AI Native Daily Paper Digest – 20260527

1. LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
🔑 Keywords: Parallel Box Decoding, unified visual grounding, detection, decoding throughput, localization accuracy
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to enhance efficiency and accuracy in visual grounding and detection by introducing a technique called Parallel Box Decoding (PBD).
🛠️ Research Methods:
– The study utilizes Parallel Box Decoding to decode geometric elements as atomic units in one step, leveraging substantial parallelism in the process.
– A scalable data engine was developed along with a comprehensive dataset, LocateAnything-Data, consisting of more than 138 million training samples to augment data diversity.
💬 Research Conclusions:
– Parallel Box Decoding significantly improves both decoding throughput and localization accuracy across various benchmarks.
– The use of large-scale training data alongside PBD demonstrates considerable complementary benefits for efficient and precise unified visual grounding and detection.
👉 Paper link: https://huggingface.co/papers/2605.27365
2. SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
🔑 Keywords: SpatialBench, spatial foundation models, cross-paradigm, deterministic sampling, spatial representation learning
💡 Category: Foundations of AI
🌟 Research Objective:
– To provide a comprehensive benchmark, SpatialBench, for evaluating spatial foundation models across diverse domains and tasks, and to identify their limitations.
🛠️ Research Methods:
– Developed SpatialBench featuring 19 datasets, 546 scenes across 5 spatial domains, evaluating 41 models across 6 paradigms on 5 task suites with 4 input density settings.
– Introduced deterministic sampling for rigorous evaluation.
💬 Research Conclusions:
– Current spatial foundation models lack generalization capabilities and are not yet all-round players.
– Full-context attention maximizes accuracy, while bounded-memory strategies enhance long-sequence scalability.
– High domain alignment and data quality are crucial for performance, overshadowing dataset scaling.
– Introduced DA-Next-5M and DA-Next to address data gaps and advance spatial representation learning.
👉 Paper link: https://huggingface.co/papers/2605.27367

3. Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
🔑 Keywords: Multi-view 3D reconstruction, Geometry-Aware Representation Denoising, feature space, RGB image decoder
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a novel framework, Geometry-Aware Representation Denoising (GARD), to improve multi-view 3D reconstruction under degraded conditions.
🛠️ Research Methods:
– Utilize a diffusion-based approach in the feature space of a 3D reconstructor to enhance scene geometry and imagery quality.
– Implement an additional RGB image decoder for restoring high-quality images.
💬 Research Conclusions:
– The GARD framework effectively recovers accurate scene geometry and high-quality imagery, demonstrating its efficacy on the Depth Anything 3 (DA3) benchmark.
👉 Paper link: https://huggingface.co/papers/2605.26230

4. D^2-Monitor: Dynamic Safety Monitoring for Diffusion LLMs via Hesitation-Aware Routing
🔑 Keywords: Diffusion Large Language Models, Bi-level Safety Monitor, Safety Hesitation, Lightweight Probe, Dynamic Routing Mechanism
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance safety monitoring for Diffusion Large Language Models (D-LLMs) through a novel bi-level safety monitoring mechanism.
🛠️ Research Methods:
– The proposed approach includes analyzing trajectory-level signals for safety hesitation and developing the D^2-Monitor which uses lightweight probes for real-time monitoring, activating heavier probes when necessary.
💬 Research Conclusions:
– D^2-Monitor achieves state-of-the-art performance with an efficient parameter footprint and effectively balances monitoring effectiveness and computational efficiency across multiple datasets and models.
👉 Paper link: https://huggingface.co/papers/2605.25893

