AI Native Daily Paper Digest – 20260615
1. OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
🔑 Keywords: Camera Motion Cloning, Grid Motion Videos, Multimodal Diffusion Transformers, Director-Level Control, Hierarchical Prompt Expansion Agent
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to create a unified framework, OmniDirector, for effective camera motion cloning using grid motion videos.
🛠️ Research Methods:
– The research uses a multimodal diffusion transformer technique and introduces a hierarchical prompt expansion agent for integrating diverse control signals, allowing for director-level video generation control.
💬 Research Conclusions:
– The proposed framework demonstrates enhanced performance and controllability in video generation tasks by effectively coordinating characters, actions, and camera movements.
👉 Paper link: https://huggingface.co/papers/2606.13432
2. Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents
🔑 Keywords: MRAgent, associative memory graph, active reconstruction, memory-augmented agents, long-horizon memory reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance dynamic memory access during reasoning by combining associative memory graphs with active reconstruction to improve long-horizon memory reasoning and reduce computational costs.
🛠️ Research Methods:
– The introduction of MRAgent, a framework utilizing a Cue-Tag-Content graph with associative tags and an active reconstruction mechanism to allow iterative exploration and adaptive memory retrieval.
💬 Research Conclusions:
– MRAgent demonstrates significant improvements in long-horizon memory reasoning on the LoCoMo and LongMemEval benchmarks, outperforming strong baselines by up to 23%, while also substantially reducing token and runtime costs.
👉 Paper link: https://huggingface.co/papers/2606.06036

3. Orchestra-o1: Omnimodal Agent Orchestration
🔑 Keywords: Omnimodal Agent Orchestration, Multi-Agent Systems, Modality-Aware Task Decomposition, Agentic Reinforcement Learning, OmniGAIA Benchmark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to introduce Orchestra-o1, an omnimodal agent orchestration framework that enhances collaboration across multiple modalities by unifying task decomposition and utilizing specialized sub-agent execution to improve performance on complex multimodal benchmarks.
🛠️ Research Methods:
– The framework employs a unified orchestration mechanism that provides modality-aware task decomposition, online sub-agent specialization, and parallel sub-task execution. Additionally, the study applies decision-aligned group relative policy optimization (DA-GRPO) as a reinforcement learning technique to train the Orchestra-o1-8B.
💬 Research Conclusions:
– Orchestra-o1 demonstrated significant improvements over existing methods, outperforming the second-best approach by 10.3% in accuracy on the OmniGAIA Benchmark, and achieving state-of-the-art performance against current open-source omnimodal agents.
👉 Paper link: https://huggingface.co/papers/2606.13707

4. Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
🔑 Keywords: VideoRAG, Retrieval-augmented generation, egocentric video, temporal granularities, chunk-adaptive reranking
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study extends VideoRAG systems to manage long egocentric videos using multi-modal retrieval across different temporal granularities, introducing a new benchmark and reranking method to address current system limitations.
🛠️ Research Methods:
– The researchers introduced V-RAGBench, enabling decoupled evaluation of retrieval and generation, and CARVE, a method for chunk-adaptive reranking which operates parallel retrievers across configurations and identifies the best configuration for each chunk.
💬 Research Conclusions:
– The CARVE method outperforms existing VideoRAG baselines by allowing chunks to be processed with multiple configuration settings, promoting better generation outcomes unattainable by traditional query-level methods.
👉 Paper link: https://huggingface.co/papers/2606.13141

5. From AGI to ASI
🔑 Keywords: Artificial General Intelligence, Artificial General Superintelligence, AI paradigm shifts, Recursive improvement, Multi-agent collectives
💡 Category: Foundations of AI
🌟 Research Objective:
– Investigate the potential pathways from Artificial General Intelligence (AGI) to Artificial Superintelligence (ASI) and the societal implications of these transitions.
🛠️ Research Methods:
– Analyze and characterize ASI, explore pathways including scaling AGI, paradigm shifts, recursive improvement, and multi-agent collectives.
💬 Research Conclusions:
– ASI development could follow various pathways, each with distinct challenges and uncertainties. Transformative changes may unfold gradually across multiple domains, necessitating an interdisciplinary global effort to prepare for societal impacts.
👉 Paper link: https://huggingface.co/papers/2606.12683

6. Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
🔑 Keywords: Large Language Models, Epistemic Resilience, Misleading Context, MedMisBench, Medical Reasoning
💡 Category: AI in Healthcare
🌟 Research Objective:
– To evaluate the Epistemic Resilience of large language models (LLMs) in the context of medical reasoning and adversarial conditions.
🛠️ Research Methods:
– Introduction of MedMisBench, a benchmark consisting of 10,932 medical question items and 48,889 misleading context-option pairs, used to assess how LLMs’ accuracy is affected when exposed to misleading context.
💬 Research Conclusions:
– LLMs demonstrate a significant drop in accuracy from 71.1% to 38.0% under misleading context, revealing a critical gap in current evaluation methods regarding the resilience of maintaining correct medical judgment.
– The study identifies that formal, authority-framed falsehoods and exception-poisoning claims pose the most significant threat to LLMs’ accuracy.
👉 Paper link: https://huggingface.co/papers/2606.12291
7. Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
🔑 Keywords: Pretrained language models, Dynamic program-of-layers, PoLar, Execution programs, Latent reasoning capacity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve accuracy and reduce computational overhead in large language models by implementing flexible, dynamic program-of-layers strategies.
🛠️ Research Methods:
– Developed a lightweight PoLar prediction network to generate execution programs that dynamically manage pretrained layers.
💬 Research Conclusions:
– The PoLar strategy consistently enhances accuracy over standard inference and previous dynamic-depth methods, even with fewer layer executions. This approach demonstrates improved results in both standard and out-of-distribution evaluations.
👉 Paper link: https://huggingface.co/papers/2606.06574

