AI Native Daily Paper Digest – 20260403

1. DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
🔑 Keywords: Data-centric training, Large language models, Sample selection, Domain mixture adjustment, Sample reweighting
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research objective is to introduce DataFlex, a unified framework aimed at enhancing the dynamic data-centric training of large language models (LLMs).
🛠️ Research Methods:
– DataFlex integrates important paradigms such as sample selection, domain mixture adjustment, and sample reweighting while maintaining compatibility with existing LLM training workflows. It leverages extensible trainer abstractions and modular components.
💬 Research Conclusions:
– DataFlex significantly outperforms traditional static full-data training, improving accuracy and efficiency in LLMs. It ensures consistent improvements in runtime and experimental accuracy across various data-centric methods, demonstrating its effectiveness and efficiency.
👉 Paper link: https://huggingface.co/papers/2603.26164

2. Generative World Renderer
🔑 Keywords: AAA games, generative inverse rendering, forward rendering, G-buffer, VLM-based evaluation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a large-scale dynamic dataset from AAA games to improve generative inverse and forward rendering techniques.
🛠️ Research Methods:
– Gathered 4 million continuous frames using a dual-screen stitched capture method, providing high-resolution synchronized RGB and G-buffer data.
– Developed a novel VLM-based assessment protocol to evaluate inverse rendering performance without ground truth by measuring semantic, spatial, and temporal consistency.
💬 Research Conclusions:
– Inverse rendering models fine-tuned on the new dataset show improved cross-dataset generalization and controllable generation.
– The VLM-based evaluation method correlates strongly with human judgment and facilitates high-fidelity video generation from G-buffers, enabling style editing of AAA games through text prompts.
👉 Paper link: https://huggingface.co/papers/2604.02329

3. EgoSim: Egocentric World Simulator for Embodied Interaction Generation
🔑 Keywords: EgoSim, egocentric simulation, 3D scene, spatial consistency, Interaction-aware State Updating
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces EgoSim, an egocentric simulator that addresses the limitations of existing systems by enabling spatially consistent interaction videos and continuous 3D scene updates.
🛠️ Research Methods:
– Utilization of a Geometry-action-aware Observation Simulation model for generating embodiment interactions and an Interaction-aware State Updating module for maintaining spatial consistency.
– Developed a scalable pipeline for extracting data from large monocular egocentric videos and introduced EgoCap for cost-effective data collection.
💬 Research Conclusions:
– EgoSim significantly outperforms existing methods in visual quality, spatial consistency, and generalization to complex scenes, also supporting cross-embodiment transfer to robotic manipulation.
👉 Paper link: https://huggingface.co/papers/2604.01001

4. LatentUM: Unleashing the Potential of Interleaved Cross-Modal Reasoning via a Latent-Space Unified Model
🔑 Keywords: LatentUM, Unified Models, Cross-Modal Reasoning, Semantic Latent Space, Visual Generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to introduce LatentUM, a novel unified model that facilitates interleaved cross-modal reasoning and generation without pixel-space mediation by utilizing a shared semantic latent space.
🛠️ Research Methods:
– The research involves developing a unified model that eliminates the need for pixel decoding and employs shared semantic latent space representation for cross-modal tasks.
💬 Research Conclusions:
– LatentUM enhances computational efficiency and aligns cross-modal operations more effectively, achieving state-of-the-art performance in Visual Spatial Planning and improving visual generation through self-reflection.
👉 Paper link: https://huggingface.co/papers/2604.02097

5. Omni-SimpleMem: Autoresearch-Guided Discovery of Lifelong Multimodal Agent Memory
🔑 Keywords: Omni-SimpleMem, Lifelong AI Agents, Autonomous Research Pipeline, Multimodal Memory, Prompt Engineering
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance lifelong AI agent performance by discovering Omni-SimpleMem, a unified multimodal memory framework.
🛠️ Research Methods:
– Utilization of an autonomous research pipeline was employed to execute multiple experiments, diagnosing failure modes, and implementing necessary architectural modifications and bug fixes.
💬 Research Conclusions:
– The new system showed remarkable improvements in performance across benchmarks, with an emphasis on non-hyperparameter changes such as bug fixes, architectural changes, and prompt engineering contributing significantly to these advancements.
👉 Paper link: https://huggingface.co/papers/2604.01007

6. Therefore I am. I Think
🔑 Keywords: AI Native, chain-of-thought, linear probe, activation steering, behavioral analysis
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To determine whether reasoning models make decisions before or after beginning textual deliberation in the decision process.
🛠️ Research Methods:
– Applied a simple linear probe to decode tool-calling decisions from pre-generation activations.
– Utilized activation steering to analyze the causal effects on deliberation and behavior changes.
💬 Research Conclusions:
– Found that reasoning models likely encode decisions early and these decisions influence the chain-of-thought process.
– Behavioral analysis indicates that the chain-of-thought often rationalizes changes in decisions rather than opposing them.
👉 Paper link: https://huggingface.co/papers/2604.01202

7. CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
🔑 Keywords: multi-agent evolution, persistent memory, open-ended discovery, AI-generated summary, knowledge reuse
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective of the research is to establish an autonomous multi-agent evolution framework named CORAL, aimed at enhancing open-ended discovery through improved agent autonomy and performance in various tasks.
🛠️ Research Methods:
– Incorporation of shared persistent memory, asynchronous execution, and heartbeat-based interventions to replace fixed heuristics, facilitating the autonomous operation of LLM agents.
💬 Research Conclusions:
– CORAL achieved state-of-the-art results in mathematical, algorithmic, and system optimization tasks, demonstrating significant performance improvements with fewer evaluations compared to traditional methods. This success is attributed to effective knowledge reuse and multi-agent exploration, showcasing the efficacy of enhanced autonomy in AI systems.
👉 Paper link: https://huggingface.co/papers/2604.01658

8. Investigating Autonomous Agent Contributions in the Wild: Activity Patterns and Code Change over Time
🔑 Keywords: AI-driven contributions, open-source projects, code quality, Autonomous coding agents, code churn
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study investigates the impact of AI-driven contributions on open-source projects, focusing on code quality, team dynamics, and software maintainability.
🛠️ Research Methods:
– A dataset of approximately 110,000 open-source pull requests was constructed, including associated commits, comments, reviews, issues, and file changes. The usage of five popular coding agents was compared across various development aspects.
💬 Research Conclusions:
– The findings indicate an increasing contribution of Autonomous coding agents in open-source projects, albeit associated with higher code churn over time compared to human-authored code.
👉 Paper link: https://huggingface.co/papers/2604.00917

9. Tex3D: Objects as Attack Surfaces via Adversarial 3D Textures for Vision-Language-Action Models
🔑 Keywords: Vision-language-action models, Adversarial attacks, 3D textures, Differentiable optimization, Tex3D
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to explore the vulnerabilities of Vision-language-action models to physically realizable 3D adversarial textures in robotic manipulation tasks.
🛠️ Research Methods:
– Introduction of Foreground-Background Decoupling (FBD) to enable differentiable texture optimization.
– Implementation of Trajectory-Aware Adversarial Optimization (TAAO) to maintain attack effectiveness over varying viewpoints and long timelines.
– Development of Tex3D framework for end-to-end optimization of 3D adversarial textures within the VLA simulation environment.
💬 Research Conclusions:
– Tex3D demonstrates significant degradation of VLA performance, with task failure rates up to 96.7%.
– Findings reveal critical vulnerabilities in VLA systems to realistic 3D adversarial attacks, emphasizing the urgency for incorporating robustness-aware training in these systems.
👉 Paper link: https://huggingface.co/papers/2604.01618

10. AIBench: Evaluating Visual-Logical Consistency in Academic Illustration Generation
🔑 Keywords: AIBench, VQA, VLM, logic correctness, aesthetics
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary goal is to evaluate the quality of AI-generated academic illustrations, particularly focusing on logic correctness and aesthetics.
🛠️ Research Methods:
– The study employs AIBench, a benchmark utilizing VQA for evaluating logic correctness and VLMs for assessing aesthetics. Four levels of questions are designed to check alignment with the paper’s method.
💬 Research Conclusions:
– There is a significant performance gap between models on generating academic illustrations, and optimizing both logic and aesthetics simultaneously is challenging. Test-time scaling improves performance in this task.
👉 Paper link: https://huggingface.co/papers/2603.28068

11. AutoMIA: Improved Baselines for Membership Inference Attack via Agentic Self-Exploration
🔑 Keywords: AutoMIA, Membership Inference Attacks, logits-level strategies, closed-loop evaluation, model-agnostic
💡 Category: Machine Learning
🌟 Research Objective:
– The primary objective is to automate membership inference attacks using AutoMIA, which involves dynamically generating and refining attack strategies through self-exploration and closed-loop evaluation.
🛠️ Research Methods:
– Utilizes a framework that decouples strategy reasoning from execution, enabling a model-agnostic approach to explore the attack search space and develop executable logits-level strategies.
💬 Research Conclusions:
– AutoMIA consistently performs on par with or surpasses current state-of-the-art methods, also eliminating the need for manual feature engineering by utilizing an automated, systematic process.
👉 Paper link: https://huggingface.co/papers/2604.01014

