AI Native Daily Paper Digest – 20260626

1. DanceOPD: On-Policy Generative Field Distillation
🔑 Keywords: DanceOPD, text-to-image generation, local editing, global editing, flow-matching models
💡 Category: Generative Models
🌟 Research Objective:
– The paper proposes DanceOPD, a novel on-policy generative field distillation framework designed to unify text-to-image generation, local editing, and global editing capabilities in flow-matching models.
🛠️ Research Methods:
– DanceOPD employs capability-specific routing and velocity-based training, routing each sample to a specific capability field and using a simple velocity MSE objective to train the model.
💬 Research Conclusions:
– The study demonstrates that DanceOPD effectively improves multi-capability composition in image generation models, enhancing targeted capabilities while maintaining anchor generation quality. This approach provides a practical solution for generative field distillation in flow-matching models.
👉 Paper link: https://huggingface.co/papers/2606.27377
2. OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
🔑 Keywords: On-Policy Skill Distillation, Outcome-based Reinforcement Learning, Token-level Supervision, Hierarchical Skills, Critical-first Routing
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To propose OPID, an on-policy skill distillation framework, which improves language agent training efficiency and performance by extracting skill supervision from completed on-policy trajectories.
🛠️ Research Methods:
– Utilizes trajectory hindsight as hierarchical skills to guide decision-making. A critical-first routing mechanism is employed for skill selection to enhance policy optimization using token-level self-distillation.
💬 Research Conclusions:
– OPID enhances agent performance, sample efficiency, and robustness in language agent tasks compared to outcome-only RL and existing skill-distillation methods.
👉 Paper link: https://huggingface.co/papers/2606.26790

3. The Verification Horizon: No Silver Bullet for Coding Agent Rewards
🔑 Keywords: Verification challenges, Human intent, Reward hacking, Policy capability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Address the verification challenges in AI agents by characterizing verification signals along scalability, faithfulness, and robustness to align with human intent.
🛠️ Research Methods:
– Analyzed four reward constructions: test verifier for coding tasks, rubric verifier for frontend tasks, user as verifier for real-world tasks, and automated agent verifier for long-horizon tasks.
💬 Research Conclusions:
– Verification systems need to evolve alongside generative capabilities as policy capability grows, with targeted verification designs able to suppress reward hacking and improve task completion quality.
👉 Paper link: https://huggingface.co/papers/2606.26300

4. GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
🔑 Keywords: GUI agents, CLI agents, execution bottlenecks, verifier-guided skill augmentation, execution-layer benchmark
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to evaluate the performance of GUI agents and CLI agents by introducing a matched execution-layer benchmark for desktop tasks across multiple applications and workflow categories.
🛠️ Research Methods:
– A controlled setting where GUI agents interact through graphical interfaces and CLI agents through command interfaces, with identical goals, states, and final-state verifiers to ensure fair comparison.
💬 Research Conclusions:
– GUI agents have a higher full pass rate at 59.1% compared to CLI agents at 48.2% initially. However, with verifier-guided skill augmentation, the CLI success rate increases to 69.3%, indicating that CLI performance is primarily hindered by incomplete skill coverage rather than model capability alone.
👉 Paper link: https://huggingface.co/papers/2606.24551

5. Why Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
🔑 Keywords: Supervisory Signals, Reinforcement Learning, Tool-Use Tasks, Catastrophic Collapse, Off-Policy Supervision
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This research explores how various supervisory signals and training strategies, particularly interleaved supervised fine-tuning and reinforcement learning, can enhance the stability and performance of large language models (LLMs) in tool-use tasks.
🛠️ Research Methods:
– The study employs a systematic investigation of diverse supervisory signals, including off-policy supervision and hint-based guidance, under synchronous and interleaved training schemes to address issues like catastrophic collapse and format sensitivity.
💬 Research Conclusions:
– Interleaved supervised fine-tuning with RL improves stability but faces challenges in format and content out-of-distribution evaluations. These findings emphasize the importance of diverse supervisory signals for robust training of LLMs in complex, multi-step tool-use tasks.
👉 Paper link: https://huggingface.co/papers/2606.26027

6. LISA: Likelihood Score Alignment for Visual-condition Controllable Generation
🔑 Keywords: score-based generative modeling, side networks, likelihood score, LISA, visual-condition controllable generation
💡 Category: Generative Models
🌟 Research Objective:
– Examine the role of side networks in visual-condition controllable generation within the framework of score-based generative modeling and introduce a regularization method, LISA, to improve training efficiency.
🛠️ Research Methods:
– Proposing the Likelihood Score Alignment (LISA) method to align intermediate features of side networks with approximated likelihood scores using a lightweight decoder, incorporating a regularization loss alongside standard diffusion loss.
💬 Research Conclusions:
– LISA consistently accelerates training convergence and enhances synthetic results while promoting feature disentanglement in side networks, without incurring additional training or inference costs.
👉 Paper link: https://huggingface.co/papers/2606.27192