8. Hy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
🔑 Keywords: End-to-End System, Robot Learning Stack, Data Collection, Model Design, Reinforcement Learning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop HyVLA-0.5, an end-to-end robotic learning system capable of real-world deployment.
🛠️ Research Methods:
– Integration of data collection, model design, pre-training, and reinforcement learning within a singular framework.
💬 Research Conclusions:
– The HyVLA-0.5 system is designed as a comprehensive solution to facilitate various stages of robotic learning and deployment in real-world environments.
👉 Paper link: https://huggingface.co/papers/2606.14409

9. LLM Agents Can See Code Repositories
🔑 Keywords: Visual repository representations, LLM-based coding agents, Multimodal large language models, Repository issue resolution, Visual graphs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To explore the effectiveness of visual repository representations in enhancing the performance of LLM-based coding agents during repository-level issue resolution.
🛠️ Research Methods:
– Conducted a systematic empirical study on visual repository representations for LLM-based agents, evaluating four recent multimodal models.
💬 Research Conclusions:
– Visual-only setups degrade accuracy and increase token cost due to lack of symbolic detail.
– Integrating visual graphs with text interfaces reduces token consumption by up to 26% and maintains or improves issue-resolution accuracy, particularly benefiting fault localization and exploration depth management.
👉 Paper link: https://huggingface.co/papers/2606.14061

10. Pythagoras-Prover: Advancing Efficient Formal Proving via Augmented Lean Formalisation
🔑 Keywords: Lean theorem provers, curriculum training, autoregressive models, diffusion-based prover, Augmented Lean Formalisation
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop compute-efficient Lean theorem provers using curriculum training and augmented formalization techniques, addressing limitations due to scarce verified data and expensive proof searches.
🛠️ Research Methods:
– Introduced a family of Lean theorem provers using autoregressive models and a diffusion-based prover.
– Utilized a stratified Lean-verified corpus and curriculum supervised fine-tuning to enhance training efficiency.
– Implemented Augmented Lean Formalisation (ALF) to expand training data without needing full verification.
💬 Research Conclusions:
– Pythagoras-Prover-4B outperformed DeepSeek-Prover-V2-671B with significantly fewer parameters.
– Pythagoras-Prover-32B achieved state-of-the-art results in open-source benchmarks, setting new performance standards for theorem proving models.
👉 Paper link: https://huggingface.co/papers/2606.12594

11. The Hidden Power of Scaling Factor in LoRA Optimization
🔑 Keywords: Low-Rank Adaptation, scaling factor, Signal-Drift framework, spectral suppression
💡 Category: Machine Learning
🌟 Research Objective:
– This study aims to explore the pivotal role of the scaling factor α in Low-Rank Adaptation (LoRA) and its optimization impact, distinguishing it from the traditional understanding as a secondary learning rate complement.
🛠️ Research Methods:
– The research employs a combination of empirical analysis and a theoretical Signal-Drift framework to investigate LoRA’s scaling mechanism.
💬 Research Conclusions:
– The study reveals LoRA’s scaling factor α as the main driver of effective optimization, outperforming learning rate adjustments in accelerating convergence and optimizing task signals without increasing drift. It also proposes LoRA-α, a minimalist framework that enhances LoRA’s compatibility with standard learning rate methods while improving performance across tasks.
👉 Paper link: https://huggingface.co/papers/2606.12883

12. MBench: A Comprehensive Benchmark on Memory Capability for Video World Models
🔑 Keywords: MBench, video world models, memory capability, entity consistency, causal consistency
💡 Category: Generative Models
🌟 Research Objective:
– Introduce MBench, a benchmark designed to evaluate the memory capabilities of video world models, focusing on entity, environment, and causal consistency over long-term temporal horizons.
🛠️ Research Methods:
– Decomposition of memory capability into three core dimensions and 12 sub-dimensions.
– Evaluation using rule-based quantitative matrices and VLM, based on real-captured long videos.
💬 Research Conclusions:
– MBench reveals critical limitations in existing video world models with regard to long-term state retention and provides a framework for further research in improving consistency.
👉 Paper link: https://huggingface.co/papers/2606.00793

