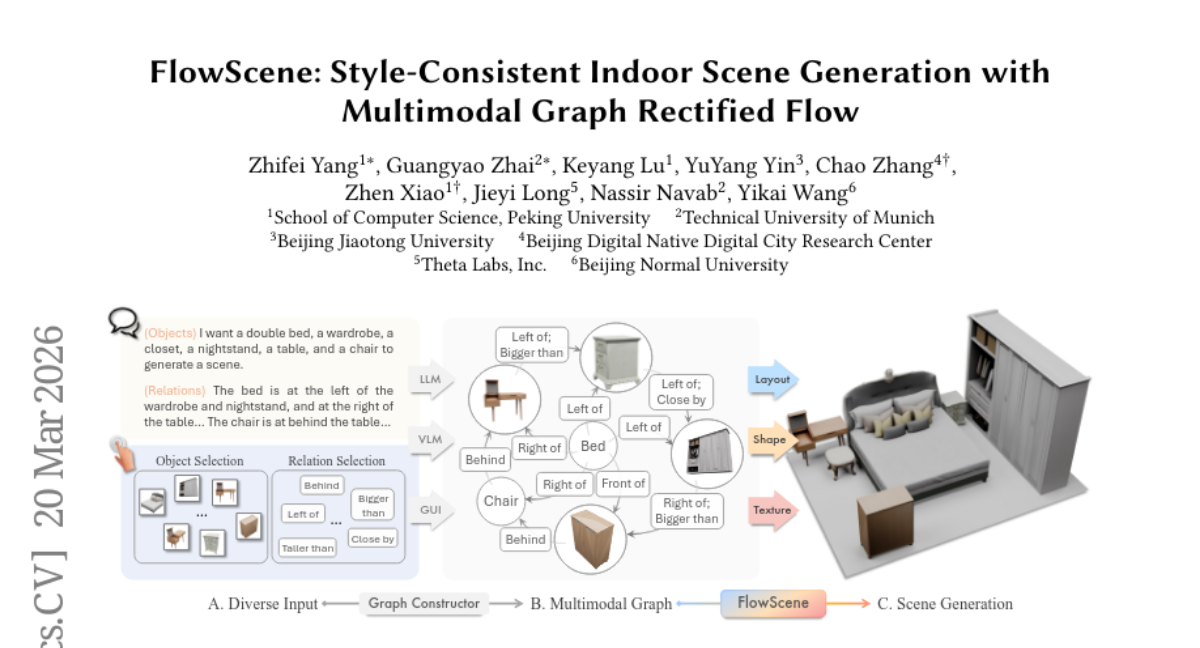
3. FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
🔑 Keywords: FlowScene, Scene Generation, Multimodal Graphs, Rectified Flow Model, Style Coherence
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces FlowScene, a tri-branch generative model aimed at producing realistic scenes with controlled geometry, appearance, and style coherence, addressing the limitations of current methods in object-level control and scene-level consistency.
🛠️ Research Methods:
– FlowScene utilizes a multimodal graph conditioning approach combined with a rectified flow model to collaboratively generate scene layouts, object shapes, and textures, ensuring fine-grained control and enforced scene-level style coherence.
💬 Research Conclusions:
– FlowScene outperforms existing language-conditioned and graph-conditioned methods by demonstrating increased realism, style consistency, and better alignment with human preferences in scene generation.
👉 Paper link: https://huggingface.co/papers/2603.19598
4. LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
🔑 Keywords: LumosX, text-to-video generation, face-attribute alignment, personalized content creation, Relational Attention
💡 Category: Generative Models
🌟 Research Objective:
– The primary aim is to enhance text-to-video generation by improving face-attribute alignment and subject consistency using the proposed LumosX framework.
🛠️ Research Methods:
– Utilizes tailored data collection pipelines and multimodal large language models to refine video-generation processes.
– Incorporates Relational Self-Attention and Relational Cross-Attention to ensure subject-attribute dependencies and intra-group consistency.
💬 Research Conclusions:
– LumosX achieves state-of-the-art performance in producing identity-consistent and semantically aligned videos across multiple subjects.
👉 Paper link: https://huggingface.co/papers/2603.20192

5. A Subgoal-driven Framework for Improving Long-Horizon LLM Agents
🔑 Keywords: LLM-based agents, Subgoal Decomposition, Milestone-based rewards, Reinforcement Learning, Web Navigation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the success rates of LLM-based agents in web navigation by addressing challenges in long-horizon planning and reinforcement learning fine-tuning.
🛠️ Research Methods:
– Introduction of an agent framework utilizing proprietary models for online planning with subgoal decomposition.
– Presentation of MiRA (Milestoning your Reinforcement Learning Enhanced Agent), an RL training framework employing dense, milestone-based reward signals.
💬 Research Conclusions:
– Enhanced proprietary models like Gemini with a 10% increase in success rate on the WebArena-Lite benchmark.
– Application of MiRA raises Gemma3-12B model’s success rate from 6.4% to 43.0%, surpassing proprietary systems like GPT-4-Turbo and previous state-of-the-art open models.
👉 Paper link: https://huggingface.co/papers/2603.19685

