AI Native Daily Paper Digest – 20260511

1. Mean Mode Screaming: Mean–Variance Split Residuals for 1000-Layer Diffusion Transformers
🔑 Keywords: Diffusion Transformers, Mean-Dominated Collapse, Mean Mode Screaming, Mean-Variance Split Residuals
💡 Category: Foundations of AI
🌟 Research Objective:
– To address structural instability in deep Diffusion Transformers caused by Mean Mode Screaming, which leads to mean-dominated collapse at extreme depths.
🛠️ Research Methods:
– Implementing Mean-Variance Split (MV-Split) Residuals to stabilize training and prevent collapses by combining centered residual updates with leaky trunk-mean replacement.
💬 Research Conclusions:
– MV-Split Residuals effectively prevent divergent collapse in a 400-layer DiT, maintaining stable training beyond the baseline approach. The approach was further validated with a 1000-layer DiT, confirming trainability at extreme depths.
👉 Paper link: https://huggingface.co/papers/2605.06169

2. Flow-OPD: On-Policy Distillation for Flow Matching Models
🔑 Keywords: Flow-OPD, Flow Matching, On-Policy Distillation, Manifold Anchor Regularization, Stable Diffusion
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the limitations in Flow Matching text-to-image models by introducing a new framework, Flow-OPD, that improves generation quality and alignment metrics.
🛠️ Research Methods:
– A two-stage alignment approach is used, combining on-policy distillation and manifold anchor regularization. Initial domain-specialized teacher models are cultivated via single-reward GRPO fine-tuning, followed by a Flow-based Cold-Start scheme and a three-step orchestration process for consolidating expertise.
💬 Research Conclusions:
– Flow-OPD achieves significant improvements in GenEval score and OCR accuracy compared to vanilla GRPO, enhancing image fidelity and human-preference alignment. The framework showcases a ‘teacher-surpassing’ effect, demonstrating its potential as a scalable alignment paradigm for generalist text-to-image models.
👉 Paper link: https://huggingface.co/papers/2605.08063

3. Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
🔑 Keywords: Group-based policy gradient, Listwise Policy Optimization, reinforcement learning, divergence minimization, response simplex
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve training performance and stability in reinforcement learning with verifiable rewards by developing Listwise Policy Optimization.
🛠️ Research Methods:
– This study employs a group-based policy gradient framework, leveraging a common geometric structure through target projection utilizing divergence minimization to optimize the policy.
💬 Research Conclusions:
– Listwise Policy Optimization shows monotonic improvement on listwise objectives, enhances training performance over typical baselines, ensures optimization stability, and maintains response diversity across various reasoning tasks and LLM backbones.
👉 Paper link: https://huggingface.co/papers/2605.06139

4. Beyond Retrieval: A Multitask Benchmark and Model for Code Search
🔑 Keywords: CoREB, code retrieval, reranking, embedding models, code-to-code retrieval
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce CoREB, a new benchmark addressing limitations in existing code search datasets, focusing on multitask evaluation and reranking capabilities.
🛠️ Research Methods:
– Developed CoREB from rewritten LiveCodeBench problems in five languages with graded relevance judgments.
– Benchmarked eleven embedding models and five rerankers across text-to-code, code-to-text, and code-to-code tasks.
💬 Research Conclusions:
– Code-specialized embeddings outperform general encoders for code-to-code retrieval but no model excels across all tasks.
– Developer-style short keyword queries lead to poor performance across models.
– Off-the-shelf rerankers show asymmetry across tasks; however, the fine-tuned CoREB-Reranker consistently improves performance across all tasks.
👉 Paper link: https://huggingface.co/papers/2605.04615

5. HumanNet: Scaling Human-centric Video Learning to One Million Hours
🔑 Keywords: HumanNet, embodied intelligence, vision-language-action, egocentric video, human-centric
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce HumanNet, a large-scale human-centric video dataset designed to enhance training of vision-language-action models by replacing robot data with egocentric human video.
🛠️ Research Methods:
– Development of HumanNet as a dataset incorporating various perspectives of human interactions, including fine-grained activities and diverse environments with interaction-centric annotations, enabling enhanced representation learning and activity understanding.
💬 Research Conclusions:
– Controlled experiments demonstrate that HumanNet’s egocentric human video can effectively substitute for robot data, providing a scalable and cost-effective solution for embodied foundation models.
👉 Paper link: https://huggingface.co/papers/2605.06747
6. UniPrefill: Universal Long-Context Prefill Acceleration via Block-wise Dynamic Sparsification
🔑 Keywords: UniPrefill, vLLM, Long-Context Inference, Continuous Batching, Prefill-Decode Co-processing
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main objective of this study is to develop UniPrefill, a prefill acceleration framework to enhance the efficiency and integration of long-context inference across diverse model architectures, especially within modern inference engines like vLLM.
🛠️ Research Methods:
– UniPrefill operates as a continuous batching operator while extending vLLM’s scheduling strategy to support prefill-decode co-processing and tensor parallelism, allowing for seamless integration and improved computational speed at the token level.
💬 Research Conclusions:
– UniPrefill achieves up to 2.1x speedup in Time-To-First-Token (TTFT), with increasingly pronounced performance improvements as the number of concurrent requests grows, highlighting its effectiveness in accelerating long-context inference.
👉 Paper link: https://huggingface.co/papers/2605.06221

7. AEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Credit Assignment, Entropy Dynamics, Exploration-Exploitation Trade-off, Response-Level Uncertainty
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research introduces a supervision-free method for credit assignment in RL to enhance exploration-exploitation balance and task performance in language model agents.
🛠️ Research Methods:
– The method adaptively modulates entropy dynamics at the response level in RL training to align with the effective action granularity of LLM agents, using a practical response-level uncertainty proxy.
💬 Research Conclusions:
– Experiments demonstrate that the proposed method improves on strong RL baselines, with noted gains when integrated into a state-of-the-art software-engineering RL framework.
👉 Paper link: https://huggingface.co/papers/2605.00425

8. MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
🔑 Keywords: Sparse Attention, Mixture-of-Experts, Long Contexts, Query Heads, Computational Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to replace the dense token-wise indexing in sparse attention with MISA (Mixture of Indexer Sparse Attention) to reduce computational costs while maintaining performance for long contexts.
🛠️ Research Methods:
– MISA uses a routed mixture-of-experts approach to create a query-dependent pool of active heads, optimizing only those heads through a lightweight router that employs block-level statistics, thus minimizing the token-level scoring cost.
💬 Research Conclusions:
– MISA matches the performance of dense DSA indexers on LongBench and GLM-5 with significantly fewer active heads, improves computational efficiency up to 3.82 times on specific hardware, and retains more than 92% of token selections by DSA per layer.
👉 Paper link: https://huggingface.co/papers/2605.07363

9. MatryoshkaLoRA: Learning Accurate Hierarchical Low-Rank Representations for LLM Fine-Tuning
🔑 Keywords: MatryoshkaLoRA, Low-Rank Adaptation, Dynamic Rank Selection, Hierarchical Low-Rank Representations, AURAC
💡 Category: Machine Learning
🌟 Research Objective:
– The research aims to introduce MatryoshkaLoRA, a hierarchical low-rank adaptation framework that dynamically adjusts rank selection to improve accuracy-performance trade-offs over existing methods.
🛠️ Research Methods:
– The framework involves inserting a fixed diagonal matrix between existing adapters to scale sub-ranks appropriately and ensures efficient embedding of gradient information across all hierarchical ranks. The research proposes a new evaluation metric, Area Under the Rank Accuracy Curve (AURAC), for assessing performance.
💬 Research Conclusions:
– MatryoshkaLoRA achieves more accurate hierarchical low-rank representations compared to prior rank-adaptive approaches, providing superior accuracy-performance trade-offs across evaluated datasets.
👉 Paper link: https://huggingface.co/papers/2605.07850

10. What if AI systems weren’t chatbots?
🔑 Keywords: Conversational Chatbots, Sociotechnical Configuration, AI Ethics, Labor Displacement, Environmental Costs
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The paper investigates the sociotechnical implications of AI’s focus on conversational chatbot interfaces and their widespread adoption.
🛠️ Research Methods:
– An analytical approach examining the effects of normalizing chatbot interactions on social, economic, and environmental aspects.
💬 Research Conclusions:
– Chatbot-based systems often fail to meet complex user needs, influence patterns of work and learning, contribute to deskilling, and have broader societal impacts such as labor displacement and increased economic concentration. The paper advocates for AI development that embraces pluralistic system design and task-specific tools, highlighting the necessity for accountability and sustainability.
👉 Paper link: https://huggingface.co/papers/2605.07896

11. STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal Generation
🔑 Keywords: Autoregressive Normalizing Flows, Transformer, Multimodal Generation, Causal Mask, KV-cache
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enable unified multimodal generation systems that can seamlessly handle interleaved text and image sequences without structural mismatches.
🛠️ Research Methods:
– The study utilizes autoregressive normalizing flows based on Transformer architecture, specifically through the introduction of STARFlow2 built on the Pretzel architecture with shared causal masking and KV-cache mechanisms.
💬 Research Conclusions:
– The findings demonstrate that autoregressive normalizing flows offer strong performance in both image generation and multimodal understanding, validating their potential as a foundational model for unified multimodal modeling.
👉 Paper link: https://huggingface.co/papers/2605.08029

12. UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
🔑 Keywords: Self-distillation, Autoregressive Language Models, UniSD, Training Stability, Efficient Adaptation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically study and enhance the adaptation of autoregressive language models using the self-distillation framework UniSD.
🛠️ Research Methods:
– Integration of mechanisms including multi-teacher agreement, EMA teacher stabilization, token-level contrastive learning, feature matching, and divergence clipping within the UniSD framework.
💬 Research Conclusions:
– UniSD effectively identifies factors that improve self-distillation over static imitation and highlights how components interact across tasks. The integrated pipeline, UniSDfull, achieves significant performance improvements, demonstrating self-distillation as a practical approach for efficient LLM adaptation without external teachers.
👉 Paper link: https://huggingface.co/papers/2605.06597

13. What Matters for Diffusion-Friendly Latent Manifold? Prior-Aligned Autoencoders for Latent Diffusion
🔑 Keywords: latent manifold, diffusion models, Prior-Aligned AutoEncoder, latent space, generative modeling
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to explore latent manifold properties in diffusion models and proposes a Prior-Aligned AutoEncoder (PAE) to optimize latent space for enhanced generative modeling.
🛠️ Research Methods:
– The study involves constructing controlled tokenizer variants to identify key properties of a diffusion-friendly latent manifold, including coherent spatial structure, local continuity, and global semantics.
– It introduces PAE, which uses refined priors and perturbation-based regularization to explicitly shape the latent manifold.
💬 Research Conclusions:
– The findings indicate that organizing the latent manifold enhances generative modeling quality, with PAE achieving improvements in training efficiency and generation quality, establishing a new state-of-the-art performance on ImageNet 256×256.
👉 Paper link: https://huggingface.co/papers/2605.07915

14. Fast Byte Latent Transformer
🔑 Keywords: Byte Latent Transformer, BLT Diffusion, Speculative Decoding, Inference Procedure, Byte-Level Language Models
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the research is to address the slow byte-by-byte autoregressive generation in byte-level language models by introducing new training and generation techniques.
🛠️ Research Methods:
– Introduction of BLT Diffusion (BLT-D), which uses block-wise diffusion objectives for faster parallel processing.
– Development of two extensions: BLT Self-speculation and BLT Diffusion+Verification, to enhance generation quality while balancing speed.
💬 Research Conclusions:
– The new methods significantly reduce memory-bandwidth cost and logistical barriers, improving the practical use of byte-level language models in generative tasks.
👉 Paper link: https://huggingface.co/papers/2605.08044

