AI Native Daily Paper Digest – 20260515

1. Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
🔑 Keywords: Reasoning Models, Reverse-Perplexity Curriculum, Reinforcement Learning, International Mathematical Olympiad, International Physics Olympiad
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to transform post-trained reasoning models into high-performing, olympiad-level solvers capable of achieving gold-medal performance in mathematical and physics competitions.
🛠️ Research Methods:
– Utilization of reverse-perplexity curriculum to develop rigorous proof-search and self-checking behaviors.
– Implementation of a two-stage reinforcement learning pipeline, progressing from verifiable rewards to proof-level reinforcement learning.
– Enhancement of solving capabilities using test-time scaling techniques.
💬 Research Conclusions:
– The developed model, SU-01, successfully performs at a gold-medal level on various competitions, including IMO and IPhO, and shows strong generalization of scientific reasoning beyond mathematics and physics.
👉 Paper link: https://huggingface.co/papers/2605.13301

2. Self-Distilled Agentic Reinforcement Learning
🔑 Keywords: AI Native, Reinforcement Learning, On-Policy Self-Distillation, token-level guidance, sigmoid gate
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reinforcement learning for multi-turn agent training by integrating On-Policy Self-Distillation with a novel sigmoid gate mechanism.
🛠️ Research Methods:
– Developed Self-Distilled Agentic Reinforcement Learning (SDAR) which utilizes a sigmoid gate to manage the transfer of token-level guidance from a teacher branch, prioritizing positive signals while minimizing negative teacher rejections.
💬 Research Conclusions:
– SDAR significantly improves performance across several domains such as ALFWorld, WebShop, and Search-QA, showing marked improvements over traditional GRPO and other RL–OPSD methods, by effectively managing the instability issues present in naive GRPO+OPSD approaches.
👉 Paper link: https://huggingface.co/papers/2605.15155

3. SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
🔑 Keywords: SANA-WM, Hybrid Linear Attention, Dual-Branch Camera Control, Two-Stage Generation Pipeline, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– To introduce SANA-WM, an efficient 2.6B-parameter world model capable of generating high-fidelity, 720p video with precise camera control, achieving industrial-level quality and efficiency.
🛠️ Research Methods:
– Utilization of a hybrid attention mechanism combining frame-wise Gated DeltaNet and softmax attention for efficient long-context modeling.
– Implementation of Dual-Branch Camera Control to adhere to precise 6-DoF trajectories.
– Application of a Two-Stage Generation Pipeline with a long-video refiner for improved quality and consistency across sequences.
– Employing a Robust Annotation Pipeline that extracts camera poses for accurate spatiotemporal action labels.
💬 Research Conclusions:
– SANA-WM demonstrates notable efficiency in data usage, training times, and hardware requirements compared to prior models, with stronger action-following accuracy and comparable visual quality at significantly higher throughput.
👉 Paper link: https://huggingface.co/papers/2605.15178

4. Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning
🔑 Keywords: Darwin Family, evolutionary merging, gradient-free, reasoning performance, Architecture Mapper
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate whether reasoning performance in large language models can be improved without additional training using evolutionary merging techniques.
🛠️ Research Methods:
– Utilized a 14-dimensional adaptive merge genome for fine-grained recombination.
– Employed MRI-Trust Fusion to balance layer-importance signals with evolutionary search.
– Developed an Architecture Mapper to enable cross-architecture breeding.
💬 Research Conclusions:
– Darwin-27B-Opus achieved high performance on GPQA Diamond without gradient-based training, surpassing its fully trained counterparts.
– Demonstrated consistent improvement over parent models across varying scales, supporting recursive multi-generation evolution.
– Showed that training-free evolutionary merging can be a cost-effective alternative for reasoning-centric language models.
👉 Paper link: https://huggingface.co/papers/2605.14386

5. STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?
🔑 Keywords: Large Language Models, Personalized Memory, Implicit Conflict, State Resolution, State-aware Memory
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the ability of large language models to update personalized memories and resolve implicit conflicts when presented with new evidence.
🛠️ Research Methods:
– Introduced STALE, a benchmark consisting of 400 expert-validated conflict scenarios and a three-dimensional probing framework to test State Resolution, Premise Resistance, and Implicit Policy Adaptation.
💬 Research Conclusions:
– There exists a notable gap between retrieving updated evidence and acting on it in large language models, with the best model achieving only 55.2% accuracy. A prototype called CUPMem demonstrated potential for enhancing robust memory by strengthening write-time revision through structured state consolidation and propagation-aware search.
👉 Paper link: https://huggingface.co/papers/2605.06527

6. Warp-as-History: Generalizable Camera-Controlled Video Generation from One Training Video
🔑 Keywords: Warp-as-History, camera-controlled video generation, zero-shot capability, positional encoding
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop Warp-as-History, enabling camera-controlled video generation without training or test-time optimization.
🛠️ Research Methods:
– This method transforms camera-induced warps into pseudo-history representations with target-frame positional alignment and visible-token selection.
💬 Research Conclusions:
– The approach demonstrates a zero-shot capability of a video generation model to adhere to camera trajectories, enhanced by lightweight LoRA finetuning for better camera adherence and visual quality.
👉 Paper link: https://huggingface.co/papers/2605.15182
7. PREPING: Building Agent Memory without Tasks
🔑 Keywords: pre-task memory, synthetic practice, proposer-guided memory construction, procedural memory, cold-start gap
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore whether agents can build procedural memory using self-generated synthetic practice before encountering any task-specific experiences in new environments.
🛠️ Research Methods:
– Introduction of Preping framework, which utilizes proposer-guided synthetic tasks, Solver execution, and Validator feedback to construct memory efficiently.
💬 Research Conclusions:
– Preping improves agent performance in new environments compared to a no-memory baseline and is competitive with playbook-based methods, reducing deployment costs significantly by controlling feasibility, redundancy, and selective memory updates.
👉 Paper link: https://huggingface.co/papers/2605.13880

