AI Native Daily Paper Digest – 20260416

1. Seedance 2.0: Advancing Video Generation for World Complexity
🔑 Keywords: Multi-modal audio-video generation, Seedance 2.0, Joint generation, Editing capabilities, Generation speed
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective is to enhance multi-modal audio-video generation quality and speed through Seedance 2.0.
🛠️ Research Methods:
– Implementing a unified, large-scale architecture supporting multi-modal inputs like text, image, audio, and video.
💬 Research Conclusions:
– Seedance 2.0 demonstrates high performance in audio-video generation, gaining positive reviews from experts and users. It also introduces an accelerated variant for low-latency scenarios.
👉 Paper link: https://huggingface.co/papers/2604.14148

2. RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time
🔑 Keywords: Reward Models, Visual Generation, Reinforcement Learning, Generate-Critique-Refine Loop, Preference-Anchored Rationalization
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to improve visual generation by training reward models that provide multi-dimensional critiques, enhancing both reinforcement learning rewards and output refining processes.
🛠️ Research Methods:
– Introduces the Preference-Anchored Rationalization (PARROT) framework to train reward models without costly rationale annotations, enabling enriched critique through anchored generation, consistency filtering, and distillation.
💬 Research Conclusions:
– Developed RationalRewards model achieves state-of-the-art preference prediction using significantly less training data, enhancing text-to-image and image-editing generators. Its test-time critique-and-refine loop outperforms RL-based fine-tuning, suggesting new potential in structured reasoning.
👉 Paper link: https://huggingface.co/papers/2604.11626

3. OccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models
🔑 Keywords: OccuBench, Language World Models, AI agents, fault injection, task completion
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a comprehensive benchmark, OccuBench, for evaluating AI agents across 100 professional domains using Language World Models.
🛠️ Research Methods:
– Implemented Language World Models for simulating domain-specific environments through LLM-driven tool response generation.
– Introduced a multi-agent synthesis pipeline to produce evaluation instances with controlled difficulty and diversity.
💬 Research Conclusions:
– No single AI model dominates all industries due to distinct occupational capability profiles.
– Implicit faults are more challenging for AI agents than explicit errors due to the lack of clear error signals.
– Larger, newer models, requiring higher reasoning effort, consistently show improved performance.
– The quality of the simulator is essential for reliable evaluations with LWMs.
👉 Paper link: https://huggingface.co/papers/2604.10866

4. From P(y|x) to P(y): Investigating Reinforcement Learning in Pre-train Space
🔑 Keywords: PreRL, NSR-PreRL, Dual Space RL, reasoning horizon, reward-driven online updates
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce PreRL, a novel reinforcement learning approach that applies reward-driven online updates to optimize the marginal distribution P(y) in pre-train space to enhance reasoning capabilities.
🛠️ Research Methods:
– Theoretical and empirical validation of gradient alignment between log P(y) and log P(y|x).
– Implementation of Negative Sample Reinforcement (NSR) within PreRL to enhance reasoning by pruning incorrect reasoning spaces.
💬 Research Conclusions:
– PreRL effectively serves as a surrogate for standard RL and improves reasoning ability significantly.
– The Dual Space RL (DSRL) approach, which combines NSR-PreRL with standard RL fine-tuning, expands reasoning horizons and consistently outperforms baseline models in experiments.
👉 Paper link: https://huggingface.co/papers/2604.14142

