AI Native Daily Paper Digest – 20260608

1. Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
🔑 Keywords: Large language models, EmbedFilter, text embeddings, high-frequency tokens, dimensionality reduction
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study aims to address the deficiency in large language models’ embedding capabilities by introducing EmbedFilter, a linear transformation that enhances semantic representations and enables dimensionality reduction.
🛠️ Research Methods:
– The authors identified that text embeddings tend to align with frequent, uninformative tokens, and thus, applied EmbedFilter to suppress the influence of these high-frequency tokens, refining the semantic quality of the embeddings.
💬 Research Conclusions:
– Experiments show that models integrated with EmbedFilter achieve better zero-shot performance on downstream tasks, even with reduced embedding dimensions, suggesting enhanced efficiency and quality of semantic representations.
👉 Paper link: https://huggingface.co/papers/2606.07502

2. AnchorWorld: Embodied Egocentric World Simulation with View-based Evolution Customization
🔑 Keywords: egocentric simulation, 3D human motion, spatial grounding, self-evolving worlds, anchor views
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance egocentric simulation through improved interaction integrity and world customization using 3D human motion and anchor view definitions.
🛠️ Research Methods:
– Utilization of 3D human motion as the primary interaction modality, and incorporation of auxiliary training supervision with exogenous viewpoints to improve spatial grounding of human-world interactions.
– Introduction of a mechanism for customizing self-evolving worlds by defining anchor views within a unified world coordinate system and using textual descriptions for dynamic evolution of scenes.
💬 Research Conclusions:
– AnchorWorld outperforms state-of-the-art baselines, with ablation studies supporting the effectiveness of its designs. The proposed customization scheme shows promising spatio-temporal geometric consistency and adheres strictly to the prescribed evolutionary dynamics.
👉 Paper link: https://huggingface.co/papers/2606.07326

3. GENEB: Why Genomic Models Are Hard to Compare
🔑 Keywords: GENEB, genomic foundation models, diagnostic benchmark, probing-based protocol, model rankings
💡 Category: Foundations of AI
🌟 Research Objective:
– To introduce GENEB, a comprehensive benchmark for evaluating genomic foundation models across diverse tasks and architectures under a unified protocol.
🛠️ Research Methods:
– Implementation of a large-scale diagnostic benchmark called GENEB, which evaluates frozen representations from 40 genomic foundation models across 100 tasks spanning 13 functional categories using a unified probing-based protocol.
💬 Research Conclusions:
– Current evaluation practices show limitations, as model rankings vary sharply across task categories, with scale providing modest and inconsistent gains. GENEB is positioned as a reference framework for principled comparison and category-aware model selection in genomic machine learning.
👉 Paper link: https://huggingface.co/papers/2606.04525

4. Robots Need More than VLA and World Models
🔑 Keywords: Generalist robot intelligence, unstructured behavioral data, embodiment mapping, world modeling, reward inference
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper argues for a shift from focusing solely on policy scaling to incorporating unstructured behavioral data through specialized interfaces to enhance robot intelligence.
🛠️ Research Methods:
– The study highlights the need for interfaces for autolabelling unstructured behavior, retargeting human motion, 3D reasoning for world modeling, and inferring rewards.
💬 Research Conclusions:
– The authors propose a research agenda for building robotic systems capable of learning from the broader physical world, not just robot demonstrations.
👉 Paper link: https://huggingface.co/papers/2606.06556

5. OpenSkill: Open-World Self-Evolution for LLM Agents
🔑 Keywords: OpenSkill, self-evolving agents, open-world deployment, verification signals, transferable skills
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This study introduces OpenSkill, aiming to enable agents to develop skills and verification signals independently using open-world resources, without relying on target-task supervision.
🛠️ Research Methods:
– OpenSkill employs a framework to bootstrap the learning loop by acquiring grounded knowledge and verification anchors from various sources and synthesizing them into transferable skills.
💬 Research Conclusions:
– OpenSkill showcases high automated performance across benchmarks without breaching the no-supervision constraint, effectively transferring skills across models and aligning self-built verifiers with ground-truth outcomes.
👉 Paper link: https://huggingface.co/papers/2606.06741

6. UniSHARP: Universal Sharp Monocular View Synthesis
🔑 Keywords: AI Native, universal monocular rendering, omnidirectional latent space, Gaussian primitives, photorealistic view synthesis
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to extend SHARP for universal monocular rendering across various camera systems by aligning images in an omnidirectional latent space.
🛠️ Research Methods:
– UniSHARP is proposed, which performs implicit alignment in both feature and Gaussian spaces using Gaussian primitives arranged in a ray-based universal representation. A benchmark stratified by field of view is constructed for evaluation.
💬 Research Conclusions:
– UniSHARP demonstrates superior performance in universal monocular rendering across diverse imaging systems, outperforming alternative methods by a large margin.
👉 Paper link: https://huggingface.co/papers/2606.07514