15. ModelLens: Finding the Best for Your Task from Myriads of Models
🔑 Keywords: ModelLens, leaderboard interactions, unified framework, model recommendation, performance-aware latent space
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop ModelLens, a unified framework for recommending models in real-world scenarios by leveraging public leaderboard data.
🛠️ Research Methods:
– Utilized a performance-aware latent space to rank unseen models on unseen datasets without direct evaluation on the target dataset.
💬 Research Conclusions:
– Demonstrated that ModelLens surpasses existing baselines, improving routing methods by up to 81% across various QA benchmarks, and generalizing well to both text and vision-language tasks.
👉 Paper link: https://huggingface.co/papers/2605.07075

16. IntentGrasp: A Comprehensive Benchmark for Intent Understanding
🔑 Keywords: IntentGrasp, intent understanding, Large Language Model, benchmark, Intentional Fine-Tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to introduce IntentGrasp as a benchmark to evaluate the intent understanding capability of large language models (LLMs).
🛠️ Research Methods:
– IntentGrasp is derived from 49 corpora spanning 12 domains and involves curation, contextualization, and task unification to form a training set and two evaluation sets.
– Extensive evaluations were conducted on 20 LLMs using IntentGrasp, followed by Intentional Fine-Tuning for improving the models’ performance.
💬 Research Conclusions:
– The LLMs demonstrated poor performance on IntentGrasp, with most models scoring below expectation.
– Intentional Fine-Tuning significantly improved the performance across evaluation sets and showed strong cross-domain generalizability.
– The study presents Intentional Fine-Tuning as a promising approach to enhance intent understanding, aiming for more capable and safe AI assistants.
👉 Paper link: https://huggingface.co/papers/2605.06832

17. SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
🔑 Keywords: Speculative decoding, SpecBlock, AI-generated summary, Autoregressive drafters, Path dependence
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces SpecBlock, a block-iterative drafter that enhances LLM inference speed and maintains accuracy by combining path dependence with economical drafting techniques.
🛠️ Research Methods:
– Utilizes a block-based approach where each drafter forward provides multiple dependent positions, enhancing the draft tree with iterative block expansion while implementing mechanisms for path dependence.
– Incorporates a co-trained rank head and valid-prefix mask for more efficient and accurate drafting.
💬 Research Conclusions:
– SpecBlock achieves a mean speedup improvement of 8-13% over EAGLE-3 at significantly lower drafting costs, and further cost-aware adaptations enhance performance gain to 11-19%.
👉 Paper link: https://huggingface.co/papers/2605.07243

18. LiVeAction: a Lightweight, Versatile, and Asymmetric Neural Codec Design for Real-time Operation
🔑 Keywords: Lightweight neural codec, Rate-distortion performance, FFT-like structure, Variance-based rate penalty, Resource-constrained devices
💡 Category: Generative Models
🌟 Research Objective:
– To develop a lightweight neural codec architecture that improves rate-distortion performance for resource-constrained devices by using an FFT-like structure and variance-based rate penalty.
🛠️ Research Methods:
– Implemented an FFT-like structure to reduce the complexity of the encoder and replace adversarial and perceptual losses with a variance-based rate penalty to accommodate arbitrary signal modalities.
💬 Research Conclusions:
– The proposed architecture, LiVeAction, achieves superior rate-distortion performance compared to existing generative tokenizers and remains practical for deployment on low-power sensors.
👉 Paper link: https://huggingface.co/papers/2605.06628

19. Empirical Evidence for Simply Connected Decision Regions in Image Classifiers
🔑 Keywords: Decision regions, Path connected, Simply connected, Quad-mesh filling procedure, Coons patches
💡 Category: Foundations of AI
🌟 Research Objective:
– To investigate whether closed loops inside decision regions in deep neural networks can be contracted without leaving the region, thus exploring their simple connectivity.
🛠️ Research Methods:
– An iterative quad-mesh filling procedure is used to construct a label-preserving surface within the decision region, connecting it to Coons patches for geometric interpolation analysis.
💬 Research Conclusions:
– The study provides empirical evidence supporting that decision regions in deep neural networks are not only path connected but also simply connected.
👉 Paper link: https://huggingface.co/papers/2605.06380

20. Who Prices Cognitive Labor in the Age of Agents? Compute-Anchored Wages
🔑 Keywords: AI agents, Cognitive labor, Compute capital, Wage-setting, Factor-pricing framework
💡 Category: Foundations of AI
🌟 Research Objective:
– To challenge the conventional view of AI agents as labor substitutes by proposing a new economic framing where AI agents are a production technology that converts compute capital into cognitive labor.
🛠️ Research Methods:
– Application of a classic factor-pricing framework to derive a Compute-Anchored Wage (CAW) bound, and use of constant elasticity of substitution (CES) aggregation to differentiate between substitutable and complementary tasks.
💬 Research Conclusions:
– The equilibrium wage for cognitive labor is increasingly governed by the compute capital market rather than traditional labor markets, shifting the price-setting mechanism due to AI agents being conceptualized as a production technology.
👉 Paper link: https://huggingface.co/papers/2605.05558

21. CASCADE: Case-Based Continual Adaptation for Large Language Models During Deployment
🔑 Keywords: Deployment-time learning, Large language models, Episodic memory, Contextual bandit, Continual Adaptation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce deployment-time learning (DTL) as an additional stage in the lifecycle of large language models (LLMs), enabling them to adapt and improve during deployment without modifying model parameters.
🛠️ Research Methods:
– Development of the CASCADE framework, which leverages episodic memory and formulates experience reuse as a contextual bandit problem, allowing for effective exploration-exploitation trade-offs and providing long-term no-regret guarantees.
💬 Research Conclusions:
– CASCADE framework demonstrated a 20.9% improvement in macro-averaged success rate across 16 diverse tasks compared to zero-shot prompting and outperformed other gradient-based and memory-based approaches, establishing a foundation for continually improving AI systems.
👉 Paper link: https://huggingface.co/papers/2605.06702