5. Target Policy Optimization
🔑 Keywords: Target Policy Optimization, Reinforcement Learning, Policy Gradient, Sparse Reward, Cross-Entropy
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve reinforcement learning performance in sparse reward scenarios by separating policy update decisions from probability assignment.
🛠️ Research Methods:
– Introduced Target Policy Optimization (TPO) which constructs a target distribution based on scored completions and adjusts the policy using cross-entropy.
💬 Research Conclusions:
– TPO matches the performance of existing methods under easy tasks and significantly outperforms them in sparse reward environments.
👉 Paper link: https://huggingface.co/papers/2604.06159
6. LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
🔑 Keywords: Continuous diffusion, LangFlow, language modeling, embedding-space DLMs, Flow Matching
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to demonstrate that continuous diffusion models can match or even rival discrete counterparts in language modeling by leveraging embedding-space flow matching alongside novel training techniques and noise scheduling.
🛠️ Research Methods:
– The authors introduce LangFlow, connecting embedding-space DLMs to Flow Matching via Bregman divergence, and introduce three key innovations: a novel ODE-based NLL bound for evaluation, an information-uniform principle for noise scheduling with a Gumbel-based learnable noise scheduler, and revised training protocols incorporating self-conditioning.
💬 Research Conclusions:
– LangFlow achieves performance levels that match or exceed the best discrete DLMs on perplexity and generative perplexity metrics, proving that continuous diffusion is a promising paradigm for language modeling, and surpassing autoregressive baselines in zero-shot transfer on several benchmarks.
👉 Paper link: https://huggingface.co/papers/2604.11748

7. SemaClaw: A Step Towards General-Purpose Personal AI Agents through Harness Engineering
🔑 Keywords: OpenClaw, SemaClaw, harness engineering, multi-agent framework, human-agent interaction
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop scalable personal AI agents with robust infrastructure for control and trustworthiness using SemaClaw’s multi-agent framework.
🛠️ Research Methods:
– Implementation of a DAG-based two-phase hybrid agent team orchestration method.
– Development of PermissionBridge for behavioral safety.
– Design of a three-tier context management architecture.
– Introduction of an agentic wiki skill for automated knowledge base construction.
💬 Research Conclusions:
– The OpenClaw initiative in 2026 marks a significant evolution in personal AI agents towards scalable systems that are controllable, auditable, and reliable.
– SemaClaw exemplifies the shift in AI engineering, emphasizing the need for harness engineering in the development of general-purpose personal AI agents.
👉 Paper link: https://huggingface.co/papers/2604.11548

8. UI-Zoomer: Uncertainty-Driven Adaptive Zoom-In for GUI Grounding
🔑 Keywords: GUI grounding, adaptive zoom-in, uncertainty quantification, localization, test-time zoom-in
💡 Category: Computer Vision
🌟 Research Objective:
– To improve localization accuracy in GUI grounding by using a training-free adaptive zoom-in framework that selectively triggers zoom-in based on prediction uncertainty.
🛠️ Research Methods:
– Implemented a confidence-aware gate to trigger zoom-in only when localization is uncertain, and used an uncertainty-driven crop sizing module based on prediction variance.
💬 Research Conclusions:
– UI-Zoomer demonstrated consistent improvements on localization accuracy in ScreenSpot-Pro, UI-Vision, and ScreenSpot-v2, achieving performance gains of up to +13.4%, +10.3%, and +4.2% respectively without requiring additional training.
👉 Paper link: https://huggingface.co/papers/2604.14113

9. ReconPhys: Reconstruct Appearance and Physical Attributes from Single Video
🔑 Keywords: ReconPhys, feedforward framework, 3D Gaussian Splatting, monocular video
💡 Category: Computer Vision
🌟 Research Objective:
– ReconPhys proposes a feedforward framework for joint learning of physical attribute estimation and 3D reconstruction using monocular video, aiming to enhance both inference speed and reconstruction quality.
🛠️ Research Methods:
– Utilizes a dual-branch architecture trained with a self-supervised strategy, eliminating the need for ground-truth physics labels.
💬 Research Conclusions:
– Achieves superior performance on synthetic datasets, improving PSNR and reducing Chamfer Distance, while enabling fast inference (<1 second) compared to hours by existing methods.
👉 Paper link: https://huggingface.co/papers/2604.07882

10. Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
🔑 Keywords: Self-Distillation, binary rewards, on-policy self-distillation, token-level self-supervision
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose Self-Distillation Zero (SD-Zero), a model that transforms binary rewards into dense token-level self-supervision, enhancing performance in reasoning tasks.
🛠️ Research Methods:
– SD-Zero trains a single model with dual roles: as a Generator and a Reviser, utilizing on-policy self-distillation to improve token-level supervision without needing an external teacher or high-quality demonstrations.
💬 Research Conclusions:
– SD-Zero outperforms strong baselines in math and code reasoning benchmarks by at least 10%, demonstrating novel characteristics like token-level self-localization and iterative self-evolution.
👉 Paper link: https://huggingface.co/papers/2604.12002

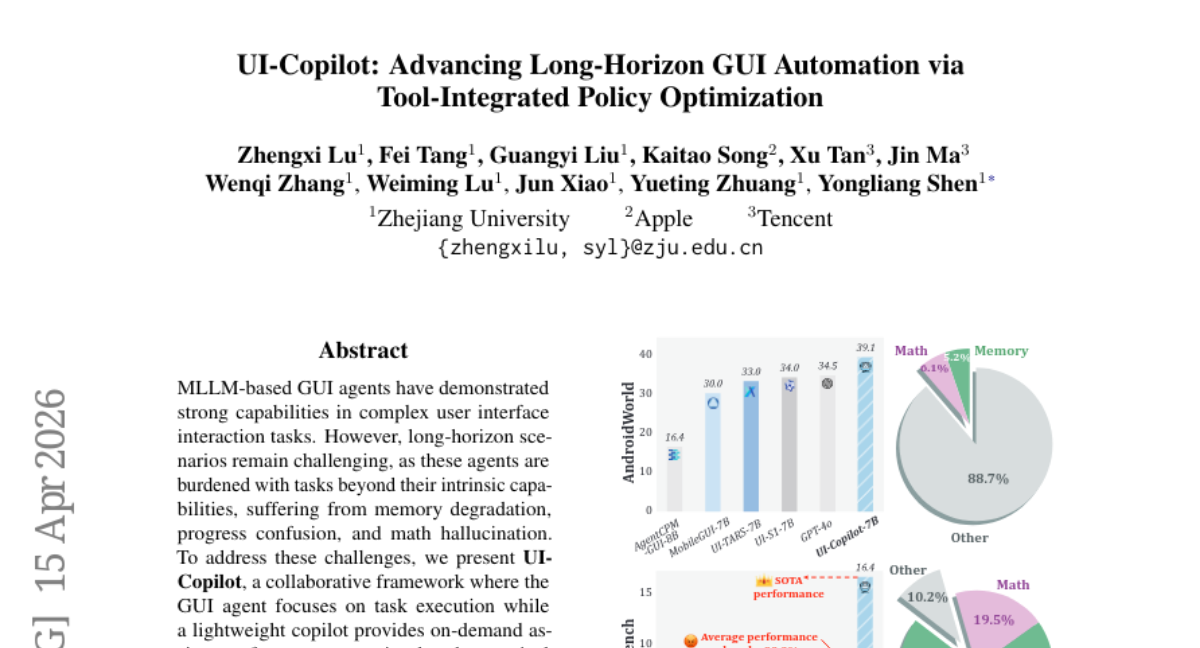
11. UI-Copilot: Advancing Long-Horizon GUI Automation via Tool-Integrated Policy Optimization
🔑 Keywords: UI-Copilot, MLLM-based GUI agents, Memory Decoupling, Tool-Integrated Policy Optimization, Tool Invocation Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to enhance the performance of GUI agents in complex user interface tasks by decoupling memory management and integrating on-demand tool assistance.
🛠️ Research Methods:
– The UI-Copilot framework integrates memory decoupling to separate persistent observations and employs Tool-Integrated Policy Optimization (TIPO) for effective tool selection and task execution through single-turn prediction and on-policy multi-turn rollouts.
💬 Research Conclusions:
– UI-Copilot-7B achieves state-of-the-art performance on challenging benchmarks like MemGUI-Bench, outperforming other GUI agents such as GUI-Owl-7B and UI-TARS-1.5-7B, and shows a significant performance improvement on AndroidWorld, indicating strong generalization capacity in real-world GUI tasks.
👉 Paper link: https://huggingface.co/papers/2604.13822
12. SkVM: Compiling Skills for Efficient Execution Everywhere
🔑 Keywords: SkVM, LLM skills, skill portability, compilation and runtime system, capability-based compilation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enable portable and efficient execution of LLM skills across different models and platforms by treating skills as code and analyzing their capability requirements.
🛠️ Research Methods:
– Analyzed 118,000 skills, inspired by traditional compiler design, treating skills as code and LLMs as heterogeneous processors.
– Developed SkVM, a compilation and runtime system, which performs capability-based compilation, environment binding, and concurrency extraction at compile time.
– Applied JIT code solidification and adaptive recompilation at runtime for performance optimization.
💬 Research Conclusions:
– SkVM significantly improves task completion rates across different models and environments, reducing token consumption by up to 40%.
– Achieves up to 3.2x speedup with enhanced parallelism and a 19-50x latency reduction through code solidification.
👉 Paper link: https://huggingface.co/papers/2604.03088