7. LIMMT: Less is More for Motion Tracking
🔑 Keywords: Motion Tracking, High-Quality Data, Data-Centric Study, Physics-Based Humanoid Motion Tracking, Data Cleaning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to improve tracking policy optimization for physics-based humanoid motion tracking using high-quality motion data, specifically by utilizing minimal data subsets to outperform full datasets.
🛠️ Research Methods:
– Introduction of LIMMT (Less Is More for Motion Tracking) as a framework, focusing on data quality defined by physics feasibility, diversity, and complexity. Data cleaning on web-sourced mocap data was also conducted.
💬 Research Conclusions:
– Demonstrated that less than 3% of the AMASS dataset yields better tracking performance than the full dataset, and extensive experiments validate the effectiveness of the LIMMT framework.
👉 Paper link: https://huggingface.co/papers/2606.06953
8. dots.tts Technical Report
🔑 Keywords: Continuous Autoregressive, AudioVAE, Flow-Matching Head, Low-Latency Speech Generation
💡 Category: Generative Models
🌟 Research Objective:
– The goal is to develop a state-of-the-art continuous autoregressive text-to-speech model, dots.tts, capable of efficient low-latency speech generation across multiple languages.
🛠️ Research Methods:
– Utilizes a novel training approach with AudioVAE for a semantically structured continuous speech space.
– Incorporates full-history conditioning and reward-free self-corrective post-training to enhance robustness and acoustic quality.
– Applies CFG-aware MeanFlow distillation to minimize latency in speech generation.
💬 Research Conclusions:
– The model, trained on a large multilingual corpus, shows superior performance on Seed-TTS-Eval benchmark with impressive WERs and SIM scores.
– Achieves open-source state-of-the-art results on multiple benchmarks, showcasing strong stability, voice cloning, and emotional expressiveness.
– Efficient inference is possible with dual-streaming modes, facilitating practical deployment and reproducible research.
👉 Paper link: https://huggingface.co/papers/2606.07080

9. PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams
🔑 Keywords: PaperFlow, scientific paper recommendation, profiling, interest drift, multi-signal aggregation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a framework called PaperFlow for recommending scientific papers by processing user profiles, daily paper streams, and addressing interest drift through a three-stage process.
🛠️ Research Methods:
– Implemented a longitudinal benchmark with 24 users, 50 daily streams, and 1,200 episodes to evaluate PaperFlow.
– Organized the framework into three stages: Profiling, Recommending, and Adapting.
💬 Research Conclusions:
– PaperFlow demonstrates superior oracle-based ranking, high behavioral alignment with simulated reading selections, and outperforms scientific recommendation baselines in blind human-evaluation scores.
👉 Paper link: https://huggingface.co/papers/2606.07454

10. Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
🔑 Keywords: Astra, Vision-Language Models, action-conditioned visual imagination, world simulator, spatial reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance Vision-Language Models with action-conditioned visual imagination through a spatial reasoning framework called Astra.
🛠️ Research Methods:
– Astra employs a reinforcement learning-trained policy coupled with a Bagel-based world simulator to generate novel-view observations, utilizing view consistency tuning and a world-simulator-in-the-loop two-phase RL curriculum.
💬 Research Conclusions:
– The Astra framework significantly improves spatial reasoning by providing useful imagined observations, demonstrating improvements on benchmarks such as MMSI-Bench and MindCube; effective reasoning requires learning the optimal use of imagined evidence.
👉 Paper link: https://huggingface.co/papers/2606.06476

11. Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors
🔑 Keywords: 3D vision-language model, autoregressive control modeling, Visual-Spatial Feature Integration, Geometry-Adaptive Voxel Compression
💡 Category: Computer Vision
🌟 Research Objective:
– The paper presents an online 3D vision-language model aimed at achieving real-time spatial understanding from streaming video.
🛠️ Research Methods:
– Utilizes autoregressive streaming control modeling to determine response timing.
– Employs a Visual-Spatial Feature Integration (VSFI) module to incrementally inject geometry priors.
– Proposes a Geometry-Adaptive Voxel Compression (GAVC) module for efficient visual token compression.
💬 Research Conclusions:
– Extensive experiments demonstrate the model’s superior performance over existing proprietary and open-source models in tasks related to 3D spatial understanding, reasoning, and grounding.
👉 Paper link: https://huggingface.co/papers/2606.06891
12. SIA: Self Improving AI with Harness & Weight Updates
🔑 Keywords: Self-Improving AI, Language-Model Agent, Task-Specific Agent, GPU Optimization, Biological Data Denoising
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a self-improving AI framework that can update both the model weights and task-specific agent architecture using a language-model feedback agent across diverse tasks.
🛠️ Research Methods:
– Introduced SIA, a self-improving loop that simultaneously updates the harness and weights of a task-specific agent across different domains such as legal classification, GPU optimization, and biological data denoising.
💬 Research Conclusions:
– The proposed method, combining both harness and weight updates, outperformed traditional scaffold-only iterations across various tasks, achieving significant improvements in benchmarks like LawBench, GPU kernel runtime, and RNA denoising.
👉 Paper link: https://huggingface.co/papers/2605.27276

13. Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
🔑 Keywords: post-hoc compression, knowledge distillation, accuracy-efficiency trade-off, reasoning traces
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore the benefits of post-hoc compression of reasoning traces for more efficient and cost-effective knowledge distillation.
🛠️ Research Methods:
– Two instruction-tuned models were used to compress reasoning traces from large teacher models, reducing them to 8.6-21.0% of their original length. Experiments conducted included main grid runs and truncation ablations to compare efficiency and accuracy.
💬 Research Conclusions:
– Compressed traces significantly reduce training time and token usage while maintaining a high level of accuracy. Raw traces retain the highest accuracy, but compressed models provide substantial efficiency improvements, up to 18x per token efficiency, especially beneficial for smaller models.
👉 Paper link: https://huggingface.co/papers/2606.05988

14. ECI_{sem}: Semantic Residual Effective Contrastive Information for Evaluating Hard Negatives
🔑 Keywords: ECI_sem, dense retrieval, semantic residual, BEIR, MS MARCO
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce ECI_sem, a semantic residual variant of Effective Contrastive Information, to rank negative sources for dense retrieval without training, using frozen embeddings.
🛠️ Research Methods:
– ECI_sem constructs a weighted residual information matrix based on target consistency, semantic locality, lexical residuality, and log-determinant diversity.
💬 Research Conclusions:
– ECI_sem achieves strong performance on MS MARCO and BEIR benchmarks, with high alignment depending on the target encoder and stability under various perturbations.
👉 Paper link: https://huggingface.co/papers/2603.20990

15. Towards Retrieving Interaction Spaces for Agentic Search
🔑 Keywords: RISE framework, BM25, agentic search, corpus exploration, interaction space
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to develop the RISE framework for efficient corpus exploration by constructing bounded interaction spaces that maintain high accuracy at scale.
🛠️ Research Methods:
– The study combines BM25 retrieval with preprocessed document indexing to create an interaction space for agentic search, optimizing for shell-style navigation.
💬 Research Conclusions:
– The RISE framework, when evaluated on BrowseComp-Plus, demonstrated comparable accuracy to the pure-shell DCI baseline at 78% accuracy with lesser costs and outperformed it significantly in larger corpus settings, achieving 81% accuracy on a 1M document set.
👉 Paper link: https://huggingface.co/papers/2606.06880

16. A Cookbook of 3D Vision: Data, Learning Paradigms, and Application
🔑 Keywords: 3D vision, geometric representations, learning frameworks, datasets, multimodal geometric grounding
💡 Category: Computer Vision
🌟 Research Objective:
– This study aims to create a data-centric taxonomy for 3D vision, integrating key elements such as geometric representations, datasets, learning frameworks, and applications into a unified conceptual map.
🛠️ Research Methods:
– The methods include analyzing various structural representations of 3D data like point clouds, meshes, voxels, and 3D Gaussians, and exploring dataset design, benchmark construction, and supervision regimes.
💬 Research Conclusions:
– The research provides a clarified view of the intricate interactions between representations, learning paradigms, and tasks, highlighting the trends toward balancing efficiency and fidelity and emphasizing multimodal geometric grounding.
👉 Paper link: https://huggingface.co/papers/2606.04291

17. When Gradients Collide: Failure Modes of Multi-Objective Prompt Optimization for LLM Judges
🔑 Keywords: Multi-objective LLM judge customization, textual gradients, Gradient specificity, instruction interference, Spearman’s rho
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to customize a large language model (LLM) judge for specific tasks or domains by optimizing its prompts across multiple evaluation criteria using textual gradients.
🛠️ Research Methods:
– The authors tested five decomposition modes of textual gradient optimizers by altering the shared cross-task information between loss, gradient, and optimizer LLMs.
💬 Research Conclusions:
– The research identified two key failure modes: gradient dilution during optimization and instruction interference during inference, which limit the effectiveness of multi-objective judge customization with textual feedback.
👉 Paper link: https://huggingface.co/papers/2605.26046

18. HarnessForge: Joint Harness and Policy Evolution for Adaptive Agent Systems
🔑 Keywords: LLM agents, meta-adaptation, HarnessForge, co-evolution, harness-conditioned policy alignment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address the challenges faced by LLM agents in heterogeneous task regimes by proposing a meta-adaptive framework, HarnessForge, which facilitates the co-evolution of agent systems.
🛠️ Research Methods:
– Introduction of a stable adaptation space through harness–policy pairs separating execution structure from reasoning behavior, and employing fault-guided harness tailoring and harness-conditioned policy alignment for co-evolution.
💬 Research Conclusions:
– HarnessForge enhances the performance of LLM agents like Qwen3-4B and Qwen3-8B, achieving up to 12.0% improvement over baselines, and emphasizes the importance of harmonizing harness and policy to optimize agent-system adaptability.
👉 Paper link: https://huggingface.co/papers/2606.01779

19. Empirical Study on the Characteristics and Evolution of AI-usage in GitHub Repositories: Evidence from Code Comments
🔑 Keywords: AI tools, LLMs, code implementation, bug fixing, human oversight
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to analyze how AI tools, particularly LLMs, are utilized by developers in real-world software development workflows and the evolution of AI-assisted code over time.
🛠️ Research Methods:
– Analysis of 35,361 GitHub code comments referencing AI use, deriving a taxonomy of AI-assisted development activities, and annotating the dataset using LLM-based classifiers. Additionally, the study examines 12,996 subsequent commit messages to understand the evolution of AI-assisted code.
💬 Research Conclusions:
– The findings indicate that developers primarily use LLMs for tasks like code implementation, enhancement, debugging, and documentation, with sustained human oversight through refactoring and bug fixing. AI tools are increasingly seen as collaborative support mechanisms, shifting from direct code generation to enhancing conceptual support over time.
👉 Paper link: https://huggingface.co/papers/2606.06843

