AI Native Daily Paper Digest – 20260616

1. JoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence
🔑 Keywords: Vision-Language Model, Real-Time Interaction, Vision-Triggered Responsiveness, Time Awareness, Deployable System
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The research aims to develop a real-time vision-language model for autonomous decision-making about when to respond or delegate tasks, enabling interactive systems that adapt to environmental changes without user prompts.
🛠️ Research Methods:
– The researchers introduced JoyAI-VL-Interaction, an 8B-scale model that internally makes response decisions. It includes a transferable training recipe and a full deployable system, integrating components such as ASR/TTS modules and a background brain.
💬 Research Conclusions:
– JoyAI-VL-Interaction demonstrates superior performance in vision-triggered responsiveness and time awareness, excelling over existing solutions like Doubao and Gemini in six real-world scenarios, as preferred by human raters.
👉 Paper link: https://huggingface.co/papers/2606.14777
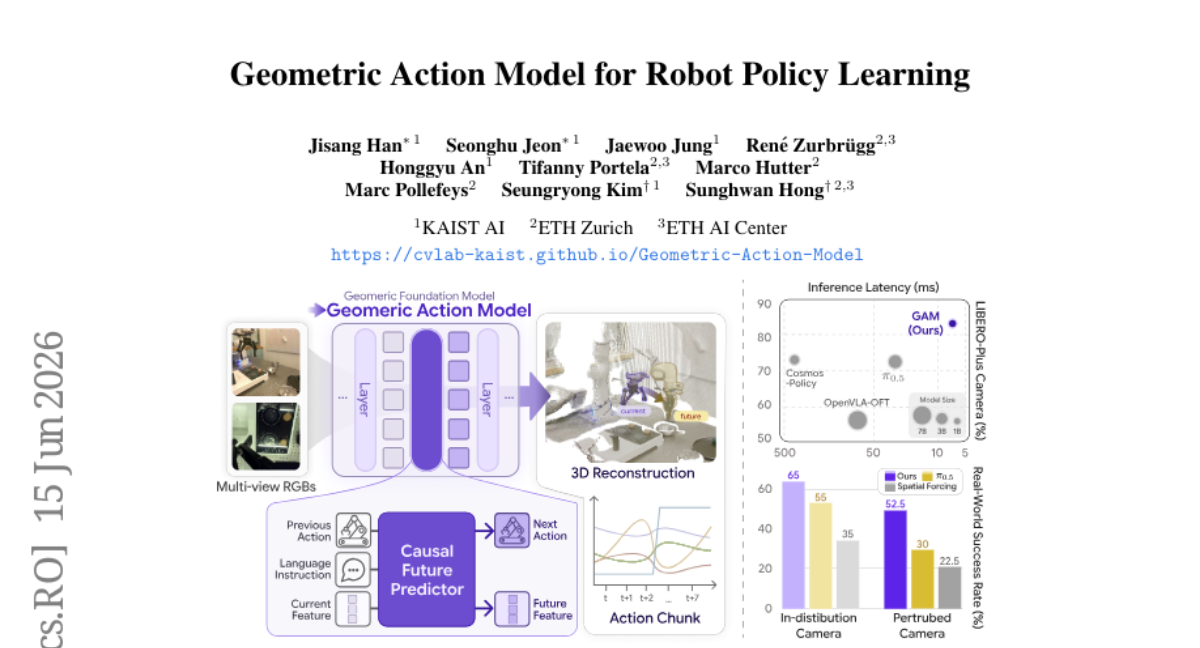
2. Geometric Action Model for Robot Policy Learning
🔑 Keywords: Geometric Action Model, language-conditioned manipulation policy, pretrained geometric foundation model, 3D physical environments, temporal world modeling
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper introduces the Geometric Action Model (GAM) designed to enhance language-conditioned manipulation policies in 3D physical environments by using pretrained geometric foundation models.
🛠️ Research Methods:
– GAM leverages a pretrained geometric foundation model, repurposed as a perception, temporal prediction, and action decoding substrate, splitting it at an intermediate layer for prediction and feature propagation.
💬 Research Conclusions:
– GAM outperforms existing foundation-model-scale baselines by being more accurate, robust, faster, and lighter in simulation and real-robot manipulation benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.17046
3. FastContext: Training Efficient Repository Explorer for Coding Agents
🔑 Keywords: FastContext, Large Language Model, exploration subagent, repository exploration, coding agents
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces FastContext to separate repository exploration from code solving in Large Language Model coding agents, aiming to improve resolution rates and reduce token consumption.
🛠️ Research Methods:
– Utilization of dedicated exploration subagents powered by specialized models with 4B–30B parameters that are bootstrapped from reference-model trajectories and refined with task-grounded rewards.
💬 Research Conclusions:
– Integration of FastContext results in up to 5.5% improvement in resolution rates and up to 60% reduction in token consumption for coding agents, showing effectiveness in segregating and handling repository exploration separately.
👉 Paper link: https://huggingface.co/papers/2606.14066

