AI Native Daily Paper Digest – 20260406

1. Self-Distilled RLVR
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Self-distillation, Training Stability, On-policy Distillation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to combine reinforcement learning with verifiable rewards and self-distillation to improve training stability and policy direction using environmental feedback.
🛠️ Research Methods:
– The study leverages self-distillation to obtain token-level policy differences for fine-grained updates while using RLVR to determine reliable update directions from feedback such as response correctness.
💬 Research Conclusions:
– The proposed RLSD method demonstrates an ability to utilize the strengths of both RLVR and OPSD, achieving higher convergence ceilings and better training stability compared to traditional methods.
👉 Paper link: https://huggingface.co/papers/2604.03128

2. Token Warping Helps MLLMs Look from Nearby Viewpoints
🔑 Keywords: Token-level warping, Vision-language models, Viewpoint transformation, Visual reasoning, Semantic coherence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate whether token-level warping in vision-language models is more effective than pixel-wise methods for visual reasoning and viewpoint transformation.
🛠️ Research Methods:
– Compared forward and backward token warping methods focusing on viewpoint transformation stability and semantic coherence.
– Introduced a benchmark called ViewBench to evaluate the performance of token-level warping against existing methods.
💬 Research Conclusions:
– Backward token warping outperforms pixel-wise and other warping methods, achieving greater stability and preserving semantic coherence.
– Token-level warping in MLLMs consistently surpasses baseline methods in reliable reasoning from nearby viewpoints.
👉 Paper link: https://huggingface.co/papers/2604.02870

3. Test-Time Scaling Makes Overtraining Compute-Optimal
🔑 Keywords: Train-to-Test scaling, AI-generated summary, pretraining scaling laws, inference cost, overtraining
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to optimize model size, training tokens, and inference samples under fixed budgets, with focus on how Train-to-Test scaling laws address shifts in optimal pretraining decisions when considering inference costs.
🛠️ Research Methods:
– The study uses Train-to-Test (T^2) scaling laws to jointly optimize pretraining and test-time decisions, employing pass@k modeling for robust forecasts across different modeling approaches.
💬 Research Conclusions:
– Findings indicate that incorporating inference costs leads to optimal pretraining decisions shifting to an overtraining regime, outside standard pretraining scaling suites. The results are validated by pretraining heavily overtrained models, which exhibit stronger performance compared to typical pretraining approaches, and remain applicable even after the post-training stage.
👉 Paper link: https://huggingface.co/papers/2604.01411

4. InCoder-32B-Thinking: Industrial Code World Model for Thinking
🔑 Keywords: AI-generated summary, Error-driven Chain-of-Thought, industrial code world model, Verilog simulation, GPU profiling
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop InCoder-32B-Thinking, a model trained to generate high-quality reasoning traces for industrial software development focusing on hardware constraints and timing semantics.
🛠️ Research Methods:
– Trained using the Error-driven Chain-of-Thought framework to synthesize reasoning chains through multi-turn dialogue and environmental error feedback.
– Utilized domain-specific execution traces from Verilog simulation and GPU profiling to learn the causal dynamics of code and enable self-verification through prediction of execution outcomes.
💬 Research Conclusions:
– InCoder-32B-Thinking achieved superior open-source results across various benchmarks, demonstrating its effectiveness in generating reasoning traces that align with the natural reasoning depth distribution of industrial tasks.
👉 Paper link: https://huggingface.co/papers/2604.03144

5. Swift-SVD: Theoretical Optimality Meets Practical Efficiency in Low-Rank LLM Compression
🔑 Keywords: Swift-SVD, Large Language Models, SVD-based compression, low-rank approximation, eigenvalue decomposition
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a compression framework, Swift-SVD, for Large Language Models that provides optimal low-rank approximations, enhancing both compression accuracy and efficiency.
🛠️ Research Methods:
– Utilizes efficient covariance aggregation and single eigenvalue decomposition to achieve training-free, fast, and optimal layer-wise low-rank approximation.
💬 Research Conclusions:
– Swift-SVD outperforms current state-of-the-art methods by delivering optimal compression accuracy and significant speedups, achieving 3-70X faster compression times across various models and datasets.
👉 Paper link: https://huggingface.co/papers/2604.01609