6. Versatile Editing of Video Content, Actions, and Dynamics without Training
🔑 Keywords: AI-generated, training-free editing, text-to-video models, complex edits, DynaEdit
💡 Category: Generative Models
🌟 Research Objective:
– The paper presents DynaEdit, a method designed to perform versatile video editing with pretrained text-to-video models without the need for additional training.
🛠️ Research Methods:
– DynaEdit utilizes a model-agnostic inversion-free approach that does not modify the internals of the flow models, allowing for flexible video editing.
💬 Research Conclusions:
– DynaEdit demonstrates superior results in complex text-based video editing tasks by overcoming low-frequency misalignment and high-frequency jitter issues, thereby performing actions like modifying actions and inserting objects effectively.
👉 Paper link: https://huggingface.co/papers/2603.17989
7. BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
🔑 Keywords: Training-free framework, Hierarchical selection, Discourse integrity, Inference latency, High-throughput applications
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve long-context LLM inference by reducing latency while maintaining semantic integrity through a training-free framework named BEAVER.
🛠️ Research Methods:
– Utilizes structure-aware hierarchical selection combined with dual-path pooling to map variable-length contexts into dense tensors.
– Employs a hybrid planning approach with semantic and lexical dual-branch selection alongside sentence smoothing.
💬 Research Conclusions:
– BEAVER achieves comparable performance to state-of-the-art methods while significantly reducing latency (by 26.4x on 128k contexts), offering a scalable solution for high-throughput applications. It maintains high fidelity in tasks like multi-needle retrieval.
👉 Paper link: https://huggingface.co/papers/2603.19635

8. WorldAgents: Can Foundation Image Models be Agents for 3D World Models?
🔑 Keywords: 3D reconstruction, Vision-Language Models, agentic framework, multi-agent architecture, 3D-consistent worlds
💡 Category: Generative Models
🌟 Research Objective:
– Explore whether 2D image models inherently possess capabilities for 3D world modeling.
🛠️ Research Methods:
– Systematic evaluation of state-of-the-art image generation models and Vision-Language Models.
– Introduction of an agentic framework utilizing a multi-agent architecture for 3D world generation.
💬 Research Conclusions:
– Demonstrated the ability of 2D models to encapsulate and synthesize realistic and expansive 3D worlds.
– Showcased a coherent and robust method for 3D reconstruction using an agentic approach.
👉 Paper link: https://huggingface.co/papers/2603.19708
9. EgoForge: Goal-Directed Egocentric World Simulator
🔑 Keywords: EgoForge, egocentric video, VideoDiffusionNFT, diffusion sampling, semantic alignment
💡 Category: Generative Models
🌟 Research Objective:
– Introduce EgoForge, an egocentric goal-directed world simulator generating coherent first-person video rollouts from minimal static inputs.
🛠️ Research Methods:
– Use of VideoDiffusionNFT for trajectory-level reward-guided refinement to optimize goal completion, temporal causality, scene consistency, and perceptual fidelity.
💬 Research Conclusions:
– EgoForge demonstrates consistent improvements in semantic alignment, geometric stability, and motion fidelity over existing methods, showing robust performance in real-world smart-glasses experiments.
👉 Paper link: https://huggingface.co/papers/2603.20169

10. Breaking the Capability Ceiling of LLM Post-Training by Reintroducing Markov States
🔑 Keywords: Reinforcement Learning, Large Language Models, Markov states, Reasoning capabilities, Open-ended discovery
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To overcome the “capability ceiling” in reinforcement learning for large language models by incorporating structured state representations.
🛠️ Research Methods:
– Theoretical and empirical analysis introducing Markov states into reinforcement learning post-training to improve reasoning capabilities and reduce sample complexity.
💬 Research Conclusions:
– Implementing Markov states breaks performance boundaries of standard RL post-training, allowing for significant improvements in complex logic puzzles and enabling genuinely new reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2603.19987

11. Teaching an Agent to Sketch One Part at a Time
🔑 Keywords: Vector Sketches, Multi-Modal Language Model, Process-Reward Reinforcement Learning, Supervised Fine-Tuning, ControlSketch-Part
💡 Category: Generative Models
🌟 Research Objective:
– To develop a method for incrementally generating vector sketches using a multi-modal language model-based agent.
🛠️ Research Methods:
– Utilization of a novel multi-turn process-reward reinforcement learning framework combined with supervised fine-tuning.
– Development of a new dataset, ControlSketch-Part, which includes rich part-level annotations for vector sketches using an automatic annotation pipeline.
💬 Research Conclusions:
– Incorporation of structured part-level data and visual feedback enhances interpretability, controllability, and local editability in text-to-vector sketch generation.
👉 Paper link: https://huggingface.co/papers/2603.19500