4. BRDFusion: Physics Meets Generation for Urban Scene Inverse Rendering
🔑 Keywords: BRDFusion, Inverse rendering, Generative models, Physical modeling, Controllable rendering
💡 Category: Computer Vision
🌟 Research Objective:
– BRDFusion aims to combine physical modeling and generative priors to achieve high-quality inverse and forward rendering of urban scenes, enabling applications like content creation and autonomous driving simulation.
🛠️ Research Methods:
– The approach integrates a unified framework using both physical modeling for scene property recovery and generative priors to reduce optimization ambiguity, enhancing video realism and artifact reduction.
💬 Research Conclusions:
– BRDFusion outperforms baselines in producing high-quality videos with precise control, supporting novel-view relighting, night simulation, and dynamic object insertion/editing in both real and synthetic environments.
👉 Paper link: https://huggingface.co/papers/2606.17049
5. VisualClaw: A Real-Time, Personalized Agent for the Physical World
🔑 Keywords: VisualClaw, multimodal agent, hybrid encoding, skill evolution, video-QA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary aim of the research is to develop VisualClaw, a self-evolving multimodal agent, that reduces deployment costs and enhances video-QA accuracy across various benchmarks.
🛠️ Research Methods:
– VisualClaw employs hybrid encoding to minimize deployment costs by filtering non-informative frames and compressing text skills, along with skill evolution through learning from failures and adjusting the skill bank for future interactions.
💬 Research Conclusions:
– VisualClaw demonstrates significant cost reduction in API usage across multiple video-QA benchmarks while improving accuracy, particularly notable in EgoSchema. It also excels in the newly curated VisualClawArena benchmark, making it apt for edge applications with personalized assistance features.
👉 Paper link: https://huggingface.co/papers/2606.16295
6. BadWorld: Adversarial Attacks on World Models
🔑 Keywords: BadWorld, Visual World Models, adversarial perturbations, self-supervised velocity attack, trajectory-adaptive bi-level optimization
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces BadWorld, a framework to reveal structural vulnerabilities in visual world models by generating imperceptible perturbations.
🛠️ Research Methods:
– The research employs a self-supervised velocity attack to disrupt early denoising dynamics without future supervision and uses trajectory-adaptive bi-level optimization to generalize across unpredictable user actions.
💬 Research Conclusions:
– BadWorld exposes severe structural fragility in visual world models, causing catastrophic degradation in future rollouts, emphasizing the risks for safety-critical systems while suggesting a method for privacy protection.
👉 Paper link: https://huggingface.co/papers/2606.16519
7. SP^3: Spherical Priors for Plug-and-Play Restoration
🔑 Keywords: SP³, Spherical Encoders, generative priors, image restoration, latent space
💡 Category: Generative Models
🌟 Research Objective:
– Introduce SP³, a novel Plug-and-Play algorithm for accelerating maximum a posteriori image restoration using Spherical Encoders as generative priors.
🛠️ Research Methods:
– Utilize spherical encoders to replace traditional denoisers, leveraging tightly structured latent space for robust projection onto the natural image manifold. Employ Half-Quadratic Splitting for stable convergence without gradient computation.
💬 Research Conclusions:
– SP³ enables “anytime” restoration, producing high-quality images from the first iteration and achieving perceptual quality comparable to state-of-the-art methods while being significantly faster (3-630 times).
👉 Paper link: https://huggingface.co/papers/2606.16396

8. CODA-BENCH: Can Code Agents Handle Data-Intensive Tasks?
🔑 Keywords: Advanced agents, data discovery, code execution, CODA-BENCH, data-intensive environment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce CODA-BENCH, a new benchmark for evaluating the integration of code and data intelligence in data-intensive environments.
🛠️ Research Methods:
– Construct a data-intensive Linux sandbox using the Kaggle ecosystem to assess agents’ capabilities in handling complex file hierarchies and data-driven tasks.
💬 Research Conclusions:
– Advanced systems have difficulty integrating data discovery with code execution, achieving a 61.1% success rate, indicating gaps in current capabilities for data-intensive tasks.
👉 Paper link: https://huggingface.co/papers/2606.15300

9. Retrieve, Don’t Retrain: Extending Vision Language Action Models to New Tasks at Test Time
🔑 Keywords: Retrieval-augmented, Vision-Language-Action, Cross-embodiment generalization, Fine-tuning, Cosmos Policy
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to eliminate per-task fine-tuning costs by using pre-trained models with indexed demonstrations, enhancing efficient cross-embodiment generalization and task adaptation.
🛠️ Research Methods:
– The methodology involves training a retrieval-augmented policy on paired demonstrations and deploying new tasks by appending pool-side demonstrations to a retrieval pool, rather than updating the model’s parameters for each task.
💬 Research Conclusions:
– The study concludes that retrieval improves policies beyond specific backbones, particularly in Cosmos Policy, providing a reusable high-level motion prior for cross-embodiment generalization and outperforming baselines on unseen tasks.
👉 Paper link: https://huggingface.co/papers/2606.15631
10. PhoneHarness: Harnessing Phone-Use Agents through Mixed GUI, CLI, and Tool Actions
🔑 Keywords: PhoneHarness, phone-use agents, mixed-action benchmark, execution framework, deterministic action routing
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate phone-use agents on verifiable mobile workflows using a new mixed-action benchmark and execution framework called PhoneHarness.
🛠️ Research Methods:
– Development of PhoneHarness running device-side agent loops over GUI, CLI, and host-side actions, including deterministic action routing, bounded GUI delegation, and auditable execution traces.
💬 Research Conclusions:
– PhoneHarness demonstrated a 75.0% pass rate, outperforming other non-PhoneHarness settings by 12.9 percentage points, highlighting the importance of action-surface routing and verifiable execution over merely visual GUI control.
👉 Paper link: https://huggingface.co/papers/2606.14832

