AI Native Daily Paper Digest – 20260612

1. EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
🔑 Keywords: EvoArena, EvoMem, memory evolution, dynamic environments
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the challenge of dynamic environments in Large Language Model (LLM) agents through the development of EvoArena and EvoMem.
🛠️ Research Methods:
– Introduce EvoArena, a benchmark suite modeling environment changes to evaluate LLM agents’ performance in dynamic settings.
– Propose EvoMem, a memory paradigm that uses structured update histories for agents to reason about environmental evolution.
💬 Research Conclusions:
– EvoMem enhances agent performance on EvoArena and other standard benchmarks, improving chain-level accuracy and memory evidence capture.
– The findings underscore the necessity of modeling evolution in both evaluation and memory for effective agent deployment.
👉 Paper link: https://huggingface.co/papers/2606.13681

2. MiniMax Sparse Attention
🔑 Keywords: MiniMax Sparse Attention, Ultra-long-context capability, Blockwise sparsity, GPU execution, Grouped Query Attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enable efficient processing of ultra-long contexts in large language models while maintaining performance and achieving significant speedups.
🛠️ Research Methods:
– Introduction of MiniMax Sparse Attention (MSA), employing blockwise sparsity based on Grouped Query Attention, with an optimized GPU execution path via exp-free Top-k selection and KV-outer sparse attention.
💬 Research Conclusions:
– The implementation of MSA achieves major reductions in per-token attention computation and significant wall-clock speedups for both prefill and decoding, maintaining performance on par with existing methods.
👉 Paper link: https://huggingface.co/papers/2606.13392

3. Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?
🔑 Keywords: Multimodal Large Language Models, visual corruptions, robustness enhancement, visual self-recovery, reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to assess whether Multimodal Large Language Models (MLLMs) can autonomously recover corrupted visual content to enhance both visual quality and reasoning performance.
🛠️ Research Methods:
– The approach consists of three core stages: supervised fine-tuning for initial reconstruction, reinforcement learning with dual rewards for high visual quality alignment, and multimodal reasoning considering both corrupted and recovered images.
💬 Research Conclusions:
– Robust-U1 achieves state-of-the-art robustness on real-world corruption benchmarks, demonstrating that self-recovery is a critical mechanism for robust visual understanding, and effectively maintains performance under adversarial corruptions on general VQA benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.08063

4. MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
🔑 Keywords: test-time scaling, mathematical proof, population-level search, tournament selection, proof generation
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– MaxProof aims to enhance mathematical proof generation by integrating multiple proof-oriented capabilities and employing a population-level search with tournament selection for high-level mathematical competitions.
🛠️ Research Methods:
– The study utilizes a framework named MaxProof in the MiniMax-M3 series, which includes training three proof capabilities—generation, verification, and repair—using a generative verifier with low false positives. MaxProof employs these capabilities for generating, verifying, refining, and ranking proofs at test time.
💬 Research Conclusions:
– The MaxProof framework achieves impressive results by scoring 35/42 on IMO 2025 and 36/42 on USAMO 2026, surpassing the human gold-medal threshold, demonstrating its competitive performance in high-level mathematical competitions.
👉 Paper link: https://huggingface.co/papers/2606.13473

5. LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
🔑 Keywords: Vision-Language-Action (VLA), Laboratory Automation, AI Systems, RoboGenesis, LabVLA
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a vision-language-action (VLA) model, named LabVLA, that bridges the gap between AI systems and laboratory automation tasks through a two-stage training approach.
🛠️ Research Methods:
– Utilization of a two-stage approach combining FAST action token pretraining and flow matching.
– Development of RoboGenesis, a simulation-based workflow and data engine for generating structured demonstrations in laboratory environments.
💬 Research Conclusions:
– LabVLA achieves superior performance and the highest success rate on the LabUtopia benchmark compared to other baselines, demonstrating its effectiveness in both in-distribution and out-of-distribution scenarios.
👉 Paper link: https://huggingface.co/papers/2606.13578

6. N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
🔑 Keywords: N-GRPO, Large Language Models, Mathematical Reasoning, Semantic Neighbor Mixing, Group Relative Policy Optimization
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance mathematical reasoning capabilities in large language models by developing the N-GRPO exploration strategy within the GRPO framework.
🛠️ Research Methods:
– Utilization of Semantic Neighbor Mixing to mix embeddings of anchor tokens with their nearest semantic neighbors, avoiding traditional token-level sampling or embedding-level noise.
💬 Research Conclusions:
– N-GRPO consistently improves performance on mathematical reasoning benchmarks and demonstrates strong generalization on out-of-distribution tasks.
👉 Paper link: https://huggingface.co/papers/2606.10768

7. Demystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning
🔑 Keywords: switchable latent reasoning, latent chain-of-thought, on-policy reinforcement learning, mechanistic analysis, GRPO policy ratio
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop a switchable latent reasoning framework known as SWITCH which utilizes explicit boundary tokens to optimize latent reasoning using on-policy reinforcement learning.
🛠️ Research Methods:
– Employed a visible-to-latent curriculum and a Switch-GRPO objective to propagate gradients through latent computation, and used discrete entry and exit tokens to facilitate mechanistic analysis.
💬 Research Conclusions:
– SWITCH surpasses previous models in latent reasoning efficiency and interpretability, revealing that the switching policy is localized and problem-specific, and that computation is focused at the entry transition on hidden-state recurrence.
👉 Paper link: https://huggingface.co/papers/2606.13106

8. Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
🔑 Keywords: Structured Defect Grounding, text-to-image models, Vision-Language Model, structured set prediction, defect diagnosis
💡 Category: Generative Models
🌟 Research Objective:
– To address the limitations in diagnosing text-to-image model defects by using Structured Defect Grounding to improve defect detection and alignment through structured set prediction.
🛠️ Research Methods:
– Introduces SDG-30K, a dataset with box-grounded annotations, and SDG-Eval, a dedicated evaluation protocol.
– Utilizes a Vision-Language Model as the SDG detector, converting predicted defects into importance-weighted rewards for model alignment.
💬 Research Conclusions:
– The SDG detector outperforms leading proprietary Vision-Language Models in defect grounding.
– SDG-guided rewards improve text-to-image model alignment and support localized image refinement, establishing SDG as a robust diagnostic tool for generative models.
👉 Paper link: https://huggingface.co/papers/2606.06113

9. MoVerse: Real-Time Video World Modeling with Panoramic Gaussian Scaffold
🔑 Keywords: MoVerse, real-time interactive video, 3D Gaussian scaffold, diffusion-based techniques, AI Native
💡 Category: Computer Vision
🌟 Research Objective:
– To create a real-time video world model from a single narrow-field-of-view image, enabling interactive and photorealistic scene navigation.
🛠️ Research Methods:
– Separation of world construction from observation rendering.
– Expansion into a 360° panorama using topology-aware diffusion.
– Creation of persistent 3D Gaussian scaffolds with geometry-aware prediction.
– Gaussian-conditioned rendering for photorealistic video along user-specified trajectories.
💬 Research Conclusions:
– MoVerse supports real-time scene roaming at 8 FPS on a single NVIDIA RTX 4090 GPU, presenting a practical approach for interactive video output from single images.
👉 Paper link: https://huggingface.co/papers/2606.13376
10. TreeSeeker: Tree-Structured Trial, Error, and Return in Deep Search
🔑 Keywords: TreeSeeker, Deep Search, Branch-And-Return, Trial-And-Error, Textual UCB Signals
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study introduces **TreeSeeker**, an inference-time framework designed to enhance exploration and exploitation in deep search tasks through systematic trial-and-error decision making.
🛠️ Research Methods:
– TreeSeeker employs a **tree-structured search** approach with branch-and-return control, utilizing textual UCB signals to make informed decisions regarding exploration, exploitation, and pruning within search tasks.
💬 Research Conclusions:
– Experiments conducted on XBench-DeepSearch, BrowseComp, and BrowseComp-ZH demonstrate that TreeSeeker surpasses existing open-source baselines, indicating its potential to improve reasoning and optimization in search processes.
👉 Paper link: https://huggingface.co/papers/2606.11662

11. Risk Under Pressure: Compute-Aware Evaluation of Adversarial Robustness in Language Models
🔑 Keywords: Adversarial robustness, large language models, alignment training, attack success rate, computational pressure
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to develop a compute-aware evaluation framework for assessing adversarial robustness in large language models (LLMs), primarily using computational pressure metrics such as FLOPs.
🛠️ Research Methods:
– Introduction of risk-compute curves to map compute budgets to attack risk, deriving metrics to measure average adversarial effort.
– Evaluation across ten models covering three families and four training stages, utilizing three distinct attack strategies.
💬 Research Conclusions:
– Alignment training results in non-monotonic impacts on robustness within compute-space.
– Model size scaling diminishes the effectiveness of gradient-based attacks but not of template-based attacks.
– Gradient-based attacks can be efficiently transferred across different models using surrogate models.
– Compute costs vary significantly across harm categories within the same model.
– Implementation of safety-aligned reinforcement learning increases overall costs while leaving certain harm categories overly exposed.
👉 Paper link: https://huggingface.co/papers/2606.11409

12. SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
🔑 Keywords: Sign-Gated On-Policy Distillation, On-Policy Distillation, binary verifier, mathematical reasoning tasks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Improve the standard On-Policy Distillation method by incorporating a binary verifier to enhance performance on mathematical reasoning tasks.
🛠️ Research Methods:
– Implement Sign-Gated On-Policy Distillation (SG-OPD), using a binary verifier as a trust signal at both phased teacher sampling and sign-consistency gate levels.
💬 Research Conclusions:
– SG-OPD consistently outperforms standard On-Policy Distillation, achieving significant performance gains on mathematical reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.09304

