AI Native Daily Paper Digest – 20260703

1. Program-as-Weights: A Programming Paradigm for Fuzzy Functions
🔑 Keywords: Fuzzy-function programming, neural artifacts, 4B compiler, PAW, foundation model
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Develop a framework for compiling natural-language specifications into compact neural artifacts for efficient local execution.
🛠️ Research Methods:
– Introduce fuzzy-function programming using a 4B compiler trained on a large dataset to create parameter-efficient adapters for a lightweight 0.6B interpreter.
💬 Research Conclusions:
– The proposed Program-as-Weights (PAW) paradigm can efficiently execute tasks with significantly reduced memory usage and faster speeds, transforming foundation models into reusable tool builders.
👉 Paper link: https://huggingface.co/papers/2607.02512

2. Multi-Resolution Flow Matching: Training-Free Diffusion Acceleration via Staged Sampling
🔑 Keywords: MrFlow, text-to-image diffusion, multi-resolution generation, super-resolution, pretrained GAN-based model
💡 Category: Generative Models
🌟 Research Objective:
– MrFlow aims to accelerate text-to-image diffusion by combining low-resolution generation with high-resolution pixel-space refinement without requiring training or runtime modifications.
🛠️ Research Methods:
– The method involves a staged low-to-high-resolution pipeline, utilizing a lightweight pretrained GAN-based model for pixel-space super-resolution and injecting noise to refine high-frequency details.
💬 Research Conclusions:
– MrFlow achieves up to 25x speedup compared to traditional methods, with minimal quality loss, and can further enhance its performance when combined with timestep distillation strategies.
👉 Paper link: https://huggingface.co/papers/2607.01642

3. AgenticSTS: A Bounded-Memory Testbed for Long-Horizon LLM Agents
🔑 Keywords: Long-horizon LLM agents, bounded contract, typed retrieval, strategic skills, explicit memory
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to improve performance in complex decision-making tasks for Long-horizon LLM agents by utilizing a bounded contract approach with typed retrieval to manage memory components.
🛠️ Research Methods:
– The study introduces a bounded contract where decisions are based on fresh user messages without raw cross-decision transcripts, enabling isolated analysis of memory components. The approach is implemented in the game “Slay the Spire 2”, and comparisons are made using a fixed-A0 ablation.
💬 Research Conclusions:
– The approach shows improved win rates in the strategic game “Slay the Spire 2” when strategic skills are incorporated, compared to the baseline. Although the statistical significance is directional, a reproducible testbed is released for further study, providing an agent design and methodology for examining explicit memory layers in long-horizon LLM agents.
👉 Paper link: https://huggingface.co/papers/2607.02255
4. WorldDirector: Building Controllable World Simulators with Persistent Dynamic Memory
🔑 Keywords: WorldDirector, video generation, semantic motion orchestration, persistent dynamic object memory, LLM
💡 Category: Generative Models
🌟 Research Objective:
– To develop WorldDirector, a framework that enables controllable video generation with persistent dynamic object memory and unrestricted viewpoint exploration by decoupling semantic motion from visual rendering.
🛠️ Research Methods:
– Utilizes a large language model (LLM) to coordinate 3D trajectories and camera movements, ensuring strict physical logic and appearance stability in video generation.
💬 Research Conclusions:
– Successfully synthesizes complex and extended events with high controllability and maintains the exact visual identities of dynamic entities even after they re-enter the scene following prolonged absences.
👉 Paper link: https://huggingface.co/papers/2607.02517
5. Logit-Contribution Scoring Identifies Non-Literal Retrieval Heads
🔑 Keywords: Logit-Contribution Scoring, attention heads, OV-circuit, non-literal context synthesis, retrieval benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Logit-Contribution Scoring (LOCOS) to identify attention heads responsible for non-literal context synthesis in large language models.
🛠️ Research Methods:
– LOCOS scores each attention head by projecting its OV-circuit output onto the answer-token unembedding direction in retrieval tasks, evaluating across multiple model families like Qwen3, Gemma-3, and OLMo-3.1.
💬 Research Conclusions:
– LOCOS outperforms existing methods on retrieval benchmarks by identifying specific attention heads critical for non-literal retrieval, demonstrating significant drops in ROUGE-L scores when top LOCOS heads are ablated.
👉 Paper link: https://huggingface.co/papers/2607.01002

