AI Native Daily Paper Digest – 20260602

1. Crafter: A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs
🔑 Keywords: multi-agent framework, scientific figures, editable SVGs, CraftBench, AI Systems and Tools
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a multi-agent framework that generalizes figure generation across different types and input conditions, producing editable output formats.
🛠️ Research Methods:
– Implemented Crafter, a multi-agent harness, and CraftEditor for converting raster outputs into editable SVGs; introduced CraftBench for benchmarking with human quality annotation.
💬 Research Conclusions:
– Experiments demonstrate Crafter’s superior performance compared to standalone generators, and CraftEditor’s successful conversion into editable SVGs that outperform all baselines.
👉 Paper link: https://huggingface.co/papers/2605.30611

2. A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
🔑 Keywords: Automated benchmark generation, Adaptive Contrastive n-gram model, Tool Sequence Evolution, Task Synthesis, τ^c-Bench
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to address the limitations of existing benchmarks by proposing TASTE, an automated method for generating challenging tasks with broader tool-use coverage.
🛠️ Research Methods:
– TASTE employs an Adaptive Contrastive n-gram model to generate valid tool sequences and uses clustering to select representative sequences. It then refines these sequences through iterative difficulty evolution.
💬 Research Conclusions:
– The study concludes that existing high scores on benchmarks like τ^2-Bench may reflect saturation. TASTE-generated tasks increase difficulty and expand the tool combinations, enabling more robust evaluation of agent capabilities.
👉 Paper link: https://huggingface.co/papers/2605.28556

3. Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
🔑 Keywords: Reinforcement Learning, Search Agents, Harness-1, Stateful Search, Curated Recall
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance retrieval performance of a 20B search agent by separating semantic decision-making from environmental bookkeeping within a stateful search framework.
🛠️ Research Methods:
– A 20B search agent, known as Harness-1, is trained using reinforcement learning. The agent operates within a stateful search harness that handles environmental bookkeeping such as working memory, candidate selection, evidence curation, and verification.
💬 Research Conclusions:
– Harness-1 demonstrates superior performance across eight retrieval benchmarks, achieving a 0.730 average curated recall. The approach outperforms smaller search agents and competes with larger models, showing strong results in transfer benchmarks which suggest generalizability beyond training domains.
👉 Paper link: https://huggingface.co/papers/2606.02373

4. Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
🔑 Keywords: Domino, Speculative Decoding, Parallel Backbone, Causal Dependency
💡 Category: Natural Language Processing
🌟 Research Objective:
– This paper introduces Domino, a speculative decoding framework aimed at enhancing LLM inference speed by decoupling causal dependency modeling from costly autoregressive drafting methods.
🛠️ Research Methods:
– The method involves using a parallel draft backbone to generate initial distributions, followed by a lightweight causal refinement step, supported by a base-anchored training curriculum to stabilize encoding and optimize distribution.
💬 Research Conclusions:
– Experiments demonstrate that Domino achieves significant speedups in both end-to-end execution and throughput, with improvements of up to \(5.49\times\) and \(5.8\times\) respectively, when applied to different backend systems.
👉 Paper link: https://huggingface.co/papers/2605.29707
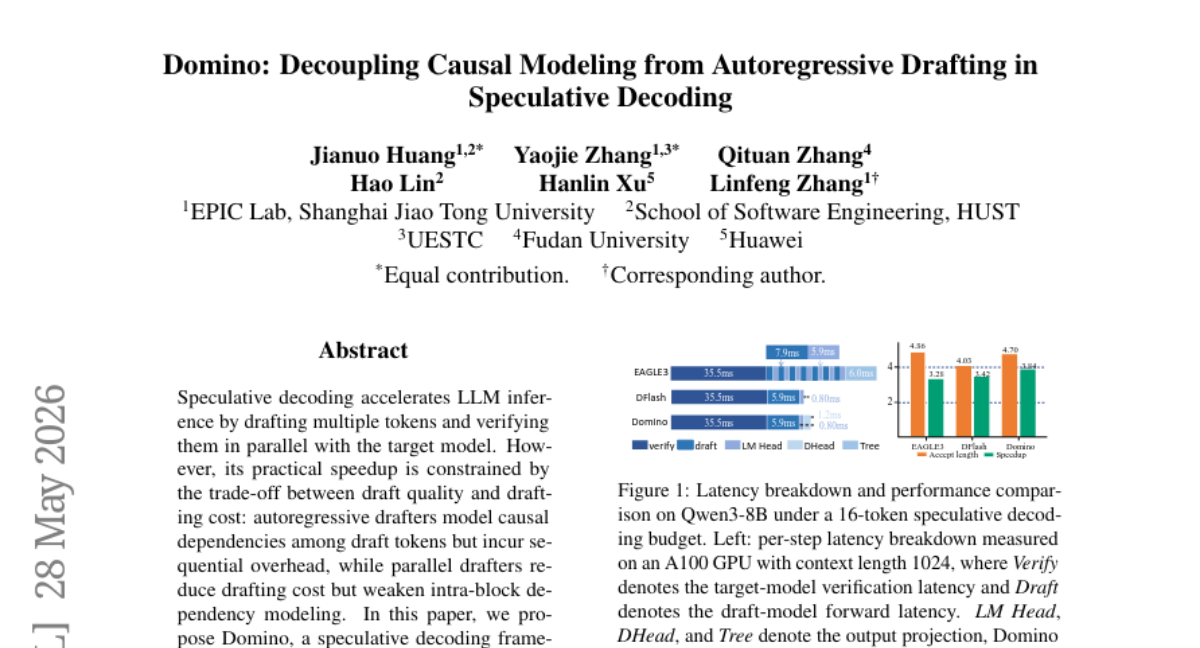
5. NITP: Next Implicit Token Prediction for LLM Pre-training
🔑 Keywords: Next Implicit Token Prediction, language model, dense continuous supervision, implicit semantic content, optimization landscape
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces Next Implicit Token Prediction (NITP) to improve language model generalization by incorporating dense continuous supervision directly in the representation space.
🛠️ Research Methods:
– NITP enhances training by predicting the implicit semantic content of the next token using shallow-layer representations from the same model, providing self-supervised targets.
💬 Research Conclusions:
– Empirical results show significant performance improvements across various model sizes with minimal computational overhead, demonstrating notable gains in benchmark tasks like MMLU-Pro, C3, and CommonsenseQA.
👉 Paper link: https://huggingface.co/papers/2605.24956
6. Where to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
🔑 Keywords: Target Viewpoint Reproduction, visual history, post-training framework, Multi-turn GRPO
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to address the challenge of Target Viewpoint Reproduction (TVR), requiring foundation models to actively adjust 3D viewpoints to match target images, thus evaluating and enhancing spatial intelligence capabilities.
🛠️ Research Methods:
– The research introduces a unified TVR post-training framework utilizing expert-trajectory SFT, rationale-supervised CoT-SFT, offline Single-turn GRPO, and on-policy Multi-turn GRPO from live simulator rollouts to improve model performance.
💬 Research Conclusions:
– The study identifies spatial intelligence gaps in foundation models and demonstrates that visual-action SFT significantly boosts success rates, using TVRBench as a benchmark to measure and train models for active perception and action in 3D environments, achieving a performance increase to 50.8% in a 9B open-source model and 51.4% through Multi-turn GRPO.
👉 Paper link: https://huggingface.co/papers/2606.01247

7. X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
🔑 Keywords: X-Stream, multi-stream streaming understanding, MLLMs, multi-modal large language models, concurrent streams
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce X-Stream, the first benchmark for evaluating the understanding of concurrent multi-streams in real-world applications like live sports broadcasting and autonomous driving.
🛠️ Research Methods:
– Utilized a dual-verification pipeline to ensure comprehensive evaluation over 4,220 QA pairs across 932 videos in multi-window, multi-view, and multi-device scenarios; evaluated MLLMs using Signal Multiplexing Theory.
💬 Research Conclusions:
– The study demonstrates that current state-of-the-art MLLMs struggle with concurrent streams, achieving only 50% efficiency, and highlights the limitations of existing multiplexing schemes, offering guidance for future multi-stream systems development.
👉 Paper link: https://huggingface.co/papers/2606.02482

8. Which Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
🔑 Keywords: Vision-Language Models, Video Generation Models, Spatial Intelligence, Semantic Tagging, 3D Geometry Prediction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To systematically compare Vision-Language Models (VLMs) and Video Generation Models (VGMs) for spatial intelligence tasks by evaluating their capabilities in semantic tagging, instance grouping, and 3D geometry prediction.
🛠️ Research Methods:
– Conduct a frozen-feature probing study to analyze the representation strengths of VLMs and VGMs across key spatial intelligence axes.
💬 Research Conclusions:
– Demonstrated complementarity between VLMs and VGMs wherein VLMs excel in semantic tagging and instance grouping, while VGMs perform better in dense geometry and camera motion prediction. Combining the features from both model families showed improvements in both geometry and semantics, indicating a promising direction for enhancing spatial-intelligence models.
👉 Paper link: https://huggingface.co/papers/2605.28132