13. EvoBrowseComp: Benchmarking Search Agents on Evolving Knowledge
🔑 Keywords: EvoBrowseComp, contamination-free, temporal freshness, automated synthesis, reasoning graphs
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces EvoBrowseComp, an evolving benchmark designed to provide contamination-free evaluation of search agents, maintaining temporal freshness and preventing parametric memorization.
🛠️ Research Methods:
– A collaborative framework involving three agents: a QA synthesis agent, an information filtering agent, and a high-level guidance agent generates complex questions via live-web traversal to ensure up-to-date content and block reasoning shortcuts.
💬 Research Conclusions:
– EvoBrowseComp demonstrates a high difficulty level, requiring broad horizontal search, and establishes a scalable paradigm for continuously updatable benchmarks aligned with evolving world knowledge and agent capabilities.
👉 Paper link: https://huggingface.co/papers/2606.13120

14. ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages
🔑 Keywords: ArogyaBodha, ArogyaSutra, multilingual medical reasoning, low-resource settings, actor-critic framework
💡 Category: AI in Healthcare
🌟 Research Objective:
– The main objective is to enhance multilingual medical reasoning in low-resource settings, particularly in multilingual and rural areas like India, through the integration of diverse data and advanced frameworks.
🛠️ Research Methods:
– The study integrates an actor-critic-based multi-agent framework with tool grounding and dual-memory mechanisms. It employs a large-scale, multilingual, and multimodal dataset, ArogyaBodha, constructed from multiple sources and languages, to improve decision-making accuracy in medical reasoning.
💬 Research Conclusions:
– The findings reveal that the ArogyaBodha dataset and ArogyaSutra framework significantly improve medical reasoning accuracy in all studied Indic languages. The experiments and ablations validate the effectiveness and contribution of each component, enhancing equitable access to AI-driven healthcare.
👉 Paper link: https://huggingface.co/papers/2606.13572

15. Rethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
🔑 Keywords: Theory of Planned Behavior, Self-Reports, Big 5, Coherence, Implicit Bias
💡 Category: Natural Language Processing
🌟 Research Objective:
– To assess the coherence of LLM (Large Language Models) behavior using specific frameworks like the Theory of Planned Behavior compared to broad personality traits such as the Big 5.
🛠️ Research Methods:
– Conducted experiments across four behavioral tasks on 11 frontier LLMs, considering session context and identity induction to determine behavior predictability.
💬 Research Conclusions:
– Theory of Planned Behavior shows human-level coherence within shared conversations; Big 5 does not.
– Coherence persists for behaviors anchored outside the immediate prompt but collapses when strongly primed.
– Persona prompting enhances self-report consistency but does not align LLM behavior with these reports, highlighting the need for task-specific evaluation frameworks.
👉 Paper link: https://huggingface.co/papers/2606.12730

16. MuJoCo-Drones-Gym: A GPU-Accelerated Multi-Drone Simulator for Control and Reinforcement Learning
🔑 Keywords: Gymnasium-compatible, MuJoCo physics engine, multi-drone environment, reinforcement learning, robotics simulators
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop and present MuJoCo-Drones-Gym, an open-source, Gymnasium-compatible multi-drone simulation environment built on the MuJoCo physics engine, supporting flexible physics models, action interfaces, and observation spaces for reinforcement learning applications.
🛠️ Research Methods:
– Leveraging the MuJoCo physics engine to create a dynamic simulation environment that supports an arbitrary number of Bitcraze Crazyflie 2.x nano-quadcopters.
– Providing a modular API to choose between different physics models, action interfaces, and observation spaces.
– Using a PettingZoo ParallelEnv wrapper for multi-agent reinforcement learning with diverse task environments.
💬 Research Conclusions:
– MuJoCo-Drones-Gym addresses the trade-offs in existing quadcopter learning environments by offering improved physical fidelity, multi-agent support, and throughput for modern deep reinforcement learning pipelines.
– The environment design and its flexible APIs enhance the development of control algorithms and the training of reinforcement learning policies for aerial robotics.
👉 Paper link: https://huggingface.co/papers/2606.08039

17. PianoKontext: Expressive Performance Rendering from Deadpan Context
🔑 Keywords: Expressive Performance Rendering, Flow Matching, Latent Space, Dynamic Time Warping, MIDI Scores
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to generate realistic and expressive classical piano performances by synchronizing MIDI scores and audio within a latent space.
🛠️ Research Methods:
– Utilizes Dynamic Time Warping (DTW) in latent space, combined with DiT blocks, to align MIDI scores with audio and prepare paired training data.
💬 Research Conclusions:
– Introduces PianoKontext, a model capable of rendering variable-length piano performances, effectively learning dependencies between scores and performances using a pretrained Music2Latent model.
👉 Paper link: https://huggingface.co/papers/2606.12282