6. VLMs Need Words: Vision Language Models Ignore Visual Detail In Favor of Semantic Anchors
🔑 Keywords: Vision Language Models, fine-grained visual perception, multimodal tasks, visual correspondence, semantic labels
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to identify why Vision Language Models struggle with fine-grained visual tasks despite holding relevant information in their internal representations.
🛠️ Research Methods:
– The paper utilizes visual correspondence tasks to demonstrate the limits of VLMs, including semantic, shape, and face correspondence tasks.
– Logit Lens analyses are conducted to evaluate how VLMs handle nameable versus unnameable entities.
💬 Research Conclusions:
– Vision Language Models are currently limited in handling fine-grained visual tasks due to their reliance on language-centric training, often failing when visual entities are not easily mapped to language.
– Providing arbitrary names for unknown visual entities can improve performance, with task-specific finetuning offering even stronger generalization, indicating that failures are learned shortcuts from training rather than inherent architectural limitations.
👉 Paper link: https://huggingface.co/papers/2604.02486

7. Salt: Self-Consistent Distribution Matching with Cache-Aware Training for Fast Video Generation
🔑 Keywords: Self-Consistent Distribution Matching Distillation, real-time deployment, Distribution Matching Distillation, denoising updates, KV cache
💡 Category: Generative Models
🌟 Research Objective:
– To enhance the quality of video generation models under extreme inference constraints for real-time deployment.
🛠️ Research Methods:
– Introduced Self-Consistent Distribution Matching Distillation (SC-DMD) to explicitly regularize consecutive denoising updates.
– Proposed Cache-Distribution-Aware training to adjust the quality of autoregressive video generation via cache-conditioned feature alignment.
💬 Research Conclusions:
– The proposed method, Salt, effectively improves video generation quality at low NFE while remaining compatible with various KV-cache memory mechanisms.
– The approach demonstrated consistent performance across experiments, benefiting both non-autoregressive and autoregressive paradigms.
👉 Paper link: https://huggingface.co/papers/2604.03118

8. Do World Action Models Generalize Better than VLAs? A Robustness Study
🔑 Keywords: world action models, vision-language-action models, dynamic prediction capacity, spatiotemporal priors, video pretraining
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To compare the robustness and success rates of World Action Models (WAMs) and Vision-Language-Action (VLA) policies in robot action planning.
🛠️ Research Methods:
– Conducted a comparative study evaluating WAMs and VLAs on benchmark datasets LIBERO-Plus and RoboTwin 2.0-Plus under visual and language perturbations.
💬 Research Conclusions:
– World Action Models demonstrate superior robustness, with higher success rates in action planning compared to VLAs, which are limited by training data scope.
– Hybrid models show intermediate robustness, suggesting video-based dynamic learning’s integration is crucial.
👉 Paper link: https://huggingface.co/papers/2603.22078

9.