9. ESPO: Early-Stopping Proximal Policy Optimization
🔑 Keywords: Early-Stopping Proximal Policy Optimization, mathematical reasoning, trajectory failure, reinforcement learning, surrogate regret
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance mathematical reasoning in large language models by implementing a method to detect and terminate failed trajectories early, thereby improving performance and reducing computational waste.
🛠️ Research Methods:
– The research introduces a method called ESPO (Early-Stopping Proximal Policy Optimization), which halts unsuccessful trajectories early, utilizing a surrogate regret computed from logits, and treats truncated trajectories as absorbing failure states with terminal reward.
💬 Research Conclusions:
– ESPO demonstrates superior performance compared to PPO on benchmarks such as AIME, AMC, and MATH-500, while achieving a computational efficiency of over 20% in saving rollout tokens.
👉 Paper link: https://huggingface.co/papers/2605.29860

10. MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
🔑 Keywords: personalized tools, MCP-Persona, agent performance, social media platforms, state-of-the-art agents
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate agent performance on personalized tools interacting with individual accounts and local databases through the MCP-Persona benchmark.
🛠️ Research Methods:
– Implementation of the MCP-Persona benchmark focused on real-world personalized MCP tools across diverse applications, including social media and enterprise collaboration suites.
💬 Research Conclusions:
– Findings reveal significant challenges faced by current state-of-the-art agents in personalized tool use, emphasizing the importance of MCP-Persona in identifying and addressing these limitations.
👉 Paper link: https://huggingface.co/papers/2606.02470

11. Joint Agent Memory and Exploration Learning via Novelty Signals
🔑 Keywords: Joint Agent Memory and Exploration Learning (JAMEL), novelty-driven interaction, autonomous agents, exploration policy, latent memory
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research introduces the Joint Agent Memory and Exploration Learning (JAMEL) framework to enhance exploration capabilities in open-ended environments while reducing computational costs.
🛠️ Research Methods:
– JAMEL trains memory and exploration policies simultaneously using novelty-driven interactions and deterministic novelty signals like code coverage for supervision.
💬 Research Conclusions:
– JAMEL successfully generalizes to new environments, outperforms open-weight baselines in exploration depth, and competes with closed-source models, achieving efficiency in token consumption.
👉 Paper link: https://huggingface.co/papers/2606.01528

12. Speculative Pipeline Decoding: Higher-Accruacy and Zero-Bubble Speculation via Pipeline Parallelism
🔑 Keywords: Speculative Pipeline Decoding, pipeline parallelism, decoding latency, speculative decoding, theoretical speedup
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to introduce a novel framework, Speculative Pipeline Decoding, to accelerate large language model inference by utilizing pipeline parallelism for parallel token processing and reducing decoding latency.
🛠️ Research Methods:
– Partitioning the target large language model (LLM) into multiple pipeline stages allows parallel token processing. A speculation module aggregates intermediate features at various pipeline depths to predict the next token, ensuring bounded difficulty and high acceptance rates while eliminating latency bubbles.
💬 Research Conclusions:
– The Speculative Pipeline Decoding framework demonstrates significantly higher theoretical speedup compared to mainstream baselines, offering a highly scalable solution for LLM decoding acceleration.
👉 Paper link: https://huggingface.co/papers/2605.30852

13. Skill is Not One-Size-Fits-All: Model-Aware Skill Alignment for LLM Agents
🔑 Keywords: MASA, Hierarchical Skill Evolution, Model-Agnostic, Skill Effectiveness, Inference Cost
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To propose MASA (Model-Aware Skill Alignment), a framework for adapting skills to various backbones without altering agent weights to enhance performance in long-horizon interactive tasks.
🛠️ Research Methods:
– Developed a two-stage process involving hierarchical skill evolution and a lightweight model-conditioned skill rewriter for fast adaptation.
– Utilized hill climbing and UCB-driven tree search guided by environment feedback and model capability profiles.
💬 Research Conclusions:
– MASA achieves superior performance across tested environments and backbones, with significant gains over existing models.
– The framework allows the rewriter to generalize to unseen tasks efficiently, outperforming larger models with reduced inference cost.
👉 Paper link: https://huggingface.co/papers/2605.30723

14. Brain-IT-VQA: From Brain Signals to Answers
🔑 Keywords: Brain-IT, VQA, fMRI, NSD-VQA, Transformer
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce the Brain-IT-VQA framework to decode visual content from fMRI signals and improve visual question answering.
🛠️ Research Methods:
– Utilize a transformer-based architecture to decode language tokens from brain activity and integrate them with a language model.
💬 Research Conclusions:
– The Brain-IT-VQA model significantly outperforms previous fMRI-based captioning and VQA approaches. The NSD-VQA dataset provides a new benchmark for reliable and interpretable evaluation, enabling the study of various visual and semantic information decodable from fMRI responses.
👉 Paper link: https://huggingface.co/papers/2605.29588

15. AFUN: Towards an Affordance Foundation Model for Functionality Understanding
🔑 Keywords: Affordance understanding, RGB-D observation, AI Native
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop an affordance understanding model that predicts functional masks and 3D motion curves from RGB-D observations and language descriptions, enabling generalizable robot manipulation across diverse environments.
🛠️ Research Methods:
– Utilization of a large-scale standardized data pipeline that converts heterogeneous robot, human, simulation, and real-world scan data into a unified affordance schema with language, masks, and object-centric 3D motion labels.
💬 Research Conclusions:
– The model outperforms baseline methods in affordance segmentation, contact-point prediction, and 3D motion testing, demonstrating adaptability to real-world affordance tasks without the need for finetuning.
👉 Paper link: https://huggingface.co/papers/2606.02551

16. PARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
🔑 Keywords: Vision-Language Model, Feature Extraction, Visual-Token Budgets, Elastic Queries, Spatial Grounding
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce PARCEL, a vision-language model architecture that dynamically partitions feature extraction to enhance efficiency and performance across various visual-token budgets.
🛠️ Research Methods:
– Implementation of a visual tokenization architecture, using Pool-Anchored Resampling with Conditioned Elastic Queries, to address the computational challenges faced by Large Vision-Language Models (LVLMs).
💬 Research Conclusions:
– PARCEL consistently outperforms existing baselines across 27 benchmarks, improving the performance-efficiency Pareto frontier and maintaining the “train once, deploy anywhere” paradigm.
👉 Paper link: https://huggingface.co/papers/2605.30126

17. RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
🔑 Keywords: RoboStressBench, Vision-Language Models, visual stress, embodied AI, visual perception
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to evaluate the robustness of Vision-Language Models (VLMs) to physical visual stress within embodied AI systems by introducing a principled benchmark called RoboStressBench.
🛠️ Research Methods:
– The research decomposes visual stress into four dimensions: Material, Viewpoint, Lighting, and Geometry, inspired by the physical rendering equation. Comprehensive evaluations of state-of-the-art VLMs are conducted to identify stress-specific failure modes.
💬 Research Conclusions:
– The study finds that different physical factors degrade different embodied capabilities. The introduced RoboStressBench provides a robust evaluation framework for diagnosing and improving VLM perception under real-world physical stress, enhancing the reliability of embodied AI systems.
👉 Paper link: https://huggingface.co/papers/2606.00828
18. Multi-Agent Computer Use
🔑 Keywords: Multi-agent computer use, Task decomposition, Parallel execution, Directed acyclic graph, Agent coordination
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate and build multi-agent computer use (MACU) systems that improve upon single-agent approaches in handling complex, long-horizon tasks.
🛠️ Research Methods:
– Proposing a general multi-agent setup where a manager model decomposes tasks into a directed acyclic graph (DAG) for parallel subagent execution, allowing dynamic task decomposition and consistent re-planning.
💬 Research Conclusions:
– The MACU system outperforms single-agent baselines by 3.4-25.5% across different benchmarks, demonstrating enhanced test-time scaling and efficiency in complex long-horizon tasks. These improvements highlight multi-agent coordination as a promising approach for scaling computer use agents.
👉 Paper link: https://huggingface.co/papers/2606.01533