8. Realiz3D: 3D Generation Made Photorealistic via Domain-Aware Learning
🔑 Keywords: Realiz3D, domain gap, diffusion models, 3D-consistent, photorealistic
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to bridge the domain gap between synthetic renders and real images in 3D-consistent image generation through the Realiz3D framework.
🛠️ Research Methods:
– The researchers developed a lightweight framework using diffusion models, residual adapters, and layer-specific denoising strategies to decouple visual domain from control signals.
💬 Research Conclusions:
– Realiz3D effectively maintains realism in generated images while applying control signals, enhancing output consistency and photorealism across tasks like text-to-multiview generation and texturing.
👉 Paper link: https://huggingface.co/papers/2605.13852
9. Learning to Communicate Locally for Large-Scale Multi-Agent Pathfinding
🔑 Keywords: Multi-agent pathfinding, Reinforcement learning, Imitation learning, Feature sharing, Scalability
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a scalable and efficient solution for Multi-agent pathfinding (MAPF) with enhanced coordination through a learnable communication module.
🛠️ Research Methods:
– The study introduces the Local Communication for Multi-agent Pathfinding (LC-MAPF) model, applying multi-round communication between neighboring agents using a pre-trained approach to solve the MAPF problem effectively.
💬 Research Conclusions:
– LC-MAPF demonstrates superior performance and improved agent coordination compared to existing learning-based MAPF solvers without sacrificing scalability, even in diverse unseen scenarios.
👉 Paper link: https://huggingface.co/papers/2605.07637

10. Long Context Pre-Training with Lighthouse Attention
🔑 Keywords: Lighthouse Attention, causal transformers, sequence length, scaled dot-product attention, hierarchical attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enable efficient training of causal transformers at long sequences by using Lighthouse Attention to reduce computational complexity while maintaining model performance.
🛠️ Research Methods:
– Introduced a hierarchical selection-based attention algorithm that wraps around ordinary scaled dot-product attention (SDPA), incorporating subquadratic hierarchical pre- and post-processing, a symmetrical compression strategy, and a two-stage training approach.
💬 Research Conclusions:
– Preliminary experiments with Lighthouse Attention show faster total training time and lower final loss compared to full attention training, validating the effectiveness of the method.
👉 Paper link: https://huggingface.co/papers/2605.06554

11. IntentVLA: Short-Horizon Intent Modeling for Aliased Robot Manipulation
🔑 Keywords: IntentVLA, short-horizon intents, partial observability, history-conditioned, ambiguity-aware benchmark
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to enhance robot imitation learning stability through IntentVLA, a framework that encodes short-horizon intents from visual observations to address challenges of partial observability and ambiguous observations.
🛠️ Research Methods:
– The researchers introduced a history-conditioned VLA framework and developed AliasBench, a 12-task benchmark, to isolate short-horizon observation aliasing across different test environments.
💬 Research Conclusions:
– IntentVLA successfully improves rollout stability and outperforms existing VLA baselines by effectively managing imitation learning in multimodal settings.
👉 Paper link: https://huggingface.co/papers/2605.14712

12. ViMU: Benchmarking Video Metaphorical Understanding
🔑 Keywords: Video Understanding Models, Implicit Meaning, Social Contexts, ViMU, Multimodal Evidence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to address the limitation of current video understanding models in interpreting implicit meanings and social contexts that go beyond literal visual comprehension.
🛠️ Research Methods:
– The introduction of ViMU, a benchmark specifically designed to evaluate the subtext understanding capabilities of advanced video understanding models using multimodal evidence, is proposed. It utilizes both open-ended and multiple-choice questions without disclosing key evidence beforehand.
💬 Research Conclusions:
– Existing models primarily focus on literal comprehension such as object and action recognition, lacking systematic understanding of metaphorical, ironic, and social meanings. ViMU provides a means to assess if models can infer implicit meanings grounded in context and social experiences.
👉 Paper link: https://huggingface.co/papers/2605.14607

13. Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models
🔑 Keywords: Autoregressive video diffusion, attention complexity, KV cache compression, static heads, dynamic heads
💡 Category: Generative Models
🌟 Research Objective:
– To address scalability issues in Autoregressive video diffusion models by optimizing attention head caching through a novel hybrid compression strategy.
🛠️ Research Methods:
– Introduction of a hybrid KV cache compression strategy called Forcing-KV that categorizes attention heads into static and dynamic, applying structured static pruning and dynamic pruning based on segment-wise similarity.
💬 Research Conclusions:
– The proposed method significantly reduces cache memory usage by 30% and improves generation speed, achieving over 29 frames per second on a single NVIDIA H200 GPU and providing substantial speedups at various resolutions, demonstrating effective scalability enhancements.
👉 Paper link: https://huggingface.co/papers/2605.09681

14. Does Synthetic Layered Design Data Benefit Layered Design Decomposition?
🔑 Keywords: Synthetic data, Layered design editing, Vision language models, Graphic design decomposition, Data-centric study
💡 Category: Computer Vision
🌟 Research Objective:
– To investigate whether pure synthetic layered data can enhance graphic design decomposition by providing scalable training and improved layer distribution control.
🛠️ Research Methods:
– Conducted a data-centric study using the CLD baseline framework and the creation of a synthetic dataset, SynLayers.
– Utilized vision language models for generating textual supervision and automated inference inputs through VLM-predicted bounding boxes.
💬 Research Conclusions:
– Pure synthetic data outperforms non-scalable traditional datasets, proving its viability as a scalable substitute.
– Increasing training data scale leads to improved performance, with gains saturating at around 50K samples.
– Synthetic data allows balanced control over layer-count distributions, addressing imbalances seen in real-world datasets.
👉 Paper link: https://huggingface.co/papers/2605.15167

