AI Native Daily Paper Digest – 20260611

1. Redesign Mixture-of-Experts Routers with Manifold Power Iteration
🔑 Keywords: Mixture-of-Experts, Router, Principal Singular Direction, Manifold Power Iteration
💡 Category: Machine Learning
🌟 Research Objective:
– To propose a novel router redesign for Mixture-of-Experts models by aligning router rows with the principal singular directions of expert matrices to enhance model effectiveness.
🛠️ Research Methods:
– Utilization of a “Power-then-Retract” paradigm within Manifold Power Iteration, applying a power iteration step on router weights followed by retraction to impose norm constraints, ensuring efficiency and stability.
💬 Research Conclusions:
– Empirical evidence from pretraining MoE models with parameters ranging from 1B to 11B confirms that the proposed alignment improves the effectiveness of Mixture-of-Experts models.
👉 Paper link: https://huggingface.co/papers/2606.12397

2. Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
🔑 Keywords: Large Language Models, Agentic Environments, Neural Synthesis, Symbolic Synthesis, Environment Engineering Lifecycle
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To systematically analyze the environments for Large Language Model agents in terms of their engineering lifecycle stages and capabilities evolution.
🛠️ Research Methods:
– Comprehensive study of environments through eight attributes and domains, along with the introduction of symbolic and neural synthesis paradigms.
– Evaluation of environment evolution via neural-driven, difficulty-driven, and scaling-driven approaches.
💬 Research Conclusions:
– Identifies key pathways for agent evolution using four perspectives: memory, orchestration, trajectory, and exploration.
– Discusses future directions, including Environment-as-a-Service and Multi-agent Environments.
👉 Paper link: https://huggingface.co/papers/2606.12191

3. Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions
🔑 Keywords: teacher-student framework, reward models, visual preference, Z-Reward, text-to-image optimization
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve preference accuracy and optimization performance in text-to-image training by decoupling complex reasoning from efficient reward deployment through a teacher-student framework.
🛠️ Research Methods:
– Introduces Z-Reward, a framework where the teacher, a large VLM, uses reasoning to infer score distributions and is trained with Group-wise Direct Score Optimization. The student employs Reasoning-Internalized Score Distillation to encode the teacher’s score distribution.
💬 Research Conclusions:
– The Z-Reward framework demonstrates significant improvements in human preference accuracy in internally annotated evaluations, with both the teacher and student models outperforming existing baselines. Additionally, it provides a differentiable reward signal leading to substantial enhancements in text-to-image optimization.
👉 Paper link: https://huggingface.co/papers/2606.09076

4. Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning
🔑 Keywords: Spatial reasoning, egocentric videos, Geometry-to-Video pipeline, MLLM, 3D geometry
💡 Category: Computer Vision
🌟 Research Objective:
– The paper proposes a training-free framework named “Reason, then Re-reason (ReRe)” for improving spatial reasoning from egocentric videos by allowing revisitation of conclusions through synthesized novel-view videos generated from predicted 3D geometry.
🛠️ Research Methods:
– The ReRe framework operates in two phases: the Reason Phase and the Re-reason Phase, utilizing MLLM to first form a spatial hypothesis from original videos and then verify or revise it through observing synthesized novel-view videos. A Geometry-to-Video pipeline is utilized for rendering complementary novel views from 3D geometry, providing elevated, oblique perspectives.
💬 Research Conclusions:
– Extensive evaluations on VSI-Bench and STI-Bench show that the ReRe framework significantly enhances the performance of open-source MLLMs, making them competitive with proprietary state-of-the-art methods.
👉 Paper link: https://huggingface.co/papers/2606.11683

5. World Pilot: Steering Vision-Language-Action Models with World-Action Priors
🔑 Keywords: World Pilot, Vision-Language-Action models, World-Action Model, zero-shot out-of-distribution
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Enhance Vision-Language-Action models with dynamic scene evolution and trajectory priors from a World-Action Model to improve performance in zero-shot out-of-distribution manipulation tasks.
🛠️ Research Methods:
– Introduce World Pilot framework that integrates dynamic priors through Latent Steering and Action Steering pathways to augment policy for VLA models.
💬 Research Conclusions:
– World Pilot achieves a state-of-the-art total success rate of 84.7% on the LIBERO-Plus zero-shot OOD benchmark and excels across real-robot settings, demonstrating high success rates even under varying conditions.
👉 Paper link: https://huggingface.co/papers/2606.12403