13. μ_0: A Scalable 3D Interaction-Trace World Model
🔑 Keywords: 3D traces, scalable world model, embodiment-agnostic, TraceExtract, action-free pretraining
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to develop a scalable world model, μ₀, using 3D traces that predict smooth trajectories for key interaction points, facilitating embodiment-agnostic robot learning without the need for action labels.
🛠️ Research Methods:
– The study introduces the TraceExtract system for automatically extracting 3D supervision through keypoint selection and globally aligned traces, enhanced by a pretrained vision-language backbone and a modular trace expert representing queries with B-spline control points.
💬 Research Conclusions:
– The μ₀ model outperforms baselines in 2D and 3D trace prediction and can be effectively used with action experts for downstream robotic tasks. It achieves competitive performance with other VLA models, establishing 3D traces as scalable and transferable for cross-embodiment manipulation.
👉 Paper link: https://huggingface.co/papers/2606.13769
14. LoSoNA: A Benchmark for Local Social Norm Adaptation in Group Conversations
🔑 Keywords: LoSoNA, LLM-based agents, local conversational norms, norm-aware prompting, group chat
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the capacity of large language models (LLMs) in inferring and adapting to implicit local conversational norms within group chat settings using the LoSoNA benchmark.
🛠️ Research Methods:
– Utilization of a benchmark named LoSoNA which provides scenarios with curated group-chat transcripts to evaluate eight frontier and open-weight models under different prompting conditions.
💬 Research Conclusions:
– The study highlights that naive prompting of LLMs is generally limited, while explicit norm-aware prompting offers varying levels of improvement, with some models like Gemini 3.1 Pro and Claude Fable 5 achieving significant success rates.
👉 Paper link: https://huggingface.co/papers/2606.14600

15. ClinHallu: A Benchmark for Diagnosing Stage-Wise Hallucinations in Medical MLLM Reasoning
🔑 Keywords: hallucinations, medical multimodal large language models, reasoning integration, trace-supervised fine-tuning
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to address and mitigate hallucinations in medical multimodal large language models (MLLMs) by introducing ClinHallu, a benchmark focusing on stage-wise reasoning analysis.
🛠️ Research Methods:
– ClinHallu provides a comprehensive set of 7,031 validated instances enriched with structured reasoning traces, differentiating sources of errors such as visual recognition, knowledge recall, and reasoning integration.
– The study employs stage-replacement interventions to analyze the impact of correcting specific stages on the final outcome.
💬 Research Conclusions:
– Trace-supervised fine-tuning is effective in reducing stage-wise hallucinations, contributing a fine-grained tool for diagnosing reasoning failures in medical MLLMs.
– ClinHallu offers a publicly available testbed to facilitate improved clinical decision support systems.
👉 Paper link: https://huggingface.co/papers/2606.14697

16. Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
🔑 Keywords: On-policy distillation, sparse parameter updates, dense teacher supervision, FFN-heavy, geometric properties
💡 Category: Machine Learning
🌟 Research Objective:
– To analyze how on-policy distillation (OPD) impacts model parameters in language and vision-language models.
🛠️ Research Methods:
– The paper examines sparsity and geometric properties of OPD in various model pairs using parameter updates and optimizer ablation studies.
💬 Research Conclusions:
– OPD leads to sparse parameter updates distributed across layers with a preference for FFN components.
– Sparse structures allow nearly equivalent performance by training only discovered subnetworks.
– Dense teacher supervision preserves gradient scales, making the AdamW optimizer effective despite sparse updates.
– Geometric updates in OPD remain full-rank but are spectrally focused and distinct from dense parameter rewriting.
👉 Paper link: https://huggingface.co/papers/2606.13657

