AI Native Daily Paper Digest – 20260624

1. Qwen-AgentWorld: Language World Models for General Agents
🔑 Keywords: Language-based world models, Agentic environment simulation, General agents, Reinforcement Learning, Foundation models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate how language-based world modeling can enhance general agents by simulating agentic environments across multiple domains.
🛠️ Research Methods:
– Developed Qwen-AgentWorld using a three-stage training pipeline involving CPT for world modeling capabilities, SFT for next-state-prediction reasoning, and RL for enhancing simulation fidelity with hybrid rubric-and-rule rewards.
– Introduced AgentWorldBench as a comprehensive benchmark to evaluate language world models.
💬 Research Conclusions:
– Qwen-AgentWorld significantly outperforms existing frontier models and supports scalable simulation of real-world environments for agentic RL, which improves downstream performance in general agents.
👉 Paper link: https://huggingface.co/papers/2606.24597

2. MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization
🔑 Keywords: Mobile GUI agents, annotation-free learning, Hierarchical Feedback-Guided Policy Optimization, AndroidWorld, MobileForge
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary goal is to enable efficient adaptation of mobile GUI agents without the need for annotations by using a novel system combining real app interaction grounding and hierarchical feedback-guided policy optimization.
🛠️ Research Methods:
– The study introduces MobileForge, comprising MobileGym for task generation and real mobile interaction rollout evaluation, and Hierarchical Feedback-Guided Policy Optimization (HiFPO) for turning trajectory outcomes into hint-contextualized updates, relying on automatically generated, annotation-free data.
💬 Research Conclusions:
– MobileForge adapts models to achieve significantly high Pass@3 scores on AndroidWorld, approaching the performance of GUI-specialized models, and demonstrates superior adaptation capability on the MobileWorld GUI-only split, proving to be the leading open-data mobile GUI agent in evaluations.
👉 Paper link: https://huggingface.co/papers/2606.19930

3. OpenThoughts-Agent: Data Recipes for Agentic Models
🔑 Keywords: open-source, data curation pipeline, agentic language models, training data, scalability
💡 Category: Natural Language Processing
🌟 Research Objective:
– To present an open-source data curation pipeline for training agentic language models, filling a significant gap in addressing diverse agentic tasks.
🛠️ Research Methods:
– Conducted over 100 controlled ablation experiments to investigate pipeline stages and assembled a training set of 100K examples to fine-tune specific models.
💬 Research Conclusions:
– The OpenThoughts-Agent project outperformed existing agentic models with a 3.9 percentage point improvement and demonstrated strong scalability, publicly releasing data and tools to support future research.
👉 Paper link: https://huggingface.co/papers/2606.24855

4. LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
🔑 Keywords: Multi-Agent Benchmark, LingxiDiagBench, LLMs, Psychiatric Diagnosis, AI in Healthcare
💡 Category: AI in Healthcare
🌟 Research Objective:
– Introduce a large-scale Multi-Agent Benchmark for evaluating Large Language Models (LLMs) in the context of Chinese psychiatric diagnosis.
🛠️ Research Methods:
– Development of LingxiDiagBench featuring LingxiDiag-16K, a dataset of 16,000 EMR-aligned synthetic consultation dialogues across 12 ICD-10 psychiatric categories for static and dynamic consultation evaluation.
💬 Research Conclusions:
– LLMs exhibit high accuracy in binary classification but struggle with comorbidity recognition and multi-way differential diagnosis.
– Dynamic consultations underperform compared to static evaluations, affected by poor information-gathering strategies.
– Consultation structure alone does not ensure correct diagnostic decisions, indicated by moderate correlation between consultation quality and diagnostic accuracy.
👉 Paper link: https://huggingface.co/papers/2602.09379

5. Semantic Browsing: Controllable Diversity for Image Generation
🔑 Keywords: Text-to-image models, Visual Fidelity, Prompt Adherence, Controlled Diversity, Semantic Browsing
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance text-to-image models by introducing controlled diversity through Semantic Browsing, allowing for structured navigation and meaningful exploration of image variations.
🛠️ Research Methods:
– The method involves leveraging Vision Language Models to utilize rich textual representations, thereby inducing diversity at the text level and employing an agentic workflow to enforce structured variation aligned with the initial prompts.
💬 Research Conclusions:
– The proposed approach successfully creates diverse and structured design spaces where each variation corresponds to a specific semantic decision that users can understand and explore.
👉 Paper link: https://huggingface.co/papers/2606.23679