13. HDR Video Generation via Latent Alignment with Logarithmic Encoding
🔑 Keywords: High dynamic range, generative models, logarithmic encoding, pretrained models, camera-mimicking degradations
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to achieve high dynamic range (HDR) video generation by utilizing pretrained models and aligning them with HDR data without requiring architectural redesign.
🛠️ Research Methods:
– The researchers employed logarithmic encoding to align HDR imagery with the latent space of pretrained models, combined with lightweight fine-tuning. Additionally, they introduced camera-mimicking degradations to help the model infer missing HDR content using learned visual priors.
💬 Research Conclusions:
– The study demonstrates that high-quality HDR video generation is feasible using existing pretrained generative models, provided the representations are aligned correctly, achieving strong results across diverse scenes and lighting conditions.
👉 Paper link: https://huggingface.co/papers/2604.11788

14. ROSE: Retrieval-Oriented Segmentation Enhancement
🔑 Keywords: Novel Emerging Segmentation Task (NEST), Retrieval-Augmented Framework, Multimodal Language Models (MLLMs), ROSE, Visual Prompt Enhancer
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce NEST focusing on segmenting novel and emerging entities that MLLMs struggle with due to lack of up-to-date knowledge.
🛠️ Research Methods:
– Develop a NEST benchmark using an automated pipeline generating news-related data samples. Propose ROSE, a retrieval-oriented framework, to enhance MLLMs with real-time web information, textual, and visual prompts.
💬 Research Conclusions:
– ROSE framework significantly enhances segmentation performance on the NEST benchmark, outperforming existing models by leveraging real-time information retrieval and visual prompts.
👉 Paper link: https://huggingface.co/papers/2604.14147

15. Mobile GUI Agents under Real-world Threats: Are We There Yet?
🔑 Keywords: Mobile GUI agents, large language models, real-world deployment, app content instrumentation, dynamic environment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate the performance of mobile GUI agents powered by large language models in real-world conditions filled with third-party content, which differ from standard benchmarks.
🛠️ Research Methods:
– Introduced a scalable app content instrumentation framework enabling modifications to app content, creating both a dynamic execution environment and a static dataset of varied GUI states.
💬 Research Conclusions:
– The experiments demonstrated significant performance degradation in all examined agents due to third-party content, with a misleading rate of 42.0% in dynamic environments and 36.1% in static settings.
👉 Paper link: https://huggingface.co/papers/2507.04227

16.