12. Cooperation and Exploitation in LLM Policy Synthesis for Sequential Social Dilemmas
🔑 Keywords: LLM policy synthesis, self-play, feedback engineering, social metrics, Sequential Social Dilemmas
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to investigate the use of large language models (LLMs) for synthesizing programmatic agent policies in multi-agent environments using iterative refinement in self-play scenarios.
🛠️ Research Methods:
– The researchers employed a framework where an LLM generates Python policy functions, which are then evaluated and refined based on performance feedback. The study compares dense feedback (including social metrics) against sparse reward-only feedback across different games and LLM versions.
💬 Research Conclusions:
– Dense feedback, which includes social metrics such as efficiency and equality, consistently outperforms sparse feedback in cooperative scenarios, particularly in the Cleanup game. Social metrics act as coordination signals guiding LLMs toward more effective strategies, such as territory partitioning and adaptive role assignment.
– Adversarial experiments reveal potential vulnerabilities in LLM policy synthesis, highlighting the balance between the expressiveness of policies and their safety.
👉 Paper link: https://huggingface.co/papers/2603.19453

13. DROID-SLAM in the Wild
🔑 Keywords: RGB SLAM, dynamic environments, Uncertainty-aware Bundle Adjustment, per-pixel uncertainty, real-time processing
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a robust, real-time RGB SLAM system capable of handling dynamic environments by leveraging Uncertainty-aware Bundle Adjustment.
🛠️ Research Methods:
– Utilization of differentiable uncertainty-aware bundle adjustment to estimate per-pixel uncertainty from multi-view visual features.
💬 Research Conclusions:
– The proposed system achieves state-of-the-art performance in dynamic and cluttered scenes with robust tracking and reconstruction, operating at around 10 FPS.
👉 Paper link: https://huggingface.co/papers/2603.19076
14. Adaptive Layerwise Perturbation: Unifying Off-Policy Corrections for LLM RL
🔑 Keywords: Adaptive Layerwise Perturbation, policy staleness, training-inference mismatch, importance ratios
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to tackle policy staleness and training-inference mismatch in large language model reinforcement learning by introducing a novel technique called Adaptive Layerwise Perturbation (ALP) to stabilize training and improve exploration.
🛠️ Research Methods:
– The method involves injecting small, learnable perturbations into hidden states across each layer during updates, which serves as part of the importance ratio calculation, to align the updated policy more closely with the inference policy and reduce the gap and sharpness in distribution.
💬 Research Conclusions:
– ALP effectively improves performance in both single-turn and multi-turn reasoning tasks, while mitigating the proliferation of importance ratio tails and KL divergences in iterative training cycles. Empirical evidence supports that perturbations across all layers yield superior outcomes compared to other variations.
👉 Paper link: https://huggingface.co/papers/2603.19470

15. From Masks to Pixels and Meaning: A New Taxonomy, Benchmark, and Metrics for VLM Image Tampering
🔑 Keywords: tampering detection, pixel-grounded, semantic understanding, localization, evaluation framework
💡 Category: Computer Vision
🌟 Research Objective:
– Reformulate vision-language model tampering detection from object masks to pixel-level analysis with semantic understanding.
– Establish a rigorous standard for tamper localization, semantic classification, and description.
🛠️ Research Methods:
– Introduce a taxonomy for edit primitives and their semantic class of tampered objects.
– Develop a new benchmark with per-pixel tamper maps and paired category supervision.
– Propose training framework and evaluation metrics quantifying pixel-level correctness and semantic comprehension.
💬 Research Conclusions:
– The research advances the field by focusing on pixels, meanings, and language descriptions, rather than coarse region labels.
– Existing segmentation/localization baselines are re-evaluated to reveal over- and under-scoring and failure modes.
– The framework improves assessment of tamper detection by linking low-level changes to high-level understanding.
👉 Paper link: https://huggingface.co/papers/2603.20193

16. CurveStream: Boosting Streaming Video Understanding in MLLMs via Curvature-Aware Hierarchical Visual Memory Management
🔑 Keywords: CurveStream, streaming video perception, semantic transitions, memory management, curvature-aware
💡 Category: Computer Vision
🌟 Research Objective:
– To improve streaming video perception by dynamically routing frames based on semantic intensity and geometric features, addressing the limitations of current visual retention and memory management methods.
🛠️ Research Methods:
– Developing CurveStream, a training-free, curvature-aware hierarchical visual memory management framework. This framework employs a Curvature Score and an online K-Sigma dynamic threshold to manage memory under a token budget.
💬 Research Conclusions:
– CurveStream consistently enhances performance by over 10% on platforms like StreamingBench and OVOBench, establishing new benchmarks in streaming video perception.
👉 Paper link: https://huggingface.co/papers/2603.19571