6. FedOT: Ownership Verification and Leakage Tracing via Watermarks for Federated LDMs
🔑 Keywords: Federated Learning, Latent Diffusion Models, Watermarking, Ownership Verification, Leakage Tracing
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the study is to develop a framework called FedOT that ensures ownership verification and leakage tracing in federated latent diffusion models by using chunked watermarking and latent vector transformation.
🛠️ Research Methods:
– Introduction of a chunked watermark system, where one part is for ownership verification and the other for client identification.
– Implementation of Latent Vector Transformation (LVT) to prevent VAE replacement attacks and maintain model integrity.
💬 Research Conclusions:
– FedOT provides superior performance in ownership verification and traceability, significantly mitigating risks associated with unauthorized model distribution or watermark removal attacks in federated learning environments.
👉 Paper link: https://huggingface.co/papers/2606.22875

7. Are Text-to-Image Models Inductivist Turkeys? A Counterfactual Benchmark for Causal Reasoning
🔑 Keywords: Text-to-Image, causal reasoning, counterfactual benchmark, pattern matching, Vision Language Model
💡 Category: Generative Models
🌟 Research Objective:
– To investigate whether text-to-image models possess causal understanding or rely solely on pattern matching.
🛠️ Research Methods:
– Introduced Counterfactual-World (CF-World), a benchmark for testing text-to-image models on counterfactual generation.
– Evaluated models using a Vision Language Model (CF-Eval) and developed metrics like Prior Resistance Rate and Reasoning Retention Rate.
💬 Research Conclusions:
– Text-to-image models show significant performance decline in counterfactual scenarios due to reliance on visual-textual co-occurrences from training data.
👉 Paper link: https://huggingface.co/papers/2606.24548

8. ReMMD: Realistic Multilingual Multi-Image Agentic Verification for Multimodal Misinformation Detection
🔑 Keywords: Multimodal misinformation detection, Agentic verification, ReMMD, ReMMDBench, ReMMD-Agent
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces ReMMD, a comprehensive multimodal misinformation detection framework designed to handle complex and multilingual content with multiple images and various verification methods.
🛠️ Research Methods:
– ReMMD includes ReMMDBench, a real-world benchmark with diverse samples and configurations, and ReMMD-Agent, a verifier that analyzes posts with persistent memory and builds reusable evidence sets.
💬 Research Conclusions:
– ReMMD-Agent achieves superior five-way veracity performance using GPT-5.2, with significant accuracy and macro-F1 scores, while reducing costs compared to other agents like MMD-Agent and T2-Agent.
👉 Paper link: https://huggingface.co/papers/2606.24112

9. Holistic Data Scheduler for LLM Pre-training via Multi-Objective Reinforcement Learning
🔑 Keywords: Holistic Data Scheduler, Online Data Mixing, Reinforcement Learning, Large Language Model, Training Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To optimize the pre-training efficiency and performance of Large Language Models using a novel online data mixing framework.
🛠️ Research Methods:
– Holistic Data Scheduler is developed using reinforcement learning with a multi-objective reward function, employing the Soft Actor-Critic algorithm.
💬 Research Conclusions:
– The framework significantly reduces the number of training iterations by 44% and improves performance on benchmarks, enhancing both training efficiency and model capability.
👉 Paper link: https://huggingface.co/papers/2606.24133
10. DREAM: Dense Retrieval Embeddings via Autoregressive Modeling
🔑 Keywords: autoregressive modeling, dense retrieval embedding models, next-token prediction, attention mechanism, frozen LLM
💡 Category: Natural Language Processing
🌟 Research Objective:
– To determine if autoregressive next-token prediction objectives can supervise dense retrieval effectively without labeled data.
🛠️ Research Methods:
– Introduced DREAM, a model that incorporates retriever-generated query-document similarity scores into the attention heads of a frozen LLM to train dense retrieval embeddings.
💬 Research Conclusions:
– DREAM consistently outperforms existing methods on retrieval benchmarks (BEIR and RTEB), highlighting its potential for improving dense retrievers through autoregressive modeling techniques.
👉 Paper link: https://huggingface.co/papers/2606.24667