11. Tangram: Unlocking Non-Uniform KV Cache Compression for Efficient Multi-turn LLM Serving
🔑 Keywords: Key-Value cache, Non-uniform KV compression, Memory management, Decode latency, Tangram
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to address memory constraints in multi-turn large language model serving by introducing a structured approach for non-uniform compression, significantly improving throughput.
🛠️ Research Methods:
– Implementing Tangram, a serving framework that statically manages budget allocation and memory, offering innovative techniques like Budget Reservation, Ragged Paging, and Ahead-of-Time Load Balancing.
💬 Research Conclusions:
– The Tangram framework effectively enhances throughput up to 2.6 times over the standard baseline, aligning with existing non-uniform compression methods in accuracy, and is available for public use.
👉 Paper link: https://huggingface.co/papers/2606.06302

12. GD^2PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
🔑 Keywords: multi-dimensional rewards, reinforcement learning, Policy Optimization, conflict-aware filtering, query-level reweighting
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve reinforcement learning efficiency in large language models by optimizing multi-dimensional rewards using a conflict-aware filtering mechanism.
🛠️ Research Methods:
– Introduction of Group-Dynamic reward-Decoupled Policy Optimization (GD^2PO) to mask out conflicting rollouts and employ query-level reweighting to adjust update intensities.
💬 Research Conclusions:
– GD^2PO notably enhances learning efficiency and performance in multi-reward scenarios, outperforming existing methods like GDPO, with experiments demonstrating success in scenarios such as tool calling and human preference alignment.
👉 Paper link: https://huggingface.co/papers/2606.16771

13. Unstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
🔑 Keywords: Sparse autoencoders, feature stability, prediction-relevant signal, activation statistics, basis ambiguity
💡 Category: Machine Learning
🌟 Research Objective:
– The primary objective is to assess the reproducibility of features in Sparse autoencoders (SAEs) and their impact on neural network interpretation.
🛠️ Research Methods:
– The study involves estimating the probability of feature reproducibility across different training runs and examining the feature stability across various models, layers, and SAE variants.
💬 Research Conclusions:
– Stable SAE features carry most of the predictive and reconstruction-relevant signals, while unstable features, though weak individually, reflect reproducible low-dimensional structures and are affected by basis ambiguity.
– By pooling cross-seed features, more stable SAEs can be constructed without losing explained variance.
👉 Paper link: https://huggingface.co/papers/2606.12138

14. Hierarchical Advantage Weighting for Online RL Fine-Tuning of VLAs from Sparse Episode Outcomes
🔑 Keywords: Hierarchical Advantage-Weighted Behavior Cloning, sparse reward, intervention-aware credit assignment, critic heads, state-adaptive balance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to address the challenges of sparse reward in robot learning by optimizing the objectives of viability and efficiency separately.
🛠️ Research Methods:
– Utilizes Hierarchical Advantage-Weighted Behavior Cloning (HABC) with separate critic heads optimized for each objective, and applies intervention-aware credit assignment to improve supervision accuracy.
💬 Research Conclusions:
– HABC significantly enhances success rates in contact-rich manipulation tasks, outperforming supervised fine-tuning baselines on several real-robot experiments.
👉 Paper link: https://huggingface.co/papers/2606.17043

15. Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
🔑 Keywords: Prompt-Level Distillation, Chain-of-Thought prompting, interpretability, cross-architecture generalizability
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The main objective is to enhance student model performance by extracting reasoning patterns from teacher models while ensuring interpretability and reducing latency.
🛠️ Research Methods:
– The research introduces a method called Prompt-Level Distillation, which organizes extracted reasoning patterns into a structured list for a student’s System Prompt.
💬 Research Conclusions:
– The study demonstrates improved performance with increased Macro F1 scores on specific datasets and shows cross-architecture generalizability, enabling more efficient use in regulated industries and edge devices by providing transparency and human verification capability.
👉 Paper link: https://huggingface.co/papers/2602.21103

16. You Don’t Need Strong Assumptions: Visual Representation Learning via Temporal Differences
🔑 Keywords: Temporal Difference in Vision, Self-Supervised Learning, Inductive Biases, Causal Relationships, Visual Representation Learning
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to develop a novel self-supervised learning approach named Temporal Difference in Vision (TDV) for video data, which eliminates traditional inductive biases, leveraging causal relationships between past and future frames.
🛠️ Research Methods:
– TDV introduces a new paradigm for self-supervised learning by jointly training an image encoder and a motion encoder, ensuring that the current frame’s representation plus the encoded motion equals the next frame’s representation.
💬 Research Conclusions:
– TDV demonstrates that it is possible to match state-of-the-art performance on dense spatial tasks without utilizing strong inductive biases, suggesting a path forward for representation learning with fewer assumptions.
👉 Paper link: https://huggingface.co/papers/2606.15956