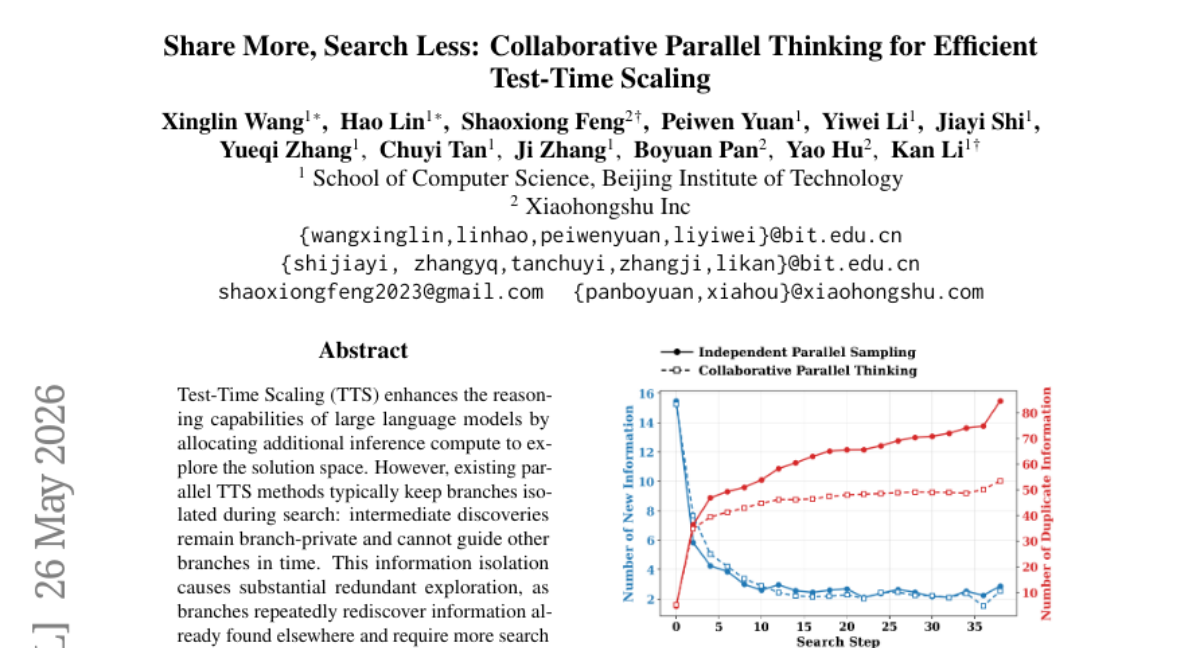
5. Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
🔑 Keywords: Collaborative Parallel Thinking, Test-Time Scaling, large language models, search-time information sharing, inference compute
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces Collaborative Parallel Thinking (CPT), aiming to enhance the efficiency of test-time scaling by enabling information sharing across parallel search branches during inference.
🛠️ Research Methods:
– CPT operates as a training-free inference framework that facilitates search-time information sharing. It constructs a deduplicated query-level information pool to disseminate compact intermediate discoveries across branches.
💬 Research Conclusions:
– Experiments on HMMT and AIME benchmarks demonstrate that CPT significantly strengthens the accuracy—latency Pareto frontier over existing methods, emphasizing the potential of search-time collaboration for efficient parallel Test-Time Scaling.
👉 Paper link: https://huggingface.co/papers/2605.27030
6. LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence
🔑 Keywords: LLaVA-OneVision-2, Windowed Attention, codec-stream tokenization, large-scale open supervision, JumpScore
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop LLaVA-OneVision-2, a vision-language model achieving superior multimodal performance across video understanding, temporal grounding, and tracking tasks.
🛠️ Research Methods:
– Utilization of Windowed Attention for efficient computation, codec-stream tokenization for allocating token budgets, and large-scale open supervision using approximately 8M re-captioned video samples for pretraining.
💬 Research Conclusions:
– LLaVA-OneVision-2 demonstrates remarkable performance, significantly surpassing existing models on multimodal benchmarks, including a notable improvement on the JumpScore benchmark and standard video, spatial, and tracking tasks.
👉 Paper link: https://huggingface.co/papers/2605.25979

7. JLT: Clean-Latent Prediction in Latent Diffusion Transformers
🔑 Keywords: latent diffusion models, clean-data prediction, latent space, JLT, FLUX.2 VAE
💡 Category: Generative Models
🌟 Research Objective:
– To evaluate whether clean-data prediction remains advantageous in latent diffusion models after images have been compressed into latent space, focusing on representation-dependent geometric choices.
🛠️ Research Methods:
– Introduction of JLT, a 130M latent diffusion Transformer, and comparison with velocity prediction DiT using the same representation and training settings; employment of local Gaussian analysis to evaluate prediction targets.
💬 Research Conclusions:
– Clean-data prediction exploits low-dimensional structures more effectively than velocity prediction in latent space, demonstrating that prediction targets are more geometrically dependent. JLT outperforms in terms of FID-50K on ImageNet with significant improvements over velocity-based methods.
👉 Paper link: https://huggingface.co/papers/2605.27102

8. Rethinking VLM Representation for VLA Initialization
🔑 Keywords: Vision-Language-Action, pretrained Vision-Language Models, embodied VQA, parameter-update strategy, robot-data pretraining
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– This study explores the initialization of Vision-Language-Action models, focusing on the integration of pretrained Vision-Language Model representations with task-specific adaptations and robot-data pretraining.
🛠️ Research Methods:
– The paper investigates VLA initialization through three main factors: capability-level embodied VQA supervision, parameter-update strategy, and robot-data pretraining. It evaluates how these factors influence action performance and initializations.
💬 Research Conclusions:
– The original pretrained VLM representation significantly impacts action performance. While embodied VQA adaptation’s benefits depend on specific bottlenecks, LoRA is more effective than Full Finetuning for reliable initialization. Robot-data pretraining enhances VLA initialization, particularly with staged LoRA-based training, suggesting the importance of retaining action-relevant and pretrained representation features.
👉 Paper link: https://huggingface.co/papers/2605.25802

9. VitaBench 2.0: Evaluating Personalized and Proactive Agents in Long-Term User Interactions
🔑 Keywords: personalized modeling, proactive interaction, user preferences, long-term user interactions, memory architectures
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To introduce VitaBench 2.0, a benchmark for evaluating personalized and proactive agent behavior in long-term user interactions by leveraging fragmented user preferences.
🛠️ Research Methods:
– Organization of tasks into temporally ordered sequences with heterogeneous interactions.
– Implementation of an extensible memory interface to support analysis of different memory architectures.
💬 Research Conclusions:
– Current large language models struggle with real-world personalization, showing a significant gap between their capabilities and practical requirements.
– Provides insights into the failure modes and capability bottlenecks of state-of-the-art models in personalized decision-making contexts.
👉 Paper link: https://huggingface.co/papers/2605.27141