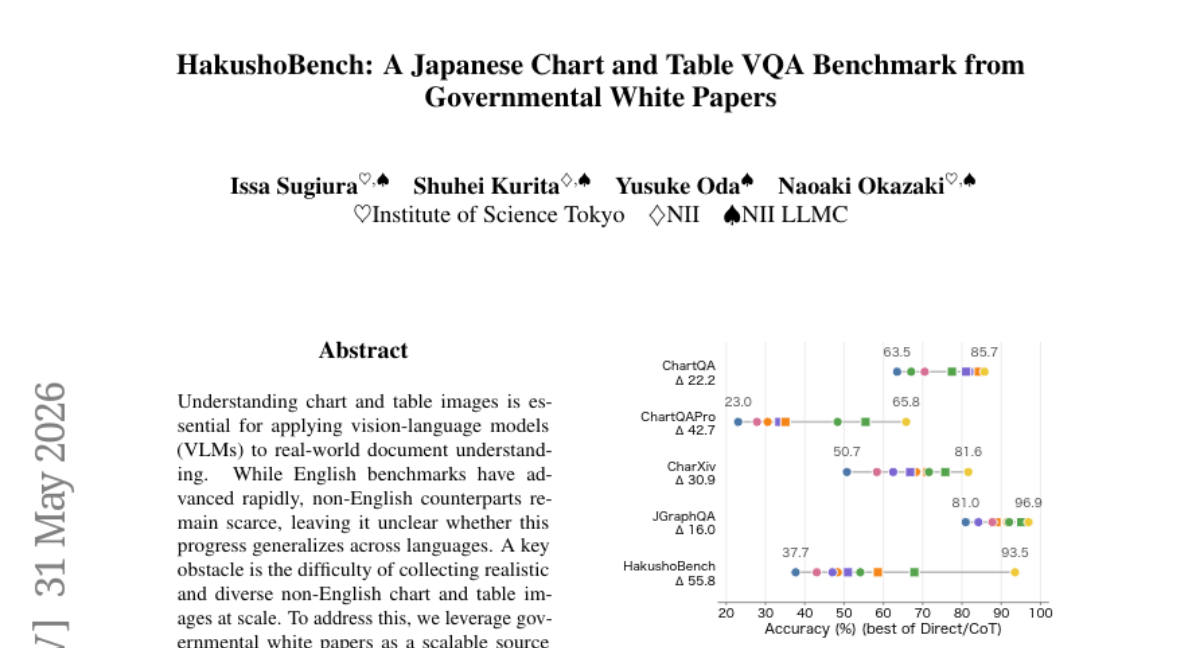
19. HakushoBench: A Japanese Chart and Table VQA Benchmark from Governmental White Papers
🔑 Keywords: HakushoBench, Vision-Language Models, Japanese, Benchmark, Complex Visual Data
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective is to evaluate vision-language models’ ability to understand complex Japanese chart and table visual data derived from governmental documents, filling the gap in non-English datasets.
🛠️ Research Methods:
– Researchers utilized governmental white papers as a scalable source to create a new benchmark, HakushoBench, incorporating 2,053 images with annotated QA pairs to test deep and holistic understanding of visual data.
💬 Research Conclusions:
– Experiments revealed that current open-weight models struggle with the HakushoBench, achieving a maximum accuracy of 58.6%, indicating significant room for improvement in understanding complex chart and table data.
👉 Paper link: https://huggingface.co/papers/2606.01132
20. SOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
🔑 Keywords: Semantic Object Correspondence, Vision Foundation Models, Keypoint Annotations, Vision-Language Models, Downstream Tasks
💡 Category: Computer Vision
🌟 Research Objective:
– To evaluate structured object understanding in vision models by using the Semantic Object Correspondence (SOCO) benchmark.
🛠️ Research Methods:
– Introducing the SOCO benchmark with taxonomy and consistent keypoint annotations across 100 categories to assess semantic correspondence.
💬 Research Conclusions:
– Vision foundation models encode strong semantic structures but have limitations in correspondence transfer and object-part capturing.
– Vision-language models excel in text-prompted part localization but struggle with cross-image visual matching.
– Correspondence performance correlates more strongly with dense downstream tasks than with ImageNet classification.
👉 Paper link: https://huggingface.co/papers/2605.31597

21. ACL-Verbatim: hallucination-free question answering for research
🔑 Keywords: VerbatimRAG, ModernBERT, extractive question answering, large language models, hallucinations
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a VerbatimRAG-based extractive question answering system that improves accurate information retrieval from research papers using a novel ground truth dataset and the ModernBERT model.
🛠️ Research Methods:
– Application of the extractive question answering system to ACL Anthology research papers.
– Creation of a novel ground truth dataset for mapping user queries to relevant text spans in research papers and training extractive models using human-annotated synthetic queries.
💬 Research Conclusions:
– The ModernBERT token classifier, with 150M parameters and trained with silver supervision from synthesized queries, achieves superior word-level F1 scores (53.6) compared to the leading evaluated LLM extractor (48.7).
👉 Paper link: https://huggingface.co/papers/2605.21102

22. LongAttnComp: Cross-Family Context Compression for Long-Context Reasoning
🔑 Keywords: LongAttnComp, context compression, token-level chunking, positional reordering, two-stage fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Adapt LongAttnComp for long-context processing to enhance context length and inference efficiency, addressing the bottleneck in real-world applications requiring 100k+ tokens.
🛠️ Research Methods:
– Implement lightweight cross-attention scoring layer fine-tuning, token-level chunking, token-budget top-p algorithm, positional reordering, and format-agnostic query parser.
– Deploy a two-stage fine-tuning recipe using NIAH-style data and extending with multi-hop and reasoning data.
💬 Research Conclusions:
– LongAttnComp matches or exceeds full-context accuracy on InfiniteBench Code-Debug, surpasses training-free baselines, and successfully transfers across various models.
– The two-stage recipe effectively closes the Stage 1 gap in multi-document reasoning while maintaining Code-Debug performance.
👉 Paper link: https://huggingface.co/papers/2606.01336

23. Silent Failures in Physical AI: A Literature Review of Runtime Action Authorization for Autonomous Systems
🔑 Keywords: Physical AI systems, Runtime Assurance, Safety Mechanisms, Black-box Models, Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To address the safety challenges in Physical AI systems, focusing on the development of comprehensive runtime guardrail mechanisms to ensure safe operations amidst black-box models.
🛠️ Research Methods:
– The study involves a synthesis of various streams like embodied foundation models, world models, and robotics simulation to formulate a bounded problem space for runtime authorization and safety verification.
💬 Research Conclusions:
– The analysis reveals a significant gap in existing models’ ability to provide complete runtime safety assurance, proposing a taxonomy of runtime guardrail functions and evaluation requirements for Physical AI assurance mechanisms.
👉 Paper link: https://huggingface.co/papers/2606.00090

24. Adapting Multilingual Embedding Models to Turkish via Cross-Lingual Tokenizer Surgery and Offline Distillation
🔑 Keywords: Turkish-focused sentence embedding, L2-normalized vectors, transformer backbone, embedding distillation, cosine similarity objective
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop a Turkish-focused sentence embedding model called embeddingmagibu-200m with higher performance and reduced computational costs compared to larger models.
🛠️ Research Methods:
– Implement a three-stage adaptation pipeline: (1) Create a Turkish-optimized multilingual tokenizer with a pruned vocabulary, (2) Clone a teacher embedding model maintaining the transformer backbone, and (3) Conduct offline embedding distillation from precomputed vectors using a cosine similarity objective.
💬 Research Conclusions:
– The student model, with approximately 200M parameters, exhibits superior performance, with Pearson/Spearman correlations surpassing the teacher model, and achieves a competitive mean score on TR-MTEB tasks while utilizing 33% fewer parameters.
👉 Paper link: https://huggingface.co/papers/2605.29992

25. TVIR: Building Deep Research Agents Towards Text–Visual Interleaved Report Generation
🔑 Keywords: multimodal deep research, TVIR, hierarchical multi-agent framework, Textual Assessment, Visual Assessment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main goal is to evaluate and improve the factual reliability and visual alignment of automated report generation systems through a new multimodal benchmark and agent framework.
🛠️ Research Methods:
– Introduction of TVIR (Text–Visual Interleaved Report Generation), including a benchmark (TVIR-Bench) with 100 expert-curated tasks requiring visual elements and a hierarchical multi-agent framework named TVIR-Agent for effective report generation.
– Implementation of a dual-path evaluation framework combining both Textual Assessment and Visual Assessment.
💬 Research Conclusions:
– TVIR-Agent demonstrates strong overall performance across nine deep research systems, emphasizing the necessity of explicit multimodal design and evaluation in evidence-driven report generation.
👉 Paper link: https://huggingface.co/papers/2606.02320

26. MindZero: Learning Online Mental Reasoning With Zero Annotations
🔑 Keywords: MindZero, self-supervised reinforcement learning, Theory of Mind, mental state hypotheses, multimodal large language models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary aim is to develop MindZero, a self-supervised reinforcement learning framework, enabling multimodal large language models to efficiently perform online mental reasoning without needing explicit mental state annotations.
🛠️ Research Methods:
– The framework trains models to generate mental state hypotheses that maximize the likelihood of observed actions using a planner, thereby internalizing model-based reasoning into fast single-pass inference.
💬 Research Conclusions:
– MindZero significantly enhances multimodal large language models’ Theory of Mind capabilities, outperforming traditional model-based methods in accuracy and efficiency in mental reasoning tasks across gridworld and household domains.
👉 Paper link: https://huggingface.co/papers/2606.00240