17. ReLMXEL: Adaptive RL-Based Memory Controller with Explainable Energy and Latency Optimization
🔑 Keywords: Reinforcement Learning, Memory Systems, Explainability, Latency Optimization, Energy Consumption
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve efficiency in modern computing by reducing latency and energy consumption in memory systems.
🛠️ Research Methods:
– Introduces ReLMXEL, a multi-agent online reinforcement learning framework, which optimizes memory controller parameters through reward decomposition and explainable decision-making.
💬 Research Conclusions:
– Demonstrates consistent performance gains across diverse workloads, enhances transparency and accountability in memory system design by incorporating explainability into the learning process.
👉 Paper link: https://huggingface.co/papers/2603.17309

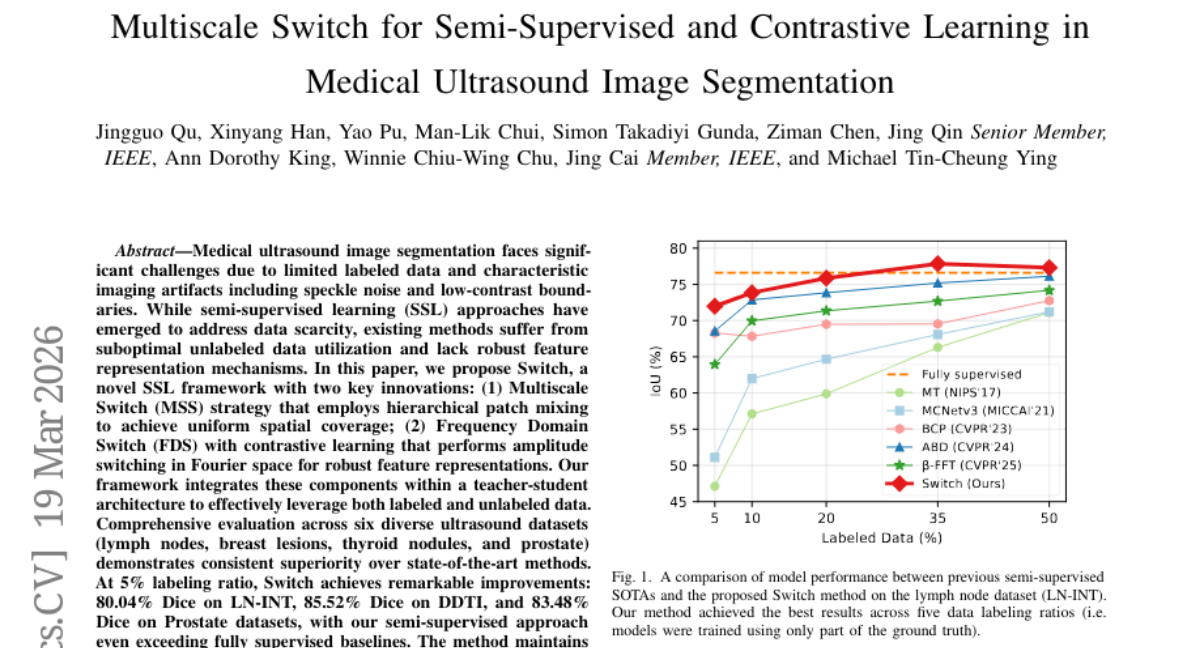
18. Multiscale Switch for Semi-Supervised and Contrastive Learning in Medical Ultrasound Image Segmentation
🔑 Keywords: Semi-supervised learning, Medical ultrasound segmentation, Multiscale patch mixing, Frequency domain contrastive learning, Teacher-student architecture
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop a novel semi-supervised learning framework called “Switch” for improving medical ultrasound image segmentation with limited labeled data.
🛠️ Research Methods:
– Utilization of Multiscale Switch (MSS) strategy for hierarchical patch mixing and Frequency Domain Switch (FDS) for amplitude switching in Fourier space, integrated within a teacher-student architecture.
💬 Research Conclusions:
– The proposed framework demonstrates superior performance across six diverse ultrasound datasets, achieving notable improvements in Dice scores compared to state-of-the-art methods, even with a 5% labeling ratio and maintaining parameter efficiency.
👉 Paper link: https://huggingface.co/papers/2603.18655
19. s2n-bignum-bench: A practical benchmark for evaluating low-level code reasoning of LLMs
🔑 Keywords: Large Language Models (LLMs), formal verification, cryptographic assembly routines, HOL Light, proof synthesis
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address the gap between competition mathematics and real-world implementation verification by evaluating large language models on formal proof synthesis for industrial cryptographic assembly routines verified in HOL Light.
🛠️ Research Methods:
– Developing a new benchmark, s2n-bignum-bench, which provides formal specifications and requires LLMs to generate proof scripts accepted by HOL Light within a fixed proof-check timeout.
💬 Research Conclusions:
– s2n-bignum-bench is the first public benchmark focused on machine-checkable proof synthesis for industrial cryptographic assembly routines, offering a challenging and practically relevant testbed for evaluating LLM-based theorem proving beyond competition mathematics.
👉 Paper link: https://huggingface.co/papers/2603.14628