12. Forecasting Supply Chain Disruptions with Foresight Learning
🔑 Keywords: Large Language Models, Supply Chain Disruptions, Probabilistic Forecasts, Calibration, Decision-Ready Signals
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to develop an end-to-end framework using **Large Language Models** to produce **calibrated probabilistic forecasts** for **supply chain disruptions**, surpassing existing baselines in decision-making efficacy.
🛠️ Research Methods:
– An end-to-end framework trains LLMs using realized disruption outcomes to enhance accuracy, calibration, and precision in predicting rare, high-impact events.
💬 Research Conclusions:
– The model significantly outperforms strong baselines such as GPT-5 and shows that **probabilistic reasoning** improves without explicit prompting, supporting transparent decision-making. The evaluation dataset is made publicly available for further research.
👉 Paper link: https://huggingface.co/papers/2604.01298

13. T5Gemma-TTS Technical Report
🔑 Keywords: Encoder-decoder codec language model, cross-attention, PM-RoPE, multilingual speech synthesis, voice cloning
💡 Category: Generative Models
🌟 Research Objective:
– To enhance voice cloning and duration control in multilingual speech synthesis using an encoder-decoder codec language model.
🛠️ Research Methods:
– Development and use of T5Gemma-TTS, which employs cross-attention at each decoder layer and introduces PM-RoPE for improved text conditioning and duration control.
💬 Research Conclusions:
– T5Gemma-TTS achieves statistically significant improvements in speaker similarity for Japanese and high Korean speaker similarity despite limited training data. Disabling PM-RoPE at inference leads to significant synthesis failures.
👉 Paper link: https://huggingface.co/papers/2604.01760

14. Omni123: Exploring 3D Native Foundation Models with Limited 3D Data by Unifying Text to 2D and 3D Generation
🔑 Keywords: 3D-native foundation model, cross-modal consistency, discrete tokens, semantic alignment, multi-view geometric consistency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Present Omni123, a 3D-native foundation model for unifying text-to-2D and text-to-3D generation within a single autoregressive framework.
🛠️ Research Methods:
– Introduce an interleaved X-to-X training paradigm to coordinate cross-modal tasks for diverse datasets without the need for fully aligned text-image-3D triplets.
💬 Research Conclusions:
– Omni123 significantly enhances text-guided 3D generation and editing, showing potential for scalable multimodal 3D world models.
👉 Paper link: https://huggingface.co/papers/2604.02289

15. FlowSlider: Training-Free Continuous Image Editing via Fidelity-Steering Decomposition
🔑 Keywords: Rectified Flow, continuous editing, fidelity term, steering term, FlowSlider
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to enable continuous image editing with stable slider-style control, preserving image fidelity and maintaining a consistent edit direction without the need for additional training.
🛠️ Research Methods:
– The study proposes a new method called FlowSlider that decomposes updates into fidelity and steering components within the Rectified Flow framework, eliminating the need for post-training.
💬 Research Conclusions:
– The FlowSlider method allows for stable and reliable strength control in image editing by scaling the steering term while keeping the fidelity term unchanged, resulting in improved quality of continuous editing across various tasks.
👉 Paper link: https://huggingface.co/papers/2604.02088

16. ActionParty: Multi-Subject Action Binding in Generative Video Games
🔑 Keywords: ActionParty, AI-generated video games, subject state tokens, video diffusion, multi-subject world model
💡 Category: Generative Models
🌟 Research Objective:
– The main objective is to develop ActionParty, a multi-agent video generation model that allows individual action control of up to seven players in diverse environments.
🛠️ Research Methods:
– Introduces subject state tokens to differentiate global video rendering from individual action control, leveraging a spatial biasing mechanism to model state tokens and video latents.
💬 Research Conclusions:
– ActionParty is the first video world model that can control multiple agents simultaneously, showing improvements in action-following accuracy and identity consistency, as well as robust autoregressive tracking of subjects in complex interactions.
👉 Paper link: https://huggingface.co/papers/2604.02330

17. Gated Condition Injection without Multimodal Attention: Towards Controllable Linear-Attention Transformers
🔑 Keywords: Controllable diffusion models, Linear attention, On-device visual generation, Multi-condition input, Gated conditioning module
💡 Category: Generative Models
🌟 Research Objective:
– To enable secure and efficient on-device visual generation using controllable diffusion models based on linear attention architectures.
🛠️ Research Methods:
– A novel framework employing a unified gated conditioning module within a dual-path pipeline to handle multi-type conditional inputs effectively.
💬 Research Conclusions:
– The proposed framework significantly improves controllable generation performance using linear-attention models, achieving state-of-the-art results in fidelity and controllability compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2603.27666

18. Memory-Augmented Vision-Language Agents for Persistent and Semantically Consistent Object Captioning
🔑 Keywords: Memory-Augmented, Vision-Language Agent, Data Association, Object Captioning, Autoregressive Framework
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce a unified, memory-augmented Vision-Language agent that ensures consistent object representation across multiple viewpoints within a single autoregressive framework.
🛠️ Research Methods:
– The model processes current RGB observations, explored maps, and episodic memory serialized into object-level tokens to maintain object identity and semantic consistency. Trained in a self-supervised manner using a disagreement-based policy and pseudo-captioning model.
💬 Research Conclusions:
– The model demonstrates improvements of up to +11.86% in standard captioning scores and +7.39% in caption self-similarity over baseline models, showcasing scalable performance with a compact scene representation.
👉 Paper link: https://huggingface.co/papers/2603.24257