11. QG-MIL: A Gated Transformer Aggregator for Domain-Agnostic Multiple Instance Learning in Medical Imaging
🔑 Keywords: Multiple Instance Learning, Medical Imaging, Gated Transformer Aggregator, Prediction Consistency, Attention Distribution
💡 Category: AI in Healthcare
🌟 Research Objective:
– The paper introduces QG-MIL, a novel model improving attention-based Multiple Instance Learning in medical imaging by stabilizing attention and prediction consistency across various medical domains.
🛠️ Research Methods:
– QG-MIL utilizes a gated transformer aggregator with four architectural components: RMSNorm-based pre-normalization, per-head QK normalization, fine-grained attention output gating, and SwiGLU-style feed-forward modules, evaluated across six benchmarks.
💬 Research Conclusions:
– The QG-MIL model outperforms existing baselines with a +6.1 mean macro F1 improvement, demonstrating enhanced distributed attention and consistent cross-domain performance, supported by attention overlays and mass analysis.
👉 Paper link: https://huggingface.co/papers/2606.20027

12. EventVLA: Event-Driven Visual Evidence Memory for Long-Horizon Vision-Language-Action Policies
🔑 Keywords: EventVLA, Memory, Visual Evidence, Keyframe Evidence Memory, RoboTwin-MeM
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research introduces EventVLA, a framework aimed at enhancing long-horizon robotic manipulation by using a sparse visual evidence memory structure to improve task performance.
🛠️ Research Methods:
– Implementation of a dynamic Keyframe Evidence Memory module to predict future keyframe probabilities for optimal visual event capture.
– Use of a diagnostic benchmark, RoboTwin-MeM, to evaluate non-Markovian manipulation tasks.
💬 Research Conclusions:
– EventVLA achieves a 40% average success rate improvement over existing state-of-the-art memory-augmented Vision-Language-Action frameworks across multiple simulation and real-world tasks.
👉 Paper link: https://huggingface.co/papers/2606.20092

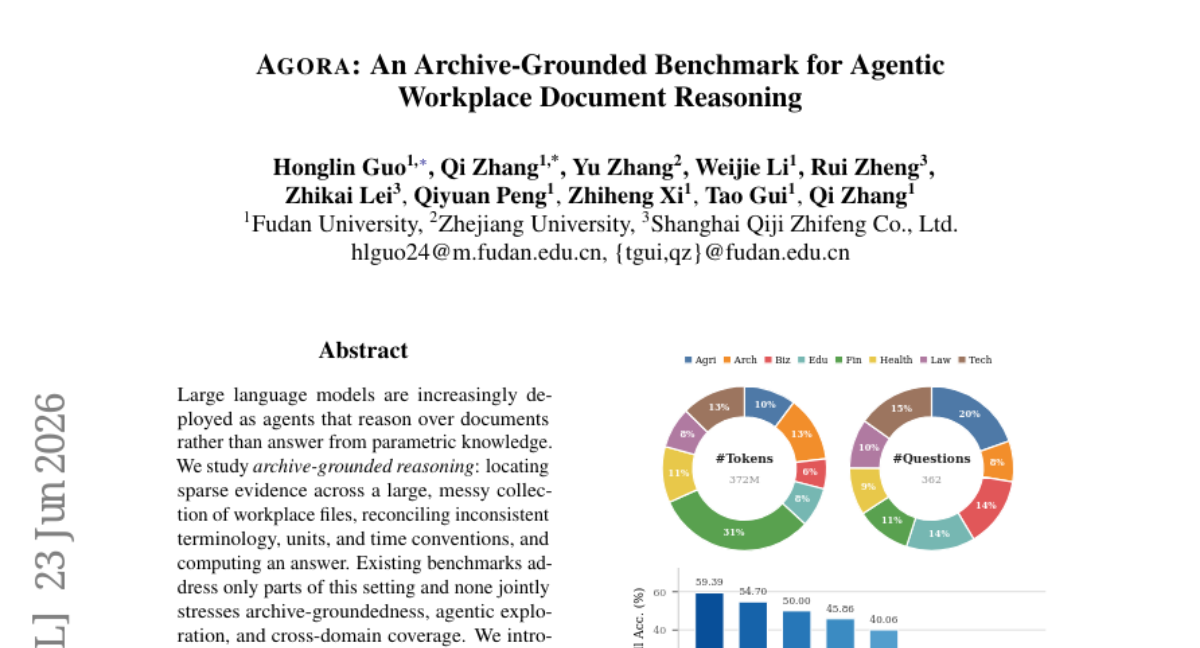
13. AGORA: An Archive-Grounded Benchmark for Agentic Workplace Document Reasoning
🔑 Keywords: Large language models, archive-grounded reasoning, agentic exploration, cross-domain coverage, benchmarks
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address the challenges large language models face in archive-grounded reasoning tasks involving evidence retrieval and synthesis across diverse document collections.
🛠️ Research Methods:
– Introduction of Agora, a benchmark consisting of 362 questions paired with eight domain collections and 9,664 documents, requiring deliberate exploration by agents, and incorporating techniques like cross-document task synthesis and leak-preventing obfuscation.
💬 Research Conclusions:
– The study finds that the task remains far from solved, with the strongest model achieving only 59.4% accuracy, and significant performance variations across different domains.
👉 Paper link: https://huggingface.co/papers/2606.24526
14. Multi4D: High-Fidelity Dynamic Gaussian Splatting via Multi-Level Competitive Allocation
🔑 Keywords: Dynamic 3D Gaussian splatting, motion consistency, visual fidelity, 4D segmentation accuracy, adaptive specialization
💡 Category: Computer Vision
🌟 Research Objective:
– To resolve the trade-off between motion consistency and visual fidelity in dynamic 3D Gaussian splatting using the Multi4D framework.
🛠️ Research Methods:
– Employed a multi-level competitive allocation framework with three structured levels: static structure, persistent dynamic geometry, and transient appearance primitives.
– Utilized shared rasterization and residual-driven optimization to achieve adaptive specialization without pre-assigned decomposition.
💬 Research Conclusions:
– Achieved state-of-the-art rendering quality and real-time performance with fewer dynamic primitives.
– Enabled state-of-the-art 4D segmentation accuracy with a significant speed improvement by explicitly tracking compact persistent Gaussians over time.
👉 Paper link: https://huggingface.co/papers/2606.22197