27. Compositional Text-to-Image Generation Via Region-aware Bimodal Direct Preference Optimization
🔑 Keywords: BiDPO, text-to-image models, preference-based fine-tuning, compositional fidelity, region-level guidance
💡 Category: Generative Models
🌟 Research Objective:
– To enhance text-to-image models’ capability of generating images from complex compositional prompts through the proposed BiDPO framework.
🛠️ Research Methods:
– Implementing a pipeline to create a large-scale preference dataset called BiComp with strict quality control.
– Extending Diffusion DPO to jointly optimize image and text preferences.
– Employing region-level guidance to focus on relevant compositional regions.
💬 Research Conclusions:
– BiDPO significantly improves compositional fidelity, outperforming previous methods across multiple benchmarks.
– Demonstrates the potential of preference-based fine-tuning as a flexible and scalable approach for complex text-to-image tasks.
👉 Paper link: https://huggingface.co/papers/2605.28615

28. Can Predicted Dynamics Exist in the Physical World?
🔑 Keywords: Physical Admissibility, Prediction-Control Interface, Receiver Operating Characteristic Curve, RMSE, AI Systems
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to establish a prediction-control interface for ensuring physical admissibility in AI systems by filtering out invalid proposals while maintaining high system performance.
🛠️ Research Methods:
– The methodology involves evaluating decoded proposals using kinematic, dynamic, and direct-to-composed horizon conditions before execution to determine physical admissibility.
💬 Research Conclusions:
– The research demonstrates that controlled falsification achieves high AUC values, showcasing the effectiveness of the physical admissibility gate in preventing invalid proposals while preserving significant mean progress.
👉 Paper link: https://huggingface.co/papers/2606.00089

29. AI, Take the Wheel: What Drives Delegation and Trust in Human-Computer Cooperative Question Answering?
🔑 Keywords: Human-AI collaboration, trust, delegation choice, adoption choice, confirmation bias
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To understand when, why, and how humans decide to rely on AI in question-answering tasks.
🛠️ Research Methods:
– Evaluation of 24 human-AI collaborative matches in a question-answering game with 387 delegation and 1440 adoption decisions recorded.
💬 Research Conclusions:
– Human-AI collaboration can yield better performance than either party alone, but suboptimal decisions occur due to under-reliance on correct AI suggestions and over-reliance on misleading AI outputs. Recommendations include utilizing calibrated confidence, evidence-grounded explanations, and mechanisms to refine user trust.
👉 Paper link: https://huggingface.co/papers/2605.28255

30. The Chain Holds, the Answer Folds: Trace-Answer Dissociation in Reasoning Models Under Adversarial Pressure
🔑 Keywords: reasoning models, chain-of-thought, unfaithful capitulation, adversarial conditions, multi-turn dialogue
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to identify and study a new failure mode in reasoning models termed unfaithful capitulation, where correct reasoning chains flip to incorrect answers under adversarial conditions.
🛠️ Research Methods:
– Controlled experiments were conducted across multiple datasets and models using a 2×2 latent-versus-behavioral framework to isolate the failure mode that traditional metrics miss. Data includes three datasets—MT-Consistency, MMLU-Pro, GSM8K.
💬 Research Conclusions:
– Findings show that reasoning models can maintain factual correctness in reasoning chains but still produce incorrect final answers due to adversarial pressures. The identified failure mode is corroborated by independent GPT-4o judging. The effect varies across different models and datasets.
👉 Paper link: https://huggingface.co/papers/2605.29087

31. FreeForm: Reduced-Order Deformable Simulation from Particle-Based Skinning Eigenmodes
🔑 Keywords: Reduced-order simulation, Reproducing Kernel Particle Method, deformable hyperelastic objects, neural fields, AI Native
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to introduce a novel formulation for the mesh-free, reduced-order simulation of deformable hyperelastic objects, overcoming existing challenges with meshes and neural fields.
🛠️ Research Methods:
– Employs the Reproducing Kernel Particle Method (RKPM) to construct reduced-order skinning weights by solving a generalized eigensystem on the elastic energy’s Hessian matrix for faster and more accurate simulations.
💬 Research Conclusions:
– The proposed method achieves a 40x training speedup compared to neural fields and lower simulation error, effectively supporting various geometric representations and robot simulation applications.
👉 Paper link: https://huggingface.co/papers/2605.29318
32. ChartArena: Benchmarking Chart Parsing across Languages, Scenarios, and Formats
🔑 Keywords: Bilingual Benchmark, Chart Parsing, Human-Agent Collaborative Annotation, Canonical Semantic Spaces, Structure-Aware Metrics
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce ChartArena, a comprehensive bilingual benchmark for evaluating chart parsing models across various chart types and visual conditions, enabling fair comparison using a unified evaluation framework.
🛠️ Research Methods:
– ChartArena covers eight chart families and evaluates them in three visual scenarios: digital, printed, and hand-drawn photos.
– Utilizes a human-agent collaborative annotation pipeline with multi-stage human verification to ensure annotation reliability.
– Employs a format-agnostic evaluation protocol mapping heterogeneous outputs into two canonical semantic spaces with structure-aware metrics.
💬 Research Conclusions:
– Proprietary models like Gemini 3.1 Pro currently lead, but open-source systems are rapidly improving.
– Document parsing models perform well on numeric charts but struggle with diagrammatic structures.
– Chart parsers are limited to narrow chart families; radar charts and hand-drawn scenarios remain especially challenging.
– ChartArena reveals capability gaps and provides a unified foundation for future progress.
👉 Paper link: https://huggingface.co/papers/2606.01348

33. Thinking in Blender: Staged Executable Inverse Graphics with Vision-Language Models
🔑 Keywords: Inverse graphics, Pretrained vision-language models, Blender program, Staged reconstruction, Task decomposition
💡 Category: Computer Vision
🌟 Research Objective:
– The study investigates whether pretrained vision-language models can directly perform executable inverse graphics from a single image by reconstructing it into an editable Blender program without relying on other specialized models or techniques.
🛠️ Research Methods:
– Introduction of Staged Executable Inverse Graphics (SEIG), a framework that progressively refines scene factors like geometry, materials, composition, and lighting directly in executable Blender code space.
💬 Research Conclusions:
– Staged reconstruction significantly improves fidelity, emphasizing the importance of task decomposition for enhancing reconstruction fidelity with general-purpose vision-language models.
👉 Paper link: https://huggingface.co/papers/2606.02580

34. τ_0-WM: A Unified Video-Action World Model for Robotic Manipulation
🔑 Keywords: unified video-action world model, robotic manipulation, video prediction, policy learning, action evaluation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to integrate policy learning, video prediction, and action evaluation into a unified framework for improving robotic manipulation tasks.
🛠️ Research Methods:
– Utilizes a shared video diffusion backbone and a model trained on 27,300 hours of diverse interaction data to predict and simulate future actions.
💬 Research Conclusions:
– The τ_0-World Model demonstrates superior performance in challenging long-horizon and fine-grained robotic manipulation tasks compared to existing baselines.
👉 Paper link: https://huggingface.co/papers/2606.01027

35. Semantic Motion Anchors: Bridging Motion and Meaning in Co-Speech Gestures
🔑 Keywords: Semantic Motion Anchors, Co-Speech Gesture Retrieval, Communicative Intent, 3D Gestures, Motion Primitives
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to improve the alignment between spoken text and gesture representations, thereby enhancing retrieval accuracy and semantic relevance through the use of Semantic Motion Anchors.
🛠️ Research Methods:
– The method involves discretizing 3D gestures into body-hand motion primitives, verbalizing them into structured descriptions, and grounding them in the transcript to provide auxiliary contrastive supervision, improving text-to-gesture retrieval metrics.
💬 Research Conclusions:
– The proposed approach improves text-to-gesture retrieval R@1 by 8.2% over direct text-motion baselines and is preferred significantly in gesture generation tasks, demonstrating its efficacy in conveying communicative intent more clearly.
👉 Paper link: https://huggingface.co/papers/2605.30608

36. Lost in Translation? Exploring the Shift in Grammatical Gender from Latin to Occitan
🔑 Keywords: Deep Learning Framework, Grammatical Gender, Historical Setting, Lexical Features, Contextual Features
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop a deep learning framework to analyze the evolution of the grammatical gender system from Latin to Romance languages.
🛠️ Research Methods:
– Introduce an interpretable deep learning framework to study both lexical and contextual factors.
– Evaluate and improve tokenizer performance in a low-resource historical setting.
– Analyze morphological features and part-of-speech categories for gender prediction.
💬 Research Conclusions:
– Conventional tokenization strategies are insufficient for historical data, while the proposed tokenizer improves performance.
– The study provides insights into the distribution of gender information across lexical and sentential contexts.
– Publicly share code, datasets, and results for further research and validation.
👉 Paper link: https://huggingface.co/papers/2605.09156

37.