15. BOOKMARKS: Efficient Active Storyline Memory for Role-playing
🔑 Keywords: search-based memory, role-playing agents, bookmarks, AI-generated summary
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To propose a search-based memory framework named BOOKMARKS that enhances role-playing agents by actively managing task-relevant information.
🛠️ Research Methods:
– The method involves initializing, maintaining, and updating structured bookmarks to capture character behaviors and story elements effectively.
💬 Research Conclusions:
– BOOKMARKS significantly outperforms existing role-playing agent memory systems, offering advantages like active grounding and passive updating for task-specific details.
👉 Paper link: https://huggingface.co/papers/2605.14169

16. Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning
🔑 Keywords: Adaptive Teacher Exposure, Self-Distillation, Beta-policy controller, Learning-progress reward
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve large language model reasoning by dynamically adjusting teacher exposure during training through a learnable policy controller, identified as Adaptive Teacher Exposure for Self-Distillation (ATESD).
🛠️ Research Methods:
– ATESD models the reveal ratio using a lightweight Beta-policy controller, conditioned on compact training-state statistics. It optimizes this controller with a discounted learning-progress reward to improve the student’s future performance rather than just focusing on immediate loss changes.
💬 Research Conclusions:
– Experiments demonstrate that ATESD consistently outperforms existing self-distillation and RL baselines in reasoning tasks, establishing adaptive teacher exposure as an effective new axis for reasoning self-distillation.
👉 Paper link: https://huggingface.co/papers/2605.11458

17. PhyMotion: Structured 3D Motion Reward for Physics-Grounded Human Video Generation
🔑 Keywords: AI-generated summary, PhyMotion, Video Generation, Reinforcement Learning, Physics Simulator
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance the realism of AI-generated human motion in videos by introducing a physics-grounded reward system called PhyMotion.
🛠️ Research Methods:
– PhyMotion evaluates 3D human trajectories using the MuJoCo physics simulator across three axes: kinematic plausibility, contact consistency, and dynamic feasibility.
💬 Research Conclusions:
– PhyMotion shows stronger correlation with human judgments compared to existing rewards, leading to improved motion realism in videos with both automatic metrics and human evaluations, and achieves improvements with modest training overhead.
👉 Paper link: https://huggingface.co/papers/2605.14269

18. Sat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
🔑 Keywords: geometry-first methodology, geometric constraints, perspective-view training strategy, 3D accuracy, photorealism
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to generate street-level 3D scenes from satellite images with improved geometric accuracy and photorealism.
🛠️ Research Methods:
– The study employs a geometry-first approach, incorporating novel geometric constraints and a perspective-view training strategy to enhance the feed-forward image-to-3D paradigm.
💬 Research Conclusions:
– The new approach significantly enhances geometric accuracy and photorealism, outperforming existing methods such as Sat2Density++ and improving metrics like RMSE and FID. The method’s versatility is demonstrated through various applications, including semantic-map-to-3D synthesis and DSM estimation, with the code available on GitHub.
👉 Paper link: https://huggingface.co/papers/2605.14984
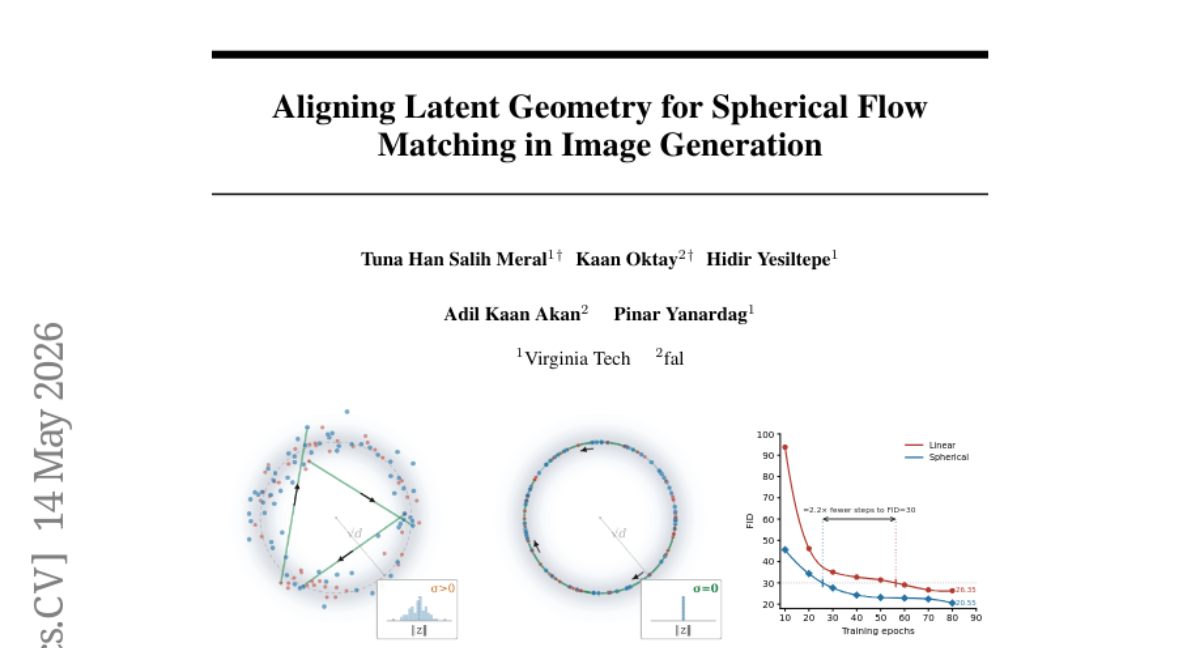
19. Aligning Latent Geometry for Spherical Flow Matching in Image Generation
🔑 Keywords: Latent Flow Matching, Geodesic Flow, Image Generation, Spherical Linear Interpolation, Variational Autoencoder
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to improve image generation by using geodesic flow matching, which involves projecting latent points onto fixed radius spheres.
🛠️ Research Methods:
– It involves decomposition of latent points into radial and angular components, and applying spherical linear interpolation instead of linear paths for image generation.
💬 Research Conclusions:
– The method enhances class-conditional ImageNet-256 FID scores consistently, maintains the diffusion architecture intact, and eliminates the need for auxiliary components.
👉 Paper link: https://huggingface.co/papers/2605.15193
20. Ideology Prediction of German Political Texts
🔑 Keywords: transformer-based model, political orientation, multiclass classifiers, DeBERTa-large, Gemma2-2B
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to create a transformer-based model to project political orientation on a continuous spectrum from left to right using multiple text corpora.
🛠️ Research Methods:
– Developed and evaluated a transformer model using four distinct corpora, including German Bundestag plenary notes and Wahl-O-Mat data, focusing on mitigating overfitting via separate training and testing datasets.
💬 Research Conclusions:
– The research concludes that transformer models, such as DeBERTa-large and Gemma2-2B, are effective in recognizing political framing across various text sources, highlighting the importance of model architecture and domain-specific training data alongside model size for estimating political bias.
👉 Paper link: https://huggingface.co/papers/2605.14352