15.

16. An Efficient Method for the Optimal Control of Microgrids Under Uncertainties using Local Reduction
🔑 Keywords: robust microgrid sizing, power scheduling, logical constraints, binary variables, continuous nonlinear programming
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to propose and compare two mathematical formulations for robust microgrid sizing and power scheduling under uncertainties.
🛠️ Research Methods:
– The study employs a comparison between two formulations: one using binary variables and big-M constraints (mixed-integer linear program) and the other using continuous nonlinear programming through a smooth reformulation of logical constraints. A novel local reduction algorithm is utilized.
💬 Research Conclusions:
– Both formulations show promising results by achieving a feasibility rate above 90% when evaluated through 100,000-sample Monte Carlo simulations.
👉 Paper link: https://huggingface.co/papers/2606.12345

17. FLUX3D: High-Fidelity 3D Gaussian Generation with Diffusion-Aligned Sparse Representation
🔑 Keywords: FLUX3D, image-to-3DGS, Sparse voxel representation, cross-modal alignment, diffusion transformers
💡 Category: Generative Models
🌟 Research Objective:
– Address limitations in image-to-3D Gaussian Splatting generation by improving representation learning and cross-modal alignment.
🛠️ Research Methods:
– Revisit 2D feature selection for sparse voxel-based 3D representation learning and propose Diffusion-Aligned Structured Latents (DA-SLAT) with a decoder-only architecture.
– Design a sparse-structure-aware diffusion framework integrating Sparse-structure Multimodal Diffusion Transformer (SMDiT) and Modal-Aware Rotary Positional Embedding (MARoPE) for 2D-3D alignment.
💬 Research Conclusions:
– FLUX3D delivers significant improvements in appearance fidelity and outperforms state-of-the-art methods in generating high-quality 3DGS assets.
👉 Paper link: https://huggingface.co/papers/2606.24874

