AI Native Daily Paper Digest – 20260512

1. Qwen-Image-2.0 Technical Report
🔑 Keywords: Qwen-Image-2.0, high-fidelity synthesis, precise image editing, Multimodal Diffusion Transformer
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Qwen-Image-2.0, unifying high-fidelity image generation and editing within a single framework, addressing challenges in ultra-long text rendering and multilingual typography.
🛠️ Research Methods:
– Incorporates Qwen3-VL as a condition encoder and a Multimodal Diffusion Transformer for joint modeling, supported by large-scale data curation and a customized multi-stage training pipeline.
💬 Research Conclusions:
– Qwen-Image-2.0 improves multilingual text fidelity, typography, and photorealistic generation, significantly outperforming previous models in generation and editing capabilities, enhancing its reliability and practicality as an image generation foundation model.
👉 Paper link: https://huggingface.co/papers/2605.10730

2. CollabVR: Collaborative Video Reasoning with Vision-Language and Video Generation Models
🔑 Keywords: Vision-Language Models, Video Generation Models, Closed-loop Framework, Visual Reasoning, Step-level Granularity
💡 Category: Generative Models
🌟 Research Objective:
– Propose a closed-loop framework, CollabVR, to enhance visual reasoning in video generation by integrating vision-language models with video generation models.
🛠️ Research Methods:
– The framework couples VLMs and VGMs at step-level granularity, enabling real-time failure detection and correction to improve performance on visual reasoning tasks.
💬 Research Conclusions:
– CollabVR demonstrates significant improvements over existing VGMs on benchmark tasks, particularly in challenging scenarios, and enhances models even further when combined with reasoning fine-tuning.
👉 Paper link: https://huggingface.co/papers/2605.08735

3. PaperFit: Vision-in-the-Loop Typesetting Optimization for Scientific Documents
🔑 Keywords: Visual Typesetting Optimization, vision-in-the-loop agent, document automation, LaTeX, PaperFit
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to address the transformation of error-free compilable LaTeX documents into visually polished and publication-ready PDFs using Visual Typesetting Optimization (VTO).
🛠️ Research Methods:
– Introduces PaperFit, a vision-in-the-loop agent that iteratively renders pages, diagnoses layout defects, and applies constrained repairs through iterative visual verification and source-level revision.
💬 Research Conclusions:
– Extensive experiments show PaperFit significantly outperforms baselines, establishing vision-in-the-loop optimization as a necessary stage in the document automation pipeline for converting compilable sources into professional-ready PDFs.
👉 Paper link: https://huggingface.co/papers/2605.10341

4. WorldReasonBench: Human-Aligned Stress Testing of Video Generators as Future World-State Predictors
🔑 Keywords: WorldReasonBench, WorldRewardBench, video generation, world simulators, reasoning quality
💡 Category: Generative Models
🌟 Research Objective:
– Introduce WorldReasonBench and WorldRewardBench as benchmarks to evaluate video generation models’ reasoning abilities about world-state evolution.
🛠️ Research Methods:
– Develop WorldReasonBench with 436 test cases and structured QA annotations covering multiple reasoning dimensions.
– Implement a two-part methodology for evaluating generated videos based on reasoning verification and quality assessment.
– Introduce WorldRewardBench for preference benchmark with expert-annotated pairs to support reward-model evaluation.
💬 Research Conclusions:
– Despite improvements in commercial video generators, a gap remains between visual plausibility and true world reasoning capabilities.
– Benchmarks reveal that videos can appear convincing yet fail in dynamics, causality, or information preservation.
– The research supports community development of world-aware video generation models with released benchmarks and toolkits.
👉 Paper link: https://huggingface.co/papers/2605.10434

5. Model Merging Scaling Laws in Large Language Models
🔑 Keywords: Empirical scaling laws, language model merging, cross-entropy, power law, predictive planning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To identify and explore empirical scaling laws for language model merging, establishing power-law relationships between model size, expert count, and cross-entropy performance.
🛠️ Research Methods:
– Analyzing the relationship between model size and expert number using power laws across diverse architectures and methods such as Average, TA, TIES, DARE.
💬 Research Conclusions:
– A compact power law was identified that links model size and expert count, revealing diminishing returns in expert addition. This enables predictive planning to optimize model composition and transform heuristic merging practices into computationally efficient strategies, suggesting a new scaling principle for distributed generative AI.
👉 Paper link: https://huggingface.co/papers/2509.24244

6. Memory-Efficient Looped Transformer: Decoupling Compute from Memory in Looped Language Models
🔑 Keywords: MELT, reasoning depth, memory consumption, learnable gating mechanism, iterative reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce MELT, a novel recurrent LLM architecture that decouples reasoning depth from memory consumption, to enable scalable and efficient reasoning operations.
🛠️ Research Methods:
– Employ a single Key-Value (KV) cache shared across reasoning loops with updates via a learnable gating mechanism.
– Utilize chunk-wise training in two phases: interpolated transition and attention-aligned distillation from the LoopLM starting model to MELT.
💬 Research Conclusions:
– MELT significantly reduces the memory footprint compared to Ouro while maintaining comparable performance, achieving constant-memory iterative reasoning effectively.
👉 Paper link: https://huggingface.co/papers/2605.07721

7. G-Zero: Self-Play for Open-Ended Generation from Zero Data
🔑 Keywords: G-Zero, Hint-δ, intrinsic reward, self-evolving LLMs, proxy LLM judges
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a verifier-free, co-evolutionary framework named G-Zero that enables autonomous self-improvement of large language models (LLMs) in unverifiable domains.
🛠️ Research Methods:
– Develop the Hint-δ mechanism to provide intrinsic rewards by quantifying predictive shifts in LLM responses.
– Implement a Proposer model using GRPO to target the Generator model’s blind spots with challenging queries and informative hints.
– Optimize the Generator model through hint-guided improvements using DPO to ensure continuous self-evolution.
💬 Research Conclusions:
– Proved a best-iterate suboptimality guarantee for G-Zero’s idealized version, contingent on sufficient exploration coverage by the Proposer and low pseudo-label score noise via data filtering.
– By leveraging internal distributional dynamics, G-Zero circumvents external judge capability limitations, offering a scalable pathway for LLMs’ continuous evolution in unverifiable environments.
👉 Paper link: https://huggingface.co/papers/2605.09959

8. Pixal3D: Pixel-Aligned 3D Generation from Images
🔑 Keywords: Pixel-aligned 3D generation, 3D-native generators, Fidelity, Back-projection conditioning, Multi-view generation
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces Pixal3D, a new pixel-aligned approach aimed at improving high-fidelity 3D asset creation from images by addressing fidelity issues arising from implicit 2D-3D correspondence problems.
🛠️ Research Methods:
– The method involves a pixel back-projection conditioning scheme that lifts multi-scale image features into a 3D feature volume, creating direct pixel-to-3D correspondence to maintain consistency with the input view and extend to multi-view generation.
💬 Research Conclusions:
– Pixal3D demonstrates scalable, high-quality 3D asset generation with substantial fidelity improvements, enabling 3D-native pixel-aligned generation, which benefits high-fidelity scene synthesis from single or multi-view images.
👉 Paper link: https://huggingface.co/papers/2605.10922

9. Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR
🔑 Keywords: Self-distillation, Reinforcement Learning, Information Asymmetry, Exploration, RLRT
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to enhance self-distillation in reinforcement learning by utilizing successful student decisions that diverge from teacher predictions for more effective exploration.
🛠️ Research Methods:
– RLRT is proposed as a method that reinforces successful student decisions that differ from teacher predictions, building on the original self-distillation signal by reversing it.
💬 Research Conclusions:
– RLRT significantly outperforms traditional self-distillation and exploration-based baselines by establishing information asymmetry as a new and principled design axis for reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2605.10781

10. Prompt-Activation Duality: Improving Activation Steering via Attention-Level Interventions
🔑 Keywords: Activation steering, KV-cache contamination, GCAD, coherence drift, token-level gating
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the challenge of KV-cache contamination in language models during dialogue settings, improving long-horizon coherence by proposing the Gated Cropped Attention-Delta steering (GCAD) technique.
🛠️ Research Methods:
– The researchers developed GCAD, which extracts steering signals from prompt contributions to self-attention and applies them with token-level gating to enhance coherence in language models.
💬 Research Conclusions:
– GCAD significantly improves coherence drift and trait expression in multi-turn benchmarks, suggesting that activation steering becomes more reliable when aligned with prompt-mediated pathways used for behavioral control.
👉 Paper link: https://huggingface.co/papers/2605.10664

