AI Native Daily Paper Digest – 20260409

1. Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning
🔑 Keywords: Process-driven image generation, Multimodal models, Textual planning, Visual drafting, Semantic consistency
💡 Category: Generative Models
🌟 Research Objective:
– To introduce a process-driven image generation paradigm that decomposes image synthesis into iterative steps, enhancing consistency and interpretability.
🛠️ Research Methods:
– The approach involves multi-step synthesis consisting of textual planning, visual drafting, textual reflection, and visual refinement, orchestrated by dense, step-wise supervision to ensure spatial and semantic consistency.
💬 Research Conclusions:
– The proposed method makes the image generation process explicit, interpretable, and directly supervisable, validated through experiments on various text-to-image generation benchmarks.
👉 Paper link: https://huggingface.co/papers/2604.04746

2. MARS: Enabling Autoregressive Models Multi-Token Generation
🔑 Keywords: MARS, Autoregressive language models, Fine-tuning, Throughput, Real-time speed adjustment
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance autoregressive language models to predict multiple tokens per forward pass without architectural changes, thereby increasing throughput and supporting dynamic speed adjustment.
🛠️ Research Methods:
– Introduced MARS, a fine-tuning method involving instruction-tuning, block-level KV caching for batch inference, and confidence thresholding for real-time speed adjustment.
💬 Research Conclusions:
– MARS achieves 1.5-1.7x throughput improvement while maintaining baseline-level accuracy and facilitates real-time speed adjustment without performance degradation.
👉 Paper link: https://huggingface.co/papers/2604.07023

3. SEVerA: Verified Synthesis of Self-Evolving Agents
🔑 Keywords: Formally Guarded Generative Models, Agentic Code Generation, Self-Evolving Verified Agents, Formal Specifications, AI Native
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to enhance safety and correctness in AI Native agentic code generation by integrating formal specifications with soft objectives.
🛠️ Research Methods:
– Development of Formally Guarded Generative Models (FGGM) to ensure returned outputs from programs meet formal correctness contracts using first-order logic and rejection samplers.
– Implementation of SEVerA, a three-stage framework that includes search, verification of hard constraints, and scalable gradient-based optimization for soft objectives.
💬 Research Conclusions:
– Through applications like Dafny program verification and symbolic math synthesis, SEVerA showed improved performance and zero constraint violations, demonstrating that enforcing formal constraints can guide synthesis towards producing higher-quality, reliable agents.
👉 Paper link: https://huggingface.co/papers/2603.25111

4. FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
🔑 Keywords: FP4 quantization, diffusion model alignment, rollout scaling, NVFP4, training convergence
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to develop a reinforcement learning framework, Sol-RL, that integrates FP4 quantization with diffusion model alignment to accelerate training without sacrificing performance quality.
🛠️ Research Methods:
– The researchers proposed a two-stage framework using high-throughput NVFP4 rollouts to initially generate a candidate pool, followed by the select regeneration of samples in BF16 precision for policy optimization.
💬 Research Conclusions:
– Sol-RL effectively accelerates the rollout phase and optimizes training convergence, achieving superior alignment performance with up to 4.64 times faster training convergence, thus balancing computational efficiency with high model fidelity.
👉 Paper link: https://huggingface.co/papers/2604.06916
5. TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
🔑 Keywords: Vision Transformer, deep compression autoencoders, latent representation collapse, token space, joint self-supervised training
💡 Category: Generative Models
🌟 Research Objective:
– To enhance deep compression autoencoders using a ViT-based architecture, improving latent representation and overcoming token space limitations.
🛠️ Research Methods:
– Studied token number scaling by adjusting the patch size in ViT under a fixed latent budget.
– Decomposed token-to-latent compression into two stages to reduce structural information loss.
– Enhanced semantic structure via joint self-supervised training.
💬 Research Conclusions:
– TC-AE significantly improves reconstruction and generative performance during deep compression, advancing ViT-based tokenizers for visual generation.
👉 Paper link: https://huggingface.co/papers/2604.07340

6. FlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
🔑 Keywords: vision-centric, multimodal generation, visual representation, flow matching model, visual prompt pairs
💡 Category: Generative Models
🌟 Research Objective:
– Introduce FlowInOne, a vision-centric framework that unifies diverse input modalities into a single visual representation for coherent image generation and editing.
🛠️ Research Methods:
– Reformulate multimodal generation into a purely visual flow, utilizing a unified flow matching model to integrate various inputs (textual descriptions, spatial layouts, editing instructions) into visual prompts.
💬 Research Conclusions:
– FlowInOne surpasses existing open-source and commercial models, achieving state-of-the-art performance across unified generation tasks by eliminating cross-modal alignment bottlenecks and establishing a cohesive vision-centric generative model.
👉 Paper link: https://huggingface.co/papers/2604.06757