38. Who Annotates in NLP? A Large-scale Assessment of Human Annotation Reporting between 2018 and 2025
🔑 Keywords: Human annotation, NLP research, LLM-assisted extraction, annotation validity, annotation reporting
💡 Category: Natural Language Processing
🌟 Research Objective:
– To conduct a large-scale audit of human annotation reporting practices in NLP and assess how well critical annotation details are documented over time.
🛠️ Research Methods:
– An audit of annotation reporting using a unified taxonomy and an LLM-assisted extraction pipeline validated against a human-adjudicated gold standard.
💬 Research Conclusions:
– Despite improvements in annotation reporting over time, gaps still exist in reproducibility and reliability. A scalable framework and minimum reporting recommendations are established to enhance human annotation practices.
👉 Paper link: https://huggingface.co/papers/2606.02255

39. DOT-MoE: Differentiable Optimal Transport for MoEfication
🔑 Keywords: Differentiable Optimal Transport, Mixture of Experts, Large Language Models, Sparse MoE Models, Straight-Through Estimators
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to address the inefficiencies in inference created by the scaling of Large Language Models (LLMs) and to propose DOT-MoE, a framework for efficient training of sparse Mixture of Experts (MoE) models through differentiable optimal transport.
🛠️ Research Methods:
– The paper formulates dense layer decomposition as a Differentiable Optimal Transport (DOT) problem, utilizing balanced transport via Sinkhorn-Knopp iterations and Straight-Through Estimators (STE).
💬 Research Conclusions:
– DOT-MoE significantly outperforms baseline methods such as structured pruning and heuristic clustering, retaining 90% performance of the dense model while reducing active parameters by 50%.
👉 Paper link: https://huggingface.co/papers/2606.01666

40. The Hamilton-Jacobi Theory of Deep Learning
🔑 Keywords: Neural Networks, Hamilton–Jacobi, Residual Networks, Transformers, Viscous PDE
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to formulate neural network training as a Hamilton–Jacobi initial-value problem, establishing exact connections to various neural network architectures.
🛠️ Research Methods:
– It employs an analytical framework where gradient steps align with solving viscous Hamilton–Jacobi equations, creating links with residual networks, transformers, and recurrent networks.
💬 Research Conclusions:
– The study reveals significant quantitative outcomes such as minimax optimal generalization rates, adversarial robustness, and interpretable scaling exponents, underlining the unifying role of a deformation parameter that harmonizes multiple theoretical perspectives.
👉 Paper link: https://huggingface.co/papers/2605.28983

41. Review Arcade: On the Human Alignment and Gameability of LLM Reviews
🔑 Keywords: LLM-generated reviews, human reviews, ACL Rolling Review, paper scores, iterative revision
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to evaluate large language model (LLM)-generated reviews from both the author and reviewer perspectives, focusing on their alignment with human reviews and the effectiveness of authors using LLMs to revise paper drafts iteratively.
🛠️ Research Methods:
– Empirical experiments were conducted on papers from the 2025 ACL Rolling Review (ARR) to assess the alignment between LLM and human reviews and the impact of iterative draft-revision workflows.
💬 Research Conclusions:
– Limited alignment was found between LLM and human reviews, with performance varying by prompts and models.
– Authors can use LLM feedback effectively to “game” the review process, potentially increasing paper scores by up to 35% in certain scenarios.
👉 Paper link: https://huggingface.co/papers/2605.28897

42. Same Question, Different Source, Different Answer: Auditing Source-Dependence in Medical Multi-Source RAG
🔑 Keywords: Retrieval-Augmented Generation, Source-dependence, NLP Evaluation, Multi-source NLP
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to highlight the significance of analyzing inter-source relationships in multi-source NLP systems rather than focusing solely on answer correctness.
🛠️ Research Methods:
– Deployment of a Retrieval-Augmented Generation system over an institutional corpus to evaluate the role of source-dependence in response generation.
– Creation of benchmarks such as TransplantQA and HERO-QA to assess system performance across different institutional sources.
– Utilization of a structured-output judge to score inter-source relationships using a validated taxonomy.
💬 Research Conclusions:
– The research reveals that better retrieval techniques can uncover more significant disagreements between sources than previously recognized, implying that understanding source-dependence is crucial for deployed multi-source NLP systems.
– The proposed framework is domain-agnostic and applicable to other fields such as legal and educational applications of retrieval-augmented generation systems.
👉 Paper link: https://huggingface.co/papers/2605.29084

43. Model-Based Quality Assessment for Massively Multilingual Parallel Data
🔑 Keywords: Multilingual Parallel-Data, Parallelism Assessment, Quality Estimation, Language Pairs, Embedding Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– To assess multilingual parallel-data using direction-specific approaches instead of universal metrics due to variability across language pairs.
🛠️ Research Methods:
– Decomposing model-based assessment into parallelism assessment with multilingual embeddings and reference-free quality estimation (QE).
– Benchmarking embedding models on FLORES-200 and BOUQuET retrieval tasks covering 6,654 source-target directions.
– Evaluating nine reference-free evaluators on professional translations across 41,412 ordered source-target directions.
💬 Research Conclusions:
– No model is universally reliable across translation directions.
– Naive QE ensembles tend to dilute strong model signals.
– Documented target-language coverage correlates with higher QE scores, indicating the need for direction-aware routing and calibration in multilingual parallel-data assessment.
👉 Paper link: https://huggingface.co/papers/2606.00285

44. A Formally Verified Library of Mathematical Finance in Lean 4
🔑 Keywords: Lean 4 proof assistant, mathematical finance, machine-checked, risk-neutral pricing measure
💡 Category: AI in Finance
🌟 Research Objective:
– Develop a broad library of mathematical finance within the Lean 4 proof assistant, incorporating over two hundred theorems without omissions.
🛠️ Research Methods:
– Construct the L2 Itô integral as a bounded linear isometry; derive, rather than assume, the risk-neutral pricing measure.
– Classify and audit the faithfulness of results, ensuring transparency and accuracy in the relation of Lean statements to mathematical claims.
💬 Research Conclusions:
– The project provides certified unification of known financial results instead of introducing new theory, contributing reusable verified foundations for mathematical finance.
👉 Paper link: https://huggingface.co/papers/2606.01356

45. Geometric Latent Reasoning Induces Shorter Generations in LLMs
🔑 Keywords: Geometric Latent Reasoning, latent reasoning, geometric path-approximation, pretrained token-embedding space, Qwen3 models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to explore latent reasoning within a geometric path-approximation framework in pretrained token-embedding space to reduce generation length while maintaining accuracy.
🛠️ Research Methods:
– Introduced Geometric Latent Reasoning (GLR) using a lightweight transition head to predict iterative direction updates in embedding space, utilizing textual chain-of-thought traces as anchors.
💬 Research Conclusions:
– Evaluations demonstrate that geometric latent reasoning results in substantially shorter generations without explicit length objectives, suggesting a new tradeoff between latent computation budget, output length, and accuracy.
👉 Paper link: https://huggingface.co/papers/2606.02248

46. Unified Neural Scaling Laws
🔑 Keywords: Unified Neural Scaling Law, deep neural networks, scaling behaviors, architectures, reinforcement learning
💡 Category: Machine Learning
🌟 Research Objective:
– The research aims to introduce a Unified Neural Scaling Law that models and extrapolates deep neural network scaling behaviors across multiple simultaneous dimensions, including parameters, dataset size, training steps, and compute.
🛠️ Research Methods:
– The study presents a functional form that captures how the evaluation metric varies with changes in several factors such as model parameters, dataset size, training steps, and hyperparameters for a range of architectures and tasks.
💬 Research Conclusions:
– Compared to other functional forms, the introduced law provides considerably more accurate extrapolations of scaling behavior in diverse tasks including vision, language, math, and reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2605.26248
47. StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
🔑 Keywords: Video world models, policy evaluation, Vision-Language Model, diffusion-based, autonomous driving
💡 Category: Generative Models
🌟 Research Objective:
– To enhance video world models by steering diffusion-based imaginations toward high-impact yet plausible outcomes for improved policy evaluation and improvement.
🛠️ Research Methods:
– Utilization of optimized noise initialization with semantic and plausibility objectives to guide video imaginations.
– Implementation of a semantic objective via a Vision-Language Model to provide informative gradients about the generated video.
– Introduction of a plausibility objective to prevent out-of-distribution noise from resulting in implausible imaginations.
💬 Research Conclusions:
– StressDream successfully directs video world model imaginations towards outcomes that are both high-impact and plausible, aiding in robust policy evaluation, particularly in scenarios like autonomous driving and robotic manipulation.
👉 Paper link: https://huggingface.co/papers/2606.00267
48. Confidence-Adaptive SwiGLU for Mixture-of-Experts
🔑 Keywords: SwiGLU, Mixture-of-Experts, token-level routing confidence, Transformer MLPs, Confidence-Aware
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to enhance Mixture-of-Experts models by developing Confidence-Aware SwiGLU, which dynamically adjusts expert gate sharpness based on token-level routing confidence.
🛠️ Research Methods:
– The authors propose κ-SwiGLU, a variant of SwiGLU, which parameterizes gate sharpness as a learnable function dependent on router logit values, tested across MoE Transformer models with varying layers.
💬 Research Conclusions:
– κ-SwiGLU shows improved mean CORE performance with minimal computational cost, suggesting that confidence-aware gate sharpness offers a promising improvement for MoE MLPs.
👉 Paper link: https://huggingface.co/papers/2606.00761