18. Getting Better at Working With You: Compiling User Corrections into Runtime Enforcement for Coding Agents
🔑 Keywords: Interactive LLM agents, TRACE, Runtime checks, User corrections, Preference compliance
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The study addresses the gap between preference access and preference compliance in interactive LLM agents by using a skill-layer pipeline named TRACE to mine user corrections and create runtime checks.
🛠️ Research Methods:
– The implementation of TRACE involves Test-time Rule Acquisition and Compiled Enforcement to transform user corrections into atomic rules for runtime checks. Experiments were conducted using simulated user-in-the-loop processes on ClawArena and MemoryArena-derived tasks.
💬 Research Conclusions:
– TRACE effectively reduces preference violations significantly, from 100% to 37.6% in-distribution and 2.0% out-of-distribution for ClawArena tasks, and from 100% to 60.5% for MemoryArena-derived tasks, surpassing memory baselines. This indicates that runtime enforcement of corrections can mitigate repeated-friction failures better than memory alone.
👉 Paper link: https://huggingface.co/papers/2606.13174

19. The Cold-Start Safety Gap in LLM Agents
🔑 Keywords: cold-start safety gap, tool-calling LLM agents, safety benchmarks, agentic tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the safety dynamics of tool-calling language model (LLM) agents during conversations and assess how safety improves after initial interactions.
🛠️ Research Methods:
– The authors introduced a systematic benchmark called Safety Over Depth for Agents (SODA) to measure safety improvement as regular agentic tasks increase, evaluating 7 models across 4 families.
💬 Research Conclusions:
– The research concludes that agents show a safety improvement ranging from 9-52% with more agentic tasks. Regular agentic tasks are the main drivers of safety enhancement, mitigating the cold-start safety gap. A recommended strategy involves pre-exposing agents to regular tasks to enhance safety before handling critical requests.
👉 Paper link: https://huggingface.co/papers/2606.07867

20. Flash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
🔑 Keywords: Flash-GMM, Triton kernel, Gaussian Mixture Models, ANN search, k-means replacement
💡 Category: Machine Learning
🌟 Research Objective:
– Develop an efficient Triton kernel for Gaussian Mixture Models that significantly improves computation speed and enables processing larger datasets on a single GPU.
🛠️ Research Methods:
– Elimination of full responsibility matrix materialization in GPU memory to increase speed and dataset capacity.
– Integration of Flash-GMM into IVF coarse quantizer for efficient approximate nearest-neighbor search.
💬 Research Conclusions:
– Achieved a 20 times speedup over existing implementations and enabled training on datasets more than 100 times larger on one device.
– Demonstrated that soft GMM clustering is a viable alternative to k-means, reducing distance computations and improving recall efficacy.
– Released the kernel as an open-source project for further application and development.
👉 Paper link: https://huggingface.co/papers/2606.10896

21. A Stationary (and Therefore Compatible) Representation is All You Need
🔑 Keywords: stationary representations, d-Simplex fixed classifiers, compatibility, cross-entropy loss, contrastive loss
💡 Category: Machine Learning
🌟 Research Objective:
– The primary goal is to demonstrate the benefits of learning stationary representations through d-Simplex fixed classifiers to ensure model compatibility during sequential fine-tuning and updates.
🛠️ Research Methods:
– The study explores aligning feature distributions using a d-Simplex fixed classifier with cross-entropy loss and demonstrates the advantages of using a convex combination of cross-entropy and contrastive loss to capture higher-order dependencies.
💬 Research Conclusions:
– The research confirms that stationary representations enable uninterrupted retrieval services while enhancing performance during model updates and replacements, achieving state-of-the-art results.
👉 Paper link: https://huggingface.co/papers/2606.12488

22. Revisiting Articulated Parts Perception in Robot Manipulation
🔑 Keywords: Geometric Primary Structure, articulated parts perception, Virtual Reality, RGB-D, heuristic policy
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce the Geometric Primary Structure (GPS) to improve articulated parts perception for robotic manipulation.
🛠️ Research Methods:
– Utilized a portable VR device for efficient data collection, taking one minute to annotate an object sequence, and trained a GPS model with a single RGB-D object image.
💬 Research Conclusions:
– Achieved a 73% success rate in object manipulation using a heuristic policy based on GPS prediction, demonstrating high efficacy without in-domain fine-tuning.
👉 Paper link: https://huggingface.co/papers/2606.08103

23.