6. SkillCoach: Self-Evolving Rubrics for Evaluating and Enhancing Agentic Skill-Use
🔑 Keywords: SkillCoach, agentic skill-use, process rubrics, training trajectories
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce SkillCoach, a self-evolving rubric framework designed to evaluate and enhance agentic skill-use.
🛠️ Research Methods:
– The framework derives skill-grounded process rubrics from real rollouts and evaluates agentic skill-use along four dimensions: skill selection, skill following, skill composition, and skill-grounded reflection.
💬 Research Conclusions:
– Evolved rubrics significantly improve evaluation quality, expose failures not visible through final outcomes, and provide stronger supervision signals than traditional outcome-only filtering methods.
👉 Paper link: https://huggingface.co/papers/2607.01874

7. AGVBench: A Reliability-Oriented Benchmark of Data Augmentation for Vein Recognition
🔑 Keywords: Vein recognition, Data augmentation, Adversarial perturbations, Feature misalignment, CNNs
💡 Category: Computer Vision
🌟 Research Objective:
– The study evaluates 30 augmentation strategies for vein recognition to understand inconsistencies between accuracy and adversarial security, highlighting dataset-specific effectiveness variations.
🛠️ Research Methods:
– Utilization of AGVBench to assess augmentation strategies across five palm- and finger-vein datasets using seven backbone architectures, including CNNs and vision transformers.
💬 Research Conclusions:
– Multi-image mixing methods generally enhance recognition performance but may lack calibration and are susceptible to adversarial perturbations. Severe geometric transformations tend to degrade recognition, and effectiveness of augmentation varies by dataset, demonstrating that accuracy-centric evaluation is insufficient for biometric augmentation.
👉 Paper link: https://huggingface.co/papers/2607.02271

8. When Search Agents Should Ask: DiscoBench for Clarification-Aware Deep Search
🔑 Keywords: large language models, multi-step retrieval, clarification questions, ambiguity detection, multi-turn interaction
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to evaluate search agents’ ability to handle ambiguous queries through the use of a benchmark called DiscoBench, focusing on multi-step information-seeking tasks.
🛠️ Research Methods:
– DiscoBench is introduced, evaluating search agents on whether they can identify ambiguity, ask effective clarification questions, and recover correct reasoning paths across 211 samples and 463 ambiguity instances in 11 real-world domains.
💬 Research Conclusions:
– The study finds that ambiguity detection and effective clarification are crucial capabilities, with experiments showing that direct interaction strategies often outperform repeated searching, thus identifying a gap between retrieval ability and interactive problem-solving in current search agents.
👉 Paper link: https://huggingface.co/papers/2606.27669