7. DeonticBench: A Benchmark for Reasoning over Rules
🔑 Keywords: DEONTICBENCH, large language models, deontic reasoning, symbolic computation, Prolog
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research introduces DEONTICBENCH, a benchmark designed to evaluate large language models on the complex and context-specific task of deontic reasoning within legal and policy domains.
🛠️ Research Methods:
– Utilizes a variety of approaches such as free-form reasoning and symbolic computation, including the use of Prolog for solving tasks with a formal problem interpretation and program trace.
💬 Research Conclusions:
– The study finds that current large language models and coding models perform below satisfactory levels on DEONTICBENCH tasks, indicating areas for improvement particularly through supervised fine-tuning and reinforcement learning methods.
👉 Paper link: https://huggingface.co/papers/2604.04443

8. The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
🔑 Keywords: latent reasoning, large language models, multi-step planning, chain-of-thought monitoring, few-shot prompting
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the capability of large language models to discover and execute multi-step planning strategies in their latent representations.
🛠️ Research Methods:
– Conducted experiments using graph path-finding tasks to test the latent reasoning limits by controlling the number of required planning steps.
💬 Research Conclusions:
– Found that small transformers can discover strategies for up to three latent steps, while more advanced models like fine-tuned GPT-4o and Qwen3-32B can reach five, and GPT-5.4 extends to seven under few-shot prompting. The strategy can generalize up to eight latent steps despite training limits.
👉 Paper link: https://huggingface.co/papers/2604.06427

9. Personalized RewardBench: Evaluating Reward Models with Human Aligned Personalization
🔑 Keywords: Personalized RewardBench, reward models, individual user preferences, downstream performance, human evaluation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Personalized RewardBench, a benchmark designed to evaluate the ability of reward models to capture individual user preferences and improve correlation with downstream performance.
🛠️ Research Methods:
– Development of chosen and rejected response pairs based on strict adherence to individual user preferences.
– Human evaluations to confirm preference distinctions.
– Extensive testing comparing the performance of state-of-the-art reward models on personalization.
💬 Research Conclusions:
– Existing state-of-the-art reward models struggle with personalization, achieving only up to 75.94% accuracy.
– Personalized RewardBench demonstrates a higher correlation with downstream performance compared to existing baselines.
– Establishes itself as a robust and accurate proxy for evaluating reward models’ performance in downstream applications.
👉 Paper link: https://huggingface.co/papers/2604.07343

10. Learning to Hint for Reinforcement Learning
🔑 Keywords: HiLL, Group Relative Policy Optimization, reinforcement learning, hint generation, transferability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This research introduces HiLL, a reinforcement learning framework designed to adaptively generate hints based on reasoner errors, aiming to improve learning signals and transfer performance in Group Relative Policy Optimization.
🛠️ Research Methods:
– HiLL trains both hinter and reasoner policies simultaneously during reinforcement learning. The framework enables online generation of adaptive hints conditioned on incorrect rollouts by the reasoner, and introduces a measure of hint reliance to assess dependence on hints for correct trajectories.
💬 Research Conclusions:
– HiLL demonstrates superiority over Group Relative Policy Optimization (GRPO) and previous hint-based methods across several benchmarks, highlighting the effectiveness of adaptive and transfer-aware hint learning in reinforcement learning. The proposed framework not only recovers informative GRPO groups but also produces enhanced signals likely to improve policies without hints.
👉 Paper link: https://huggingface.co/papers/2604.00698

11. A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
🔑 Keywords: DeltaTok, DeltaWorld, generative world model, feature space, multi-hypothesis training
💡 Category: Generative Models
🌟 Research Objective:
– To introduce DeltaTok, a tokenizer that encodes visual feature differences as delta tokens, and DeltaWorld, a generative model that generates diverse video futures efficiently.
🛠️ Research Methods:
– Utilizes Delta tokens to reduce video representation to a one-dimensional temporal sequence, facilitating tractable multi-hypothesis training where multiple futures are generated and only the best is supervised.
💬 Research Conclusions:
– DeltaWorld is capable of forecasting futures that align closely with real-world outcomes while significantly reducing parameter count and computational cost compared to existing models.
👉 Paper link: https://huggingface.co/papers/2604.04913