6. ComBench: A Benchmark for Rigorous Proof Reasoning and Constructive Realization in Olympiad-Level Combinatorics
🔑 Keywords: ComBench, Olympiad-level, combinatorial reasoning, large language models
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study introduces a new benchmark named ComBench to evaluate the combinatorial reasoning capabilities of large language models using Olympiad-level problems.
🛠️ Research Methods:
– ComBench includes 100 human-annotated problems divided into analysis-centric and construction-centric settings, using rubric-guided proof grading and deterministic construction verification for evaluation.
💬 Research Conclusions:
– The study found that even the strongest models are not fully adept at tackling Olympiad-level combinatorial problems, with a top model scoring 65.4% on average. It highlights the distinction between rigorous proof reasoning and constructive realization as separate capabilities of the models.
👉 Paper link: https://huggingface.co/papers/2606.10479

7. InternVideo3: Agentify Foundation Models with Multimodal Contextual Reasoning
🔑 Keywords: Multimodal Contextual Reasoning, Multimodal Multi-head Latent Attention, Video Agent, Long-Horizon Tasks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance long-horizon multimodal tasks through Multimodal Contextual Reasoning and efficient attention mechanisms, particularly focusing on video understanding challenges.
🛠️ Research Methods:
– The research employs a novel framework named InternVideo3, which utilizes Multimodal Contextual Reasoning and introduces Multimodal Multi-head Latent Attention to improve efficiency in video task processing. The training process involves staged training with components like continued pretraining, short-to-long supervised fine-tuning, rule-based reinforcement learning, and on-policy distillation.
💬 Research Conclusions:
– InternVideo3 exhibits strong performance on video understanding benchmarks such as Video-MME, MLVU, and EgoSchema. It also demonstrates robust and evidence-grounded behavior as a video agent, suggesting that efficient context handling and closed-loop reasoning are critical for long-horizon visually grounded agency.
👉 Paper link: https://huggingface.co/papers/2606.12195

8. TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
🔑 Keywords: TRACE, rollout allocation, reward contrast, multi-turn, tree-structured rollouts
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Improve reward contrast in multi-turn agentic reinforcement learning through dynamic resource distribution across tree-structured rollouts.
🛠️ Research Methods:
– Model each ReAct-style thought-action-observation turn as a distinct node for enhanced budget allocation.
– Use a shared generalizable predictor to estimate conditional success probability for guiding allocation.
💬 Research Conclusions:
– TRACE framework enriches outcome-only feedback and amplifies the policy-update signal.
– Achieved improvements in performance and efficiency, notably improving Qwen3-14B Multi-Hop QA accuracy by 2.8 points with competitive baselines at equal sampling cost.
👉 Paper link: https://huggingface.co/papers/2606.11119

9. ICA Lens: Interpreting Language Models Without Training Another Dictionary
🔑 Keywords: Independent Component Analysis, Interpretable Directions, Language Model Representations, Sparse Autoencoders, ICA Lens
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to assess the efficacy of Independent Component Analysis (ICA) for identifying interpretable directions in language model representations as a faster alternative to sparse autoencoder training.
🛠️ Research Methods:
– ICA Lens, a novel workflow combining optimized GPU-parallel FastICA pipeline with LLM-specific stability recipes and diagnostics, was introduced to analyze LLM activations efficiently.
💬 Research Conclusions:
– ICA Lens demonstrates competitive performance to sparse autoencoders in probing tasks and performs better in targeted probe perturbations under smaller budgets, suggesting that it should be considered a robust option for language model interpretability.
👉 Paper link: https://huggingface.co/papers/2606.11722

10. Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
🔑 Keywords: Embodied Foundation Model, Embodied Reasoning, Multi-task Balanced Reinforcement Learning, Zero-shot Real-robot Experiments, AI Native
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper introduces Embodied-R1.5, a unified Embodied Foundation Model aimed at enhancing embodied reasoning capabilities and achieving state-of-the-art performance on embodied vision-language benchmarks.
🛠️ Research Methods:
– The model employs a multi-task balanced reinforcement learning approach and integrates a Planner-Grounder-Corrector (PGC) closed-loop framework to autonomously execute and self-correct long-horizon tasks.
💬 Research Conclusions:
– Embodied-R1.5 achieves state-of-the-art results in 16 out of 24 benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5, and demonstrates robust generalization to the physical world through extensive zero-shot real-robot experiments. The model’s components, including weights and datasets, have been open-sourced to aid future research in Embodied Foundation Models.
👉 Paper link: https://huggingface.co/papers/2606.11324
11. World Model Self-Distillation: Training World Models to Solve General Tasks
🔑 Keywords: Self-distillation, Reinforcement Learning, Video Diffusion Model, Vision-Language Model, Task Solving
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a scalable framework that leverages self-distillation and reinforcement learning to transfer task-solving abilities from vision-language models to video diffusion models without requiring labeled task-video data.
🛠️ Research Methods:
– Combining self-distillation with reinforcement learning to elicit task-solving ability of pretrained video generators, supported by vision-language model-generated candidate tasks and step-by-step solutions.
💬 Research Conclusions:
– The Executor, enhanced through reinforcement learning from VLM feedback, surpasses the performance of the Demonstrator in task-solving capabilities, especially when evaluated through VLM-based protocol and benchmark tests such as WorldTasks-Benchmark and DreamGen robotics benchmark.
👉 Paper link: https://huggingface.co/papers/2606.12072