21. LLM-based Detection of Manipulative Political Narratives
🔑 Keywords: Manipulative political narratives, Social media, Prompt-based filtering, Unsupervised clustering, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a computational framework for detecting and structuring manipulative political narratives from social media posts without relying on predefined categories.
🛠️ Research Methods:
– Implemented a few-shot prompt-based filtering to distinguish manipulative narratives from legitimate critiques.
– Utilized dimensionality reduction techniques and unsupervised clustering methods such as UMAP and HDBSCAN to identify distinct narrative clusters.
💬 Research Conclusions:
– Successfully identified 41 distinct manipulative narrative clusters from over 1.2 million social media posts by integrating prompt-based filtering with unsupervised clustering.
👉 Paper link: https://huggingface.co/papers/2605.14354

22. RewardHarness: Self-Evolving Agentic Post-Training
🔑 Keywords: RewardHarness, Agentic Reward Framework, Context Evolution, Image Edit Evaluation, Preference Demonstrations
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary objective is to develop RewardHarness, a framework designed to enhance image edit evaluation by utilizing limited human demonstrations, moving beyond traditional large-scale preference annotation models.
🛠️ Research Methods:
– The framework reimagines reward modeling through context evolution rather than weight optimization. It builds a library of tools and skills that iteratively improves with minimal human input, using a sophisticated Orchestrator and a frozen Sub-Agent to generate preference judgments.
💬 Research Conclusions:
– RewardHarness successfully achieves superior accuracy compared to existing models, even with minimal data usage. It records a 47.4% average accuracy in benchmarks, surpassing GPT-5 by 5.3 points, demonstrating its efficacy as a reward signal in RL-tuned models.
👉 Paper link: https://huggingface.co/papers/2605.08703

23. Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
🔑 Keywords: Closed-Loop Visual Reasoning, Proxy Prompt Reinforcement Learning, Δ-Space Weight Merge, Multi-Step Reasoning, Pixel-Level Diffusion Generation
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance complex image synthesis by integrating visual-language planning with pixel-level diffusion generation, addressing challenges in latency and optimization in text-to-image models.
🛠️ Research Methods:
– The Closed-Loop Visual Reasoning (CLVR) framework is introduced, combining visual-language logical planning with pixel-level diffusion generation.
– Innovations such as Proxy Prompt Reinforcement Learning (PPRL) are used for optimizing long-context scenarios by distilling multimodal histories.
– Δ-Space Weight Merge (DSWM) method is proposed to reduce inference costs without expensive re-distillation.
💬 Research Conclusions:
– The CLVR framework demonstrates superior performance over existing open-source baselines and approaches the capabilities of proprietary commercial models, enabling effective general test-time scaling for complex visual generation.
👉 Paper link: https://huggingface.co/papers/2605.14876

24. BEAM: Binary Expert Activation Masking for Dynamic Routing in MoE
🔑 Keywords: BEAM, Mixture-of-Experts, token-adaptive, binary masks
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the efficiency of Mixture-of-Experts models by introducing BEAM, a method that utilizes trainable binary masks for dynamic expert selection, aiming to reduce computation while maintaining high performance.
🛠️ Research Methods:
– Development of BEAM which incorporates trainable binary masks and uses a straight-through estimator and auxiliary regularization loss for end-to-end training.
– Implementation of a custom CUDA kernel for integration with the vLLM inference framework to ensure efficient performance.
💬 Research Conclusions:
– BEAM retains over 98% of the original model’s performance while reducing MoE layer FLOPs by up to 85%.
– Achieves up to 2.5 times faster decoding and 1.4 times higher throughput, proving its effectiveness as a practical solution for efficient MoE inference.
👉 Paper link: https://huggingface.co/papers/2605.14438