12. VenusBench-Mobile: A Challenging and User-Centric Benchmark for Mobile GUI Agents with Capability Diagnostics
🔑 Keywords: VenusBench-Mobile, mobile GUI agents, online benchmark, user-intent-driven task design, capability-oriented annotation scheme
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce VenusBench-Mobile, a comprehensive online benchmark for evaluating mobile GUI agents under realistic and varied user-centric conditions.
🛠️ Research Methods:
– Builds evaluation on two key pillars: user-intent-driven task design for reflecting real mobile usage and capability-oriented annotation scheme for fine-grained behavior analysis.
💬 Research Conclusions:
– Extensive evaluations reveal significant performance gaps in state-of-the-art mobile GUI agents compared to previous benchmarks, with deficiencies in perception and memory and high brittleness under environmental variations, underscoring the challenge of real-world deployment.
👉 Paper link: https://huggingface.co/papers/2604.06182

13. Qualixar OS: A Universal Operating System for AI Agent Orchestration
🔑 Keywords: Qualixar OS, universal AI agent orchestration, LLM providers, agent frameworks, multi-agent topologies
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Present Qualixar OS, a comprehensive application-layer operating system that facilitates universal AI agent orchestration by integrating diverse LLM providers, agent frameworks, and communication protocols.
🛠️ Research Methods:
– Developed execution semantics for 12 multi-agent topologies.
– Introduced Forge, an LLM-driven team design engine with historical strategy memory.
– Implemented three-layer model routing using Q-learning, Bayesian POMDP, and dynamic multi-provider discovery.
– Established a consensus-based judge pipeline with advanced features like Goodhart detection and content attribution methods.
💬 Research Conclusions:
– Validated with 2,821 test cases, Qualixar OS achieves 100% accuracy on a custom 20-task evaluation at minimal cost, demonstrating its efficiency and robustness in managing heterogeneous multi-agent systems.
👉 Paper link: https://huggingface.co/papers/2604.06392

14. AgentGL: Towards Agentic Graph Learning with LLMs via Reinforcement Learning
🔑 Keywords: Agentic Graph Learning, reinforcement learning, Graph-native tools, AI-generated summary, Long-horizon policy learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Agentic Graph Learning (AGL) to enable Large Language Models (LLMs) to autonomously navigate and reason over complex relational data using graph-native tools and curriculum learning strategies.
🛠️ Research Methods:
– Develop AgentGL, the first reinforcement learning-driven framework for AGL, incorporating graph-native tools for multi-scale exploration and employing a graph-conditioned curriculum RL strategy.
💬 Research Conclusions:
– AgentGL outperforms established baselines in node classification and link prediction, highlighting AGL’s potential in enhancing LLMs’ abilities to interact with complex relational environments.
👉 Paper link: https://huggingface.co/papers/2604.05846

15. Improving Semantic Proximity in Information Retrieval through Cross-Lingual Alignment
🔑 Keywords: Cross-Lingual Information Retrieval, Multilingual Retrieval Models, Cross-Lingual Alignment, English Inclination, Novel Training Strategy
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the bias toward English documents in multilingual retrieval models and enhance cross-lingual alignment with minimal data.
🛠️ Research Methods:
– Introduce scenarios and metrics for evaluating cross-lingual alignment performance.
– Propose a novel training strategy using a small dataset of 2.8k samples.
💬 Research Conclusions:
– The proposed method effectively improves cross-lingual retrieval performance and mitigates the bias toward English documents, enhancing the capabilities of multilingual embedding models.
👉 Paper link: https://huggingface.co/papers/2604.05684

16. MoRight: Motion Control Done Right
🔑 Keywords: motion control, motion causality, disentangled motion modeling, temporal cross-view attention, physically plausible interactions
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to create a unified framework, MoRight, capable of separating object motion from camera viewpoint, ensuring realistic interactions in video generation.
🛠️ Research Methods:
– The study employs a framework that uses disentangled motion modeling with temporal cross-view attention, allowing for independent control of objects and camera movement. Motion is decomposed into active and passive components to teach the model motion causality.
💬 Research Conclusions:
– MoRight achieves state-of-the-art performance in generation quality, motion controllability, and interaction awareness on three different benchmarks.
👉 Paper link: https://huggingface.co/papers/2604.07348