10. QUACK: Questioning, Understanding, and Auditing Communicated Knowledge in Multimodal Social Deduction Agents
🔑 Keywords: QUACK, multimodal social reasoning, large language models, statement verification, adversarial settings
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce QUACK, a framework to audit the grounding of agent language in multimodal social reasoning environments.
🛠️ Research Methods:
– Evaluate agent performance through game outcomes, behavioral trajectories, and utterance-level consistency.
– Use the Statement Verification Pipeline to check the consistency and accuracy of agent claims against their ground-truth trajectories.
💬 Research Conclusions:
– Current agents, even the strongest, exhibit a significant rate of hallucination and unsupported accusations, with 15.1% of spatial claims being unverifiable and over half of accusations lacking evidence.
👉 Paper link: https://huggingface.co/papers/2605.27068
11. Beyond Final Answers: Auditing Trajectory-Level Hallucinations in Multi-Agent Industrial Workflows
🔑 Keywords: Trajectory-level hallucination, Large Language Models, Five-type taxonomy, Trajectory-aware detection, Agentic deployment
💡 Category: Natural Language Processing
🌟 Research Objective:
– To audit trajectory-level hallucinations in multi-step workflows of Large Language Models (LLMs) using the Trajel framework and a five-type hallucination taxonomy.
🛠️ Research Methods:
– Development and utilization of the Trajel dataset and evaluation framework; benchmarking of supervised detection models across subtask, trajectory, and long-context levels in multi-agent industrial workflows.
💬 Research Conclusions:
– Conventional detection methods overlook nuanced failures in intermediate steps; nearly half of hallucinated trajectories involve multiple types; trajectory-aware detection is essential for safer deployment, outperforming traditional post-hoc verification methods.
👉 Paper link: https://huggingface.co/papers/2605.24219

12. Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
🔑 Keywords: Multimodal embedding, zero-shot performance, contrastive learning, retrieval, Gemini Embedding 2
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Gemini Embedding 2, a multimodal embedding model that unifies representations for video, audio, image, and text data.
🛠️ Research Methods:
– Implement large-scale contrastive learning in a multi-task, multi-stage training setup to improve embedding performance.
💬 Research Conclusions:
– Achieved state-of-the-art performance on key embedding benchmarks, demonstrating superior zero-shot performance across specialized domains and a wide range of tasks.
👉 Paper link: https://huggingface.co/papers/2605.27295

13. RT-Lynx: Putting the GEMM Sparsity In a Right Way for Diffusion Models
🔑 Keywords: Diffusion Transformers, image generation, inference costs, activation sparsification, CUDA kernels
💡 Category: Generative Models
🌟 Research Objective:
– Propose RT-Lynx to accelerate image generation using activation sparsification and optimized CUDA kernels.
🛠️ Research Methods:
– Apply N:M sparsification to activations instead of weights.
– Incorporate error-compensation techniques.
– Utilize highly optimized CUDA kernels to enhance performance.
💬 Research Conclusions:
– RT-Lynx achieves up to a 1.55x speedup in inference while preserving the generation quality of diffusion models.
👉 Paper link: https://huggingface.co/papers/2605.26632

14. FastKernels: Benchmarking GPU Kernel Generation in Production
🔑 Keywords: LLM-based agents, GPU kernel generation, benchmarks, FastKernels, production inference frameworks
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To bridge the gap between benchmark evaluation and production performance for LLM-based GPU kernel agents using the FastKernels framework.
🛠️ Research Methods:
– Development of FastKernels, a benchmark set and inference framework that evaluates primarily on real-world deployments and aligns with production systems. It includes evaluation of 46 representative architectures covering 96.2% of HuggingFace Transformers.
💬 Research Conclusions:
– Existing benchmarks misalign with real-world inference frameworks, causing suboptimal kernel performance in production. FastKernels addresses this issue, though even the best agents only achieve a 0.94x speedup over production baselines, highlighting the critical bottleneck in the field.
👉 Paper link: https://huggingface.co/papers/2605.23215

15. Squeezing Capacity from Multimodal Large Language Models for Subject-driven Generation
🔑 Keywords: multimodal large language models, diffusion models, VAE-based identity conditioning, Dual Layer Aggregation, multi-stage denoising strategy
💡 Category: Generative Models
🌟 Research Objective:
– The paper proposes a novel approach to improve subject-driven image generation by enhancing semantic understanding and identity preservation through improved methods of encoding.
🛠️ Research Methods:
– Combines text and reference image encoding with VAE-based identity conditioning.
– Uses a Dual Layer Aggregation module for optimal conditioning of features.
– Implements a multi-stage denoising strategy to balance semantic and identity details.
💬 Research Conclusions:
– The approach effectively harmonizes multimodal understanding with identity preservation.
– It mitigates copy-paste artifacts and demonstrates superior human preference performance in subject-driven image generation.
👉 Paper link: https://huggingface.co/papers/2605.26111

16. NSF-SciFy: Mining the NSF Awards Database for Scientific Claims
🔑 Keywords: NSF-SciFy, scientific claims, investigation proposals, language models, fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The introduction of NSF-SciFy, a comprehensive dataset designed to enhance claim verification and scientific discovery tracking through language model fine-tuning.
🛠️ Research Methods:
– Developing a scalable method using zero-shot prompting for the extraction of scientific claims and proposals.
– Fine-tuning language models on the dataset to improve claim and proposal extraction, achieving significant performance gains.
💬 Research Conclusions:
– The dataset allows for substantial relative improvements in language model performance, particularly in claim and proposal extraction tasks.
– Error analysis indicates high precision but lower recall, suggesting potential for methodological advancements.
– NSF-SciFy opens new research avenues in large-scale claim verification and scientific discovery tracking.
👉 Paper link: https://huggingface.co/papers/2503.08600