20.

21. Human-AI Synergy in Agentic Code Review
🔑 Keywords: AI agents, Human reviewers, Code review, Collaboration, Code quality
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The study aims to compare the effectiveness and feedback differences between AI agents and human reviewers in code review processes on GitHub.
🛠️ Research Methods:
– Conducted a large-scale empirical analysis of 278,790 code review conversations across 300 open-source GitHub projects to investigate human-AI collaboration patterns and adoption of code suggestions.
💬 Research Conclusions:
– Human reviewers provide more comprehensive feedback, especially in understanding, testing, and knowledge transfer than AI agents.
– Code suggestions made by AI agents are adopted at a lower rate and often result in increased code complexity and size when adopted, highlighting the importance of human oversight in ensuring the quality of code suggestions.
👉 Paper link: https://huggingface.co/papers/2603.15911

22. TAPESTRY: From Geometry to Appearance via Consistent Turntable Videos
🔑 Keywords: 360-degree turntable videos, neural rendering, video diffusion models, 3D-Aware Inpainting, UV textures
💡 Category: Generative Models
🌟 Research Objective:
– To generate high-fidelity 360-degree turntable videos conditioned on explicit 3D geometry, enabling consistent texture synthesis and neural rendering for creating complete 3D assets.
🛠️ Research Methods:
– Introducing TAPESTRY, a framework that reframes the 3D appearance generation as a geometry-conditioned video diffusion problem, utilizing multi-modal geometric features and a multi-stage pipeline with 3D-Aware Inpainting for downstream reconstruction tasks.
💬 Research Conclusions:
– TAPESTRY surpasses existing methods in video consistency and final reconstruction quality, allowing for the automated creation of production-ready, complete 3D assets from untextured meshes.
👉 Paper link: https://huggingface.co/papers/2603.17735

23. Automatic detection of Gen-AI texts: A comparative framework of neural models
🔑 Keywords: Large Language Models, AI-generated text detection, Multilayer Perceptron, Transformer model, supervised detectors
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the effectiveness of machine learning-based detectors in identifying AI-generated text across multiple languages and domains.
🛠️ Research Methods:
– Implementation and comparative evaluation of four neural architectures: Multilayer Perceptron, Convolutional Neural Network, MobileNet-based CNN, and Transformer model.
– Benchmarking against commercial online detectors like ZeroGPT and GPTZero using datasets focused on different languages and themes.
💬 Research Conclusions:
– Supervised machine learning detectors demonstrated more stable and robust performance compared to commercial tools, emphasizing strengths and limitations in current AI-generated text detection methods.
👉 Paper link: https://huggingface.co/papers/2603.18750

24. ReLi3D: Relightable Multi-view 3D Reconstruction with Disentangled Illumination
🔑 Keywords: ReLi3D, multi-view constraints, transformer cross-conditioning architecture, unified two-path prediction strategy, differentiable Monte Carlo multiple importance sampling renderer
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce ReLi3D, a unified end-to-end pipeline for simultaneous 3D geometry, material, and illumination reconstruction from multi-view images.
🛠️ Research Methods:
– Employ a transformer cross-conditioning architecture with a unified two-path prediction strategy to enhance material and illumination disentanglement using multi-view constraints.
– Utilize a differentiable Monte Carlo multiple importance sampling renderer and a mixed domain training protocol using synthetic PBR datasets and real-world RGB captures.
💬 Research Conclusions:
– Achieve near-instantaneous generation of complete, relightable 3D assets by unifying separate reconstruction tasks into a single feed-forward pass, improving geometry, material accuracy, and illumination quality.
👉 Paper link: https://huggingface.co/papers/2603.19753