22. PrefixGuard: From LLM-Agent Traces to Online Failure-Warning Monitors
🔑 Keywords: PrefixGuard, trace analysis, prefix-based risk scoring, StepView induction, event abstraction
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce PrefixGuard, a framework for online monitoring of large language model (LLM) agents through trace analysis and prefix-based risk scoring.
🛠️ Research Methods:
– Develop a trace-to-monitor framework with an offline StepView induction step followed by supervised monitor training to induce deterministic typed-step adapters from raw trace samples.
💬 Research Conclusions:
– PrefixGuard demonstrates strong performance across multiple benchmark tasks, achieving notable improvements over raw-text controls. Despite LLM judges being weaker under the same protocol, PrefixGuard offers actionable early alerts with explicit diagnostics to support effective interventions.
👉 Paper link: https://huggingface.co/papers/2605.06455

23. R^3-SQL: Ranking Reward and Resampling for Text-to-SQL
🔑 Keywords: R^3-SQL, Text-to-SQL, unified reward, agentic resampling, execution accuracy
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to address inconsistencies in scoring functionally equivalent SQL queries and to improve candidate recall in Text-to-SQL systems.
🛠️ Research Methods:
– Introduces R^3-SQL, a framework that employs unified reward ranking by grouping candidates by execution result and combining pairwise preference with pointwise utility.
– Utilizes agentic resampling to enhance candidate pool by selectively resampling when correct SQL is likely absent.
💬 Research Conclusions:
– R^3-SQL achieves 75.03 execution accuracy on BIRD-dev, establishing a new state of the art, with consistent improvements across five benchmarks.
👉 Paper link: https://huggingface.co/papers/2604.25325

24. Shallow Prefill, Deep Decoding: Efficient Long-Context Inference via Layer-Asymmetric KV Visibility
🔑 Keywords: SPEED, KV-visibility policy, long-context inference, Llama-3.1-8B, prompt tokens
💡 Category: Natural Language Processing
🌟 Research Objective:
– To reduce long-context inference costs in decoder-only language models by implementing a phase-asymmetric KV-visibility policy called SPEED.
🛠️ Research Methods:
– Introduced Shallow Prefill, dEEp Decode (SPEED) that materializes non-anchor prompt-token KV states only in lower layers.
– Conducted a controlled Llama-3.1-8B instruction-tuning study comparing the effectiveness of using only 75% of layers for prefill tokens.
💬 Research Conclusions:
– SPEED maintains benchmark quality while reducing long-context costs and improving efficiency metrics like TTFT and TPOT.
– Demonstrates that long-context prompt tokens do not need to persist as full-depth KV-cache objects if Decode-phase tokens remain full-depth.
👉 Paper link: https://huggingface.co/papers/2605.06105

25. Sparse Autoencoders as Plug-and-Play Firewalls for Adversarial Attack Detection in VLMs
🔑 Keywords: SAEgis, adversarial attacks, Vision-Language Models, sparse autoencoders, cross-domain generalization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce SAEgis, a framework for detecting adversarial attacks on Vision-Language Models using sparse autoencoders.
🛠️ Research Methods:
– Insert sparse autoencoder modules into pretrained Vision-Language Models, trained with reconstruction objectives to capture attack-relevant signals naturally.
💬 Research Conclusions:
– SAEgis achieves robust performance across in-domain, cross-domain, and cross-attack settings without requiring additional training, enhancing the safety of real-world VLM systems.
👉 Paper link: https://huggingface.co/papers/2605.07447

26. BalCapRL: A Balanced Framework for RL-Based MLLM Image Captioning
🔑 Keywords: Image captioning, multimodal large language models, reinforcement learning, continuous multi-objective reward formulation, GDPO-style
💡 Category: Computer Vision
🌟 Research Objective:
– The primary goal is to develop a balanced reinforcement learning framework for image captioning that optimizes correctness, coverage, and linguistic quality, surpassing the performance of existing methods.
🛠️ Research Methods:
– The study employs a continuous multi-objective reward formulation with GDPO-style reward-decoupled normalization and length-conditional reward masking to enhance captioning performance.
💬 Research Conclusions:
– The proposed method consistently improves caption quality with significant gains in various models, evidencing enhancements of +13.6 in DCScore, +9.0 in CaptionQA, and +29.0 in CapArena.
👉 Paper link: https://huggingface.co/papers/2605.07394

27. Delta-Adapter: Scalable Exemplar-Based Image Editing with Single-Pair Supervision
🔑 Keywords: Delta-Adapter, single-pair supervision, semantic delta, pre-trained vision encoder, Perceiver-based adapter
💡 Category: Computer Vision
🌟 Research Objective:
– To improve image editing accuracy and generalization through a method called Delta-Adapter, which enables editing with single-pair supervision by utilizing semantic deltas extracted from pre-trained vision encoders.
🛠️ Research Methods:
– Employed Delta-Adapter by using a pre-trained vision encoder to extract semantic deltas and integrating them into an image editing model via a Perceiver-based adapter. Introduced semantic delta consistency loss to enhance transformation fidelity.
💬 Research Conclusions:
– Delta-Adapter demonstrates consistent improvement in editing accuracy and content consistency, effectively generalizing to both seen and unseen editing tasks over existing baselines.
👉 Paper link: https://huggingface.co/papers/2605.07940

28.