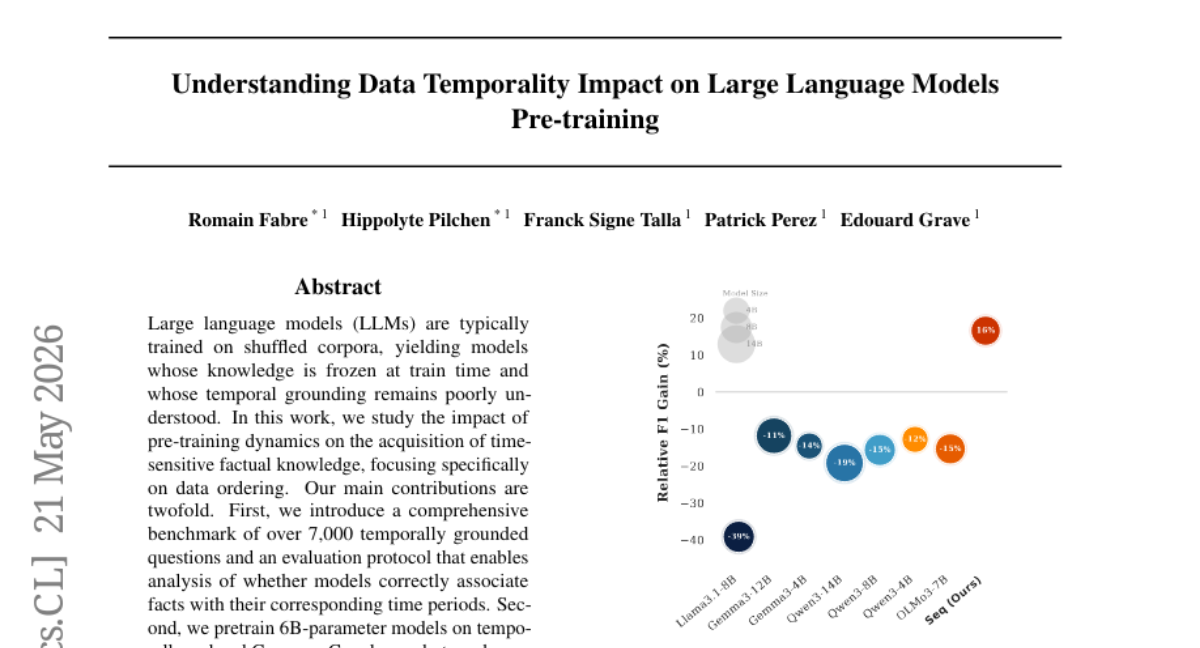
17. Understanding Data Temporality Impact on Large Language Models Pre-training
🔑 Keywords: large language models, pre-training dynamics, temporally grounded questions, factual freshness, continual learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the impact of pre-training dynamics on large language models, specifically focusing on the acquisition of time-sensitive factual knowledge through data ordering.
🛠️ Research Methods:
– Introduction of a benchmark consisting of over 7,000 questions that are temporally grounded.
– Pre-training 6B-parameter models on temporally ordered datasets and comparing them with standard shuffled pre-training.
💬 Research Conclusions:
– Sequentially trained models exhibit more up-to-date and temporally precise knowledge while maintaining general language understanding capabilities, compared to shuffled pre-training models.
– Temporally ordered pre-training improves factual freshness, providing a base for future research on continual learning for large language models.
👉 Paper link: https://huggingface.co/papers/2605.22769
18. ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models
🔑 Keywords: ZeroUnlearn, machine unlearning, model editing, representational orthogonality
💡 Category: Natural Language Processing
🌟 Research Objective:
– To reformulate machine unlearning as precise knowledge re-mapping through model editing, enabling the removal of sensitive information from large language models without compromising their general utility.
🛠️ Research Methods:
– Implemented ZeroUnlearn, a few-shot unlearning framework using model editing to overwrite sensitive inputs, employing a multiplicative parameter update with a closed-form solution.
– Developed a gradient-based variant of ZeroUnlearn for multi-sample unlearning.
💬 Research Conclusions:
– ZeroUnlearn effectively removes sensitive information while maintaining the overall utility of large language models.
– The framework outperforms existing baselines in terms of efficiency and targeted unlearning.
👉 Paper link: https://huggingface.co/papers/2605.18879

19. STREAM: A Data-Centric Framework for Mining High-Value Task-Oriented Dialogues from Streaming Media
🔑 Keywords: Stream, AI-generated, streaming media, retrieval-augmented generation, multi-domain dataset
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Stream, a data-centric framework, to generate large-scale, multi-domain service dialogues by synthesizing interactions from streaming media.
🛠️ Research Methods:
– Utilize publicly available streaming media to create high-value service dialogues.
– Integrate role-grounded persona construction and Conversational Blueprint for dialogue synthesis.
– Employ retrieval-augmented generation for knowledge-aware responses.
💬 Research Conclusions:
– The StreamDial dataset enhances dialogue quality across domains such as automotive, restaurant, and hotel.
– Models trained with StreamDial show improvements in Dialogue State Tracking and effective multilingual transfer.
– Comprehensive evaluations demonstrate superior performance compared to strong baselines.
👉 Paper link: https://huggingface.co/papers/2605.25162