7. Confidence-Aware Tool Orchestration for Robust Video Understanding
🔑 Keywords: Robust-TO, Blind Trust Problem, video reasoning, reliability-relevance score, calibrated reliability score
💡 Category: Computer Vision
🌟 Research Objective:
– Address the Blind Trust Problem in video reasoning by incorporating per-frame trustworthiness to improve accuracy under realistic perturbations.
🛠️ Research Methods:
– Integrate heterogeneous visual perception tools under a unified evidence interface using a reliability-relevance score to select trustworthy frames.
– Utilize a three-tier synthesis process for evidence weighting based on a calibrated reliability score.
💬 Research Conclusions:
– Robust-TO outperforms current state-of-the-art models, achieving 56.4% average accuracy on clean inputs and maintaining 54.3% accuracy under realistic corruption, with the smallest accuracy drop compared to other methods.
👉 Paper link: https://huggingface.co/papers/2606.26904

8. Hallucination in World Models is Predictable and Preventable
🔑 Keywords: world models, hallucination, data-centric signals, coverage-aware sampling, curiosity rewards
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to address hallucinations in world models, particularly in low-data regions by using data-centric signals and coverage-aware sampling techniques.
🛠️ Research Methods:
– The study introduces MMBench2, a comprehensive dataset for visual world modeling, and trains a 350M-parameter world model on it.
– Three distinct hallucination modes are identified and mitigated using data-centric signals.
– A coverage-aware sampling technique is developed for closing coverage gaps at training time.
💬 Research Conclusions:
– The findings reveal that hallucinations in world models stem mainly from data coverage issues.
– The same signals used to detect hallucinations can effectively mitigate them, enabling efficient finetuning to adapt models to new environments with minimal data.
👉 Paper link: https://huggingface.co/papers/2606.27326
9. Discretizing Reward Models
🔑 Keywords: Reinforcement Learning, Reward Models, Oversensitivity, Discretization, Monte Carlo Dropout
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Address the oversensitivity of reward models in reinforcement learning and propose discretization techniques to mitigate this issue.
🛠️ Research Methods:
– Introduce a training-free algorithm using Monte Carlo dropout to generate discrete reward clusters in neural reward models.
💬 Research Conclusions:
– Oversensitivity in reward models leads to poor policy learning; discretizing rewards reduces oversensitivity without losing discriminative ability, resulting in improved policy outcomes.
👉 Paper link: https://huggingface.co/papers/2606.21795

10. EO-WM: A Physically Informed World Model for Probabilistic Earth Observation Forecasting
🔑 Keywords: Weather-driven uncertainties, Earth Observation forecasting, Video diffusion transformer, Physically informed conditioning framework, Meteorological forcing
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance multispectral Earth Observation forecasting by addressing weather-driven uncertainties in land-surface dynamics through a novel video diffusion transformer named EO-WM.
🛠️ Research Methods:
– EO-WM employs a physically informed conditioning framework that distinguishes between climatological baselines and weather anomalies to improve prediction accuracy under varying meteorological conditions.
💬 Research Conclusions:
– EO-WM significantly reduces the error in predicting NDVI decline amplitude by 5.63% and improves the directional hit rate by 7.80% compared to standard methods, highlighting its efficacy in weather-responsive Earth Observation forecasting.
👉 Paper link: https://huggingface.co/papers/2606.27277

11. Neglected Free Lunch from Post-training: Progress Advantage for LLM Agents
🔑 Keywords: Reinforcement Learning, progress advantage, Markov decision process, reward models, step-level scoring
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To demonstrate that reinforcement learning post-training enables effective step-level scoring for language models by deriving a progress advantage, without the need for dedicated reward model training.
🛠️ Research Methods:
– The study derives an implicit advantage function, termed progress advantage, in a stochastic Markov decision process.
– Validation across three applications: test-time scaling, uncertainty quantification, and failure attribution on multiple benchmarks and model families.
💬 Research Conclusions:
– The progress advantage consistently outperforms confidence-based baselines and surpasses dedicated trained reward models, providing practical guidance for real-world agentic systems.
👉 Paper link: https://huggingface.co/papers/2606.26080