25. Probing Cultural Signals in Large Language Models through Author Profiling
🔑 Keywords: Large language models, Cultural biases, Author profiling, Fairness metrics, Zero-shot setting
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To evaluate the cultural biases of large language models (LLMs) by utilizing them for author profiling from song lyrics in a zero-shot setting.
🛠️ Research Methods:
– Conducted experiments using several open-source LLMs on more than 10,000 song lyrics to infer singers’ gender and ethnicity, and introduced Modality Accuracy Divergence (MAD) and Recall Divergence (RD) as fairness metrics.
💬 Research Conclusions:
– LLMs show non-trivial profiling capabilities with cultural alignment, where models like DeepSeek-1.5B are more aligned with Asian ethnicity, and Ministral-8B exhibits the strongest ethnic bias. Gemma-12B emerges as the most balanced model in terms of fairness.
👉 Paper link: https://huggingface.co/papers/2603.16749

26. Language on Demand, Knowledge at Core: Composing LLMs with Encoder-Decoder Translation Models for Extensible Multilinguality
🔑 Keywords: XBridge, Large Language Models, multilingual performance, encoder-decoder translation models, cross-model mapping layers
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study introduces XBridge, a compositional architecture to enhance multilingual capabilities of large language models by integrating pretrained translation models.
🛠️ Research Methods:
– The method employs lightweight cross-model mapping layers and an optimal transport-based alignment objective to address representation misalignment between models.
💬 Research Conclusions:
– XBridge outperforms existing baselines in multilingual understanding and generation, particularly excelling in low-resource or unseen languages without requiring retraining of the LLM.
👉 Paper link: https://huggingface.co/papers/2603.17512

27. Do VLMs Need Vision Transformers? Evaluating State Space Models as Vision Encoders
🔑 Keywords: Vision-Language Models, State Space Models, Vision Backbones, Stabilization Strategies, Transformer-based Architectures
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate the performance of State Space Models (SSMs) as vision backbones for Vision-Language Models (VLMs) compared to Transformer-based architectures.
🛠️ Research Methods:
– Systematic evaluation of SSM vision backbones for VLMs in a controlled setting, including comparisons under ImageNet-1K initialization and adaptation with detection or segmentation training.
💬 Research Conclusions:
– SSM backbones achieve strong performance in VQA and localization tasks, remaining competitive at smaller scales. Stabilization strategies are proposed to improve robustness, highlighting SSM as a viable alternative to transformers for VLMs.
👉 Paper link: https://huggingface.co/papers/2603.19209

28. AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
🔑 Keywords: AI agents, human-AI collaboration, large language models, domain-specific data science, AgentDS
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate AI agents and human-AI collaboration in domain-specific data science tasks through the AgentDS benchmark and competition.
🛠️ Research Methods:
– Conducting an open competition involving 29 teams and 80 participants across 17 challenges in six industries to systematically compare human-AI collaborative approaches with AI-only baselines.
💬 Research Conclusions:
– Current AI agents underperform in domain-specific reasoning and struggle to match human experts, particularly in data science. The strongest performances emerge from human-AI collaboration, emphasizing the ongoing necessity of human expertise despite advancements in AI technologies.
👉 Paper link: https://huggingface.co/papers/2603.19005

29. Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD
🔑 Keywords: D-MMD, Discrete Moment Matching Distillation, Discrete Diffusion Models, Continuous Diffusion, Sampling Steps
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a new distillation method called Discrete Moment Matching Distillation (D-MMD) for effective distillation of discrete diffusion models.
🛠️ Research Methods:
– D-MMD leverages successful continuous-domain techniques to maintain high quality and diversity in distillation, outperforming previous discrete methods.
💬 Research Conclusions:
– D-MMD maintains performance quality and diversity with sufficient sampling steps and shows superior performance on text and image datasets compared to previous methods.
– The newly distilled generators can surpass their original models, demonstrating enhanced performance capabilities.
👉 Paper link: https://huggingface.co/papers/2603.20155

30. LoopRPT: Reinforcement Pre-Training for Looped Language Models
🔑 Keywords: LoopRPT, Looped language models, Reinforcement learning, Next-token reasoning, Latent reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This paper introduces LoopRPT, a reinforcement pre-training framework designed to enhance latent reasoning in looped language models (LoopLMs) by reshaping intermediate representations through next-token reasoning tasks.
🛠️ Research Methods:
– LoopRPT reframes next-token prediction as a next-token reasoning task, assigning reinforcement signals directly to latent steps utilizing an EMA teacher reference and noisy latent rollouts.
– The framework is implemented on the Ouro architecture across various model scales to test its effectiveness.
💬 Research Conclusions:
– LoopRPT shows consistent improvement in per-step representation quality, achieving Pareto dominance in accuracy-computation trade-offs, especially enhancing early-stage reasoning on difficult tokens.
– The study emphasizes reinforcement pre-training as an efficient approach for learning effective latent reasoning in LoopLMs.
👉 Paper link: https://huggingface.co/papers/2603.19714