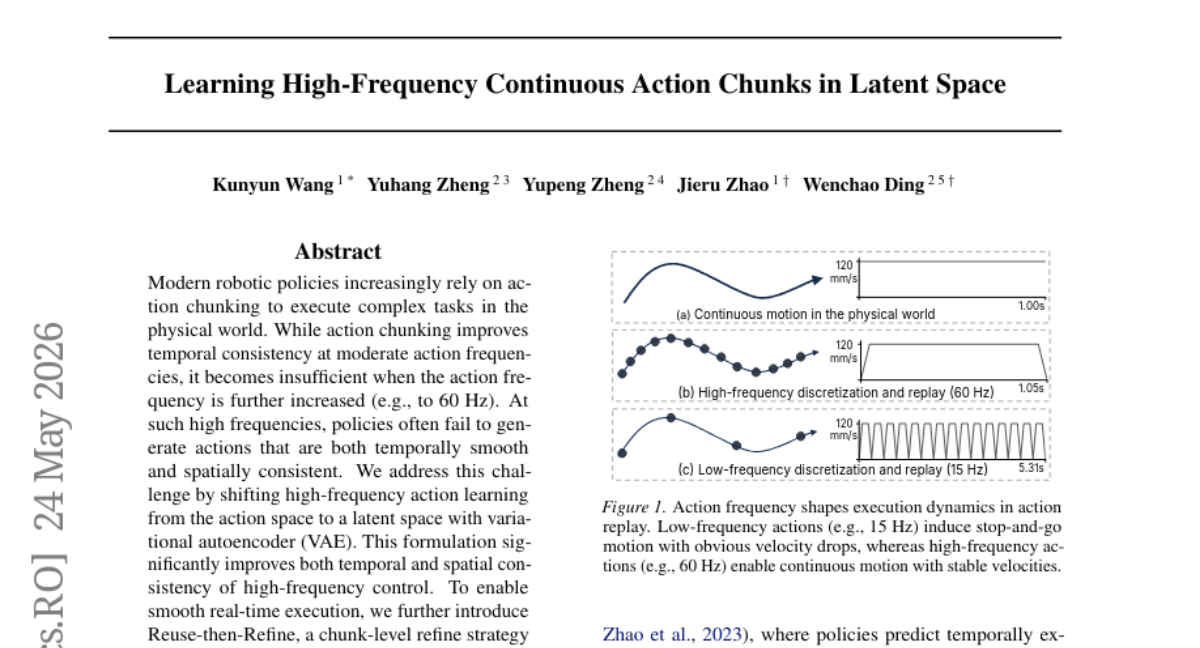
20. Learning High-Frequency Continuous Action Chunks in Latent Space
🔑 Keywords: high-frequency control, variational autoencoder, temporal consistency, spatial consistency, Reuse-then-Refine
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to improve temporal and spatial consistency in high-frequency robotic control by utilizing variational autoencoders and a reuse-then-refine strategy.
🛠️ Research Methods:
– The study employs a shift of high-frequency action learning from action space to latent space using a variational autoencoder (VAE) and introduces a “Reuse-then-Refine” strategy for smooth real-time execution in robotic policies.
💬 Research Conclusions:
– The approach enhances robots’ ability to perform complex contact-rich tasks continuously in real-world settings with fewer pauses and smoother motions, as demonstrated by experiments on three robotic tasks.
👉 Paper link: https://huggingface.co/papers/2605.24931
21.

22. EverAnimate: Minute-Scale Human Animation via Latent Flow Restoration
🔑 Keywords: EverAnimate, Animated Video Generation, Visual Quality, Character Identity, Long-Horizon
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces EverAnimate to tackle the challenges in maintaining visual quality and character identity in long-horizon animated video generation.
🛠️ Research Methods:
– Employs Persistent Latent Propagation to maintain identity and motion.
– Utilizes Restorative Flow Matching for velocity adjustment and within-chunk fidelity improvements through lightweight LoRA tuning.
💬 Research Conclusions:
– EverAnimate surpasses state-of-the-art animation methods, enhancing PSNR/SSIM and reducing LPIPS/FID across both short- and long-horizon settings.
👉 Paper link: https://huggingface.co/papers/2605.15042

23. CroCo: Cross-Lingual Contrastive Preference Tuning on Self-Generations
🔑 Keywords: Cross-lingual contrastive preference tuning, multilingual language model, self-generations, reward model, catastrophic forgetting
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance multilingual language models without needing language-specific annotations by applying cross-lingual contrastive preference tuning.
🛠️ Research Methods:
– The methodology involves using a reward model trained on English preferences and applying it to 14 languages. The setup tests both monolingual and multilingual settings to evaluate improvement across structured and open-ended tasks.
💬 Research Conclusions:
– The findings indicate that cross-lingual contrastive preference tuning is effective across different languages and tasks, with significant improvements observed in most cases. It also prevents catastrophic forgetting and demonstrates the requirement for on-policy data for optimal gains.
👉 Paper link: https://huggingface.co/papers/2605.26293

24. Can LLMs Introspect? A Reality Check
🔑 Keywords: Large Language Models, Internal States, Introspection, Pattern Matching, Metacognitive Monitoring
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate whether large language models can genuinely introspect and detect their own internal states.
🛠️ Research Methods:
– Re-examine two evaluation paradigms: detecting tampered internal states and predicting labels from hidden states.
💬 Research Conclusions:
– Current evidence suggests that large language models do not exhibit true metacognitive monitoring, as their success may be attributed to pattern matching and anomaly detection rather than genuine internal state introspection.
👉 Paper link: https://huggingface.co/papers/2605.26242

