AI Native Daily Paper Digest – 20260529

1. AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
🔑 Keywords: agent safety alignment, taxonomy-guided training, lightweight agents, real-time safety moderation, AI models
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The main objective is to develop a lightweight and scalable agent safety alignment framework to address safety risks introduced by advanced AI models like OpenClaw and Codex.
🛠️ Research Methods:
– The framework uses a taxonomy-guided data engine and influence-function purification to train AgentDoG 1.5 variants with minimal samples, enabling efficient deployment and real-time safety moderation.
💬 Research Conclusions:
– AgentDoG 1.5 demonstrates state-of-the-art performance in complex interactive scenarios and significantly reduces deployment overhead, facilitating its broader real-world application.
👉 Paper link: https://huggingface.co/papers/2605.29801

2. OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
🔑 Keywords: OmniRetrieval, Knowledge Sources, Natural-Language Query, Source-Native Queries, Heterogeneous Sources
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces OmniRetrieval, a framework designed to handle diverse knowledge sources by identifying appropriate repositories and dispatching native queries, enhancing information retrieval across multiple dataset types.
🛠️ Research Methods:
– The framework processes any natural-language query and selectively employs source-native queries dispatched to their respective execution engines. This approach contrasts with single-source retrievers and accounts for structural distinctions, tested across 13 datasets and 309 distinct knowledge bases.
💬 Research Conclusions:
– OmniRetrieval outperforms existing single-source approaches by serving as a general-purpose interface to heterogeneous data sources, preserving the structural distinctions that make each source valuable.
👉 Paper link: https://huggingface.co/papers/2605.29250

3. minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
🔑 Keywords: real-time interactive video world models, causality, low-latency, autoregressive training, camera control
💡 Category: Generative Models
🌟 Research Objective:
– This paper presents minWM, a comprehensive framework aiming to transform bidirectional video diffusion models into real-time interactive world models with capabilities for control, causality, and low latency.
🛠️ Research Methods:
– The framework uses a full-stack open-source approach, involving steps such as fine-tuning, autoregressive training, few-step distillation, and streaming inference to convert video models.
– Causal Forcing is employed alongside AR diffusion training, causal ODE, causal consistency distillation, and asymmetric DMD for model adaptation.
💬 Research Conclusions:
– minWM provides an adaptable and reproducible method for developing real-time interactive video models, which is validated by integrating with different architectures and assessing features like camera trajectory quality and controllability.
👉 Paper link: https://huggingface.co/papers/2605.30263
4. GenClaw: Code-Driven Agentic Image Generation
🔑 Keywords: agentic image generation, visual comprehension, LLMs, code-driven, generative models
💡 Category: Generative Models
🌟 Research Objective:
– To develop GenClaw, a code-driven image generation framework that mimics human artistic processes including conceptualization, sketching, and coloring.
🛠️ Research Methods:
– The integration of code (e.g., SVG, HTML, Three.js) to create executable visual sketches as an intermediate step, bridging linguistic reasoning and pixel synthesis with generative models.
💬 Research Conclusions:
– GenClaw transforms image generation from a black-box process into a human-like staged creation system, enhancing control and interpretability in visual generation systems.
👉 Paper link: https://huggingface.co/papers/2605.30248

5. How LoRA Remembers? A Parametric Memory Law for LLM Finetuning
🔑 Keywords: parametric memory, LoRA, power law, phase transition, MemFT
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to investigate the quantitative limits of parametric memory in large language models and establish a power law relationship through the use of LoRA as a probe.
🛠️ Research Methods:
– The study employs LoRA as a controlled memory capacity probe within the latent space to systematically quantify exact parametric memory and introduces a threshold-guided optimization strategy (MemFT) to improve memory performance.
💬 Research Conclusions:
– The study introduces the Parametric Memory Law, demonstrating a robust power law linking loss reduction to effective parameters and sequence length. It reveals a deterministic phase transition at the token level and proves that MemFT can dynamically enhance memory fidelity and efficiency.
👉 Paper link: https://huggingface.co/papers/2605.30260