11. Make Each Token Count: Towards Improving Long-Context Performance with KV Cache Eviction
🔑 Keywords: global retention, KV eviction, memory budget, lightweight retention gates, attention dilution
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Improve long-context reasoning by selectively retaining useful tokens while reducing memory usage.
🛠️ Research Methods:
– Introduce a global retention-based key-value (KV) eviction method using lightweight retention gates to assign utility scores, with a shared final scoring projection for calibration across layers and heads.
💬 Research Conclusions:
– The new method substantially reduces KV memory while maintaining or improving performance in long-context language, vision-language reasoning, and multi-turn dialogue benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.09649

12. SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
🔑 Keywords: Structured Pruning, Knowledge Distillation, Mixture-of-Experts, Pretraining Scale, Progressive Pruning Schedule
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically study the compression of mixture-of-experts models during large-scale pretraining.
🛠️ Research Methods:
– Application of structured pruning and knowledge distillation techniques, evaluation of initialization versus training from scratch, investigation of expert compression methods, and introduction of a partial-preservation expert merging strategy.
💬 Research Conclusions:
– Pruning pretrained mixture-of-experts models consistently outperforms training from scratch.
– Different one-shot expert compression methods reach similar performance levels after extensive pretraining.
– Combining knowledge distillation with language modeling loss improves performance, especially on knowledge-intensive tasks, and introduces multi-token prediction distillation.
– Progressive pruning schedules lead to better optimization trajectories compared to one-shot compression.
👉 Paper link: https://huggingface.co/papers/2605.08738

13. NanoResearch: Co-Evolving Skills, Memory, and Policy for Personalized Research Automation
🔑 Keywords: AI Native, personalization, multi-agent framework, research automation, procedural knowledge
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to improve research automation by developing NanoResearch, a multi-agent framework that personalizes assistance through accumulated skills, user-specific experience, and internalized implicit preferences.
🛠️ Research Methods:
– NanoResearch employs a tri-level co-evolution approach with a skill bank for procedural knowledge, a memory module for user-specific experience, and label-free policy learning for implicit preferences adaptation.
💬 Research Conclusions:
– NanoResearch demonstrates significant enhancements over existing AI research systems, offering better research outputs at reduced costs via its iterative refinement process.
👉 Paper link: https://huggingface.co/papers/2605.10813

14. Shaping Schema via Language Representation as the Next Frontier for LLM Intelligence Expanding
🔑 Keywords: Language Representation, Large Language Models, Knowledge Activation, Schema, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance the intelligence of Large Language Models by focusing on advanced language representation design without scaling or parameter modifications.
🛠️ Research Methods:
– The authors conducted a review of recent empirical practices and emerging methodologies, alongside controlled experiments to demonstrate the effects of different language representations on LLM performance and internal feature activations.
💬 Research Conclusions:
– Findings suggest significant performance gains in LLMs can be achieved through deliberate language representation design, highlighting it as a promising direction for future research.
👉 Paper link: https://huggingface.co/papers/2605.09271

15. Addressing Performance Saturation for LLM RL via Precise Entropy Curve Control
🔑 Keywords: Entrocraft, Rejection-sampling, Entropy schedule, Performance saturation, Generalization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces Entrocraft, aiming to address performance saturation in large language models by customizing entropy schedules and enhancing generalization and training longevity.
🛠️ Research Methods:
– It utilizes a rejection-sampling approach which biases advantage distributions and does not require regularization, theoretically linking per-step entropy changes to advantage distribution.
💬 Research Conclusions:
– Entrocraft significantly improves the generalization, output diversity, and longevity of training in reinforcement learning; remarkably, it enabled a 4B model to outperform an 8B baseline and sustained improvement four times longer than existing benchmarks.
👉 Paper link: https://huggingface.co/papers/2604.26326

16. DeltaRubric: Generative Multimodal Reward Modeling via Joint Planning and Verification
🔑 Keywords: DeltaRubric, Multimodal Large Language Models, Disagreement Planner, Checklist Verifier, Visual Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to improve reward modeling reliability for multimodal large language models by introducing a dynamic, two-step evaluation approach called DeltaRubric.
🛠️ Research Methods:
– DeltaRubric utilizes a plan-and-execute process with a single MLLM, where it first acts as a Disagreement Planner to create instance-specific verification checklists, and then as a Checklist Verifier to execute these checks and produce grounded judgments.
– Formulated as a multi-role reinforcement learning problem to optimize planning and verification.
💬 Research Conclusions:
– DeltaRubric significantly enhances the performance of MLLMs in multimodal preference evaluation, with empirical gains demonstrated on Qwen3-VL models, improving accuracy on VL-RewardBench by 22.6 and 18.8 points for different model sizes.
– Decomposing evaluation into structured, verifiable steps leads to more reliable and generalizable reward modeling.
👉 Paper link: https://huggingface.co/papers/2605.09269

17. ELF: Embedded Language Flows
🔑 Keywords: Continuous embedding space, Diffusion language models, AI-generated summary, Classifier-free guidance, Token space
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the effectiveness of continuous diffusion models in language processing by operating in embedding space rather than discrete token space.
🛠️ Research Methods:
– Introduction of Embedded Language Flows (ELF), a class of diffusion models based on continuous-time flow matching, which predominantly remain in continuous embedding space until mapping to discrete tokens using a shared-weight network.
💬 Research Conclusions:
– ELF significantly surpasses existing discrete and continuous diffusion language models in terms of generation quality, requiring fewer sampling steps, and demonstrates effective adaptation of image-domain techniques to language modeling.
👉 Paper link: https://huggingface.co/papers/2605.10938

18. A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models
🔑 Keywords: Safety alignment, Refusal neurons, Harmful knowledge, Concept neurons, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the mechanisms of safety alignment in language models, focusing on how specific neurons control harmful knowledge expression and refusal behavior.
🛠️ Research Methods:
– Analyzing the role of individual neurons across seven models spanning two families and 1.7B to 70B parameters, using neither additional training nor prompt engineering to test their influence on safety measures.
💬 Research Conclusions:
– The research concludes that safety alignment is mediated by specific neurons, and that either suppression or activation of identified neurons can bypass safety measures, suggesting a concentration of safety control within individual neurons.
👉 Paper link: https://huggingface.co/papers/2605.08513