12. ReVision: Scaling Computer-Use Agents via Temporal Visual Redundancy Reduction
🔑 Keywords: ReVision, Computer-use agents, visual tokens, patch selector, multimodal language models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance efficiency in computer-use agents by reducing visual token usage through the removal of redundant visual patches in consecutive screenshots, while maintaining essential spatial information.
🛠️ Research Methods:
– The method involves a learned patch selector used within a framework named ReVision, which is applied to train multimodal language models. The selector compares patch representations across screenshots to identify and remove redundant patches.
💬 Research Conclusions:
– Implementing ReVision results in a significant reduction of token usage by 46% on average, while improving the success rate by 3% across benchmarks such as OSWorld, WebTailBench, and AgentNetBench, thus demonstrating enhanced efficiency in processing longer interaction trajectories with fewer tokens.
👉 Paper link: https://huggingface.co/papers/2605.11212

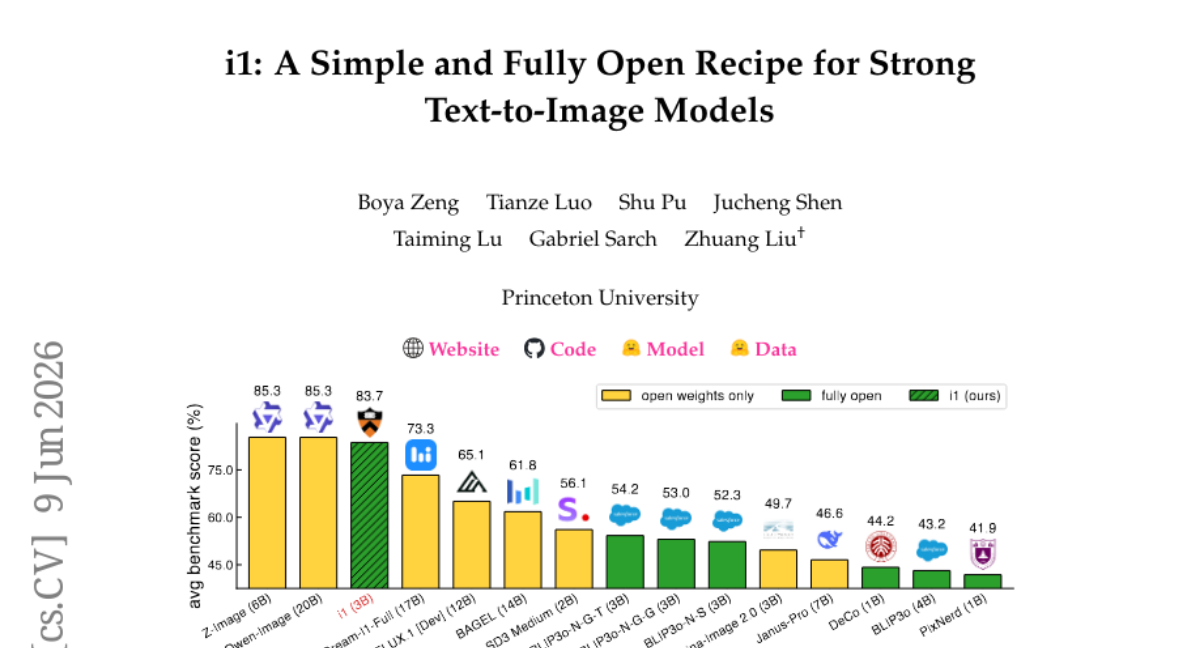
13. i1: A Simple and Fully Open Recipe for Strong Text-to-Image Models
🔑 Keywords: text-to-image diffusion, diffusion models, open models, i1 model
💡 Category: Generative Models
🌟 Research Objective:
– This study aims to investigate the design choices in text-to-image diffusion models and develop i1, a new 3B-parameter model that maintains transparency and matches leading performance.
🛠️ Research Methods:
– Conducted over 300 controlled experiments consuming 700K+ TPU v6e hours to analyze and identify effective modeling and data design choices for text-to-image diffusion models.
💬 Research Conclusions:
– The i1 model is created utilizing publicly available datasets and achieves competitive results across five representative benchmarks, outperforming existing fully open models by an average of 29.5 percentage points. The study offers the i1 model checkpoints, training and inference code, and a data processing pipeline to facilitate open research.
👉 Paper link: https://huggingface.co/papers/2606.11289
14. Time-Series Foundation Model Embeddings for Remaining Useful Life Estimation
🔑 Keywords: RUL prediction, industrial sensor data, TSFM, Chronos-2, frozen pretrained model
💡 Category: Machine Learning
🌟 Research Objective:
– To improve Remaining Useful Life (RUL) prediction performance using a lightweight approach by integrating a frozen pretrained time-series foundation model with a simple regression head.
🛠️ Research Methods:
– Utilized a frozen pretrained time-series foundation model, TSFM, specifically Chronos-2, as the backbone for feature extraction from multivariate sensor data.
– Implemented a lightweight regression neural network to estimate RUL.
💬 Research Conclusions:
– The approach demonstrated superior RUL prediction performance compared to recurrent, convolutional, Transformer-based, and gradient-boosting methods on real-world industrial sensor data.
– Longer historical data significantly enhances prediction performance, suggesting TSFM’s practical and efficient application in industrial RUL estimation.
👉 Paper link: https://huggingface.co/papers/2606.11990