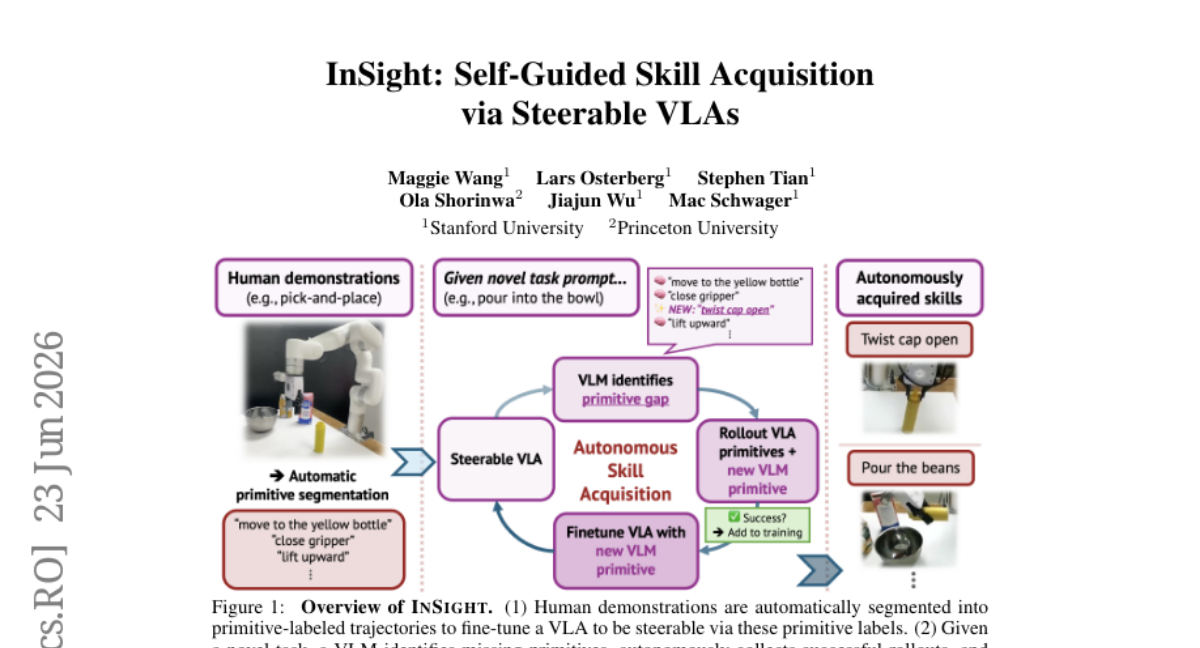
18. InSight: Self-Guided Skill Acquisition via Steerable VLAs
🔑 Keywords: InSight, Vision-language-action models, Autonomous skill acquisition, Primitive-action level, Continual skill acquisition
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to enable autonomous skill acquisition for vision-language-action models by introducing primitive-action level steerability and automated demonstration generation with a new framework called InSight.
🛠️ Research Methods:
– InSight employs an automated segmentation pipeline to partition demonstrations into labeled primitives using VLM plan decomposition and end-effector poses, and a VLM-guided data flywheel to discover and integrate missing primitives required for novel tasks.
💬 Research Conclusions:
– The study concludes that primitive steerability allows vision-language-action models to autonomously acquire new skills and compose them to accomplish novel long-horizon tasks, eliminating the need for further human demonstrations.
👉 Paper link: https://huggingface.co/papers/2606.24884
19. World Value Models for Robotic Manipulation
🔑 Keywords: World Value Model, value estimation, temporal modeling, robotic policy learning, mixed-quality data
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to enhance robotic policy learning by integrating world models with accurate value estimation to assess task progression more effectively.
🛠️ Research Methods:
– The research introduces the World Value Model (WVM), combining world models with value estimation, and evaluates its performance on benchmarks including the novel Suboptimal-Value-Bench.
💬 Research Conclusions:
– WVM achieves state-of-the-art results in Value-Order Correlation and maintains high performance with both expert and suboptimal data, proving its robustness and improving manipulation performance in various policy extraction methods.
👉 Paper link: https://huggingface.co/papers/2606.24742