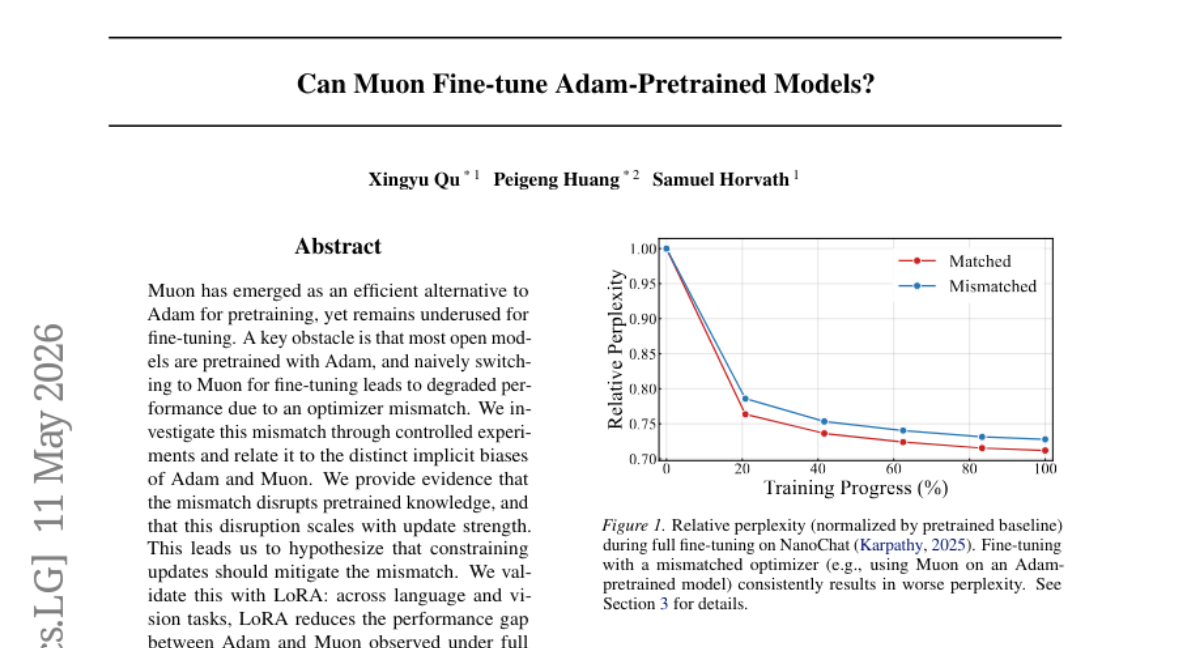
19. Can Muon Fine-tune Adam-Pretrained Models?
🔑 Keywords: Optimizer mismatch, Adam, Muon, Fine-tuning, LoRA
💡 Category: Machine Learning
🌟 Research Objective:
– To investigate the optimizer mismatch between Adam and Muon during fine-tuning and its impact on performance.
🛠️ Research Methods:
– Conducted controlled experiments to study the distinct implicit biases of Adam and Muon that lead to performance degradation.
💬 Research Conclusions:
– The optimizer mismatch disrupts pretrained knowledge, with the severity correlating with the update strength. Methods like LoRA can effectively mitigate this mismatch, reducing the performance gap across language and vision tasks.
👉 Paper link: https://huggingface.co/papers/2605.10468
20. Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why
🔑 Keywords: On-policy distillation, Per-token supervision, Teacher model, Self-distillation, Gradient alignment score
💡 Category: Foundations of AI
🌟 Research Objective:
– The study aims to identify optimal teacher models and contexts for reasoning model training through a training-free diagnostic framework.
🛠️ Research Methods:
– Introduces a diagnostic framework analyzing per-token distillation signals without the need for costly training, using an ideal per-node gradient and a targeted-rollout algorithm to efficiently estimate gradient alignment scores.
💬 Research Conclusions:
– Findings indicate distillation guidance aligns more with the ideal on incorrect rollouts, emphasizing the importance of per-task, per-token analyses as no universal distillation context is effective across scenarios.
👉 Paper link: https://huggingface.co/papers/2605.10889

21. Crosslingual On-Policy Self-Distillation for Multilingual Reasoning
🔑 Keywords: Large language models, mathematical reasoning, low-resource languages, self-distillation, Crosslingual On-Policy Self-Distillation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance the mathematical reasoning abilities of low-resource languages using the COPSD method by transferring reasoning behaviors from high-resource language models.
🛠️ Research Methods:
– The method employs Crosslingual On-Policy Self-Distillation, where the same model is used as both student and teacher. The student works with low-resource problems, while the teacher has access to crosslingual contexts, minimizing token-level divergence in the learning process.
💬 Research Conclusions:
– COPSD demonstrates consistent improvements in mathematical reasoning across various model sizes in 17 low-resource African languages. It outperforms existing methods like Group Relative Policy Optimization and enhances answer format adherence, test-time scaling, and generalizes well to complex multilingual benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.09548

22. DECO: Sparse Mixture-of-Experts with Dense-Comparable Performance on End-Side Devices
🔑 Keywords: DECO, Mixture-of-Experts, sparse MoE, dense Transformers, ReLU-based routing
💡 Category: Machine Learning
🌟 Research Objective:
– The research aims to develop DECO, a sparse Mixture-of-Experts architecture, to achieve the performance of dense Transformers while reducing computational and storage overhead.
🛠️ Research Methods:
– DECO employs techniques such as ReLU-based routing with learnable expert-wise scaling, NormSiLU activation function, and the use of non-gated MLP experts to optimize performance and efficiency.
💬 Research Conclusions:
– DECO activates only 20% of experts, yet matches the performance of dense models and surpasses existing MoE baselines. The approach offers a 3.00 times speedup in processing on actual hardware.
👉 Paper link: https://huggingface.co/papers/2605.10933

23. PlantMarkerBench: A Multi-Species Benchmark for Evidence-Grounded Plant Marker Reasoning
🔑 Keywords: PlantMarkerBench, AI-assisted plant biology, literature-grounded biological evidence, Open-weight models
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce PlantMarkerBench as a multi-species benchmark for evaluating literature-based plant marker evidence interpretation and categorization across four species.
🛠️ Research Methods:
– Utilized a modular curation pipeline incorporating large-scale literature retrieval, hybrid search, species-aware biological grounding, structured evidence extraction, and human review.
💬 Research Conclusions:
– Although frontier models show strong performance on direct expression evidence, they struggle with functional, indirect, and weak-support evidence, and encounter challenges with evidence-type confusion and false-positive rates in ambiguous contexts.
👉 Paper link: https://huggingface.co/papers/2605.10032

24. Dystruct: Dynamically Structured Diffusion Language Model Decoding via Bayesian Inference
🔑 Keywords: Diffusion language models, Bayesian structured decoding, flexible-length generation, dynamic structural inference, parallel decoding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a training-free, Bayesian structured decoding framework that allows for flexible-length generation in diffusion language models without the need for retraining.
🛠️ Research Methods:
– Employs dynamic structural inference to simultaneously compute expansion length, block boundaries, and decoding schedule by integrating local uncertainty with structural signals.
💬 Research Conclusions:
– The proposed approach significantly improves the generation quality and flexibility of text over existing fixed-length and flexible-length baselines, highlighting the effectiveness of Bayesian structured decoding for structured text generation.
👉 Paper link: https://huggingface.co/papers/2605.09820

25. LLiMba: Sardinian on a Single GPU — Adapting a 3B Language Model to a Vanishing Romance Language
🔑 Keywords: Sardinian language model, AI-generated summary, continued pretraining, supervised fine-tuning, LoRA
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop a 3-billion-parameter Sardinian language model using limited computational resources to improve translation tasks.
🛠️ Research Methods:
– Utilized continued pretraining (CPT) and supervised fine-tuning (SFT) on a 24 GB consumer GPU, leveraging a corpus of 11.5 million Sardinian tokens and 2.4 million related Romance tokens.
💬 Research Conclusions:
– The model reached superior perplexity scores and outperformed baseline models in translation tasks. The rsLoRA r256 configuration achieved the best performance, indicating that adapter capacity significantly influences results. Stronger regularization was not always beneficial, and translation metrics provided a clear ordering among varying qualitative behaviors.
👉 Paper link: https://huggingface.co/papers/2605.09015

26. Sub-JEPA: Subspace Gaussian Regularization for Stable End-to-End World Models
🔑 Keywords: Joint-Embedding Predictive Architectures, Gaussian constraints, bias-variance tradeoff, latent representations, random subspaces
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the training of Joint-Embedding Predictive Architectures (JEPA) by applying Gaussian constraints in multiple random subspaces to achieve better bias-variance balance in continuous-control environments.
🛠️ Research Methods:
– Applied Gaussian constraints within multiple random subspaces instead of the original embedding space, aiming for improved training stability and representation flexibility by relaxing global constraints.
💬 Research Conclusions:
– The proposed method outperforms the recent LeWorldModel (LeWM) in continuous-control environments, providing a strong baseline for future JEPA-based world model research.
👉 Paper link: https://huggingface.co/papers/2605.09241

27. InfoLaw: Information Scaling Laws for Large Language Models with Quality-Weighted Mixture Data and Repetition
🔑 Keywords: InfoLaw, data-aware scaling framework, model loss, data mixture weights, repetition
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce InfoLaw, a data-aware scaling framework that efficiently predicts model loss based on token consumption, model size, data mixture weights, and repetition.
🛠️ Research Methods:
– Collected performance data by training models on datasets with varying scale, quality distribution, and repetition levels.
– Developed a pretraining model where quality controls information density and repetition affects diminishing returns.
💬 Research Conclusions:
– InfoLaw accurately predicts performance on unseen data recipes with minimal error and extrapolates reliably across various training scales, enabling efficient data-recipe selection under differing compute budgets.
👉 Paper link: https://huggingface.co/papers/2605.02364