20. Towards Human-Like Interactive Speech Recognition With Agentic Correction and Semantic Evaluation
🔑 Keywords: Interactive ASR, semantic correction, multi-turn refinement, Sentence-level Semantic Error Rate, reasoning-based editing
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The primary objective is to reduce semantic errors in Automatic Speech Recognition (ASR) through the integration of semantic correction and reasoning-based editing in a multi-turn refinement process.
🛠️ Research Methods:
– The study introduces the Agentic ASR framework which combines a single-pass ASR front-end with semantic correction, intent routing, and reasoning-based editing, validated through a new Sentence-level Semantic Error Rate (S^2ER) metric and an Interactive Simulation System.
💬 Research Conclusions:
– Iterative interaction in multilingual, named-entity-intensive, and code-switching benchmarks significantly reduces semantic errors more effectively in S^2ER than conventional token-level metrics, demonstrating enhanced alignment and robustness of the proposed framework.
👉 Paper link: https://huggingface.co/papers/2605.29430

21. Measuring Model Robustness via Fisher Information: Spectral Bounds, Theoretical Guarantees, and Practical Algorithms
🔑 Keywords: Fisher Information Matrix, spectral norm, robustness metric, deep neural networks, adversarial vulnerability
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to introduce a novel attack-agnostic robustness metric for deep neural networks using the spectral norm of the Fisher Information Matrix.
🛠️ Research Methods:
– The study develops scalable evaluation methods such as power iteration and Hutchinson-based estimation for robustness assessment across different architectures, including VGG, ResNet, DenseNet, and Transformer in both white-box and black-box settings.
💬 Research Conclusions:
– The research demonstrates a strong correlation between the proposed metric and adversarial vulnerability, suggesting that the framework serves as an interpretable diagnostic tool for complementing attack-based evaluations and guiding robust model design.
👉 Paper link: https://huggingface.co/papers/2606.04767

22. WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
🔑 Keywords: WorldBench, Multimodal Large Language Models, Visual Diversity, Reasoning Benchmark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to introduce WorldBench, a visually diverse reasoning benchmark for evaluating Multimodal Large Language Models (MLLMs) and to reveal limitations in current models’ visual understanding capabilities.
🛠️ Research Methods:
– The study involves constructing a taxonomy of thousands of visual concepts across multiple domains, and curating a broad collection of images from search engines and datasets to represent the visual world comprehensively. It uses structured trial-and-error to design challenging questions for MLLMs.
💬 Research Conclusions:
– WorldBench demonstrates higher visual diversity compared to existing benchmarks, revealing weaknesses in visual understanding where even the strongest MLLMs only reach a 64.0% accuracy, emphasizing the importance of visual diversity in building multimodal benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.06538

23. The Distillation Game: Adaptive Attacks & Efficient Defenses
🔑 Keywords: Distillation attacks, Minimax game, Adaptive evaluation, Defense strategy, Product-of-Experts
💡 Category: Machine Learning
🌟 Research Objective:
– To study the trade-off between model utility and vulnerability to imitation attacks through a minimax game framework.
🛠️ Research Methods:
– Developed a minimax game between a utility-constrained teacher and an adaptive student to explore defensive strategies, including adaptive evaluation and a forward-pass-only defense called Product-of-Experts.
💬 Research Conclusions:
– The adaptive student recovers more capabilities than passive evaluation reveals, narrowing the robustness gap between costly defenses and the cheaper Product-of-Experts.
– The study suggests that strong distillation prevention requires evaluation against adaptive students for progress in antidistillation efforts.
👉 Paper link: https://huggingface.co/papers/2605.22737

24.

25. Augmenting Attention with Exponentially Decaying Memory Improves Query-Aware KV Sparsity
🔑 Keywords: RAT+, Memory Module, Sparse Inference, Long-Context Language Models, Query-Aware
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates whether the RAT+ memory module can enhance accuracy in query-aware sparse inference methods for long-context language models.
🛠️ Research Methods:
– The paper utilizes RAT+ for various representative methods including Quest, MoBA, and SnapKV, validating the improvements in accuracy across different sparse budgets and tasks.
💬 Research Conclusions:
– RAT+ consistently improves accuracy over standard attention in eight needle-in-a-haystack tasks and is verified on both RAT+ released checkpoints and continued pretraining on OLMo2-7B with a new memory module.
– Two hypotheses are proposed and supported by targeted experiments to explain the benefits of this memory module for query-aware sparse inference.
👉 Paper link: https://huggingface.co/papers/2605.28640