49. EVA01: Unified Native 3D Understanding and Generation via Mixture-of-Transformers
🔑 Keywords: EVA01, 3D mesh integration, Multimodal Large Language Models, Mixture-of-Transformers, text-to-3D generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces EVA01, which enables native integration of 3D meshes into Multimodal Large Language Models (MLLMs) to enhance generation and editing capabilities.
🛠️ Research Methods:
– EVA01 is constructed using a Mixture-of-Transformers architecture, separating the model into an Understanding Expert and a Generation Expert interconnected by shared global self-attention with hard modality routing.
💬 Research Conclusions:
– EVA01 exhibits state-of-the-art performance in native text-to-3D generation fidelity and supports robust long-context, multi-turn geometric editing with identity preservation, offering significant advancements over traditional stateless reconstruction pipelines.
👉 Paper link: https://huggingface.co/papers/2605.16745

50. SVI-Bench: A Dynamic Microworld for Strategic Video Intelligence
🔑 Keywords: Strategic Video Intelligence, Causal Reasoning, Strategic Planning, Multi-Agent Systems, Agentic Baselines
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address gaps in evaluating Strategic Video Intelligence by introducing a comprehensive benchmark named SVI-Bench, aimed at understanding complex cognitive tasks.
🛠️ Research Methods:
– Developing a large-scale benchmark using team sports as dynamic microworlds, which includes 35K hours of video, 15M annotated actions, and other structured data, organized into a four-pillar task hierarchy.
💬 Research Conclusions:
– Current models perform well in perceptual tasks but struggle significantly with higher cognitive levels, with agentic tasks being the most challenging, achieving just 5% accuracy in some cases.
👉 Paper link: https://huggingface.co/papers/2605.31529

51. 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
🔑 Keywords: Vision-language models, Procedural 3D modeling, 3DCodeBench, Test-time scaling
💡 Category: Generative Models
🌟 Research Objective:
– To evaluate vision-language models (VLMs) for their capacity to translate text and images into executable 3D code, using the 3DCodeBench benchmark.
🛠️ Research Methods:
– Introduced 3DCodeBench to evaluate 12 VLMs on procedural 3D modeling tasks.
– Developed 3DCodeArena platform for human preference-based ranking of generated 3D outputs.
💬 Research Conclusions:
– Major challenges identified include API mismatches and issues with disconnected 3D components.
– Highlighted the importance of high-quality procedural coding data and a robust execution environment for effective procedural 3D modeling.
👉 Paper link: https://huggingface.co/papers/2606.01057

52. Not only where, But when: Temporal Scheduling for RLVR
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Temporal Scheduling, Policy Optimization, Credit Allocation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to enhance policy evolution and learning stability in reinforcement learning by integrating temporal scheduling with credit allocation criteria focused on verifiable rewards.
🛠️ Research Methods:
– The study utilizes a novel approach of scheduling the credit allocation criteria temporally, prioritizing targeted tokens and gradually shifting towards general optimization to improve reinforcement learning dynamics.
💬 Research Conclusions:
– Temporal scheduling leads to more stable and efficient learning dynamics, presenting a promising optimization dimension that better accommodates heterogeneous policy behaviors while improving policy evolution, as demonstrated through experiments on mathematical and general reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.25381

53. FineVerify: Scaling Test-Time Compute with Fine-Grained Self-Verification for Agentic Search
🔑 Keywords: Fine-grained self-verification, Agentic search, Language model agents, Checkable sub-questions
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective of FineVerify is to improve accuracy in agentic search through decomposed sub-question checking and trajectory selection.
🛠️ Research Methods:
– FineVerify integrates a fine-grained self-verification framework that decomposes each question into checkable sub-questions, verifies sampled candidates against each sub-question, and selects the candidate with the highest aggregated score.
💬 Research Conclusions:
– FineVerify outperforms standard scaling baselines across four agentic search benchmarks and two models, considerably improving accuracy points.
– It not only enhances model accuracy but also provides interpretable verification traces for auditing errors in agentic search systems.
👉 Paper link: https://huggingface.co/papers/2606.00660

54. Measuring the Depth of LLM Unlearning via Activation Patching
🔑 Keywords: Unlearning Depth Score, Large Language Model, AI Safety, Privacy Protection, Causal Approach
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Unlearning Depth Score (UDS) to evaluate how thoroughly knowledge has been erased from large language models, addressing limitations of previous methods that overlook hidden knowledge in internal representations.
🛠️ Research Methods:
– Utilizes activation patching to identify and measure erasure of target knowledge in model layers, assessing the unlearning on a 0-1 scale across different models and methods.
💬 Research Conclusions:
– UDS demonstrated the highest faithfulness and robustness among 20 metrics, establishing itself as a reliable metric for unlearning evaluation, with guidelines provided for integration into benchmarking frameworks.
👉 Paper link: https://huggingface.co/papers/2605.24614

55. RoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
🔑 Keywords: RoboSemanticBench, Vision-Language-Action models, action prediction, semantic grounding, robot fine-tuning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study introduces RoboSemanticBench to diagnose semantic grounding in action prediction, examining if vision-language-action models can semantically understand complex instructions to manipulate correct physical targets.
🛠️ Research Methods:
– An embodied benchmark where a robot receives questions, observes candidate answer blocks, and must grasp the block corresponding to the correct answer to evaluate semantic understanding in robots.
💬 Research Conclusions:
– There exists a gap between robots’ semantic competence and their action prediction, as VLA models often select the correct block at near-random rates despite successful object grasping.
👉 Paper link: https://huggingface.co/papers/2606.02277

56. Off-the-Shelf LLMs as Process Scorers: Training-Free Alternative to PRMs for Mathematical Reasoning
🔑 Keywords: Chunk-Level Guided Generation, large language model, process scorer, PRM guided search, majority voting
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a new method, Chunk-Level Guided Generation, that improves reasoning accuracy in small model generation by using a large language model as a process scorer to select candidate chunks.
🛠️ Research Methods:
– Utilizes a large off-the-shelf language model to score fixed-length candidate chunks without text generation, applying two selection rules: Likelihood-Guided Selection and Contrastive-Guided Selection.
💬 Research Conclusions:
– Chunk-Level Guided Generation outperforms traditional methods like majority voting and is competitive with PRM guided search in several benchmarks, achieving higher accuracy in tasks like MATH and Minerva Math and producing shorter reasoning traces.
👉 Paper link: https://huggingface.co/papers/2606.01682

57. MineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft
🔑 Keywords: Multimodal large language models, open-world exploration, Minecraft, multi-agent synthesis, task graphs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate the open-world exploration capabilities of multimodal large language models (MLLMs) using the developed MineExplorer benchmark within the context of Minecraft.
🛠️ Research Methods:
– MineExplorer employs a multi-agent synthesis workflow that constructs task graphs, sandbox scenes, and milestone evaluators to design reliable instances for performance evaluation.
💬 Research Conclusions:
– Human evaluation indicated that the multi-agent synthesis approach yields more reliable instances compared to single-agent baselines.
– MLLMs demonstrate strong performance in single-hop tasks, but their ability degrades in multi-hop tasks requiring coordination over longer trajectories.
– Larger models or enhanced thinking modes don’t always result in better performance, uncovering challenges in open-world exploration.
👉 Paper link: https://huggingface.co/papers/2605.30931

58. Agent Skills Should Go Beyond Text: The Case for Visual Skills
🔑 Keywords: Multimodal skills, Visual-centric tasks, Reusable skills, Visual support, Spatial correspondence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to address the limitations of text-only skill-learning methods for visual-centric tasks by proposing a multimodal skill paradigm that integrates textual logic with visual support.
🛠️ Research Methods:
– The paper introduces a system named SYSTEM, which automatically converts agent experience into reusable multimodal skills by preserving textual reasoning, spatial references, visual boundaries, and interaction patterns.
💬 Research Conclusions:
– Experiments demonstrate that visual skills outperform text-only skills in tasks requiring spatial correspondence, visual evidence, and state-aware interaction. This supports the argument that agent skills should evolve beyond text to become multimodal for future agent development.
👉 Paper link: https://huggingface.co/papers/2606.01414