24. On the Limits of LLM Adaptability: Impact of Model-Internalized Priors on Annotation Task Performance
🔑 Keywords: Large Language Models, zero-shot errors, Definition-Specific Familiarity, decision stickiness, misaligned task definitions
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate how model-internalized priors and user-provided instructions interact in LLMs, focusing on their ability to correct zero-shot errors.
🛠️ Research Methods:
– Experiments conducted on toxicity detection across diverse datasets with dense and mixture-of-experts models to assess correction of zero-shot errors.
💬 Research Conclusions:
– Nearly two-thirds of zero-shot errors are resistant to correction, with a rescue rate of only 34.8%. High-confidence errors are especially resistant. Definition-Specific Familiarity positively affects performance, highlighting its importance over text-level memorization.
👉 Paper link: https://huggingface.co/papers/2606.00467

25. Leveraging Morphology for Historical Script Metrological Analysis
🔑 Keywords: Transformer-based architecture, prototype learning, paleographic measurements, line-level transcription, historical documents
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a transformer-based architecture with prototype learning that enables scalable and meaningful paleographic measurements from historical manuscripts using minimal data requirements.
🛠️ Research Methods:
– Utilization of a prototype-based line reconstruction module and transformer-based detection architecture to learn and analyze prototypical characters and their variations from line-level transcriptions.
💬 Research Conclusions:
– The introduced deep architecture effectively improves character modeling and paleographic measurement, as demonstrated on a 160-page codex with minimal annotations. The approach allows for accurate character bounding box prediction and visual differentiation of graphical profiles, highlighting subtle variations, with the results being applicable even with sparse training data.
👉 Paper link: https://huggingface.co/papers/2606.09446

26. WebChallenger: A Reliable and Efficient Generalist Web Agent
🔑 Keywords: WebChallenger, Autonomous web navigation, PageMem, Cognitive-inspired mechanisms, Open-weight models
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The main objective of the research is to enhance autonomous web navigation by developing a framework, WebChallenger, which utilizes structured page representation and cognitive-inspired mechanisms to improve performance without the need for large proprietary models.
🛠️ Research Methods:
– The study introduces PageMem, a structured page representation constructed from the DOM, facilitating a hierarchy of semantic sections. It employs mechanisms like a divide-and-conquer observation pipeline, an exploration and memory system, and compound action workflows to replicate human cognitive advantages.
💬 Research Conclusions:
– WebChallenger achieves significant performance on multiple benchmarks, approaching proprietary systems at much lower inference costs. It demonstrates the viability of using open-weight models to achieve high performance across various websites without requiring site-specific adaptations.
👉 Paper link: https://huggingface.co/papers/2606.10423

27. ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs
🔑 Keywords: parametric tool retrieval, Large Language Models, ToolBench, ToolSense, embedding-based retrieval
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address the performance gap in parametric tool retrieval models when dealing with realistic ambiguous queries, compared to standard benchmarks.
🛠️ Research Methods:
– Introduction of ToolSense, an open-source LLM-powered diagnostic framework that generates three benchmarks to evaluate tool retrieval: Realistic Retrieval Benchmark (RRB), MCQ probing, and QA probing.
💬 Research Conclusions:
– Several parametric model configurations significantly underperform on RRB queries, demonstrating a knowledge-retrieval dissociation.
– Despite high retrieval performance on standard benchmarks, some models fail on factual probes, suggesting a lack of true tool comprehension.
👉 Paper link: https://huggingface.co/papers/2606.12451

28. IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
🔑 Keywords: representation autoencoders, deep learning frameworks, visual fidelity, discrete representation autoencoding, autoregressive image generation
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance image reconstruction quality by developing an In-depth Alignment framework for discrete representation autoencoding that combines shallow and deep visual feature representations.
🛠️ Research Methods:
– Implementation of the Ideal framework that aligns quantized tokens with both shallow and deep VFM features to maintain visual fidelity and rich semantics.
💬 Research Conclusions:
– The Ideal framework significantly improves reconstruction performance with an rFID of 0.61 on ImageNet, outperforming existing methods, and sets a new benchmark in autoregressive image generation with a gFID of 1.89.
👉 Paper link: https://huggingface.co/papers/2606.11096

29. WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
🔑 Keywords: WEAVER, robotic manipulation, flow-matching loss, world models, policy evaluation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to develop a multi-view world model architecture, WEAVER, that achieves high fidelity, consistency, and efficiency in robotic manipulation tasks.
🛠️ Research Methods:
– WEAVER employs a flow-matching loss to train its model, focusing on predicting future latents and reward values across various views.
💬 Research Conclusions:
– WEAVER shows superior performance in policy evaluation, policy improvement, and test-time planning, achieving state-of-the-art results in robotic manipulation tasks and demonstrating better performance in out-of-distribution scenarios compared to previous world models.
👉 Paper link: https://huggingface.co/papers/2606.13672

30. See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents
🔑 Keywords: Heterogeneous multi-agent systems, KV-cache communication, cross-model latent alignment, dense alignment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To investigate whether heterogeneous agents can achieve effective knowledge transfer and alignment for improved communication performance.
🛠️ Research Methods:
– Utilization of lightweight cross-model cache transformation and a two-phase training approach consisting of reconstruction followed by generation for dense alignment in KV-cache communication.
💬 Research Conclusions:
– The proposed method outperforms previous heterogeneous baselines, maintains effectiveness in context-unaware transfer, and matches or exceeds text communication with significantly reduced computational costs.
👉 Paper link: https://huggingface.co/papers/2606.13594

31. Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
🔑 Keywords: Evoflux, compact language models, evolutionary search, tool workflows, execution feasibility
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to enhance the execution reliability of compact language models in tool workflows using Evoflux, an evolutionary search method.
🛠️ Research Methods:
– Evoflux operates at inference-time, employing evolutionary search to repair failed plans through structured edits, execution feedback, adaptive intensity, meta-guided redesign, and diversity pruning.
💬 Research Conclusions:
– Evoflux significantly improves execution feasibility of compact language models, raising it from approximately 3% to 17-24% on held-out MCP-Bench tasks, compared to other methods like SFT, SFT+DPO, and ReAct.
👉 Paper link: https://huggingface.co/papers/2606.12674

32. Surflo: Consistent 3D Surface Flow Model with Global State
🔑 Keywords: Surflo, latent tokens, flow matching, photometric gradient, feed-forward reconstruction
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces Surflo, a method designed to compress unposed RGB views into latent tokens for flexible 3D surface point decoding with high efficiency and resolution variance.
🛠️ Research Methods:
– The method uses flow matching to decode 3D points and employs an inference-time guidance term to mitigate local inconsistencies, utilizing photometric gradients during the process.
💬 Research Conclusions:
– Surflo provides a substantial improvement over existing feed-forward methods, offering speed advantages over optimization-based approaches and uniquely enabling global latent with flexible resolution output.
👉 Paper link: https://huggingface.co/papers/2606.13644
33. MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
🔑 Keywords: MaskAlign, diffusion transformer, representation alignment, vision models, token-subset representation
💡 Category: Generative Models
🌟 Research Objective:
– To reduce reliance on complete token sets during diffusion transformer training by introducing token-subset representation alignment.
🛠️ Research Methods:
– Developed MaskAlign which applies alignment to randomly sampled token subsets during training.
– Introduced a lightweight pre-mask token mixing block to mitigate information loss from dropping tokens.
💬 Research Conclusions:
– MaskAlign enhances training by maintaining stable alignment behavior under token-subset perturbations.
– It results in more efficient convergence and improved generation quality in diffusion transformers.
👉 Paper link: https://huggingface.co/papers/2606.08788

34. Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
🔑 Keywords: Visual Reasoning, Multi-Agent Framework, Shared MLLM Policy, Hallucination, Role-Specific Training
💡 Category: Computer Vision
🌟 Research Objective:
– To improve visual reasoning by reducing hallucinations and enabling efficient parallel processing using a multi-agent framework.
🛠️ Research Methods:
– Visual Para-Thinker++ framework employing shared MLLM policy instantiated as role-conditioned agents.
– Utilization of Multi-Agent Capability Injection and Role-Decoupled Multi-Agent Optimization for training.
💬 Research Conclusions:
– Visual Para-Thinker++ consistently outperforms existing baselines on hallucination-sensitive visual reasoning tasks across multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.09290

35. HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
🔑 Keywords: HarnessBridge, learnable harness controller, bidirectional projection, long-horizon tasks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To investigate if a harness can be generated by a learnable plug-in module trained in an end-to-end fashion, specifically for enhancing agent-environment interactions.
🛠️ Research Methods:
– HarnessBridge is introduced, a lightweight learnable harness controller that parameterizes agent-environment interfaces through two bidirectional projections: observation projection and action projection. Training is performed using a harness supervision dataset via unified instruction tuning.
💬 Research Conclusions:
– HarnessBridge matches or surpasses existing specialized harnesses in performance while significantly reducing computational overhead and effectively generalizing from smaller generators to larger commercial models.
👉 Paper link: https://huggingface.co/papers/2606.12882

36. High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
🔑 Keywords: Diffusion Distillation, 2-Step Image Generation, Distribution-Aligned Adversarial Learning, Step-Decoupled Parameterization, End-to-End Training
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Z-Image Turbo++, a 2-step image generation model, distilled from an 8-step teacher model, aimed at improving the quality-efficiency of few-step image generation.
🛠️ Research Methods:
– Uses 3 main design choices: Distribution-Aligned Adversarial Learning, Step-Decoupled Parameterization, and End-to-End Training with Iterative Regularization to address the challenges of increased task difficulty and model capacity limitation in 2-step generation.
💬 Research Conclusions:
– The proposed designs effectively reduce the quality gap between 2-step and 8-step image generation, indicating the potential for improved quality-efficiency trade-off with tailored distillation strategies.
👉 Paper link: https://huggingface.co/papers/2606.12575