29. Trajectory as the Teacher: Few-Step Discrete Flow Matching via Energy-Navigated Distillation
🔑 Keywords: Discrete Flow Matching, Trajectory-Shaped Guidance, Distillation, Perplexity, Language Modeling
💡 Category: Natural Language Processing
🌟 Research Objective:
– Improve text generation efficiency by replacing stochastic jumps with trajectory-shaped guidance to achieve better performance with reduced computational requirements.
🛠️ Research Methods:
– Utilize Trajectory-Shaped Discrete Flow Matching (TS-DFM) which employs a lightweight energy compass for guided navigation, evaluating candidate continuations at each midpoint during training.
💬 Research Conclusions:
– TS-DFM achieves superior perplexity compared to baseline discrete-generation methods, is notably faster, and effective across different source distributions and evaluators.
👉 Paper link: https://huggingface.co/papers/2605.07924

30. CPCANet: Deep Unfolding Common Principal Component Analysis for Domain Generalization
🔑 Keywords: Domain Generalization, Common Principal Component Analysis, zero-shot transfer, domain-invariant subspace, invariant learning
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to create a structured domain-invariant subspace using Common Principal Component Analysis to enhance domain generalization under out-of-distribution conditions.
🛠️ Research Methods:
– CPCANet employs the iterative Flury-Gautschi algorithm within differentiable neural layers, integrating statistical properties of CPCA into a trainable framework to identify shared subspaces across domains.
💬 Research Conclusions:
– CPCANet achieves state-of-the-art performance in zero-shot transfer without the need for architecture-specific tuning, making it a simple and efficient solution for learning robust representations amid distribution shifts.
👉 Paper link: https://huggingface.co/papers/2605.05136

31. Rubric-based On-policy Distillation
🔑 Keywords: On-policy distillation, teacher logits, structured semantic rubrics, sample efficiency, rubric-based OPD
💡 Category: Foundations of AI
🌟 Research Objective:
– To demonstrate the effectiveness of rubric-based OPD as a scalable and black-box-compatible alternative to traditional logit-based methods for model alignment.
🛠️ Research Methods:
– Introduction of ROPD, a framework using structured semantic rubrics from teacher-student contrasts to score student rollouts for on-policy optimization.
💬 Research Conclusions:
– ROPD achieves up to a 10x gain in sample efficiency over advanced logit-based OPD methods, positioning it as a flexible alternative suitable for both proprietary and open-source large language models.
👉 Paper link: https://huggingface.co/papers/2605.07396

32. Learning Visual Feature-Based World Models via Residual Latent Action
🔑 Keywords: Visual world models, Residual Latent Action, RLA World Model, Robot Learning, Video Diffusion
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To introduce a novel world model, RLA-WM, based on Residual Latent Action representations, for predicting future visual features efficiently and for enhancing robot learning techniques.
🛠️ Research Methods:
– Utilized the RLA to predict transitions using flow matching, and developed robot learning methods that leverage the new RLA World Model for policy learning from offline videos.
💬 Research Conclusions:
– RLA-WM outperforms current state-of-the-art methods in both simulation and real-world settings with improved efficiency, and it supports novel robot learning approaches that require no online interaction or handcrafted rewards.
👉 Paper link: https://huggingface.co/papers/2605.07079
33. CGM-JEPA: Learning Consistent Continuous Glucose Monitor Representations via Predictive Self-Supervised Pretraining
🔑 Keywords: Continuous Glucose Monitoring, Self-supervised Pretraining, Cross-Modal, Cohort Generalization, AI in Healthcare
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop a self-supervised pretraining framework (CGM-JEPA) that abstracts continuous glucose monitoring data for better cross-modal and cross-cohort performance by predicting masked latent representations.
🛠️ Research Methods:
– Pretraining on unlabeled CGM data from 228 subjects.
– Evaluation through cross-validation on clinical cohorts in various regimes like cohort generalization and venous-to-CGM transfer.
💬 Research Conclusions:
– X-CGM-JEPA achieves top performance on AUROC across all regimes, significantly exceeding baseline models.
– Introduces a novel distributional objective that enhances performance under modality shift and improves label-aware clustering on sparse venous data.
👉 Paper link: https://huggingface.co/papers/2605.00933

34. Gated QKAN-FWP: Scalable Quantum-inspired Sequence Learning
🔑 Keywords: Quantum-inspired, Fast Weight Programmers, NISQ device compatibility, Scalar-gated update, Solar cycle forecasting
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– To develop a quantum-inspired fast-weight programming framework using single-qubit circuits that achieves superior forecasting performance with fewer parameters compared to classical recurrent models, while ensuring compatibility with NISQ devices.
🛠️ Research Methods:
– Integration of Fast Weight Programmers (FWPs) with Quantum-inspired Kolmogorov-Arnold Network (QKAN) using single-qubit data re-uploading circuits as nonlinear activation.
– Introduction of a scalar-gated fast-weight update rule with theoretical analysis on adaptive memory kernel, geometric boundedness, and parallelizable gradient paths.
💬 Research Conclusions:
– The proposed framework achieves lower scaled Mean Square Error (MSE), peak amplitude error, and peak timing error in long-horizon solar cycle forecasting compared to traditional recurrent models, including LSTM networks, with significantly fewer parameters.
– The framework is validated on NISQ devices, maintaining high forecasting accuracy, highlighting its scalability, parameter efficiency, and practical applicability in real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2605.06734

35. Rethinking RL for LLM Reasoning: It’s Sparse Policy Selection, Not Capability Learning
🔑 Keywords: Reinforcement Learning, ReasonMaxxer, Large Language Models, Token-Level Analysis, Entropy
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to investigate whether the reinforcement learning (RL) optimization loop is necessary for correcting uncertainties at specific decision points in large language models.
🛠️ Research Methods:
– The authors conducted a token-level analysis across various model families and RL algorithms to assess the impact of RL on decision-making and utilized entropy-gated decision point corrections through the proposed ReasonMaxxer method.
💬 Research Conclusions:
– It was concluded that RL primarily corrects uncertainty at key decision points rather than acquiring new capabilities, and ReasonMaxxer can achieve similar or better performance compared to full RL with significantly reduced training costs.
👉 Paper link: https://huggingface.co/papers/2605.06241

36. Discovering Reinforcement Learning Interfaces with Large Language Models
🔑 Keywords: Automated reinforcement learning interface discovery, LLM-guided evolutionary algorithms, observation mappings, reward functions, co-design
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to automate the discovery of reinforcement learning task interfaces, particularly focusing on generating both observation mappings and reward functions from raw simulator states using LLM-guided evolutionary algorithms.
🛠️ Research Methods:
– The research introduces LIMEN, an evolutionary framework guided by large language models (LLMs), which iteratively refines candidate interfaces using policy training feedback across various control domains, including novel discrete gridworld tasks.
💬 Research Conclusions:
– The research demonstrates that the joint evolution of observations and rewards can effectively discover RL interfaces, significantly reducing the need for manual engineering. It highlights that optimizing these components together is crucial, as single-component optimization leads to failures in certain domains.
👉 Paper link: https://huggingface.co/papers/2605.03408