31. HiMu: Hierarchical Multimodal Frame Selection for Long Video Question Answering
🔑 Keywords: AI-generated summary, Long-form video question answering, Training-free, hierarchical logic tree, vision-language models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop HiMu, a training-free framework to improve efficiency and accuracy in long-form video question answering by selecting relevant frames while maintaining temporal and cross-modal integrity.
🛠️ Research Methods:
– Utilizes a hierarchical logic tree and lightweight experts encompassing vision (including CLIP, open-vocabulary detection, OCR) and audio (ASR, CLAP) to process and align different modalities, forming a continuous satisfaction curve.
💬 Research Conclusions:
– HiMu enhances the efficiency-accuracy Pareto front, surpassing existing methods in performance with significantly fewer computational resources.
👉 Paper link: https://huggingface.co/papers/2603.18558

32. How Well Does Generative Recommendation Generalize?
🔑 Keywords: Generative recommendation, Item ID-based models, Generalization, Memorization, Recommendation performance
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to investigate the observed superiority of Generative recommendation models in generalization tasks compared to item ID-based models, which excel in memorization tasks.
🛠️ Research Methods:
– The researchers categorize data instances based on whether they require memorization or generalization for accurate predictions, performing extensive experiments to evaluate performance across these dimensions.
💬 Research Conclusions:
– Generative recommendation models are more effective for instances necessitating generalization, whereas item ID-based models excel when memorization is crucial. The study finds that a combination of both approaches through a memorization-aware indicator enhances overall recommendation performance.
👉 Paper link: https://huggingface.co/papers/2603.19809

33. Deep Tabular Research via Continual Experience-Driven Execution
🔑 Keywords: agentic framework, Deep Tabular Research, multi-step reasoning, hierarchical meta graph, siamese structured memory
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address the challenges of complex long-horizon analytical tasks over unstructured tables that involve hierarchical and bidirectional headers and non-canonical layouts through the formalization of Deep Tabular Research (DTR).
🛠️ Research Methods:
– The introduction of a novel agentic framework that includes hierarchical meta-graph construction, expectation-aware path selection, and siamese structured memory for iterative refinement.
💬 Research Conclusions:
– The proposed framework demonstrates the effectiveness and necessity of separating strategic planning from low-level execution for effective long-horizon tabular reasoning, as validated by extensive experiments on challenging unstructured tabular benchmarks.
👉 Paper link: https://huggingface.co/papers/2603.09151

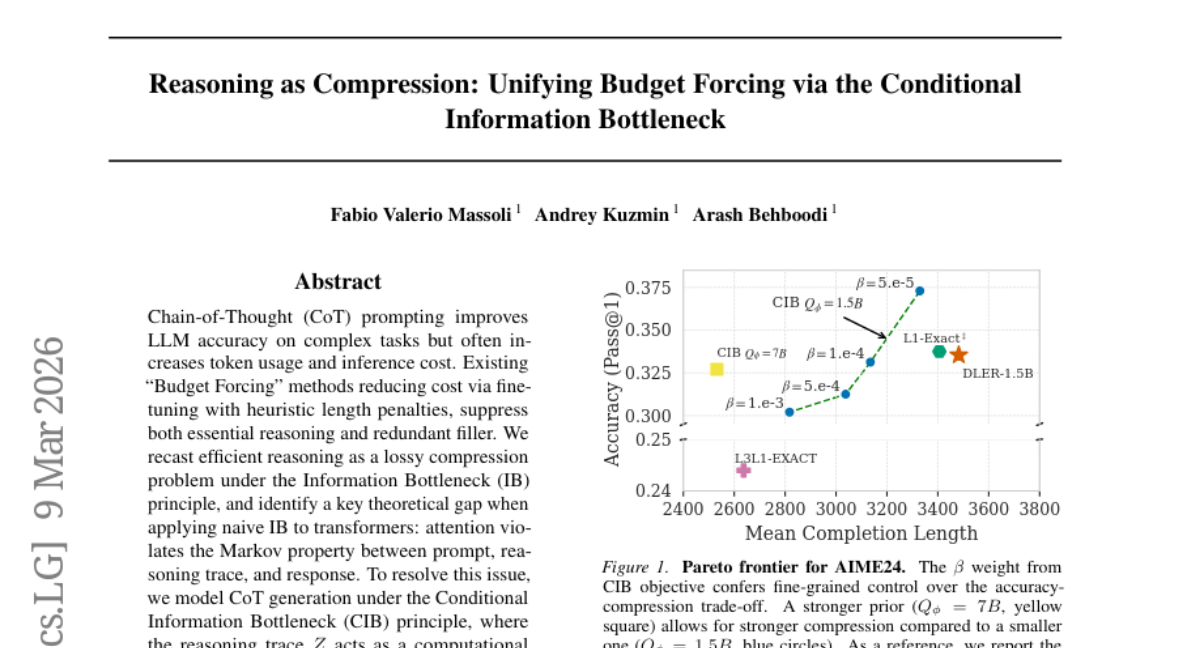
34. Reasoning as Compression: Unifying Budget Forcing via the Conditional Information Bottleneck
🔑 Keywords: Chain-of-Thought, Conditional Information Bottleneck, Reinforcement Learning, lossy compression, cognitive bloat
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to reformulate efficient reasoning in language models as a lossy compression problem using the Conditional Information Bottleneck (CIB) to reduce cognitive overhead while maintaining model performance.
🛠️ Research Methods:
– The study models Chain-of-Thought (CoT) generation under the CIB principle, with the reasoning trace acting as a computational bridge to optimize task reward and compress completions based on a semantic prior that measures token cost by surprisal.
💬 Research Conclusions:
– The empirical results show that the CIB approach prunes cognitive bloat, maintains fluency and logic, and improves model accuracy at moderate compression, enabling more aggressive compression with minimal accuracy drop.
👉 Paper link: https://huggingface.co/papers/2603.08462
35. Hyperagents
🔑 Keywords: Hyperagents, Self-improving AI systems, Meta-agent, Metacognitive self-modification, Open-ended AI systems
💡 Category: Foundations of AI
🌟 Research Objective:
– The study introduces Hyperagents, a novel framework that integrates task and meta-agents into a single program, aiming for continual metacognitive self-modification and improvement across various computational domains.
🛠️ Research Methods:
– The authors extend the Darwin Gödel Machine (DGM) by creating DGM-Hyperagents, eliminating the need for domain-specific alignment between task performance and self-modification ability, allowing for self-accelerating progress on any computable task.
💬 Research Conclusions:
– DGM-Hyperagents demonstrate superior performance over time compared to baselines without self-improvement and surpass previous self-improving systems, showing potential for open-ended AI systems that not only find better solutions but also enhance their methods for improving.
👉 Paper link: https://huggingface.co/papers/2603.19461