15. Large Language Models Are Overconfident in Their Own Responses
🔑 Keywords: Instruction tuning, Chat template, Calibration, Ownership bias, Confidence elicitation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the calibration issue in instruction-tuned large language models, particularly focusing on the role of chat templates and ownership bias.
🛠️ Research Methods:
– Decoupling the effects of post-training algorithms and chat template formats to study their impact on calibration.
– Conducting extensive experiments across six recent open-weight LLMs, three benchmarks, and three methods of confidence elicitation.
💬 Research Conclusions:
– Instruction tuning harms the calibration of LLMs, with chat templates exacerbating overconfidence via ownership bias.
– Proposing a novel inference-time strategy to frame the model’s answer as user input, improving calibration by up to 26% without retraining.
👉 Paper link: https://huggingface.co/papers/2606.03437

16. Which Models Are Our Models Built On? Auditing Invisible Dependencies in Modern LLMs
🔑 Keywords: ModSleuth, LLM Dependency Graphs, Source-Grounded Evidence, License Obligations, Train-Evaluation Coupling
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop an agentic system (ModSleuth) that reconstructs large-scale dependency graphs for LLM development by analyzing public artifacts.
🛠️ Research Methods:
– Formalization distinguishing between direct and indirect dependencies.
– Operation-centered relationships to represent heterogeneous pipeline roles.
– Resolving artifact identities across names, versions, and repositories.
💬 Research Conclusions:
– ModSleuth successfully recovered 1,060 source-verified dependencies to construct large-scale dependency graphs for LLMs.
– Revealed multi-hop license obligations, train-evaluation coupling, and documentation inconsistencies in modern LLM development.
👉 Paper link: https://huggingface.co/papers/2606.12385

17. Lius: Translation Model Based Instructional Lingustic Using Continual Instruction Tuning In Kupang Malay
🔑 Keywords: Continual Instruction Tuning, Large Language Models, low-resource languages, Kupang Malay, bilingual dictionary
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the translation performance of large language models on low-resource languages like Kupang Malay by using a new fine-tuning approach.
🛠️ Research Methods:
– Employing a training paradigm called Continual Instruction Tuning (CIT) that utilizes instruction-based training with a bilingual dictionary.
💬 Research Conclusions:
– The proposed model, Lius, significantly improves translation accuracy over standard models and surpasses traditional translation systems on various evaluation metrics, reducing the need for large-scale parallel data.
👉 Paper link: https://huggingface.co/papers/2606.11786

18. Towards Diverse Scientific Hypothesis Search with Large Language Models
🔑 Keywords: Evolutionary framework, Large language models, Hypothesis generation, Diversity, Quality
💡 Category: Generative Models
🌟 Research Objective:
– To develop an evolutionary framework that enhances diversity and quality in generating scientific hypotheses using multi-temperature sampling and information exchange.
🛠️ Research Methods:
– Employs an evolutionary framework inspired by parallel tempering that explores multiple temperature levels for hypothesis generation.
💬 Research Conclusions:
– The approach consistently improves the quality and diversity of hypotheses across various domains, operating efficiently under a fixed validation budget while maintaining robustness against expensive downstream computational validations.
👉 Paper link: https://huggingface.co/papers/2606.10587