19. Executing as You Generate: Hiding Execution Latency in LLM Code Generation
🔑 Keywords: Parallel Execution, LLM-based Coding Agents, End-to-end Latency, Three-stage Pipeline, Eager
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to reduce the latency in LLM-based coding agents by implementing a parallel execution paradigm.
🛠️ Research Methods:
– A novel three-stage pipeline consisting of generation, detection, and execution is formalized.
– The introduction of Eager, which utilizes AST-based chunking, dynamic batching with gated execution, and early error interruption, is evaluated.
💬 Research Conclusions:
– Eager successfully decreases non-overlapped execution latency by up to 99.9% and end-to-end latency by up to 55% in tested benchmarks and environments.
👉 Paper link: https://huggingface.co/papers/2604.00491

20. Brainstacks: Cross-Domain Cognitive Capabilities via Frozen MoE-LoRA Stacks for Continual LLM Learning
🔑 Keywords: Continual Fine-tuning, Modular Architecture, MoE-LoRA, Residual Boosting, Outcome-based Routing
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study presents Brainstacks, aiming to enable continual multi-domain fine-tuning of large language models using modular adapter stacks.
🛠️ Research Methods:
– Implementation of five interlocking components including MoE-LoRA, residual boosting, and outcome-based routing with experiments on models such as TinyLlama-1.1B and Gemma 3 12B IT to validate performance and compatibility with post-SFT alignment.
💬 Research Conclusions:
– The research finds that domain stacks encode transferable cognitive primitives rather than domain-specific knowledge, facilitating efficient cross-domain operations and achieving 2.5x faster convergence rates compared to traditional methods.
👉 Paper link: https://huggingface.co/papers/2604.01152

21. Automatic Image-Level Morphological Trait Annotation for Organismal Images
🔑 Keywords: Sparse autoencoders, Foundation-model features, Vision-language prompting, Bioscan-Traits, Ecological studies
💡 Category: Machine Learning
🌟 Research Objective:
– Develop a scalable pipeline for extracting and annotating morphological traits from biological images using AI techniques.
🛠️ Research Methods:
– Train sparse autoencoders on foundation-model features to produce monosemantic neurons.
– Implement a trait annotation pipeline leveraging vision-language prompting and create the Bioscan-Traits dataset.
💬 Research Conclusions:
– The new pipeline allows for scalable, cost-effective extraction and annotation of traits, bridging ecological studies and machine-learning approaches.
– Human evaluation shows the biological plausibility of generated trait descriptions, enabling large-scale ecological analyses.
👉 Paper link: https://huggingface.co/papers/2604.01619

22. MultiGen: Level-Design for Editable Multiplayer Worlds in Diffusion Game Engines
🔑 Keywords: Video world models, External memory, User control, Multiplayer interactions, Memory representation
💡 Category: Generative Models
🌟 Research Objective:
– To address interactivity limitations in video world models by introducing an explicit external memory for enhanced user control and multiplayer interactions.
🛠️ Research Methods:
– The system employs a decomposition approach into Memory, Observation, and Dynamics modules, allowing user-controlled environment editing and enabling real-time interactions.
💬 Research Conclusions:
– The proposed design offers editable control over environment structure through memory representation, extending naturally to real-time multiplayer rollouts with coherent viewpoints and consistent interactions among players.
👉 Paper link: https://huggingface.co/papers/2603.06679

23.

24. An Empirical Recipe for Universal Phone Recognition
🔑 Keywords: PhoneticXEUS, multilingual speech recognition, accented speech, pretrained representations, data scale
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve multilingual and accented speech recognition performance by analyzing key factors such as data scale, model architecture, and training objectives.
🛠️ Research Methods:
– PhoneticXEUS was developed through large-scale training and systematic controlled ablations, evaluating SSL representations, data scale, and loss objectives across over 100 languages.
💬 Research Conclusions:
– PhoneticXEUS achieved state-of-the-art performance with a PFER of 17.7% for multilingual and 10.6% for accented English speech, highlighting the efficacy of the training methodology and analysis of error patterns.
👉 Paper link: https://huggingface.co/papers/2603.29042