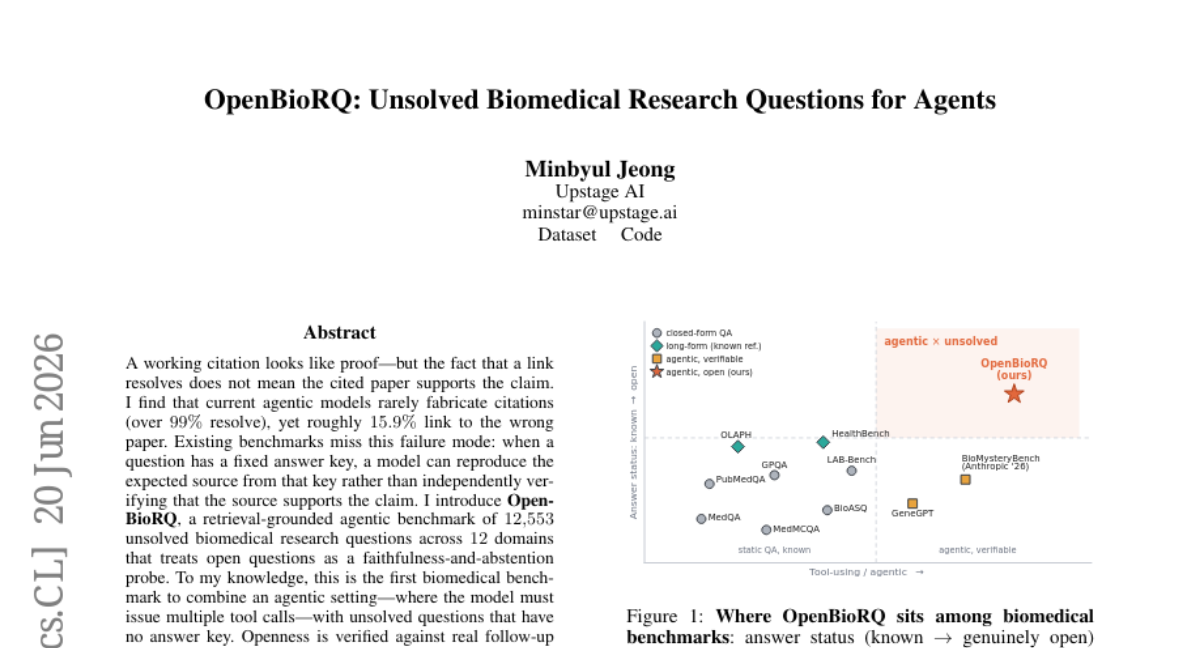
12. OpenBioRQ: Unsolved Biomedical Research Questions for Agents
🔑 Keywords: Agentic Models, Biomedical Benchmark, Retrieval-Grounded Reasoning, Open Questions, Agentic Collapse
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research introduces a new biomedical benchmark, \openbiorq{}, to evaluate agentic models’ abilities to verify sources against unsolved biomedical research questions without predefined answer keys.
🛠️ Research Methods:
– The study focuses on retrieval-grounded agentic benchmarks across 12 domains, treating open questions as faithfulness-and-abstention probes.
– Difficulty is empirically assessed by using questions unanswered by open-weight reference models and challenging frontier agents with these queries.
💬 Research Conclusions:
– It is observed that the agentic models exhibit a significant failure in retrieval-grounded reasoning and tool usage.
– On the hardest subset of questions, current models solve only a minor fraction, indicating the benchmark’s discriminating power across capability tiers.
– Notably, there’s an agentic collapse where models fail to utilize tools effectively; a static checklist improves inter-judge agreement significantly.
👉 Paper link: https://huggingface.co/papers/2606.21959
13.

14. How Post-Training Shapes Biological Reasoning Models
🔑 Keywords: biological reasoning models, multimodal biological data, post-training, reinforcement learning, generalization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate the effects of post-training stages on generalization in biological reasoning models.
🛠️ Research Methods:
– Over 100 models were trained and evaluated across genomics, transcriptomics, and proteins using variations in backbone, continued pre-training, supervised fine-tuning, and reinforcement learning.
💬 Research Conclusions:
– Continued pre-training aligns models with biological language, improving downstream performance.
– Supervised fine-tuning increases in-domain performance but decreases out-of-domain generalization.
– Reinforcement learning enhances out-of-domain performance when applied to well-aligned models, indicating that the composition of training stages is crucial for the ID-OOD trade-off.
👉 Paper link: https://huggingface.co/papers/2606.16517