19. FlowLet: Conditional 3D Brain MRI Synthesis using Wavelet Flow Matching
🔑 Keywords: Brain Age Prediction, FlowLet, generative data augmentation, flow matching, invertible 3D wavelet domain
💡 Category: Generative Models
🌟 Research Objective:
– To improve brain age prediction performance for underrepresented age groups by synthesizing age-conditioned 3D MRIs using a novel framework FlowLet.
🛠️ Research Methods:
– Utilized FlowLet, a conditional generative framework that employs flow matching within an invertible 3D wavelet domain to avoid reconstruction artifacts and reduce computational demands.
💬 Research Conclusions:
– FlowLet effectively generates high-fidelity MRI volumes with minimal sampling steps and enhances brain age prediction models by providing diverse data, increasing performance in underrepresented age groups while preserving anatomical structures.
👉 Paper link: https://huggingface.co/papers/2601.05212

20. Can Generalist Agents Automate Data Curation?
🔑 Keywords: Automated data curation, generalist coding agents, Curation-Bench, method-guided exploration, data-selection policy
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Explore whether generalist coding agents can automate the data-curation loop in modern AI development.
🛠️ Research Methods:
– Introduction of Curation-Bench, an agent-centric benchmark allowing command-line access for implementing and submitting data policies to a fixed training/evaluation pipeline.
💬 Research Conclusions:
– Current agents can autonomously compose data-selection policies that outperform strong baselines, but scaffolded method adaptation is required for reliable data research.
👉 Paper link: https://huggingface.co/papers/2606.04261

21.

22. Distilling LLM Feedback for Lean Theorem Proving
🔑 Keywords: Feedback Distillation, self-distillation, token-level supervision, language model, GRPO
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To improve post-training techniques for reasoning models by introducing Feedback Distillation combined with GRPO.
🛠️ Research Methods:
– Feedback Distillation employs token-level supervision and integrates privileged feedback from language models for enhanced training diversity and trajectory generation.
💬 Research Conclusions:
– Feedback Distillation maintains greater diversity and complements GRPO, with superior performance when GRPO is initialized from a Feedback Distillation checkpoint.
– This approach shows promise for enhancing post-training in complex reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2605.30861

23. SparDA: Sparse Decoupled Attention for Efficient Long-Context LLM Inference
🔑 Keywords: SparDA, Sparse attention, KV cache, Forecast projection, AI Systems and Tools
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance long-context LLM inference by addressing KV cache bottlenecks and attention complexity using a novel decoupled sparse attention architecture called SparDA.
🛠️ Research Methods:
– Introduces SparDA architecture with an additional Forecast projection for lookahead selection, reducing selection overhead with one Forecast head per GQA group.
💬 Research Conclusions:
– SparDA maintains or improves accuracy, achieving up to 1.25 times prefill speedup and 1.7 times decode speedup over the baseline, enabling larger batch sizes on a single GPU with up to 5.3 times higher decode throughput.
👉 Paper link: https://huggingface.co/papers/2606.04511

24. τ-Rec: A Verifiable Benchmark for Agentic Recommender Systems
🔑 Keywords: Agentic Recommender Systems, Conversational Interfaces, Verifiable Rewards, Reliability Metric, Qwen/Qwen2.5-Coder-32B-Instruct
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces a benchmark, τ-Rec, aimed at evaluating the reliability of agentic recommender systems using verifiable rewards and controlled dialogue constraints.
🛠️ Research Methods:
– The research employs τ-Rec as a benchmark tool to test agents against structured catalog predicates and utilizes a pass^k reliability metric to systematically assess reasoning consistency.
💬 Research Conclusions:
– Findings reveal significant reliability challenges, with the best model achieving only ~57% at pass^1 and ~38% at pass^4, demonstrating a critical gap in current conversational agent deployment.
👉 Paper link: https://huggingface.co/papers/2606.10156

25. Building Social World Models with Large Language Models
🔑 Keywords: Social World Model, temporal pattern mining, social belief dynamics, prediction markets, state-of-the-art results
💡 Category: Foundations of AI
🌟 Research Objective:
– The study introduces the Social World Model (SWM), a framework designed to capture the evolution of social beliefs in response to major events.
🛠️ Research Methods:
– SWM employs temporal pattern mining and evidence lower bound optimization to learn state-transition functions for social beliefs without requiring explicit human annotations.
💬 Research Conclusions:
– SWM significantly outperforms time-series foundation models, achieving state-of-the-art performance on Kalshi data and demonstrating competitive results on Polymarket data.
👉 Paper link: https://huggingface.co/papers/2606.11482