25. Friends and Grandmothers in Silico: Localizing Entity Cells in Language Models
🔑 Keywords: Entity-centric factual question answering, MLP neurons, Causal interventions, Entity-consistent predictions, Canonicalization interpretation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the internal mechanisms of language models in answering entity-centric factual questions, focusing on localizing entity-selective MLP neurons.
🛠️ Research Methods:
– The research utilizes templated prompts and causal interventions on PopQA-based QA examples to investigate and validate localized neurons’ roles.
💬 Research Conclusions:
– Entity-selective MLP neurons are prominent in early layers, and activating a single neuron can retrieve entity-consistent predictions.
– Robustness to linguistic variations suggests a canonicalization interpretation, although coverage is higher for more popular entities.
👉 Paper link: https://huggingface.co/papers/2604.01404

26. Ask or Assume? Uncertainty-Aware Clarification-Seeking in Coding Agents
🔑 Keywords: LLM agents, underspecification, uncertainty-aware, multi-agent scaffold, task resolve rate
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To improve the performance of Large Language Model (LLM) agents in handling underspecified software development tasks by employing a multi-agent system that proactively seeks clarifications.
🛠️ Research Methods:
– Systematic evaluation of clarification-seeking abilities of LLM agents using an uncertainty-aware multi-agent scaffold that separates underspecification detection from code execution on the SWE-bench Verified variant.
💬 Research Conclusions:
– The multi-agent system, integrating OpenHands + Claude Sonnet 4.5, achieves a 69.40% task resolve rate, surpassing the single-agent setup and closing the gap with fully specified instruction agents. It also effectively balances when to seek further information on complex tasks, transforming current models into proactive collaborators.
👉 Paper link: https://huggingface.co/papers/2603.26233

27. UniRecGen: Unifying Multi-View 3D Reconstruction and Generation
🔑 Keywords: Sparse-view 3D modeling, reconstruction fidelity, generative plausibility, diffusion-based generation, disentangled cooperative learning
💡 Category: Generative Models
🌟 Research Objective:
– To create a unified framework, UniRecGen, that improves 3D modeling from sparse inputs by integrating feed-forward reconstruction with diffusion-based generation.
🛠️ Research Methods:
– Utilizing a shared canonical space for model alignment and employing disentangled cooperative learning to enable seamless integration of different paradigms.
💬 Research Conclusions:
– UniRecGen achieves superior fidelity and robustness, outperforming previous methods in generating complete and consistent 3D models from sparse observations.
👉 Paper link: https://huggingface.co/papers/2604.01479

28. Woosh: A Sound Effects Foundation Model
🔑 Keywords: Woosh, Sound Effect Foundation Model, Audio Encoder/Decoder, Text-to-Audio, Generative Models
💡 Category: Generative Models
🌟 Research Objective:
– Develop a sound effect foundation model named Woosh that supports audio encoding/decoding, text-audio alignment, and text-to-audio/video-to-audio generation.
🛠️ Research Methods:
– Evaluating Woosh’s model architecture and training process against other popular open models to establish its efficacy and performance.
💬 Research Conclusions:
– Woosh demonstrates competitive or superior performance compared to existing models such as StableAudio-Open and TangoFlux, with advantages in low-resource operation and fast inference, illustrating its potential as a foundational tool in audio research.
👉 Paper link: https://huggingface.co/papers/2604.01929

29. Working Notes on Late Interaction Dynamics: Analyzing Targeted Behaviors of Late Interaction Models
🔑 Keywords: Late Interaction models, length bias, multi-vector scoring, MaxSim operator, NanoBEIR benchmark
💡 Category: Natural Language Processing
🌟 Research Objective:
– Explore the length bias and efficiency of similarity exploitation in Late Interaction retrieval models within the context of multi-vector scoring.
🛠️ Research Methods:
– Analysis of state-of-the-art models on the NanoBEIR benchmark focusing on identified behaviors, particularly concerning length bias and token-level similarity scoring employing the MaxSim operator.
💬 Research Conclusions:
– While the length bias is evident in causal models, it can also affect bi-directional models in extreme situations. The MaxSim operator effectively utilizes token-level similarity scores, as confirmed by the absence of significant trends beyond the top-1 document token.
👉 Paper link: https://huggingface.co/papers/2603.26259

30. Efficient and Principled Scientific Discovery through Bayesian Optimization: A Tutorial
🔑 Keywords: Bayesian Optimisation, Scientific Discovery, Surrogate Models, Gaussian Processes, Human-in-the-loop Integration
💡 Category: Foundations of AI
🌟 Research Objective:
– To automate and formalize the scientific discovery process using Bayesian Optimisation to enhance resource efficiency and gain critical insights.
🛠️ Research Methods:
– Utilizing surrogate models like Gaussian Processes to model empirical observations and using acquisition functions to balance exploration and exploitation in experiments.
💬 Research Conclusions:
– Bayesian Optimisation bridges AI advances with practical applications in fields like catalysis, materials science, and organic synthesis, enabling cross-disciplinary researchers to design more efficient experiments.
👉 Paper link: https://huggingface.co/papers/2604.01328