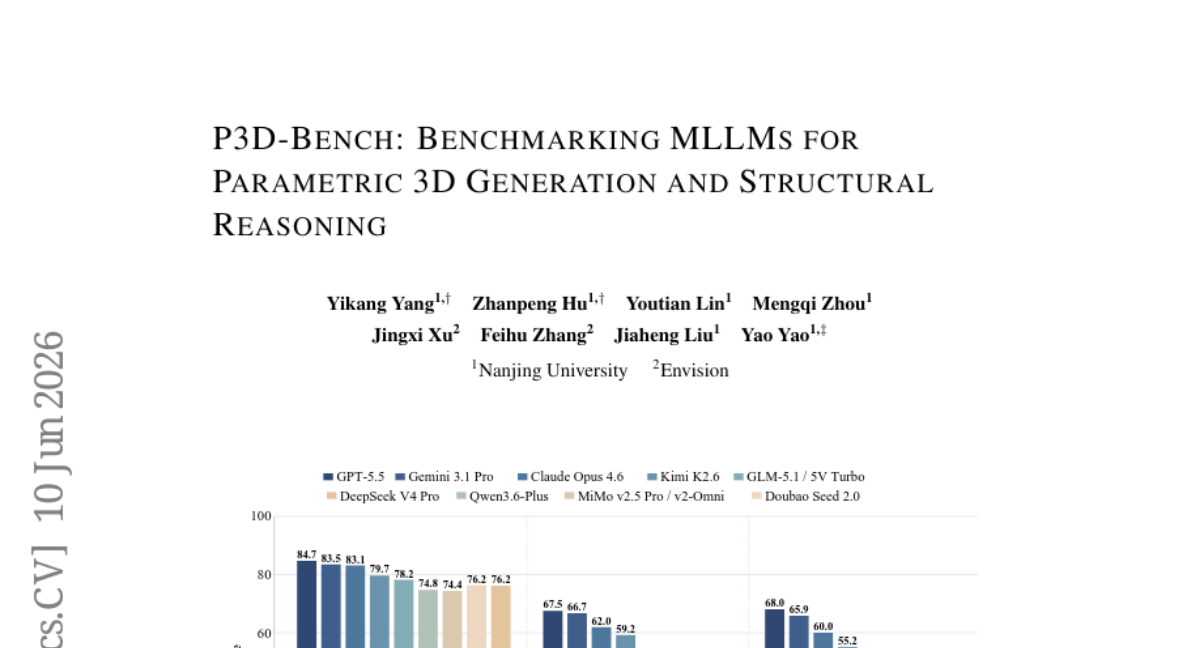
17. P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
🔑 Keywords: Parametric 3D generation, Multimodal large language models, 3D modeling, P3D-Bench, Geometric precision
💡 Category: Generative Models
🌟 Research Objective:
– This study introduces P3D-Bench, a benchmark designed to assess parametric 3D generation through geometric precision, semantic alignment, and assembly consistency.
🛠️ Research Methods:
– Evaluation of frontier Multimodal Large Language Models (MLLMs) and text-only LLMs across 400 text cases, 400 image cases, and 203 annotated assemblies to benchmark their performance in parametric 3D modeling tasks.
💬 Research Conclusions:
– The research highlights three major findings: models struggle with assemblies, often failing to compose coherent structures; they frequently succeed in capturing global shape and semantic identity but fail in precise parametric geometry reproduction; part-level modeling in assemblies remains weak with accurate geometry and part count challenges.
👉 Paper link: https://huggingface.co/papers/2606.11152
18. AlloSpatial: Agentic Harness Framework for Spatial Reasoning in Foundation Models
🔑 Keywords: AlloSpatial, allocentric representations, cognitive mapping, Spatial Reasoning Harness, reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective of the research is to enhance spatial reasoning in foundation models by transforming egocentric observations into structured allocentric representations and enabling reliable spatial cognition.
🛠️ Research Methods:
– The implementation of the AlloSpatial framework, which includes components like World2Mind for cognitive mapping and Allocentric-Spatial Trees, as well as a Spatial Reasoning Harness for tool-use judgment and cue collection.
💬 Research Conclusions:
– Experiments indicated that AlloSpatial improves model performance by 5%-18% in training-free settings, and structured allocentric representations and tool-use reasoning can significantly enhance the spatial reasoning capabilities of foundation models.
👉 Paper link: https://huggingface.co/papers/2606.08952

19. World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
🔑 Keywords: World Tracing, pixel-aligned geometry, diffusion transformer, depth estimators, visible-surface reconstruction
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce World Tracing, a generative geometry representation that aligns 3D points with input pixels and completes hidden surfaces.
🛠️ Research Methods:
– Utilizes a diffusion transformer, WT-DiT, leveraging pixel-space flow matching and a mixed noise schedule for training.
💬 Research Conclusions:
– Achieves superior performance in visible-surface reconstruction and complete geometry generation, enabling applications in text-driven 3D scene editing and novel-view video synthesis.
👉 Paper link: https://huggingface.co/papers/2606.13652
20. FVSpec: Real-World Property-Based Tests as Lean Challenges
🔑 Keywords: AI-assisted formal verification, Lean specifications, property-based tests, LLM pipeline, proof generation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To create a benchmark for evaluating AI models and agents on formal software verification tasks by translating property-based tests from Python into Lean specifications.
🛠️ Research Methods:
– Scraping 11,039 property-based tests from Python repositories and translating 2,772 tests into 9,415 Lean specifications using a three-agent LLM pipeline.
💬 Research Conclusions:
– A novel benchmark and open-source resources (scraper, agents, data) are presented to stimulate advancements in the field of AI-assisted formal verification of real-world software.
👉 Paper link: https://huggingface.co/papers/2606.01008

21. ActiveMimic: Egocentric Video Pretraining with Active Perception
🔑 Keywords: ActiveMimic, Active Perception, Egocentric Video, Robot Pretraining, Camera Motion
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to leverage egocentric human video to enable active perception learning and match robot data performance in pretraining.
🛠️ Research Methods:
– The study introduces the ActiveMimic pretraining framework, which recovers synchronized camera and wrist trajectories from egocentric video to model camera motion as a viewpoint action.
💬 Research Conclusions:
– Experiments demonstrate that ActiveMimic consistently surpasses traditional human video-based baselines and matches models pretrained with robot data, highlighting active perception as essential for effectively using egocentric human video in robot pretraining.
👉 Paper link: https://huggingface.co/papers/2606.06194

22. Quickest Detection of Hallucination Onset: Delay Bounds and Learned CUSUM Statistics
🔑 Keywords: Token-level hallucination detection, quickest change detection, Markov model, CUSUM, detection delay
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to reformulate token-level hallucination detection as a quickest change detection problem, demonstrating limitations on detection delay and showcasing improved performance with causal recurrent modeling.
🛠️ Research Methods:
– The research utilizes a first-order Markov model validated on RAGTruth to situate the task within classical change-point theory, producing Lorden’s lower bound on detection delay.
– A causal recurrent labeler is used, functioning as a CUSUM with a learned increment, to assess its efficacy compared to a linear per-token baseline.
💬 Research Conclusions:
– The causal recurrent labeler, at a comparable false-alarm rate, is significantly quicker in detecting hallucinations than the baseline, attributing its advantage to better per-token scoring.
– Donsker-Varadhan type theorem explains the gap between learned scores and the features’ inherent divergence, indicating some limits due to finite-horizon effects rather than recalibration. Sequential analysis helps expose delay structures that classification metrics might disguise.
👉 Paper link: https://huggingface.co/papers/2606.12476