25. Quantitative Video World Model Evaluation for Geometric-Consistency
🔑 Keywords: PDI-Bench, Generative Models, Geometric Coherence, Monocular Reconstruction, Projective-Geometry Residuals
💡 Category: Generative Models
🌟 Research Objective:
– To evaluate geometric coherence in AI-generated videos using a new quantitative framework named PDI-Bench, aiming to identify geometry-specific failure modes in video generators.
🛠️ Research Methods:
– The study uses segmentation and point tracking to obtain object-centric observations, which are then converted to 3D coordinates through monocular reconstruction. This process allows for computing projective-geometry residuals to capture failure dimensions such as scale-depth alignment, 3D motion consistency, and structural rigidity.
💬 Research Conclusions:
– PDI-Bench exposes consistent geometry-specific failure modes across state-of-the-art video generators, which are not detected by standard perceptual metrics. This framework serves as a diagnostic tool toward achieving physically grounded video generation, highlighting its importance given the limitations of current evaluation methods.
👉 Paper link: https://huggingface.co/papers/2605.15185
26. CurveBench: A Benchmark for Exact Topological Reasoning over Nested Jordan Curves
🔑 Keywords: Hierarchical Topological Reasoning, Visual Reasoning, Benchmarks, Fine-Tuning, Vision-Language Models
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce CurveBench as a new benchmark for evaluating hierarchical topological reasoning from visual input using non-intersecting Jordan curves.
🛠️ Research Methods:
– Structured prediction task using a model to recover the rooted containment tree from images.
– Evaluating models like Gemini 3.1 Pro and fine-tuning vision-language models such as Qwen3-VL-8B.
💬 Research Conclusions:
– Despite simplicity, models show low accuracy on CurveBench, indicating challenges in topology-aware visual reasoning.
– Fine-tuned models show improved performance, yet there remains a significant gap, especially in difficult tasks.
👉 Paper link: https://huggingface.co/papers/2605.14068

27. PreScam: A Benchmark for Predicting Scam Progression from Early Conversations
🔑 Keywords: Conversational scams, Scam progression, Scam kill chain, Psychological actions, Real-time termination prediction
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces the PreScam benchmark, designed to model the progression of scams through multi-turn conversations to understand how real-world scams evolve over time.
🛠️ Research Methods:
– The research structures user-submitted scam reports into conversational scam instances following a hierarchy based on the scam lifecycle, annotated with psychological actions and victim responses. It benchmarks models on tasks such as real-time termination prediction and scammer action prediction.
💬 Research Conclusions:
– Current models show capability in capturing some scam-related cues yet face challenges in accurately tracking risk escalation and manipulation tactics over multiple conversation turns. Supervised encoders outperform zero-shot language models in predicting conversation termination stages.
👉 Paper link: https://huggingface.co/papers/2605.12243

28.

29. Overcoming Dynamics-Blindness: Training-Free Pace-and-Path Correction for VLA Models
🔑 Keywords: Vision-Language-Action, temporal dynamics, quadratic optimization, training-free correction, Pace-and-Path Correction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve Vision-Language-Action models’ performance in dynamic environments by addressing temporal blindness without needing retraining.
🛠️ Research Methods:
– Implementation of a training-free, closed-form inference-time operator through quadratic optimization to simultaneously correct pace and path dynamics.
💬 Research Conclusions:
– The proposed method significantly outperforms existing training-free wrappers and dynamic-adaptive methods, enhancing success rates up to 28.8% and 25.9% over foundational VLA models in dynamic-only and mixed environments, respectively.
👉 Paper link: https://huggingface.co/papers/2605.11459

30. SPIN: Structural LLM Planning via Iterative Navigation for Industrial Tasks
🔑 Keywords: DAG planning, execution control, AssetOpsBench, MCP Bench, LLM agent systems
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To improve task execution and plan validity in industrial LLM agent systems by integrating validated DAG planning with prefix-based execution control.
🛠️ Research Methods:
– Utilization of a planning wrapper named SPIN that combines validated Directed Acyclic Graph (DAG) planning with prefix-based execution control. It validates and repairs plans before execution and evaluates DAG prefixes incrementally.
💬 Research Conclusions:
– SPIN effectively reduces executed tasks and tool calls, improving the accomplishment rate on AssetOpsBench and enhances planning, grounding, and dependency scores on MCP Bench, benefiting systems like GPT OSS1 and Llama 4 Maverick.
👉 Paper link: https://huggingface.co/papers/2605.14051

31. Nexus : An Agentic Framework for Time Series Forecasting
🔑 Keywords: Nexus, multi-agent forecasting, contextual information, LLMs, temporal fluctuations
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop Nexus, a multi-agent forecasting framework that enhances accuracy and explainability by decomposing time series prediction into specialized stages to effectively integrate numerical patterns and contextual information.
🛠️ Research Methods:
– The framework isolates macro-level and micro-level temporal fluctuations, integrates contextual information when available, and synthesizes a final forecast. It adapts to both seasonal signals and volatile, event-driven information without relying on external anchors.
💬 Research Conclusions:
– Nexus demonstrates superior forecasting performance compared to state-of-the-art TSFMs and LLM baselines by utilizing current-generation LLMs’ intrinsic abilities and provides reasoning traces that explain forecast drivers, solidifying that real-world forecasting requires agentic reasoning beyond sequence modeling.
👉 Paper link: https://huggingface.co/papers/2605.14389

32. LiSA: Lifelong Safety Adaptation via Conservative Policy Induction
🔑 Keywords: Adaptive safety guardrails, Policy abstractions, Evidence-aware confidence gating, Sparse feedback, Noisy user feedback
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study proposes LiSA (Lifelong Safety Adaptation), a framework that enhances safety guardrails for AI agents by adapting to their operating environments.
🛠️ Research Methods:
– LiSA utilizes policy abstractions to generalize sparse feedback, incorporates conflict-aware local rules, and applies evidence-aware confidence gating to improve robustness against noisy feedback.
💬 Research Conclusions:
– LiSA demonstrates superior performance compared to memory-based baselines under sparse and noisy feedback conditions, offering a practical approach to safeguard AI agents against real-world risks.
👉 Paper link: https://huggingface.co/papers/2605.14454

33. Boosting Reinforcement Learning with Verifiable Rewards via Randomly Selected Few-Shot Guidance
🔑 Keywords: FEST, Reinforcement Learning, Few-Shot, Supervised Fine-Tuning, AI Native
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce FEST, a few-shot demonstration-guided reinforcement learning algorithm that combines supervised signals, on-policy learning, and weighted training to achieve high performance with minimal data.
🛠️ Research Methods:
– Utilize only 128 demonstrations from a Supervised Fine-Tuning dataset, employing a combination of supervised signal, on-policy signal, and decaying weights to prevent overfitting and ensure sample efficiency.
💬 Research Conclusions:
– FEST achieves strong performance on several benchmarks, surpassing baseline methods with significantly less data while matching their performance when a full dataset is used.
👉 Paper link: https://huggingface.co/papers/2605.15012

34. Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
🔑 Keywords: Omni-modal language models, visual shortcuts, post-training, OmniClean, self-distillation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study investigates whether current omni-modal benchmarks effectively differentiate visual shortcuts from genuine audio-visual-language evidence integration, and examines the impact of post-training techniques in visually debiased evaluation settings.
🛠️ Research Methods:
– Nine omni-modal benchmarks were audited using visual-only probing, retaining queries that could not be solved visually to create OmniClean. A post-training process, OmniBoost, involving mixed bi-modal SFT, mixed-modality RLVR, and self-distillation on the Qwen2.5-Omni-3B model was evaluated.
💬 Research Conclusions:
– The research concludes that omni-modal progress is more comprehensible with controlled visual leakage during evaluation. Additionally, small omni-modal models benefit from staged post-training, demonstrating competitive performance even without a stronger omni-modal teacher.
👉 Paper link: https://huggingface.co/papers/2605.12034

35. FutureSim: Replaying World Events to Evaluate Adaptive Agents
🔑 Keywords: FutureSim, world events, forecasting performance, test-time adaptation, reasoning about uncertainty
💡 Category: AI Systems and Tools
🌟 Research Objective:
– This study introduces FutureSim to evaluate AI agents’ long-term predictive capabilities by simulating real-world event sequences.
🛠️ Research Methods:
– The method involves using grounded simulations where AI agents forecast world events beyond their knowledge cutoff by interacting with a chronological replay of real news articles and questions.
💬 Research Conclusions:
– FutureSim demonstrated that AI agents exhibit significant performance gaps in forecasting, with best agents achieving 25% accuracy. It also highlighted areas for future research such as long-horizon test-time adaptation and reasoning about uncertainty.
👉 Paper link: https://huggingface.co/papers/2605.15188

36. Dynamic Latent Routing
🔑 Keywords: MDP, General Dijkstra Search, Dynamic Latent Routing, time-varying rewards, supervised fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the temporal composition of sub-policies in Markov Decision Processes (MDPs) with time-varying reward functions and introduce a novel method for language model post-training called Dynamic Latent Routing (DLR).
🛠️ Research Methods:
– Utilized General Dijkstra Search (GDS) to demonstrate the recovery of globally optimal policies through intermediate optimal sub-policies.
– Proposed DLR, integrating discrete latent codes and routing policies through a dynamic search, enhancing model parameters in a single training stage.
💬 Research Conclusions:
– Dynamic Latent Routing (DLR) effectively achieves superior performance in low-data fine-tuning scenarios, outperforming traditional supervised fine-tuning methods across various datasets and models with a significant average gain of +6.6 percentage points.
– DLR demonstrates structured routing behaviors, surpassing existing discrete-latent baselines that typically fall short of supervised fine-tuning.
👉 Paper link: https://huggingface.co/papers/2605.14323

37. Topology-Preserving Neural Operator Learning via Hodge Decomposition
🔑 Keywords: Hodge orthogonality, spectral interference, topological degrees of freedom, Hybrid Eulerian-Lagrangian architecture, Hodge Spectral Duality
💡 Category: Foundations of AI
🌟 Research Objective:
– This research focuses on analyzing physical field equations on geometric meshes and aims to improve accuracy and efficiency through a hybrid Eulerian-Lagrangian architecture that distinctly separates topological and geometric components.
🛠️ Research Methods:
– The study utilizes Hodge theory and operator splitting to achieve a principled operator-level decomposition, using discrete differential forms and orthogonal auxiliary spaces to capture and represent various dynamics.
💬 Research Conclusions:
– The developed Hybrid Eulerian-Lagrangian architecture, known as Hodge Spectral Duality (HSD), significantly enhances accuracy and efficiency on geometric graphs, maintaining fidelity to physical invariants.
👉 Paper link: https://huggingface.co/papers/2605.13834

38. WildTableBench: Benchmarking Multimodal Foundation Models on Table Understanding In the Wild
🔑 Keywords: WildTableBench, multimodal foundation models, table images, structural perception, numerical reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce WildTableBench as the first question-answering benchmark for real-world table images, addressing challenges in structural perception and numerical reasoning.
🛠️ Research Methods:
– Evaluation of 21 proprietary and open-source multimodal foundation models on the newly introduced WildTableBench, which contains 402 high-information-density table images and 928 manually annotated questions.
💬 Research Conclusions:
– The evaluation revealed significant challenges, with only one model exceeding 50% accuracy. Persistent weaknesses in structural perception and reasoning were identified, highlighting the benchmark’s value as a diagnostic tool for understanding capabilities.
👉 Paper link: https://huggingface.co/papers/2605.01018

39. PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution
🔑 Keywords: PRISM, Text-SR, Flow-Matching Prior Rectification, Uncertainty-aware Residual Encoding, diffusion-based
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to develop a text super-resolution framework, PRISM, designed to improve accuracy even under severe degradation.
🛠️ Research Methods:
– The study employs a diffusion-based framework integrating Flow-Matching Prior Rectification and a Structure-guided Uncertainty-aware Residual Encoder to address challenges in Text-SR.
💬 Research Conclusions:
– PRISM demonstrates state-of-the-art performance in both synthetic and real-world benchmarks with efficient, millisecond-level inference, offering improved text fidelity and readability.
👉 Paper link: https://huggingface.co/papers/2605.13027