26. Critic-R: Improving Agentic Search using Instruction-tuned Retrievers with Natural Language Introspective Feedback
🔑 Keywords: Agentic search, Retrieval models, Critic model, Feedback loop, Query refinement
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The main aim is to enhance agentic search by improving the interaction between reasoning agents and retrieval models through a feedback loop mechanism.
🛠️ Research Methods:
– Introduces Critic-R, a framework utilizing a critic model to evaluate reasoning and retrieval outcomes via dual optimization mechanisms: Critic-R-Zero for inference-time query refinement and Critic-Embed for optimizing retrieval models using automatic supervision.
💬 Research Conclusions:
– Critic-R significantly improves retrieval quality and answer accuracy, as demonstrated by evaluations on HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle.
👉 Paper link: https://huggingface.co/papers/2606.00590

27. How Far Can Chord-Symbol Time-Series Adaptation Carry Genre Identity? Capabilities and Boundaries in Multi-Genre Chord-Symbol Modeling
🔑 Keywords: Music Transformer, harmonic prediction, LoRA, IA3, genre adaptation
💡 Category: Generative Models
🌟 Research Objective:
– To evaluate the effectiveness of small adaptation interfaces in extending a frozen Music Transformer model to handle multiple genres in harmonic prediction.
🛠️ Research Methods:
– The study compared five methods, including LoRA and IA3, across a complete 165-cell grid for 11 genres and three seeds, analyzing improvements in chord prediction.
💬 Research Conclusions:
– All methods improved the model over the base, with LoRA and IA3 scoring highest. Chord-symbol adaptation is shown to reliably enhance genre-local harmonic prediction, but it does not fully represent genre identity.
👉 Paper link: https://huggingface.co/papers/2606.07334

28. CORE: Contrastive Reflection Enables Rapid Improvements in Reasoning
🔑 Keywords: Contrastive Reflection, reasoning tasks, verifiable rewards, natural-language insights
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to enhance AI Native reasoning capabilities in language models by using Contrastive Reflection to generate concise and interpretable insights for model self-improvement.
🛠️ Research Methods:
– Introduced Contrastive Reflection (CORE), a non-parametric algorithm analyzing differences in reasoning traces to derive insights, allowing efficient and faster reasoning task improvements.
💬 Research Conclusions:
– CORE demonstrated rapid and cost-effective performance improvements across various reasoning tasks compared to traditional parametric and non-parametric methods.
– It achieves comparable or superior outcomes with limited training samples and is more context-efficient, offering a more interpretable path to model self-improvement than existing approaches.
👉 Paper link: https://huggingface.co/papers/2605.28742

29. Parametric Social Identity Injection and Diversification in Public Opinion Simulation
🔑 Keywords: Large language models, public opinion simulation, Diversity Collapse, Parametric Social Identity Injection, representation-level control
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the issue of reduced social diversity in public opinion simulations with large language models by introducing a parametric framework to enhance demographic representation fidelity and diversity.
🛠️ Research Methods:
– Implemented a Parametric Social Identity Injection framework to inject explicit demographic and value-oriented representations into LLMs.
– Conducted extensive experiments using the World Values Survey and multiple open-source LLMs.
💬 Research Conclusions:
– The proposed method significantly improves the distributional fidelity and diversity of simulated public opinion data, reducing KL divergence and enhancing overall diversity, offering new insights into scalable, diversity-aware simulations.
👉 Paper link: https://huggingface.co/papers/2603.16142

30. Imaginative Perception Tokens Enhance Spatial Reasoning in Multimodal Language Models
🔑 Keywords: Imaginative Perception Tokens, spatial reasoning, Vision language models, Perspective Taking, Path Tracing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance vision-language models’ spatial reasoning capabilities by utilizing Imaginative Perception Tokens (IPT), which provide intermediate perceptual representations for improved interpretation of unseen viewpoints.
🛠️ Research Methods:
– Three tasks, Perspective Taking, Path Tracing, and Multiview Counting, were formulated and tested using datasets with approximately 20K examples and the unified vision-language model BAGEL as the backbone.
💬 Research Conclusions:
– IPT supervision enhances spatial reasoning and often outperforms traditional text-based methods, improving accuracy by 3.4% on Multiview Counting and showing competitive performance on Path Tracing. Combining IPT with label-only supervision further improves results, whereas textual chain of thought training could hinder performance.
👉 Paper link: https://huggingface.co/papers/2606.03988
31. Data-Efficient Autoregressive-to-Diffusion Language Models via On-Policy Distillation
🔑 Keywords: Autoregressive Models, Diffusion Language Models, On-Policy Distillation, Train-Inference Mismatch, Bidirectional Attention
💡 Category: Generative Models
🌟 Research Objective:
– To transform autoregressive language models (ARLMs) into diffusion language models (DLMs) using on-policy distillation to address train-inference mismatch and reduce training token requirements.
🛠️ Research Methods:
– Implementing an On-Policy Diffusion Language Model (OPDLM) where on-policy distillation (OPD) is used for transforming ARLMs to DLMs, incorporating bidirectional attention for generating trajectories and using original ARLMs for knowledge distillation.
💬 Research Conclusions:
– OPDLM significantly reduces the need for training tokens (15x to 7,000x fewer) while maintaining strong performance across various tasks, thus eliminating the high cost of DLM pretraining and improving knowledge retention from ARLMs.
👉 Paper link: https://huggingface.co/papers/2606.06712

