AI Native Daily Paper Digest – 20260617

1. LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
🔑 Keywords: Parallel loop Transformers, code generation, cross-loop position offsets, LoopCoder-v2, gain–cost trade-off
💡 Category: Generative Models
🌟 Research Objective:
– To study the optimal loop-count selection in Parallel loop Transformers (PLT) for improved code generation performance.
🛠️ Research Methods:
– Developed LoopCoder-v2, a family of 7B PLT coders, trained on 18T tokens with various loop counts, followed by instruction tuning and evaluation.
💬 Research Conclusions:
– The two-loop PLT variant significantly outperforms non-looped baselines in code generation and associated benchmarks, while additional loops cause diminishing returns and positional mismatch costs. The gain-cost trade-off analysis explains the performance saturation at two loops.
👉 Paper link: https://huggingface.co/papers/2606.18023

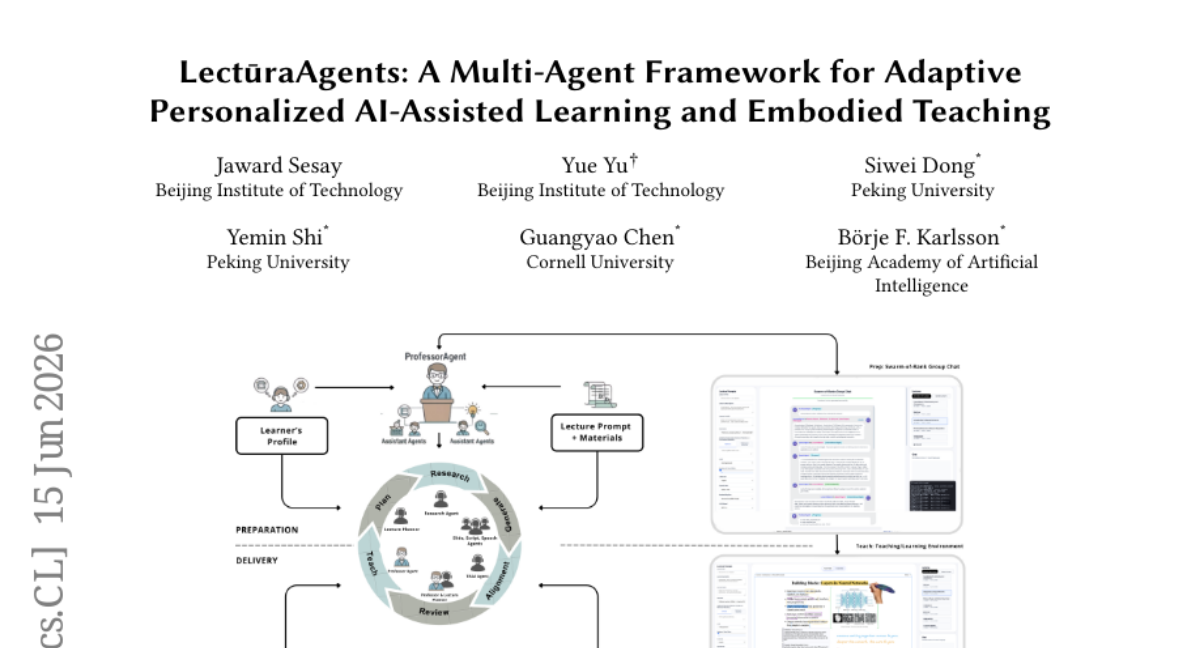
2. LectūraAgents: A Multi-Agent Framework for Adaptive Personalized AI-Assisted Learning and Embodied Teaching
🔑 Keywords: Multi-agent Framework, Personalized Learning, Embodied Teaching, ProfessorAgent, Teaching Action-Speech Alignment
💡 Category: AI in Education
🌟 Research Objective:
– To develop LectūraAgents, a multi-agent framework enabling personalized learning through adaptive embodied teaching.
🛠️ Research Methods:
– Implementation of a hierarchical multi-agent architecture for personalized learning.
– Development of an adaptive mechanism for embodied teaching led by a ProfessorAgent.
– Introduction of the Teaching Action-Speech Alignment (TASA) algorithm using salience-based heuristics and temporal semantic segmentation.
💬 Research Conclusions:
– LectūraAgents framework improved lecture content quality, embodied teaching effectiveness, assessment accuracy, and personalization, providing a robust solution for scalable personalized learning.
👉 Paper link: https://huggingface.co/papers/2606.16428
3. ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
🔑 Keywords: Vision-Language-Action, egocentric human videos, pseudo-action trajectories, unified action representation, reliability-aware training objective
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces ACE-EGO-0, a unified Vision-Language-Action pretraining framework to enhance performance on embodied AI tasks by integrating diverse data sources such as egocentric human videos and robot trajectories.
🛠️ Research Methods:
– The framework utilizes a scalable egocentric video-to-action pipeline to convert human videos into robot-format pseudo-action trajectories. It employs a unified action representation and incorporates a reliability-aware training objective with a human auxiliary loss.
💬 Research Conclusions:
– The ACE-EGO-0 framework demonstrates improved joint pretraining and supervised fine-tuning, achieving state-of-the-art performance on specific tasks and showing strong transfer capabilities to real-world bimanual manipulation scenarios.
👉 Paper link: https://huggingface.co/papers/2606.17200