6. Native Audio-Visual Alignment for Generation
🔑 Keywords: AI Native, audio-video generation, synchronization, controllability, Timbre-in-Context
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce NAVA, a Native Audio-Visual Alignment framework, to enhance synchronization and controllability in joint audio-video generation.
🛠️ Research Methods:
– Utilize an Align-then-Fuse MMDiT architecture for modality-aware audio-video alignment followed by joint denoising.
– Implement Timbre-in-Context Conditioning to associate reference timbre cues with certain speech spans for controlled speech timbre.
💬 Research Conclusions:
– Demonstrated NAVA’s superior video quality and precise audio-visual synchronization with competitive audio quality and effective timbre controllability using 6.3B parameters.
👉 Paper link: https://huggingface.co/papers/2605.30073

7. LaRA: Layer-wise Representation Analysis for Detecting Data Contamination in RL Post-Training
🔑 Keywords: LaRA, data contamination, reinforcement learning, large language models, layer-wise representation analysis
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To detect data contamination in reinforcement learning post-trained large language models using LaRA, which examines geometric deviations across model layers.
🛠️ Research Methods:
– Proposed a layer-wise representation analysis framework with three metrics: perturbation sensitivity, directional collapse, and local representation rigidity, under controlled perturbations.
💬 Research Conclusions:
– LaRA’s contamination detection protocol outperforms existing output-level baselines, demonstrating that contamination leads to progressive geometric deviations across layers in RL-trained reasoning models.
👉 Paper link: https://huggingface.co/papers/2605.29888

8. Xetrieval: Mechanistically Explaining Dense Retrieval
🔑 Keywords: dense retrieval, high-dimensional embeddings, Xetrieval, human-interpretable features, reasoning internalizer
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The primary goal is to enhance sentence embeddings used in dense retrieval with reasoning information, decomposing them into human-interpretable sparse features for better explanation of retrieval decisions.
🛠️ Research Methods:
– Introduction of the Xetrieval framework, which uses a reasoning internalizer to incorporate Chain-of-Thought reasoning directly within the embedding space, followed by decomposition into sparse features that are human-interpretable.
💬 Research Conclusions:
– Xetrieval successfully uncovers interpretable features and provides feature-level explanations of retrieval decisions, showing coherence and strong intervention effects across various benchmarks and retrievers.
👉 Paper link: https://huggingface.co/papers/2605.29507

9. Why Far Looks Up: Probing Spatial Representation in Vision-Language Models
🔑 Keywords: Vision-language models, spatial reasoning, representation-level analysis, perspective bias, robustness
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to understand if vision-language models (VLMs) have a true 3D spatial understanding or if they rely on statistical shortcuts by analyzing the entangled spatial representations within these models.
🛠️ Research Methods:
– A representation-level analysis framework is implemented using minimalist contrastive pairs to evaluate how spatial axes are organized and disentangled in VLM embeddings.
💬 Research Conclusions:
– The analysis shows a consistent vertical-distance entanglement, reflecting the perspective bias of natural photos, causing accuracy gaps across benchmarks.
– Introducing a synthetic benchmark, SpatialTunnel, exposed model-intrinsic spatial shortcut biases, asserting that well-structured spatial representations enhance robustness and reliability in spatial reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2605.30161

10. Is Position Bias in Dense Retrievers Built In-or Learned from Data?
🔑 Keywords: Dense retrievers, positional bias, query-relevant information, retrieval performance, position-balanced training
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate how the positional distribution of evidence in training data affects retrieval-level bias in dense retrievers.
🛠️ Research Methods:
– Construct synthetic position-targeted training sets and fine-tune eight architecturally diverse pretrained models under position-skewed and balanced training distributions.
💬 Research Conclusions:
– Balanced training significantly reduces positional sensitivity by up to 87% while maintaining competitive retrieval performance, identifying training-position distribution as a major controllable factor in retrieval-level position bias.
👉 Paper link: https://huggingface.co/papers/2605.26578