25. Agentic CLEAR: Automating Multi-Level Evaluation of LLM Agents
🔑 Keywords: Agentic Systems, Agent Behavior, Observability Layer, Textual Insights, Task Success Rate
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces Agentic CLEAR, an automatic evaluation framework aimed at providing dynamic and multi-level textual insights into agent behavior across various benchmarks and settings.
🛠️ Research Methods:
– The framework evaluates agent behavior on three levels of granularity: system, trace, and node, and incorporates experiments on four benchmarks, seven agentic settings, and tens of thousands of LLM calls.
💬 Research Conclusions:
– Agentic CLEAR effectively produces high-quality, data-driven feedback that aligns with human annotations and predicts task success rates, making agent evaluation accessible and insightful.
👉 Paper link: https://huggingface.co/papers/2605.22608

26. SAM: State-Adaptive Memory for Long-Horizon Reasoning Agent
🔑 Keywords: Long-horizon agentic reasoning, Large language models, State-Adaptive Memory, Reinforcement learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Develop a state-adaptive memory framework to enhance long-horizon reasoning in AI systems.
🛠️ Research Methods:
– Proposing the State-Adaptive Memory (SAM) framework which consolidates interactions into compact memory cues and optimizes the memory module through expert-guided supervision and reinforcement learning.
💬 Research Conclusions:
– The proposed SAM framework significantly outperformed existing methods by effectively modeling memory, offering a robust foundation for long-horizon agentic reasoning.
👉 Paper link: https://huggingface.co/papers/2605.24468

27. MRT: Masked Region Transformer for Layered Image Generation and Editing at Scale
🔑 Keywords: masked region diffusion model, multi-layer transparent image generation, text-to-layers, image-to-layers, diffusion distillation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a 20B-parameter masked region diffusion model designed for scalable multi-layer transparent image generation and editing.
🛠️ Research Methods:
– Unified handling of tasks: text-to-layers, image-to-layers, and layers-to-layers within a masked region diffusion framework.
– Introduction of an overflow-aware canvas layer for seamless layer generation and boundary management.
– Use of diffusion distillation for efficient, real-time multi-layer generation.
💬 Research Conclusions:
– MRT model outperforms existing state-of-the-art methods, including commercial systems, and establishes a new benchmark in multi-layer image generation.
– Achieves significantly improved image-to-layer quality over the Qwen-Image-Layered model, with enhanced inference speed and reduced GPU memory consumption.
👉 Paper link: https://huggingface.co/papers/2605.27235

28. Learning to Act under Noise: Enhancing Agent Robustness via Noisy Environments
🔑 Keywords: AI Native, environmental imperfections, NoisyAgent, agentic training framework, decision-making behaviors
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This research introduces NoisyAgent, an agentic training framework designed to improve agent robustness by incorporating environmental imperfections into the learning process.
🛠️ Research Methods:
– The framework identifies and incorporates user noise and tool noise into the training pipeline by modifying user interactions and simulating tool execution results. Noise is progressively increased in difficulty to adapt agents to real-world stochastic environments effectively.
💬 Research Conclusions:
– Training agents under noisy conditions not only enhances robustness in dynamic environments but also improves performance on idealized benchmarks. This approach advances generalizable reasoning and decision-making, bridging the gap between agent training and real-world deployment.
👉 Paper link: https://huggingface.co/papers/2605.27209

29. MobileMoE: Scaling On-Device Mixture of Experts
🔑 Keywords: MobileMoE, on-device deployment, Mixture-of-Experts, scaling law, quantization-aware training
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary aim is to introduce MobileMoE, efficient on-device Mixture-of-Experts language models with sub-billion parameters that offer enhanced performance and efficiency over existing dense and MoE models for mobile deployment.
🛠️ Research Methods:
– Development of an on-device scaling law to optimize MoE architectures under memory and compute constraints, focusing on achieving a balance with moderate sparsity and shared experts.
– Training MobileMoE using a comprehensive four-stage process: pre-training, mid-training, instruction fine-tuning, and quantization-aware training.
💬 Research Conclusions:
– MobileMoE demonstrates superior performance by matching or exceeding the performance of leading on-device dense LLMs with significantly fewer inference FLOPs and surpassing the state-of-the-art MoE models with fewer parameters.
– Successful demonstration of efficient MoE inference on commodity smartphones, offering significantly faster processing speeds compared to dense baseline models such as MobileLLM-Pro.
👉 Paper link: https://huggingface.co/papers/2605.27358

30. DarkForest: Less Talk, Higher Accuracy for Multi-Agent LLMs
🔑 Keywords: DarkForest, Multi-agent LLM, error propagation, communication overhead, belief distribution
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research introduces DarkForest, a framework designed to enhance reasoning in multi-agent LLM systems by managing communication and semantic clustering to reduce error propagation and communication overhead.
🛠️ Research Methods:
– DarkForest facilitates independent operation of agents, parses responses into structured records, clusters semantically equivalent candidates, and estimates belief distributions based on agent reliability, confidence, and other factors, all while implementing controlled communication.
💬 Research Conclusions:
– DarkForest demonstrated significant improvements in reasoning quality, outperforming existing methods by up to 30.7% in benchmark metrics and reducing token consumption by up to 6.5 times.
👉 Paper link: https://huggingface.co/papers/2605.25188