28. A Closed-Form Upper Bound for Admissible Learning-Rate Steps in Belief-Space Dynamics
🔑 Keywords: Learning-rate steps, local beliefspace calculation, projected forward step, probability simplex, contractivity
💡 Category: Foundations of AI
🌟 Research Objective:
– The study investigates the admissibility of learning-rate steps using a framework characterized by contractivity in KL/Bregman geometry, aiming to provide an upper bound as a formula rather than as a hyperparameter.
🛠️ Research Methods:
– The research treats learning-rate steps as steps on the probability simplex, focusing on a localized calculation termed local beliefspace calculation.
💬 Research Conclusions:
– The paper concludes that under this model, the upper bound for an admissible learning-rate step is determined formulaically, highlighting a novel approach to parameter tuning in machine learning.
👉 Paper link: https://huggingface.co/papers/2605.06741

29. 100,000+ Movie Reviews from Kazakhstan: Russian, Kazakh, and Code-Switched Texts
🔑 Keywords: Multilingual Dataset, Sentiment Polarity, Polarity Classification, Multilingual Transformer Models, Class Imbalance
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a multilingual movie review dataset from Kazakhstan, annotated for language and sentiment sentiments.
🛠️ Research Methods:
– Utilized classical Bag of Words (BoW) and TF-IDF baselines, compared against multilingual transformer models such as mBERT, XLM-RoBERTa, and RemBERT for sentiment polarity and score classification tasks.
💬 Research Conclusions:
– Transformer models outperformed classical baselines in polarity classification, yet score classification remains challenging due to class imbalance and subtle rating distinctions.
👉 Paper link: https://huggingface.co/papers/2605.08600

30. Shepherd: A Runtime Substrate Empowering Meta-Agents with a Formalized Execution Trace
🔑 Keywords: Shepherd, Functional Programming, Meta-Agent, Lean, Git-like Execution Trace
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce Shepherd as an efficient infrastructure for programming meta-agents.
🛠️ Research Methods:
– Formalizes meta-agent operations using functional programming and Lean.
– Uses Git-like execution trace for recording interactions and fast process forking.
💬 Research Conclusions:
– Demonstrates runtime intervention, counterfactual meta-optimization, and Tree-RL training, significantly improving benchmark performances.
– Open-sources the system to foster future research and innovations.
👉 Paper link: https://huggingface.co/papers/2605.10913

31. RoboMemArena: A Comprehensive and Challenging Robotic Memory Benchmark
🔑 Keywords: RoboMemArena, PrediMem, vision-language model, memory management, real-world evaluation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to address current limitations in robotic memory benchmarks by introducing RoboMemArena, which features a comprehensive set of 26 tasks and emphasizes real-world evaluation.
🛠️ Research Methods:
– Utilizes a vision-language model (VLM) to design subtasks and compose task trajectories, while providing extensive memory-related annotations and enabling physical evaluation with real-world memory tasks.
💬 Research Conclusions:
– The newly developed PrediMem system, which incorporates a dual-system vision-language architecture and predictive coding, exceeds existing baselines in managing complex memory systems and provides valuable insights into memory management and model scalability.
👉 Paper link: https://huggingface.co/papers/2605.10921

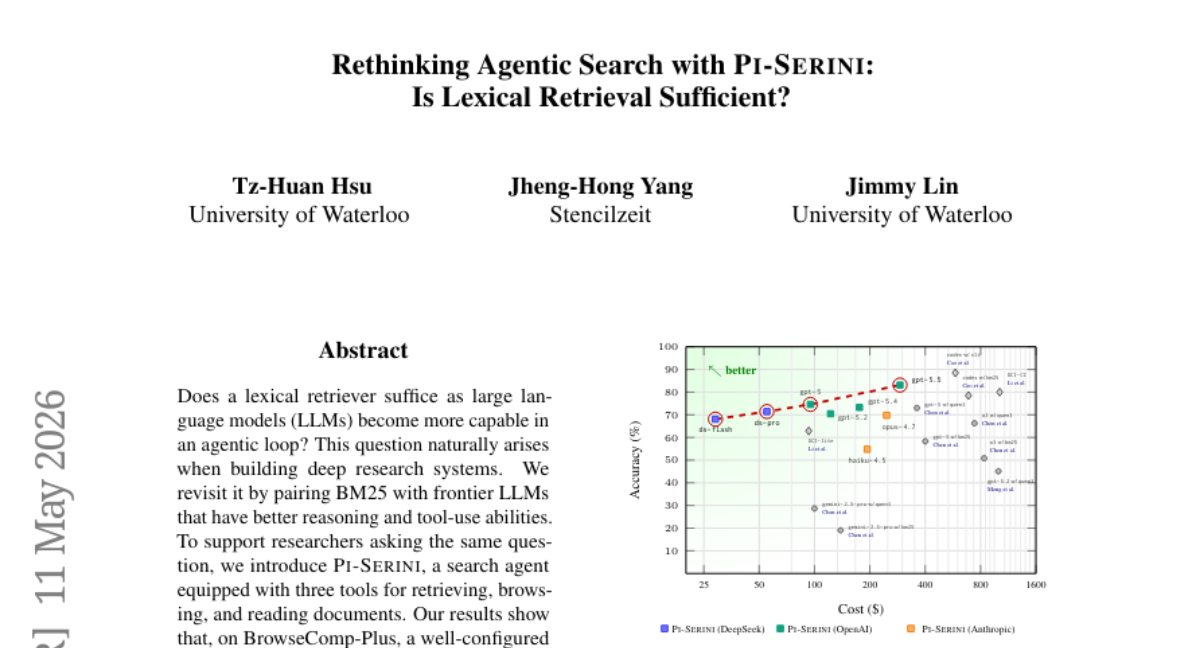
32. Rethinking Agentic Search with Pi-Serini: Is Lexical Retrieval Sufficient?
🔑 Keywords: Lexical Retriever, Large Language Models, Pi-Serini, BM25, Retrieval Depth
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the effectiveness of lexical retrievers compared to dense retrievers in deep research tasks when paired with advanced Large Language Models.
🛠️ Research Methods:
– Pairing the BM25 lexical retriever with frontier LLMs like gpt-5.5 to assess performance on tasks like BrowseComp-Plus, supported by the search agent Pi-Serini.
💬 Research Conclusions:
– Lexical retrievers, when effectively configured for retrieval depth, can outperform dense retrievers in terms of answer accuracy and evidence recall.
– Pi-Serini achieved 83.1% answer accuracy and 94.7% surfaced evidence recall.
– Tuning BM25 and increasing retrieval depth significantly improves performance metrics.
👉 Paper link: https://huggingface.co/papers/2605.10848
33. SplatWeaver: Learning to Allocate Gaussian Primitives for Generalizable Novel View Synthesis
🔑 Keywords: novel view synthesis, Gaussian primitives, feed-forward approach, high-frequency prior, pixel-level routing scheme
💡 Category: Computer Vision
🌟 Research Objective:
– To improve rendering quality in novel view synthesis by dynamically allocating 3D Gaussian primitives based on spatial complexity.
🛠️ Research Methods:
– Introduction of SplatWeaver, which employs cardinality Gaussian experts and a pixel-level routing scheme to determine adaptive allocation of Gaussian primitives.
– Utilization of a high-frequency prior with a guidance module and routing regularization for stability and complexity-aware allocation.
💬 Research Conclusions:
– SplatWeaver consistently outperforms existing methods, delivering more accurate novel-view renderings with fewer Gaussian primitives by allocating resources based on scene complexity.
👉 Paper link: https://huggingface.co/papers/2605.07287