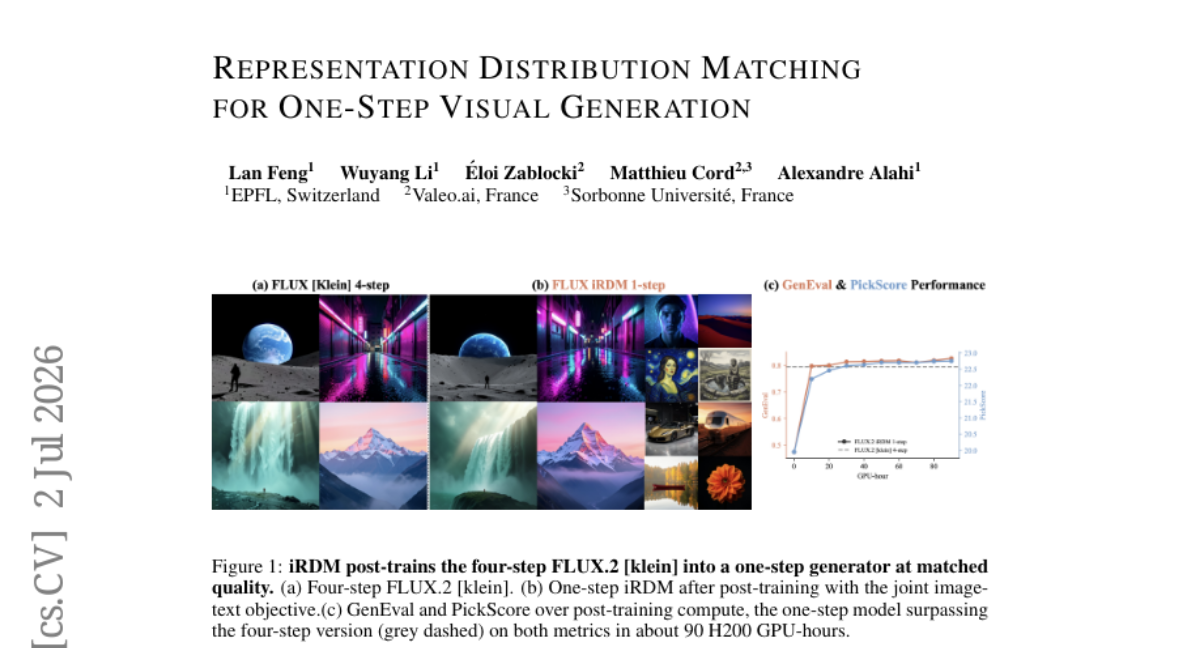
9. Representation Distribution Matching for One-Step Visual Generation
🔑 Keywords: Representation Distribution Matching, pretrained encoders, feature distributions, Sliced-Wasserstein distance, PickScore
💡 Category: Generative Models
🌟 Research Objective:
– Explore and elucidate the design space of Representation Distribution Matching (RDM) for one-step high-quality image generation by matching feature distributions using pretrained encoders.
🛠️ Research Methods:
– Identification and study of two design axes: comparison of distributions and representation spaces, leading to findings that improve RDM performance.
– Implementation of Sliced-Wasserstein distance over multiple encoders to ensure evaluation independence from training loss.
💬 Research Conclusions:
– Enhanced Maximum Mean Discrepancy (MMD) becomes effective for training scalable image generators.
– Optimum batch size identified above 2048.
– Introduced improved RDM (iRDM) achieving state-of-the-art results on ImageNet with elevated SW_r14 score and outperforming prior models in human-preference testing via PickScore.
👉 Paper link: https://huggingface.co/papers/2607.02375
10. AutoMem: Automated Learning of Memory as a Cognitive Skill
🔑 Keywords: Memory management, AutoMem, Metamemory, Long-horizon tasks, Memory skill
💡 Category: Natural Language Processing
🌟 Research Objective:
– To automate memory management in large language models by developing a framework that optimizes memory structure and proficiency, enhancing performance in long-horizon tasks.
🛠️ Research Methods:
– Introduction of AutoMem framework which automates memory optimization through a dual-loop process: reviewing agent trajectories to revise memory structures, and using the agent’s successful memory decisions as training signals for proficiency improvement.
💬 Research Conclusions:
– The study demonstrates that optimizing memory alone can significantly enhance performance in long-horizon tasks, with improvements of 2x-4x, making a 32B open-weight model competitive with leading systems even without altering task-action behaviors.
👉 Paper link: https://huggingface.co/papers/2607.01224

11. Denser neq Better: Limits of On-Policy Self-Distillation for Continual Post-Training
🔑 Keywords: On-policy self-distillation, Continual post-training, Out-of-distribution, Forgetting, Reinforcement learning
💡 Category: Machine Learning
🌟 Research Objective:
– The paper investigates the effectiveness of on-policy self-distillation in continuous post-training, focusing on in-domain specialization and addressing its shortcomings in preventing forgetting and managing out-of-distribution scenarios.
🛠️ Research Methods:
– The approach centers on self-distillation policy optimization (SDPO) and compares its performance with on-policy reinforcement learning methods like GRPO in terms of retaining prior capabilities.
💬 Research Conclusions:
– SDPO accelerates in-domain specialization but struggles with forgetting and out-of-distribution scenarios, often collapsing, while denser self-distillation can cause drift and amplify artifacts. These findings suggest on-policy data alone is insufficient for continual learning stabilization.
👉 Paper link: https://huggingface.co/papers/2607.01763

12. WARP: Weight-Space Analysis for Recovering Training Data Portfolios
🔑 Keywords: WARP, Foundation models, Training data, Model merging, Geometric features
💡 Category: Machine Learning
🌟 Research Objective:
– The objective of the research was to develop WARP, a framework that infers training data compositions from released model weights by analyzing geometric footprints.
🛠️ Research Methods:
– WARP interpolates between base and fine-tuned models using model merging, generating pseudo-checkpoints that recreate the training trajectory.
– It extracts geometric features and maps them to domain proportions using either parameter-free softmax readout or an MLP projector.
💬 Research Conclusions:
– WARP effectively recovers domain mixtures from model weights, achieving a low average MAE performance in controlled experiments with BERT and GPT-2.
– This approach outperforms traditional membership inference and variants accessing the true training trajectory.
👉 Paper link: https://huggingface.co/papers/2607.01686