23. Squeeze-Release: Iterative Pruning with Exact Structural Minimization
🔑 Keywords: Squeeze-Release, Pruning, Structural Minimization, CompensatedLayerNorm, Transformer Architectures
💡 Category: Machine Learning
🌟 Research Objective:
– The primary goal is to develop a Squeeze-Release compression method that significantly reduces the size of neural networks without sacrificing accuracy.
🛠️ Research Methods:
– The method incorporates pruning, structural minimization, and an intermediate release step, converting sparse networks into smaller dense networks and retaining trainable parameters as small noise.
– Introduced CompensatedLayerNorm to facilitate structural minimization across LayerNorm-equipped residual streams.
💬 Research Conclusions:
– The Squeeze-Release method can compress deployable networks up to 39x smaller for fully-connected models and 14.8x smaller for modern CNNs, maintaining comparable accuracy.
– This approach can be extended and applied to transformer architectures effectively.
👉 Paper link: https://huggingface.co/papers/2606.14346

24.

25. CARVE: Certified Affordable Repair of Vetoed Maneuvers via Envelopes for Interactive Driving
🔑 Keywords: interactive repair certification, CARVE, autonomous vehicle, rule systems
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to address failures in autonomous vehicle rule systems by introducing CARVE, a certification framework providing runtime proofs for multi-agent repairs without predicting other drivers’ compliance.
🛠️ Research Methods:
– The methods involve using CARVE, a prediction-free certificate layer, to evaluate interactive driving scenarios and formulate interactive repair certification, focusing on the cooperation envelope of tactical operators.
💬 Research Conclusions:
– CARVE effectively recovers human-resolved false vetoes and accepts maneuvers initially vetoed while maintaining right-of-way respect and zero priority-agent false positives, all without predicting other drivers’ compliance.
👉 Paper link: https://huggingface.co/papers/2606.02641

26. Statistically Reliable LLM-Based Ranking Evaluation via Prediction-Powered Inference
🔑 Keywords: Prediction-Powered Inference, LLM, Precision@K, Bias-Correction, A/B Testing
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to extend Prediction-Powered Inference to provide bias-corrected estimates for ranking evaluation metrics by integrating human labels with judgments from Large Language Models (LLMs).
🛠️ Research Methods:
– The paper combines a smaller set of human-labeled data with a larger set judged by LLMs to reduce computation complexity and correct bias in hierarchical metrics, specifically utilizing metrics like Precision@K.
💬 Research Conclusions:
– PRECISE significantly reduces the standard error in metrics evaluation (from 4.45 to 3.50 on the ESCI benchmark) and accurately ranks system variants. A/B testing confirms improved precision with a notable increase in daily sales performance.
👉 Paper link: https://huggingface.co/papers/2606.05308

27. WaveDiT: Distribution-Aware Wavelet Flow Matching for Efficient 3D Brain MRI Synthesis
🔑 Keywords: WaveDiT, 3D brain MRIs, conditional flow matching, 3D Haar Discrete Wavelet Transform, full-resolution 3D synthesis
💡 Category: Generative Models
🌟 Research Objective:
– To enable efficient synthesis of full-resolution 3D brain MRIs using WaveDiT, facilitating data augmentation in neuroimaging.
🛠️ Research Methods:
– Utilization of conditional flow matching in wavelet coefficient space with adaptive precision modeling.
– Integration of factorized spatio-depth attention and band-wise heteroscedastic uncertainty modeling.
💬 Research Conclusions:
– WaveDiT allows full-resolution 3D synthesis on a single modern GPU with improved anatomical detail alignment.
– Demonstrated enhanced brain age prediction and anatomical agreement compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2606.08670

28. AdaSR: Adaptive Streaming Reasoning with Hierarchical Relative Policy Optimization
🔑 Keywords: Adaptive Streaming Reasoning, Hierarchical Reasoning Process, Hierarchical Relative Policy Optimization, Reasoning Accuracy, Computational Efficiency
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To propose AdaSR, an adaptive streaming reasoning framework that allows models to dynamically allocate computation during input streaming while optimizing task performance and reducing latency.
🛠️ Research Methods:
– Introduction of Hierarchical Relative Policy Optimization (HRPO) to decompose policy optimization into streaming reasoning and deep reasoning phases.
💬 Research Conclusions:
– AdaSR achieves a better balance among reasoning accuracy, computational efficiency, and streaming latency compared with supervised fine-tuning baselines.
👉 Paper link: https://huggingface.co/papers/2606.14694

29. Two-Fidelity Best-Action Identification for Stochastic Minimax Tree
🔑 Keywords: Two-fidelity tree-search algorithm, Stochastic minimax trees, Best-action identification, Monte Carlo Tree Search, AI Planning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To propose a two-fidelity tree-search algorithm, 2FFS, that balances cheap biased evaluations with expensive accurate evaluations in stochastic minimax trees for fixed-confidence best-action identification.
🛠️ Research Methods:
– The algorithm integrates fast expansion from minimax style and stochastic sampling from Monte Carlo Tree Search (MCTS), deciding adaptively between biased evaluations and accurate local certifications.
💬 Research Conclusions:
– 2FFS achieves fixed-confidence correctness with finite stopping for exact identification. It demonstrates reduced sample and computational operations compared to existing BAI-MCTS baselines, proving efficient for general-depth trees.
👉 Paper link: https://huggingface.co/papers/2606.01708

30. APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
🔑 Keywords: Vision-Language-Action models, generalization, Bayesian perspective, Action expert PreTraining, out-of-distribution instructions
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve generalization in Vision-Language-Action models by addressing structural imbalances and enhancing performance on out-of-distribution instructions through a novel two-stage training method called APT.
🛠️ Research Methods:
– APT involves a two-stage training approach where the first stage focuses on pretraining action experts on vision-action pairs to counter language imbalance. The second stage integrates language tokens using a gated fusion mechanism within mainstream VLA architectures.
💬 Research Conclusions:
– The proposed APT method consistently enhances generalization capabilities and performance on unseen instructions and compositional tasks in Vision-Language-Action models, demonstrating its effectiveness through comprehensive experiments.
👉 Paper link: https://huggingface.co/papers/2606.12366

31. An Enigma of Artificial Reason: Investigating the Production-Evaluation Gap in Large Reasoning Models
🔑 Keywords: Large reasoning models, answer confirmation bias, reasoning evaluation, Valid-Answer-Invalid-Reasoning, chain-of-thought
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To investigate the ability of large reasoning models (LRMs) to evaluate reasoning using the Valid-Answer-Invalid-Reasoning (VAIR) dataset, focusing on the reasoning evaluation independent of reasoning production.
🛠️ Research Methods:
– Utilization of the VAIR dataset comprising math problems with trivial reasoning flaws and valid answers, along with detailed chain-of-thought analysis and linear probes to identify biases in LRMs.
💬 Research Conclusions:
– Findings reveal a significant gap in LRMs’ ability to evaluate reasoning, highlighting an answer confirmation bias. LRMs often prioritize confirming answers over verifying reasoning steps, indicating limitations in current reasoning training approaches.
👉 Paper link: https://huggingface.co/papers/2606.01462

32. Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
🔑 Keywords: AI agents, scientific research, benchmark, novel insights, reliability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces SciAgentArena, a benchmark designed to evaluate AI agents in real scientific research scenarios, aiming to identify limitations and opportunities for improvement in agent performance and autonomy.
🛠️ Research Methods:
– Approximately 200 tasks were developed, featuring stepwise verification and an interactive, agent-agnostic environment to assess diverse AI agents.
💬 Research Conclusions:
– AI agents can effectively contribute to structured data-analysis workflows but struggle with generating novel insights and maintaining autonomy in open-ended research questions. SciAgentArena serves as a framework for evaluating and guiding future AI agent development to tackle complex scientific challenges.
👉 Paper link: https://huggingface.co/papers/2606.12736

33. AFFORDANCE20Q: Evaluating Affordance Reasoning from Physical Properties
🔑 Keywords: Affordance20Q, Affordance reasoning, Large Language Models, 20-Questions game, Knowledge Base
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to evaluate the reasoning capabilities of Large Language Models (LLMs) in inferring object action possibilities without revealing object identities, highlighting performance gaps compared to humans.
🛠️ Research Methods:
– The research introduces Affordance20Q, a novel benchmark in the form of a 20-Questions game, wherein models identify hidden object affordances by asking yes/no questions about physical properties.
💬 Research Conclusions:
– Significant performance gaps (~20 points) between LLMs and human reasoning were identified, and efforts to reduce this gap using KB-Anchored Rule Induction (KARI) showed improvements of up to 15.2 points, yet limited by the coverage of Knowledge Bases.
👉 Paper link: https://huggingface.co/papers/2606.14240

34. When is Your LLM Steerable?
🔑 Keywords: Activation steering, language models, early decoding dynamics, steerability prediction, Gradient Boosting Decision Trees
💡 Category: Natural Language Processing
🌟 Research Objective:
– To predict the effectiveness of activation steering in language models using early decoding states and optimize steering strength with reduced computational cost.
🛠️ Research Methods:
– Introduced ASTEER testbed with 1.4M steered generations and conducted analysis on early decoding dynamics.
– Trained a Gradient Boosting Decision Trees (GBDT) classifier to predict steering success using features extracted from hidden states.
💬 Research Conclusions:
– The predictor achieved around 0.7 macro-F1 score on unseen concepts, demonstrating early hidden states can encode structured information about steering efficacy.
– The steerability predictor helps in steering strength searching, achieving near-optimal performance with minimal decoding cost.
👉 Paper link: https://huggingface.co/papers/2606.11599

35. RhymeFlow: Training-Free Acceleration for Video Generation with Asynchronous Denoising Flow Scheduling
🔑 Keywords: RhymeFlow, Video generation, Diffusion Transformers, Keyframes, Latent trajectory projection
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to enhance video generation by accelerating diffusion transformers, focusing on reducing computational costs while maintaining visual quality through decoupling denoising trajectories across frames.
🛠️ Research Methods:
– RhymeFlow is introduced as a training-free framework that anchors keyframes and applies latent trajectory projection, allowing keyframes to undergo dense denoising and other frames to skip steps, thereby minimizing computational complexity.
💬 Research Conclusions:
– Experiments show RhymeFlow enhances inference speed and visual quality in DiT-based video generation models, outperforming existing baseline methods.
👉 Paper link: https://huggingface.co/papers/2606.06309