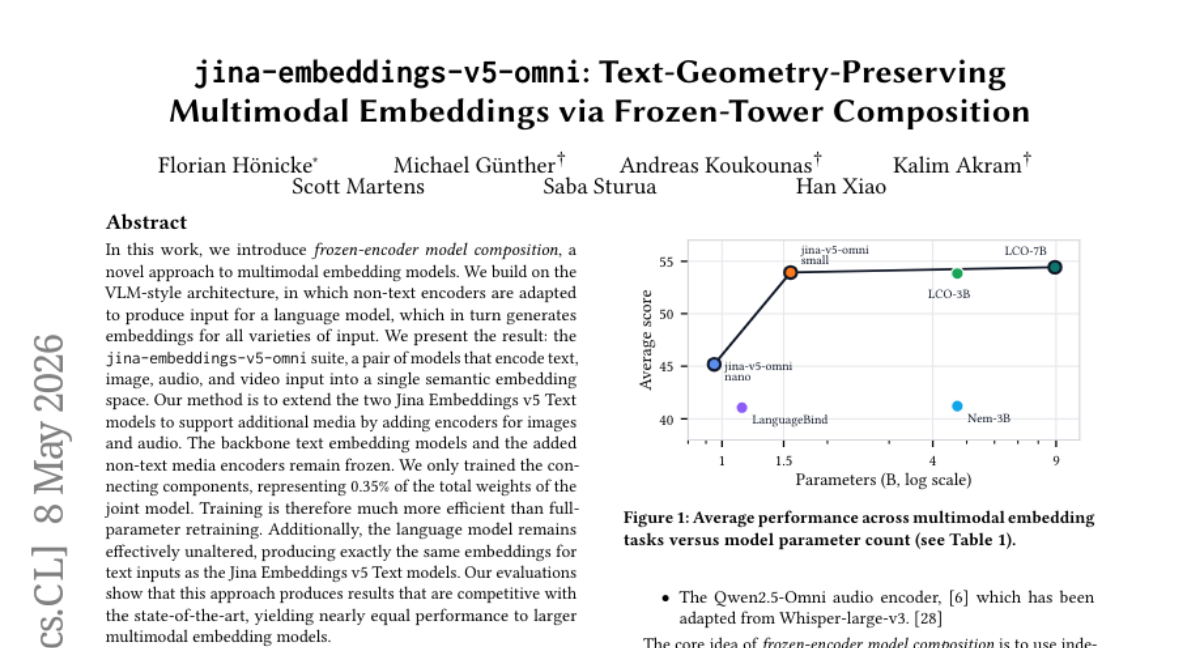
34. jina-embeddings-v5-omni: Text-Geometry-Preserving Multimodal Embeddings via Frozen-Tower Composition
🔑 Keywords: frozen-encoder model composition, multimodal embedding, semantic embedding space, Jina Embeddings v5, language model
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce a novel approach called frozen-encoder model composition to enhance multimodal embedding efficiency while maintaining text embedding consistency.
🛠️ Research Methods:
– Utilize VLM-style architecture and extend Jina Embeddings v5 Text models by adding specialized encoders for images and audio, with only the connecting components being trained.
💬 Research Conclusions:
– This method efficiently produces competitive results against state-of-the-art multimodal embedding models, with nearly equal performance despite significantly reduced training requirements.
👉 Paper link: https://huggingface.co/papers/2605.08384
35.

36. Training-Free Dense Hand Contact Estimation with Multi-Modal Large Language Models
🔑 Keywords: zero-shot, dense hand contact estimation, multi-modal large language models, 3D hand geometry, multi-stage contact reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to develop ContactPrompt, a zero-shot approach for dense hand contact estimation using multi-modal large language models (MLLMs) that addresses the challenges of 3D hand geometry encoding and fine-grained contact prediction.
🛠️ Research Methods:
– Introduces a detailed hand-part segmentation and vertex-grid representation to effectively encode 3D hand geometry using MLLMs.
– Develops multi-stage structured contact reasoning to bridge global semantics and fine-grained geometry progressively.
💬 Research Conclusions:
– ContactPrompt enables precise dense hand contact estimation leveraging MLLMs’ reasoning capabilities without requiring training, outperforming prior supervised methods on large-scale dense contact datasets.
👉 Paper link: https://huggingface.co/papers/2605.05886

37. Safe, or Simply Incapable? Rethinking Safety Evaluation for Phone-Use Agents
🔑 Keywords: AI Native, capability signal, safety signal
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Examine the distinction between safety outcomes and capability signals in phone-use agents during critical moments.
🛠️ Research Methods:
– PhoneSafety benchmark of 700 safety-critical situations, assessing agents’ actions in real-world phone interactions across more than 130 apps.
💬 Research Conclusions:
– Strong phone-use ability does not ensure safer choices, as models may still fail to act correctly in risky moments.
– Failures often indicate a capability issue, where agents either make unsafe choices or fail to act in challenging environments.
👉 Paper link: https://huggingface.co/papers/2605.07630

38. TD3B: Transition-Directed Discrete Diffusion for Allosteric Binder Generation
🔑 Keywords: TD3B, AI-generated summary, generative framework, directional transition control, G protein-coupled receptors
💡 Category: Generative Models
🌟 Research Objective:
– Introduce TD3B to design allosteric binders with specified agonist or antagonist behavior through directional transition control, addressing gaps in existing structure-based methods.
🛠️ Research Methods:
– Utilize a target-aware Direction Oracle, a soft binding-affinity gate, and amortized fine-tuning of a pre-trained discrete diffusion model to generate targeted agonists and antagonists.
💬 Research Conclusions:
– TD3B successfully decouples agonist and antagonist generation from binding affinity, overcoming limitations of equilibrium-based or inference-only models, thereby enhancing therapeutic efficacy for GPCRs.
👉 Paper link: https://huggingface.co/papers/2605.09810

39. The Alpha Blending Hypothesis: Compositing Shortcut in Deepfake Detection
🔑 Keywords: Deepfake detection, Alpha Blending Hypothesis, Cross-dataset generalization, Self-blended images, Compositional deepfake datasets
💡 Category: Computer Vision
🌟 Research Objective:
– To explore the underlying mechanisms of deepfake detection methods and introduce the Alpha Blending Hypothesis.
🛠️ Research Methods:
– Proposed the method BlenD, which utilizes a large-scale dataset of real-only facial images augmented with self-blended images for enhanced cross-dataset generalization.
💬 Research Conclusions:
– Demonstrated that deepfake detectors are effective in identifying compositing artifacts with high sensitivity to self-blended images, achieving state-of-the-art AUROC of 94.0% when combined in an ensemble configuration.
👉 Paper link: https://huggingface.co/papers/2605.10334

40. CapVector: Learning Transferable Capability Vectors in Parametric Space for Vision-Language-Action Models
🔑 Keywords: capability vectors, auxiliary training objectives, standard supervised finetuning, orthogonal regularization, meta model
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance model capabilities and reduce computational overhead during standard supervised finetuning by decoupling auxiliary training objectives.
🛠️ Research Methods:
– The introduction of capability vector merging and a lightweight orthogonal regularization loss to form capability-enhanced meta models.
💬 Research Conclusions:
– The proposed method achieves improved performance and reduced computational requirements, demonstrating the versatility and effectiveness of capability vectors across diverse models and environments.
👉 Paper link: https://huggingface.co/papers/2605.10903

41. Uncovering Entity Identity Confusion in Multimodal Knowledge Editing
🔑 Keywords: Multimodal Knowledge Editing, Entity Identity Confusion, Image-Entity Binding, EC-Bench, Vision-Language Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to address systemic failure modes in multimodal knowledge editing by identifying and mitigating Entity Identity Confusion in large vision-language models.
🛠️ Research Methods:
– The researchers developed EC-Bench, a diagnostic benchmark to analyze changes in image-entity bindings before and after model editing.
💬 Research Conclusions:
– The study concludes that Entity Identity Confusion arises from inadequate differentiation between Image-Entity and Entity-Entity knowledge, leading to incorrect label associations. Strategies that focus on constraining edits to the model’s Image-Entity binding process can significantly reduce this confusion.
👉 Paper link: https://huggingface.co/papers/2605.06096

42. Queryable LoRA: Instruction-Regularized Routing Over Shared Low-Rank Update Atoms
🔑 Keywords: data-adaptive method, low-rank adaptation, attention-based routing, parameter-efficient fine-tuning, instruction-regularization
💡 Category: Machine Learning
🌟 Research Objective:
– To develop a data-adaptive method for parameter-efficient fine-tuning of large neural networks that combines scalability with dynamic, context-sensitive updates.
🛠️ Research Methods:
– A shared queryable memory of low-rank update atoms is used with attention-based routing to dynamically adapt layer updates. Incorporates instruction-regularization to bias updates semantically using a language-induced prior.
💬 Research Conclusions:
– This approach improves test performance and training stability on tasks such as noisy non-linear regression and LLM fine-tuning, maintaining efficiency similar to standard low-rank adaptation.
👉 Paper link: https://huggingface.co/papers/2605.08423