11. AsyncTool: Evaluating the Asynchronous Function Calling Capability under Multi-Task Scenarios
🔑 Keywords: LLM-based agents, asynchronous tool calling, AsyncTool, task coordination, temporal reasoning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate LLM-based agents’ capability in asynchronous tool calling, focusing on their task coordination and temporal reasoning in environments with delayed tool feedback.
🛠️ Research Methods:
– The researchers introduced a benchmark named AsyncTool, which assesses LLM-based agents in interactive multi-task tool-use scenarios with simulated tool response latency and evaluates models at different levels using efficiency-oriented metrics.
💬 Research Conclusions:
– The findings reveal substantial challenges due to delayed tool feedback, leading to performance degradation. Efficient task coordination, dependency tracking, and state maintenance are critical for improved performance, suggesting directions for future enhancements in temporal reasoning and coordination capabilities.
👉 Paper link: https://huggingface.co/papers/2605.27995

12. UI-KOBE: Knowledge-Oriented Behavior Exploration for Lightweight Graph-Guided GUI Agents
🔑 Keywords: GUI agents, app-specific graph knowledge, lightweight models, runtime decisions, task planning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to enhance lightweight mobile GUI agents for improved task planning and execution efficiency using reusable app-specific graph knowledge.
🛠️ Research Methods:
– Development of the UI-KOBE framework, which involves autonomously exploring a mobile app to construct an app knowledge graph representing UI states and executable transitions.
💬 Research Conclusions:
– UI-KOBE supports runtime decision-making with graph guidance, reducing the burden on end-to-end GUI planning and enabling more efficient, interpretable, and privacy-conscious performance by lightweight models.
👉 Paper link: https://huggingface.co/papers/2605.29534

13. PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
🔑 Keywords: Automated peer review, LLMs, Argument mining, Retrieval-augmented verification, PRISM
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate the performance of LLM-based automated peer review systems against human reviewers across various dimensions of review quality.
🛠️ Research Methods:
– Introduction of PRISM, a benchmarking framework that assesses review quality on dimensions such as depth of analysis, novelty assessment, flaw identification, and constructiveness using argument mining and retrieval-augmented verification.
💬 Research Conclusions:
– LLMs can match or exceed human reviewers in individual aspects like novelty verification and priority of critique, but no single system matches human reviewers across all dimensions consistently. LLM-based systems are best used as supplements rather than standalone replacements for human reviews.
👉 Paper link: https://huggingface.co/papers/2605.26730

14. PhyGenHOI: Physically-Aware 4D Generation of Dynamic Human-Object Interactions
🔑 Keywords: 4D Human-Object Interaction, Motion Diffusion Model, Material Point Method, AI-generated summary, 3D Gaussian representations
💡 Category: Generative Models
🌟 Research Objective:
– To generate physically accurate and visually faithful 4D human-object interactions using AI techniques.
🛠️ Research Methods:
– Combination of motion diffusion models with material point method simulations using 3D Gaussian representations.
– Introduction of PhyGenHOI framework to integrate generative human motion and physical object simulation.
💬 Research Conclusions:
– PhyGenHOI effectively generates consistent 4D human-object interactions across varied actions, outperforming existing baselines.
👉 Paper link: https://huggingface.co/papers/2605.30268

15. Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
🔑 Keywords: CorVer, Wikipedia co-occurrence statistics, factual accuracy, reinforcement learning, sentence-level feedback
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance factual accuracy in knowledge-intensive question answering systems by developing a reward mechanism that improves upon traditional neural verifiers.
🛠️ Research Methods:
– The CorVer framework employs a corpus-grounded reward signal based on Wikipedia co-occurrence statistics to provide precise sentence-level feedback, distinguishing correct from incorrect statements.
💬 Research Conclusions:
– CorVer demonstrates improved performance over baselines, including four neural-verifier setups, and achieves faster training times. It consistently improves results across a diverse set of benchmark scenarios.
👉 Paper link: https://huggingface.co/papers/2605.29648

16. REPOT: Recoverable Program-of-Thought via Checkpoint Repair
🔑 Keywords: RePoT, Program-of-Thought, deterministic verified replay, LLM call, checkpoint information
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to enhance the one-shot Program-of-Thought model by introducing RePoT, which allows for deterministic verified replay and recovery through interaction with the environment.
🛠️ Research Methods:
– RePoT employs a deterministic verified replay that advances the action plan until an invalid transition occurs, then resumes with a single Large Language Model (LLM) call for continuation.
– An Adaptive RePoT approach is tested, utilizing a rule-based dispatcher for routing between suffix repair and a fresh PoT retry.
💬 Research Conclusions:
– RePoT significantly improves success rates over the original PoT across various models and benchmarks, such as PuzzleZoo-775 and PlanBench Blocksworld.
– Performance gains are notable in certain models, with RePoT achieving peak rates and outperforming matched-budget PoT-retry baselines.
– Utilizing checkpoint information greatly enhances recovery success over error-only feedback, establishing it as a critical recovery signal.
👉 Paper link: https://huggingface.co/papers/2605.30052

17. WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
🔑 Keywords: Multimodal large language models, long-horizon agents, Action-World Interaction Loop, WorldMemArena, harness-based memory agents
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To formulate multimodal agent memory as an Action-World Interaction Loop and instantiate it in WorldMemArena for comprehensive analysis.
🛠️ Research Methods:
– Development of WorldMemArena with 400 multi-session multimodal tasks for detailed diagnostics of memory systems through various stages.
– Comparison of long-context, manually designed memory systems and harness-based memory agents.
💬 Research Conclusions:
– Better memory writing and storage do not necessarily lead to improved performance.
– Multimodal memory systems struggle to effectively utilize visual evidence.
– Systems show instability across different domains and degrade in agentic trajectories.
– Harness-based memory, while more flexible, is costly and less reliable.
👉 Paper link: https://huggingface.co/papers/2605.29341

18. SmartDirector: Keyframe-Conditioned Cinematic Video Generation with Narrative Pacing Control
🔑 Keywords: SmartDirector, video generation, narrative structure, keyframes, temporal pacing
💡 Category: Generative Models
🌟 Research Objective:
– The primary aim is to enhance the narrative capacity of video generation models using multiple keyframes to improve both narrative structure and temporal pacing.
🛠️ Research Methods:
– SmartDirector employs a two-stage process comprising low-resolution generation (Director-Gen) and high-resolution refinement (Director-SR), using keyframes as semantic anchors. A data pipeline is constructed to support robust multi-keyframe training.
💬 Research Conclusions:
– Extensive experiments indicate that SmartDirector significantly outperforms existing state-of-the-art video generation methodologies. Plans to release the code aim to facilitate further research in this area.
👉 Paper link: https://huggingface.co/papers/2605.27891