31. Confidence and Calibration of Activation Oracles for Reliable Interpretation of Language Model Internals
🔑 Keywords: Activation oracles, uncertainty quantification, bootstrap mode frequency, confidence scores, log-probability
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate confidence estimation methods for activation oracles and to determine the best-calibrated confidence scoring method.
🛠️ Research Methods:
– Investigation and comparison of six different confidence estimation methods using a dataset of 6,000 samples per oracle with varying verbalizers and context prompts.
💬 Research Conclusions:
– Bootstrap mode frequency provides better-calibrated confidence scores than log-probability approaches, with notable improvements in expected calibration error (ECE) across models Qwen3-8B and Qwen3.6-27B.
– Log-probability serves as a cost-effective fast triage signal despite being less well-calibrated.
👉 Paper link: https://huggingface.co/papers/2605.26045

32. Does Seeing More Mean Knowing More? Mono-Anchored Advantage Normalization for Multi-Source Visual Reasoning
🔑 Keywords: Mono-anchored, Multi-source reasoning, Reinforcement learning, Information gain, Modality interaction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a novel mono-anchored multi-source reasoning framework (MARS) that enhances reinforcement learning with verifiable rewards by effectively managing information gain and regulating modality interactions in the presence of diverse multi-source inputs.
🛠️ Research Methods:
– The framework models each visual modality as an independent information source, using mono-source rewards as dynamic anchors. It explicitly incorporates information gain into advantage normalization and adapts mutual promotion between sources while minimizing noise or conflicts.
💬 Research Conclusions:
– MARS effectively quantifies information gain caused by multi-source integration in gradient estimation, achieving consistent modality regulation. Empirical results indicate a notable performance boost (3.2% and 4.9%) on GRPO and DAPO across various datasets, demonstrating its effectiveness.
👉 Paper link: https://huggingface.co/papers/2605.25437

33. MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation
🔑 Keywords: Skill-centric agent framework, Memory-Utilizing Skill Evolution, task-solving capability, skill-level memory, cross-agent transfer
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces the MUSE-Autoskill Agent framework to enable agents to improve their task-solving capabilities by unifying skill creation, memory, management, evaluation, and refinement.
🛠️ Research Methods:
– The framework utilizes skill-level memory to accumulate experience, allowing for better reuse and adaptation of skills across tasks.
💬 Research Conclusions:
– Experiments on SkillsBench show that lifecycle-managed skills can enhance task success, efficiency, reuse, and cross-agent transfer, underscoring the importance of skills as long-lived, experience-aware, and testable assets.
👉 Paper link: https://huggingface.co/papers/2605.27366

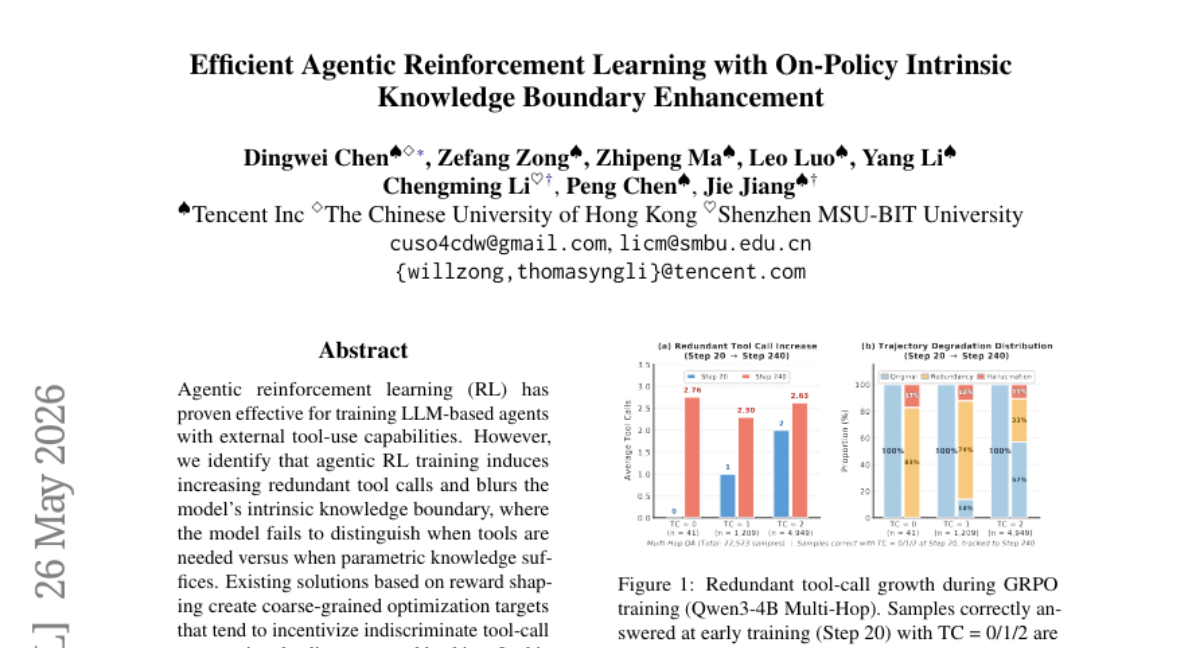
34. Efficient Agentic Reinforcement Learning with On-Policy Intrinsic Knowledge Boundary Enhancement
🔑 Keywords: AI-generated summary, agentic reinforcement learning, knowledge boundary, supervisory signals, tool productivity
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance LLM (Large Language Model) agent training by dynamically determining when external tools are necessary versus when internal knowledge is sufficient, thereby improving accuracy and reducing unnecessary tool usage.
🛠️ Research Methods:
– The researchers propose AKBE (Agentic Knowledge Boundary Enhancement), an on-policy method utilizing dual-path rollouts to probe the model’s intrinsic knowledge boundary. This method integrates targeted supervisory signals into the training loop to optimize tool-use patterns.
💬 Research Conclusions:
– Experiments on seven QA benchmarks show that AKBE improves task accuracy by an average of +1.85 and reduces tool calls by 18% compared to standard agentic RL. Furthermore, AKBE increases tool productivity by 25% without sacrificing accuracy or efficiency and is compatible with various RL algorithms.
👉 Paper link: https://huggingface.co/papers/2605.26952
35. Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
🔑 Keywords: Scale vectors, LLMs, Pre-Norm architectures, Weight decay, Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically study the role of scale vectors in large language models (LLMs) focusing on their expressivity, optimization, and architectural influence.
🛠️ Research Methods:
– Empirical analysis and theoretical study of scale vectors in LLMs, exploration of the effects of weight decay, and proposals of three improvements: branch-specific heterogeneity, improved placement, and magnitude-direction reparameterization.
💬 Research Conclusions:
– Scale vectors, though small in parameter count, are crucial for LLM optimization. They do not enhance expressivity but improve optimization in Pre-Norm architectures. Proposed improvements show consistent performance gains, lower final loss in large-scale experiments, and enhance scaling behavior with minimal parameter overhead.
👉 Paper link: https://huggingface.co/papers/2605.26895