31. Apriel-Reasoner: RL Post-Training for General-Purpose and Efficient Reasoning
🔑 Keywords: Apriel-Reasoner, Reinforcement Learning, Multi-domain, Efficiency, Reasoning Traces
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance reasoning efficiency and accuracy across diverse tasks while reducing inference costs through a 15B-parameter language model named Apriel-Reasoner.
🛠️ Research Methods:
– The model is trained using a fully reproducible multi-domain RL post-training recipe on five public dataset domains—mathematics, code generation, instruction following, logical puzzles, and function calling. An adaptive domain sampling mechanism and a difficulty-aware extension of length penalty are employed to optimize the training process.
💬 Research Conclusions:
– Apriel-Reasoner surpasses its predecessor, Apriel-Base, and matches other strong open-weight models with similar parameter sizes while reducing inference costs by 30-50%. It effectively balances accuracy and token budget, redefining the Pareto frontier in this context.
👉 Paper link: https://huggingface.co/papers/2604.02007

32. DynaVid: Learning to Generate Highly Dynamic Videos using Synthetic Motion Data
🔑 Keywords: video diffusion models, synthetic motion data, optical flow, video synthesis framework, dynamic motions
💡 Category: Generative Models
🌟 Research Objective:
– Address limitations in video diffusion models by improving realistic video synthesis with dynamic motions and fine-grained motion control using synthetic motion data.
🛠️ Research Methods:
– Implementation of a framework called DynaVid that uses synthetic motion data represented as optical flow within a two-stage generation process, separating motion and appearance.
💬 Research Conclusions:
– DynaVid improves realism and controllability in dynamic motion generation and camera motion control, validated through experiments on scenarios with limited existing datasets.
👉 Paper link: https://huggingface.co/papers/2604.01666
33. MDPBench: A Benchmark for Multilingual Document Parsing in Real-World Scenarios
🔑 Keywords: Multilingual Document Parsing, Open-Source Models, Closed-Source Models, Non-Latin Scripts, Photographed Documents
💡 Category: Computer Vision
🌟 Research Objective:
– The study introduces the Multilingual Document Parsing Benchmark to evaluate model performance on multilingual digital and photographed document parsing, addressing a lack in systematic benchmarks for diverse scripts and low-resource languages.
🛠️ Research Methods:
– The benchmark comprises 3,400 document images in 17 languages, annotated through a pipeline involving expert models, manual correction, and human verification. It includes separate public and private evaluation splits to ensure fair comparison and to prevent data leakage.
💬 Research Conclusions:
– A significant performance gap was discovered between closed-source and open-source models, especially on non-Latin scripts and photographed documents. Closed-source models like Gemini3-Pro exhibit robustness, while open-source alternatives see a substantial performance drop of up to 17.8% on photographed documents and 14.0% on non-Latin scripts. This highlights the need for more inclusive and deployment-ready parsing systems.
👉 Paper link: https://huggingface.co/papers/2603.28130