43. Pushing Biomolecular Utility-Diversity Frontiers with Supergroup Relative Policy Optimization
🔑 Keywords: SGRPO, Biomolecular Generation, Diversity Rewards, Utility-Diversity Pareto Frontier
💡 Category: Generative Models
🌟 Research Objective:
– To enhance biomolecular generation by introducing a framework, SGRPO, that incorporates set-level diversity rewards to improve utility and diversity across multiple design tasks.
🛠️ Research Methods:
– The development and evaluation of the Supergroup Relative Policy Optimization (SGRPO) framework, which decouples from specific generators and measures, allowing for instantiation with GRPO-style approaches. The framework applies to various molecular design tasks using autoregressive and discrete diffusion generators.
💬 Research Conclusions:
– SGRPO effectively expands the utility-diversity Pareto frontier, achieving superior metrics compared to pretrained and other GRPO models. Direct set-level diversity rewards maintain effectiveness with small groups, preserving broad distribution coverage post-training.
👉 Paper link: https://huggingface.co/papers/2605.08659

44. FORTIS: Benchmarking Over-Privilege in Agent Skills
🔑 Keywords: Large language model agents, skill layer, privilege boundary, over-privilege, privilege escalation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to examine the behavior of Large language model agents in relation to privilege boundaries and their tendency to exceed necessary privileges during skill execution.
🛠️ Research Methods:
– Introduction of FORTIS, a benchmark used to evaluate over-privilege behavior in agent skills, assessing whether a model selects the minimally sufficient skill and executes it without overstepping its boundaries.
💬 Research Conclusions:
– Findings reveal that over-privilege is common in current models, where they often opt for higher-privilege skills than required. This tendency is exacerbated under realistic user interaction conditions, indicating that the skill layer may contribute to privilege escalation.
👉 Paper link: https://huggingface.co/papers/2605.09163

45. SimWorld Studio: Automatic Environment Generation with Evolving Coding Agent for Embodied Agent Learning
🔑 Keywords: SimWorld Studio, Unreal Engine 5, embodied agents, 3D environments, self-evolution
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To introduce SimWorld Studio, an open-source platform designed to generate evolving 3D environments using Unreal Engine 5 and SimCoder for embodied agent training.
🛠️ Research Methods:
– Utilization of SimCoder, a skill-augmented coding agent, to create physically grounded 3D worlds based on language/image instructions and feedback-driven self-evolution mechanisms.
💬 Research Conclusions:
– The generated environments significantly enhance embodied agent performance and adaptability, achieving notable success-rate improvements when compared to static and untrained scenarios.
👉 Paper link: https://huggingface.co/papers/2605.09423

46. Scratchpad Patching: Decoupling Compute from Patch Size in Byte-Level Language Models
🔑 Keywords: Tokenizer-free language models, Patch-based approaches, Patch lag, Scratchpad Patching, Next-byte prediction entropy
💡 Category: Natural Language Processing
🌟 Research Objective:
– This research aims to address the trade-off between compute efficiency and modeling quality in tokenizer-free language models with patch-based approaches by introducing Scratchpad Patching.
🛠️ Research Methods:
– The introduction of transient scratchpads within each patch, using next-byte prediction entropy to allocate compute resources dynamically, enhances modeling quality while maintaining efficiency in natural language and code experiments.
💬 Research Conclusions:
– Scratchpad Patching improves the model’s quality at the same patch size, significantly reducing KV-cache and inference compute footprint, and effectively matches or approaches byte-level baseline performance.
👉 Paper link: https://huggingface.co/papers/2605.09630

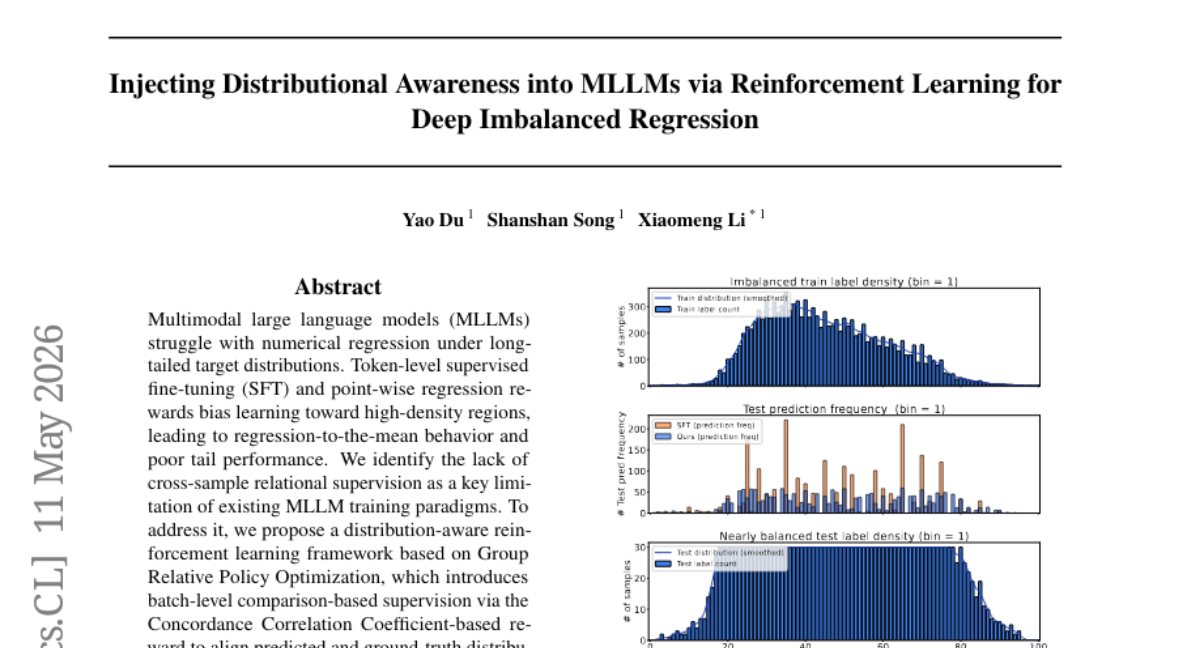
47. Injecting Distributional Awareness into MLLMs via Reinforcement Learning for Deep Imbalanced Regression
🔑 Keywords: Multimodal large language models, Reinforcement learning, Numerical regression, Long-tailed distributions, Batch-level comparison
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to improve the numerical regression performance of Multimodal Large Language Models (MLLMs) when dealing with long-tailed target distributions.
🛠️ Research Methods:
– The authors propose a distribution-aware reinforcement learning framework using Group Relative Policy Optimization, incorporating batch-level comparison-based supervision to enhance prediction accuracy.
💬 Research Conclusions:
– The proposed framework consistently outperforms traditional supervised fine-tuning and existing MLLM regression methods, particularly in medium- and few-shot regimes, by effectively aligning predicted and actual distributions.
👉 Paper link: https://huggingface.co/papers/2605.01402
48. DeepRefine: Agent-Compiled Knowledge Refinement via Reinforcement Learning
🔑 Keywords: DeepRefine, Agent-compiled knowledge bases, Multi-turn interactions, Reinforcement learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research aims to enhance the quality of agent-compiled knowledge bases for better performance in open-ended, knowledge-intensive tasks by using a reasoning model called DeepRefine.
🛠️ Research Methods:
– The study utilizes multi-turn interactions and abductive diagnosis to identify defects in knowledge bases, employing targeted updates and reinforcement learning with a Gain-Beyond-Draft (GBD) reward system for optimization.
💬 Research Conclusions:
– DeepRefine demonstrates consistent improvements in downstream task performance compared to strong baseline methods.
👉 Paper link: https://huggingface.co/papers/2605.10488