36. Soap2Soap: Long Cinematic Video Remaking via Multi-Agent Collaboration
🔑 Keywords: Soap2Soap, video-to-video generation, narrative structure, identity drift, multi-agent framework
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenges in long-horizon video-to-video generation by maintaining narrative structure and character identity across extensive sequences.
🛠️ Research Methods:
– Introduces a multi-agent framework, Soap2Soap, with a Dual-Bridge Consistency mechanism that uses a scene-aware JSON screenplay and visual reference anchors to ensure long-term language-visual consistency.
💬 Research Conclusions:
– Experiments on SoapBench show significant improvements over commercial video generation APIs in terms of long-term consistency and narrative fidelity.
👉 Paper link: https://huggingface.co/papers/2605.17423
37. The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
🔑 Keywords: Mixture-of-Experts, MiniMax-M2, AI Native, agentic deployment
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce the MiniMax-M2 series of Mixture-of-Experts language models designed for efficient and high-performance agentic tasks deployment.
🛠️ Research Methods:
– Utilization of agent-driven data pipelines, a scalable agent-native RL system, and innovative scheduling and inference optimization techniques.
💬 Research Conclusions:
– The MiniMax-M2 series achieves frontier-tier performance by leveraging minimal activated parameters, optimized through agent-native systems and evolving self-debugging capabilities.
👉 Paper link: https://huggingface.co/papers/2605.26494

38. LongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
🔑 Keywords: LongAV-Compass, audio-visual generation, benchmark, narrative coherence, multimodal metrics
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce LongAV-Compass, a comprehensive benchmark for evaluating minute-long audio-visual generation across multiple modalities. The benchmark aims to assess quality, consistency, and alignment over extended temporal sequences.
🛠️ Research Methods:
– LongAV-Compass comprises 284 curated test cases and employs a unified evaluation framework integrating MLLM-assisted assessment and multimodal metrics like DINO-v2, ArcFace, CLIP, and ImageBind across various fine-grained dimensions such as within-segment quality and semantic alignment.
💬 Research Conclusions:
– LongAV-Compass serves as a diagnostic testbed for analyzing the limitations of current systems in producing coherent, semantically aligned, and temporally consistent audio-visual content spanning diverse input modalities.
👉 Paper link: https://huggingface.co/papers/2605.26244

39. MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
🔑 Keywords: MobileGym, deterministic evaluation, reinforcement learning, JSON state management, scalable online RL
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce MobileGym, a mobile environment that enables deterministic evaluation and scalable reinforcement learning for mobile applications.
🛠️ Research Methods:
– Utilization of a browser-hosted environment with structured JSON state management and a declarative task-definition framework.
– Implementation of parallel execution on a single server, supporting numerous instances with minimal resource requirements.
💬 Research Conclusions:
– MobileGym provides a robust platform for verifiable outcome signals and efficient RL training.
– The conducted Sim-to-Real case study demonstrated significant performance improvements and high retention of training gains on real devices.
👉 Paper link: https://huggingface.co/papers/2605.26114
40. EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
🔑 Keywords: EvalVerse, Generative Video Models, Vision-Language Models, Cinematic Assessment, Reinforcement Learning
💡 Category: Generative Models
🌟 Research Objective:
– To bridge the gap between human aesthetic judgment and machine scoring for generative video models using EvalVerse, a comprehensive evaluation framework.
🛠️ Research Methods:
– Utilization of expert-calibrated vision-language models and a multi-stage cinematic evaluation framework, organizing domain knowledge into an evaluation taxonomy, and fine-tuning these models with human expert judgments to enable Vision-Language Models to perform Chain-of-Thought reasoning.
💬 Research Conclusions:
– EvalVerse expands existing evaluation criteria beyond basic prompt-following to include cinematic quality and aesthetics, providing a richer diagnostic framework that serves as a fundamental infrastructure for future work such as reward models and evaluator agents.
👉 Paper link: https://huggingface.co/papers/2605.23271