15. COrigami: An AI Pipeline for Co-Designing Flat-Foldable Visually Recognisable Origami
🔑 Keywords: Generative AI, Computational Origami, AI-driven Optimization, Human-AI Collaboration, Reinforcement Learning
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenge of generating physical art, specifically computational origami, that satisfies strict geometric constraints and subjective visual aesthetics through an AI-driven approach.
🛠️ Research Methods:
– The study introduces COrigami, an end-to-end pipeline that generates crease patterns from natural language. This involves semantic stick figure generation, base packing computation, solving for flat-foldable crease patterns, and utilizing reinforcement learning for model refinement through aesthetic evaluation.
💬 Research Conclusions:
– The research demonstrates the effectiveness of an AI system that integrates algorithmic optimization with aesthetic critique to enable co-creativity. The system serves as a powerful collaborative tool for artists, providing mathematically grounded, reliable, structural designs that can be further developed.
👉 Paper link: https://huggingface.co/papers/2606.26299

16. When Does Combining Language Models Help? A Co-Failure Ceiling on Routing, Voting, and Mixture-of-Agents Across 67 Frontier Models
🔑 Keywords: Multi-model systems, accuracy limits, beta, Gaussian copula, heterogeneous ensembles
💡 Category: Foundations of AI
🌟 Research Objective:
– To determine the accuracy limits of multi-model systems and how often they fail simultaneously, regardless of their correlations or ensemble strategies.
🛠️ Research Methods:
– Utilization of the Clopper-Pearson bound to provide a finite-sample certificate for model accuracy evaluation. Analysis across 67 models from 21 providers to assess the rate of simultaneous failure using tetrachoric calibration.
💬 Research Conclusions:
– The accuracy of multi-model systems is fundamentally limited by the rate at which all models fail on the same query, defined as beta.
– Low correlation heterogeneous ensembles can outperform high-correlation self-ensembling strategies on specific tasks.
– The observed beta rates show significant divergence from predicted values under the Gaussian copula model, highlighting the challenge of co-failure in model ensembles.
👉 Paper link: https://huggingface.co/papers/2606.27288

17. Information-Aware KV Cache Compression for Long Reasoning
🔑 Keywords: InfoKV, KV cache compression, information-theoretic signals, predictive uncertainty, long-context reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance long-context reasoning in large language models (LLMs) by introducing an entropy-aware KV cache compression framework, InfoKV, which incorporates information-theoretic signals alongside traditional attention weights.
🛠️ Research Methods:
– The methodology involves introducing the concept of Forward Influence to measure the impact of compressed tokens on future contexts. InfoKV combines token-level predictive uncertainty with layer-wise representation evolution, integrating entropy scores with attention scores during reasoning.
💬 Research Conclusions:
– Experiments on benchmark models like Llama-3.1, Llama-3.2, and DeepSeek-R1 show that InfoKV significantly outperforms existing attention-based KV compression methods in both prefilling and decoding scenarios.
👉 Paper link: https://huggingface.co/papers/2606.26875

18. PhysiFormer: Learning to Simulate Mechanics in World Space
🔑 Keywords: PhysiFormer, 3D meshes, denoising diffusion process, attention factorised, physical consistency
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to generate physically-plausible 3D object motions using coordinate-space diffusion without relying on explicit inductive biases, enabling efficient multi-object reasoning and application to complex materials and geometries.
🛠️ Research Methods:
– Research employs a diffusion transformer called PhysiFormer, which models objects as 3D meshes in world coordinates, and formulates vertex trajectory prediction as a denoising diffusion process. It utilizes a probabilistic formulation to capture uncertainties and applies factorised attention over time, space, and objects.
💬 Research Conclusions:
– PhysiFormer significantly outperforms traditional autoregressive models in terms of trajectory accuracy, rigidity preservation, and physical consistency. It demonstrates generalization to mixed-material settings, unseen geometries, and larger object counts, making it promising for applications in robotics, graphics, and physical design.
👉 Paper link: https://huggingface.co/papers/2606.27364

19. CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
🔑 Keywords: LLM Agents, Multi-Agent Economy, Long-Horizon Tasks, Communication, Autonomous Agents
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate the performance of Large Language Model (LLM) agents within a multi-agent economic simulation over an extended period.
🛠️ Research Methods:
– Introduced CoffeeBench, a benchmark that simulates a 90-day interaction among heterogeneous firms, utilizing a mix of autonomous LLM agents and fixed reference agents.
💬 Research Conclusions:
– All evaluated models outperformed a passive baseline by achieving positive net income, with better-performing models engaging more actively in communication. Notably, a failure mode was observed in one model characterized by inaction despite coherent planning.
👉 Paper link: https://huggingface.co/papers/2606.16613