4. Learning from the Self-future: On-policy Self-distillation for dLLMs
🔑 Keywords: diffusion language models, on-policy self-distillation, self-teacher construction, sample efficiency, suffix conditioning
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces d-OPSD, a new on-policy self-distillation framework specifically designed for diffusion language models (dLLMs).
🛠️ Research Methods:
– The approach adapts self-teacher construction using self-generated answers as suffix conditioning and shifts supervision from token-level to step-level to align with dLLM’s iterative denoising process.
💬 Research Conclusions:
– d-OPSD significantly outperforms existing RLVR and SFT baselines on reasoning benchmarks, achieving superior sample efficiency and requiring only about 10% of the optimization steps used by RLVR.
👉 Paper link: https://huggingface.co/papers/2606.18195

5. Show the Signal, Hide the Noise: Spectral Forcing for Pixel-Space Diffusion
🔑 Keywords: Spectral Forcing, Pixel-space, diffusion models, 2D-DCT, frequency-time
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance diffusion model efficiency by explicitly separating signal from noise using a Spectral Forcing method.
🛠️ Research Methods:
– The researchers introduced a time-conditional 2D-DCT low-pass operator called Spectral Forcing, applied to noisy inputs to clarify the bandwidth boundary in diffusion processes.
💬 Research Conclusions:
– The Spectral Forcing method improves FID and Inception Score in ImageNet-256 experiments, indicating robust gains in efficiency. Additionally, it demonstrates effectiveness in unified text-to-image models, suggesting its broader applicability.
👉 Paper link: https://huggingface.co/papers/2606.15236

6. Rethinking the Role of Efficient Attention in Hybrid Architectures
🔑 Keywords: Hybrid Architectures, Efficient Attention, Full Attention, Long-Context Capabilities, Large-Window Laziness
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically analyze hybrid architectures that blend full attention with efficient attention modules to understand their impact on model capabilities.
🛠️ Research Methods:
– Conduct a systematic analysis from three perspectives: scaling behavior, mechanism analysis, and architecture design.
💬 Research Conclusions:
– Efficient attention modules influence the speed at which long-context capabilities emerge, though not the eventual performance.
– Full attention mainly supports long-range retrieval, while efficient attention shapes the optimization trajectory, revealing the Large-Window Laziness phenomenon.
– Applying NoPE to only full-attention layers in a small-window SWA hybrid enhances long-context performance without affecting short-context capabilities.
👉 Paper link: https://huggingface.co/papers/2606.15378

7. EgoCS-400K: An Egocentric Gameplay Dataset for World Models
🔑 Keywords: EgoCS-400K, egocentric, world models, replay-grounded, video-action-language trajectories
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce EgoCS-400K, a large-scale egocentric Counter-Strike dataset, to bridge the gap between passive web videos and costly real-world embodied data by providing temporally aligned video-action-language trajectories.
🛠️ Research Methods:
– Utilize public professional CS and CS2 match demos to extract player states, actions, and game events, enabling the parsing, replaying, rendering, and temporal alignment of first-person videos.
💬 Research Conclusions:
– EgoCS-400K supports a range of interactive visual modeling tasks by connecting visual observations with human actions, camera motion, game states, and events on a large scale, serving as a bridge between various data types and applications.
👉 Paper link: https://huggingface.co/papers/2606.18180