17. EgoPhys: Learning Generalizable Physics Models of Deformable Objects from Egocentric Video
🔑 Keywords: EgoPhys, deformable digital twin, egocentric RGB video, generalizable priors, inverse-physics solutions
💡 Category: Computer Vision
🌟 Research Objective:
– To address the challenge of predicting complex deformable dynamics using EgoPhys, enabling the generation of deformable digital twins from egocentric RGB-only video.
🛠️ Research Methods:
– Utilizing generalizable priors and compact codebooks for inverse-physics solutions to predict dense spring stiffness fields without per-spring optimization, based on diverse egocentric interactions.
💬 Research Conclusions:
– EgoPhys outperforms existing baselines in reconstruction, future prediction, and zero-shot generalization. Demonstrated deployment on a real xArm6 robot shows potential in aiding deformable-object planning, leveraging egocentric RGB video as a path toward scalable real-to-sim pipelines.
👉 Paper link: https://huggingface.co/papers/2606.16202

18. PermaVid: Consistent Video Generation Across Edits via Disentangled Context Memory
🔑 Keywords: PermaVid, multi-modal memory banks, consistent video generation, semantic appearance, geometric structure
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to address the challenge of maintaining long-term video consistency after edits by separating appearance and geometric structure, thereby enabling coherent video generation across time and viewpoints.
🛠️ Research Methods:
– The authors propose a framework called PermaVid, which utilizes a multi-modal context memory that differentiates spatial context into semantic appearance and geometric structure. They implement an edit-aware memory update and retrieval strategy and develop two complementary memory banks: an RGB context memory for appearance and a depth context memory for geometry.
💬 Research Conclusions:
– Experiments show that the proposed method maintains strong long-term semantic and structural consistency after edits, outperforming existing state-of-the-art methods.
👉 Paper link: https://huggingface.co/papers/2606.16449
19. Selective Control under Noisy Perception: Governance Failures Hidden by Aggregate Metrics in Modular Networks
🔑 Keywords: Content Moderation, Bridge Users, Governance Loss, False-Positive-Heavy Noise, Aggregate Accuracy
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The paper investigates the adverse effects of content moderation systems on bridge users who connect separate communities and assesses the governance loss in conditions with a high rate of false positives.
🛠️ Research Methods:
– Utilizes an agent-based model with 240 learning agents in a community-structured network to simulate posting and the application of a noisy classifier for moderation.
💬 Research Conclusions:
– Although standard accuracy metrics seem satisfactory, aggregate accuracy conceals the harm inflicted on bridge users. These users’ correct posts are suppressed wrongly, and harmful posts are spared, causing a significant increase in governance loss when mistakes are frequent.
👉 Paper link: https://huggingface.co/papers/2606.14819

20. LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
🔑 Keywords: LaWAM, Latent Visual Subgoals, Latent World Action Model, Robot Control, Low-Latency Inference
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To improve robot control efficiency by predicting latent visual subgoals instead of relying on expensive video generation for future prediction.
🛠️ Research Methods:
– Utilization of a latent-action-conditioned Latent World Model trained in the latent space of a pretrained vision foundation model to predict future observation features for scene evolution.
– Action generation conditioned on predicted latent visual subgoals for dynamics-aware control.
💬 Research Conclusions:
– LaWAM achieves state-of-the-art success rates in various robotics tasks with significantly reduced computational latency, running 24x faster than traditional pixel-space World-Action Models.
👉 Paper link: https://huggingface.co/papers/2606.15768

21. Attacks on Machine-Text Detectors Retain Stylistic Fingerprints
🔑 Keywords: machine-text detection, stylistic features, evasion strategies, few-shot detectors, multi-document analysis
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the limitations of evasion strategies in machine-text detection and assess the potential of stylistic features as a defense.
🛠️ Research Methods:
– Evaluation of current evasion techniques like prompt engineering and detector-guided optimization, and introduction of a novel paraphrasing approach.
💬 Research Conclusions:
– Stylistic features are robust against several detection evasion attempts but not foolproof. While few-shot detectors using stylistic analysis are effective, they can be evaded by paraphrasing methods. However, variance in human and machine text distribution can be highlighted through multi-document analysis.
👉 Paper link: https://huggingface.co/papers/2505.14608

22. The Ghosts of Polymarket: When Off-Chain Matches Meet On-Chain Reverts
🔑 Keywords: DeFi, Ghost Fills, Polymarket, Security, Attack Vectors
💡 Category: AI in Finance
🌟 Research Objective:
– To understand the security implications of the consistency gap known as Ghost Fills in the Polymarket prediction platform.
🛠️ Research Methods:
– Developed GHOSTHUNTER to reconstruct failed on-chain settlements and analyze attack patterns in 1,952,440 reverted match-order transactions.
💬 Research Conclusions:
– Identified four attack vectors and realized at least $1.49M in profit, highlighting significant vulnerabilities that affect over 167 independent contracts and extend beyond Polymarket.
👉 Paper link: https://huggingface.co/papers/2606.16852

23.