32. Streaming Video Generation with Streaming Force Control
🔑 Keywords: StreamForce, causal model, video generation, distillation pipeline, autoregressive efficiency
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce StreamForce, a streaming video generation framework that provides real-time, physically grounded responses to time-varying forces.
🛠️ Research Methods:
– Design a unified force representation as a control signal and develop a distillation pipeline for force-controllable video generation.
– Combine autoregressive efficiency with force responsiveness to achieve stable photometric and dynamic realism.
💬 Research Conclusions:
– StreamForce achieves state-of-the-art performance in force adherence and motion realism, running at up to 16.6 FPS on a single GPU.
👉 Paper link: https://huggingface.co/papers/2606.07508
33. LayerRoute: Input-Conditioned Adaptive Layer Skipping via LoRA Fine-Tuning for Agentic Language Models
🔑 Keywords: LayerRoute, transformer blocks, LoRA adapters, inference, compute savings
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a lightweight adapter, LayerRoute, that selectively skips transformer blocks during inference to save computational resources while maintaining or improving model quality.
🛠️ Research Methods:
– Utilized LayerRoute with a per-layer router and LoRA adapters for gated routing on Qwen2.5-0.5B-Instruct, alongside a single end-to-end training pass on agentic data with gate regularization.
💬 Research Conclusions:
– Achieved a 12.91% skip differential in FLOPs: tool calls skip 15.25% of FLOPs, while planning steps skip 2.34%. Quality improved over the base model due to LoRA adaptation, with reduced perplexity for both tool calls and planning steps.
👉 Paper link: https://huggingface.co/papers/2606.01838

34. Entropy as a Structural Prior: How a Log-Barrier on DiT Belief Space Drives Musical Diversity and Development
🔑 Keywords: Confidence-based loss weighting, generative models, entropy, diffusion training, Stable Audio 3
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve audio generation through adaptive gradient scaling using confidence-based loss weighting in supervised diffusion training.
🛠️ Research Methods:
– Introduces the Eisbach log-barrier, a parameter-free weight derived from the entropy of the DiT output’s spatial energy distribution, influencing gradient dampening or preservation.
– Applies this method to LoRA fine-tuning of Stable Audio 3 Medium on MusicCaps.
💬 Research Conclusions:
– Achieves stronger thematic development, clearer acoustic differentiation, and higher textural diversity in audio generation.
– Demonstrates the emergence of a self-referential data curriculum purely from the forward pass with testable predictions.
👉 Paper link: https://huggingface.co/papers/2606.07207

35. Reinforcement Learning from Rich Feedback with Distributional DAgger
🔑 Keywords: Forward Cross-Entropy, Distributional Imitation Learning, Monotonic Policy Improvement, Reasoning Tasks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enable monotonic policy improvement and enhance performance in reasoning tasks through forward cross-entropy objective with distributional imitation learning compared to traditional reinforcement learning methods.
🛠️ Research Methods:
– Utilization of a distributional variant of the classic imitation learning algorithm DAgger, where learners have local access to expert distribution on visited states for the current policy.
💬 Research Conclusions:
– Forward cross-entropy provides monotonic policy improvement and guarantees on regret, illustrating improvements over traditional RL and RL with self-distillation baselines in areas like scientific reasoning, coding, and solving complex mathematical problems.
👉 Paper link: https://huggingface.co/papers/2606.05152

36. Almieyar-Oryx-BloomBench: A Bilingual Multimodal Benchmark for Cognitively Informed Evaluation of Vision-Language Models
🔑 Keywords: Vision-Language Models, multimodal benchmark, cognitive asymmetry, cross-lingual multimodal reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce BloomBench, a cognitively grounded bilingual multimodal benchmark to reveal cognitive asymmetries and cross-lingual performance gaps in Vision-Language Models.
🛠️ Research Methods:
– Utilize Bloom’s Taxonomy to systematically evaluate six cognitive levels through image-question-answer tasks, employing a semi-automated pipeline and hybrid quality assurance protocol.
💬 Research Conclusions:
– Identify strong performance in semantic understanding but weaknesses in factual recall and creative synthesis, highlighting cognitive asymmetries and performance gaps between languages in current models.
👉 Paper link: https://huggingface.co/papers/2606.05531

37. SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
🔑 Keywords: Vision-Language Models, Spatial Numerical Understanding, Coordinate-Aware Representations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study revisits spatial numerical understanding of Vision-Language Models (VLMs) using the framework SpaceNum for evaluating map capabilities between spatial structures and numerical representations.
🛠️ Research Methods:
– Formulated bidirectional tasks (Num2Space and Space2Num) to systematically study if VLMs understand numerical values in spatial settings.
💬 Research Conclusions:
– Current VLMs fail to ground numerical values in spatial meaning, perform near random guesses, and continue to rely on shallow spatial cues instead of developing stable coordinate-aware representations. Explicit reasoning provides marginal improvements, but tuning can partially enhance spatial numerical understanding.
👉 Paper link: https://huggingface.co/papers/2605.23898

38. Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
🔑 Keywords: Socratic-SWE, self-evolving software engineering agents, historical solving traces, closed-loop self-evolution framework, repair patterns
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance LLM-driven software engineering agents using Socratic-SWE, which generates targeted repair tasks by leveraging historical solving traces.
🛠️ Research Methods:
– Implement a closed-loop self-evolution framework that distills historical solving traces into structured agent skills, guiding the generation of repair tasks.
– Validate tasks through execution-based validation and solver-gradient alignment rewards.
💬 Research Conclusions:
– Socratic-SWE improves self-evolution in software engineering agents across various benchmarks, achieving significant performance gains on constrained budgets.
– The approach demonstrates that solving traces can be a scalable substrate for enhancing the capabilities of self-evolving SWE agents.
👉 Paper link: https://huggingface.co/papers/2606.07412

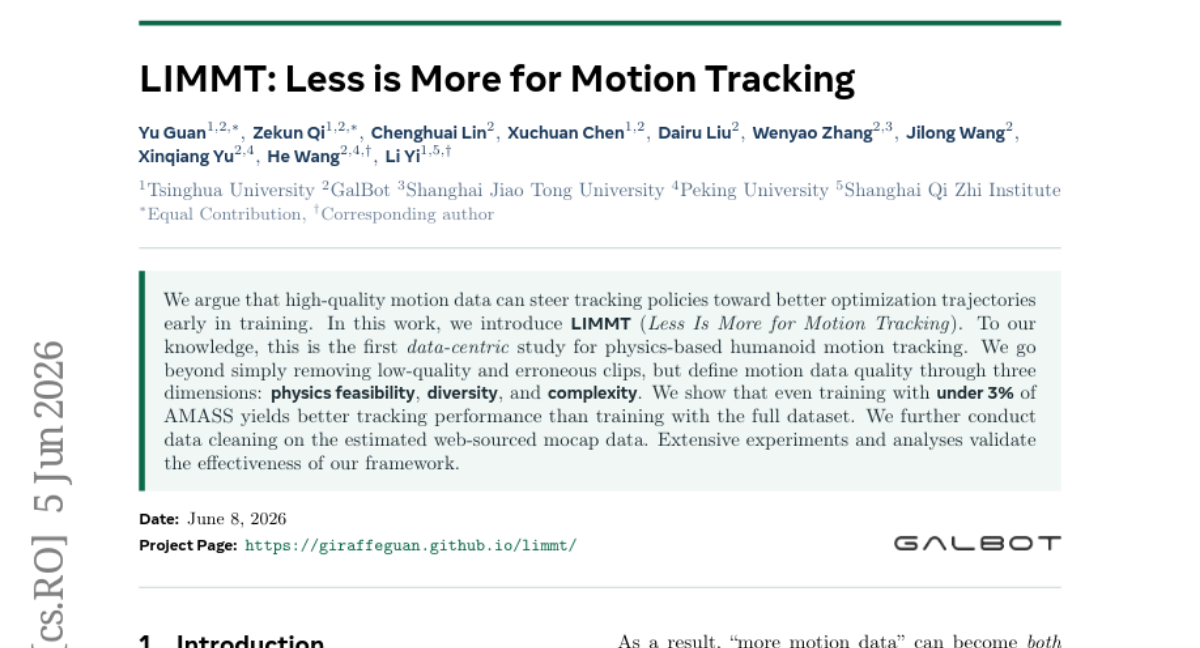
39. Physics in 2-Steps: Locking Motion Priors Before Visual Refinement Erases Them
🔑 Keywords: PhaseLock, Image-to-Video diffusion models, physical consistency, motion priors, Latent Delta Guidance
💡 Category: Generative Models
🌟 Research Objective:
– To improve physical consistency in image-to-video diffusion models by preserving motion priors during the denoising process.
🛠️ Research Methods:
– Utilized a training-free approach called PhaseLock to maintain motion priors from early-step inference throughout the denoising trajectory, using spectral analysis and Latent Delta Guidance.
💬 Research Conclusions:
– PhaseLock effectively mitigates phase degradation, improving physical consistency by an average of 6.2 points across diverse models, while preserving visual fidelity with minimal computational overhead.
👉 Paper link: https://huggingface.co/papers/2606.06361
40. LLM Explainability with Counterfactual Chains and Causal Graphs
🔑 Keywords: Causal graphs, Large Language Models, concept discovery, counterfactual augmentation, concept-level explainability
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to model Large Language Model inference processes using causal graphs to enhance transparency and explainability.
🛠️ Research Methods:
– A four-phase method involving concept discovery, mapping, and MCMC-inspired counterfactual augmentation is proposed to construct interpretable graphs, applied across various tasks including disease diagnosis and sentiment analysis.
💬 Research Conclusions:
– The discovered causal graphs reflect meaningful dependencies aligned with LLMs’ reasoning, supporting concept-level explainability of language models.
👉 Paper link: https://huggingface.co/papers/2606.05972
41. Watch, Remember, Reason: Human-View Video Understanding with MLLMs
🔑 Keywords: Multimodal large language models, video understanding, perceptual representations, memory modeling, reasoning traces
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to transform video understanding through Multimodal Large Language Models (MLLMs) that handle complex video scenarios by focusing on watching, remembering, and reasoning capabilities.
🛠️ Research Methods:
– The study introduces a human-view perspective, organizing LLMs by their roles in video tasks: perceptual representation, memory states, and reasoning. Challenges are identified in areas such as spatio-temporal perception and memory modeling.
💬 Research Conclusions:
– It offers insights into the future of scalable, memory-aware video intelligence, emphasizing the development of unified models for comprehensive video analysis and the exploration of application domains such as sports and medical videos.
👉 Paper link: https://huggingface.co/papers/2606.07433