36. Avatar V: Scaling Video-Reference Avatar Video Generation
🔑 Keywords: Avatar V, video-reference-conditioned identity modeling, Sparse Reference Attention, motion representation stream, identity-aware super-resolution
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to develop Avatar V, a production-scale framework for generating behaviorally recognizable avatar videos conditioned on full video references to overcome the limitations of existing methods that struggle with identity fidelity and dynamic behavioral reproduction.
🛠️ Research Methods:
– The framework employs Sparse Reference Attention for efficient conditioning on lengthy references and introduces a motion representation stream to enhance talking style transfer and identity-aware super-resolution refiners. The data engine processes over 100 million training clips from 50 million raw videos, using a comprehensive five-stage training pipeline with innovations like flow matching pre-training and personality fine-tuning.
💬 Research Conclusions:
– Avatar V generates 1080p videos of unlimited duration with high fidelity in identity preservation, lip synchronization, and overall generation quality. It surpasses current systems like Seedance 2.0 and OmniHuman 1.5 in both automated and human evaluations.
👉 Paper link: https://huggingface.co/papers/2606.13872

37. The Arbiter Agent: Continually Monitoring Multi-Agent Conversations to Detect Emergent Misalignment
🔑 Keywords: AI systems, multi-agent, misalignment, Arbiter, active inspection
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce and evaluate the Arbiter, an agent designed to monitor multi-agent conversations and identify misaligned behaviors in real time.
🛠️ Research Methods:
– Utilizes the Arbiter framework under resource constraints to observe and inspect conversations, employing various strategies such as questioning participants and logging behaviors. Experiments conducted across five conversation conditions with different tool configurations and backbone models.
💬 Research Conclusions:
– The Arbiter effectively detects misalignment among agents earlier in conversations, with active inspection tools significantly enhancing detection accuracy and speed. Continual monitoring with a budget-aware approach improves the oversight of multi-agent systems.
👉 Paper link: https://huggingface.co/papers/2606.10747

38. VISTA: View-Consistent Self-Verified Training for GUI Grounding
🔑 Keywords: VISTA, GRPO, GUI Grounding, Self-Verified Cross-View Anchor, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper proposes VISTA, a framework aimed at improving training stability and accuracy for GUI Grounding by using multiple consistent views of the same GUI instance.
🛠️ Research Methods:
– VISTA leverages Group Relative Policy Optimization, constructing comparison groups from multiple target-preserving views.
– Introduces a self-verified cross-view anchor to stabilize short coordinate generation without unconditional imitation.
💬 Research Conclusions:
– VISTA consistently improves grounding accuracy across five GUI-grounding benchmarks.
– Increases accuracy on ScreenSpot-Pro with lower prediction flip rates and higher worst-view accuracy.
👉 Paper link: https://huggingface.co/papers/2606.14579

39. No Hidden Prompts Needed! You Can Game AI Peer Review with Presentation-Only Revisions
🔑 Keywords: AI reviewers, adversarial repackaging, paper presentation, optimization surface, AI-generated reviews
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To investigate how adversarial repackaging, a manipulation of presentation-level content, can exploit AI reviewers’ weakness for impressive strengths over resolved weaknesses.
🛠️ Research Methods:
– Study presentation-level content manipulation without altering scientific evidence to test its effectiveness against AI reviewers across three mainstream platforms.
💬 Research Conclusions:
– Adversarial repackaging achieves a high attack success rate and score gain by emphasizing strengths and misleading reviewers into seeing unchanged evidence as improved scientific contributions. This poses a risk beyond traditional attack methods, indicating vulnerabilities in AI reviewers regarding paper presentation optimization.
👉 Paper link: https://huggingface.co/papers/2606.13044

40. iMaC: Translating Actions into Motion and Contact Images for Embodied World Models
🔑 Keywords: iMac, embodied world models, image-based action tokens, visual robotic decision-making
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To propose iMac, a novel unified control paradigm using raw visual images as action representations for embodied world models, enhancing robotic control expressiveness and generalization.
🛠️ Research Methods:
– Development of a dual-branch architecture with an image-action encoder and a dynamic world predictor to compress visual images into action embeddings and learn environment transition rules.
💬 Research Conclusions:
– iMac excels in prediction accuracy, task success rate, and cross-scene generalization against traditional vector-based control, and achieves flexible control for diverse robotic agents.
👉 Paper link: https://huggingface.co/papers/2606.09813

41. RepFusion: Leveraging Multimodal Priors for Denoising in Representation Space
🔑 Keywords: RepFusion, Multimodal Large Language Models, Text-to-Image, Diffusion Transformers, Denoising
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate the use of multimodal large language models (MLLMs) as noisy representation encoders for diffusion transformers in text-to-image generation.
🛠️ Research Methods:
– Implementation of RepFusion, which uses MLLM outputs as conditioning signals for diffusion transformers, compared against traditional text-to-image systems with newly trained generative backbones.
💬 Research Conclusions:
– RepFusion outperforms traditional approaches by effectively utilizing MLLMs’ strong priors for denoising visual representations and optimizing test-time computation through repeated MLLM conditioning.
👉 Paper link: https://huggingface.co/papers/2606.14700