24. TuneJury: An Open Metric for Improving Music Generation Preference Alignment
🔑 Keywords: Text-to-Music, Pairwise Reward Model, Human-Preference Labels, Anchor Calibration, Frozen Reward
💡 Category: Generative Models
🌟 Research Objective:
– Introduction of TuneJury, an open-source pairwise reward model designed for text-to-music generation that generates music preference scores from text prompts and audio clips.
🛠️ Research Methods:
– The model is trained using public human-preference labels and employs a frozen reward mechanism enabling consistency across multiple applications, including anchor calibration for improved data efficiency.
💬 Research Conclusions:
– TuneJury achieves well-calibrated preference scoring, maintaining competitive performance on out-of-distribution benchmarks, and demonstrates utility in applications like inference-time best-of-N selection and latent optimization.
👉 Paper link: https://huggingface.co/papers/2606.17006

25. Human Universal Grasping
🔑 Keywords: flow-matching model, RGB-D image, zero-shot grasping, HUG-Bench, MANO hand pose
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The goal is to enable zero-shot robotic grasping by generating diverse human grasps from RGB-D images using a flow-matching model.
🛠️ Research Methods:
– Developed the HUG model to generate human-like grasps by collecting a large dataset using smart glasses and fusing RGB and depth data.
– Created the HUG-Bench simulated benchmark to evaluate the model’s performance on various unseen objects.
💬 Research Conclusions:
– The HUG model demonstrated superior performance, outpacing existing grasping baselines by up to 34% on challenging test sets.
👉 Paper link: https://huggingface.co/papers/2606.17054

26. Who Flips? Self- and Cross-Model Counterarguments Reveal Answer Instability in LLMs
🔑 Keywords: answer stability, large language models, self-attribution, flip rates, adversarial challenges
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the answer stability of large language models when faced with plausible counterarguments, beyond traditional accuracy metrics.
🛠️ Research Methods:
– Implemented a controlled protocol to measure flip rates, isolating argumentative content from social pressure, and varying argument length, self-attribution, and cross-model sources.
💬 Research Conclusions:
– Significant variation in model reliability was found, with flip rates ranging from 17.5% to 97.3%.
– Self-attribution increases flip rates.
– Pooling arguments across models enhances adversarial challenge strength.
– MaxFlip challenge set increases flip rates up to +23.6pp over standard challenges.
👉 Paper link: https://huggingface.co/papers/2606.16011

27. Implicit Reasoning for Large Language Model-based Generative Recommendation
🔑 Keywords: Large Language Models, Generative Recommendation, Semantic IDs, Implicit Reasoning, PauseRec
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address the challenges of using Large Language Models for generative recommendation by proposing a new lightweight implicit reasoning approach called PauseRec, which overcomes the limitations of explicit methods.
🛠️ Research Methods:
– The study decomposes existing explicit reasoning training pipelines for LLM-based generative recommendation to expose their limitations and proposes an innovative implicit reasoning paradigm, PauseRec, to improve performance and efficiency.
💬 Research Conclusions:
– PauseRec significantly outperforms traditional explicit reasoning methods by enhancing performance, reducing training costs, and speeding up inference, positioning it as an effective and efficient alternative for LLM-based generative recommendation.
👉 Paper link: https://huggingface.co/papers/2606.14142

28. ExpRL: Exploratory RL for LLM Mid-Training
🔑 Keywords: ExpRL, Sparse reward, Reinforcement learning, Language models, Math reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reinforcement learning priming for language models using ExpRL by implementing human-written question-answer data as reward scaffolds, specifically in math reasoning tasks.
🛠️ Research Methods:
– ExpRL employs large corpora of human-written question-answer data to automate mid-training reinforcement learning for language models, using these as reward scaffolds instead of targets to imitate.
💬 Research Conclusions:
– ExpRL outperforms traditional reinforcement learning methods such as SFT and GRPO in challenging math reasoning tasks and shows potential for broader applications beyond math-specific domains.
👉 Paper link: https://huggingface.co/papers/2606.17024

29. Artificial Intelligence Index Report 2026
🔑 Keywords: AI Index, Governance Frameworks, Generative AI, AI Sovereignty, AI in Science
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To investigate the gap between AI advancements and the readiness of systems designed to manage AI.
🛠️ Research Methods:
– Tracking ambitious testing of AI in reasoning, safety, and task execution.
– New estimates of generative AI’s economic value and labor market impacts.
– Analytical framework on AI sovereignty.
💬 Research Conclusions:
– There is a significant gap between AI capabilities and the preparedness of governance and evaluative structures.
– AI’s impact is expanding across various domains, notably in science and medicine.
👉 Paper link: https://huggingface.co/papers/2606.15708