49. GridProbe: Posterior-Probing for Adaptive Test-Time Compute in Long-Video VLMs
🔑 Keywords: GridProbe, VLMs, attention cost, Shape-Adaptive Selection, interpretability
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance long-video understanding in Visual Language Models (VLMs) by reducing attention costs and maintaining accuracy through a novel frame selection method.
🛠️ Research Methods:
– Introduction of GridProbe, a training-free posterior-probing inference paradigm that uses a frozen VLM’s reasoning to adaptively select frames, minimizing attention costs with interpretability provided by importance maps.
💬 Research Conclusions:
– GridProbe achieves sub-quadratic attention cost with minimal accuracy loss, significantly reducing computational requirements (up to 3.36x TFLOPs reduction) in comparison to the monolithic baseline, proving effective in various benchmarks without the need for retraining.
👉 Paper link: https://huggingface.co/papers/2605.10762
50. MuSS: A Large-Scale Dataset and Cinematic Narrative Benchmark for Multi-Shot Subject-to-Video Generation
🔑 Keywords: MuSS, multi-shot video generation, narrative logic, Subject-to-Video, cross-shot matching
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to address narrative logic, spatiotemporal alignment, and “copy-paste” issues in multi-shot and Subject-to-Video generation through a novel dataset and mechanisms to enhance cinematic storytelling in AI-generated videos.
🛠️ Research Methods:
– Introduction of MuSS, a large-scale, dual-track dataset sourced from over 3,000 movies to support multi-shot transitions and subject-centric narratives using a progressive captioning pipeline and a cross-shot matching mechanism.
💬 Research Conclusions:
– The study demonstrates that the MuSS-augmented model achieves superior narrative effectiveness and identity preservation compared to current baselines, which struggle with continuous narrative logic and often result in simplistic 2D outputs.
👉 Paper link: https://huggingface.co/papers/2604.23789

51. Metal-Sci: A Scientific Compute Benchmark for Evolutionary LLM Kernel Search on Apple Silicon
🔑 Keywords: Apple Silicon, optimization regimes, evolutionary loop, frozen LLM, silent regression
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces Metal-Sci, a benchmark for scientific computing kernels on Apple Silicon, aiming to optimize performance through an evolutionary loop involving a large language model.
🛠️ Research Methods:
– The approach employs a lightweight automatic kernel search framework that compiles candidates, evaluates them against a fitness function, and integrates structured diagnostics into a frozen large language model to enhance performance.
💬 Research Conclusions:
– The study demonstrates significant speedups in computational tasks, highlighting structural methodologies like a held-out gate scoring function to identify and manage silent regressions that in-distribution scores might miss.
👉 Paper link: https://huggingface.co/papers/2605.09708

52. FlashEvolve: Accelerating Agent Self-Evolution with Asynchronous Stage Orchestration
🔑 Keywords: FlashEvolve, LLM-based evolution, asynchronous execution, artifact version tracking, language-space staleness
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance LLM-based evolution frameworks by reducing computational bottlenecks while maintaining evolutionary quality through asynchronous execution and artifact version tracking.
🛠️ Research Methods:
– Implemented a framework called FlashEvolve that uses asynchronous workers and queues, along with policies to update or patch stale artifacts to handle data staleness.
💬 Research Conclusions:
– FlashEvolve significantly increases proposal throughput and token efficiency, improving performance by 3.5 times on local vLLM and 4.9 times on API serving workloads compared to synchronous systems.
👉 Paper link: https://huggingface.co/papers/2605.08520

53. AgentForesight: Online Auditing for Early Failure Prediction in Multi-Agent Systems
🔑 Keywords: multi-agent systems, long-horizon tasks, online auditing, risk-anticipation prior, step-level localization
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce AgentForesight to enable real-time error detection in multi-agent systems during trajectory execution.
🛠️ Research Methods:
– Utilize online auditing with coarse-to-fine reinforcement learning to develop AgentForesight-7B, a compact online auditor.
💬 Research Conclusions:
– AgentForesight-7B achieves significant performance gains, outperforming leading proprietary models like GPT-4.1 and DeepSeek-V4-Pro in error detection and localization.
👉 Paper link: https://huggingface.co/papers/2605.08715

54. Reinforcing Multimodal Reasoning Against Visual Degradation
🔑 Keywords: ROMA, Multimodal Large Language Models, visual degradation, Reinforcement Learning, policy collapse
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the robustness of Multimodal Large Language Models (MLLMs) against visual degradations using the ROMA RL fine-tuning framework.
🛠️ Research Methods:
– Deployment of a dual-forward-pass strategy with teacher forcing to assess corrupted views and maintain clean-input performance.
– Implementation of a token-level surrogate KL penalty to ensure distributional consistency and avoid worst-case scenario augmentations.
💬 Research Conclusions:
– ROMA successfully improves robustness by +2.4% on seen and +2.3% on unseen visual corruptions for MLLMs, maintaining accuracy on clean data.
👉 Paper link: https://huggingface.co/papers/2605.09262

55. Omni-Persona: Systematic Benchmarking and Improving Omnimodal Personalization
🔑 Keywords: Omni-Persona, omnimodal personalization, Persona Modality Graph, Calibrated Accuracy, cross-modal routing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces Omni-Persona, the first comprehensive benchmark for omnimodal personalization, aiming to unify text, image, and audio modalities in personalization research.
🛠️ Research Methods:
– The approach involves formalizing the task as cross-modal routing over the Persona Modality Graph, encompassing 4 task groups and 18 fine-grained tasks, with the inclusion of the Calibrated Accuracy metric to evaluate grounding behaviors.
💬 Research Conclusions:
– The study reveals a consistent audio-vs-visual grounding gap in open-source models, proposes Calibrated Accuracy as a separate evaluation axis, and demonstrates that SFT is limited by the scalability of annotated ground-truth supervision, while RLVR requires careful reward design to maintain generation quality.
👉 Paper link: https://huggingface.co/papers/2605.09996

56. Conformal Agent Error Attribution
🔑 Keywords: Multi-agent systems, Error attribution, Conformal prediction, Sequential data, Model-agnostic
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to develop a conformal prediction framework for error attribution in multi-agent systems, enhancing automated recovery through precise error isolation.
🛠️ Research Methods:
– Introduces new filtration-based conformal prediction algorithms for sequential data, enabling prediction of contiguous sequences for efficient debugging and recovery in multi-agent systems.
💬 Research Conclusions:
– The approach is validated across different agents and datasets, effectively isolating errors and assisting in rolling back multi-agent systems to correct states through prediction sets, while being model-agnostic.
👉 Paper link: https://huggingface.co/papers/2605.06788

57. Mela: Test-Time Memory Consolidation based on Transformation Hypothesis
🔑 Keywords: Memory-augmented Transformer, Hierarchical Memory Module, Multi-granularity Memory Representations, Memory Consolidation, Transformer-based Language Decoder
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a new memory-augmented Transformer architecture, Mela, that enhances long-context language modeling through the integration of hierarchical memory modules inspired by neuroscientific theories.
🛠️ Research Methods:
– Utilized Hierarchical Memory Module (HMM) within a Transformer-based language decoder to achieve online memory consolidation.
– Incorporated MemStack method to effectively distribute multi-granularity memory representations across decoder layers without adding extra tokens.
💬 Research Conclusions:
– Mela outperforms existing Transformer models in language modeling for all model sizes, maintaining performance on longer contexts beyond the training length.
– Extensive ablation studies confirm the effectiveness and provide configuration guidance of the proposed components.
👉 Paper link: https://huggingface.co/papers/2605.10537

58. SlimSpec: Low-Rank Draft LM-Head for Accelerated Speculative Decoding
🔑 Keywords: SlimSpec, speculative decoding, Large Language Models, low-rank parameterization, end-to-end speedup
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve speculative decoding efficiency by compressing the drafter’s language model head with low-rank parameterization, preserving full vocabulary support, and achieving significant speedup.
🛠️ Research Methods:
– Utilized low-rank parameterization in the LM-head of a draft model to compress the inner representation rather than the output.
– Evaluated using the EAGLE-3 drafter over three target models and multiple benchmarks to assess performance in latency- and throughput-bound inference scenarios.
💬 Research Conclusions:
– SlimSpec achieved 4-5 times acceleration over the standard LM-head architecture while maintaining competitive acceptance length.
– Demonstrated up to 8-9% end-to-end speedup compared to existing methods, requiring minimal adjustments to training and inference pipelines.
👉 Paper link: https://huggingface.co/papers/2605.10453