26. APEX: A Network-Native Time-Series Foundation Model for Forecasting and Anomaly Detection for Wireless Edge Operations
🔑 Keywords: Network-native, APEX, Wireless Network Telemetry, Decoder-Only Transformer, Privacy-Preserving Inference
💡 Category: Machine Learning
🌟 Research Objective:
– To present APEX, a network-native, decoder-only transformer model for forecasting enterprise access point (AP) telemetry and evaluate its performance on DHCP degradation tasks.
🛠️ Research Methods:
– Pre-training of APEX on 10-channel multivariate telemetry from approximately 4,500 production wireless networks, with evaluation against existing foundation models and traditional methods.
💬 Research Conclusions:
– APEX-Large outperforms existing models by reducing MAE by 18% over the best foundation-model baseline and 38% over SARIMA on a 192-step DHCP degradation benchmark. APEX-Edge offers sub-second, privacy-preserving inference, suggesting the practicality of network-native pre-training for proactive wireless operations.
👉 Paper link: https://huggingface.co/papers/2606.11553

27. Adaptive Multi-Resolution Procedural Knowledge Compression for Large Language Models
🔑 Keywords: Large language models, procedural knowledge, skill compression
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces SKIM, an adaptive multi-resolution soft token compression framework, aiming to efficiently compress procedural skills while maintaining task performance in Large language model (LLM) applications.
🛠️ Research Methods:
– SKIM adapts to various skill complexities by creating different numbers of soft tokens to improve the efficiency of LLM inference and preserve the effectiveness of skill usage.
💬 Research Conclusions:
– SKIM effectively reduces the token length of procedural skills to 30-60% of their original size while preserving task performance better than existing methods. The authors have made their code available publicly.
👉 Paper link: https://huggingface.co/papers/2606.12203

28. DRIFT: A Residual Flow Adapter for Decoding Continuous Outputs in Vision-Language Models
🔑 Keywords: DRIFT, vision-language models, continuous decoding, flow matching, robotic control
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces DRIFT, a framework aimed at improving pretrained vision-language models for continuous decoding tasks by integrating coarse prediction with iterative refinement through flow matching.
🛠️ Research Methods:
– DRIFT employs a base predictor coupled with a generative refinement module using flow matching to iteratively enhance predictions, transforming the generative modeling problem to localize around a strong prior.
💬 Research Conclusions:
– DRIFT consistently outperforms existing regression- and generative-based solutions in perception and planning tasks, such as visual grounding and robotic control, across multiple architectures.
👉 Paper link: https://huggingface.co/papers/2606.05758
29. Fine-tuning Multi-modal LLMs with ART: Art-based Reinforcement Training
🔑 Keywords: ART, Parameter-Efficient Fine-Tuning, LoRA, Computational Graphs, Multimodal Large Language Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enable parameter-efficient fine-tuning of frozen multimodal language models by optimizing raw visual inputs through gradient backpropagation.
🛠️ Research Methods:
– Introduced ART (Art-based Reinforcement Training) for injecting information into a frozen Multimodal Large Language Model by optimizing its raw visual input without altering precompiled computational graphs.
💬 Research Conclusions:
– ART demonstrates performance comparable to LoRA, achieving competitive accuracy across various benchmarks, especially in mathematics and structured-tool-use scenarios.
👉 Paper link: https://huggingface.co/papers/2606.11854

30. POISE: Position-Aware Undetectable Skill Injection on LLM Agents
🔑 Keywords: POISE, Skill-Poisoning Attack, LLM Scanners, Attack Success Rate, Context-Aware Generator
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective of this research is to introduce and evaluate POISE, a stealthy skill-poisoning attack that embeds malicious triggers within benign-looking instructions to maintain high attack success rates while avoiding detection.
🛠️ Research Methods:
– The research used position-aware skill-poisoning attacks blended with context-aware generation to evaluate the detection success rates, leveraging established frameworks like Skill-Inject with codex+gpt-5.2.
💬 Research Conclusions:
– POISE achieved an 89.3% Attack Success Rate, outperforming both random body placement and YAML-only baselines, while retaining stealth advantages. Its design minimizes detection by LLM scanners, which tend to mistakenly flag benign skills.
👉 Paper link: https://huggingface.co/papers/2606.07943