37. From 2D Grids to 1D Tokens: Reforming Shared Representations for Multimodal Image Fusion
🔑 Keywords: Multimodal image fusion, 1D token interface, Selective Token Editing, global appearance coherence, local structure restoration
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to develop a multimodal image fusion approach that enhances global appearance coherence while preserving local details.
🛠️ Research Methods:
– Utilization of a 1D token interface from a pretrained image tokenizer for modeling non-local appearance/base factors and introduction of Selective Token Editing (STE) to sparingly update critical tokens without altering the fusion backbone.
💬 Research Conclusions:
– Experiments indicate that this method achieves superior performance across multiple benchmarks, offering improvements in global coherence and local fidelity without additional losses.
👉 Paper link: https://huggingface.co/papers/2606.12303

38. VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
🔑 Keywords: Speculative Decoding, Intra-Model Routing, Slim-Verifier, Speedup, Multi-Tier Framework
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce VIA-SD, a multi-tier speculative decoding framework utilizing intra-model routing to reduce verification costs by employing slim submodels.
🛠️ Research Methods:
– Employ lightweight drafters to generate candidates for large verifiers, optimizing token validation processes through a hierarchical approach with a routed slim-verifier.
💬 Research Conclusions:
– VIA-SD significantly lowers rejection rates and enhances speed across multiple tasks, achieving 10-20% speedups compared to strong speculative decoding baselines, offering a general paradigm for scalable and efficient LLM inference.
👉 Paper link: https://huggingface.co/papers/2606.12243

39. VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
🔑 Keywords: VideoMDM, diffusion framework, 3D human motion priors, 2D poses, monocular videos
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to train 3D human motion priors from 2D poses using VideoMDM, achieving near-3D supervised performance without the need for 3D ground truth.
🛠️ Research Methods:
– A diffusion-based framework is introduced that uses 2D reprojection loss and 3D motion regularizers. A pretrained 2D-to-3D lifter provides approximate 3D pose sequences as a noisy teacher to train the model.
💬 Research Conclusions:
– VideoMDM achieves results nearly equivalent to fully 3D-supervised methods and generates motions preferred by humans, proven by strong quantitative results on datasets like HumanML3D, Fit3D, and NBA.
👉 Paper link: https://huggingface.co/papers/2606.13364
40. EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery
🔑 Keywords: Environment engineering, EurekAgent, autonomous scientific discovery, agent environments, reward hacking
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance autonomous scientific discovery through the design of structured agent environments, optimizing behaviors such as exploration and collaboration while mitigating issues like reward hacking.
🛠️ Research Methods:
– Development of EurekAgent, an environment-engineered system using permissions engineering, artifact engineering, budget engineering, and human-in-the-loop engineering to optimize agent behavior in scientific discovery tasks.
💬 Research Conclusions:
– EurekAgent achieves state-of-the-art results across various domains such as mathematics, kernel engineering, and machine learning, with cost-effective use, signifying the importance of environment engineering as a core area for developing reliable autonomous research agents.
👉 Paper link: https://huggingface.co/papers/2606.13662
41. HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
🔑 Keywords: HYDRA-X, Unified Multimodal Models, Vision Transformer, Spatiotemporal Reconstruction, Hierarchical Temporal Compression
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to develop a unified multimodal model, named HYDRA-X, that integrates image and video tokenization using a single Vision Transformer to enhance spatiotemporal reconstruction and semantic awareness.
🛠️ Research Methods:
– The approach involves frame-level causal temporal attention to support visual reconstruction, hierarchical temporal compression for effective processing, and a lightweight decompressor for semantic structuring, with image-video teacher supervision.
💬 Research Conclusions:
– HYDRA-X demonstrates strong performance in image and video understanding and generation tasks, highlighting improvements in editing consistency and convergence speed, and sets a foundation for future unified-tokenizer UMMs.
👉 Paper link: https://huggingface.co/papers/2606.13289

42. WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
🔑 Keywords: Computer-use agents, hybrid-interface benchmark, long-horizon task orchestration, trajectory-aware judge, GUI/CLI operations
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce WeaveBench, a comprehensive benchmark aimed at evaluating the performance of Computer-use agents across multiple interfaces, especially focusing on long-horizon task orchestration.
🛠️ Research Methods:
– Evaluating 114 tasks across 8 real-world domains that require GUI observations/actions combined with CLI/code operations within a single trajectory on a real Ubuntu desktop environment.
– Implementation of a trajectory-aware judge to inspect deliverables and detect shortcut behaviors like fabricated evidence or hard-coded metrics.
💬 Research Conclusions:
– The best PassRate achieved on the benchmark is 41.2%, indicating the challenge in saturating the benchmark.
– The use of outcome-only grading can substantially overestimate agent performance, highlighting the critical gap in CUA evaluation.
– WeaveBench serves as an effective testbed to assess an agent’s ability to orchestrate complex operations across different interfaces.
👉 Paper link: https://huggingface.co/papers/2606.09426

43. FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
🔑 Keywords: Deep Search Agents, Shortcut Risks, FORT, Supervised Fine-Tuning, Shortcut-Resistant Training Data
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study proposes a framework to create shortcut-resistant training data for deep search agents by identifying and mitigating four shortcut risks in data synthesis processes.
🛠️ Research Methods:
– A shortcut-aware difficulty framework is used, identifying risks such as evidence co-coverage and single-clue selectivity. The FORT framework constructs shortcut-resistant data with controlled risks.
💬 Research Conclusions:
– The FORT framework produces longer pre-answer searches and fewer shortcut patterns, achieving superior performance compared to existing deep search datasets on benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.12087

44. InterleaveThinker: Reinforcing Agentic Interleaved Generation
🔑 Keywords: InterleaveThinker, multi-agent pipeline, interleaved generation, planner agent, critic agent
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enable interleaved generation capabilities for image generators through a novel pipeline, enhancing their performance and reasoning abilities.
🛠️ Research Methods:
– A novel multi-agent pipeline is developed using a planner agent to organize image-text sequences and a critic agent to evaluate outputs and refine instructions. Specific models like Interleave-Planner-SFT-80k and Interleave-Critic-SFT-112k are implemented alongside reinforcement learning techniques with GRPO for step-wise instruction correction.
💬 Research Conclusions:
– InterleaveThinker achieves performance comparable to state-of-the-art models such as Nano Banana and GPT-5 in interleaved generation benchmarks. It significantly enhances reasoning-based benchmarks, demonstrating substantial gains in specific tasks.
👉 Paper link: https://huggingface.co/papers/2606.13679

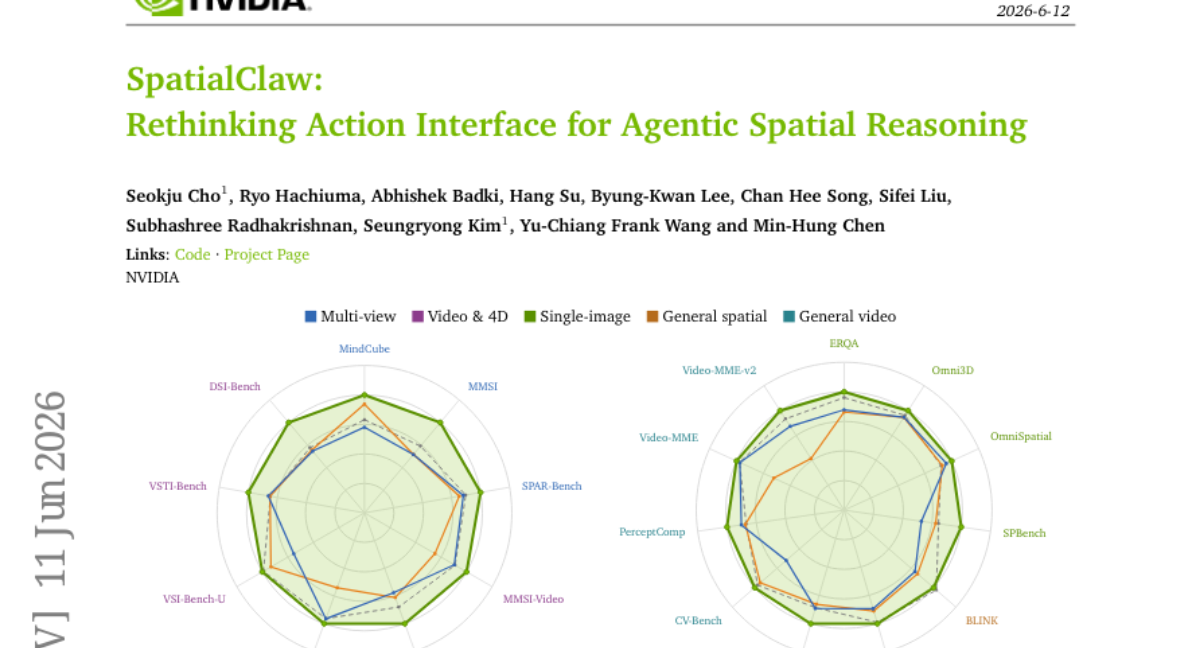
45. SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
🔑 Keywords: SpatialClaw, spatial reasoning, vision-language models, action interface
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To propose a training-free framework, SpatialClaw, which enhances 3D/4D spatial reasoning in vision-language models by utilizing code as an action interface.
🛠️ Research Methods:
– Employs a stateful Python kernel pre-loaded with frames and primitives, allowing flexible composition and manipulation of perception results for adaptive spatial analysis without prior training.
💬 Research Conclusions:
– SpatialClaw demonstrated a significant performance improvement, achieving 59.9% average accuracy across 20 benchmarks, outperforming recent spatial agents by 11.2 points with consistent gains across six vision-language model backbones.
👉 Paper link: https://huggingface.co/papers/2606.13673