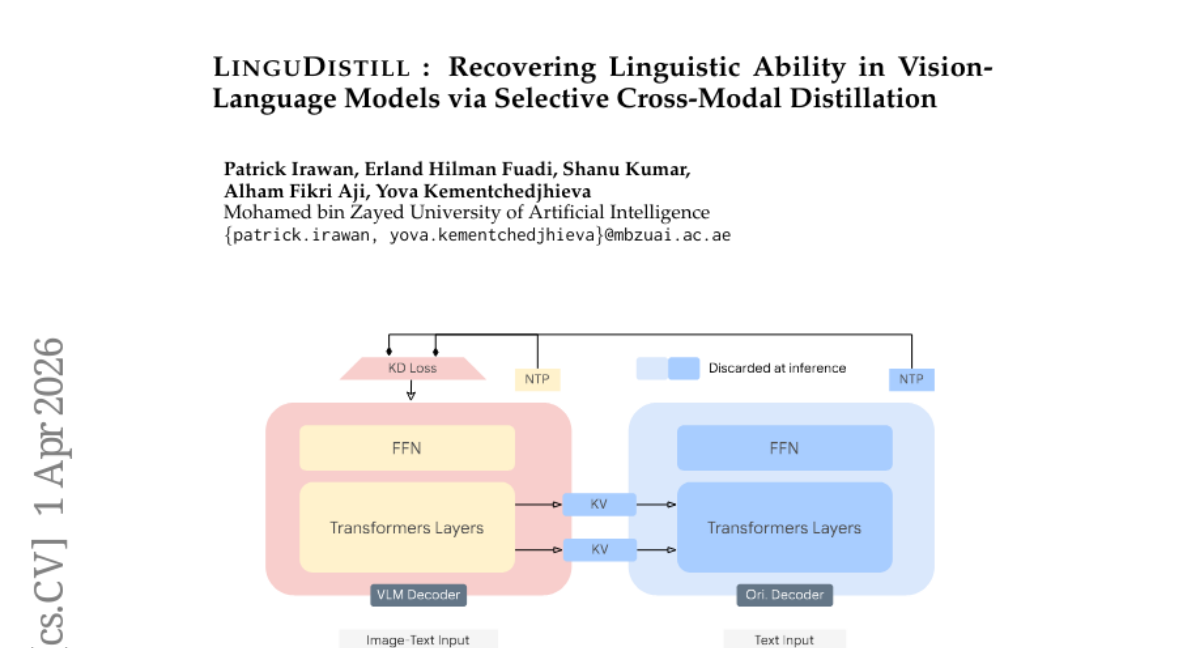
34. LinguDistill: Recovering Linguistic Ability in Vision- Language Models via Selective Cross-Modal Distillation
🔑 Keywords: LinguDistill, vision-language models, adapter-free distillation, KV-cache sharing, multimodal representations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To recover linguistic capabilities in vision-language models without compromising visual task performance by using adapter-free distillation with frozen language models as teachers.
🛠️ Research Methods:
– Introduces an adapter-free distillation method called LinguDistill and utilizes layer-wise KV-cache sharing to enable vision-conditioned teacher supervision, allowing the original language model to restore linguistic capabilities effectively.
💬 Research Conclusions:
– LinguDistill successfully restores up to 10% of the performance lost on language and knowledge benchmarks while maintaining competitive performance on vision-specific tasks, proving that linguistic capability can be recovered efficiently without additional modules in multimodal models.
👉 Paper link: https://huggingface.co/papers/2604.00829
35. VideoZeroBench: Probing the Limits of Video MLLMs with Spatio-Temporal Evidence Verification
🔑 Keywords: VideoZeroBench, spatio-temporal evidence, long-video question answering, grounded video understanding, evidence-based reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces VideoZeroBench, a comprehensive benchmark for evaluating long-video question answering with meticulous verification of spatio-temporal evidence.
🛠️ Research Methods:
– The benchmark consists of 500 manually annotated questions across 13 domains, incorporating temporal intervals and spatial bounding boxes as evidence. It applies a five-level evaluation protocol to distinguish answering generation, temporal, and spatial grounding.
💬 Research Conclusions:
– Experiments demonstrate that surface-level answer correctness does not equate to genuine evidence-based reasoning. Models, including Gemini-3-Pro, show a significant gap in grounded video understanding, achieving less than 1% accuracy when stringent grounding constraints are applied.
👉 Paper link: https://huggingface.co/papers/2604.01569

36. Video Models Reason Early: Exploiting Plan Commitment for Maze Solving
🔑 Keywords: Video diffusion models, Emergent reasoning, Path length, Chaining with Early Planning, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– To understand the internal planning dynamics of video diffusion models using 2D maze solving as a controlled testbed.
🛠️ Research Methods:
– Examination of video diffusion models’ reasoning abilities through early plan commitment and path length prediction.
💬 Research Conclusions:
– Video diffusion models exhibit emergent reasoning capability with a commitment to a high-level motion plan in early denoising steps.
– Path length is a key predictor of maze difficulty over obstacle density.
– The introduction of Chaining with Early Planning (ChEaP) significantly boosts task performance on complex mazes.
👉 Paper link: https://huggingface.co/papers/2603.30043

37. GPA: Learning GUI Process Automation from Demonstrations
🔑 Keywords: GUI Process Automation, Robotic Process Automation, Sequential Monte Carlo, readiness calibration, fully local execution
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a vision-based Robotic Process Automation (RPA) that provides robust, deterministic, and privacy-preserving automation with faster execution compared to vision-language model approaches.
🛠️ Research Methods:
– Utilization of Sequential Monte Carlo-based localization for handling rescaling and detection uncertainty; implementation of readiness calibration for deterministic and reliable execution; execution entirely in local environments to ensure privacy.
💬 Research Conclusions:
– The proposed GUI Process Automation (GPA) achieves higher success rates and operates at ten times the speed of currently established models, offering significant improvements in adaptability, robustness, and security for enterprise workflows.
👉 Paper link: https://huggingface.co/papers/2604.01676

38. ASI-Evolve: AI Accelerates AI
🔑 Keywords: AI-driven discovery, AI-for-AI, neural architecture design, pretraining data curation, reinforcement learning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce ASI-Evolve, an agentic framework aimed at facilitating AI-driven discovery across key components of AI development, including data, architectures, and learning algorithms.
🛠️ Research Methods:
– ASI-Evolve employs a learn-design-experiment-analyze cycle, enhanced by a cognition base for injecting human priors and a dedicated analyzer for distilling experimental outcomes.
💬 Research Conclusions:
– ASI-Evolve demonstrates significant performance improvements in neural architecture design, pretraining data curation, and reinforcement learning algorithm design, offering early evidence for the potential of closed-loop AI research.
👉 Paper link: https://huggingface.co/papers/2603.29640