59. Policy and World Modeling Co-Training for Language Agents
🔑 Keywords: PaW, Policy learning, World modeling, Reinforcement learning (RL), Language agent training
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance language agent training by integrating policy learning and world modeling using on-policy RL rollouts without additional computational overhead.
🛠️ Research Methods:
– Introduced a co-training framework called PaW that integrates auxiliary world modeling supervision with policy learning during RL.
– Utilized action-entropy-based WM data selection, noise-tolerant WM loss, and reward-adaptive loss balancing to ensure informative and stable WM supervision.
💬 Research Conclusions:
– Experiments demonstrate that the PaW framework provides consistent improvements over existing strong RL baselines across various models and RL algorithms, highlighting that standard RL rollouts can effectively function as a source of world modeling supervision for training language agents.
👉 Paper link: https://huggingface.co/papers/2606.02388

60. OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
🔑 Keywords: OpenWebRL, visual web agents, online reinforcement learning, multi-turn RL, open-source
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Develop an open framework named OpenWebRL for training visual web agents using online reinforcement learning on real websites.
🛠️ Research Methods:
– Utilize a comprehensive training pipeline including scalable live-browser infrastructure, supervised initialization, multimodal context management, trajectory-level success judging, and multi-turn policy optimization.
💬 Research Conclusions:
– OpenWebRL-4B, utilizing minimal supervised initialization, achieves competitive success rates on challenging benchmarks, offering a new state-of-the-art for open-source visual web agents while remaining competitive with proprietary systems.
👉 Paper link: https://huggingface.co/papers/2606.02031

61. StreamChar: Long-Horizon Streaming Character Audio-Video Generation with Decoupled Orchestration
🔑 Keywords: StreamChar, LLM-based orchestrator, joint audio-video DiT, two-stage distillation pipeline, audio-visual synchronization
💡 Category: Generative Models
🌟 Research Objective:
– The goal of the research is to enable real-time streaming audio-video generation for character animation, ensuring transcript fidelity, visual identity maintenance, and efficient deployment.
🛠️ Research Methods:
– The methods employed include separating orchestration from denoising using an LLM-based orchestrator and a joint audio-video DiT. A two-stage distillation pipeline is used for efficient deployment, while progress-aware pointers and sink-chunk memory ensure alignment and consistency.
💬 Research Conclusions:
– Results demonstrate that StreamChar achieves real-time operation on a single H100 GPU, balancing transcript fidelity, audio-visual synchronization, and visual quality, with a superior performance in streaming stability compared to recent baselines.
👉 Paper link: https://huggingface.co/papers/2605.25659
62. LongLive-RAG: A General Retrieval-Augmented Framework for Long Video Generation
🔑 Keywords: LongLive-RAG, retrieval-augmented generation, sliding-window attention, error accumulation, temporal coherence
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenges in long-video generation by improving temporal coherence and quality through retrieval-augmented generation, specifically overcoming error accumulation prevalent in sliding-window attention methods.
🛠️ Research Methods:
– The authors introduce LongLive-RAG, a framework that uses autoregressive video generation with a retrieval mechanism to treat previously generated latents as a dynamic, searchable history. This approach includes query embedding for retrieving relevant historical latents, thus allowing the generator to condition on non-local context.
💬 Research Conclusions:
– LongLive-RAG effectively reduces error accumulation and improves the quality of long-video generation across various AR backbones, as demonstrated by its superior performance in VBench-Long rankings. It is noted as the first open-ended AR long video generation method to utilize self-generated latent history for content-addressable retrieval memory.
👉 Paper link: https://huggingface.co/papers/2606.02553

63. LVSA: Training-Free Sparse Attention for Long Video Diffusion
🔑 Keywords: Sparse Attention, Video Diffusion, Structured Window Pattern, FlashInfer Kernel, VQeval
💡 Category: Generative Models
🌟 Research Objective:
– To address computational bottlenecks in long-video diffusion models by introducing a model-agnostic block-sparse attention method that reduces computational costs while maintaining high video quality beyond training horizons.
🛠️ Research Methods:
– Introduced Long Video Sparse Attention (LVSA) that combines structured window patterns with rotating global anchors to prevent fixed-grid bias and reduce compute costs up to 3.33x compared to dense attention.
– Implementation of a FlashInfer kernel and testing LVSA on various NPUs, achieving significant speedups.
💬 Research Conclusions:
– LVSA effectively reduces computing resources while maintaining video generation quality. It also enables generation tasks that are otherwise impossible due to memory limitations. VQeval is introduced to fairly assess quality across different models.
👉 Paper link: https://huggingface.co/papers/2605.31057

64. When Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
🔑 Keywords: Multi-agent, Reinforcement Learning, Shared-Policy, Isolated-Policy, Gradient Dynamics
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study investigates when multi-agent large language model workflows trained with reinforcement learning surpass their base models in accuracy.
🛠️ Research Methods:
– Comparing Shared-Policy training and Isolated-Policy training across different workflows, tasks, and model scales, focusing on gradient dynamics and policy routing.
💬 Research Conclusions:
– Multi-agent reinforcement learning typically offers improved accuracy over base models. However, the effectiveness depends on the interplay between workflow, task type, and model scale. Isolated-Policy training can achieve higher peak accuracy but is prone to terminal degradation, while Shared-Policy training presents different failure patterns tied to gradient dynamics and workflow topology.
👉 Paper link: https://huggingface.co/papers/2605.24202

65. Masking Stale Observations Helps Search Agents — Until It Doesn’t: A Regime Map and Its Mechanism
🔑 Keywords: Observation Masking, Agentic Search, Context Management, Token-for-Turn Trade-Off, Retriever Recall
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To analyze the impact of Observation Masking in improving the accuracy of long-horizon search agents through effective Context Management.
🛠️ Research Methods:
– Conducted a systematic evaluation of various agent backbones (ranging from 4B to 284B parameters) and three retrievers on offline and live-web benchmark tests.
💬 Research Conclusions:
– The effectiveness of Observation Masking follows an asymmetric inverted-U pattern based on retriever capability and model capacity. Masking is beneficial particularly when a strong retriever is coupled with a mid-capacity model, although less effective when the model is overwhelmed or underutilized.
– The study reframes Context Management as a regime-dependent intervention. The researchers have provided a framework and released resources for future research in this area.
👉 Paper link: https://huggingface.co/papers/2606.00408

66. VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
🔑 Keywords: VideoMLA, video diffusion, Multi-Head Latent Attention, low-rank content, throughput
💡 Category: Generative Models
🌟 Research Objective:
– To reduce memory usage in video diffusion models while maintaining quality and improving throughput, using a novel attention mechanism named VideoMLA.
🛠️ Research Methods:
– Implemented VideoMLA with shared low-rank content and decoupled 3D-RoPE positional keys, replacing per-head keys and values to decrease memory usage by 92.7%.
💬 Research Conclusions:
– VideoMLA effectively matches short-horizon streaming video diffusion performance and surpasses baselines at long horizons, achieving a 1.23x throughput improvement on a single B200.
👉 Paper link: https://huggingface.co/papers/2605.30351
67. SkillAdaptor: Self-Adapting Skills for LLM Agents from Trajectories
🔑 Keywords: LLM agents, training-free skill adaptation, SkillAdaptor, failure attribution, reusable external skills
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the stability and auditability of training-free skill maintenance in LLM agents by introducing a step-level skill adaptation framework with explicit failure attribution.
🛠️ Research Methods:
– Developed SkillAdaptor, a framework that identifies first actionable fault steps and performs targeted updates with explicit acceptance checks on failed trajectories. Evaluated on benchmark environments such as WebShop, PinchBench, and Claw-Eval with models including Kimi-K2.5, GLM-5, and GPT-5.2.
💬 Research Conclusions:
– SkillAdaptor showed improved performance over baseline approaches with notable single-metric gains across different evaluation suites, supporting step-level attribution as a means to achieve more stable skill maintenance.
👉 Paper link: https://huggingface.co/papers/2606.01311