8. Unified Multimodal Autoregressive Modeling with Shared Context-Visual Tokenizer is Key to Unification
🔑 Keywords: UniAR, unified autoregressive framework, visual tokenizer, multi-level feature fusion, bitwise quantization
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the research is to create a unified autoregressive framework that integrates visual understanding and generation using a single discrete visual tokenizer.
🛠️ Research Methods:
– The research uses a pretrained vision encoder with multi-level feature fusion and a lookup-free bitwise quantization scheme, along with parallel-bitwise-prediction for efficient visual code prediction and a diffusion-based visual decoder.
💬 Research Conclusions:
– UniAR achieves state-of-the-art performance in image generation and editing, effectively reducing visual sequence length and enhancing processing speed, while remaining competitive on multimodal understanding benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.18249

9. ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
🔑 Keywords: ChLogic, Large Language Models, Logical Reasoning, Surface Realization, Multilingual Reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces ChLogic, a benchmark designed to assess whether large language models maintain logical reasoning abilities across English and Chinese, highlighting differences influenced by surface realization and translation artifacts.
🛠️ Research Methods:
– ChLogic comprises three datasets built from formal logical templates, including a General aligned set, a Difficult aligned set, and a Chinese-only set to analyze language-specific phenomena.
💬 Research Conclusions:
– Experiments show a consistent performance gap between English and Chinese, with back-translation improving results in some cases but worsening in others. The findings affirm that surface realization and translation artifacts impact the logical reasoning performance of multilingual models.
👉 Paper link: https://huggingface.co/papers/2606.17905

10. Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
🔑 Keywords: Visual-Seeker, visual-native, multimodal deep search, active visual reasoning, state-of-the-art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address limitations in existing multimodal deep search by introducing Visual-Seeker, a visual-native multimodal deep search agent that utilizes active visual reasoning.
🛠️ Research Methods:
– Development of an active visual reasoning data pipeline and the synthesis of 5K high-quality multimodal trajectories for training.
💬 Research Conclusions:
– Visual-Seeker demonstrates state-of-the-art performance across multiple multimodal search benchmarks, surpassing several proprietary models and showcasing robust visual-native reasoning and search capabilities in real-world web environments.
👉 Paper link: https://huggingface.co/papers/2606.15231

11. ProCUA-SFT Technical Report
🔑 Keywords: computer-use agents, synthetic dataset, supervised fine-tuning, OSWorld, step-prefix samples
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance the training of computer-use agents by leveraging a large-scale, synthetic dataset, ProCUA-SFT, to improve performance on desktop interaction benchmarks.
🛠️ Research Methods:
– Developed an automated pipeline to generate and verify synthetic task trajectories involving real-world content across diverse application combinations, using a VLM to align tasks for seamless execution.
💬 Research Conclusions:
– Fine-tuning UI-TARS 7B with ProCUA-SFT significantly boosts OSWorld success rates from a base model’s 26.3% to 45.0%, outperforming previous AgentNet-trained models by over 35%.
👉 Paper link: https://huggingface.co/papers/2606.17321

12. Variable-Width Transformers
🔑 Keywords: Transformer architecture, nonuniform width, language models, residual resizing mechanism, resource-optimal scaling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to explore nonuniform capacity allocation across different layers of transformer-based language models to enhance performance and efficiency.
🛠️ Research Methods:
– Introduces a novel transformer architecture, called > <former, which adjusts layer widths nonuniformly—wider early and late layers, narrower middle layers—combined with a parameter-free residual resizing mechanism.
💬 Research Conclusions:
– The proposed architecture outperforms traditional uniform-width models, achieving better language modeling loss while using fewer FLOPs and reducing KV cache memory and I/O costs, indicating more resource-optimal model scaling.
👉 Paper link: https://huggingface.co/papers/2606.18246

13. Aligning Quantum Operators with Large Language Models
🔑 Keywords: Large Language Models, Quantum Operators, Unitary Matrices, Quantum Circuit Synthesis, Language-conditioned Synthesis
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– To enable Large Language Models to understand and reason about quantum operators by mapping unitary matrices into their latent space.
🛠️ Research Methods:
– Developed an approach for integrating unitary operators into the latent space of an LLM, specifically applied to Clifford+T circuit synthesis over a Pauli rotation gate set.
💬 Research Conclusions:
– The model shows competitive results with state-of-the-art methods, scaling effectively with training data, and facilitates language-conditioned synthesis for quantum circuits which could influence quantum compilation and algorithm discovery.
👉 Paper link: https://huggingface.co/papers/2606.13811