40. Learning to Build the Environment: Self-Evolving Reasoning RL via Verifiable Environment Synthesis
🔑 Keywords: Self-improving language models, Environment-construction loop, Stable solve-verify asymmetry, EvoEnv, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to develop self-improving language models that focus on constructing training environments rather than simply generating data, leveraging the concept of stable solve-verify asymmetry to ensure informative learning rewards.
🛠️ Research Methods:
– The approach, as demonstrated in the EvoEnv system, involves synthesizing Python environments from seeds, conducting staged validation, semantic self-review, difficulty calibration, and novelty checks to maintain the challenging nature of tasks relative to the model’s capabilities.
💬 Research Conclusions:
– The study finds that models achieve stable self-improvement not by producing more synthetic data, but by creating environments that remain structurally challenging. The EvoEnv method shows improvement in performance, increasing average metrics from 72.4 to 74.8, indicating a 3.3% relative gain.
👉 Paper link: https://huggingface.co/papers/2605.14392

41. PanoWorld: Towards Spatial Supersensing in 360^circ Panorama World
🔑 Keywords: PanoWorld, spherical spatial cross-attention, panoramic reasoning, equirectangular projection, geometry-aware
💡 Category: Computer Vision
🌟 Research Objective:
– Investigate pano-native understanding requiring MLLMs to reason over ERP panoramas as continuous, observer-centered spaces.
🛠️ Research Methods:
– Defined key abilities for pano-native understanding, constructed a metadata pipeline for converting ERP panoramas into geometry-aware and depth-aware data, and introduced PanoWorld with Spherical Spatial Cross-Attention.
💬 Research Conclusions:
– PanoWorld significantly outperforms existing baselines on several benchmarks, demonstrating that effective panoramic reasoning needs pano-native supervision and model adaptation focusing on geometry awareness.
👉 Paper link: https://huggingface.co/papers/2605.13169

42. RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
🔑 Keywords: RAVEN, causal autoregressive, video generation, reinforcement learning, CM-GRPO
💡 Category: Generative Models
🌟 Research Objective:
– Develop RAVEN to enable real-time video generation using causal autoregressive extrapolation to improve training alignment.
🛠️ Research Methods:
– Introduce a new framework that aligns training with inference by repacking each self rollout into an interleaved sequence of clean and noisy states.
– Propose CM-GRPO using reinforcement learning applied directly to a conditional Gaussian transition for consistency sampling.
💬 Research Conclusions:
– RAVEN demonstrates superior performance over existing causal video distillation models in quality and dynamic evaluations.
– CM-GRPO enhances RAVEN’s performance further when combined, optimizing through a novel reinforcement learning approach.
👉 Paper link: https://huggingface.co/papers/2605.15190
43. Orchard: An Open-Source Agentic Modeling Framework
🔑 Keywords: Agentic modeling, AI-generated summary, open-source framework, scalable agent training, Credit-assignment SFT
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce Orchard, an open-source framework designed for scalable agentic modeling to train diverse autonomous agents effectively.
🛠️ Research Methods:
– Employed Orchard Env, a lightweight environment service with reusable primitives for lifecycle management.
– Developed three agentic modeling recipes: Orchard-SWE for coding, Orchard-GUI for vision-language tasks, and Orchard-Claw for personal assistance.
💬 Research Conclusions:
– Demonstrated that an open-source, harness-agnostic environment can support scalable agentic data and training across domains, achieving state-of-the-art performance metrics among comparable open-source models.
👉 Paper link: https://huggingface.co/papers/2605.15040

44. VGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction
🔑 Keywords: 3D scene editing, depth-synchronized text injection, geometric displacements, DeltaScene Dataset
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces VGGT-Edit, a framework for text-conditioned native 3D scene editing, aiming to improve the quality and efficiency over existing 2D-lifting methods.
🛠️ Research Methods:
– VGGT-Edit employs depth-synchronized text injection for aligning semantic guidance with spatial poses and a residual transformation head to predict direct geometric displacements, preserving the scene’s structure and stability.
– The approach is reinforced with a multi-term objective function to ensure geometric accuracy and multi-view consistency. Additionally, a new dataset, the DeltaScene Dataset, is constructed to validate quality and efficacy.
💬 Research Conclusions:
– VGGT-Edit significantly outperforms traditional 2D-lifting baselines, offering sharper object details, enhanced multi-view consistency, and rapid inference capabilities.
👉 Paper link: https://huggingface.co/papers/2605.15186

45. DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
🔑 Keywords: DiffusionOPD, multi-task training, online policy distillation, diffusion models, stochastic SDE
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enhance multi-task training efficiency for diffusion models using a novel approach, DiffusionOPD, leveraging online policy distillation.
🛠️ Research Methods:
– DiffusionOPD involves independently training task-specific teachers and distilling their knowledge into a unified student. It extends the OPD framework from discrete tokens to continuous-state Markov processes by deriving a closed-form per-step KL objective.
💬 Research Conclusions:
– DiffusionOPD outperforms existing reinforcement learning approaches in both training efficiency and final performance, achieving state-of-the-art results in multi-task settings.
👉 Paper link: https://huggingface.co/papers/2605.15055

46. FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
🔑 Keywords: FrontierSmith, Open-ended coding, LLM coding, Competitive programming, Idea divergence metric
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To automate the creation of open-ended coding problems from closed-ended tasks to enhance the performance of Large Language Models (LLMs) on coding benchmarks.
🛠️ Research Methods:
– Implementing FrontierSmith, an automated system that generates open-ended problem variants from existing competitive programming tasks, using a metric to select diverse solutions and training agents with synthesized data.
💬 Research Conclusions:
– The synthesized open-ended problems lead to significant performance improvements in LLMs, achieving notable score gains on FrontierCS and ALE-bench, while also promoting more interactive and token-rich agent interactions.
👉 Paper link: https://huggingface.co/papers/2605.14445
47. ATLAS: Agentic or Latent Visual Reasoning? One Word is Enough for Both
🔑 Keywords: Visual reasoning, agentic operations, functional tokens, latent visual reasoning, RL training
💡 Category: Computer Vision
🌟 Research Objective:
– The objective of the research is to develop a visual reasoning framework, ATLAS, that efficiently combines agentic operations and latent representations to improve performance on complex benchmarks.
🛠️ Research Methods:
– The study introduces ATLAS, which utilizes functional tokens serving as both agentic operations and latent visual reasoning units without requiring visual supervision, and introduces a method called Latent-Anchored GRPO to stabilize training.
💬 Research Conclusions:
– The research concludes that the ATLAS framework achieves superior performance and clear interpretability in visual reasoning tasks, showing potential for inspiring future research in the field.
👉 Paper link: https://huggingface.co/papers/2605.15198