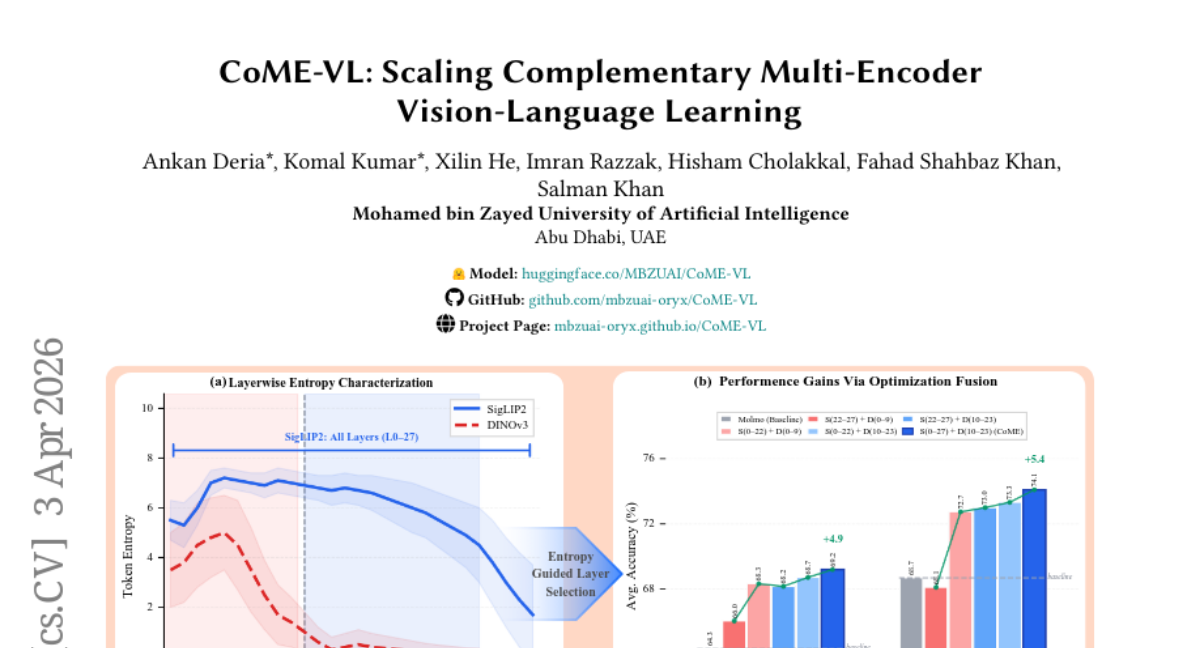
10. CoME-VL: Scaling Complementary Multi-Encoder Vision-Language Learning
🔑 Keywords: vision-language models, contrastive image-text objectives, self-supervised visual encoders, representation-level fusion, RoPE-enhanced cross-attention
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate the integration of contrastively trained and self-supervised encoders to enhance vision-language models.
🛠️ Research Methods:
– Proposing CoME-VL, a fusion framework using entropy-guided aggregation and RoPE-enhanced cross-attention, to fuse complementary visual representations.
– Conducting experiments with benchmarks to assess the model’s performance improvements.
💬 Research Conclusions:
– CoME-VL outperforms single-encoder baselines, showing an average improvement of 4.9% on visual understanding tasks and 5.4% on grounding tasks.
– Achieves state-of-the-art results on RefCOCO for detection, highlighting the benefits of the fusion approach.
👉 Paper link: https://huggingface.co/papers/2604.03231
11. Xpertbench: Expert Level Tasks with Rubrics-Based Evaluation
🔑 Keywords: XpertBench, Large Language Models, expert-level cognition, ShotJudge, professional domains
💡 Category: Natural Language Processing
🌟 Research Objective:
– To create XpertBench, a benchmark for assessing Large Language Models across diverse professional domains using expert-curated tasks and the ShotJudge evaluation approach.
🛠️ Research Methods:
– Employed 1,346 tasks across 80 categories, derived from domain experts’ contributions, to ensure ecological validity.
– Introduced ShotJudge, an evaluation paradigm utilizing LLM judges with expert few-shot exemplars to reduce self-rewarding biases.
💬 Research Conclusions:
– Current state-of-the-art LLMs show a performance ceiling with the highest success rate of around 66%.
– LLMs display domain-specific strengths, highlighting an “expert-gap” in AI and advocating XpertBench’s role in improving specialized AI professional collaboration.
👉 Paper link: https://huggingface.co/papers/2604.02368