17. What do Language Models Learn and When? The Implicit Curriculum Hypothesis
🔑 Keywords: Pretraining, Large Language Models, Scaling Laws, Implicit Curriculum Hypothesis, Model Representations
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to investigate the structured curriculum followed during pretraining of Large Language Models and how model capabilities emerge.
🛠️ Research Methods:
– Designed composable tasks covering retrieval, morphology, coreference, logical reasoning, and mathematics to analyze emergence points across model families from 410M to 13B parameters.
💬 Research Conclusions:
– It was found that the emergence of skills is consistent in a compositional order across different models and can be predicted from model representations, suggesting a structured nature of pretraining.
👉 Paper link: https://huggingface.co/papers/2604.08510

18. InfiniteScienceGym: An Unbounded, Procedurally-Generated Benchmark for Scientific Analysis
🔑 Keywords: InfiniteScienceGym, scientific reasoning, Large language models, verifiable question-answering, evidence-grounded reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The primary goal is to present InfiniteScienceGym, a procedurally generated benchmark for evaluating scientific reasoning in language models, specifically addressing limitations of traditional benchmarks.
🛠️ Research Methods:
– Utilizes a simulator to deterministically generate self-contained scientific repositories, and a privileged QA generator to create both answerable and unanswerable questions, enabling evaluation in a controlled setting.
💬 Research Conclusions:
– Findings indicate that current models do not achieve more than 45% accuracy, with significant challenges remaining in recognizing unanswerable questions. Stronger models are observed to leverage tools more effectively rather than just processing more tokens.
👉 Paper link: https://huggingface.co/papers/2604.13201

19. Do AI Coding Agents Log Like Humans? An Empirical Study
🔑 Keywords: Software Logging, AI Coding Agents, Natural Language Instructions, Log Density, Deterministic Guardrails
💡 Category: AI Systems and Tools
🌟 Research Objective:
– This study seeks to understand how AI coding agents handle software logging and the effectiveness of natural language instructions in this context.
🛠️ Research Methods:
– The researchers conducted an empirical study analyzing 4,550 agentic pull requests across 81 open-source repositories. They compared AI agent logging patterns with human logging baselines and examined the impact of explicit logging instructions.
💬 Research Conclusions:
– AI agents change logging less frequently than humans in the majority of repositories but maintain higher log density when changes occur. Explicit logging instructions are seldom used and largely ineffective, with a 67% non-compliance rate. The study highlights the potential need for deterministic guardrails to ensure consistent logging practices.
👉 Paper link: https://huggingface.co/papers/2604.09409

20. Geometric Context Transformer for Streaming 3D Reconstruction
🔑 Keywords: LingBot-Map, geometric context transformer, attention mechanism, coordinate grounding, dense geometric cues
💡 Category: Computer Vision
🌟 Research Objective:
– To develop LingBot-Map, a feed-forward 3D foundation model for reconstructing scenes from video streams, with a focus on geometric accuracy and temporal consistency.
🛠️ Research Methods:
– Utilization of a geometric context transformer architecture with specialized attention mechanisms, including anchor context, pose-reference window, and trajectory memory, to enhance coordinate grounding and correct long-range drifts.
💬 Research Conclusions:
– The proposed LingBot-Map model achieves superior performance in streaming 3D reconstruction compared to existing methods, maintaining stable real-time performance at 20 FPS and processing long sequences effectively.
👉 Paper link: https://huggingface.co/papers/2604.14141

21. Anthropogenic Regional Adaptation in Multimodal Vision-Language Model
🔑 Keywords: Vision-language models, Anthropogenic Regional Adaptation, GG-EZ, Cultural Relevance, Regional Data Filtering
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Optimize vision-language models for regional contexts while maintaining global performance and enhancing cultural relevance.
🛠️ Research Methods:
– Introduce Anthropogenic Regional Adaptation and GG-EZ methods utilizing regional data filtering and model merging, applied to large vision-language models and tested in a Southeast Asia case study.
💬 Research Conclusions:
– Demonstrated 5-15% gains in cultural relevance without compromising global performance, establishing a foundational paradigm for using vision-language models across diverse regions.
👉 Paper link: https://huggingface.co/papers/2604.11490