37. Steering Visual Generation in Unified Multimodal Models with Understanding Supervision
🔑 Keywords: Unified multimodal models, Understanding-Oriented Post-Training, generative representations, semantic abstraction, visual regression
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance generative models by integrating comprehension tasks as supervisory signals for better image generation and editing.
🛠️ Research Methods:
– A lightweight framework named Understanding-Oriented Post-Training (UNO) is introduced, treating understanding as both a distinct task and a supervisory signal for generative representations.
💬 Research Conclusions:
– Extensive experiments demonstrate that incorporating understanding as a catalyst can significantly improve the performance of image generation and editing.
👉 Paper link: https://huggingface.co/papers/2605.05781

38. MDN: Parallelizing Stepwise Momentum for Delta Linear Attention
🔑 Keywords: Linear Attention, Momentum DeltaNet, Large Language Models, Stochastic Gradient Descent, Momentum-Based Optimizers
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address challenges in training efficiency and convergence in Linear Attention models using a momentum-based approach.
🛠️ Research Methods:
– Develop a chunkwise parallel algorithm with a stepwise momentum rule.
– Analyze momentum-based recurrence through a dynamical systems perspective with complex conjugate eigenvalues.
💬 Research Conclusions:
– Momentum DeltaNet (MDN) achieves comparable training throughput to existing models and demonstrates consistent performance improvements across benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.05838

39. From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms
🔑 Keywords: Large Language Model, memory mechanisms, continual learning, proactive exploration, cross-trajectory abstraction
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to bridge the gaps between operating systems engineering and cognitive science through a unified evolutionary framework for LLM agent memory mechanisms, structured into three phases: Storage, Reflection, and Experience.
🛠️ Research Methods:
– The paper proposes a formal definition and analysis of the stages of memory mechanisms within LLM-based agents. It focuses on the need for long-range consistency, challenges in dynamic environments, and the goal of continual learning.
💬 Research Conclusions:
– By synthesizing fragmented insights in existing literature, the paper offers design principles and a roadmap for the future development of next-generation LLM agents, highlighting transformative mechanisms like proactive exploration and cross-trajectory abstraction.
👉 Paper link: https://huggingface.co/papers/2605.06716

40. InterLV-Search: Benchmarking Interleaved Multimodal Agentic Search
🔑 Keywords: Interleaved Language-Vision Agentic Search, Multimodal Search, Visual Evidence Seeking, Multimodal Evidence Integration
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research introduces the InterLV-Search benchmark to assess interleaved Language-Vision agentic search, emphasizing the repeated use of both textual and visual evidence.
🛠️ Research Methods:
– The study leverages 2,061 examples across active visual evidence seeking, controlled offline interleaved searching, and open-web searching, constructed through automated and machine-led, human-supervised pipelines.
💬 Research Conclusions:
– Current systems struggle significantly with interleaved multimodal search, evidenced by a best model accuracy below 50%, revealing ongoing challenges in visual evidence seeking, search control, and multimodal evidence integration.
👉 Paper link: https://huggingface.co/papers/2605.07510

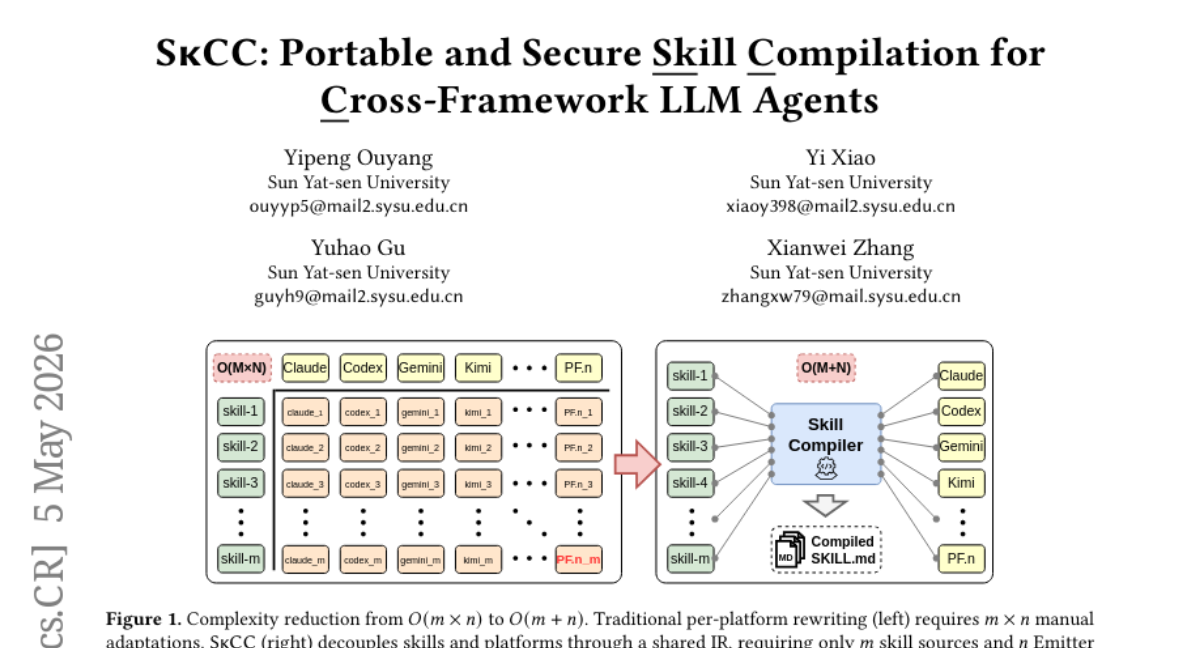
41. SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
🔑 Keywords: SkCC, AI-generated summary, LLM-Agents, SKILL.md, agent frameworks
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces SkCC, a compilation framework designed to enable portable deployment of agent skills across various platforms with improved security and performance.
🛠️ Research Methods:
– SkCC uses a strongly-typed intermediate representation (SkIR) to decouple skill semantics from platform-specific formatting and includes a compile-time Analyzer to enforce security constraints via Anti-Skill Injection.
💬 Research Conclusions:
– Experiments demonstrate that SkCC consistently improves performance and security, increasing pass rates on multiple platforms and achieving substantial runtime token savings.
👉 Paper link: https://huggingface.co/papers/2605.03353
42. Scaling Continual Learning to 300+ Tasks with Bi-Level Routing Mixture-of-Experts
🔑 Keywords: Continual learning, class-incremental learning, pre-trained model, bi-level routing, OmniBenchmark-1K
💡 Category: Machine Learning
🌟 Research Objective:
– To address the challenge of class-incremental learning (CIL) with a novel continual learning framework called CaRE, capable of handling very long task sequences efficiently.
🛠️ Research Methods:
– Introduction of a Bi-Level Routing Mixture-of-Experts (BR-MoE) mechanism, which includes a router selection stage and an expert routing phase to optimize task-specific and expert-based learning processes.
– Presentation of a new dataset, OmniBenchmark-1K, for evaluating CIL performance on extensive task sequences involving hundreds of tasks.
💬 Research Conclusions:
– CaRE exhibits superior performance across various datasets and task configurations, particularly in extensive task sequences ranging from 100 to over 300 non-overlapping tasks, surpassing current baselines by a notable margin.
– The work encourages further exploration into continual learning over extremely prolonged task sequences, offering publicly accessible code and dataset.
👉 Paper link: https://huggingface.co/papers/2602.03473