20. In-Context World Modeling for Robotic Control
🔑 Keywords: In-Context World Modeling, system identification, in-context adaptation, novel configurations, robot policies
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enable robot policies to adapt to novel configurations without parameter updates by using ICWM to infer system variables from self-generated interactions.
🛠️ Research Methods:
– Introduction of In-Context World Modeling (ICWM) framework treating system identification as an in-context adaptation problem; evaluation through experiments in simulations and real-world robot platforms.
💬 Research Conclusions:
– ICWM significantly outperforms standard Vision-Language-Action models, allowing adaptation to new environments such as altered camera viewpoints without needing intensive fine-tuning.
👉 Paper link: https://huggingface.co/papers/2606.26025

21. Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
🔑 Keywords: Agentic systems, Web-based benchmark, Temporal perception, Graphical understanding, 3D reasoning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce GauntletBench, a web-based benchmark for evaluating agent generalization in scenarios requiring temporal perception, graphical understanding, and 3D reasoning.
🛠️ Research Methods:
– Developed a modular pipeline compatible with open- and closed-source agent frameworks, incorporating a controlled web-based application with vision-intensive tasks.
💬 Research Conclusions:
– Frontier agentic systems show significant limitations in generalization, achieving only a 19.1% success rate compared to the over 80% success rate of non-expert human annotators.
👉 Paper link: https://huggingface.co/papers/2606.14397

22. Fast LeWorldModel
🔑 Keywords: Visual Planning, Fast-LeWM, Latent World Model, Action-Prefix Prediction, Autoregressive Rollout
💡 Category: Machine Learning
🌟 Research Objective:
– To accelerate visual planning by replacing computationally expensive autoregressive rollouts with parallel action-prefix prediction, thereby reducing computational costs and latency during long-horizon predictions.
🛠️ Research Methods:
– Implementation of Fast-LeWM, which encodes action-prefixes and predicts future states in parallel, as opposed to repeated local rollouts.
💬 Research Conclusions:
– Fast-LeWM improves average success rates over LeWM and reduces planning time significantly, achieving lower open-loop latent loss with slower growth as the rollout horizon increases.
👉 Paper link: https://huggingface.co/papers/2606.26217

23. JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
🔑 Keywords: JetSpec, Speculative Decoding, Large Language Models, Autoregressive, Speedup
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to develop a speculative decoding framework, JetSpec, that enhances Large Language Models (LLMs) inference speed and acceptance rates by combining efficient forward drafting with causal conditioning.
🛠️ Research Methods:
– JetSpec trains a causal parallel draft head over fused hidden states from the frozen target model, enabling the generation of candidate trees that align with the autoregressive factorization of the target model.
💬 Research Conclusions:
– JetSpec consistently outperforms existing bidirectional-head and tree-based speculative decoding baselines across a range of benchmarks, achieving up to 9.64x speedup on MATH-500 and 4.58x on open-ended conversational workloads, with further latency gains demonstrated through vLLM integration under realistic serving conditions.
👉 Paper link: https://huggingface.co/papers/2606.18394

24. Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation
🔑 Keywords: Qwen-Image-Agent, Context Gap, agentic framework, Context-Aware Planning, Image Agent Bench
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to bridge the “Context Gap” in text-to-image generation by introducing the Qwen-Image-Agent, which integrates planning, reasoning, searching, and memory mechanisms to construct a complete generation context.
🛠️ Research Methods:
– The authors developed Qwen-Image-Agent, a unified agentic framework, employing Context-Aware Planning and Context Grounding to enhance the generation process.
– Evaluations were conducted using Image Agent Bench (IA-Bench), along with experiments on Mindbench and WISE-Verified to assess the capabilities.
💬 Research Conclusions:
– The study concludes that the Qwen-Image-Agent surpasses existing baselines and delivers state-of-the-art performance in agentic image generation tasks.
👉 Paper link: https://huggingface.co/papers/2606.26907

25. ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
🔑 Keywords: Visual Quantized Representations, multimodal modeling, text-aligned pre-training, feature discretization, proximal representation learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces ViQ, a Visual Quantized Representations framework, designed to balance semantic richness and detail preservation in discrete visual representations.
🛠️ Research Methods:
– The approach involves structuring quantization learning into two stages: text-aligned pre-training and feature discretization, with a position-aware head-wise quantization mechanism.
💬 Research Conclusions:
– ViQ achieves competitive performance in multimodal tasks, maintaining high precision in low-level reconstruction, and significantly improves training efficiency, with up to 20%-70% acceleration.
👉 Paper link: https://huggingface.co/papers/2606.27313