19. AdaState: Self-Evolving Anchors for Streaming Video Generation
🔑 Keywords: Video diffusion models, AI-generated summary, Autoregressive video diffusion, Adaptive state
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance video dynamics by utilizing adaptive state replacement in video diffusion models, moving beyond fixed initial frame references.
🛠️ Research Methods:
– Implementing a recurrent denoising function as the transition mechanism, the model dynamically generates scene anchors at each step by referencing both previous states and current content.
💬 Research Conclusions:
– The introduction of an adaptive state significantly improves video dynamics, allowing for more fluid motion and natural scene progression in generated videos.
👉 Paper link: https://huggingface.co/papers/2605.30349
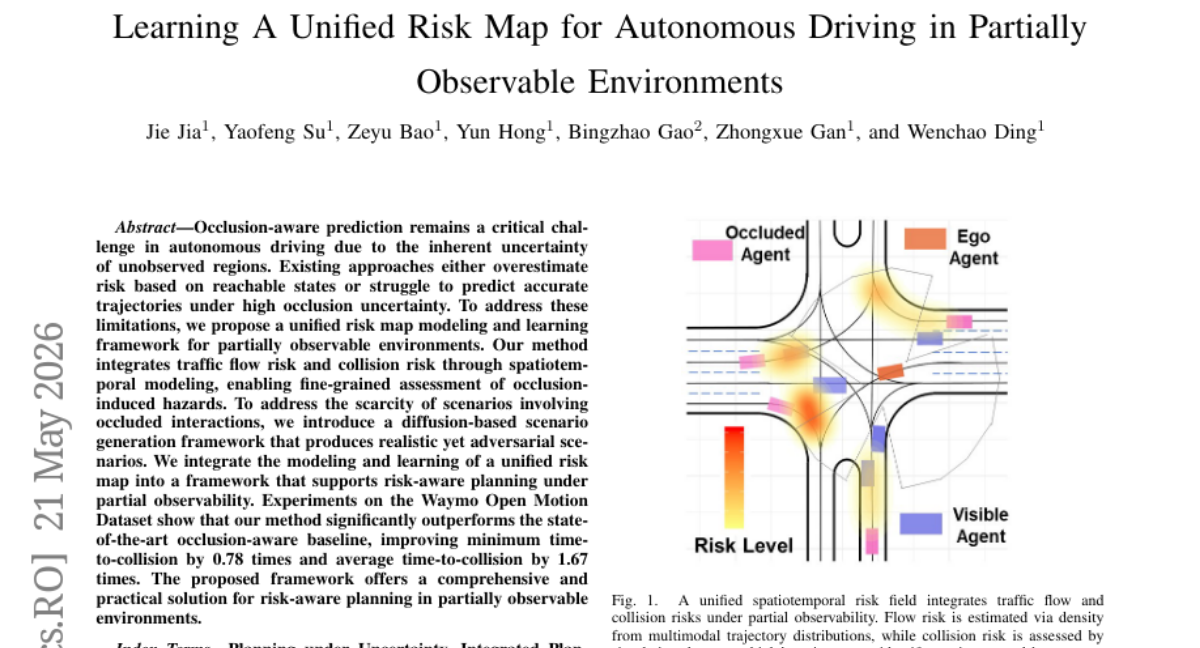
20. Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
🔑 Keywords: Occlusion-aware prediction, unified risk map modeling, spatiotemporal modeling, diffusion-based scenario generation, risk-aware planning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To address occlusion challenges in autonomous driving by integrating traffic flow and collision risks through spatiotemporal modeling and scenario generation.
🛠️ Research Methods:
– Development of a unified risk map modeling and learning framework that leverages spatiotemporal modeling.
– Introduction of a diffusion-based scenario generation framework for producing realistic yet adversarial scenarios.
💬 Research Conclusions:
– The proposed framework significantly outperforms existing baselines, offering improved minimum and average time-to-collision in tests using the Waymo Open Motion Dataset.
– Provides a comprehensive solution for risk-aware planning in partially observable environments.
👉 Paper link: https://huggingface.co/papers/2605.22189
21. Thinking Before Constraining: A Unified Decoding Framework for Large Language Models
🔑 Keywords: In-Writing, Hybrid Approach, Free-form Reasoning, Structured Generation, Trigger Token, Classification, Reasoning, Constrained Decoding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a hybrid approach called In-Writing that combines free-form reasoning with structured generation to enhance accuracy in classification and reasoning tasks.
🛠️ Research Methods:
– Utilizing a newly proposed mechanism where structured decoding is only applied after a trigger token is generated, allowing for decoupling of reasoning from formatting.
💬 Research Conclusions:
– The In-Writing approach outperforms state-of-the-art methods, achieving up to 27% accuracy gains over natural generation, effectively addressing issues with premature triggering in constrained decoding.
👉 Paper link: https://huggingface.co/papers/2601.07525

22. NeuROK: Generative 4D Neural Object Kinematics
🔑 Keywords: 4D dynamics, latent space, Neural Object Kinematics, transformer-based encoder-decoder model, neural simulation framework
💡 Category: Generative Models
🌟 Research Objective:
– Develop a data-driven kinematic state parameterization for dynamic object simulation, called Neural Object Kinematics (NeuROK), that utilizes a latent space and transformer-based encoding-decoding.
🛠️ Research Methods:
– Leverage a large-scale 4D dataset to train a transformer-based encoder-decoder model, focusing on learning a latent space for object states and a decoder for shape deformation.
💬 Research Conclusions:
– The proposed method significantly simplifies generating 4D dynamics by reducing the problem to a low-dimensional latent space, demonstrating effectiveness and generality across diverse dynamic objects.
👉 Paper link: https://huggingface.co/papers/2605.30347
23. Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
🔑 Keywords: Larger models, Model scaling, Gradient interference, Task features, Resource allocation
💡 Category: Foundations of AI
🌟 Research Objective:
– To investigate why larger models outperform smaller ones on complex and rare tasks, even with infinite training data.
🛠️ Research Methods:
– Study of model scaling effects using synthetic setups with a mixture of tasks.
– Pretraining OLMo models ranging from 4M to 4B parameters on tasks of varying frequency and complexity.
💬 Research Conclusions:
– Larger models reduce gradient interference allowing for better task feature learning.
– Small models allocate resources poorly to rare and complex tasks, while larger models embed more task features.
– These findings provide insights into model sizing and training data mixtures for practical applications.
👉 Paper link: https://huggingface.co/papers/2605.29548