13. Transferability for General Reasoning: An Automated Curriculum for Multi-Domain RLVR
🔑 Keywords: Transfer-Aware Curriculum, multi-domain reinforcement learning, gradient-geometry alignment, cross-domain transferability, verifiable rewards
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to enhance multi-domain reinforcement learning by developing a Transfer-Aware Curriculum (TAC) that effectively identifies and prioritizes domains with broad benefits to others in the training suite.
🛠️ Research Methods:
– This study proposes a bandit-style online curriculum that uses gradient-geometry alignment to estimate cross-domain transferability, leveraging signals from reinforcement learning for domain prioritization, with less than 1% overhead in time cost.
💬 Research Conclusions:
– TAC achieves superior macro-averaged accuracy across a six-domain reasoning suite, outperforming other methods like proportional random sampling and learnability-only curricula, establishing the significance of cross-domain transferability in reinforcement learning curriculum design.
👉 Paper link: https://huggingface.co/papers/2606.25178

14. Scaling Laws for Grid-Based Approximate Nearest Neighbor Search in High Dimensions
🔑 Keywords: Grid-based multiprobe algorithms, High-dimensional, Approximate nearest neighbor, Dimensional scaling, Indexing cost
💡 Category: Foundations of AI
🌟 Research Objective:
– To systematically characterize the performance of grid-based multiprobe algorithms in approximate nearest neighbor search, particularly focusing on dataset size and dimensionality.
🛠️ Research Methods:
– Experimental analysis of a multiprobe grid algorithm to study dimensional scaling properties, using GloVe embeddings as part of the evaluation dataset.
💬 Research Conclusions:
– Grid-based methods, such as the multiprobe grid algorithm, exhibit constant dimensional scaling exponents and lower indexing costs compared to graph-, tree-, and partitioning-based methods, making them competitive in high-dimensional and rebuild-heavy scenarios. Additionally, the research highlights that ANN algorithm scaling properties can inform the cost analysis of efficient transformer architectures.
👉 Paper link: https://huggingface.co/papers/2607.01283

15.

16. Parameter-Efficient Quantum-Inspired Fast Weight Programmers for Traffic-Matrix Forecasting
🔑 Keywords: Quantum-inspired recurrent models, Traffic matrices, Fast-weight programmers, LSTM, Root-mean-square error
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– The study aims to assess the effectiveness of quantum-inspired recurrent models for traffic matrix forecasting, particularly under constraints of online network control.
🛠️ Research Methods:
– Utilization of gated quantum-inspired Kolmogorov-Arnold network fast-weight programmers (QKAN-FWPs) for multi-step forecasting of Abilene TM, benchmarked against various LSTM configurations under a fixed-budget training protocol.
💬 Research Conclusions:
– The G-QKANFWP model exhibits superior forecasting accuracy and efficiency, achieving a lower root-mean-square error while using significantly fewer resources than larger LSTM models. Its performance surpasses both matched-size LSTMs and classical fast-weight programmer baselines, demonstrating advantages in convergence and low validation-loss area.
👉 Paper link: https://huggingface.co/papers/2606.27821

17. DuoMem: Towards Capable On-Device Memory Agents via Dual-Space Distillation
🔑 Keywords: DuoMem, dual-space distillation, Large Language Model, LoRA adapters
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop DuoMem, a dual-space distillation framework, aiming to transfer procedural problem-solving capabilities from large language models to compact student models efficiently.
🛠️ Research Methods:
– Utilized dual-space distillation, comprising context-space distillation and parameter-space distillation, to enhance model performance, focusing specifically on ALFWorld benchmarks.
💬 Research Conclusions:
– DuoMem achieved significant improvements in task success rates, elevating a 4B-parameter model from 4.3% to 77.9%, while significantly reducing computational requirements for real-time edge deployment.
👉 Paper link: https://huggingface.co/papers/2606.29961

18. Discrete Diffusion Language Models for Interactive Radiology Report Drafting
🔑 Keywords: Diffusion language models, Autoregressive models, Medical visual question answering, Fast decoding, Infilling
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research aims to adapt and evaluate a mixture-of-experts diffusion language model, DiffusionGemma-26B, against its autoregressive counterpart Gemma-4-26B on medical visual question answering tasks.
🛠️ Research Methods:
– The study benchmarks DiffusionGemma-26B against the same-size autoregressive sibling using an identical LoRA recipe, assessing performance on medical visual question answering datasets.
💬 Research Conclusions:
– Diffusion language models match or exceed autoregressive models in performance on medical visual question answering tasks, offering 3.5-4.4x faster decoding and unique bidirectional text editing capabilities suitable for real-world medical text applications.
👉 Paper link: https://huggingface.co/papers/2607.01436