36. The Y-Combinator for LLMs: Solving Long-Context Rot with λ-Calculus
🔑 Keywords: λ-calculus, long-context reasoning, Recursive Language Models, neural inference, functional runtime
💡 Category: Foundations of AI
🌟 Research Objective:
– The study aims to address the bottleneck of fixed context windows in general-purpose reasoners by introducing λ-RLM, which replaces free-form recursive code generation with a typed functional runtime based on λ-calculus, providing formal guarantees for long-context reasoning tasks.
🛠️ Research Methods:
– The λ-RLM framework employs a typed functional runtime grounded in λ-calculus to execute pre-verified combinators, using neural inference only on bounded leaf subproblems, hence structuring recursive reasoning into a functional program with explicit control flow.
💬 Research Conclusions:
– λ-RLM demonstrates improved performance over standard Recursive Language Models in long-context reasoning tasks, with up to a 21.9-point accuracy increase and a 4.1x reduction in latency, illustrating a more reliable and efficient foundation than open-ended recursive code generation. The complete implementation is available as an open-source resource for the community.
👉 Paper link: https://huggingface.co/papers/2603.20105

37. ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
🔑 Keywords: ProactiveBench, Proactiveness, Reinforcement Learning, Fine-tuning, Multi-Modal Learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to assess the capability of MLLMs to demonstrate proactive behavior by introducing and utilizing ProactiveBench.
🛠️ Research Methods:
– Evaluated 22 MLLMs on ProactiveBench, a benchmark created from seven datasets testing tasks like recognizing occluded objects, image enhancement, and sketch interpretation.
💬 Research Conclusions:
– MLLMs generally lack proactiveness and this trait is not linked to model capacity.
– The conversational context and in-context learning biases negatively influence performance.
– A simple reinforcement learning-based fine-tuning strategy shows potential in teaching proactiveness and generalizing to new scenarios.
👉 Paper link: https://huggingface.co/papers/2603.19466

38. Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
🔑 Keywords: Astrolabe, Distilled Autoregressive, Reinforcement Learning, Streaming Training, Multi-reward Objective
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The main objective is to enhance the generation quality of distilled autoregressive video models using an efficient online reinforcement learning framework.
🛠️ Research Methods:
– Introduced a forward-process RL formulation based on negative-aware fine-tuning.
– Proposed a streaming training scheme using a rolling KV-cache to maintain long-range coherence and reduce computational overhead.
💬 Research Conclusions:
– The method enhances generation quality for various distilled AR video models by providing a scalable and robust alignment solution.
– The integration of multi-reward objectives stabilized by uncertainty-aware selective regularization effectively mitigates reward hacking.
👉 Paper link: https://huggingface.co/papers/2603.17051