24. ChildVox: A Speech, Audio, and Large Audio-Language Model Benchmark in Understanding and Characterizing Sound across Childhood
🔑 Keywords: ChildVox, acoustic signals, audio and speech foundation models, development stages, cross-domain comparison
💡 Category: AI in Education
🌟 Research Objective:
– To develop ChildVox, a benchmark for analyzing children’s acoustic communication across developmental stages using diverse audio and speech models.
🛠️ Research Methods:
– Integration of more than 20 sub-tasks from 17 child-centered datasets to enable systematic cross-corpus and cross-domain comparison.
– Evaluation of audio and speech models including self-supervised, ASR-oriented, and large audio-language models on various tasks.
💬 Research Conclusions:
– ChildVox offers high-performance models for recognizing a wide range of children’s acoustic signals, aiding in characterizing language levels and tracking speech production with age.
👉 Paper link: https://huggingface.co/papers/2605.29257

25. RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
🔑 Keywords: RUBRIC-ARROW, reward modeling, rubric-based methods, pairwise preference data, LLM post-training
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary aim of RUBRIC-ARROW is to improve reward modeling by overcoming limitations of rubric-based methods, particularly focusing on reducing ties and utilizing pairwise preference data effectively.
🛠️ Research Methods:
– The study employs an alternating framework that includes a rubric generator and a rubric-conditioned judge. The RL stage leverages pairwise preference data, using a probability-based scoring rule and phase-specific preference-based rewards within an alternating GRPO scheme.
💬 Research Conclusions:
– RUBRIC-ARROW enhances reward-modeling accuracy and ensures consistent improvement for downstream policy post-training through its innovative approach.
👉 Paper link: https://huggingface.co/papers/2605.29156

26. Towards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation
🔑 Keywords: Multi-agent system, multimodal reports, autonomous agents, Visual Working Memory, verifier agent
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a multi-agent system, Ptah, for generating reliable and visually informative multimodal reports by interleaving textual and visual evidence.
🛠️ Research Methods:
– Utilization of specialized agents for constructing visual-aware plans and collecting claim-grounded evidence.
– Use of a verifier agent to ensure factual grounding and cross-modal consistency.
– Introduction of PtahEval, an evaluation protocol with image-level and presentation-level assessments.
💬 Research Conclusions:
– Ptah produces more reliable and visually informative multimodal reports than existing strong baselines on deep research benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.29861

27. LiteCoder-Terminal: Scaling Long-Horizon Terminal Environments for Learning Language Agents
🔑 Keywords: LiteCoder-Terminal-Gen, language agents, multi-step planning, executable environments, AI-generated summary
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces LiteCoder-Terminal-Gen, aiming to enable scalable training of language agents in terminal environments through the use of synthetic and executable environments.
🛠️ Research Methods:
– A zero-dependency synthesis pipeline is deployed to autonomously generate verifiable terminal training environments from domain specifications, creating resources like LiteCoder-Terminal-SFT and LiteCoder-Terminal-RL.
💬 Research Conclusions:
– The synthetic environments created provide a scalable supervision signal, significantly improving performance in command-line workflows, with notable success in supervised fine-tuning and Direct Multi-turn Preference Optimization (DMPO).
👉 Paper link: https://huggingface.co/papers/2605.29559

28. When Cloud Agents Meet Device Agents: Lessons from Hybrid Multi-Agent Systems
🔑 Keywords: Hybrid multi-agent systems, Large language models, Small language models, On-device inference, Task accuracy
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to systematically examine the design space of Hybrid multi-agent systems (MASs) that balance large and small language models to optimize task accuracy, cost efficiency, and energy consumption.
🛠️ Research Methods:
– Two representative MAS architectures were adapted to support hybrid inference, analyzing how design choices affect the balance of power, cost, and performance along the Pareto frontier.
💬 Research Conclusions:
– The research reveals that optimal architecture for MASs is highly task-dependent, with small language models benefiting from large model assistance. However, higher compute does not always lead to better performance.
👉 Paper link: https://huggingface.co/papers/2605.30102

29. CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
🔑 Keywords: CausaLab, LLM Agents, causal discovery, structural causal model, intervention
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces CausaLab, a scalable environment designed to evaluate interactive causal discovery by Large Language Model (LLM) agents, focusing on both accurate predictions and the faithful recovery of underlying causal mechanisms.
🛠️ Research Methods:
– Agents are placed in a synthetic laboratory where they receive prior measurements, conduct interventions, and predict outcomes, with the hidden process being a randomly sampled structural causal model.
💬 Research Conclusions:
– The study reveals a gap between prediction accuracy and causal mechanism recovery in LLM agents, suggesting intervention strategies improve results but remain challenging; consistency verification helps address premature stopping issues.
👉 Paper link: https://huggingface.co/papers/2605.26029

30. Colored Noise Diffusion Sampling
🔑 Keywords: Diffusion models, spectral bias, Colored Noise Sampling, stochastic differential equation, FID
💡 Category: Generative Models
🌟 Research Objective:
– Address spectral bias in image synthesis by developing a new sampling method called Colored Noise Sampling (CNS).
🛠️ Research Methods:
– Introduce a novel mathematical framework reinterpreting SDE inference as frequency-decoupled energy transfer, utilizing dynamic, frequency-dependent schedules to allocate injected energy during image generation.
💬 Research Conclusions:
– CNS significantly outperforms standard ODE and SDE baselines by reducing FID scores across various architectures and maintaining consistent improvements with Classifier-Free Guidance.
👉 Paper link: https://huggingface.co/papers/2605.30332

31. When Should Models Change Their Minds? Contextual Belief Management in Large Language Models
🔑 Keywords: Contextual Belief Management, reinforcement learning, BeliefTrack, representation-level steering, Natural Language Processing
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance language models’ capabilities in managing long-term information, specifically focusing on updating, preserving, and filtering relevant information through Contextual Belief Management (CBM).
🛠️ Research Methods:
– Implementation of a closed-world benchmark called BeliefTrack to measure CBM effectiveness in Rule Discovery and Circuit Diagnosis, using reinforcement learning with belief-state rewards and representation-level steering techniques.
💬 Research Conclusions:
– Vanilla language models often fail in CBM tasks, but using reinforcement learning significantly lowers failure rates by 70.9%, with additional benefits from representation-level steering reducing failures by 46.1%.
👉 Paper link: https://huggingface.co/papers/2605.30219

32. Skill0.5: Joint Skill Internalization and Utilization for Out-of-Distribution Generalization in Agentic Reinforcement Learning
🔑 Keywords: Skill0.5, Agentic Reinforcement Learning, Cognitive Foundation, Diagnostic Probing, Dynamic Router
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To propose Skill0.5, an innovative reinforcement learning framework for improving task performance by balancing general skill internalization and task-specific skill utilization.
🛠️ Research Methods:
– Utilizes a dynamic, difficulty-aware router to stream tasks into mastery tiers, combining privileged distillation for complex tasks with diagnostic probing for simpler tasks.
💬 Research Conclusions:
– Skill0.5 exhibits superior performance compared to traditional memory-based and skill-based RL methods, demonstrating effectiveness across both in-distribution and out-of-distribution scenarios.
👉 Paper link: https://huggingface.co/papers/2605.28424

33. LoMo: Local Modality Substitution for Deeper Vision-Language Fusion
🔑 Keywords: Modality Substitution, Vision-Language Models, Data Curation, Multimodal Reasoning, Cross-Modal Representation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to address the performance degradation in vision-language models caused by modality sensitivity due to training data bias.
🛠️ Research Methods:
– The introduction of Local Modality Substitution (LoMo), a novel data curation approach, which reformulates prompts into interleaved multimodal sequences to ensure cross-modal representational invariance.
💬 Research Conclusions:
– LoMo significantly improves multimodal reasoning and cross-modal fusion, delivering consistent performance gains across various foundational models and benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.30265