19. Learning to Move Before Learning to Do: Task-Agnostic pretraining for VLAs
🔑 Keywords: Task-Agnostic Pretraining, self-supervised Inverse Dynamics, Vision-Language-Action models, Embodied AI
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– This study aims to enhance Vision-Language-Action (VLA) models by mitigating the need for extensive expert demonstrations, focusing on separating physical competence and semantic alignment.
🛠️ Research Methods:
– Introduces Task-Agnostic Pretraining (TAP), a two-stage framework using self-supervised inverse dynamics on unlabeled data and lightweight language grounding with minimal expert data.
💬 Research Conclusions:
– TAP demonstrates superior performance on the SIMPLER benchmark with significantly less labeled data, showing a 10% gain over traditional methods and retaining robustness under real-world perturbations, offering a scalable solution for Embodied AI.
👉 Paper link: https://huggingface.co/papers/2607.02466

20. PACE: A Proxy for Agentic Capability Evaluation
🔑 Keywords: PACE, agentic benchmarks, non-agentic benchmarks, regression, instance-selection strategies
💡 Category: Foundations of AI
🌟 Research Objective:
– Investigate whether expensive agentic benchmark performance can be predicted using a small subset of atomic evaluation instances.
🛠️ Research Methods:
– Presented the PACE framework utilizing proxy benchmarks by selecting instances from existing non-agentic evaluations.
– Utilized a regression to map model scores on a compact subset to target agentic benchmark scores.
– Employed two instance-selection strategies: target-relevance local selection and globally informative global selection, evaluated via PACE-Bench.
💬 Research Conclusions:
– PACE-Bench accurately predicts agentic benchmark performance with mean absolute error under 4%, Spearman correlation above 0.80, and pairwise model-ranking accuracy around 85%, at a fraction of the full evaluation cost.
– Enables obtaining reliable estimates of agentic performance with reduced time and resource overhead.
👉 Paper link: https://huggingface.co/papers/2607.02032

21. AnyGroundBench: A Specialized-Domain Benchmark for Video Grounding in Vision-Language Models
🔑 Keywords: Vision-Language Models, Spatio-Temporal Video Grounding, Zero-Shot Generalization, Domain Adaptation, In-Context Learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to address the limitations in domain adaptation for Vision-Language Models during spatio-temporal video grounding tasks, particularly their inability to effectively generalize in zero-shot scenarios and adapt through in-context learning.
🛠️ Research Methods:
– Introduction of AnyGroundBench, a benchmark specifically designed for domain adaptation across specialized spatio-temporal video grounding tasks, including five distinct domains with comprehensive spatio-temporal annotations.
💬 Research Conclusions:
– Current Vision-Language Models demonstrate limitations in zero-shot and in-context learning-based adaptation, revealing significant deficiencies in their ability to reason across specialized spatio-temporal domains.
👉 Paper link: https://huggingface.co/papers/2607.02269

22. InstanceControl: Controllable Complex Image Generation without Instance Labeling
🔑 Keywords: InstanceControl, Vision-Language Model, visual conditions, multi-instance scenes, adaptive mask refinement
💡 Category: Generative Models
🌟 Research Objective:
– Introduce InstanceControl, a novel method for multi-instance controllable image generation that eliminates the need for manual instance labeling.
🛠️ Research Methods:
– Utilize Vision-Language Models to establish instance-level correspondences between text prompts and visual conditions, and implement adaptive mask refinement to improve accuracy.
💬 Research Conclusions:
– InstanceControl outperforms existing state-of-the-art methods by achieving higher fidelity and precise instance-level control in multi-instance image generation.
👉 Paper link: https://huggingface.co/papers/2606.31924