17. Beyond Hard Negatives: The Importance of Score Distribution in Knowledge Distillation for Dense Retrieval
🔑 Keywords: Knowledge Distillation, Stratified Sampling, retrieval models, teacher score distribution, hard negatives
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to enhance the process of Knowledge Distillation in retrieval models by proposing a Stratified Sampling strategy that preserves the full range of teacher scores, addressing the underexplored area of teacher score distribution.
🛠️ Research Methods:
– Implementation of a Stratified Sampling strategy that uniformly covers the entire score spectrum, maintaining the variance and entropy of teacher scores in both in-domain and out-of-domain benchmarks.
💬 Research Conclusions:
– Stratified Sampling significantly outperforms traditional top-K and random sampling methods by preserving the diverse range of relative scores perceived by the teacher, suggesting its effectiveness as a baseline in Knowledge Distillation.
👉 Paper link: https://huggingface.co/papers/2604.04734

18. Fast Spatial Memory with Elastic Test-Time Training
🔑 Keywords: Elastic Test-Time Training, Fast Spatial Memory, 4D reconstruction, catastrophic forgetting, spatiotemporal representations
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to enhance LaCT’s ability to handle arbitrarily long sequences in a single pass by proposing an Elastic Test-Time Training approach to stabilize fast-weight updates and mitigate issues like catastrophic forgetting and overfitting.
🛠️ Research Methods:
– Elastic Test-Time Training utilizes a Fisher-weighted elastic prior and an anchor state evolving as an exponential moving average to balance stability and plasticity, alongside a Fast Spatial Memory model for efficient and scalable 4D reconstruction.
💬 Research Conclusions:
– The proposed method enables high-quality 3D/4D reconstruction with faster adaptation over long sequences, successfully moving beyond single-large-chunk limitations, and alleviates activation-memory bottlenecks.
👉 Paper link: https://huggingface.co/papers/2604.07350

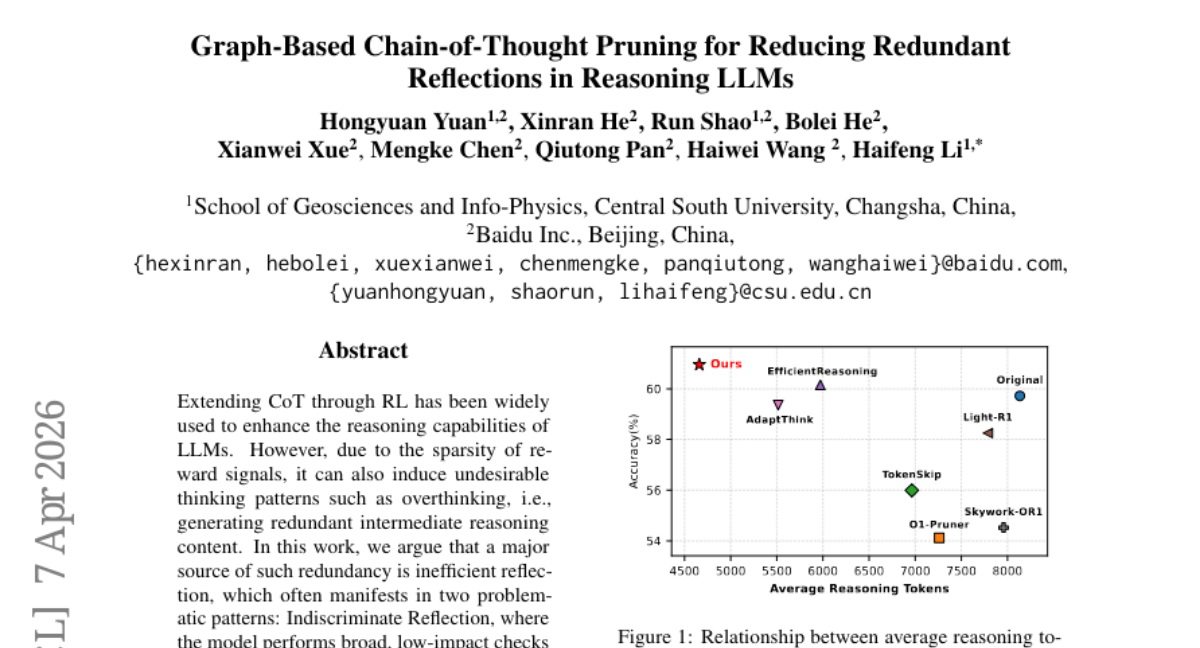
19. Graph-Based Chain-of-Thought Pruning for Reducing Redundant Reflections in Reasoning LLMs
🔑 Keywords: Chain-of-Thought Reasoning, Redundant Thinking Patterns, Reinforcement Learning, Directed Acyclic Graph, Pruning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to optimize Chain-of-Thought reasoning in large language models by reducing redundant thinking patterns using a graph-based framework.
🛠️ Research Methods:
– The researchers employ a graph-based optimization framework that transforms linear thought processes into a directed acyclic graph. They apply a dual pruning strategy involving branch-level and depth-level pruning, alongside a three-stage pipeline that includes SFT, DPO, and GRPO with length penalty.
💬 Research Conclusions:
– The proposed approach successfully reduces average reasoning tokens by 42% while maintaining or improving the accuracy of the large language models.
👉 Paper link: https://huggingface.co/papers/2604.05643
20. Neural Computers
🔑 Keywords: Neural Computers, Learned Runtime State, I/O Traces, Completely Neural Computer, Short-horizon Control
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to explore the concept of Neural Computers (NCs), a new computing paradigm that integrates computation, memory, and I/O into a learned runtime state, and to study the feasibility of Completely Neural Computers (CNCs) as a mature, general-purpose machine form.
🛠️ Research Methods:
– The study investigates if early NC primitives can be learned solely from collected I/O traces without an instrumented program state, by implementing NCs as video models that process instructions, pixels, and user actions in CLI and GUI environments.
💬 Research Conclusions:
– Initial results indicate that learned runtimes can acquire early interface primitives, like I/O alignment and short-horizon control, yet routine reuse, controlled updates, and symbolic stability require further investigation. The paper suggests a roadmap to overcome these challenges, potentially establishing a new computing paradigm beyond traditional models.
👉 Paper link: https://huggingface.co/papers/2604.06425

21. INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
🔑 Keywords: Spatiotemporal Autoregressive, High-Fidelity Dynamic Scenes, Real-Time Interactive Methods, Spatial Consistency, Generative Models
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a framework, INSPATIO-WORLD, capable of generating high-fidelity and dynamic interactive scenes from a single reference video using a spatiotemporal autoregressive architecture.
🛠️ Research Methods:
– Implementing the Spatiotemporal Autoregressive (STAR) architecture alongside an Implicit Spatiotemporal Cache and Explicit Spatial Constraint Module.
– Introducing Joint Distribution Matching Distillation (JDMD) for improved data fidelity.
💬 Research Conclusions:
– INSPATIO-WORLD outperforms existing state-of-the-art models in spatial consistency and interaction precision on the WorldScore-Dynamic benchmark, establishing a practical pipeline for navigating 4D environments from monocular videos.
👉 Paper link: https://huggingface.co/papers/2604.07209
22. Combee: Scaling Prompt Learning for Self-Improving Language Model Agents
🔑 Keywords: Combee, prompt learning, parallel scans, augmented shuffle, self-improving agents
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce Combee, a framework that scales parallel prompt learning for self-improving agents, enhancing both efficiency and quality.
🛠️ Research Methods:
– Combee employs parallel scans and an augmented shuffle mechanism, along with a dynamic batch size controller to balance quality and delay.
💬 Research Conclusions:
– Combee achieves up to 17x speedup over previous methods while maintaining or improving accuracy and cost efficiency, as demonstrated through evaluations on AppWorld, Terminal-Bench, Formula, and FiNER.
👉 Paper link: https://huggingface.co/papers/2604.04247

23. RAGEN-2: Reasoning Collapse in Agentic RL
🔑 Keywords: template collapse, mutual information, entropy, SNR-aware filtering, reasoning quality
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research identifies template collapse in multi-turn LLM agents as a hidden failure mode undetectable by entropy, aiming to improve reasoning quality and task performance.
🛠️ Research Methods:
– The study decomposes reasoning quality into within-input diversity and cross-input distinguishability, using mutual information proxies for diagnosis and SNR-Aware Filtering as solutions.
💬 Research Conclusions:
– It concludes that mutual information strongly correlates with final performance, offering a more reliable proxy than entropy. The SNR-Aware Filtering consistently enhances input dependence and task performance across diverse tasks.
👉 Paper link: https://huggingface.co/papers/2604.06268