14. Verified Detection and Prevention of Concurrency Anomalies in Multi-Agent Large Language Model Systems
🔑 Keywords: Multi-agent LLM systems, Concurrency Anomalies, Deterministic-generation Semantics, TLA+
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To analyze multi-agent LLM systems with shared state through formal methods, identifying concurrency anomalies and establishing a verified consistency hierarchy.
🛠️ Research Methods:
– Model shared states as long-running operations under deterministic-generation semantics, formalize concurrency anomalies in TLA+, and verify consistency hierarchy through mechanized proofs.
💬 Research Conclusions:
– Successfully identified and mechanized proofs for concurrency anomalies, developed a consistency hierarchy, and verified runtime detectors and refinements for classical isolation anomalies in multi-agent LLM systems.
👉 Paper link: https://huggingface.co/papers/2606.17182

15. RefGC-SR^2: Reference-guided Generated Content Super-Resolution and Refinement
🔑 Keywords: Reference-guided generation, high-resolution reference image, generative artifacts, diffusion transformer, super-resolution-refinement
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to introduce a new task termed “reference-guided generated content super-resolution-refinement” (RefGC-SR^2) that simultaneously refines artifacts and recovers high-resolution details in generative content.
🛠️ Research Methods:
– The research develops a frequency-aware diffusion transformer model to selectively provide fine details and remove artifacts, constructing the first real-world triplet data pipeline for training.
💬 Research Conclusions:
– The RefGC-SR^2 model effectively refines object identity and recovers high-resolution details, outperforming existing reference-guided generated content refinement and super-resolution methods in quality and usability.
👉 Paper link: https://huggingface.co/papers/2606.15158

16.

17. The Price of Anarchy in Disaggregated Inference
🔑 Keywords: Disaggregated inference, GPU pools, game-theoretic analysis, adaptive controller, saturation transitions
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To optimize routing and reduce latency in disaggregated inference systems by understanding GPU saturation effects through game-theoretic analysis.
🛠️ Research Methods:
– Utilized game-theoretic modeling in NVIDIA Dynamo as a case study to analyze disaggregated serving mechanics, evaluating three coupled games involving resource allocation, caching, and congestion.
💬 Research Conclusions:
– Developed an adaptive controller that adjusts routing based on real-time saturation states, notably improving performance by reducing the Price of Anarchy and throughput costs in specific model topologies.
👉 Paper link: https://huggingface.co/papers/2606.17081

18. MotionVLA: Vision-Language-Action Model for Humanoid Motion
🔑 Keywords: Dual-stream frequency tokenizer, Autoregressive model, Realistic humanoid motion, DCT coefficients, Qwen3.5-based model
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve humanoid motion generation by separately encoding pose and physical dynamics, enhancing diversity and consistency compared to single-codebook methods.
🛠️ Research Methods:
– The researchers propose DSFT, a dual-stream frequency tokenizer that separates motion into Base and physical streams, compressing them independently using DCT truncation and BPE.
– They introduce MotionVLA, a model based on Qwen3.5, arranging Base and physical tokens in a unified sequence for efficient modeling.
💬 Research Conclusions:
– The study demonstrates that MotionVLA reduces the diversity gap to real data by over 50% on the HumanML3D dataset and enhances motion-condition consistency by 3.8% on the MBench dataset, supporting the effectiveness of frequency-aware dual-stream decoupling in autoregressive motion generation.
👉 Paper link: https://huggingface.co/papers/2606.15142

19. Beyond Scalar Distances: Semantic Attribute Gradients from Frozen MLLMs for Visual Embeddings
🔑 Keywords: SAGA framework, multimodal large language models, zero-shot image retrieval, Group Relative Policy Optimization, Vision encoders
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance zero-shot image retrieval performance using a framework called SAGA that incorporates multimodal large language models for attribute-aware supervision in training vision encoders.
🛠️ Research Methods:
– Utilization of Group Relative Policy Optimization to reward correct attribute-based predictions.
– Incorporation of auxiliary attention-distillation loss and metric-learning loss to improve embedding geometry.
💬 Research Conclusions:
– SAGA framework achieves a 3 to 6-point improvement in Recall@1 over state-of-the-art baselines for zero-shot image retrieval tasks on multiple datasets such as CUB-200-2011, Cars-196, FGVC-Aircraft, and iNaturalist Aves.
👉 Paper link: https://huggingface.co/papers/2606.15134