48. EvolveMem:Self-Evolving Memory Architecture via AutoResearch for LLM Agents
🔑 Keywords: EvolveMem, adaptive memory, LLM agents, self-evolving memory, structured action space
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop EvolveMem, a self-evolving memory architecture for LLM agents, enabling truly adaptive memory through self-optimization of retrieval mechanisms.
🛠️ Research Methods:
– Utilizes a structured action space optimized by an LLM-powered diagnosis module, which performs failure log analysis and configuration adjustments, supported by a meta-analyzer for evolution cycles.
💬 Research Conclusions:
– EvolveMem achieves significant performance improvements over baselines, indicating effectiveness in adaptive retrieval strategies and successful transfer across benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.13941

49. RouteProfile: Elucidating the Design Space of LLM Profiles for Routing
🔑 Keywords: LLM profiling, routing performance, structured profiles, query-level signals, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to understand how LLM profile design affects routing performance across different routers and to distinguish the role of profiles from router design.
🛠️ Research Methods:
– A systematic evaluation was conducted across three representative routers under both standard and new-LLM generalization settings, using a general design space of LLM profiles called RouteProfile.
💬 Research Conclusions:
– Structured profiles outperform flat ones.
– Query-level signals are more reliable than domain-level signals.
– Generalization to new models benefits most from structured profiles under trainable configurations, highlighting LLM profile design as crucial for future routing research.
👉 Paper link: https://huggingface.co/papers/2605.00180

50. WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
🔑 Keywords: WildClawBench, CLI environments, multimodal tasks, Docker container, semantic verification
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate large language and vision-language models on realistic long-horizon tasks using actual CLI environments with real tools instead of synthetic sandboxes.
🛠️ Research Methods:
– Execution of 60 human-authored, bilingual, multimodal tasks within Docker containers hosting true CLI agent harnesses; uses hybrid grading combining deterministic and semantic verification.
💬 Research Conclusions:
– Current models like Claude Opus 4.7 achieve only 62.2% under OpenClaw, with significant variability among models, indicating unresolved challenges in long-horizon native-runtime evaluation.
👉 Paper link: https://huggingface.co/papers/2605.10912

51. Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems
🔑 Keywords: AI Native, Multi-agent systems, coordination, self-improvement, collective intelligence
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To provide a unified review and a conceptual roadmap for autonomous, self-improving multi-agent intelligence through structured collaboration and continuous self-diagnosis and improvement.
🛠️ Research Methods:
– Introduction of the LIFE progression framework: Lay the capability foundation, Integrate agents through collaboration, Find faults through attribution, and Evolve through autonomous self-improvement; systematic taxonomies and characterization of dependencies between stages.
💬 Research Conclusions:
– Identification of open challenges at stage boundaries with a cross-stage research agenda, aiming to enhance coordination frameworks toward self-organizing forms of collective intelligence in multi-agent systems.
👉 Paper link: https://huggingface.co/papers/2605.14892

52. MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory
🔑 Keywords: multimodal memory, visual evidence, VLM backbones, temporal tracking, detail extraction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate the capabilities of agent memory in preserving and utilizing visual evidence across various tasks.
🛠️ Research Methods:
– Introduction of the MemEye framework to assess memory with emphasis on visual evidence granularity and retrieval usage complexity.
💬 Research Conclusions:
– Current architectures struggle with preserving fine-grained visual details and reasoning about visual state changes, emphasizing the need for improved evidence routing, temporal tracking, and detail extraction techniques.
👉 Paper link: https://huggingface.co/papers/2605.15128

53. MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
🔑 Keywords: vision-language models, memory capabilities, long-context LVLMs, memory-augmented agents, multimodal retrieval
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces MEMLENS, a benchmark designed to evaluate memory capabilities in vision-language models during multi-session conversations, addressing the lack of systematic comparison between long-context LVLMs and memory-augmented agents.
🛠️ Research Methods:
– The benchmark consists of 789 questions addressing five memory abilities, evaluated at different context lengths, and includes an image-ablation study to assess the necessity of visual evidence.
💬 Research Conclusions:
– Results suggest that long-context LVLMs excel in short-context accuracy but struggle with prolonged conversations, whereas memory-augmented agents maintain length-stability but compromise on visual fidelity.
– Neither approach independently solves the task effectively, indicating a need for hybrid architectures that integrate long-context attention with structured multimodal retrieval capabilities.
👉 Paper link: https://huggingface.co/papers/2605.14906

54. Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
🔑 Keywords: causal consistency distillation, frame-wise autoregression, AI-generated video, low-latency video generation, VBench
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enable efficient frame-wise video generation with reduced latency and improved quality compared to existing chunk-wise approaches, especially for real-time interactive applications.
🛠️ Research Methods:
– The paper introduces Causal Forcing++, a principled pipeline leveraging causal consistency distillation for few-step AR initialization, enhancing efficiency and optimization.
💬 Research Conclusions:
– The proposed method outperforms the state-of-the-art chunk-wise causal forcing in frame-wise settings, evidenced by improvements in metrics like VBench Total, VBench Quality, and VisionReward while significantly reducing latency and training cost.
👉 Paper link: https://huggingface.co/papers/2605.15141