20. FlowR2A: Learning Reward-to-Action Distribution for Multimodal Driving Planning
🔑 Keywords: Multimodal driving planning, Dense reward supervision, Flow-matching decoder, Generative conditions, Anchor-based methods
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective of the paper is to resolve the tension between scoring-based methods and anchor-based methods in multimodal driving planning by introducing a novel approach named FlowR2A. This approach redefines simulation-based rewards and learns reward-conditioned action distributions to provide superior driving proposals.
🛠️ Research Methods:
– The research employs a flow-matching decoder to unify dense supervision and dynamic proposal generation. It utilizes fine-grained per-timestep reward conditioning and reward noise augmentation to balance safety and progress objectives. Additionally, it incorporates generative formulations for controllable sampling during tests.
💬 Research Conclusions:
– FlowR2A demonstrates state-of-the-art performance on NAVSIM benchmarks by generating multimodal proposals of substantially higher quality than previous methods. The method effectively internalizes the correlation between actions and outcomes in various domains such as safety and comfort.
👉 Paper link: https://huggingface.co/papers/2606.24231
21. ChartWalker: Benchmarking the Cross-Chart RAG Task
🔑 Keywords: Cross-Chart Retrieval-Augmented Generation, hierarchical knowledge graph, structure-aware sampling, multi-hop reasoning paths
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The primary goal of the research is to develop a novel framework, ChartWalker, to enhance cross-chart retrieval-augmented generation tasks for complex multi-modal analyses in various domains.
🛠️ Research Methods:
– The study introduces hierarchical knowledge graph construction tailored specifically for charts, alongside a structure-aware sampling algorithm to create semantically coherent multi-hop reasoning paths, controlling query difficulty and granularity.
💬 Research Conclusions:
– Extensive evaluations using the new ChartWalker-Bench benchmark reveal significant performance gaps in major RAG paradigms, highlighting the challenges and utility of the benchmark. Additionally, the ChartWalker-Agent serves as a baseline to inspire further system design improvements.
👉 Paper link: https://huggingface.co/papers/2606.23997

22. VeriEvol: Scaling Multimodal Mathematical Reasoning via Verifiable Evol-Instruct
🔑 Keywords: VeriEvol, Reinforcement Learning, Visual Mathematical Reasoning, Reward Labels, Evolution Operators
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce VeriEvol, a framework aimed at improving reinforcement learning scalability in visual mathematical reasoning by ensuring reliable reward labels through a two-axis approach.
🛠️ Research Methods:
– Utilizing evolutionary operators and hypothesis testing for data verification, the methodology involves separating prompt difficulty from answer reliability, with a type-aware evolution module and HTV-Agent verifier.
💬 Research Conclusions:
– VeriEvol significantly improves model performance and transparency, increasing mean accuracy on a visual-math suite from 35.42 to 54.73 by expanding SFT data from 10K to 250K samples; additional accuracy improvements are highlighted when using evolved prompts and HTV-Agent verifier.
👉 Paper link: https://huggingface.co/papers/2606.23543

23. DiffusionBench: On Holistic Evaluation of Diffusion Transformers
🔑 Keywords: NanoGen, Diffusion transformer, ImageNet, text-to-image, FID
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces NanoGen, a framework for training and evaluating diffusion transformers to assess progress in generative modeling beyond ImageNet class-conditional generation.
🛠️ Research Methods:
– NanoGen supports multiple diffusion methods such as RAE, VAE, pixel-space, and MeanFlow under both ImageNet and text-to-image setups.
💬 Research Conclusions:
– Researchers found no strong correlation between method rankings on ImageNet and text-to-image tasks using NanoGen, suggesting the importance of evaluating diffusion transformers on both tasks. They propose DiffusionBench as a more holistic benchmark.
👉 Paper link: https://huggingface.co/papers/2606.24888

24. Escaping the Self-Confirmation Trap: An Execute-Distill-Verify Paradigm for Agentic Experience Learning
🔑 Keywords: EDV, Large Language Model, Experience Learning, Self-Confirmation Trap, Execute-Distill-Verify
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the Self-Confirmation Trap in Large Language Model agents and improve reliable experience learning through the EDV framework.
🛠️ Research Methods:
– Introduce a three-stage Execute-Distill-Verify framework employing multiple heterogeneous agents for collaborative experience construction, preventing self-confirmatory errors.
💬 Research Conclusions:
– Demonstrated that the EDV framework consistently outperforms strong baselines on long-horizon benchmarks, enhancing the self-evolution capabilities of LLM agents.
👉 Paper link: https://huggingface.co/papers/2606.24428