34. UniSteer: Text-Guided Flow Matching in Activation Space for Versatile LLM Steering
🔑 Keywords: Activation-based control, Large Language Models, Text-guided activation flow matching, Conditional distribution, Universal conditional velocity field
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce UniSteer to control LLM behaviors and classification tasks through text-guided activation flow matching and universal conditional velocity field.
🛠️ Research Methods:
– Develop a model that learns a conditional distribution over residual-stream activations, performs flow inversion, and supports activation-space classification.
💬 Research Conclusions:
– UniSteer offers a unified interface for behavioral control in LLMs, achieving effectiveness in truthfulness steering, fine-grained concept steering, and multi-constraint instruction following.
👉 Paper link: https://huggingface.co/papers/2605.30076

35. EarlyTom: Early Token Compression Completes Fast Video Understanding
🔑 Keywords: EarlyTom, Visual Tokens, Vision Encoder, Time-to-First-Token, Token Compression
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to develop EarlyTom, a training-free framework to enhance the efficiency of vision encoders by compressing visual tokens early, reducing computational costs and maintaining model accuracy.
🛠️ Research Methods:
– Introduced a strategy for early-stage visual token compression within the vision encoder, utilizing a decoupled spatial token selection to improve compression effectiveness.
💬 Research Conclusions:
– EarlyTom reduces time-to-first-token (TTFT) by up to 2.65x and decreases FLOPs by up to 61%, while maintaining accuracy on par with full-token baselines, thus improving the practicality of deploying Video-LLMs in production environments.
👉 Paper link: https://huggingface.co/papers/2605.30010

36. YoCausal: How Far is Video Generation from World Model? A Causality Perspective
🔑 Keywords: Video diffusion models, Causality, Reverse Surprise Index, Causality Cognition Index, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– Investigate whether video diffusion models truly understand causality or just fit temporal patterns.
🛠️ Research Methods:
– Introduce YoCausal, a benchmark inspired by the Violation of Expectation paradigm, using real-world video reversal to measure causal cognition.
💬 Research Conclusions:
– Current video diffusion models may perceive the arrow of time but lack true causal understanding, highlighting a discrepancy with human-level cognition.
👉 Paper link: https://huggingface.co/papers/2605.30346

37. CollectionLoRA: Collecting 50 Effects in 1 LoRA via Multi-Teacher On-Policy Distillation
🔑 Keywords: CollectionLoRA, Low-Rank Adaptation, multi-teacher distillation, concept isolation, deployment overhead
💡 Category: Generative Models
🌟 Research Objective:
– Introduce CollectionLoRA to effectively distill multiple image editing effects into a single model, reducing deployment overhead and resolving feature interference issues.
🛠️ Research Methods:
– Utilized a multi-teacher on-policy distillation framework.
– Introduced Probabilistic Dual-Stream Routing for improved generalization.
– Employed Asymmetric Orthogonal Prompting for concept isolation.
– Developed a Coarse-to-Fine Distillation Objective to bridge the distribution gap between the teacher and student models.
💬 Research Conclusions:
– CollectionLoRA successfully integrates numerous effects into one model, cutting deployment costs and maintaining or exceeding concept fidelity compared to independently trained models.
👉 Paper link: https://huggingface.co/papers/2605.25378

38. Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
🔑 Keywords: Vision-Language-Action Model, Robotics, Generalization, Embodiment-Aware Prompt Conditioning, Multi-Task Performance
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study investigates whether diverse embodied decision-making tasks can be unified within a single Vision-Language-Action Model, named Qwen-VLA, for tasks like manipulation, navigation, and trajectory prediction.
🛠️ Research Methods:
– Qwen-VLA, a unified embodied foundation model, is trained using a large-scale joint pretraining approach over a variety of data sources, integrating vision, language, and continuous action generation through a DiT-based action decoder. The model also employs embodiment-aware prompt conditioning to cater to different robot platforms.
💬 Research Conclusions:
– Qwen-VLA demonstrates robust multi-task performance and generalization across different tasks and environments, achieving high success rates in benchmarks such as LIBERO, Simpler-WidowX, RoboTwin, and real-world ALOHA experiments.
👉 Paper link: https://huggingface.co/papers/2605.30280