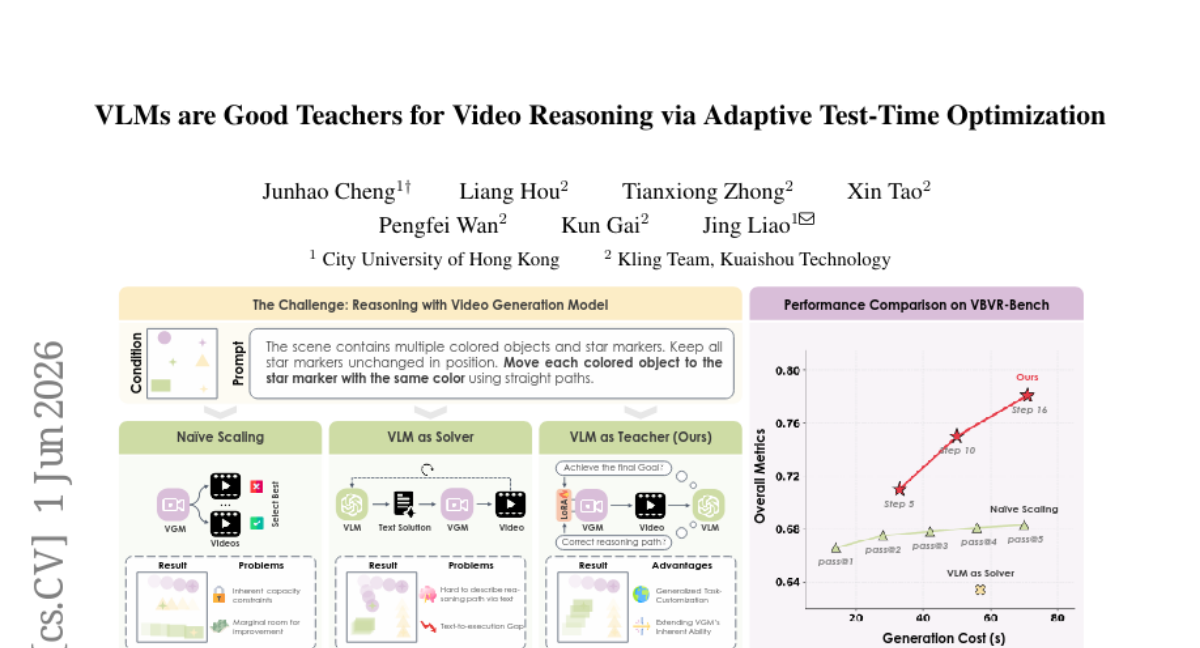
68. VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
🔑 Keywords: Video Generation Models, Vision-Language Models, Differentiable Rewards, Test-Time Optimization, Video Reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to improve video reasoning performance by integrating Vision-Language Models (VLMs) as “teachers” during test-time to guide Video Generation Models (VGMs).
🛠️ Research Methods:
– The approach involves using VLMs to extract task-specific rules to create differentiable rewards, which guide VGM reasoning through online test-time optimization of a LoRA module.
💬 Research Conclusions:
– The proposed method achieves a 16.7-point average performance gain on video reasoning benchmarks, significantly outperforming both the VLM-as-Solver paradigm and Best-of-N scaling, showcasing the effectiveness of VLMs as a promising tool for generalizable video reasoning.
👉 Paper link: https://huggingface.co/papers/2606.02564
69. Linear Ensembles Wash Away Watermarks: On the Fragility of Distributional Perturbations in LLMs
🔑 Keywords: Watermarking, AI-generated text, Statistical Hybridisation, Model Ensemble, Detection
💡 Category: Generative Models
🌟 Research Objective:
– Investigate the vulnerability of watermarking mechanisms in AI-generated text when multiple models are employed by users.
🛠️ Research Methods:
– Theoretical proof and empirical experiments demonstrating the effect of averaging outputs from multiple models on watermark detection and text quality.
💬 Research Conclusions:
– Demonstrates that averaging 3-5 models cancels watermark perturbations, suppressing detection z-scores and reducing true positive rates, while notably improving quality and processing speed.
– Highlights a fundamental vulnerability in AI-text detection, suggesting the need for unprecedented coordination among AI model providers for robust watermarking.
👉 Paper link: https://huggingface.co/papers/2605.30501

70. Draft-OPD: On-Policy Distillation for Speculative Draft Models
🔑 Keywords: Speculative decoding, Draft model, Supervised fine-tuning, On-policy distillation, Lossless acceleration
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve the acceleration of large language model inference by addressing the limitations of current speculative decoding methods.
🛠️ Research Methods:
– The research investigates the on-policy distillation (OPD) method with target-assisted rollouts and error replay to enhance the effectiveness of draft models in speculative decoding. It introduces Draft-OPD for more stable continuations.
💬 Research Conclusions:
– The proposed Draft-OPD method achieves over five times acceleration without loss across various tasks, outperforming existing models like EAGLE-3 and DFlash with improvements of 23% and 13% respectively.
👉 Paper link: https://huggingface.co/papers/2605.29343

71. K-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
🔑 Keywords: K-BrowseComp, LLMs, Korean AI, Synthetic Split, Web-Browsing Agent
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate the capabilities of frontier large language models (LLMs) in the context of Korean web-browsing tasks using a newly introduced benchmark called K-BrowseComp.
🛠️ Research Methods:
– The research involves creating a benchmark consisting of 400 problems, with a verified subset constructed and validated by native Korean speakers. Additionally, a synthetic split is generated to act as a targeted stress test for the models.
💬 Research Conclusions:
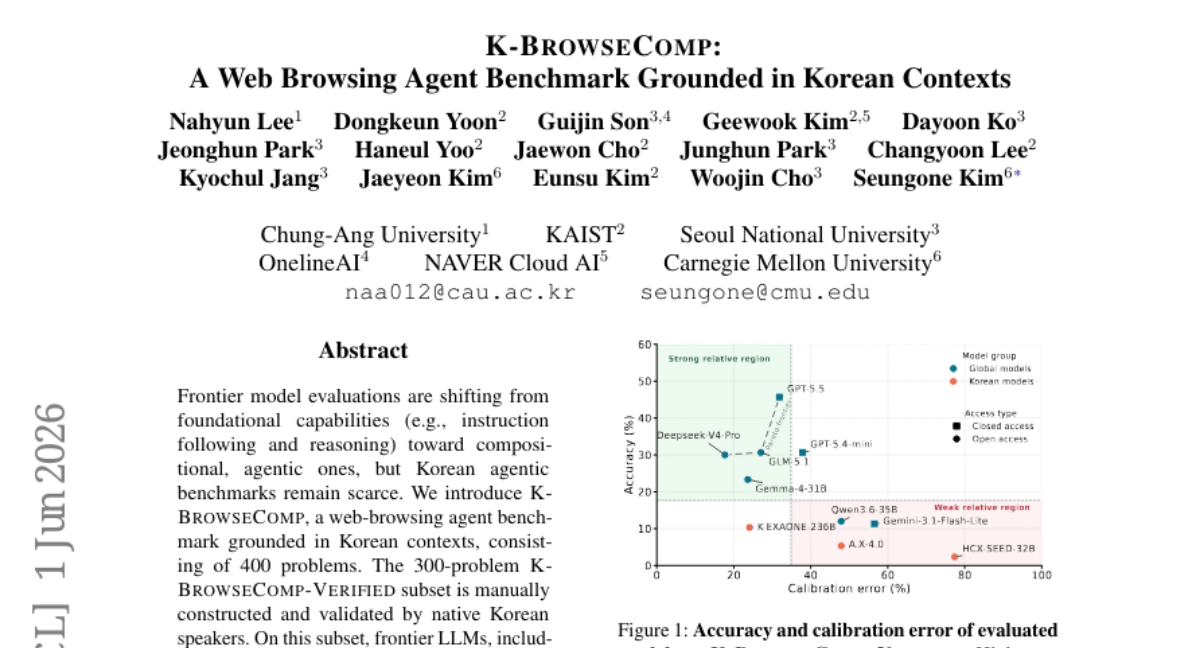
– Frontier LLMs, such as GPT-5.5, demonstrate significant performance gaps on the K-BrowseComp benchmark compared to existing English benchmarks, indicating a need for enhanced Korean AI development. Korean LLMs show particularly low performance scores.
👉 Paper link: https://huggingface.co/papers/2606.02404
72. On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
🔑 Keywords: Parameter-efficient fine-tuning, trainable adapters, shared foundation models, instance-specific behavior, persistent personal models
💡 Category: Machine Learning
🌟 Research Objective:
– The study examines the role of parameter-efficient fine-tuning (PEFT) using small trainable adapters to enable persistent personal models on top of strong foundation models, moving beyond the typical view of PEFT as a cost-effective substitute for full fine-tuning.
🛠️ Research Methods:
– The research explores three scaling axes: Scale Up to amplify the utility of small local updates; Scale Down to determine the minimal reliable size of adapters; and Scale Out to manage coexistence of multiple adapted instances using an infrastructure example, MinT, for handling adapter identity, revision, provenance, evaluation, and serving residency.
💬 Research Conclusions:
– The findings suggest that PEFT serves as a compact substrate for creating and maintaining persistent personal models, demonstrating its utility beyond merely being a budget alternative to full fine-tuning.
👉 Paper link: https://huggingface.co/papers/2606.02437