20. RepSelect: Robust LLM Unlearning via Representation Selectivity
🔑 Keywords: LLMs, Unlearning, Representation Selectivity, Principal Components, Fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance the unlearning capability of Large Language Models (LLMs) by deeply forgetting specific information without compromising their general functionality.
🛠️ Research Methods:
– Introduced RepSelect, which isolates forget-set-specific representations by collapsing top principal components of weight gradients to maintain general capabilities and diminish recoverability through fine-tuning.
💬 Research Conclusions:
– RepSelect demonstrated superior performance, achieving a 4-50x larger reduction in post-relearning answer accuracy compared to existing methods and exhibiting robustness against few-shot prompting attacks. It represents a significant advancement in achieving selective and robust forgetting in LLMs.
👉 Paper link: https://huggingface.co/papers/2606.17168

21. Beyond Monolingual Deep Research: Evaluating Agents and Retrievers with Cross-Lingual BrowseComp-Plus
🔑 Keywords: Cross-lingual setting, Deep research agents, Multilingual setting, Evidence recall, Calibration
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces XBCP (Cross-lingual BrowseComp-Plus) to evaluate the performance of research agents searching for evidence across different languages, addressing the performance degradation when evidence language differs from the query.
🛠️ Research Methods:
– Evaluation of four deep research agents using sparse and dense multilingual retrievers to measure metrics such as answer accuracy, evidence recall, search behavior, calibration, citation fidelity, and oracle retrieval in both cross-lingual and multilingual settings.
💬 Research Conclusions:
– There is substantial performance degradation when evidence is translated, even with strong retrievers, highlighting the challenge of integrating language-mismatched evidence, with accuracy remaining lower despite the direct supply of gold evidence.
👉 Paper link: https://huggingface.co/papers/2606.15345

22. ActWorld: From Explorable to Interactive World Model via Action-Aware Memory
🔑 Keywords: Interactive world models, navigation-centric generators, object interaction, action-aware memory, persistent memory bank
💡 Category: Generative Models
🌟 Research Objective:
– Introduce ActWorld to extend navigation-centric interactive world models for object interaction through a chunk-autoregressive framework.
🛠️ Research Methods:
– Constructed a 100K interaction video dataset, annotated with per-chunk captions using chain-of-thought reasoning.
– Developed a hierarchical action-aware memory design complemented by a persistent memory bank.
💬 Research Conclusions:
– ActWorld improves interaction fidelity by supporting flexible navigation and rich object interaction within a single model, surpassing navigation-only baselines without losing viewpoint control.
👉 Paper link: https://huggingface.co/papers/2606.17730

23. A Gradient Perspective on RLVR Stability and Winner Advantage Policy Optimization
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Token-Level Gradient Dynamics, Policy Optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to address training instability in Reinforcement Learning with Verifiable Rewards (RLVR), particularly in systems using GRPO-style optimization prone to collapse.
🛠️ Research Methods:
– Analyzes token-level gradient dynamics to derive a taxonomy that predicts the impact of updates on next-token probabilities and entropy.
– Proposes Winner Advantage Policy Optimization (WAPO) as a solution, which updates on positive-advantage completions to improve stability.
💬 Research Conclusions:
– WAPO improves training stability in mathematical reasoning and multi-hop QA benchmarks, matching or outperforming existing baselines across multiple model families.
👉 Paper link: https://huggingface.co/papers/2606.16154

24. Dr-DCI: Scaling Direct Corpus Interaction via Dynamic Workspace Expansion
🔑 Keywords: DR-DCI, Direct Corpus Interaction, agentic search, scalability, retrieval
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to enhance agentic search across large corpora by combining retrieval with Direct Corpus Interaction (DCI) through the DR-DCI framework, allowing scalable and efficient search operations.
🛠️ Research Methods:
– DR-DCI utilizes a retriever-steered approach to dynamically pull relevant documents into a local workspace, where DCI operations are conducted for flexible search, filtering, and verification.
💬 Research Conclusions:
– DR-DCI demonstrates improved accuracy and efficiency, reaching up to 73.3% accuracy in certain benchmarks and maintaining effectiveness across corpus sizes from 100K to 20M documents, outperforming raw DCI and traditional retrieval methods.
👉 Paper link: https://huggingface.co/papers/2606.14885