25. Critique of Agent Model
🔑 Keywords: True artificial agency, Large Language Model, agent architectures, Goal-Identity-Configurator, self-directed learning
💡 Category: Artificial Intelligence Systems and Tools
🌟 Research Objective:
– The research aims to clarify where automation ends and agency begins in AI systems, focusing on constructing systems with internalized structures for autonomy.
🛠️ Research Methods:
– The study surveys current AI agent landscapes and analyzes agent architectures along five dimensions: goal, identity, decision-making, self-regulation, and learning. It introduces the Goal-Identity-Configurator architecture for general-purpose agent models.
💬 Research Conclusions:
– The paper concludes that true agency in AI requires internal structures, distinguishing agentive systems with capabilities arising endogenously from those designed for specific tasks. Insights on auditability, controllability, and safety of autonomous systems are also provided.
👉 Paper link: https://huggingface.co/papers/2606.23991

26. FLAT: Feedforward Latent Triangle Splatting for Geometrically Accurate Scene Generation
🔑 Keywords: Video Diffusion Models, Latent Space, 3D Scene Generation, Explicit Surface Primitives, Triangle Splats
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to explore whether compressed video diffusion latents can be directly mapped to explicit surface primitives in one pass to improve geometric accuracy and support real-time rendering in 3D scene generation.
🛠️ Research Methods:
– Introduced FLAT, utilizing triangle splats for decoding from video diffusion latents.
– Developed a ray-centered rotation parameterization for triangle regression and a novel product window function to enhance gradient flow in differentiable triangle rendering.
💬 Research Conclusions:
– FLAT outperforms existing feedforward baselines in geometric accuracy while maintaining competitive visual quality.
– A lightweight test-time refinement step converts predicted triangle models into game-engine-ready representations, supporting real-time rendering.
– Conducted a systematic analysis of representation tradeoffs in feedforward scene generation.
👉 Paper link: https://huggingface.co/papers/2606.24876
27. AOHP: An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction
🔑 Keywords: AI agents, Agent-native operating systems, Android Open Source Project, Personalized service composition
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop AOHP, an Android-based operating system framework that considers AI agents as first-class entities, aiming to improve task completion rates and reduce execution costs.
🛠️ Research Methods:
– Utilization of the Android Open Source Project to implement three key agent-oriented mechanisms: personalized service composition, efficient agent interfaces, and secure information flow.
💬 Research Conclusions:
– AOHP demonstrates improved task completion rates by 21.12%, reduces execution costs by 51.55%, and enhances security-policy compliance, showcasing its effectiveness as an AI agent-friendly OS framework.
👉 Paper link: https://huggingface.co/papers/2606.23449
28. MemGUI-Agent: An End-to-End Long-Horizon Mobile GUI Agent with Proactive Context Management
🔑 Keywords: MemGUI-Agent, Context-as-Action, long-horizon tasks, proactive context management, supervised training
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to address the limitations faced by mobile GUI agents on long-horizon tasks by introducing MemGUI-Agent, which utilizes proactive context management through a novel approach called Context-as-Action (ConAct).
🛠️ Research Methods:
– MemGUI-Agent leverages ConAct to manage context proactively, maintaining critical information with structured context fields. The study constructs a 2,956-trajectory dataset, MemGUI-3K, to facilitate supervised training and offline analysis.
💬 Research Conclusions:
– Training an 8B model using MemGUI-3K leads to the development of MemGUI-8B-SFT, achieving top performance on MemGUI-Bench and generalizing to the MobileWorld benchmark. The research successfully showcases improved reliability and context retention for long-horizon mobile GUI tasks.
👉 Paper link: https://huggingface.co/papers/2606.19926

29. NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?
🔑 Keywords: NatureBench, AI coding agents, scientific innovation, methodological translation, containerized environment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces NatureBench, a benchmark of 90 tasks from Nature publications, designed to assess if AI coding agents can achieve scientific discovery rather than just reproduction.
🛠️ Research Methods:
– NatureBench utilizes NatureGym, an automated pipeline that creates standardized containerized environments from source papers to address environment fragmentation in research benchmarks.
💬 Research Conclusions:
– The analysis indicates that AI coding agents primarily achieve success through methodological translation into familiar supervised prediction problems rather than true scientific innovation. The leading model surpasses the state-of-the-art in only 17.8% of the tasks.
👉 Paper link: https://huggingface.co/papers/2606.24530