39. UniDriveVLA: Unifying Understanding, Perception, and Action Planning for Autonomous Driving
🔑 Keywords: Vision-Language-Action, UniDriveVLA, Mixture-of-Transformers, Semantic Reasoning, Autonomous Driving
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research introduces UniDriveVLA, a Unified Vision-Language-Action model to enhance autonomous driving by separating spatial perception from semantic reasoning through a Mixture-of-Transformers architecture.
🛠️ Research Methods:
– The model utilizes expert decoupling with three specialized experts for driving understanding, scene perception, and action planning, coordinated by masked joint attention, alongside a sparse perception paradigm with three-stage progressive training.
💬 Research Conclusions:
– UniDriveVLA exhibits state-of-the-art performance in various evaluation scenarios, demonstrating strong applicability in perception, prediction, and understanding tasks for autonomous driving, with its broad capabilities proven in both open-loop and closed-loop evaluations.
👉 Paper link: https://huggingface.co/papers/2604.02190

40. VOID: Video Object and Interaction Deletion
🔑 Keywords: VOID, video object removal, vision-language models, video diffusion models, causal reasoning
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces VOID, a framework for video object removal that aims to generate physically plausible scenes by leveraging causal and counterfactual reasoning.
🛠️ Research Methods:
– VOID utilizes a combination of vision-language models and video diffusion models to preserve consistent scene dynamics in videos with significant object interactions.
– A new paired dataset is created using Kubric and HUMOTO for counterfactual object removal scenarios.
💬 Research Conclusions:
– VOID demonstrates superior performance in maintaining consistent scene dynamics post object removal compared to existing methods, highlighting its effectiveness in complex scenarios.
👉 Paper link: https://huggingface.co/papers/2604.02296
41. NearID: Identity Representation Learning via Near-identity Distractors
🔑 Keywords: identity-focused vision tasks, Near-identity distractors, dataset, evaluation protocol, contrastive objective
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a framework using Near-identity distractors to improve reliability in identity-focused vision tasks by separating identity from background context.
🛠️ Research Methods:
– Introduce NearID dataset with a margin-based evaluation protocol.
– Utilize a two-tier contrastive objective approach on a frozen backbone to enhance identity-aware representations.
💬 Research Conclusions:
– Pre-trained encoders perform poorly without NearID strategies, with low Sample Success Rates.
– The proposed method achieves SSR of 99.2%, improved part-level discrimination and better aligns with human judgments on DreamBench++.
👉 Paper link: https://huggingface.co/papers/2604.01973
42. Steerable Visual Representations
🔑 Keywords: Steerable Visual Representations, Early Fusion, Multimodal LLMs, Cross-Attention, Zero-Shot Generalization
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce Steerable Visual Representations that allow language-guided focus on specific image elements while maintaining representation quality.
🛠️ Research Methods:
– Developed a method using early fusion of text and visual features through lightweight cross-attention in the visual encoder.
– Introduced benchmarks for measuring representational steerability.
💬 Research Conclusions:
– The approach enables visual features to focus on any desired objects in an image, preserving underlying representation quality.
– Demonstrated effectiveness with zero-shot generalization in tasks such as anomaly detection and personalized object discrimination.
👉 Paper link: https://huggingface.co/papers/2604.02327

43. SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
🔑 Keywords: SKILL0, LLM agents, zero-shot, skill internalization, Dynamic Curriculum
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces SKILL0, aiming to internalize skills into model parameters to facilitate zero-shot autonomous behavior and eliminate the need for runtime skill retrieval.
🛠️ Research Methods:
– Developed a Dynamic Curriculum that systematically reduces skill context during training, retaining valuable skills for improved task performance in a zero-shot setting.
– Implemented extensive agentic experiments to assess improvements over standard reinforcement learning baselines.
💬 Research Conclusions:
– SKILL0 significantly enhances task performance, with a 9.7% improvement in ALFWorld and 6.6% in Search-QA, all while maintaining efficient token usage.
👉 Paper link: https://huggingface.co/papers/2604.02268

44. The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
🔑 Keywords: latent space, language-based models, continuous representation, sequential inefficiency, semantic loss
💡 Category: Natural Language Processing
🌟 Research Objective:
– To provide a comprehensive overview of the role and evolution of latent space in language-based models, highlighting its advantages over explicit token-level approaches.
🛠️ Research Methods:
– The survey is structured into five perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook, to systematically examine the development and capabilities of latent space.
💬 Research Conclusions:
– Identifies latent space as a preferred computational substrate due to its ability to overcome structural limitations of explicit-space computation and supports a broad range of cognitive capabilities. Discusses open challenges and future research directions.
👉 Paper link: https://huggingface.co/papers/2604.02029