22. Narrative-Driven Paper-to-Slide Generation via ArcDeck
🔑 Keywords: Multi-agent framework, Narrative reconstruction, Discourse tree, Iterative multi-agent refinement, ArcBench
💡 Category: AI Systems and Tools
🌟 Research Objective:
– ArcDeck aims to improve paper-to-slide generation by modeling logical flow and using a multi-agent framework to enhance narrative coherence.
🛠️ Research Methods:
– The framework utilizes a discourse tree to parse input, guiding an iterative multi-agent refinement with specialized agents for refining presentation outlines.
💬 Research Conclusions:
– The use of explicit discourse modeling and agent coordination in ArcDeck significantly enhances the narrative flow and coherence, as evidenced by improved results on the ArcBench benchmark.
👉 Paper link: https://huggingface.co/papers/2604.11969
23. MERRIN: A Benchmark for Multimodal Evidence Retrieval and Reasoning in Noisy Web Environments
🔑 Keywords: MERRIN, search-augmented agents, multimodal evidence, multi-hop reasoning, noisy web environments
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce MERRIN as a benchmark to evaluate search-augmented agents in multimodal, noisy web environments by examining their ability to perform multi-hop reasoning and evidence retrieval.
🛠️ Research Methods:
– Evaluation of diverse AI agents powered by ten models in three search settings focusing on the retrieval and reasoning of multimodal evidence under challenging conditions.
💬 Research Conclusions:
– MERRIN proves highly challenging with low overall accuracy, highlighting inefficiencies in current agents, such as over-reliance on text, inefficient resource use, and difficulty handling diverse modalities. This underscores the need for improved agent capabilities in noisy web environments.
👉 Paper link: https://huggingface.co/papers/2604.13418

24. TREX: Automating LLM Fine-tuning via Agent-Driven Tree-based Exploration
🔑 Keywords: Large Language Models, TREX, multi-agent system, search tree, FT-Bench
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to automate the entire lifecycle of Large Language Model training through a multi-agent system called TREX.
🛠️ Research Methods:
– TREX orchestrates collaboration between Researcher and Executor modules to perform tasks like requirement analysis, data research, training strategy formulation, and model evaluation. The process is structured as a search tree allowing for efficient exploration and insights from iterative trials.
💬 Research Conclusions:
– The TREX agent demonstrates consistent optimization of model performance across 10 real-world tasks within the FT-Bench benchmark.
👉 Paper link: https://huggingface.co/papers/2604.14116

25. TIP: Token Importance in On-Policy Distillation
🔑 Keywords: On-policy knowledge distillation, student entropy, teacher-student divergence, Token Importance, entropy-based sampling
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to improve on-policy knowledge distillation token selection by identifying informative tokens using student entropy and teacher-student divergence.
🛠️ Research Methods:
– The research employs a two-axis taxonomy called TIP to categorize token importance based on student entropy and teacher-student divergence. Empirical validation is conducted across various teacher-student pairs and benchmarks.
💬 Research Conclusions:
– Informative tokens are primarily located in positions with either high student entropy or low student entropy with high teacher-student divergence. Using this method, efficient training is achieved, exceeding all-token training and significantly reducing memory usage.
👉 Paper link: https://huggingface.co/papers/2604.14084

26. Free Geometry: Refining 3D Reconstruction from Longer Versions of Itself
🔑 Keywords: Free Geometry, Feed-forward 3D reconstruction models, Self-supervision, LoRA updates, Camera pose accuracy
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to address the challenges of existing feed-forward 3D reconstruction models by introducing a new framework called Free Geometry that allows models to self-evolve at test time for improved reconstruction accuracy.
🛠️ Research Methods:
– The method involves utilizing self-supervised cross-view feature consistency. It enforces consistency between representations from full and partial observations through masking a subset of testing sequence frames. This approach is enhanced by lightweight LoRA updates.
💬 Research Conclusions:
– The implementation of Free Geometry leads to significant improvements in state-of-the-art 3D reconstruction models, resulting in an average enhancement of 3.73% in camera pose accuracy and 2.88% in point map prediction across various benchmark datasets.
👉 Paper link: https://huggingface.co/papers/2604.14048