43. SCOPE: Structured Decomposition and Conditional Skill Orchestration for Complex Image Generation
🔑 Keywords: SCOPE, Semantic Commitments, Conceptual Rift, Specification-Guided Skill Orchestration, Entity-Gated Intent Pass Rate
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the study is to enhance complex visual intent fulfillment in text-to-image generation by maintaining semantic commitments throughout the process.
🛠️ Research Methods:
– The study introduces SCOPE, a specification-guided framework that organizes retrieval, reasoning, and repair skills to uphold semantic commitments, and evaluates it using a human-annotated benchmark, Gen-Arena, equipped with Entity-Gated Intent Pass Rate (EGIP).
💬 Research Conclusions:
– SCOPE significantly improves performance over baselines on Gen-Arena, achieving 0.60 EGIP, and shows strong results on other benchmarks like WISE-V and MindBench, highlighting its effectiveness in persistent commitment tracking for complex image generation.
👉 Paper link: https://huggingface.co/papers/2605.08043

44. Q-RAG: Long Context Multi-step Retrieval via Value-based Embedder Training
🔑 Keywords: Q-RAG, Multi-step retrieval, Reinforcement learning, Embedder model, Long-context benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance large language models’ retrieval capabilities for complex queries by introducing Q-RAG, a multi-step retrieval approach fine-tuned using reinforcement learning.
🛠️ Research Methods:
– The study fine-tunes the Embedder model in a resource-efficient manner using reinforcement learning for multi-step retrieval, offering a new alternative to traditional resource-intensive methods.
💬 Research Conclusions:
– Q-RAG achieves state-of-the-art results on long-context benchmarks BabiLong and RULER, demonstrating its effectiveness and efficiency for open-domain question answering tasks with contexts up to 10 million tokens.
👉 Paper link: https://huggingface.co/papers/2511.07328

45. Normalizing Trajectory Models
🔑 Keywords: Normalizing Trajectory Models, diffusion-based generation, likelihood training, self-distillation, text-to-image benchmarks
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Normalizing Trajectory Models (NTM) to improve diffusion-based generation with exact likelihood training.
🛠️ Research Methods:
– Model each reverse step as a conditional normalizing flow, integrating shallow invertible blocks and a deep parallel predictor for high-quality sample generation in few steps.
💬 Research Conclusions:
– NTM achieves superior performance on text-to-image benchmarks, matching or surpassing existing baselines in just four sampling steps while maintaining exact likelihood over the generative trajectory.
👉 Paper link: https://huggingface.co/papers/2605.08078

46. A^2RD: Agentic Autoregressive Diffusion for Long Video Consistency
🔑 Keywords: A^2RD, Agentic Auto-Regressive Diffusion, long video synthesis, semantic drift, narrative collapse
💡 Category: Generative Models
🌟 Research Objective:
– To address the challenges of synthesizing consistent and coherent long videos by introducing A^2RD, a novel architecture that separates creative synthesis from consistency enforcement.
🛠️ Research Methods:
– Implementation of a closed-loop process with a Retrieve–Synthesize–Refine–Update cycle, utilizing components like Multimodal Video Memory, Adaptive Segment Generation, and Hierarchical Test-Time Self-Improvement.
💬 Research Conclusions:
– A^2RD significantly enhances consistency and narrative coherence compared to existing baselines, achieving improvements of up to 30% in consistency and 20% in narrative coherence on public benchmarks and the novel LVBench-C. Human evaluations confirm improvements in motion and transition smoothness.
👉 Paper link: https://huggingface.co/papers/2605.06924

47. 4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
🔑 Keywords: 4D reasoning, vision-language models, dynamic spatial reasoning, data generation pipeline, Dynamic-Imagery Fine-Tuning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce 4DThinker, a framework enabling vision-language models to perform dynamic spatial reasoning through 4D latent mental imagery.
🛠️ Research Methods:
– Utilize a scalable, annotation-free data generation pipeline to create 4D reasoning data from raw videos.
– Implement Dynamic-Imagery Fine-Tuning (DIFT) for grounding models in dynamic visual semantics.
– Apply 4D Reinforcement Learning (4DRL) with outcome-based rewards for complex reasoning tasks.
💬 Research Conclusions:
– 4DThinker outperforms existing baselines in dynamic spatial reasoning and offers a new approach to 4D reasoning in VLMs.
👉 Paper link: https://huggingface.co/papers/2605.05997