42. RedAct: Redacting Agent Capability Traces for Procedural Skill Protection
🔑 Keywords: execution traces, RedAct, CapTraceBench, security, provenance analysis
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To quantify the risk and evaluate protection of private procedural skills exposed through execution traces.
🛠️ Research Methods:
– Construction of CapTraceBench, a benchmark comprising 75 specialized long-horizon tasks and 154 curated skills.
– Introduction of RedAct, a protected trace release framework for localizing and redacting key information while preserving verifier-critical evidence.
💬 Research Conclusions:
– RedAct effectively reduces normalized skill transfer from 44.7–67.1% to below the no-skill baseline while preserving audit evidence.
– Standalone behavioral watermarks achieve 93.6–100.0% true detection rate with a false alarm rate of at most 1.9%.
– Public agent traces can act as security interfaces, and selective redaction can reduce procedural capability leakage without compromising audit evidence.
👉 Paper link: https://huggingface.co/papers/2606.10813

43. Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
🔑 Keywords: Small-to-Large Policy Optimization, Group Relative Policy Optimization, rollout diversity, policy-level diversity, progressive annealing
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve large language model training efficiency by leveraging smaller models as explorers to enhance policy diversity.
🛠️ Research Methods:
– A novel framework called S2L-PO (Small-to-Large Policy Optimization) is proposed, using fixed small models to guide larger models and employing a progressive annealing strategy for efficient exploration and exploitation.
💬 Research Conclusions:
– S2L-PO achieves faster convergence and higher performance, improving accuracy on diverse mathematical reasoning benchmarks while reducing computational requirements for rollouts.
👉 Paper link: https://huggingface.co/papers/2605.30789

44. OmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
🔑 Keywords: Entity-Anchored Video Scripting, Clue-Guided QA Generation, cross-modal reasoning, temporal consistency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address limitations in current audio-visual question answering systems by enhancing cross-modal reasoning and temporal consistency through innovative video processing techniques.
🛠️ Research Methods:
– Development of an automated data engine with two key mechanisms: Entity-Anchored Video Scripting and Clue-Guided QA Generation. Introduction of OmniVideo-100K for instruction-tuning and OmniVideo-Test for evaluation.
💬 Research Conclusions:
– Fine-tuning different models on the proposed datasets demonstrated up to 20.59% performance gains, showcasing improved generalization in benchmarks like Daily-Omni and JointAVBench.
👉 Paper link: https://huggingface.co/papers/2606.14702

45. HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry
🔑 Keywords: HarnessX, AI agent, runtime interface, compositional primitives, multi-agent evolution
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce HarnessX, a platform for creating composable, adaptive, and evolvable AI agent runtime interfaces to enhance model training and harness design.
🛠️ Research Methods:
– Leverage compositional primitives, trace-driven evolution with AEGIS, and feedback loops to improve AI agent runtime performance.
💬 Research Conclusions:
– HarnessX delivers an average performance gain of +14.5% across five benchmarks, demonstrating that improvements in AI agents can be achieved through enhanced runtime interfaces rather than model scaling alone.
👉 Paper link: https://huggingface.co/papers/2606.14249

46. From Chatbot to Digital Colleague: The Paradigm Shift Toward Persistent Autonomous AI
🔑 Keywords: Large Language Models, Digital Colleague, Thinking LLMs, State-Action-Observation trajectories, self-evolving AI ecosystems
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary aim is to explore and conceptualize the transformation of Large Language Models (LLMs) from conversational agents to integrated AI systems with enhanced reasoning and persistent environments.
🛠️ Research Methods:
– The study organizes this transformation along cognitive core advancements and tool-augmented task execution, introducing concepts like Thinking LLMs, OpenClaw-style workstation systems, and the “Workspace + Skill” paradigm.
💬 Research Conclusions:
– This evolution represents a shift from traditional chatbot capabilities to Digital Colleagues, marked by deliberate cognition, reliable reasoning, episodic tool use, and the transition towards auditable and self-evolving AI ecosystems.
👉 Paper link: https://huggingface.co/papers/2606.14502

47. APPO: Agentic Procedural Policy Optimization
🔑 Keywords: Agentic Reinforcement Learning, multi-turn tool-use, credit assignment, branching decisions, procedure-level advantage scaling
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance multi-turn tool-use capabilities in agentic Reinforcement Learning by refining branching decisions and credit assignment through fine-grained decision points.
🛠️ Research Methods:
– The study introduces Agentic Procedural Policy Optimization (APPO), which relocates branching and credit assignment to fine-grained decision points. It utilizes a Branching Score that combines token uncertainty with policy-induced likelihood gains for targeted exploration and introduces procedure-level advantage scaling for credit distribution.
💬 Research Conclusions:
– APPO improves strong agentic RL baselines by nearly 4 points across 13 benchmarks while maintaining efficient tool-calls and interpretability of behavior.
👉 Paper link: https://huggingface.co/papers/2606.12384