42. UnpredictaBench: A Benchmark for Evaluating Distributional Randomness in LLMs
🔑 Keywords: UnpredictaBench, Large Language Models, Simulation, Output Diversity, Distributional Sampling
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the capacity of large language models (LLMs) in simulating target distributions and assessing the unpredictability of systems.
🛠️ Research Methods:
– Introduction of UnpredictaBench, which includes 448 problems aimed at testing LLMs’ ability to sample outcomes from individual target distributions, using the KS@N evaluation metric to quantify performance.
– Utilization of the Kolmogorov-Smirnov test to measure how well LLMs’ samples approximate target distributions.
💬 Research Conclusions:
– Significant variations exist among models in their distributional capabilities, with scores indicating room for improvement in distributional sampling.
– Current advancements in reasoning and output diversity have yet to provide a complete solution for accurate distributional simulations, highlighting ongoing challenges.
👉 Paper link: https://huggingface.co/papers/2606.06622

43. SubtleMemory: A Benchmark for Fine-Grained Relational Memory Discrimination in Long-Horizon AI Agents
🔑 Keywords: Persistent AI assistants, memory relations, long-term memory, relational memory, SubtleMemory
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To evaluate AI agents’ capacity to manage complex relational memory structures using the SubtleMemory benchmark, focusing on long-term memory relations.
🛠️ Research Methods:
– Introduced SubtleMemory, a benchmark specifically designed to assess fine-grained relational memory discrimination in prolonged AI interactions, consisting of 1,522 evaluation instances and grounded in 1,090 memory-variant sets.
💬 Research Conclusions:
– Existing memory systems exhibit limitations in discriminating fine-grained relational memory, and distinct capability profiles emerge across preservation, retrieval, and reasoning stages.
👉 Paper link: https://huggingface.co/papers/2606.05761

44. When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
🔑 Keywords: ToolMaze, Tool-Integrated Reasoning (TIR), implicit semantic failures, dynamic replanning, agentic fault-tolerance
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce ToolMaze, a benchmark designed for dynamic path discovery and error recovery in Tool-Integrated Reasoning (TIR) agents, addressing real-world tool failures.
🛠️ Research Methods:
– Employ a two-dimensional design incorporating DAG-based topological complexity and a 2×2 taxonomy of tool perturbations (explicit/implicit, transient/permanent) to evaluate performance under various conditions.
💬 Research Conclusions:
– Real-world tool failures, especially implicit semantic ones, significantly degrade TIR performance, with an approximate 37% drop in Perturbation Recovery Rate; dynamic replanning emerges as a crucial bottleneck inadequately addressed by model scaling or prompting.
👉 Paper link: https://huggingface.co/papers/2606.05806

45. Direct 3D-Aware Object Insertion via Decomposed Visual Proxies
🔑 Keywords: Object Insertion, Diffusion-based Methods, Pose Control, High-fidelity 2D Image Synthesis
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces DIRECT, a novel framework designed to enable pose-controllable object insertion with high-fidelity 2D image synthesis.
🛠️ Research Methods:
– The method utilizes decomposed guidance components comprising appearance guidance, geometry guidance, and context guidance to ensure accurate pose manipulation and visual detail integration.
💬 Research Conclusions:
– The proposed method, DIRECT, demonstrates superior performance in geometric controllability and visual quality compared to previous approaches, with the help of an automated data construction pipeline enhancing data diversity and quality.
👉 Paper link: https://huggingface.co/papers/2606.06601
46. MMAE: A Massive Multitask Audio Editing Benchmark
🔑 Keywords: Instruction-based Audio Editing, MMAE, Multitask Audio Editing, Audio Modalities
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduction of MMAE as a comprehensive benchmark for instruction-based audio editing across various modalities and complexity levels.
🛠️ Research Methods:
– The benchmark includes a taxonomy covering 7 audio modalities, 6 task complexity levels, and 8 operation types, based on a rubric-based evaluation framework.
💬 Research Conclusions:
– Current models show significant gaps in capabilities, with an Exact Match Rate below 5% and 0% in complex tasks, indicating challenges in execution precision and robustness.
👉 Paper link: https://huggingface.co/papers/2606.07229
47. SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
🔑 Keywords: SoCRATES, LLM mediators, socio-cognitive adaptation, consensus gap, multi-domain testbeds
💡 Category: Natural Language Processing
🌟 Research Objective:
– To present SoCRATES, a realistic benchmark for evaluating proactive LLM mediators across various socio-cognitive adaptation axes.
🛠️ Research Methods:
– Construct scenarios from real conflicts using an agentic pipeline in eight domains; probe five socio-cognitive adaptation axes; evaluate using a topic-localized evaluator aligned with human experts.
💬 Research Conclusions:
– Even top-performing Large Language Models (LLMs) resolve only about a third of the consensus gap; performance varies sharply by socio-cognitive axis, indicating need for better social adaptation.
👉 Paper link: https://huggingface.co/papers/2606.05563