48. Rethinking State Tracking in Recurrent Models Through Error Control Dynamics
🔑 Keywords: Affine recurrent networks, State tracking, Error control, State-space models, Linear Attention
💡 Category: Foundations of AI
🌟 Research Objective:
– The study aims to examine the limitations of affine recurrent networks in achieving robust state tracking and highlight the significance of error control alongside expressive capacity.
🛠️ Research Methods:
– Theoretical analysis and empirical demonstration on group state-tracking tasks are used to understand the failure mechanics of affine recurrent networks in maintaining accurate state tracking.
💬 Research Conclusions:
– Affine recurrent networks fail to correct errors in state-separating subspaces and resort to finite horizon solutions driven by accumulated errors. The study demonstrates that robust state tracking relies not only on the architecture’s expressivity but critically on error control and predicts that tracking collapses when the distinguishability ratio surpasses the readability threshold.
👉 Paper link: https://huggingface.co/papers/2605.07755

49. DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
🔑 Keywords: AI agents, security, red-teaming, simulation environments, attack strategies
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate and enhance AI agent security through a controllable red-teaming platform, DecodingTrust-Agent Platform (DTap).
🛠️ Research Methods:
– Use of DTap to simulate 14 real-world domains and over 50 simulation environments.
– Introduction of DTap-Red, an autonomous red-teaming agent, to systematically explore injection vectors and discover effective attack strategies.
💬 Research Conclusions:
– Large-scale evaluations using DTap-Bench dataset reveal systematic vulnerability patterns in AI agents.
– Insights are provided for developing more secure next-generation AI agents.
👉 Paper link: https://huggingface.co/papers/2605.04808

50. TextLDM: Language Modeling with Continuous Latent Diffusion
🔑 Keywords: TextLDM, Representation Alignment, Diffusion Transformers, GPT-2, OpenWebText2
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to adapt visual latent diffusion transformers for language modeling by mapping discrete tokens to continuous latents and utilizing representation alignment for enhanced text generation quality.
🛠️ Research Methods:
– TextLDM employs a Transformer-based VAE to map tokens to latents, enhanced by Representation Alignment with a frozen pretrained language model. Standard Diffusion Transformers perform flow matching in the latent space.
💬 Research Conclusions:
– TextLDM, trained on OpenWebText2, significantly outperforms prior diffusion language models, matching GPT-2 under similar conditions. This demonstrates the effectiveness of transferring the visual DiT recipe to language for multimodal generation and understanding.
👉 Paper link: https://huggingface.co/papers/2605.07748

51. Anisotropic Modality Align
🔑 Keywords: Modality Gap, Multimodal Model, Anisotropic Geometric Correction, Semantic Geometry, Modality Alignment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to address the Modality Gap in multimodal models through an Anisotropic Geometric Correction framework for effective unpaired modality alignment.
🛠️ Research Methods:
– The study revisits the geometric nature of the modality gap and proposes the AnisoAlign framework, which focuses on anisotropic modality gap alignment by aligning with the target-modality distribution while preserving the source modality’s semantic structure.
💬 Research Conclusions:
– Experiments demonstrate that the proposed AnisoAlign framework benefits both geometric diagnostics and text-only multimodal large language model training, transforming the modality gap from an empirical observation into a correctable structured geometric phenomenon.
👉 Paper link: https://huggingface.co/papers/2605.07825

52. LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
🔑 Keywords: AutoTTS, Test-time scaling, controller synthesis, reasoning trajectories, probe signals
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to automate the discovery of test-time scaling (TTS) strategies by developing AutoTTS, an environment-driven framework that replaces hand-crafted heuristics with automatic strategy discovery.
🛠️ Research Methods:
– AutoTTS operates by formulating TTS as controller synthesis over reasoning trajectories and probe signals. It introduces beta parameterization and fine-grained execution trace feedback to optimize strategy discovery.
💬 Research Conclusions:
– Experiment results demonstrate that AutoTTS-discovered TTS strategies outperform manually designed baselines, enhancing the accuracy-cost tradeoff efficiently across various benchmarks, and generalizing well across different model scales at a low discovery cost.
👉 Paper link: https://huggingface.co/papers/2605.08083

53. HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
🔑 Keywords: HyperEyes, Parallel Multimodal Search, Reinforcement Learning, Inference Efficiency, Dual-Grained Efficiency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a parallel multimodal search agent, HyperEyes, that performs concurrent entity searches while enhancing inference efficiency.
🛠️ Research Methods:
– HyperEyes is trained using a Parallel-Amenable Data Synthesis Pipeline and a Dual-Grained Efficiency-Aware Reinforcement Learning framework. Additionally, specific benchmarks (IMEB) are introduced to evaluate both accuracy and efficiency.
💬 Research Conclusions:
– HyperEyes-30B achieves significant improvements, surpassing the strongest comparable open-source agent by 9.9% in accuracy with a 5.3x reduction in tool-call rounds on average.
👉 Paper link: https://huggingface.co/papers/2605.07177

54. MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
🔑 Keywords: MACE-Dance, AI-generated content (AIGC), music-driven dance generation, Mixture-of-Experts, diffusion models
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal is to create a high-quality music-driven dance video generation framework, MACE-Dance, that excels in producing realistic human motion and visual appearance by integrating cascaded Mixture-of-Experts and diffusion models.
🛠️ Research Methods:
– Utilization of a hybrid architecture consisting of Mixture-of-Experts and a diffusion model within the Motion Expert to convert music into 3D motion, ensuring kinematic plausibility and artistic expressiveness.
– Adoption of a decoupled kinematic-aesthetic fine-tuning strategy for the Appearance Expert to maintain visual identity and achieve state-of-the-art performance in pose-driven image animation.
💬 Research Conclusions:
– MACE-Dance significantly enhances the quality of music-driven dance video generation and sets a new state-of-the-art benchmark by effectively capturing both motion and appearance aspects, supported by a curated large-scale dataset and an innovative evaluation protocol.
👉 Paper link: https://huggingface.co/papers/2512.18181