31. Breaking the Bubble: Asynchronous Pipeline Parallel Training with Bounded Weight Inconsistency
🔑 Keywords: PACI, asynchronous pipeline, gradient accumulation, training throughput, stability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance the efficiency of asynchronous pipeline training for large neural networks by controlling weight inconsistency, improving throughput and training time-to-accuracy without compromising stability.
🛠️ Research Methods:
– Introduced PACI, a method using local gradient accumulation as a version-control mechanism to manage forward/backward weight inconsistency in pipelines without needing weight stashing or global synchronization.
💬 Research Conclusions:
– PACI achieves similar stability and memory usage as synchronous pipelines while significantly increasing training throughput and reducing time-to-accuracy by up to 1.69 times compared to traditional methods, demonstrating that carefully controlled inconsistency can enhance training efficiency.
👉 Paper link: https://huggingface.co/papers/2606.07881

32. Verifiable Environments Are LEGO Bricks: Recursive Composition for Reasoning Generalization
🔑 Keywords: Recursive Automated Composition, Reinforcement Learning, Verifiable Environments, Large Language Models, Recursive Composition
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance the reasoning capabilities of Large Language Models through a framework that enables scalable reinforcement learning by compositing verifiable environments.
🛠️ Research Methods:
– Introduction of RACES, a framework utilizing compositional operators to automatically combine 300 verifiable environments, focusing on recursive composition methods.
💬 Research Conclusions:
– RACES improves reasoning generalization, achieving better performance metrics for models such as DeepSeek-R1-Distill-Qwen-14B and Qwen3-14B on six benchmarks while maintaining efficiency in environment utilization.
👉 Paper link: https://huggingface.co/papers/2606.12373

33. EvoTrainer: Co-Evolving LLM Policies and Training Harnesses for Autonomous Agentic Reinforcement Learning
🔑 Keywords: EvoTrainer, Autonomous LLM Training, Empirical Feedback, Reusable Skills, Diagnostics
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To demonstrate the superior performance of EvoTrainer in evolving language model policies and training harnesses autonomously through empirical feedback, surpassing traditional handcrafted methods.
🛠️ Research Methods:
– EvoTrainer autonomously co-evolves LLM policies and training harnesses by diagnosing rollout-level evidence, revising diagnostics, backtesting interventions, and accumulating reusable skills.
💬 Research Conclusions:
– EvoTrainer matches or exceeds human-engineered RL references, especially in long-horizon agentic software engineering tasks, by preventing invalid high-scoring branches and shaping later strategies through reusable skills.
👉 Paper link: https://huggingface.co/papers/2606.03108

34. Reroute, Don’t Remove: Recoverable Visual Token Routing for Vision-Language Models
🔑 Keywords: Vision-language models, visual tokens, token reduction, grounding-sensitive queries, Reroute
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve grounding performance in vision-language models by employing recoverable routing instead of irreversible visual-token pruning.
🛠️ Research Methods:
– Introduced a training-free plug-in called Reroute, where selected vision tokens bypass certain stages only to re-enter later, using existing attention-score ranking rules to enhance performance.
💬 Research Conclusions:
– Reroute improves grounding performance under aggressive token reduction while maintaining general VQA performance, suggesting a shift in VLM token reduction perspective from irreversible pruning to recoverable routing.
👉 Paper link: https://huggingface.co/papers/2606.12412

35. Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling
🔑 Keywords: Reinforcement Learning, Multi-Token Prediction, Model Entropy, Probabilistic Rejection Sampling, TV Loss
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to address efficiency bottlenecks in reinforcement learning training for large language models by optimizing multi-token prediction techniques.
🛠️ Research Methods:
– The authors conducted a systematic study on Multi-Token Prediction (MTP) in post-training of large language models, applying entropy-aware sampling and novel training objectives to improve acceptance rates and inference throughput.
💬 Research Conclusions:
– The proposed novel end-to-end TV loss optimizes the multi-step rejection sampling acceptance rate, achieving significant improvements in acceptance rates and inference throughput across various tasks. Experimental results demonstrate the methodology achieves up to 1.8x acceleration in async RL training.
👉 Paper link: https://huggingface.co/papers/2606.12370

36. Grammar-Constrained Decoding Can Jailbreak LLMs into Generating Malicious Code
🔑 Keywords: Grammar-Constrained Decoding, CodeSpear, CodeShield, Large Language Models, Jailbreak Attack
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to uncover the risks associated with Grammar-Constrained Decoding (GCD) in code generation by exposing its potential as an attack surface and proposes a solution to mitigate these risks.
🛠️ Research Methods:
– The study reveals a new jailbreak attack called CodeSpear that exploits GCD to induce Large Language Models into generating malicious code. It further introduces CodeShield, a safety alignment approach to counteract this vulnerability effectively.
💬 Research Conclusions:
– Experiments demonstrate that CodeSpear significantly increases the attack success rate, revealing inherent risks in GCD. Conversely, CodeShield is shown to restore safety while maintaining benign functionality, emphasizing the need for attention to GCD’s security implications.
👉 Paper link: https://huggingface.co/papers/2606.11817