27. Sema Code: Decoupling AI Coding Agents into Programmable, Embeddable Infrastructure
🔑 Keywords: AI coding framework, decoupled agent engine, npm library, multi-agent collaborative scheduling, SemaClaw
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop an open AI coding framework, Sema Code, that enables shared reasoning capabilities across diverse development environments by decoupling the agent engine from client interfaces.
🛠️ Research Methods:
– Implementation of a modular architecture featuring a standalone npm library and design of eight key mechanisms, including multi-agent collaborative scheduling and adaptive context compression.
💬 Research Conclusions:
– Sema Code successfully transforms a complex agent engine into a shared, programmable core. It demonstrates architectural versatility by powering different product forms like a VSCode extension and a multi-channel messaging gateway, SemaClaw, using the same reasoning kernel.
👉 Paper link: https://huggingface.co/papers/2604.11045

28. Exploration and Exploitation Errors Are Measurable for Language Model Agents
🔑 Keywords: Language Model, Embodied AI, Exploration-Exploitation, Reasoning Models, Harness Engineering
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To design controllable environments to evaluate language model agents in embodied AI tasks and distinguish exploration and exploitation activities.
🛠️ Research Methods:
– Development of a partially observable 2D grid map with tasks defined by Directed Acyclic Graphs (DAG).
– Creation of programmatically adjustable environments to test the balance between exploration and exploitation without relying on the agent’s internal policy.
💬 Research Conclusions:
– Reasoning models outperform other approaches in exploration and exploitation tasks.
– State-of-the-art models show different failure modes, but both exploration and exploitation can be improved through minimal harness engineering.
– Findings highlight the potential for improved embodied AI task performance with targeted environment design and evaluation metrics.
👉 Paper link: https://huggingface.co/papers/2604.13151

29. Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
🔑 Keywords: Memory Transfer Learning, Unified Memory Pools, Abstraction, Meta-Knowledge, Negative Transfer
💡 Category: Machine Learning
🌟 Research Objective:
– To explore the potential of Memory Transfer Learning (MTL) by using unified memory pools from heterogeneous domains to enhance cross-domain code generation.
🛠️ Research Methods:
– Evaluated the performance across six coding benchmarks using four different memory representations, ranging from concrete traces to abstract insights.
💬 Research Conclusions:
– Cross-domain memory utilization improves performance by 3.7% by transferring meta-knowledge rather than specific task-oriented code.
– High-level abstraction generalizes well, while low-level traces often cause negative transfer due to their specificity.
– Transfer effectiveness increases with the memory pool size, and memory can be transferred across different models.
👉 Paper link: https://huggingface.co/papers/2604.14004

30. SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
🔑 Keywords: 3D spatial reasoning, self-evolving framework, Deterministic Geometric Environment, interactive oracles, spatial reasoning benchmarks
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces SpatialEvo, a self-evolving framework for improving 3D spatial reasoning using deterministic geometric environments without relying on model consensus.
🛠️ Research Methods:
– SpatialEvo leverages deterministic ground truth derived from point clouds and camera poses, replacing model consensus with objective physical feedback.
– It formalizes 16 spatial reasoning tasks with explicit geometric validation rules and employs a shared-parameter policy to co-evolve questioner and solver roles under DGE constraints.
💬 Research Conclusions:
– SpatialEvo consistently achieves the highest average scores in 3D spatial reasoning benchmarks, demonstrating effectiveness at both 3B and 7B scales without compromising general visual understanding.
👉 Paper link: https://huggingface.co/papers/2604.14144