23. From SRA to Self-Flow: Data Augmentation or Self-Supervision?
🔑 Keywords: diffusion transformers, data augmentation, self-alignment, noise dimension, Attention Separation
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the study is to investigate the mechanisms behind self-alignment methods in diffusion transformers and to determine if performance improvements primarily arise from data augmentation along the noise dimension rather than from token interactions at different noise levels.
🛠️ Research Methods:
– The study introduces Attention Separation to assess the influence of avoiding interactions between tokens assigned to different noise levels, while maintaining the dual-timestep input format used by Self-Flow.
💬 Research Conclusions:
– Findings suggest that the performance improvement from SRA to Self-Flow mainly results from data augmentation along the noise dimension. Additionally, the study shows that using Attention Separation provides an augmentation effect by effectively splitting a single image into multiple training parts, improving generation performance on datasets such as ImageNet.
👉 Paper link: https://huggingface.co/papers/2607.02508

24. Optimizing Visual Generative Models via Distribution-wise Rewards
🔑 Keywords: reinforcement learning, distribution-wise rewards, generative models, mode collapse, perceptual quality
💡 Category: Generative Models
🌟 Research Objective:
– To improve image diversity and quality with a novel reinforcement learning framework using distribution-wise rewards, addressing mode collapse and computational efficiency issues.
🛠️ Research Methods:
– Fine-tuning generative models using distribution-wise rewards.
– Implementing a subset-replace strategy to efficiently estimate rewards.
– Optimizing post-hoc model merging coefficients using reinforcement learning.
💬 Research Conclusions:
– The approach significantly enhances FID-50K scores across diverse base models, improving perceptual quality while preserving sample diversity.
👉 Paper link: https://huggingface.co/papers/2607.02291

25. Breaking Failure Cascades: Step-Aware Reinforcement Learning for Medical Multimodal Reasoning
🔑 Keywords: Reinforcement Learning, Clinical Image Reasoning, Cascading Errors, Medical Reasoning-aware Policy Optimization (MRPO), Final Answer Accuracy
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to enhance clinical image reasoning by addressing cascading errors, using a novel reinforcement learning approach called MRPO.
🛠️ Research Methods:
– MRPO utilizes step-wise process rewards to mitigate early-stage reasoning errors, applying exponentially larger penalties for incorrect reasoning steps while preserving successful paths.
💬 Research Conclusions:
– MRPO notably improves reasoning quality and accuracy over existing methods, reducing early-stage reasoning failures from 64.0% to 13.0% and outperforming standard baselines in medical visual question answering benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.31825

26. AgenticDataBench: A Comprehensive Benchmark for Data Agents
🔑 Keywords: AgenticDataBench, data agents, AI Native, benchmark, data-driven applications
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce AgenticDataBench to evaluate data agents across diverse domains with fine-grained task annotations.
🛠️ Research Methods:
– Collection of datasets and tasks from 15 vertical domains, including real-world B2B use cases.
– Implementation of skill-aligned hierarchical clustering and task generation with large language models.
💬 Research Conclusions:
– AgenticDataBench allows capturing the diversity and complexity of data science workflows and provides detailed skill-level insights of data agents.
👉 Paper link: https://huggingface.co/papers/2607.01647

27. Morphing into Hybrid Attention Models
🔑 Keywords: FlashMorph, hybrid layer selection, budget-constrained optimization, Transformer-to-hybrid conversion, linear attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve long-context efficiency in Transformers through a budget-constrained subset optimization approach for hybrid layer selection.
🛠️ Research Methods:
– Utilized morphable models and linearization regularization for efficient layer selection.
– Implemented FlashMorph, a scalable method for converting Transformers to hybrid models by optimizing layerwise gates on synthetic long-context retrieval data.
💬 Research Conclusions:
– FlashMorph achieves effective hybrid configurations that maintain strong long-context recall and benchmark performance while reducing layer selection costs, showcasing its effectiveness, efficiency, and scalability.
👉 Paper link: https://huggingface.co/papers/2606.30562

28. EvoPolicyGym: Evaluating Autonomous Policy Evolution in Interactive Environments
🔑 Keywords: Autonomous agents, Policy Evolution, Feedback, EvoPolicyGym, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to explore how autonomous agents can improve executable policies through feedback within fixed resource constraints.
🛠️ Research Methods:
– The research introduces a controlled evaluation setting called Autonomous Policy Evolution, using a benchmark named EvoPolicyGym to assess agents’ iterative policy improvements in interactive reinforcement learning environments.
💬 Research Conclusions:
– The study concludes that strong autonomous policy evolution requires discovering task-specific mechanisms and refining policies with bounded feedback, as demonstrated by GPT-5.5’s top performance across all tested environments.
👉 Paper link: https://huggingface.co/papers/2607.02440