30. Track2View: 4D-Consistent Camera-Controlled Video Generation via Paired 3D Point Tracks
🔑 Keywords: Track2View, 3D point tracks, spatiotemporal correspondences, video diffusion transformer, camera viewpoints
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to create a system called Track2View that can generate novel camera viewpoints from videos, focusing on enhancing visual quality and camera accuracy compared to existing methods.
🛠️ Research Methods:
– Track2View uses paired 3D point tracks to establish explicit spatiotemporal correspondences, alongside a video diffusion transformer and a dual-view track conditioner to ensure continuity and coherence between source and target camera views.
💬 Research Conclusions:
– Track2View demonstrated significant improvement in visual quality, view synchronization, and camera accuracy on a 400-video benchmark, reducing rotation error by 30-65% and translation error by 61-72% relative to leading baselines.
👉 Paper link: https://huggingface.co/papers/2606.15534

31. MMDiff: Extending Diffusion Transformers for Multi-Modal Generation
🔑 Keywords: MMDiff, multi-modal generative system, diffusion transformers, semantic segmentation, lightweight decoder
💡 Category: Generative Models
🌟 Research Objective:
– To transform frozen diffusion transformers into a multi-modal generative system using lightweight decoders to improve semantic segmentation and other perceptual tasks.
🛠️ Research Methods:
– Utilization of multi-timestep feature fusion with spatially varying aggregation weights and concept-driven attention extraction on a frozen backbone.
💬 Research Conclusions:
– MMDiff significantly enhances semantic segmentation results and enables effective large-scale synthetic data generation with strong performance in salient object detection and depth estimation.
👉 Paper link: https://huggingface.co/papers/2606.16673

32. MVEB: Massive Video Embedding Benchmark
🔑 Keywords: Video Embedding, Classification, Multi-Modal Learning, Zero-Shot Classification, Generative MLLMs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces the Massive Video Embedding Benchmark (MVEB) to evaluate diverse models across 23 different video understanding tasks, deriving insights into model performance across various domains.
🛠️ Research Methods:
– MVEB evaluates 33 models across tasks such as classification, zero-shot classification, clustering, retrieval, and video-centric question answering, comparing video-only with audio+video implementations to analyze audio impacts based on dataset annotation sources.
💬 Research Conclusions:
– Findings reveal that different models excel in specific tasks; MLLM-based embeddings are superior in classification and QA, while multimodal binding excels in retrieval. Audio enhances performance in multi-modal labeled datasets but reduces it in visually-labeled ones.
👉 Paper link: https://huggingface.co/papers/2606.14958

33. Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
🔑 Keywords: Nemotron 3 Ultra, Large-scale language model, Hybrid Mamba-Attention, Mixture-of-Experts, Supervised Fine Tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The development of Nemotron 3 Ultra, a highly capable language model with 550 billion parameters, designed to achieve high inference throughput and extended context length.
🛠️ Research Methods:
– Utilized specialized training techniques, including pre-training on 20 trillion text tokens, Supervised Fine Tuning, Reinforcement Learning, and Multi-teacher On-Policy Distillation.
💬 Research Conclusions:
– Nemotron 3 Ultra achieves up to ~6x higher inference throughput compared to other state-of-the-art language models, maintaining high accuracy and supporting long-context applications, with resources available for public use on HuggingFace.
👉 Paper link: https://huggingface.co/papers/2606.15007