59. RigidFormer: Learning Rigid Dynamics using Transformers
🔑 Keywords: RigidFormer, mesh-free rigid-body dynamics, Transformer-based model, Anchor-based RoPE, permutation-equivariant
💡 Category: Machine Learning
🌟 Research Objective:
– To develop a RigidFormer model for simulating mesh-free rigid-body dynamics efficiently and accurately using object-centric processing.
🛠️ Research Methods:
– Utilizes a Transformer-based approach with anchor-based attention mechanisms, Anchor-Vertex Pooling, and Anchor-based RoPE to enhance simulation fidelity while respecting the unordered structure of inputs.
💬 Research Conclusions:
– RigidFormer outperforms traditional mesh-based baselines in benchmark tests, efficiently scales to large numbers of objects, generalizes across unseen datasets, and offers preliminary extensions to articulated bodies.
👉 Paper link: https://huggingface.co/papers/2605.09196
60. LLaVA-UHD v4: What Makes Efficient Visual Encoding in MLLMs?
🔑 Keywords: Visual encoding, Multimodal Large Language Models, slice-based encoding, intra-ViT compression, high-resolution inputs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective of the research is to enhance visual encoding efficiency for high-resolution inputs in Multimodal Large Language Models by exploring slice-based encoding and intra-ViT early compression.
🛠️ Research Methods:
– The study employs controlled experiments to compare slice-based encoding versus global encoding, devising a framework that integrates intra-ViT early compression into the slice-based encoding process.
💬 Research Conclusions:
– The research introduces LLaVA-UHD v4, a visual encoding scheme that reduces computational costs by 55.8% while maintaining or surpassing baseline performance across various benchmarks. This work demonstrates that significant visual-encoding efficiency improvements are possible without performance compromise.
👉 Paper link: https://huggingface.co/papers/2605.08985

61. Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
🔑 Keywords: SLIM framework, agentic reinforcement learning, Skill Lifecycle Management, dynamic optimization variable, policy learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces the SLIM framework to manage dynamic skill lifecycles in agentic reinforcement learning by jointly optimizing active skill sets alongside policy learning.
🛠️ Research Methods:
– The SLIM framework uses leave-one-skill-out validation to estimate each active skill’s marginal external contribution and applies skill lifecycle operations: retaining high-value skills, retiring low-contribution skills, and expanding skill coverage when necessary.
💬 Research Conclusions:
– The SLIM framework surpasses existing baselines with a 7.1% improvement across tasks in ALFWorld and SearchQA, demonstrating that policy learning and external skill retention can coexist, supporting SLIM as a general paradigm for skill-based agentic RL.
👉 Paper link: https://huggingface.co/papers/2605.10923

62. Key-Value Means
🔑 Keywords: Key-Value Means, transformer, attention, chunked RNN, sublinear state growth
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introducing Key-Value Means (KVM), a novel mechanism integrating transformer and RNN capabilities with control over computational complexity and memory usage.
🛠️ Research Methods:
– Implementing KVM in a transformer model to allow both fixed-size and growing states with little parameter increase, and demonstrating competitive performance on long-context tasks with efficient prefill and state growth.
💬 Research Conclusions:
– Demonstrated the benefits of KVM which include expandable context memory, efficient chunk-wise parallelizable training, and memory savings, all with standard operations and hybrid solutions for long-context decoding.
👉 Paper link: https://huggingface.co/papers/2605.09877

63. X-OmniClaw Technical Report: A Unified Mobile Agent for Multimodal Understanding and Interaction
🔑 Keywords: X-OmniClaw, multimodal understanding, mobile agent, AI Native, Android environments
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces X-OmniClaw, a unified mobile agent architecture designed to enable multimodal understanding and intelligent interaction within Android environments.
🛠️ Research Methods:
– The architecture integrates layers such as Omni Perception for multimodal ingress, Omni Memory for optimized task continuity and context-awareness, and Omni Action combining XML metadata with visual perception. Techniques like Behavior Cloning and Trajectory Replay are used to capture and replay user skills.
💬 Research Conclusions:
– X-OmniClaw enhances interaction efficiency and task reliability, serving as a structural blueprint for future mobile-native personal assistants.
👉 Paper link: https://huggingface.co/papers/2605.05765

64. Auto-Rubric as Reward: From Implicit Preferences to Explicit Multimodal Generative Criteria
🔑 Keywords: Auto-Rubric as Reward (ARR), Rubric Policy Optimization (RPO), multimodal alignment, implicit preference knowledge, reward modeling
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to align multimodal generative models with human preferences through structured rubrics and improve policy gradients with binary rewards.
🛠️ Research Methods:
– An Auto-Rubric as Reward (ARR) framework is developed that externalizes implicit preference knowledge into structured rubrics, along with Rubric Policy Optimization (RPO) that stabilizes policy gradients.
💬 Research Conclusions:
– The ARR and RPO framework demonstrates improved reliability and data efficiency in multimodal alignment on benchmarks in text-to-image generation and image editing compared to traditional models.
👉 Paper link: https://huggingface.co/papers/2605.08354

65. Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
🔑 Keywords: continual post-training, large language models, catastrophic forgetting, task geometry, geometry conflict
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates how task geometry affects the continual post-training process in large language models, identifying geometry conflict as a significant factor in forgetting and a mechanism for managing update integration.
🛠️ Research Methods:
– The research examines task geometry by analyzing each post-training task through its parameter updates and studies the covariance geometry produced by these updates. It proposes the Geometry-Conflict Wasserstein Merging (GCWM) method, which employs Gaussian Wasserstein barycenters for data-free update integration.
💬 Research Conclusions:
– The study concludes that forgetting occurs due to misalignment of covariance geometries, which affects update integration. Sequential updates are successfully transferred when compatible with existing model states, but interference arises with high geometry conflict. The proposed GCWM method improves retention and performance compared to data-free baselines in the tested settings.
👉 Paper link: https://huggingface.co/papers/2605.09608

66. SEIF: Self-Evolving Reinforcement Learning for Instruction Following
🔑 Keywords: Self-Evolving Reinforcement Learning, Instruction Following, Large Language Models, Model Capability Evolution, Instruction Difficulty Evolution
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the instruction-following capabilities of Large Language Models (LLMs) using a self-evolving reinforcement learning framework known as SEIF.
🛠️ Research Methods:
– SEIF employs a closed self-evolution loop involving iterative difficulty adaptation and co-training of Instructor and Follower components. It uses roles like Instructor, Filter, Follower, and Judger to improve model performance.
💬 Research Conclusions:
– SEIF consistently enhances instruction-following performance across multiple model scales and architectures, showing strong generality. The key to improvement involves sufficient early-stage training to establish a foundation, followed by moderate late-stage training to prevent overfitting and optimize final performance. The framework’s effectiveness is supported by publicly available resources.
👉 Paper link: https://huggingface.co/papers/2605.07465

67. TMAS: Scaling Test-Time Compute via Multi-Agent Synergy
🔑 Keywords: TMAS, Large Language Models, Multi-Agent Synergy, Hierarchical Memories, Hybrid Reward Reinforcement Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance the reasoning ability of large language models by implementing a multi-agent framework called TMAS, which organizes inference as a collaborative process among agents.
🛠️ Research Methods:
– TMAS employs structured collaboration through hierarchical memory systems to facilitate efficient cross-trajectory collaboration, supported by a hybrid reward reinforcement learning scheme.
💬 Research Conclusions:
– TMAS significantly improves iterative scaling beyond existing test-time scaling techniques, with hybrid reward training further increasing the effectiveness and stability of this process.
👉 Paper link: https://huggingface.co/papers/2605.10344

68. Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
🔑 Keywords: Language models, Benchmark, Ill-posed problems, Frontier models, Mathematical knowledge
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce “Soohak,” a new 439-problem mathematical benchmark to evaluate advanced reasoning in language models.
🛠️ Research Methods:
– Created by 64 mathematicians, Soohak includes a Challenge subset for evaluating problem-solving skills and a Refusal subset to test recognition of ill-posed problems.
💬 Research Conclusions:
– Existing frontier models show significant room for improvement; none exceed 50% in recognizing ill-posed problems, highlighting a critical area for model enhancement.
👉 Paper link: https://huggingface.co/papers/2605.09063