37. On Subquadratic Architectures: From Applications to Principles
🔑 Keywords: xLSTM, Sequence Modeling, Memory Dynamics, State Tracking, Gating Scheme
💡 Category: Machine Learning
🌟 Research Objective:
– To compare the efficiency and effectiveness of three sequence modeling approaches: xLSTM, Mamba-2, and Gated DeltaNet, particularly focusing on tasks with complex dependencies.
🛠️ Research Methods:
– The models were evaluated across multiple scenarios: code-model pre-training, code model distillation from large language models, and pre-training of time-series foundation models, with additional analysis on synthetic length-generalization tasks.
💬 Research Conclusions:
– xLSTM outperforms Mamba-2 and Gated DeltaNet due to its superior state tracking and memory dynamics, providing more flexible and stable memory correction via its gating scheme.
👉 Paper link: https://huggingface.co/papers/2606.12364

38. DeNovoSWE: Scaling Long-Horizon Environments for Generating Entire Repositories from Scratch
🔑 Keywords: DeNovoSWE, whole-repository generation, sandboxed agentic workflow, divide and conquer, Qwen3-30B-A3B
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce DeNovoSWE, a large-scale dataset designed for training code agents to generate entire software repositories from documentation, aiming to enhance long-horizon software engineering tasks.
🛠️ Research Methods:
– The dataset is created using a sandboxed agentic workflow for automated construction, employing a “divide and conquer” approach combined with a critic-repair philosophy and incorporating a difficulty-aware trajectory filtering strategy for quality assurance.
💬 Research Conclusions:
– Fine-tuning the Qwen3-30B-A3B model on DeNovoSWE significantly boosts its performance on complex software engineering benchmarks, notably raising the score from 5.8% to 47.2% on the BeyondSWE-Doc2Repo benchmark.
👉 Paper link: https://huggingface.co/papers/2606.10728

39. TRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders
🔑 Keywords: TRL-Bench, Tabular Representation Learning, Tabular Encoders, End-to-End Pipelines, Data-Lake Table Enrichment
💡 Category: Machine Learning
🌟 Research Objective:
– The paper aims to establish a standardized benchmark called TRL-Bench that evaluates tabular representation learning models across different granularities and task types.
🛠️ Research Methods:
– The methodology involves exporting row, column, or table embeddings and testing them with lightweight probes across TRL-CTbench, TRL-Rbench, and TRL-DLTE for comprehensive assessment in a cross-paradigm context.
💬 Research Conclusions:
– TRL-Bench reveals that tabular encoder performance is capability-specific and cannot be solely evaluated through single leaderboard rankings, emphasizing the need for compatibility in downstream task conditions.
👉 Paper link: https://huggingface.co/papers/2606.09323

40. Claw-SWE-Bench: A Benchmark for Evaluating OpenClaw-style Agent Harnesses on Coding Tasks
🔑 Keywords: Claw-SWE-Bench, OpenClaw, adapter protocol, coding agents, SWE-bench
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces Claw-SWE-Bench, a new benchmark and adapter protocol, to enable fair comparison and enhance performance evaluation of diverse coding agents, particularly emphasizing the significance of adapter design.
🛠️ Research Methods:
– The protocol standardizes evaluation conditions with a focus on fair settings, utilizing a comprehensive 350 GitHub issue instance benchmark across 8 languages and introducing a lite version for expedited validation.
💬 Research Conclusions:
– Results demonstrate that the adapter design is critical; with the right adapter, coding agents like OpenClaw can significantly boost performance from 19.1% to 73.4% Pass@1 score, stressing the importance of harness choice and cost considerations in the evaluation.
👉 Paper link: https://huggingface.co/papers/2606.12344

41. Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
🔑 Keywords: Autonomous scientific research, AI framework, Hypothesis Tree Refinement, Iterative experimentation, Autonomous Optimization
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To explore how an AI agent can autonomously facilitate scientific research by coordinating and executing hypothesis tests while maintaining a knowledge tree that refines research over time.
🛠️ Research Methods:
– Introduction of Arbor, an AI framework that consists of a long-lived coordinator and short-lived executors to manage and test hypotheses, respectively, employing Hypothesis Tree Refinement for strategic research evolution.
💬 Research Conclusions:
– Arbor demonstrates significant improvements in six research tasks across model training, harness engineering, and data synthesis, achieving superior results compared to Codex and Claude Code with notable gains in efficiency and outcome quality.
👉 Paper link: https://huggingface.co/papers/2606.11926