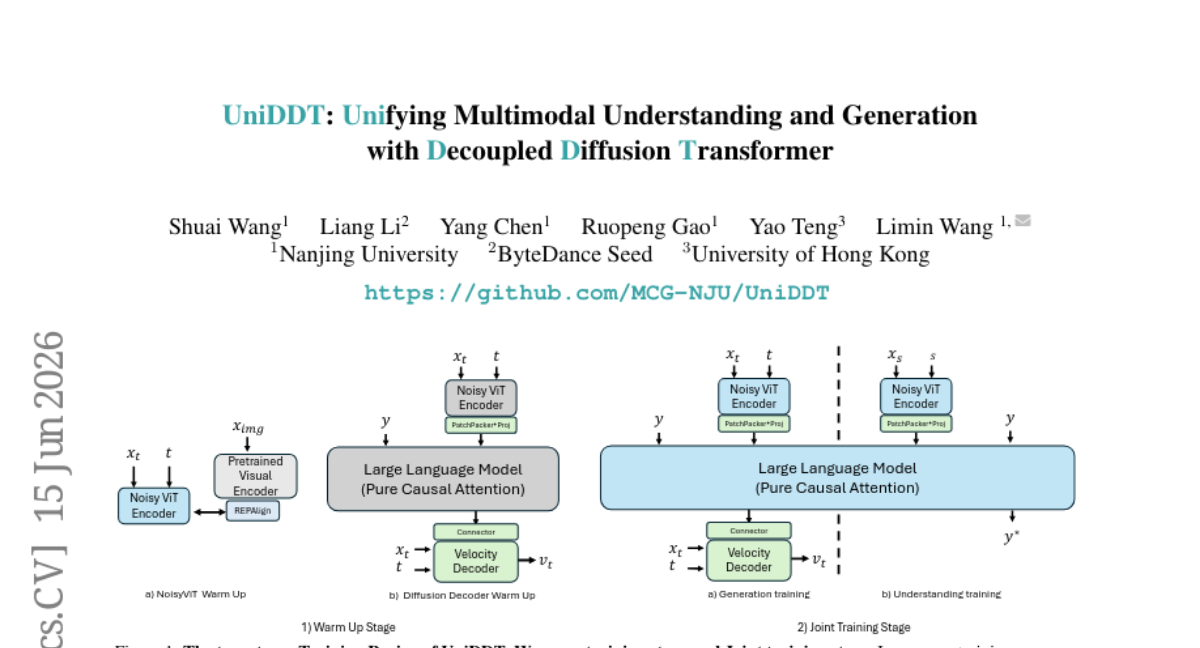
34. UniDDT: Unifying Multimodal Understanding and Generation with Decoupled Diffusion Transformer
🔑 Keywords: Unified Multimodal Models, Noisy ViT encoder, semantic encoding, diffusion decoder, multimodal understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– UniDDT aims to overcome challenges in unified multimodal models, integrating visual understanding and generation tasks using a Noisy ViT encoder and separate diffusion decoders.
🛠️ Research Methods:
– The study utilizes a Noisy ViT encoder and an LLM for semantic encoding, employing separate diffusion decoders to balance tasks, and constructing dual data structures for text-image pairs.
💬 Research Conclusions:
– UniDDT successfully unifies multimodal understanding and generation with enhanced semantic consistency and scalability, achieving high scores in both visual generation and multimodal understanding benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.16255
35. Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
🔑 Keywords: agentic intelligence, scalable solutions, fast response times, advanced reasoning, open-source
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To present Ling-2.6 and Ring-2.6 models as scalable solutions for delivering both low-latency responses and strong reasoning capabilities in agentic intelligence.
🛠️ Research Methods:
– Architectural upgrades and specialized training methods including architectural migration pre-training and large-scale post-training, hybrid linear attention design, and reinforcement learning framework KPop.
💬 Research Conclusions:
– Ling-2.6 is optimized for instant response, while Ring-2.6 focuses on deeper reasoning. The models integrate multiple enhancements to improve capability and efficiency, providing a practical path for scalable, open agentic systems, and are open-sourced to support further research.
👉 Paper link: https://huggingface.co/papers/2606.15079

36. Where Did It Go Wrong? Process-Level Evaluation of Web Agents with Semantic State Tracking
🔑 Keywords: Web agents, semantic MDP, process-level analysis, exploration reach, execution accuracy
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enable a process-level analysis of web agents using the WebStep benchmark for detailed performance differentiation and error localization beyond terminal success metrics.
🛠️ Research Methods:
– Introduced the WebStep benchmark with 1,800 task instances characterized by controlled difficulty and automatic semantic state tracking.
– Analyzed semantic trajectories to reveal performance differences and conducted decompositional and bifurcation analysis for skill-specific differentiation and error localization.
💬 Research Conclusions:
– Process metrics reveal significant differences in agent performance not visible through outcome evaluation alone.
– Analysis showed skill-specific performance variations, highlighting areas for targeted improvement within web agents.
– Demonstrated that increased task difficulty exacerbates performance differences among agents.
👉 Paper link: https://huggingface.co/papers/2606.15673

37. Memento: Reconstruct to Remember for Consistent Long Video Generation
🔑 Keywords: Memento, memory-based reconstruction, subject preservation, dual-query mechanism, visual quality
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to improve long-form video generation by maintaining consistency of recurring subjects through a framework called Memento, which focuses on subject preservation as an identity grounding problem.
🛠️ Research Methods:
– The method involves a memory-based subject reconstruction approach, jointly training autoregressive next-shot generation with historical memory and global captions.
– A dual-query memory mechanism is used to differentiate long-range subject evidence from short-range cues for coherent continuation.
💬 Research Conclusions:
– Memento achieves state-of-the-art results in maintaining long-term subject consistency, cross-shot coherence, and enhancing visual quality in video generation.
👉 Paper link: https://huggingface.co/papers/2606.14667
38. TokenPilot: Cache-Efficient Context Management for LLM Agents
🔑 Keywords: TokenPilot, context management, inference costs, Lifecycle-Aware Eviction, Ingestion-Aware Compaction
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to introduce TokenPilot, a dual-granularity context management framework, to reduce inference costs in long-horizon large language model (LLM) sessions by stabilizing prompt prefixes and managing context segments conservatively.
🛠️ Research Methods:
– TokenPilot uses Ingestion-Aware Compaction to stabilize prompt prefixes and mitigate environmental noise at the ingestion gate, and Lifecycle-Aware Eviction to monitor context segment utility, ensuring segments are offloaded only when no longer relevant.
💬 Research Conclusions:
– TokenPilot demonstrates a significant reduction in costs of 61% and 56% in isolated mode and 61% and 87% in continuous mode, maintaining competitive performance compared to existing systems, and it is integrated into the LightMem2 platform.
👉 Paper link: https://huggingface.co/papers/2606.17016

39. Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
🔑 Keywords: Qwen-RobotWorld, language-conditioned video world model, embodied intelligence, double-stream diffusion transformer, Embodied World Knowledge
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to introduce Qwen-RobotWorld, a language-conditioned video world model designed for predicting physically grounded future visual trajectories across various robotic domains using a unified action interface.
🛠️ Research Methods:
– Utilizes a three-part design: Double-Stream MMDiT with MLLM Action Encoding, Embodied World Knowledge (EWK) corpus, and General+Expert Progressive Curriculum for training.
💬 Research Conclusions:
– The model demonstrates strong competitiveness, ranking first on multiple benchmarks such as EWMBench and DreamGen Bench, and shows robust generalization and multi-view consistency through zero-shot analyses.
👉 Paper link: https://huggingface.co/papers/2606.17030

40. OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
🔑 Keywords: Transformer-native, Multi-task learning, Recommender systems, Task-private channels, Dynamic matching-based scoring
💡 Category: AI Systems and Tools
🌟 Research Objective:
– OneRank presents a Transformer-native multi-task learning framework to reduce inter-task interference and improve ranking performance in recommender systems.
🛠️ Research Methods:
– The framework eliminates the separation between encoder and predictor by introducing task-private channels for task-specialized learning, enabling task-specific representation learning and backward optimization.
💬 Research Conclusions:
– OneRank unifies and scales the architectural paradigm, significantly outperforming state-of-the-art baselines in both offline and online experiments on large-scale datasets while maintaining computational efficiency.
👉 Paper link: https://huggingface.co/papers/2606.16838

41. Who Should Lead Decoding Now? Tracking Reliable Trajectories for Ensembling Masked Diffusion Language Models
🔑 Keywords: Masked Diffusion Language Models, decoding dynamics, confidence dynamics, Trajectory-based Iterative Ensembling
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the unique decoding dynamics of Masked Diffusion Language Models (MDLMs) and explore ways to combine their diverse capabilities and knowledge.
🛠️ Research Methods:
– Proposed TIE (Trajectory-based Iterative Ensembling) to track confidence dynamics over answer-relevant positions and iteratively transfer reliable decoding trajectories between models.
💬 Research Conclusions:
– TIE allows models to contribute complementary strengths and provides a practical approach to addressing the ensembling problem in MDLMs, showcasing strong performance across diverse reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2606.16281

42. VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
🔑 Keywords: VibeThinker-3B, verifiable reasoning, Spectrum-to-Signal, curriculum-based supervised fine-tuning, multi-domain reinforcement learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The primary objective is to demonstrate how compact models like VibeThinker-3B can achieve state-of-the-art performance on verifiable reasoning tasks through specialized training techniques.
🛠️ Research Methods:
– Utilization of a specialized pipeline that includes curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation to enhance the model.
💬 Research Conclusions:
– VibeThinker-3B achieves frontier-level performance on demanding reasoning tasks and attains high scores in various benchmarks, challenging larger models.
– It supports the Parametric Compression-Coverage Hypothesis, suggesting compact models are efficient yet capable of high-level performance in dense capability regimes without compromising instruction controllability.
👉 Paper link: https://huggingface.co/papers/2606.16140

43. DreamX-World 1.0: A General-Purpose Interactive World Model
🔑 Keywords: DreamX-World 1.0, interactive text/image-to-video, camera control, long-horizon generation, Event Instruction Tuning
💡 Category: Generative Models
🌟 Research Objective:
– Develop DreamX-World 1.0 as an interactive text/image-to-video model that facilitates controllable, long-horizon video content generation with camera control.
🛠️ Research Methods:
– Employ techniques such as E-PRoPE for camera geometry, causal forcing, and long-rollout training to create a robust world model.
– Use a combination of Unreal Engine rendering, gameplay recordings, and real-world videos for data collection.
– Incorporate Memory-Conditioned Scene Persistence and Event Instruction Tuning for enhanced control and scene consistency.
💬 Research Conclusions:
– DreamX-World 1.0 achieves high scores in camera control and overall performance, surpassing existing models like HY-WorldPlay 1.5 and LingBot-World.
– The model successfully handles extended video generation scenarios while maintaining visual quality and event control.
👉 Paper link: https://huggingface.co/papers/2606.16993
44. Data Journalist Agent: Transforming Data into Verifiable Multimodal Stories
🔑 Keywords: Data Journalism, Multi-Agent Framework, Transparency, Verifiability, Evidence-Grounded
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to automate the process of data journalism by implementing Data2Story, a multi-agent framework that generates evidence-grounded and multimodal news stories.
🛠️ Research Methods:
– The study introduces two main innovations: evidence-grounded claims using an Inspector, and multimodal generative articles. It evaluates the system on 18 articles using criteria such as coverage, rubric evaluation, interactive navigation, and verifiability.
💬 Research Conclusions:
– Data2Story successfully creates competitive and evidence-traceable multimedia stories, enhancing transparency and auditability. It serves as a journalist collaborator, focusing on evidence-based and verifiable reporting while human journalists maintain an edge in creative aspects.
👉 Paper link: https://huggingface.co/papers/2606.11176