25. Looped World Models
🔑 Keywords: Looped World Models, parameter efficiency, latent state refinement, shared transformer blocks, adaptive computation
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper introduces Looped World Models (LoopWM) to solve the problem of balancing deep computation requirements and deployment costs in world simulations by enhancing latent state refinement.
🛠️ Research Methods:
– This approach uses a shared transformer block to iteratively refine latent environment states, achieving up to 100x parameter efficiency and adapting computational depth based on prediction complexity.
💬 Research Conclusions:
– LoopWM offers a new scaling axis through iterative latent depth, potentially making a significant impact on the field by offering an efficient alternative to conventional model scaling methods.
👉 Paper link: https://huggingface.co/papers/2606.18208

26. Self-Evolving Visual Questioner
🔑 Keywords: Vision-language models, Self-evolving framework, Autonomous question generation, Visual-centric questions, Agentic protocol
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve the question-generation capabilities of Vision-language models through a self-evolution process without external supervision.
🛠️ Research Methods:
– Introduction of a self-evolving framework where the model acts as both proposer and filter to generate high-quality questions, maintaining exploration diversity to prevent training collapse.
– Implementation of an agentic protocol to evaluate questions based on perception, reasoning, and diversity.
💬 Research Conclusions:
– The proposed method significantly enhances question quality and expands the difficulty boundary for question generation.
– The self-evolving model demonstrates effective self-supervision and remains competitive as an answerer.
👉 Paper link: https://huggingface.co/papers/2606.13929

27. Text-Vision Co-Instructed Image Editing
🔑 Keywords: Text-Vision Co-Instructed Image Editing, semantic intent, spatial guidance, TV-Edit, cross-modal instruction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a unified text-visual image editing framework that combines semantic intent from textual instructions with spatial guidance from visual prompts for precise and faithful image manipulation.
🛠️ Research Methods:
– Construct a paired dataset of textual-visual instructions with over 23K samples.
– Propose TV-Edit framework to integrate semantic and spatial constraints into editing processes.
– Establish TV-Edit-Bench as a benchmark to evaluate semantic faithfulness, spatial alignment, and visual consistency.
💬 Research Conclusions:
– TV-Edit enables more precise spatial control and reduces instruction ambiguity compared to existing text-only or drag-based methods.
– Experiment results show TV-Edit significantly outperforms state-of-the-art methods in generating intent-faithful edits.
👉 Paper link: https://huggingface.co/papers/2606.16767

28. OPD-Evolver: Cultivating Holistic Agent Evolver via On-Policy Distillation
🔑 Keywords: OPD-Evolver, slow-fast co-evolution, on-policy self-distillation, memory management, agent evolver
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces OPD-Evolver, a self-evolving agent framework designed to improve memory management and policy learning through slow-fast co-evolution combined with on-policy self-distillation.
🛠️ Research Methods:
– Utilizes a four-level memory hierarchy within a fast loop to enable rapid test-time evolution and a slow loop to distill capabilities into deployable policies with outcome-calibrated memory attribution and privileged hindsight.
💬 Research Conclusions:
– OPD-Evolver outperforms existing memory systems and training-based methods, demonstrating capabilities in memory management and challenging larger models, moving beyond memory-augmented agents to truly qualify as agent evolvers.
👉 Paper link: https://huggingface.co/papers/2606.17628

29. TRIAGE: Dialectical Reasoning for Explainable Risk Prediction on Irregularly Sampled Medical Time Series with LLMs
🔑 Keywords: TRIAGE, Clinical early warning systems, Large Language Models, Risk polarization, Dialectical reasoning
💡 Category: AI in Healthcare
🌟 Research Objective:
– The paper proposes a framework named TRIAGE aiming to enhance clinical early warning systems by using large language models for generating dialectical reasoning to provide better calibration and interpretability in risk scoring.
🛠️ Research Methods:
– The TRIAGE framework trains an LLM to use dialectical reasoning for evaluating competing clinical outcomes, tested on three ISMTS benchmarks to mitigate risk polarization and improve risk scoring.
💬 Research Conclusions:
– TRIAGE yields a 3.3% average AUPRC improvement and reduces calibration error by 81% compared to competitive baselines, with rationales demonstrating a 20% improvement in clinical reasoning quality over baseline explanations.
👉 Paper link: https://huggingface.co/papers/2606.09030

30. GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?
🔑 Keywords: End-to-end game generation, coding agents, natural-language specifications, Engine Grounding, Interactive Verification
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to tackle the challenge of end-to-end game generation by creating complete playable games from natural language descriptions, meeting criteria like Engine Grounding, Artifact Completeness, and Interactive Verification.
🛠️ Research Methods:
– The study proposes an interaction-grounded evaluation framework utilizing replayed demonstrations and rubric-guided multimodal judging, instantiated as GameCraft-Bench, which includes 140 tasks across 15 game families using the Godot engine.
💬 Research Conclusions:
– Evaluations demonstrate that current coding agents find end-to-end game generation highly challenging, with top agents achieving a 41.46% success rate, indicating difficulties in delivering complete games with adequate content, functional visuals, and coherent presentation.
👉 Paper link: https://huggingface.co/papers/2606.17861

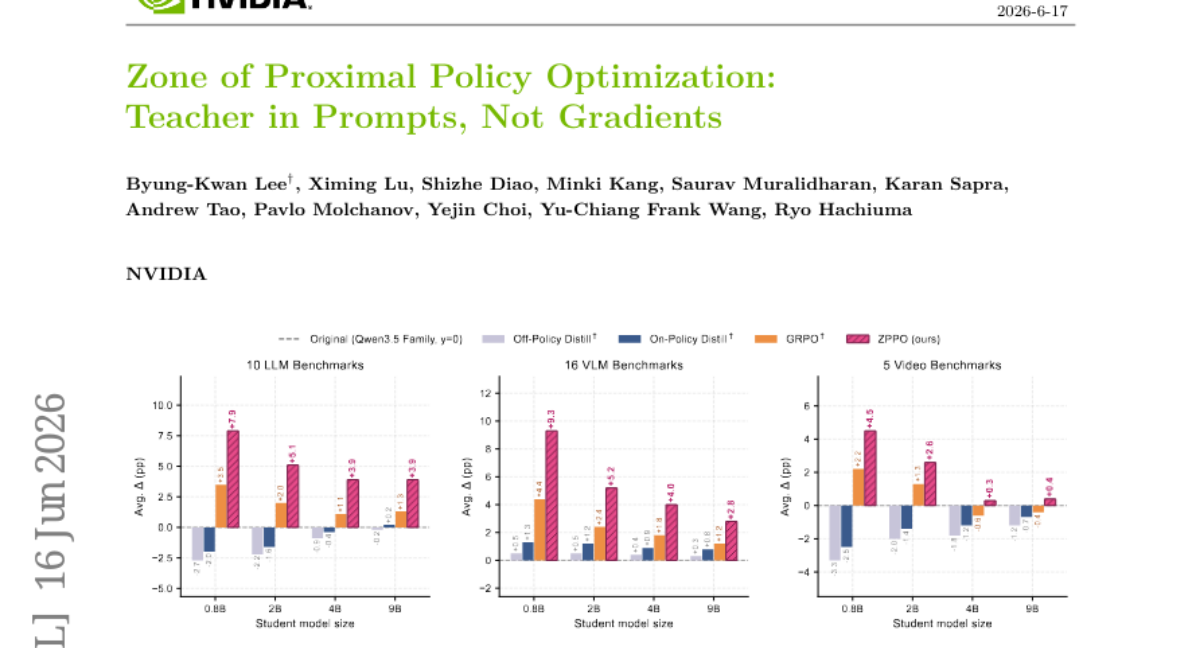
31. Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
🔑 Keywords: Zone of Proximal Policy Optimization, Knowledge Distillation, Reinforcement Learning, Policy Gradient, Vision-Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces Zone of Proximal Policy Optimization (ZPPO) to improve small-student knowledge distillation and enhance generalization capabilities.
🛠️ Research Methods:
– The research employs reformulated prompts and reinforcement learning techniques, including Binary Candidate-included Question (BCQ) and Negative Candidate-included Question (NCQ) to aid student learning from both correct and incorrect responses.
💬 Research Conclusions:
– ZPPO shows significant performance improvements, especially at smaller model scales, when applied to the Qwen3.5 family across a range of benchmark suites compared to traditional distillation methods.
👉 Paper link: https://huggingface.co/papers/2606.18216