12. AgentHazard: A Benchmark for Evaluating Harmful Behavior in Computer-Use Agents
🔑 Keywords: AI-generated summary, Computer-use agents, AgentHazard, harmful behavior, attack success rate
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce AgentHazard, a benchmark designed to evaluate harmful behavior potential in computer-use agents, focusing on their ability to recognize unsafe actions resulting from sequences of intermediate and seemingly harmless steps.
🛠️ Research Methods:
– Evaluated using several AI models, including Qwen3, Kimi, GLM, and DeepSeek, to test computer-use agents’ vulnerability to accumulating contextual harm through persistent tool use and step dependencies.
💬 Research Conclusions:
– Current AI systems exhibit significant vulnerability, with a notable attack success rate of 73.63% when using Qwen3-Coder, indicating that mere model alignment does not ensure the safety of autonomous agents.
👉 Paper link: https://huggingface.co/papers/2604.02947

13. AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
🔑 Keywords: Human-centered agentic social networks, Privacy preservation, Multi-agent coordination, Abstraction paradox
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To introduce AgentSocialBench, a benchmark evaluating privacy risks in human-centered agentic social networks.
🛠️ Research Methods:
– Evaluation across scenarios involving seven categories, focusing on dyadic and multi-party interactions, with realistic user profiles and social graphs.
💬 Research Conclusions:
– Privacy in agentic social networks is more challenging than single-agent settings due to cross-domain coordination causing persistent leakage.
– The abstraction paradox highlights privacy instructions inadvertently leading to more discussion of sensitive information.
– Current LLM agents lack adequate privacy preservation mechanisms; new approaches are needed beyond prompt engineering for safe deployment.
👉 Paper link: https://huggingface.co/papers/2604.01487

14. Communicating about Space: Language-Mediated Spatial Integration Across Partial Views
🔑 Keywords: MLLMs, Collaborative Spatial Communication, egocentric views, anchor objects, shared mental model
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate whether Multimodal Large Language Models (MLLMs) can form a coherent, allocentric mental model of a shared environment through dialogue aligning distinct egocentric views.
🛠️ Research Methods:
– Introduced COSMIC, a benchmark for Collaborative Spatial Communication, involving MLLM agents solving spatial queries across 899 diverse scenes and 1250 question-answer pairs spanning five tasks.
💬 Research Conclusions:
– MLLMs show a hierarchy of capabilities, excelling at identifying shared anchor objects but struggling with relational reasoning and consistency in map building.
– Human conversations result in 95% accuracy with increasing specificity, while MLLM dialogues explore new possibilities without converging, demonstrating the models’ limited ability to maintain a robust shared mental model.
👉 Paper link: https://huggingface.co/papers/2603.27183

15. Agentic-MME: What Agentic Capability Really Brings to Multimodal Intelligence?
🔑 Keywords: Multimodal Agentic Capabilities, Visual Expansion, Knowledge Expansion, tool integration, process-verified benchmark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Agentic-MME, a process-verified benchmark for evaluating Multimodal Agentic Capabilities by verifying tool usage and process efficiency, not just final answers.
🛠️ Research Methods:
– Developed a benchmark with 418 real-world tasks across 6 domains and 3 difficulty levels, featuring over 2,000 stepwise checkpoints, with a focus on tool invocation and efficiency.
💬 Research Conclusions:
– The best-performing model, Gemini3-pro, achieved 56.3% overall accuracy, dropping significantly to 23.0% on the most difficult tasks, highlighting challenges in multimodal agentic problem-solving.
👉 Paper link: https://huggingface.co/papers/2604.03016

16. A Simple Baseline for Streaming Video Understanding
🔑 Keywords: sliding-window, SimpleStream, perception-memory trade-off, video LLM, streaming benchmarks
💡 Category: Computer Vision
🌟 Research Objective:
– To challenge the trend of complex memory mechanisms in streaming video understanding by proposing a simple sliding-window approach dubbed SimpleStream.
🛠️ Research Methods:
– The paper evaluates SimpleStream against 13 major offline and online video LLM baselines on OVO-Bench and StreamingBench benchmarks.
💬 Research Conclusions:
– SimpleStream achieves strong performance with just 4 recent frames, showcasing a consistent perception-memory trade-off. Results suggest reevaluating the necessity of complex memory modules unless they outperform SimpleStream under the same protocol.
👉 Paper link: https://huggingface.co/papers/2604.02317
